|

2007 г.
Современные внутренние шины – смена приоритетов!
Максим Шиша
Тестовая лаборатория Ferra
Всё течёт, всё меняется. В сфере компьютерных технологий эта фраза никогда не потеряет актуальности, равно как и девиз «Быстрее! Выше! Сильнее!». И действительно, последние несколько лет можно назвать «временами перемен» компьютерной индустрии. В полной мере это коснулось и такой специфичной области, как шины передачи данных.
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной»1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне2).
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом, он входит в состав набора системной логики (чипсета).
Используемая Intel в настоящее время эволюция FSB – QPB, или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц)3.
В архитектуре же AMD64 (и её микроархитектуре K8), используемой компанией AMD в своих процессорах линеек Athlon 64/Sempron/Opteron, применён революционно новый подход к организации интерфейса центрального процессора – здесь имеет место наличие в самом процессоре нескольких отдельных шин. Одна (или две – в случае двухканального контроллера памяти) шина служит для непосредственной связи процессора с памятью, а вместо процессорной шины FSB и для сообщения с другими процессорами используются высокоскоростные шины HyperTransport. Преимуществом данной схемы является уменьшение задержек (латентности) при обращении процессора к оперативной памяти, ведь из пути следования данных по маршруту «процессор – ОЗУ» (и обратно) исключаются такие весьма загруженные элементы, как интерфейсная шина и контроллер северного моста.
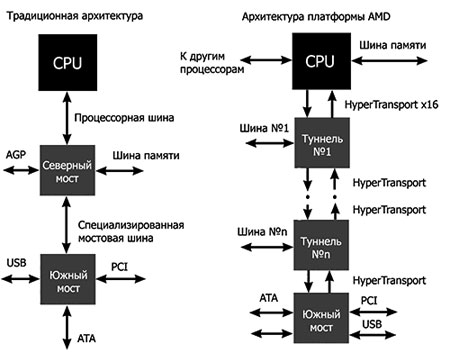
Различия реализации классической архитектуры и АМD-K8
Ещё одним довольно заметным отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора4
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).
HyperTransport

Эмблема HyperTransport Technology Consortium
HyperTransport – это прежде всего технология, управлением спецификациями и продвижением которой занимается HyperTransport Technology Consortium, куда входят такие компании, как Advanced Micro Devices (AMD), Alliance Semiconductor, Apple Computer, Broadcom Corporation, Cisco Systems, NVIDIA, PMC-Sierra, Sun Microsystems, Transmeta и ещё более 140 малых и больших компаний.
Основные особенности и возможности, предоставляемые технологией HyperTransport
Технология HyperTransport (ранее известная как Lightning Data Transport) – это последовательная (пакетная) связь, построенная по схеме peer-to-peer (точка-точка), обеспечивающая высокую скорость при низкой латентности (low-latency responses). HyperTransport имеет оригинальную топологию на основе линков, тоннелей, цепей (цепь – последовательное объединение нескольких туннелей) и мостов (мост выполняет маршрутизацию пакетов между отдельными цепями), что позволяет этой архитектуре легко масштабироваться. Иными словами, HyperTransport призвана упростить внутрисистемные сообщения (передачи) посредством замены существующего физического уровня передачи существующих шин и мостов, а также снизить количество узких мест и задержек. При всех этих достоинствах HyperTransport характеризуется также малым числом выводов (low pin counts) и низкой стоимостью внедрения. HyperTransport поддерживает автоматическое определение ширины шины6, допуская ширину от 2 до 32 бит в каждом направлении, использует Double Data Rate, или DDR (данные посылаются как по переднему, так и по заднему фронтам сигнала синхронизации), кроме того, она позволяет передавать асимметричные потоки данных к периферийным устройствам и от них.
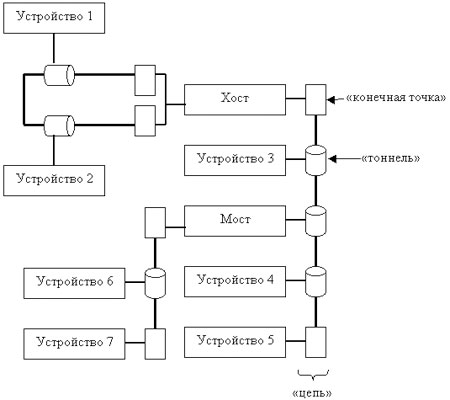
Топология шины HyperTransport
На данный момент консорциумом HyperTransport разработана уже третья версия спецификации, согласно которой шина HyperTransport может работать на частотах до 2,6 ГГц (сравните с шиной PCI и её 33 или 66 МГц). Это позволяет передавать до 5200 миллионов пакетов в секунду при частоте сигнала синхронизации 2,6 ГГц; частота сигнала синхронизации настраивается автоматически.
Полноразмерная (32-битная) полноскоростная (2,6 ГГц) шина способна обеспечить пропускную способность до 20800 МБ/с (2*(32/8)*2600) в каждую сторону, являясь на сегодняшний день самой быстрой шиной среди себе подобных.
Самые известные решения c использованием HyperTransport:
- шина, созданная по технологии HyperTransport, является основной шиной, используемой в процессорах восьмого поколения компании AMD – Athlon 64 и Opteron, а также внутри поддерживающих их устройств: концентратора ввода-вывода (I/O hub) AMD-8111, AMD-8131 PCI-X tunnel и AMD-8151 AGP 3.0 graphics tunnel
- SiPackets предлагает мост между HyperTransport и PCI (HyperTransport-to-PCI bridge)7
- соединение между северным и южным мостами в чипсетах NVIDIA nForce (nForce-nForce 6)
- платформенная архитектура обработки данных NVIDIA (NVIDIA nForce Platform Processing Architecture), включающая встроенный графический процессор NVIDIA (NVIDIA nForce Integrated Graphics Processor (IGP) и процессор передачи данных NVIDIA (NVIDIA nForce Media and Communications Processor (MCP)
- соединение между мостами в чипсете ATI Radeon® Xpress 200 для процессоров AMD
- консольный чипсет игровой приставки Xbox фирмы Microsoft (Microsoft Xbox)
- системный контроллер ServerWorks HT-2000 HyperTransport™ SystemI/O™ Controller
- компьютеры фирмы Apple с процессором PowerPC G5
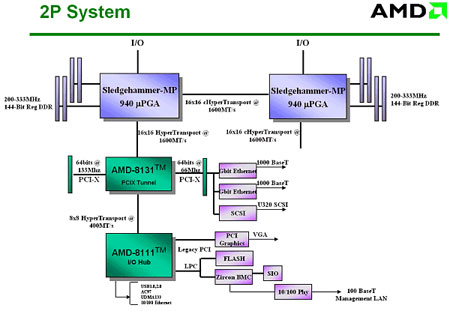
Увеличить
Использование шины НyperТransport на примере двухпроцессорной системы на базе AMD Opteron
| 1(к тексту) | Компьютерная шина (магистраль передачи данных между отдельными функциональными блоками компьютера) – совокупность сигнальных линий, объединённых по их назначению (данные, адреса, управление), которые имеют определённые электрические характеристики и протоколы передачи информации. Шины отличаются разрядностью, способом передачи сигнала (последовательные или параллельные), пропускной способностью, количеством и типами поддерживаемых устройств, протоколом работы, назначением (внутренняя, интерфейсная).
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также могут использовать мультиплексирование (передачу адреса и данных по одним и тем же линиям) и различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами). |
| 2(к тексту) | Основным отличием параллельных шин от последовательных является сам способ передачи данных. В параллельных шинах понятие «ширина шины» соответствует её разрядности – количеству сигнальных линий, или, другими словами, количеству одновременно передаваемых («выставляемых на шину») битов информации. Сигналом для старта и завершения цикла приёма/передачи данных служит внешний синхросигнал. В последовательных же каналах передачи используется одна сигнальная линия (возможно использование двух отдельных каналов для разделения потоков приёма-передачи). Соответственно, информационные биты здесь передаются последовательно. Данные для передачи через последовательную шину облекаются в пакеты (пакет – единица информации, передаваемая как целое между двумя устройствами), в которые, помимо собственно полезных данных, включается некоторое количество служебной информации: старт-биты, заголовки пакетов, синхросигналы, биты чётности или контрольные суммы, стоп-биты и т. п. Но в свете последних достижений в «железной» сфере компьютерной индустрии малое количество сигнальных линий и логически более сложный механизм передачи данных последовательных шин оборачиваются для них существенным преимуществом – возможностью практически безболезненного наращивания рабочих частот в таких пределах, каких никогда не достичь громоздким параллельным шинам с их высокочастотными проблемами ожидания доставки каждого бита к месту назначения. Проблема в том, что каждая линия такой шины имеет свою длину, свою паразитную ёмкость и индуктивность и, соответственно, своё время прохождения сигнала от источника к приёмнику, который вынужден выжидать дополнительное время для гарантии получения данных по всем линиям. Так, к примеру, каждый байт, передаваемый через линк шины PCIExpress, для увеличения помехозащищённости «раздувается» до 10 бит, что, однако, не мешает шине передавать до 0,25 ГБ за секунду по одной паре проводов. Да, ширина последовательной шины на самом деле является количеством одновременно задействованных отдельных последовательных каналов передачи. |
| 3(к тексту) | Кстати, именно результирующей «учетверённой» частотой передачи данных (как и в случае с «удвоенной» передачей DDR-шины, где данные передаются дважды за такт) хвастаются производители и продавцы, умалчивая тот факт, что для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись важнее именно частота тактирования. |
| 4(к тексту) | Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11. |
| 5(к тексту) | Пример: процессор Intel Celeron 1,7GHz Willamette с заявленной на коробке частотой шины FSB-QPB 400 МГц, тем не менее, имеет коэффициент умножения 17 (1700=100*17), а не 4,5. |
| 6(к тексту) | Несмотря на присутствие такого параметра, как ширина, шина HyperTransport является последовательной, что не позволяет соотносить ширину шины с её разрядностью. |
| 7(к тексту) | Напомним, что к процессору х86-архитектуры нельзя напрямую подключать устройства с шинами PCI, так как этот процессор использует свою специализированную процессорную шину, которая, однако, может быть различной у разных процессоров. |
Далее
|
|

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС