СУБД Oracle всегда отличалась богатейшими функциональными возможностями и средствами, состав и количество которых увеличиваются в каждом новом выпуске СУБД. Это помогает пользователям сделать систему базы данных более надежной, мощной и эффективной, но этот рост функциональных возможностей СУБД также оказывает непосредственное влияние и на методы администрирования СУБД. Для того чтобы воспользоваться преимуществами новых функциональных возможностей, АБД должны пересматривать используемые методы администрирования и приводить их в соответствие с каждой новой версией программного обеспечения. В этой работе в общих чертах представлен ряд практических методов, которые могут помочь АБД воспользоваться новыми функциональными возможностями СУБД Oracle9i для повышения надежности, доступности, сопровождаемости и производительности систем баз данных. Мы отдаем себе отчет, что каждый заказчик имеет уникальную систему базы данных, поэтому предлагаемые практические методы должны учитывать это. В данной работе мы делаем акцент на обобщенных методах администрирования, независимых от платформ и среды, но в то же время важных для хорошего сопровождения СУБД. Рассматриваемые методы можно разделить на четыре категории:
Перед созданием базы данных АБД должен принять ряд решений о конфигурировании системы. Правильно принятые решения могут в дальнейшем помочь избежать существенных проблем. В данную категорию попадают определение оптимальной конфигурации подсистемы хранения и выбор подходящего размера блоков базы данных. В данном разделе рассматриваются возможные проблемы и лучшие методы конфигурирования и создания баз данных.
Оптимальное конфигурирование подсистемы хранения базы данных – очень важная задача в большинстве систем. Плохо сконфигурированная подсистема хранения может стать причиной возникновения узких мест ввода-вывода, которые могут существенно снизить скорость работы самой быстрой машины. Поэтому системные администраторы отдают должное конфигурированию внешней памяти и тратят на это очень много времени. Исторически конфигурирование систем хранения базировалось на глубоком понимании приложений базы данных, что приводило к необоснованному усложнению процесса конфигурирования, к уменьшению его управляемости. Альтернативой этого подхода является модель конфигурации внешней памяти SAME (Stripe and Mirror Everything – расщепление и зеркалирование всех данных), в которой предлагается лучший и более управляемый подход. Эта модель была разработана экспертами корпорации Oracle, проделавших значительную исследовательскую работу по определению оптимальной конфигурации внешней памяти систем баз данных Oracle. Модель базируется на четырех простых предложениях:
http://www.oracle.com/ru/oramag/julyaugust2002/index.html?easy_myth2.html.
Вместе с тем, в данном разделе показано, что большинство высказанных замечаний может быть учтено при корректном
использовании модели SAME.]
- Расщепляйте все файлы по всем дискам с шириной полосы расщепления, равной 1 Мб.
Расщепление всех файлов по всем дискам обеспечивает полное использование пропускной способности всех доступных дисководов для любых операций ввода-ввода. Это позволяет равномерно распределить нагрузку по всем дисководам и устранить “горячие участки”. Параллельное выполнение операций и операций с интенсивным вводом-выводом не обязательно должно приводить к возникновению узких мест из-за дисковой конфигурации. Для реконфигурации дискового пространства могут потребоваться большие усилия, поэтому расщепление данных по всем дисководам представляет собой наиболее безопасный и оптимальный вариант. Другим преимуществом расщепления является простота сопровождения. Администраторам для уменьшения времени выполнения запросов с интенсивным обращением к дискам больше не нужно будет заниматься перемещением файлов (а это – нетривиальная задача администрирования). Наиболее простым способом расщепления является расщепление на уровне томов с помощью диспетчеров томов (volume managers). Диспетчеры томов позволяют выполнить расщепление данных по сотням дисков с незначительными накладными расходами ввода-вывода, поэтому в настоящее время они являются лучшим доступным средством для выполнения такой работы.
В результате реализации данного предложения появляется возможность конфигурирования подсистем хранения не только на основании размера базы данных, но и на требуемой пропускной способности ввода-вывода. Например, если общий размер базы данных – 100 гигабайтов с требуемой пропускной способностью – 2000 операций ввода-вывода в секунду, то система может быть сконфигурирована с использованием 20 дисководов размером 5 гигабайтов каждый или же – с 2 дисководами размером 50 гигабайтов каждый. Обе эти конфигурации обеспечивают требуемый объем данных, но только одна из них удовлетворяет требованию пропускной способности ввода-вывода. Таким образом, подсистемы хранения можно конфигурировать, исходя как из требуемого объема данных, так и требуемой пропускной способности ввода-вывода.
Рекомендация использовать размер полосы расщепления (stripe size), равный одному мегабайту, основана на скорости передачи данных и пропускной способности современных дисководов. Чем меньше размер полосы расщепления, тем больше времени тратится на подвод дисковых головок (по сравнению со временем фактической передачи данных). Ниже в таблице 1 показаны результаты наших измерений скоростей передачи данных при различных размерах полосы расщепления. Для этого исследования использовались диспетчер томов Veritas VxVM и подсистема хранения EMC Symmetrix. Как показано в таблице, размер полосы расщепления, равный одному мегабайту, обеспечивает приемлемую пропускную способность, большие размеры полосы дают только незначительные улучшения. Однако, учитывая современные тенденции совершенствования технологии производства дисков, можно предположить, что размер полосы расщепления нужно будет постепенно увеличивать.
Таблица 1. Время передачи данных для различных размеров полосы расщепления.
|
Размер полосы расщепления |
Время позиционирования головок |
Время передачи данных |
% времени передачи данных |
|
16 K |
10 мсек |
1 мсек |
10% |
|
64 K |
10 мсек |
3 мсек |
23% |
|
256 K |
10 мсек |
12 мсек |
55% |
|
1 M |
10 мсек |
50 мсек |
83% |
|
2 M |
10 мсек |
100 мсек |
91% |
Если используются приложения с интенсивным выполнением операций обновления данных, желательно размещать журнальные файлы на отдельных дисках. Особенно в тех случаях, когда в подсистемах хранения отсутствует возможность кеширования операций записи. Кроме того, нужно иметь в виду, запись в журнальные файлы выполняется последовательно (запись за записью, блок за блоком). Во многих подсистемах хранения максимальный объем данных, записываемых одной операцией записи, не превышает одного мегабайта, поэтому для журнальных файлов следует устанавливать меньший размер полосы расщепления, равный 64K.
- Зеркалируйте данные для обеспечения высокой доступности.
Зеркалирование данных на уровне подсистем хранения является лучшим способом предотвращения потери данных. В таких системах данные могут пропасть только в случае одновременного сбоя нескольких дисков, что, учитывая высокую надежность современных дисководов, мало вероятно. Кроме зеркалирования дисков следует также использовать средства мультиплексирования СУБД Oracle. Использование этих средств, однако, ограничено только журнальными и управляющими файлами. Хорошая практическая рекомендация: мультиплексируйте зеркалированные журнальные и управляющие файлы, поскольку мультиплексированные файлы менее подвержены физическому разрушению данных.
(Прим. науч. ред. А.П.Соколова В документации Oracle "мультиплексирование" и "зеркалирование" – разные термины ("При зеркалировании файлов СУБД Oracle выполняет операцию записи один раз, а операционная система выполняет эту же операцию на нескольких дисках, при мультиплексировании СУБД Oracle записывает одни и те же данные в несколько файлов". – Сервер Oracle9i. Концепции резервирования и восстановления). Однако в документации они часто используются и как синонимы.)
- Распределяйте данные по секциям, а не по дискам.
Иногда требуется разделять или секционировать весь набор данных. Например, АБД может захотеть разделить данные только для чтения и записываемые данные по разным томам. В таких случаях следует размещать секции по всем дискам, а потом объединять и расщеплять их для формирования отдельных логических томов. Логическое разделение файлов данных не компрометирует никаких достоинств методологии SAME.
- Размещайте данные, к которым возможен частый доступ, на внешних половинах пространства дисков.
Скорость передачи данных для различных частей поверхности дисков различна – для внешних секторов она выше чем для внутренних. Кроме того, во внешних частях дисков можно размещать больше данных. Поэтому файлы данных с более частым доступом следует размещать на внешних половинах пространства дисков. Журнальные файлы и архивные журнальные файлы, к которым возможен частый доступ при выполнении операций обновления, также следует размещать на внешних половинах пространства дисков. Подобная работа по распределению файлов может привести к дополнительной нагрузке на АБД, поэтому может быть принято простое решение – оставлять внутреннюю часть дисков пустой. Это не настолько расточительное решение, как может показаться, так как более 60% емкости дика размещается на его внешней половине (из-за его круглой формы). Кроме того, современные тенденции увеличения емкости дисководов делают это предложение достаточно жизнеспособным.
Основное достоинство модели SAME заключается в том, что она существенно упрощает конфигурацию системы хранения и подходит для всех режимов рабочей нагрузки. Она одинаково хорошо работает в OLTP-системах, хранилищах данных и при обработке пакетных заданий. Она устраняет "горячие участки ввода-вывода и максимизирует пропускную способность. Наконец, модель SAME не связана с каким-либо технологическим решением управления хранением, доступным сегодня на рынке, и может быть реализована с использованием современных технологий. Более подробно о методологии SAME см. технический документ корпорации Oracle "Optimal Storage Configuration Made Easy" (оптимальная конфигурация внешней памяти, сделанная просто) по адресу
http://otn.oracle.com/deploy/performance/content.html.
Размер блоков базы данных
Одно из первых решений, которое должен принять АБД при создании базы данных в СУБД Oracle, заключается в выборе размера блоков базы данных. Это делается во время создания базы данных установкой значения параметра инициализации DB_BLOCK_SIZE. Этот параметр может иметь значения 2К, 4К, 8К, 16К или 32К байтов. Как правило, размер блоков базы данных должен быть кратным размеру блоков операционной системы. Большой размер блоков базы данных повышает эффективность физического и логического ввода-вывода. Однако, если размер блоков слишком велик, то в каждом блоке можно будет размещать много логических записей, что в OLTP-среде может привести к возникновению конкуренции за блоки. Другой отрицательной стороной использования очень большого размера блоков является то, что при индексном доступе, когда извлекается только одна строка данных, без всякой необходимости читается много лишних данных. Таким образом, достоинства использования большого размера блоков следует балансировать с недостатками их использования. Размеры блоков 4Кб и 8Кб подходят для большинства сред (4Кб более подходит для OLTP-систем, а 8Кб – для DSS-систем).
Если во время создания базы данных выбран неподходящий размер блоков, в СУБД Oracle9i ситуацию можно исправить. Для этого нужно сначала создать новые табличные пространства с надлежащим размером блоков (в операторе создания используется предложение BLOCKSIZE). Затем, с помощью средств СУБД Oracle для оперативной реорганизации можно перенести объекты в эти новые табличные пространства (без остановки экземпляра СУБД). Для таких реорганизаций можно использовать графические средства инструментария Oracle Enterprise Manager. Следует заметить, табличное пространство SYSTEM нельзя реорганизовать оперативно, поэтому размер блоков этого табличного пространства можно изменить только путем повторного создания базы данных. Хорошая практическая рекомендация: во время создания базы данных постараться принимать верные решения и выбрать надлежащий размер блоков базы данных.
Метод создания базы данных
Процесс создания баз данных, их уничтожения и изменения структуры можно упростить с помощью графического инструментального средства конфигурирования Oracle Database Configuration Assistant (DBCA). В режиме адаптации к требованиям пользователей (custom) DBCA позволяет подключать различные опции СУБД (такие, как Spatial – обработка пространственных данных, OLAP-сервисы и т.п.), определять размерные параметры, местонахождение архивных и других файлов, атрибуты хранения, а также, в конце процесса создания базы данных, вручную выполнять все штатные SQL-скрипты. DBCA выполняет все требуемые шаги с минимальным вводом информации и устраняет необходимость детального планирования параметров и структуры базы данных. Более того, DBCA также выдает рекомендации о конкретных установках параметров базы данных в зависимости от введенной информации и, таким образом, помогает АБД принять правильные решения по выбору оптимальной конфигурации базы данных. DBCA можно использовать как для создания баз данных в режиме работы с одним экземпляром СУБД, так и для создания или добавления экземпляров в среде Oracle Real Application Cluster.
В СУБД Oracle9i в DBCA введено понятие шаблонов баз данных (database templates), которое существенно упрощает сопровождение баз данных. Шаблоны баз данных – это новый механизм хранения определений баз данных в XML-формате. В определения включаются все характеристики баз данных, такие, как параметры инициализации, журнальных файлов и т.п.; они могут использоваться для создания идентичных баз данных как в локальных машинах, так и в удаленных. Существует два вида шаблонов: для создания только структур баз данных и для создания структур совместно с данными. Эта функциональная возможность позволяет АБД создавать новые базы данных с помощью предопределенных шаблонов или создавать по существующей базе данных новые шаблоны для их последующего использования. В результате, с помощью этого нового мощного средства существующие базы данных можно "клонировать" с данными или без данных. Шаблоны можно сохранять и повторно использовать для развертывания новых баз данных.
Используя предопределенные шаблоны, DBCA можно запускать в пакетном (silent) режиме и автоматически создавать базы данных или связанные с ними приложения. Это означает, что запуск заданий создания баз данных можно осуществлять с помощью планировщика заданий ОС без какого-либо вмешательства АБД. Все эти возможности делают DBCA очень мощным средством, которое мы рекомендуем для создания баз данных и экземпляров СУБД Oracle.
Сопровождение пространства и объектов
В СУБД Oracle9i для облегчения сопровождения различных объектов базы данных и повышения производительности работы с ними сделан ряд усовершенствований. Карл Бутнер (Karl Buttner), президент компании "170 Systems", приветствуя новые средства СУБД Oracle9i, заявляет: "усовершенствованные средства администрирования и управления базами данных позволяют нашим заказчикам снизить их административные и эксплуатационные издержки, повышая при этом доступность и производительность своих систем". Одним из наиболее значительных усовершенствований в сфере сопровождения СУБД Oracle9i является появление опции Automatic Undo Management (автоматическое управление пространством отката транзакций) которая позволяет устранить необходимость вручную сопровождать сегменты отката. Коме того, улучшено управление табличными пространствами и сегментами, которое при соответствующем использовании позволяет существенно снизить объем работы АБД.
Автоматическое управление пространством отката транзакций
Для упрощения сопровождения сегментов отката в СУБД Oracle9i введено автоматическое управление пространством отката транзакций (Automatic Undo Management), которое позволяет серверу базы данных автоматически управлять выделением и сопровождением пространства отката транзакций для различных активных сеансов. Администраторам уже не нужно вручную создавать сегменты отката (rollback segments). Вместо этого, они могут просто создать табличное пространство отката (табличное пространство типа UNDO) и выделить для него достаточный объем дисковой памяти.
Первым преимуществом такого подхода является улучшение сопровождаемости. АБД больше не требуется назначать некоторым транзакциям конкретные сегменты отката или беспокоиться об их размере и количестве.
Другим преимуществом автоматического управления пространством отката транзакций является то, что существенно ограничивается возможность конкуренции за блоки для отката и блоки для согласованного чтения. Используя это средство, СУБД Oracle динамически регулирует количество сегментов отката (undo segments), удовлетворяющее потребностям текущей рабочей нагрузки. При необходимости она создает дополнительные сегменты отката (undo segments). В то же время, по мере необходимости сегменты отката переводятся в автономный или оперативный режимы, позволяя регулировать использование памяти в зависимости от текущей рабочей нагрузки. Все эти операции выполняются без вмешательства администратора. АБД только должен установить в параметре инициализации UNDO_MANAGEMEN (управление пространством отката транзакций) значение AUTO (автоматическое), а в параметре UNDO_RETENTION (сохранение информации в пространстве отката) – время выполнения самого продолжительного запроса, а также выделить достаточное пространство для табличного пространства отката. В Enterprise Manager для этого предусмотрено инструментальное средство определения размера табличного пространства отката в зависимости от времени сохранения сегментов отката.
Например, для конфигурирования сервера базы, в котором продолжительность выполнения запросов не превышает 30 минут, АБД может просто установить в параметре UNDO_RETENTION значение, равное 30 минутам. С помощью управления временем сохранения информации сегментов отката пользователи могут успешно выполнять продолжительные запросы без возникновения неприятной ошибки ORA-1555 (snapshot too old – моментальная копия слишком стара).
Локально управляемые табличные пространства
Локально управляемые табличные пространства (locally managed tablespaces) работают лучше табличных пространств, управляемых с помощью словаря данных (dictionary managed tablespaces), их легче сопровождать и они устраняют проблемы, связанные с фрагментацией пространства. Для выполнения операций, типа выделение и освобождение пространства, в них используются битовые карты, которые хранятся в заголовках файлов данных и, в отличии от табличных пространств, управляемых с помощью словаря данных, и при работе с ними не нужно конкурировать за централизованные ресурсы. Это устраняет необходимость выполнения многих рекурсивных операций, которые иногда требуются для табличных пространств, управляемых с помощью словаря данных, таких, как выделение нового экстента.
В локально управляемых табличных пространствах для управления экстентами предлагается два режима: Auto Allocate (автоматическое выделение) и Uniform (выделение экстентов одинакового размера). В режиме Auto Allocate СУБД Oracle определяет размер каждого выделяемого экстента без вмешательства АБД, тогда как в режиме Uniform АБД указывает размер всех экстентов, выделяемых в данном табличном пространстве. Мы рекомендуем использовать режим Auto Allocate, поскольку, несмотря на то, что в этом режиме у объектов могут появиться множественные экстенты, пользователям не нужно об этом беспокоиться, так как локально управляемые табличные пространства могут поддерживать большое количество экстентов (свыше 1000 для каждого объекта), причем без заметного влияния на производительность. Поэтому мы полагаем, что АБД не будут беспокоиться о размере экстентов и использовать режим Auto Allocate.
В СУБД Oracle9i пользователи могут перемещать табличные пространства, управляемые с помощью словаря данных, в локально управляемые табличные пространства с помощью процедуры PL/SQL DBMS_SPACE_ADMINISTRATION.TABLESPACE_MIGRATE_TO_LOCAL. Это позволяет осуществлять переход с более ранних версий СУБД Oracle и использовать преимущества локально управляемых табличных пространств. Начиная с СУБД Oracle9i Release 2 все табличные пространства (исключая табличное пространство SYSTEM) по умолчанию создаются как локально управляемые табличные пространства.
Временные табличные пространства
В СУБД Oracle для выполнения различных операций сортировки создаются временные сегменты. Использование постоянных табличных пространств для таких сегментов ведет к излишним накладным расходам по управлению пространством, аналогичным расходам по управлению пространством для постоянных данных. Хорошей практикой в таких случаях является использование специального типа табличного пространства, которое называется Temporary Tablespace (временное табличное пространство). Во временном табличном пространстве выделение пространства осуществляется посредством выборки экстентов из пула в SGA, снижая, таким образом, конкуренцию множественных операций сортировки, уменьшая накладные расходы и устраняя множественные операции управления пространством. Во временном табличном пространстве все операции сортировки разделяют один и тот же сегмент сортировки данного табличного пространства. Ясно, что это представляет собой наиболее эффективный способ работы с временными сегментами, как с точки зрения использования системных ресурсов, так и производительности системы баз данных.
Временные табличные пространства могут управляться как локально, так и с помощью словаря данных. После обсуждения преимуществ использования локально управляемых табличных пространств понятно, что предпочтительно создавать локально управляемое временное табличное пространство. Локально управляемые временные табличные пространства не требуют резервирования и могут использоваться как в базах данных только для чтения, так и в резервных базах данных. Следует отметить, оператор создания таких табличных пространств отличается от операторов создания других табличных пространств: CREATE TEMPORARY TABLESPACE <имя> TEMPFILE <имя_файла> SIZE <размер_файла> EXTENT MANAGEMENT LOCAL.
В СУБД Oracle9i АБД могут для всей базы данных устанавливать Default Temporary Tablespace (временное табличное пространство по умолчанию). Это делается с помощью предложения DEFAULT TEMPORARY TABLESPACE операторов CREATE DATABASE или ALTER DATABASE. Использование опции "временное табличное пространство по умолчанию" гарантирует, что всем пользователям будет назначаться временное табличное пространство. Это обеспечивает выполнение всех дисковых сортировок во временном табличном пространстве, а не в табличном пространстве SYSTEM, которое ошибочно может быть использовано для выполнения сортировок. Кроме того, опция "временное табличное пространство по умолчанию" гарантирует, что постоянные и временные объекты не будут совместно использовать одно и то же табличное пространство – еще одна хорошая практическая рекомендация.
Сопровождение сегментов
Другим вопросом, интересующим АБД, является сопровождение пространства для объектов базы данных. Начиная с СУБД Oracle9i, АБД получают возможность сопровождения пространства для объектов автоматически с помощью опции Automatic Segment Space Management (автоматическое управление пространством сегментов). Она упрощает задачи администрирования пространства и устраняет многие задачи оптимизации производительности, связанные с управлением пространством. Она облегчает сопровождение свободного пространства в таблицах и индексах, повышает уровень использования пространства и обеспечивает существенно лучшие "коробочные" производительность и масштабируемость.
До СУБД Oracle9i администрирование управления пространством осуществлялось с помощью структур данных, называемых FREELISTS (списки свободных блоков). С помощью FREELISTS СУБД следила за блоками объектов, в которых имелось достаточное свободное пространство для вставки новых строк. АБД при создании объектов определял для объектов количество списков свободных блоков и количество групп списков свободных блоков (FREELIST GROUPS), а на уровне таблиц использовался параметр PCTUSED (процент использованного пространства), с помощью которого осуществлялось управление размещением и удалением блоков из списков свободных блоков.
Новый механизм, введенный в СУБД Oracle9i, делает управление пространством в объектах полностью прозрачным, используя для этого битовые карты, позволяющие отслеживать использование пространства в каждом блоке данных, выделенном объекту. Состояние битовой карты показывает, сколько в данном блоке данных имеется свободного пространства (например, >75%, от 50% до 75%, от 25% to 50% или <25%), а также, является ли оно сформатированным или нет. Эта новая реализация освобождает АБД от необходимости ручного управления пространством в объектах. Другим преимуществом механизма автоматического управления пространством сегментов является повышение использования пространства в блоках данных. Причина заключается в том, что битовые карты по сравнению с FREELISTS намного лучше приспособлены для отслеживания и управления свободным пространством на уровне блоков данных. Это делает возможным улучшение повторного использования доступного свободного пространства, особенно для объектов со строками переменного размера. Кроме того, механизм Automatic Segment Space Management существенно повышает производительность конкурентных DML-операций, так как различные части битовой карты могут быть использоваться одновременно, устраняя сериализацию при поиске достаточного свободного пространства.
Улучшение производительности и сопровождаемости, обеспечиваемое механизмом Automatic Segment Space Management особенно заметно в среде Real Application Cluster. Ниже, на рис. 1, показаны результаты внутреннего тестирования, проведенного в СУБД Oracle для сравнения производительности при автоматическом и ручном управлении пространством в сегментах. Этот тест проводился в среде Real Application Cluster в двух узлах (каждый узел имел 6 x 336 Мгц ЦП, 4 Гбайта ОП), при этом в таблицу вставлялось около 3 миллионов строк. Механизм Automatic Segment Space Management обеспечил, по сравнению с оптимально настроенным ручным режимом (8 FREELIST GROUPS, 20 FREELISTS), повышение производительности более чем на 35%.
Рис. 1. Механизм Automatic Segment Space Management обеспечивает лучшую производительность.
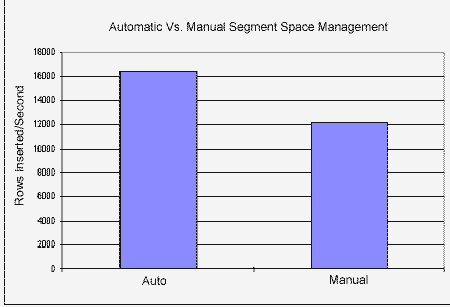
Надписи на рисунке:
- Automatic Vs. Manual Segment Space Management – автоматическое управление пространством сегментов по сравнению с ручным;
- Rows Inserted/Second
– строки, вставленные в секунду;
- Auto
– автоматическое;
- Manual
– ручное.
Механизм Automatic Segment Space Management доступен только в локально управляемых табличных пространствах (locally managed tablespaces). В операторе CREATE TABLESPACE (создать табличное пространство) появилось новое предложение SEGMENT SPACE MANAGEMENT (управление пространством сегментов), которое имеет два параметра: AUTO (автоматическое) и MANUAL (ручное). Параметр AUTO позволяет использовать механизм Automatic Segment Space Management, а в режиме MANUAL для управления свободным пространством в объектах по-прежнему будут использоваться списки свободных блоков.
Плохо настроенная система – это только небольшой шаг, чтобы система стала недоступной. Настройка системы баз данных должна обеспечивать приемлемую производительность, поэтому настройка имеет у АБД высший приоритет. В СУБД Oracle9i появилось несколько новых функциональных возможностей, облегчающих настройку. Марк Шейман (Mark Shaiman), старший научный аналитик компании META Group, подтверждает: “Хотя СУБД Oracle всегда обладала существенными функциональными возможностями, в общем, для достижения оптимальной производительности требовались различные "настройки". В СУБД Oracle9i автоматизированы многие вспомогательные процессы, позволяющие АБД облегчить сопровождение и обеспечить "дружественность по отношению к пользователям" ”. В этом разделе мы обсудим ряд хороших практических методов в свете новых возможностей СУБД Oracle9i.
Общая методология
Оптимизация производительности – это не одноразовая задача, а постоянный процесс. Для эффективной настройки систем баз данных требуются хорошие методы и инструментальные средства. В комплексный процесс оптимизации производительности должны входить следующие шаги:
- Регулярный сбор полного набора статистических показателей операционной системы, экземпляров СУБД и приложений.
АБД всегда должны иметь набор статистических показателей, собранных в конкретный момент времени, которые они должны использовать как базовый набор для сравнения. Когда они будут пытаться определить причину деградации производительности или пытаться повысить производительность, сравнение текущих статистических показателей с базовыми статистическими показателями поможет АБД быстро определить главную область приложения усилий. Это даже более важно в случае перехода на новую версию СУБД. Статистические показатели всегда следует собирать перед и после перехода на новую версию СУБД, что может позволить АБД в случае неожидаемого поведения системы определить, настолько быстро, насколько возможно, причину проблемы. Для этих целей в СУБД Oracle предусмотрена утилита StatsPack. StatsPack – это инструментальное средство для комплексного диагностирования проблем производительности на уровне СУБД и приложений. Эта утилита может быть настроена для снятия "моментальных копий" данных производительности и сохранения их в постоянных таблицах базы данных. Пользователь может задать интервал снятия моментальных копий, т.е. частоту сбора данных, а также количество собираемых статистических показателей. Более подробно об инсталляции и использовании утилиты StatsPack см. в технических документах "Diagnosing Performance Using StatsPack, Part I and II" (диагностирование производительности с помощью пакета StatsPack, части I и II)
(http://otn.Oracle.com/deploy/performance/content.html).
- Определение проблемных областей.
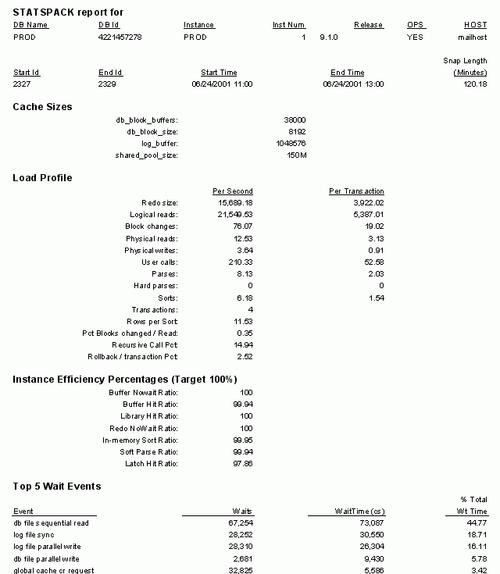
Главная цель сбора статистических показателей – определить проблемы производительности сервера базы данных. Утилита StatsPack выдает легкочитаемый отчет, который указывает на потенциальные области проблем производительности. Итоговая страница типового отчета утилиты StatsPack показана на рис. 2. Этот отчет наиболее полезен, когда для сравнения с текущими показателями производительности системы имеются базовые показатели, поскольку это позволяет АБД обнаружить, что действительно изменилось в системе. Например, если бы процент использования разделяемого пула существенно увеличился, это указало бы на возможное использование в приложениях литеральных значений, приводящее к дополнительному разбору операторов SQL и, следовательно, к замедлению работы системы.
Рис. 2. На первой странице типового отчета утилиты StatsPack на первом плане размещаются ключевые данные о системе.
- Определение потенциальных решений.
Как только проблемные области будут идентифицированы, определение потенциальных решений будет относительно простой задачей. Например предположим, на шаге (ii) мы обнаружили, что причиной появления узких мест в системе является использование в хранимых процедурах литеральных значений. Очевидным решением этой проблемы является замена в хранимых процедурах литеральных значений на переменные связывания. Если приложение очень большое, такое, как большинство ERP-приложений, это решение может оказаться нежизнеспособным. В таком случае лучшим решением было бы включение принудительного разделение курсоров с помощью установки параметра инициализации CURSOR_SHARING=FORCE. Таким способом следует наметить в общих чертах одно или более решений для каждой идентифицированной проблемной области.
- Реализация решений.
Золотое правило настройки системы – одновременное внесение одного изменения, а затем измерение возникших различий. Давайте предположим, что на шаге (ii) мы идентифицировали несколько проблемных областей, а на следующем шаге определили потенциальные
способы решения проблем. Рекомендуемое правило заключается в реализации каждого способа по отдельности, а затем в измерении его влияния на систему. Однако требования к времени простоя системы могут не позволить воспользоваться таким правилом. В этом случае нужно попытаться реализовать только такой набор способов, которые можно проверить независимо.
- Повторение процесса.
Как только способ решения проблем реализован, его необходимо проверить. Проверку следует осуществлять на уровне пользовательского восприятия производительности, а также повторением шага (i) и сбора дополнительных статистических показателей, позволяющих оценить, имеет ли данный способ желательное влияние или нет. Кроме того, если нагрузка на систему со временем изменяется или модифицируются приложения, весь процесс настройки следует повторить.
Настройка кеша буферов.
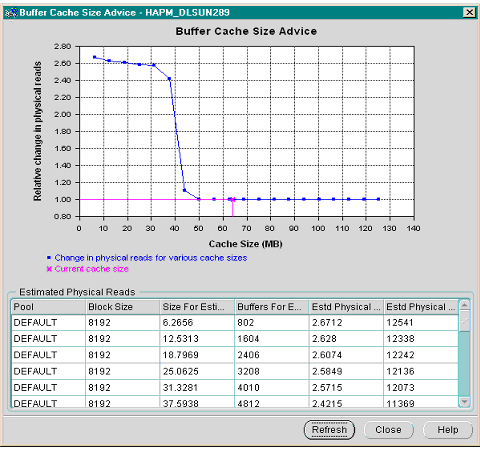
Некоторые структуры оперативной памяти СУБД, такие, как кеш буферов, существенно влияют на производительность СУБД. Несмотря на то, что утилита StatsPack раскрывает тайны процесса настройки, важность хорошо настроенного кеша буферов заслуживает более строгого метода. С этой целью в СУБД Oracle9i введен механизм консультативной справки по кешу буферов (Buffer Cache Advisory). Эта справка выдается по результатам внутреннего моделирования, основанного на текущей рабочей нагрузке. Справка предсказывает частоту неудачных обращений к кешу для различных размеров кеша буферов в диапазоне от 10% до 200% текущего размера кеша. Эти предсказания публикуются через новое представление V$DB_CACHE_ADVICE, которое можно использовать для определения оптимального размера кеша буферов при существующей рабочей нагрузке. В Oracle Enterprise Manager имеется удобное средство, которое интерпретирует данные представления V$DB_CACHE_ADVICE (см. рис. 3). Обеспечивая детерминированный способ определения размера кеша буферов, СУБД Oracle9i берет на себя работу по предсказанию конфигурации кеша буферов.
Рис 3. Консультативная справка по кешу буферов.
АБД должны использовать эту консультативную справку для настройки кеша буферов. Все консультативные справки, включая консультативную справку по кешу буферов, и сбор статистических данных в СУБД Oracle9i Release 2 управляются с помощью одного параметра STATISTICS_LEVEL (уровень сбора статистических данных). У него может быть три возможных значения: BASIC (базовый), TYPICAL (типовой) и ALL (все). Значение по умолчанию – TYPICAL. Значения TYPICAL и ALL позволяют включать в сервере механизмы создания консультативных справок: Buffer Cache Advisory (кеш буферов), Shared Pool Advisory (разделяемый пул), PGA Advisory (программная глобальная область) и MTTR Advisory (ожидаемое среднее время восстановления). При этом оказывается незначительное влияние на производительность, связанное со сбором данных и моделированием кеша. Однако выгоды от надлежащим образом настроенной памяти намного перевешивают эти накладные расходы.
Настройка разделяемого пула.
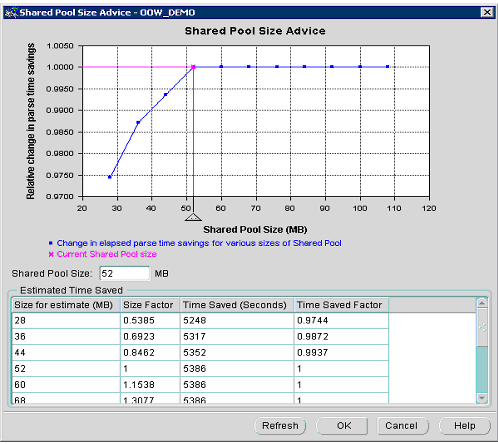
Разделяемый пул, так же как и кеш буферов, представляет собой важную структуру оперативной памяти, которую необходимо тщательно настраивать для обеспечения высокой производительности сервера базы данных. Влияние настройки разделяемого пула на время реакции СУБД Oracle идентично настройке кеша буферов – облегчайте настройку, используя консультативные справки, которые основаны на внутреннем моделировании рабочей нагрузки. Статистические данные консультативной справки по разделяемому пулу (Shared Pool Advisory) позволяют отслеживать использование библиотечного кеша в памяти разделяемого пула и предсказывать изменение общего времени разбора на уровне экземпляра для различных размеров разделяемого пула. Два новых представления, V$SHARED_POOL_ADVICE и V$LIBRARY_CACHE_MEMORY содержат информацию для определения, сколько памяти используется для библиотечного кеша, сколько памяти закреплено в настоящее время, сколько объектов в LRU-списке разделяемого пула, а также сколько времени может быть потеряно или сэкономлено при изменении размера разделяемого пула. Представление V$SHARED_POOL_ADVICE содержит информацию о расчетной экономии времени разбора для различных размеров разделяемого пула. Эти размеры варьируются в пределах от 50% до 200% текущего размера разделяемого пула с равными интервалами изменения. В Oracle Enterprise Manager имеется средство графической визуализации этого моделирования, с которым проще работать, чем с представлением V$SHARED_POOL_ADVICE через интерфейс командной строки (см. рис. 4).
Рис. 4. Консультативная справка по разделяемому пулу.
Консультативная справка по разделяемому пулу также управляется с помощью параметра STATISTICS_LEVEL. Когда в параметре установлены значения TYPICAL или ALL, механизм создания этой справки включается, для его отключения следует установить значение BASIC. Как отмечено ранее, с помощью параметра STATISTICS_LEVEL выполняется управление сбором статистических данных для всех консультативных справок. Установка в нем значения BASIC отключит все справки.
Настройка памяти для выполнения операторов SQL.
Производительность выполнения сложных долго работающих запросов, типичных в DSS-среде, существенно зависит от размера памяти, доступной в программной глобальной области (PGA, Program Global Area). В СУБД Oracle8i администраторы устанавливают размер PGA, тщательно настраивая ряд параметров инициализации, таких, как SORT_AREA_SIZE, HASH_AREA_SIZE, BITMAP_MERGE_AREA_SIZE, CREATE_BITMAP_AREA_SIZE и т.д. В СУБД Oracle9i появилась опция полностью автоматического управления памятью PGA. Администраторам нужно просто указать максимальный объем памяти PGA, доступной экземпляру СУБД. Для этого используется новый параметр инициализации PGA_AGGREGATE_TARGET (суммарная память PGA). Сервер базы данных автоматически некоторым интеллектуальным способом распределяет эту память между различными активными запросами так, чтобы обеспечить максимальную производительность и наиболее эффективно использовать память. Кроме того, СУБД Oracle9i может сама адаптироваться к изменению рабочей нагрузки, таким образом ресурсы используются эффективно независимо от нагрузки на систему. Объем памяти PGA, доступной экземпляру, можно изменять динамически, изменяя значение параметра PGA_AGGREGATE_TARGET. Это позволяет оперативно добавлять или отнимать память PGA у активного экземпляра. АБД должны использовать данную опцию и не пытаться настраивать PGA вручную, поскольку машина базы данных лучше оснащена средствами определения потребностей в памяти для выполнения операторов SQL. Это относится как к повышению пропускной способности систем с большим количеством пользователей, так и к уменьшению времени ответа при выполнении запросов.
С этой самонастраивающейся PGA единственная остающаяся задача для АБД состоит в том, чтобы установить надлежащим образом значение параметра PGA_AGGREGATE_TARGET. Это очень просто делать с помощью новой консультативной справки по размеру PGA (PGA Advisory), введенной в СУБД Oracle9i Release 2. Как и консультативная справка по кешу буферов эта справка использует внутреннее моделирование для предсказания оптимального размера PGA при текущей рабочей нагрузке. В представлении V$PGA_TARGET_ADVICE содержатся результаты этого моделирования, показывающие надлежащее значение параметра PGA_AGGREGATE_TARGET. В Oracle Enterprise Manager имеется очень простое средство графической визуализации этого моделирования (см. рис. 5).
Рис. 5. Консультативная справка по PGA.
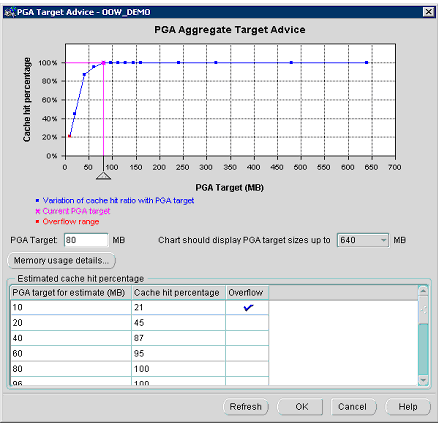
Средство автоматического управления памятью для выполнения операторов SQL включается установкой в файле инициализации значения в параметре PGA_AGGREGATE_TARGET, в противном случае сервер базы данных вернется в режим ручного управления памятью PGA. Для включения механизма создания консультативной справки по PGA необходимо в параметре инициализации STATISTICS_LEVEL установить значение TYPICAL или ALL.
Несмотря на то что повышение производительности наиболее значительным будет в DSS-среде с большой рабочей нагрузкой, это средство будет также полезно и в OLTP-среде. В большинстве OLTP-приложений требуется регулярно подготавливать сложные отчеты, производительность их подготовки может быть повышена благодаря автоматической настройке рабочих областей PGA. Следовательно, АБД должны использовать это средство совместно с консультативной справкой по PGA независимо от характера нагрузки на их системы.
Общие причины проблем производительности
Итак, мы обсудили лучшие практические методы оптимизации производительности, давайте сейчас рассмотрим методы, использование которых приводит к возникновению проблем производительности. Наша рекомендация здесь очень простая: "избегайте их".
- Плохое управление соединениями.
Приложение соединяется и отсоединяется от базы данных при каждом взаимодействии с ней. Это – обычная проблема программного обеспечения промежуточного слоя в серверах приложений. Эта ошибка снижает производительность более чем на два порядка, а также полностью отсутствует масштабируемость. Возможное решение – трехзвенная архитектура, когда пользователи или клиенты соединяются со средним звеном, который имеет постоянные соединения с базой данных. Таким образом, одно постоянное соединение с базой данных может быть использовано разными пользователями.
- Плохое совместное использование курсоров.
Отсутствие разделения курсоров приводит к многократным разборам. Если не используются переменные связывания, то выполняется полный разбор (hard parsing) всех операторов SQL. Это имеет существенное отрицательное влияние на производительность. В курсорах, которые открываются и повторно используются много раз, следует использовать переменные связывания. Для больших приложений, в которых не используются переменные связывания, разделение курсоров можно включить принудительно, установив параметр инициализации CURSOR_SHARING=FORCE.
- Неправильное конфигурирование ввода-вывода.
На многих установках базы данных неудачно размещаются на доступных дисках. На других установках неправильно задается количество дисков, так как диски конфигурируются по дисковому пространству, а не по пропускной способности ввода-вывода. Этой проблемы можно избежать, используя методологию SAME, которая была рассмотрена в начале этой статьи.
- Проблемы конфигурирования журнала базы данных.
На многих установках слишком мало журнальных файлов и размер их слишком мал. Небольшие журнальные файлы являются причиной частых переключений журнальных файлов, которые могут существенно нагрузить кеш буферов и систему ввода-вывода. Если журнальных файлов слишком мало, процесс архивирования может не справляться со своей работой и работа сервера базы данных будет приостанавливаться. Общее правило: базы данных должны иметь по крайней мере 3 журнальных группы с двумя журнальными файлами в каждой.
- Нехватка списков свободных блоков, групп списков свободных блоков и сегментов отката.
В кеше буферов может возникать сериализация блоков данных из-за нехватки списков свободных блоков (free lists), групп списков свободных блоков (free list groups), участков транзакций (INITRANS) или сегментов отката (rollback segments). Особенно часто это возникает в приложениях, часто выполняющих операции вставки данных в базу данных с большим размером блоков (от 8Kб до 16Kб). Этой проблемы легко избежать, используя опцию автоматического управления пространством сегментов (Automatic Segment Space Management) вместе с опцией автоматического управления откатом (Automatic Undo Management).
- Длительные полные просмотры таблиц.
Длительные полные просмотры таблиц в операциях большого объема или в интерактивных операциях, выполняемых в оперативном режиме, могут указывать на неудовлетворительное проектирование транзакций, отсутствие индексов или плохую оптимизацию операторов SQL. Длительные полные просмотры таблиц по своей природе являются операциями, интенсивными по вводу-выводу и немасштабируемыми при увеличении количества пользователей. В пакете настройки (tuning pack) Enterprise Manager предлагается мощный инструмент, SQL-анализатор (SQL Analyze), для обнаружения и оптимизации операторов SQL, интенсивно потребляющих ресурсы. Это – хороший способ решения проблем оптимизации операторов SQL.
- Дисковые сортировки.
Дисковые сортировки, в противоположность сортировкам в оперативной памяти, могут в операциях, выполняемых в оперативном режиме, указывать на неудовлетворительное проектирование транзакций, отсутствие индексов, неоптимальное конфигурирование PGA или плохую оптимизацию операторов SQL. Дисковые сортировки по своей природе являются операциями, интенсивными по вводу-выводу и немасштабируемыми. Эту проблему можно устранить, выделяя память PGA достаточного размера и используя опцию автоматической настройки PGA (Automatic PGA Tuning), рассмотренную выше.
- Большие объемы рекурсивных операций SQL.
Большие объемы рекурсивных операций SQL, выполняемых в схеме SYS, могут указывать, что имеют место действия по управлению пространством, такие, как выделение экстентов. Эти действия немасштабируемы и влияют на время реакции системы. Обычно это возникает при использовании табличных пространств, управляемых с помощью словаря данных, (dictionary managed tablespaces). В таких случаях повышению производительности может помочь использование локально управляемых табличных пространств (locally managed tablespaces), существенно уменьшающих объемы рекурсивных операций SQL.
- Ошибки схем и оптимизатор.
Во многих случаях в приложении используются чрезмерные ресурсы из-за того, что схема, которой принадлежат ресурсы, была неправильно перенесена из среды разработки или из более старой среды промышленной эксплуатации. Примеры: отсутствие индексов или некорректные статистические данные. Эти ошибки могут привести к появлению неоптимальных планов выполнения и низкой производительности интерактивной работы пользователей. При переносе приложений с известной производительностью для поддержи стабильности планов экспортируйте статистические данные схемы с помощью пакета DBMS_STATS. Более того, набор параметров оптимизатора, установленный в файле параметров инициализации, может привести к изменению испытанных оптимальных планов выполнения. По этим причинам для обеспечения устойчивой производительности статистическими данными схемы и параметрами оптимизатора следует управлять вместе как группой.
- Использование нестандартных параметров инициализации.
Они могли быть установлены на основании плохого совета, неправильного предположения или предшествующей потребности. В частности, параметры, связанные со счетчиком циклических запросов защелок (spin_count ) и недокументированными возможностями оптимизатора, могут привести к возникновению большого количества проблем, которые могут потребовать значительного исследования.
Резервирование и восстановление
Просто говоря, здесь могут происходить плохие дела. Может быть полный отказ систем, файлы могут ошибочно удаляться, могут происходить сбои носителя. АБД, у которого нет обоснованной стратегии резервирования и восстановления для разрешения таких ситуаций, должен иметь под рукой свое резюме о поступлении на работу. В этом разделе мы кратко рассмотрим некоторые процедуры и практические методы, которые помогут АБД сохранить свою работу.
У бизнеса должна быть стратегия восстановления после катастроф, которые приводят к потере данных. В настоящее время только 45% компаний из списка крупнейших компаний мира (Fortune 500) имеют формальные стратегии для своей защиты от бедственной потери данных. Только 12% из этих стратегий рассматриваются на корпоративном уровне ("Calculating the Cost of Downtime" (вычисление стоимости времени простоя), Анжела Карр (Angela Karr), Advanstar Communications). При разработке формальной стратегии АБД должны планировать потерю данных из-за неожиданных отказов, причинами которых могут быть аппаратные или программные сбои, человеческие ошибки, природные явления и т.д. Для каждого из таких возможных событий АБД должны иметь план действий. В некоторых случаях может потребоваться восстановление носителя, в других будет достаточно восстановления экземпляра. Для обеих этих ситуаций АБД должны иметь планы действий. Мы рассмотрим их в этом разделе ниже. В конце концов, администратор базы данных и системный администратор должны документировать среду базы данных и стратегии восстановления, чтобы при возникновении сбоя АБД мог диагностировать проблему и немедленно заняться ее решением.
Планирование восстановления экземпляра
Работа систем может аварийно завершаться по разным причинам, например, из-за прекращения подачи электроэнергии. В этом случае после перезапуска экземпляра СУБД и до открытия базы данных для пользователей будет выполняться восстановление экземпляра. Цель восстановления экземпляра – восстановление физического содержимого базы данных в транзакционно согласованное состояние. Поэтому во время восстановления должны применяться все сделанные зафиксированными транзакциями изменения, которые находились в кеше буферов и не были записаны на диск до сбоя, а затем выполняется откат всех записанных на диск изменений, сделанных незафиксированными транзакциями. Восстановление экземпляра выполняется внутренними механизмами СУБД Oracle и не требует вмешательства администратора. Единственный аспект, о котором должен заботиться АБД – продолжительность выполнения восстановления; это легко контролируется настройкой в файле инициализации параметра FAST_START_MTTR_TARGET (MTTR – mean time to recover, среднее время восстановления). В системах, в которых размер кеша буферов составляет много гигабайтов, восстановление экземпляра может быть очень длительным с совершенно не предсказуемым временем восстановления. Для АБД оба эти свойства мало допустимы. Новая опция быстрого восстановления с предсказуемым временем (Fast-Start Time-Based Recovery) в СУБД Oracle9i позволяет АБД задавать среднее время восстановления экземпляра (в секундах) с помощью установки значения в параметре FAST_START_MTTR_TARGET. Эта опция реализуется ограничением количества "грязных" буферов и количества журнальных записей, сгенерированных после последней контрольной точки. Для обеспечения заданного времени восстановления сервер базы данных по существу регулирует скорость выполнения контрольных точек.
Если в параметре FAST_START_MTTR_TARGET установлено слишком низкое значение, сервер базы данных будет писать на диск очень часто, и это может привести к снижению скорости работы системы. Поэтому этот параметр необходимо настраивать так, чтобы сервер не выполнял чрезмерное количество контрольных точек, но при этом время восстановления оставалось бы в приемлемых пределах. С этой целью в СУБД Oracle9i Release 2 введена новая консультативная справка по MTTR (MTTR Advisory). Эта справка позволяет экземпляру оценивать (в процентах) изменение количества записей на диск, которое могло бы произойти при других значениях в параметре FAST_START_MTTR_TARGET. Используя оценку, полученную при типичной рабочей нагрузке на экземпляр, вы можете определить влияние повышения или понижения значения в данном параметре. Значения консультативной справки по MTTR содержатся в представлении V$MTTR_TARGET_ADVICE. Это представление имеет пять строк, которые показывают предполагаемую дисковую активность при различных значениях в параметре FAST_START_MTTR_TARGET: текущее значение; приблизительно десятая часть текущего значения; приблизительно половина текущего значения; приблизительно полтора текущего значения и приблизительно двойное текущее значение. В Enterprise Manager можно получить графическое представление консультативной справки по MTTR (см. рис. 6).
Теперь АБД имеют инструментарий для управления временем восстановления экземпляра и могут это делать без компрометирования производительности системы. Они должны использовать этот инструментарий, поскольку он позволяет сделать время восстановления экземпляра предсказуемым, а также дает ручки настройки этого времени в соответствии с их потребностями.
Рис. 6. Консультативная справка по MTTR.
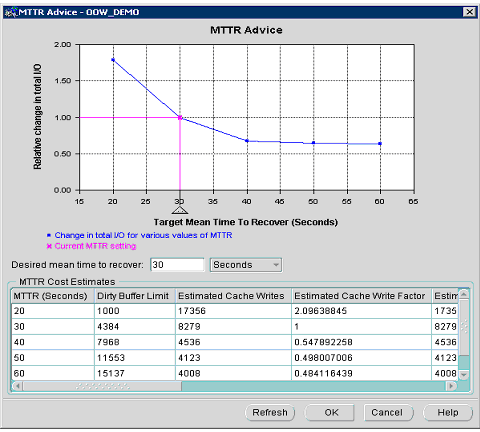
Планирование восстановления носителя
Стратегия резервирования
Восстановление носителя требуется всегда, когда теряются данные. Наиболее общие причины потери данных: сбои носителя и человеческие ошибки. Для того чтобы можно было восстанавливать носитель, сервер базы данных должен функционировать в режиме ARCHIVELOG (архивирование журнала). Его легко включить с помощью оператора ALTER DATABASE. Затем АБД должны выбрать метод резервирования. В прошлом АБД писали свои собственные скрипты для резервирования базы данных. Сейчас делать это уже нецелесообразно, так как утилита
Recovery Manager (диспетчер восстановления) лучше оснащена для управления резервированием. Утилита Recovery Manager имеет вариант с интерфейсом командной стоки, а также вариант с графическим интерфейсом, встроенным в Enterprise Manager. Утилита Recovery Manager позволяет пользователям специфицировать все их требования резервирования, например, полное оперативное резервирование базы данных на ленту, автономное резервирование всей базы данных на диск и т.п. Более того, использование средств планирования в Enterprise Manager позволяет запускать задания создания резервных копий в заданное время, как регулярно, так и по потребности. Хорошая практическая рекомендация: вместе с резервными копиями файлов данных базы данных создавать резервную копию управляющего файла. Резервную копию управляющего файла, как минимум, необходимо создавать при изменении структуры базы данных.
Для тех администраторов, которым требуются также файлы систем резервирования, корпорация Oracle инициировала, совместно с поставщиками систем управления носителями, программу решения проблем резервирования (Backup Solution Program,
http://otn.oracle.com/deploy/availability). Участники этой программы – сторонние поставщики, инструментальные средства которых обеспечивают комплексное решение вопросов резервирования как системных файлов, так и файлов базы данных Oracle. Это лучше использования для управления резервированием двух отдельных инструментов, Recovery Manager или Enterprise Manager для файлов базы данных Oracle и отдельного инструмента для системных файлов.
Как обсуждалось ранее, журнальные файлы следует мультиплексировать. Это означает, что каждая журнальная группа будет иметь два журнальных файла или элемента. Настоятельно рекомендуется, чтобы задание создания резервных копий резервировало по крайней мере два элемента каждой журнальной группы. Это подчеркивает важность журнальных файлов, поскольку если во время восстановления возникнут проблемы с архивными журнальными файлами из-за их физического повреждения или человеческой ошибки, то полное восстановление базы данных будет невозможным, и это приведет к потере некоторых данных. Вероятность такого происшествия существенно уменьшается, если есть запасная резервная копия. Заметим, АБД не должны создавать резервную копию журнального файла, а затем резервировать ее еще один раз. Вместо этого они должны резервировать два зеркальных журнальных файла по отдельности, так чтобы в случае повреждения одного из них для восстановления был доступен второй журнальный файл. Если обе копии являются копиями одного и того же архивного журнального файла, то мы не защищаем себя от повреждений журнала.
Стратегия восстановления
АБД должны моделировать сценарии потери данных и тестировать свои планы восстановления. К сожалению, большинство АБД не тестируют свои стратегии резервирования и восстановления. Проведение испытаний плана восстановления помогает проверить процессы на месте, а также держит администраторов в курсе проблем и ловушек восстановления. Четыре основные причины потери данных: сбои носителя, человеческие ошибки, повреждение блоков данных и стихийные бедствия. План восстановления необходимо разрабатывать с учетом каждого случая.
- Сбой носителя.
Обычный пример сбоя носителя – разрушение дисковых головок, которое приводит к потере всех файлов базы данных, размещенных на диске. Для полного отказа диска уязвимы все файлы, связанные с базой данных, включая файлы данных, управляющие файлы, оперативные и архивные журнальные файлы. Восстановление после сбоя носителя включает в себя копирование всех неисправных файлов из резервной копии, а затем их восстановление. В наихудшем случае может потребоваться копирование и восстановление всей базы данных. Сбой носителя – первостепенная задача стратегии резервирования и восстановления, поскольку во время восстановления обычно требуется копировать некоторые или все файлы базы данных, а затем применять для их восстановления журнальные файлы.
- Человеческая ошибка.
Пользователи могут непредумышленно удалять данные или уничтожать таблицы. Хороший способ минимизации последствий таких ситуаций – предоставлять пользователям только такие привилегии базы данных, которые им безусловно необходимы. Но человеческие ошибки будут по-прежнему возникать и АБД должны быть готовы к работе над ними. Создание логических резервных копий или экспорт таблиц – хороший способ справляться со случайными уничтожениями таблиц. Ретроспективный запрос (Flashback Query), новое средство, введенное в СУБД Oracle9i, очень хорошо подходит для восстановления после случайных удалений или вставок. Последним средством, к которому можно прибегнуть, является копирование из резервной копии и восстановление всего табличного пространства, содержащее объекты, на которые подействовала человеческая ошибка. Существуют различные методы восстановления после человеческих ошибок, и все они должны быть протестированы.
- Повреждение блоков данных.
Неисправная аппаратура или ошибка операционной системы могут быть причиной повреждения блоков данных, в результате которого их формат не будет распознаваться СУБД Oracle или их содержимое будет внутренне несогласованным. В СУБД Oracle имеется средство восстановления носителя на уровне блоков (Block Media Recovery), которое копирует и восстанавливает только поврежденные блоки, и не требует восстановления всего файла данных. Это уменьшает среднее время восстановления (MTTR, Mean Time to Recovery), так как копируются и восстанавливаются только те блоки, которые требуется восстановить, а испорченные файлы данных остаются в оперативном режиме.
- Стихийные бедствия.
Землетрясения и наводнения могут привести к полному разрушению оборудования информационного центра. В таких случаях требуется копирование из резервных копий и восстановление на альтернативных установках. Это неизбежно влечет за собой необходимость поддержки резервных копий не только на основной установке, но и на альтернативной. "Внешнее" копирование и восстановление следует тщательно тестировать и планировать по времени, чтобы бизнес мог выдержать такие стихийные бедствия без компрометирования своих соглашений об уровнях сервиса.
Тщательно тестируя и документируя свой план восстановления, АБД могут существенно ограничить неожидаемые перерывы в работе и повысить доступность систем баз данных.
Заключение
Бизнес пришел к оценке своих ИТ-инфраструктур как стратегического императива. Учитывая, что системы управления базами данных являются ядром ИТ-инфраструктуры, их надежность и доступность имеют принципиальную важность для бизнеса. В этой работе мы наметили в общих чертах некоторые ключевые практические методы в области конфигурирования систем баз данных, их производительности, управления и восстановления, которые существенно повышают надежность и доступность баз данных, а также уменьшают для бизнеса эксплуатационные и административные расходы. Даже минимальное время простоя системы базы данных становится недопустимым для увеличивающегося числа компаний, кроме того, в связи с ростом мощности систем баз данных и расширением их функциональных возможностей, нагрузка на корпоративных АБД в недавнем прошлом росла экспоненциально. Мы надеемся, что эта работа устранит часть этой нагрузки и в то же самое время повысит эффективность их систем баз данных.
Благодарности
Идеи этой работы разрабатывались с помощью многих экспертов корпорации Oracle. Их вклад очень ценен. Особые благодарности Грэму Вуду (Graham Wood), Бенуа Дажвилю (Benoit Dageville), Алексу Цукерману (Alex Tsukerman), Рону Вайссу (Ron Weiss) и Сушиле Кумар (Sushil Kumar) за их вклад и обратную связь.
Ссылки
- J. Loaiza. Optimal Storage Configuration Made Easy, http://otn.oracle.com/deploy/performance/index.htm
- S. Kumar. Server Manageability: DBA’s Mantra for a Good Night’s Sleep.
- G. Wood, C. Dialeris. Diagnosing Performance Using StatsPack, http://otn.oracle.com/deploy/performance/index.htm
- Oracle White Paper: Oracle Performance Improvement Method, http://otn.oracle.com/deploy/performance/index.htm
- T. Lahiri, et al. Fast-Start: Quick Fault Recovery in Oracle,
http://web06-02.us.oracle.com/deploy/availability/techlisting.html
- T. Bednar. Database Backup and Recovery: Strategies and Best Practices.
- Oracle9i DBAs Guide, Release 1 (9.0.1) (Прим. пер. Имеется также русский перевод: Сервер Oracle9i. Руководство администратора. Выпуск 2 (9.2). Его можно заказать в
http://www.rdtex.ru/.)
- Oracle9i Database Performance Guide and Reference, Release 1 (9.0.1)
- Oracle9i Database Concepts, Release 1 (9.0.1) (Прим. пер. Имеется также русский перевод: Сервер Oracle9i. Основные концепции. Выпуск 2 (9.2). Его можно заказать в http://www.rdtex.ru/.)
- Oracle9i Performance Methods, Release 1 (9.0.1)
- Oracle Technology Network, http://otn.oracle.com

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

