2004 г.
СЖАТИЕ ТАБЛИЦ В СУБД Oracle9i RELEASE 2: АНАЛИЗ ЭФФЕКТИВНОСТИ
Александр Соколов,
Виктор Сусойкин,
компания РДТЕХ
Источник: OracleWorld, San Francisco, California, 10-14 November 2002 (http://www.oracle.com/pls/oow/oow_user.show_public? p_event=13&p_type=session&p_session_id=38383)
Предисловие редакторов русского перевода
В данной работе анализируется эффективность механизма сжатия данных, появившегося в СУБД Oracle9i, на примере сжатия таблиц схемы типа "звезда" и нормализованной схемы эталонных тестов TPC-H и TPC-R (то есть, типичных схем в системах поддержки принятия решений). Подчеркнем, сжатие данных, в результате которого может быть достигнута значительная экономия дискового пространства и пространства кеша буферов, не является самоцелью. Современные цены за "мегабайт" дисковой или оперативной памяти делают этот вопрос неактуальным. Главное здесь - повышение общей пропускной способности и уменьшение времени реакции больших систем.
Вместе с тем, следует отметить, этот механизм может быть эффективным и в традиционных интерактивных системах с интенсивным выполнением операций чтения данных с диска. Поскольку сжатие таблиц позволяет уменьшить их размер, это приводит к пропорциональному уменьшению времени, требуемому для резервирования и восстановления базы данных. Кроме того, сжатие таблиц будет несомненно эффективным при работе с табличными пространствами только для чтения (READ ONLY). И все это достигается без каких-либо изменений в приложениях, то есть, этим может заниматься администратор базы данных без привлечения разработчиков приложений.
Данная работа была также с незначительными изменениями опубликована как технический документ (white paper) корпорации Oracle - http://otn.oracle.com / products / bi / pdf / o9ir2_compression_performance_twp.pdf. Некоторые опечатки и ошибки в переводимом документе исправлены по данной публикации. Кроме того, на основании данного документа Микел Посс в соавторстве с Германом Баером (Hermann Baer) опубликовал в Oracle Magazine статью "Decision Speed: Table Compression In Action" (скорость принятия решений: сжатие таблиц на практике) - http://otn.oracle.com / oramag / webcolumns / 2003 / techarticles / poess_tablecomp.htm.
Дополнительно об оптимизации производительности в хранилищах данных можно прочитать в техническом документе "Data Warehouse Performance Enhancements with Oracle9i", An Oracle White Paper, April 2001, http://otn.oracle.com / products / Oracle9i / pdf / o9i_dwperfcomp_dwflow.pdf.
Содержание
- Введение
- Функционирование механизма сжатия таблиц
- Конфигурация тестируемых схем (типа "звезда" и нормализованная)
- Экономия пространства в результате сжатия
- Схема типа "звезда"
- Нормализованная схема (эталонные тесты TPC-H и TPC-R)
- Примеры запросов типа "звезда"
Обсуждение производительности выполнения запросов типа "звезда"
Запросы в эталонном тесте TPC-H
- Запрос номер 1 в эталонном тесте TPC-H
Запрос номер 6 в эталонном тесте TPC-H
Запрос номер 15 в эталонном тесте TPC-H
Введение
Сжатие таблиц (Table Compression) - новое средство, введенное в СУБД Oracle 9i Release 2, может быть использовано для сжатия целых таблиц, секций таблиц и материализованных представлений. Оно радикально уменьшает потребности в дисковом пространстве и кеше буферов и, во многих случаях, повышает производительность выполнения запросов, особенно в системах с интенсивным вводом-выводом. Сжатие ориентировано на приложения поддержки принятия решений и OLAP-приложения, но и в других областях могут быть также получены большие выгоды. После объяснения работы механизма сжатия таблиц в данной работе вводятся два типа схем, обычно используемых в системах поддержки принятия решений (как в OLAP-системах, так и в хранилищах данных), а именно, схемы типа "звезда" и нормализованные схемы. С помощью этих схем в двух основных разделах данной работы анализируется, как сжатие таблиц может привести к огромной экономии пространства, и исследуется влияние сжатия таблиц на запросы.
Функционирование механизма сжатия таблиц
СУБД Oracle9i Release2 сжимает данные, устраняя дубликаты значений в блоках базы данных. В алгоритме используется метод сжатия информации без потерь на основе словаря (lossless dictionary-based compression technique) [4]. Сжатые данные, хранимые в блоках базы данных, являются самодостаточными (self-contained). То есть, вся информация, необходимая для восстановления исходных данных в блоке, находится в самом этом блоке. Алгоритм решает, исходя из длины столбца и количества экземпляров значений, будет ли для конкретного столбца создаваться вход в таблице идентификаторов (словаре). Сжимаются только целые столбцы или последовательности столбцов. Все экземпляры таких значений заменяются короткой ссылкой на таблицу идентификаторов. Для коротких значений и значений с небольшим количеством экземпляров входы в таблице идентификаторов не создаются. Чтобы добиться оптимальной производительности, столбцы в блоке могут быть переупорядочены. Тем не менее, это прозрачно для пользователей.
По сравнению с другими методами сжатия, в которых для сжатия целой таблицы используется фиксированное количество входов в таблице идентификаторов, обычно 256, реализация механизма сжатия в СУБД Oracle имеет много преимуществ. Во-первых, чтобы получить оптимальные результаты сжатия, в СУБД Oracle количество входов в таблице идентификаторов выбирается системой на уровне блоков во время загрузки данных. Во-вторых, входы в таблице идентификаторов создаются системой и для них не требуется пользовательская настройка. В-третьих, в СУБД Oracle алгоритм сжатия динамически адаптируется к изменениям распределения данных без компрометации механизма сжатия. Следовательно, для создания сжатой таблицы нужно только включить в определение таблицы ключевое слово COMPRESS.
На рис. 1 показаны различия между хранением данных в сжатом блоке по сравнению с несжатым блоком. Исключая таблицу идентификаторов в начале блока, сжатые блоки базы данных очень похожи на обычные блоки базы данных. Модификации кода, сделанные в СУБД Oracle для реализации механизма сжатия, были существенно локализованы. Были модифицированы только те части кода, которые имеют дело с форматированием блока и доступом к строкам и столбцам. В результате, сжатые блоки полностью прозрачны для пользователей базы данных и любых приложений, а все средства и функции СУБД, которые работают с обычными блоками базы данных, также работают и со сжатыми блоками базы данных.
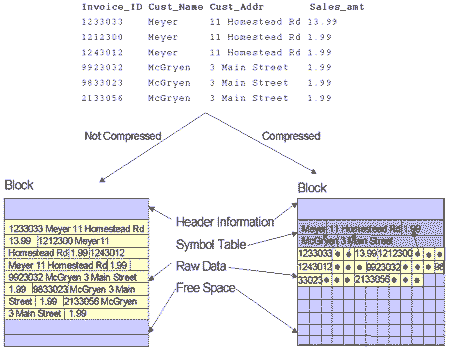
Рис. 1. Сжатый блок по сравнению с несжатым блоком
Надписи на рисунке:
· Not Compressed - несжатый;
· Compressed - сжатый;
· Block - блок;
· Header Information - информация заголовка;
· Symbol Table - таблица идентификаторов;
· Raw Data - данные строк;
· Free Space - свободное пространство.
Конфигурация тестируемых схем (типа "звезда" и нормализованная)
В моделях схем, проектируемых для хранилищ данных, существует большое разнообразие способов размещения объектов схем. Одна из моделей схем для хранилищ данных - схема типа "звезда" (star schema). Другая схема - схема в третьей нормальной форме (3NF-схема, third normal form schema). Кроме того, некоторые схемы хранилищ данных не являются ни схемами типа "звезда", ни 3NF-схемами, они имеют свойства обеих схем; такие схемы представляются гибридными моделями схем.
СУБД Oracle9i разработана для поддержки всех схем хранилищ данных наиболее эффективным способом. Некоторые средства могут быть специфическими для одной модели схем (такие, как преобразования запросов типа "звезда", специфические для схем типа "звезда"). Тем не менее, подавляющее большинство средств для хранилищ данных в СУБД Oracle в равной степени применимы для схем типа "звезда", 3NF-схем и гибридных. Основные функциональные возможности для хранилищ данных, такие, как секционирование (включая загрузку данных методом "скользящее окно" - rolling window load technique), параллелизм, материализованные представления и аналитический SQL, реализованы для всех моделей схем. (Прим. ред. С методом "скользящее окно" можно ознакомиться по [5].)
Определение, какую модель схемы следует использовать для хранилища данных, должно быть основано на требованиях и предпочтениях конкретной команды проектировщиков хранилища данных. Сравнение достоинств альтернативных моделей схем выходит за рамки данной работы. Вместо этого, в этой работе для иллюстрации сжатия для различных схем используются примеры схемы типа "звезда" и нормализованной схемы.
На рис. 2 показан пример схемы типа "звезда", подчеркивающий типичную структуру "звезда", в которой таблица фактов DAILY_ SALES (продажи) - центр "звезда", окруженный таблицами измерений: TIME (время), CUSTOMER (клиент), SALES REGION (регион продаж), ITEM (продукт) и PROMOTION (продвижение). Существует две таблицы итогов, определенные на таблице DAILY_SALES (дневные продажи): WEEKLY_SALES (продажи за неделю) и SALES_AGGR (агрегирование продаж). В таблице WEEKLY_SALES агрегируются продажи из таблицы DAILY_SALES по продуктам и клиентам за каждую неделю. Таблица SALES_AGGR строится на таблице DAILY_SALES с дальнейшим агрегированием по регионам продаж.
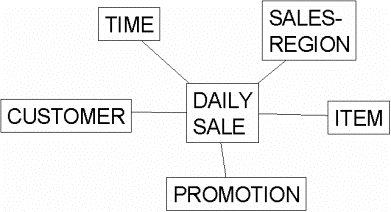
Рис. 2. Типичная схема типа "звезда"
В нашем втором примере мы показываем сжатие для различного типа нормализованных схем на примере стандартных эталонных тестов (benchmark) для оценки среды поддержки принятия решений TPC-H/TPC-R. (Прим. ред. О тестах TPC см. например, [6].) Схема этих тестов состоит из восьми базовых таблиц, моделирующих хранилище данных типичной среды розничной торговли (см. рис. 3). Таблицы, такие, как PART, SUPPLIER, PARTSUPP и CUSTOMER, содержат относительно статичную информацию о продуктах, которые типичная компания розничной торговли покупает у своих поставщиков (supplier) и продает своим клиентам (customer). Объем этих таблиц составляет примерно 15% от общего объема базы данных. Объем двух самых больших таблиц, LINEITEM и ORDERS, составляет примерно 85% от общего объема базы данных. Они содержат данные об отдельных сделках. В отличие от предыдущего примера эта схема не организована как схема типа "звезда", в ней используется нормализованный [3] подход.
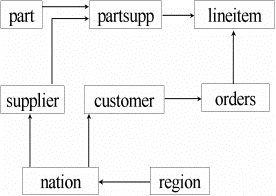
Рис. 3. Нормализованные схемы эталонных тестов TPC-H и TPC-R
Экономия пространства в результате сжатия
Сжатие таблиц может привести к существенному уменьшению потребности в дисковом пространстве и кеше буферов для таблиц базы данных. Для сжатия данных на уровне блоков алгоритм сжатия использует избыточность данных, поэтому, чем выше избыточность данных в одном блоке, тем больше будут выгоды от сжатия. Хотя может быть и избыточность данных в совокупности блоков, такие данные не могут быть использованы для их дальнейшего сжатия.
Если таблица определена как "сжатая" (compressed), она будет использовать меньше блоков данных на диске, уменьшая, следовательно, потребности в дисковом пространстве. Данные из сжатой таблицы читаются в сжатом формате, и они восстанавливаются только во время доступа к ним. Поскольку данные кешируются в своем сжатом формате, то существенно больше данных может быть размещено в одном и том же объеме кеша буферов (см. рис. 4).
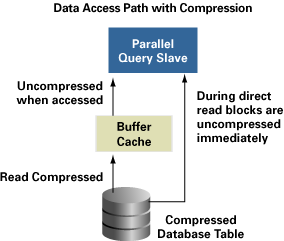
Рис. 4. Пути доступа к сжатым данным
Надписи на рисунке:
· Data Access Path with Compression - пути доступа к сжатым данным;
· Parallel Query Slave - подчиненный процесс параллельного запроса;
· Uncompressed when accessed - восстановление сжатых данных при доступе к ним;
· During direct read blocks are uncompressed immediately - во время прямого чтения блоки восстанавливаются немедленно;
· Buffer Cache - кеш буферов;
· Read compressed - чтение в сжатом формате;
· Compressed Database Table - сжатая таблица базы данных.
Перед измерением экономии пространства в результате сжатия двух наших демонстрационных схем мы определим коэффициент сжатия и экономию пространства. Коэффициент сжатия (КС) таблицы определяется как отношение количества блоков, требуемых для хранения несжатого объекта, к количеству блоков, требуемых для сжатого варианта:
КС = #несжатых_блоков/#сжатых_блоков
Следовательно, экономия пространства (ЭП) определяется следующим образом:
ЭП = ((#несжатых_блоков-#сжатых_блоков)/#несжатых_блоков)х100
Коэффициент сжатия главным образом зависит от содержимого данных на уровне блоков. Неповторяемые поля (поля с высокой кардинальностью), такие, как первичные ключи, не могут быть сжатыми, тогда как поля с очень низкой кардинальностью могут сжиматься очень хорошо. С другой стороны, более длинные поля позволяют получить больший коэффициент сжатия, поскольку экономия пространства будет большей, чем для более коротких полей. Кроме того, если в последовательности столбцов содержится одно и то же содержимое, алгоритм сжатия объединяет эти столбцы в элементе многостолбцового сжатия, что дает еще более лучшие результаты сжатия.
Таблица идентификаторов, в которой содержатся значения полей с множественными экземплярами, автоматически генерируется СУБД Oracle для каждого блока. В большинстве случаев большие размеры блоков позволяют увеличить коэффициент сжатия таблиц базы данных, поскольку с одной таблицей идентификаторов может быть связано большее количество значений столбцов.
Сортировка данных перед их загрузкой может дополнительно увеличить коэффициент сжатия. Чем больше полей с одинаковым содержимым сосредотачивается в каждом блоке, тем более эффективно работает алгоритм сжатия. Если вы знаете, что одно или несколько полей объекта базы данных имеют одинаковые значения - на это указывает небольшое количество уникальных значений сортировка данных по этим полям, вероятно, приведет к увеличению коэффициента сжатия. Тем не менее, сортировка по полям с очень низкой кардинальностью не обязательно приведет к большому увеличению коэффициента сжатия. В результате низкой кардинальности этого поля строки с одинаковыми значениями уже могут иметь высокую концентрацию в каждом блоке. Следовательно, лучшие результаты могут быть достигнуты сортировкой по полям, которые как длинные, так и имеют среднюю кардинальность.
Схема типа "звезда"
Таблицы фактов и таблицы итогов обычно являются самыми большими таблицами в схеме типа "звезда", занимая 70% или даже больше общего пространства базы данных. Напротив, таблицы измерений имеют очень маленький размер. Следовательно, сжатие таблиц измерений не приводит к большой общей экономии дискового пространства и его нужно рассматривать только при работе с очень большими измерениями. Поэтому мы для нашей конфигурации тестовых схем сжимаем только таблицы фактов и материализованные представления.
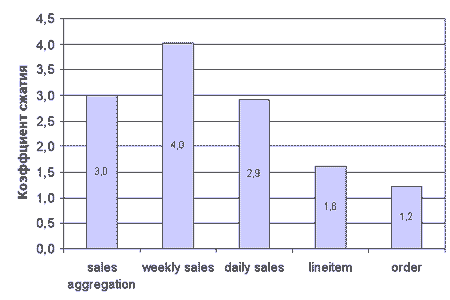
Рис. 5. Коэффициенты сжатия для схемы типа "звезда" и нормализованной схемы
Рис. 5 иллюстрирует, как хорошо сжимаются данные схемы типа "звезда" и нормализованной схемы. Коэффициенты сжатия для таблицы фактов DAILY SALES и таблицы итогов WEEKLY SALES в схеме типа "звезда" варьируются от 2.9 до 4.0, что приводит к экономии пространства от 67 до 75 процентов. То есть, для сжатого варианта таблицы WEEKLY SALES требуется только 25% дискового пространства и пространства кеша буферов по сравнению с ее несжатым аналогом, тогда как для сжатых вариантов таблиц DAILY SALES и SALES AGGREGATION требуется только 33% ресурсов по сравнению с их несжатыми аналогами. Общая экономия пространства базы данных при сжатии только таблиц фактов, достигнутая на схеме заказчика типа "звезда" приблизительно составляет 67% с коэффициентом сжатия, равным примерно 3.1.
Нормализованная схема (эталонные тесты TPC-H и TPC-R)
В нормализованных схемах для эталонных тестов TPC-H и TPC-R доминируют две таблицы: LINEITEM и ORDERS. Эти таблицы, в которых хранится информация о заказах, похожи на таблицы фактов в схеме типа "звезда", и они содержат приблизительно 75% всех данных. Сжатие таблицы LINEITEM - наибольшее, с коэффициентом сжатия, равным примерно 1.6, тогда как таблица ORDERS сжимается с коэффициентом сжатия, равным примерно 1.2 (см. рис. 5). Это означает, что для сжатых вариантов таблиц LINEITEM и ORDERS требуется приблизительно 60 и 80 процентов от объема несжатых таблиц. Общий коэффициент сжатия для базы данных эталонного теста TPC-H равен примерно1.4, что приводит к экономии пространства, приблизительно равной 29%.
Почему схема типа "звезда" сжимается лучше нормализованной схемы эталонного теста TPC-H
В двух предыдущих разделах мы рассмотрели коэффициенты сжатия и экономию пространства, которые могут быть получены в реальных схемах: схеме типа "звезда" и нормализованной схеме эталонного теста TPC-H. При сжатии всех таблиц фактов и таблиц итогов коэффициент сжатия для схемы типа "звезда" оказался приблизительно равным 3.1, что позволило сэкономить примерно 67% пространства. То есть, пространство, занимаемое базой данных на диске, сократилось в результате сжатия более чем на половину. С другой стороны, для нормализованной схемы, в которой сжимались две самые большие таблицы, эквивалентные таблицам фактов в хранилище данных, коэффициент сжатия оказался приблизительно равным только 1.4, а экономия пространства - 29%.
Коэффициент сжатия таблиц зависит от избыточности данных в этих таблицах. Данные сжимаются за счет устранения дубликатов значений в каждом блоке базы данных. Более высокая избыточность данных обычно позволяет получить более высокий коэффициент сжатия. Для таблицы, в которой содержится большое количество столбцов с небольшим количеством различающихся значений (на это указывает представление словаря данных DBA_TAB_COL_STATISTICS), автоматически не следует получение высокого коэффициента сжатия. Это скорее зависит от распределения данных и средней длины каждого конкретного столбца. Очевидно, распределение данных определяет количество потенциальных различающихся значений, а средняя длина столбца - количество записей, хранимых в одном блоке.
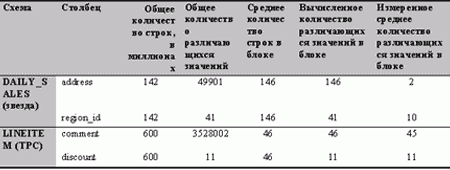
Рис. 6. Сжатие таблиц схемы типа "звезда" и схемы тестов TPC-H/R
Внимательное рассмотрение количества различающихся значений в двух столбцах (ADDRESS, REGION_ID) таблицы DAILY_SALES схемы типа "звезда" и в двух столбцах (COMMENT, DISCOUNT) таблицы LINEITEM схемы тестов TPC-H/R, объясняет, почему данные нашего примера схемы типа "звезда" сжимаются лучше данных базы данных тестов TPC-H/R. Для каждого столбца на рис. 6 показано общее количество строк в таблице, общее количество различающихся значений, среднее количество строк в блоке (берется из представления словаря данных DBA_TAB_COL_STATISTICS), вычисленное количество различающихся значений в блоке и измеренное среднее количество различающихся значений в блоке (была исследована репрезентативная выборка из блоков). При вычислении количества различающихся значений в блоке мы предполагаем равномерное распределение строк. То есть, вычисленное количество различающихся значений в блоке равно среднему количеству строк в блоке, если общее количество различающихся значений больше количества строк в блоке, в противном случае, оно равно общему количеству различающихся значений. Рассмотрим следующую равномерно распределенную последовательность номеров {1,2,…5}, которая представляет собой строки, состоящие из одного столбца, значением которого является номер:
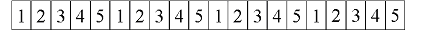
Предположим далее, что среднее количество строк в блоке (Block) равно 4. Тогда отображение строк на блоки будет выглядеть следующим образом:

Как видно, в каждом блоке содержится 4 различающихся значения. Впрочем, данная последовательность была выбрана для демонстрации равномерного распределения данных, она не является общим случаем. Читатель может проверить, что разные последовательности могут приводить к уменьшению количества различающихся значений в блоке.
Для столбцов схемы типа "звезда" измеренное среднее количество различающихся значений существенно меньше вычисленного количества различающихся значений. Это указывает на то, что данные являются не равномерно распределенными, а кластеризованными. Это очень распространенное явление для таблиц фактов и таблиц итогов в хранилищах данных; почти в каждой среде хранилища данных при периодическом обновлении данных происходит какое-то группирование или сортировка новых данных. Например, ETL-процесс (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных.), собирающий новую информацию для таблицы фактов из различных источников, должен перед вставкой данных в таблицу фактов сравнивать и агрегировать их, то есть, сортировать данные. Аналогичная кластеризация данных происходит, естественно, и в таблицах итогов, которая выполняется с помощью группирования данных или специализированных OLAP-операций, таких, как операции суперагрегатного группирования rollup и cube.
С другой стороны, в схемах эталонных тестов TPC-H и TPC-R действительное количество различающихся значений в блоке совпадает с вычисленным количеством различающихся значений в блоке, что указывает на строгое равномерное распределение данных. В действительности, генератор данных эталонных тестов TPC-H и TPC-R критиковался за генерацию нормально распределенных данных.
Если данные не кластеризуются, как в случае тестов TPC-H и TPC-R, сортировка данных перед их загрузкой может существенно увеличить сжатие. Выбор столбцов для включения в сортировку зависит от их кардинальности и средней длины. В общем, длинные столбцы обеспечивают большее сжатие по сравнению с короткими столбцами. Что касается кардинальности, то оказалось, что сортировка по столбцам с очень низкой кардинальностью, таким, как GENDER (пол) или MARITAL STATUS (семейное положение), менее эффективна по сравнении с сортировкой по столбцам со средней кардинальностью. Оптимальными столбцами для сортировки представляются те, у которых кардинальность на уровне таблицы равна количеству строк в блоке. Сортировка по столбцам, кардинальность которых меньше количества строк в блоке, менее эффективна, поскольку значения столбца уже имеют большую избыточность. Сортировка по столбцам с каким-либо столбцом с более высокой кардинальностью также приводит к более высокому уровню увеличения сжатия.