ORACLE и коммерческая GRID
Mарк Ривкин, http://mrivkin.narod.ru/Эта статья о подходе компании Oracle к концепции GRID состоит из 2х частей. В первой части мы рассмотрим, что такое GRID, для чего она нужна и какие дает преимущества, почему именно сейчас пришло время GRID. Эта часть более описательная, менее техническая. А во второй части мы рассмотрим, какие механизмы предлагает Oracle для разработки и эксплуатации приложений в среде GRID, почему новая версия Oracle называется Oracle 10G (где G означает GRID), а также обсудим, чем идеальная концепция GRID отличается от реальности, от того, что можно использовать сегодня.
Термин GRID (переводится как решетка или как вычислительная сеть) только недавно начал входить в лексикон специалистов по информационным технологиям. Однако аналитики уже сейчас прогнозируют, что идея GRID может радикально изменить мир информационных технологий, точно также, как когда-то это сделал интернет. Еще несколько лет назад только специалисты говорили об интернет и Web, а сегодня дети и неподготовленные пользователи “лазают” в интернет, совершают покупки и платежи через интернет, узнают погоду, новости и курсы валют через интернет и т. д.
Сегодня, когда компания Oracle выпускает СУБД Oracle 10G, которая позволяет создавать и выполнять приложения в среде GRID, а основные производители компьютеров выпускают программное обеспечение и оборудование, позволяющее объединить компьютеры в GRID, мы можем говорить о наступлении эпохи GRID. А поскольку идея GRID прозрачна и всем понятна, а также позволяет экономить средства и более эффективно использовать имеющиеся вычислительные мощности, то понятно, что наступление эпохи GRID остановить нельзя.
1. В чем же заключается идея или концепция GRID?
Термин GRID вычисления (Computing grid) появился по аналогии с термином Power grid (единая энергосистема). Т. е. его можно перевести как единая компьютерная система. Идея очень проста, понятна и давно описана писателями-фантастами. В мире существует множество компьютеров. Давайте объединим их в один большой суперкомпьютер невиданной мощности. Это даст нам огромное количество преимуществ. Сегодня одни компьютеры работают в половину своей мощности, в то время как другие компьютеры перегружены. В то время как в одних странах ночь и компьютеры простаивают, в других странах не хватает вычислительных ресурсов для решения важных и сложных задач. Для некоторых задач (таких как задачи предсказания погоды, моделирование физических процессов, астрофизика и т. д.) необходимы очень мощные компьютеры, которых пока еще не создали. Создание же суперкомпьютера, элементами которого являются обычные компьютеры, принадлежащие различным странам, организациям, людям, позволило бы решить эти проблемы.
Сегодняшняя реальность любой организации такова, что под любое новое коммерческое приложение покупается новый компьютер (компьютеры) и мы имеем множество слабо связанных вычислительных “островков”. Связывание их в единый “континент” даже в рамках одной организации позволило бы резко повысить эффективность использования оборудования и уменьшить количество компьютеров в организации. Имея такой суперкомпьютер неограниченной мощности, любой пользователь может в любое время и в любом месте попросить столько вычислительных ресурсов, сколько ему требуется (и сколько он может оплатить), решить свои задачи и освободить ресурс.
Очень часто в связи с концепцией GRID упоминают термин “computing utility” т е. коммунальная услуга, поскольку GRID позволяет получить вычислительные ресурсы также, как мы получаем другие коммунальные услуги, такие как электричество, газ вода и т д. Когда нам нужно электричество, мы просто находим розетку, включаем прибор и затем оплачиваем по счетчику потребленную электроэнергию. При этом мы не задумываемся о том, на каких ГЭС, ГРЭС, АЭС и т д. электроэнергия была выработана, по каким линиям ЛЭП шла и т д. Концепция GRID позволяет точно также получать и использовать вычислительные ресурсы.
Часто в связи с концепцией GRID также используют термин “виртуализация”. Действительно, в GRID мы работаем не с множеством мелких компьютеров, а с одним виртуальным суперкомпьютером, не с множеством дисков, на которых лежат наши файлы и базы данных, а с единой виртуальной областью хранения данных (огромным виртуальным диском), которая образуется из множества отдельных дисков.
Итак, с точки зрения пользователя GRID не важно, где размещаются данные и какой компьютер будет обрабатывать его запросы. Главное – это то, что пользователь потребовал информацию или выполнение вычислений и получил результат.
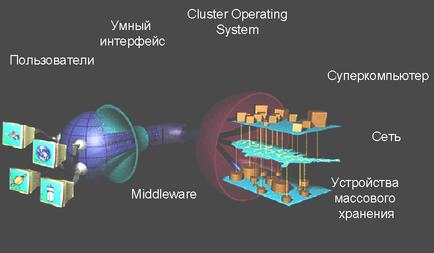
Рис. 1. GRID
Концепцию GRID описали в своих статьях “Анатомия GRID” и “Физиология GRID” [1, 2] американские ученые Фостер, Кессельман, Ник и Тукке. Они так определили термин Computing Grid в 1998 г.: “Вычислительная Grid – это программно-аппаратная инфраструктура, которая обеспечивает из любого места в мире надежный, согласованный и недорогой доступ к высокоэффективным вычислительным ресурсам”. Отметим слово “недорогой” в этом определении, поскольку появившаяся сегодня возможность использовать в качестве элементов GRID недорогие вычислительные элементы с недорогой операционной системой дала толчок развитию коммерческого использования GRID вычислений.
В 2000 г Фостер и Тукке определили GRID как “Скоординированное разделение ресурсов и решение проблем в динамической, многокомпонентной виртуальной организации ”, где виртуальная организация – это группа предприятий, объединяющих свои вычислительные ресурсы в единую GRID и совместно их использующая.
Однако еще задолго до появления первых работ по GRID один из основоположников интернет Лен Клейнрок (Len Kleinrock) предсказывал в 1969 г. “Мы, возможно, станем свидетелями распространения ‘computer utilities’ (вычислительных коммунальных услуг), которые, также как сегодня телефонные услуги будут доступны во всех домах и офисах по всей стране”. Прошло чуть меньше 30 лет и это предсказание начинает сбываться.
Мы не случайно приводим здесь классические определения концепции GRID. Конечно все вышеописанное – это идеальная картина. Надо различать идеальное понимание термина GRID и его реальную реализацию. Так сегодня невозможно еще создать единый мировой суперкомпьютер, но начать реализовывать эту концепцию в рамках организации уже возможно. Далее мы посмотрим, что из этих идеальных понятий реализуемо уже сегодня, а что может быть реализовано только в далеком будущем.
Если со стороны пользователя GRID все просто (попросил ресурс – получил его), то со стороны организаций, предоставляющих этот единый вычислительный ресурс, необходимо обеспечить ряд требований.
Необходимо обеспечить, что требования на выделение вычислительных ресурсов всегда удовлетворяются, а ресурсы полностью используются, т. е. не должно возникать ситуации, когда пользователь будет ждать выделения ресурса. Еще более сложная задача – это сделать информацию, необходимую для выполнения вычислений, доступной в то время, когда она необходима, и в том месте, где она необходима. Так если речь идет о быстрой переброске огромных баз данных в ту часть света, где есть свободные вычислительные мощности, то сегодня эта задача невыполнима. Скорость и пропускная способность сегодняшних сетей передачи данных этого не позволяет. Но в рамках предприятия и ограниченного числа файлов и баз данных решить эту задачу можно.
Необходимо также обеспечить постоянную доступность и работоспособность системы GRID. Выход из строя отдельных ее элементов не должен останавливать работу приложений. Некоторые решения в этой области, такие как серверный кластер - Real Application Cluster, кластеры серверов приложений, резервные базы данных и т. д. уже сегодня позволяют обеспечить высокую надежность [6].
Основная идея GRID – обеспечить эффективное использование составляющих ее ресурсов. Для этого оборудование и программное обеспечение GRID должно определять загруженность отдельных элементов GRID и балансировать нагрузки, направляя пользователей и приложения на менее загруженные узлы, подключая новые узлы и т. д.
Элементы GRID должны быть дешевыми и простыми, только это позволит оценить экономическую выгоду от внедрения GRID.
Как уже упоминалось выше, создать сегодня мировую коммерческую GRID мы еще не можем. Поэтому выделим три этапа построения GRID.
Самый простой этап – это GRID одного центра обработки данных (ЦОД). ЦОД предприятия уже сегодня может начать объединять свои компьютеры в единую GRID для того, чтобы потом предоставлять интегрированную коммунальную услугу внутри предприятия.
Следующим шагом будет объединение различных ЦОД предприятия в единую GRID уровня предприятия. А вот третьим этапом, который наступит не ранее чем через 10 лет, будет объединение GRID предприятий в единую GRID города, страны и т д. Здесь придется решать огромное количество организационных, правовых, финансовых вопросов. Например, вопросы защиты информации и взаиморасчетов между предприятиями могут сильно тормозить эту работу.
2. Почему сейчас?
Почему же только сейчас IT компании начали активно говорить о GRID? Почему только сейчас компания Oracle выпускает первую в мире платформу для коммерческих GRID вычислений - Oracle 10G? Дело в том, что и общество и уровень развития техники и технологии только сейчас созрели для реализации и восприятия концепции GRID.
Во-первых, для того, чтобы связать множество компьютеров в единую GRID нужны хорошие сети передачи данных. Американский ученый Джон Гилдер писал “Когда сеть работает также быстро, как внутренние шины компьютера, машина расщепляется по сети на набор специализированных устройств”. Конечно, пропускная способность и скорость сетей еще недостаточны, но они очень быстро развиваются. Если число транзисторов компьютерного чипа удваивается каждые 18 месяцев, то скорость сети передачи данных удваивается всего за 9 месяцев. На рисунке 2, взятом из журнала Scientific American (январь 2001 г) видно, что скорость передачи данных по сетям растет экспоненциально.
Во-вторых, в мире появляется все более сложные задачи и накапливаются все большие объемы данных. И для решения этих суперзадач и обработки этих огромных массивов данных уже не годятся обычные компьютеры. Нужны суперкомпьютеры с очень высокой мощностью и таких компьютеров требуется все больше. Стоимость этих суперкомпьютеров очень высока, но их мощности очень быстро перестает хватать. В последнее время бурно развиваются такие области, как анализ данных, хранилища данных, извлечение знаний (DataMining). Уже не редкость базы данных размером в несколько терабайт. Даже в Москве мы знаем несколько организаций, имеющих терабайтные базы данных. И объем этих баз быстро растет. Сегодня СУБД Oracle 9i позволяет создавать базы размером 512 петабайт. Oracle 10G будет поддерживать базы данных размером в 8 экзобайт. По прогнозам аналитиков к 2015 г базы размером более 1000 петабайт станут обычным решением и будут содержать тексты, графику, видео, файлы и т д.
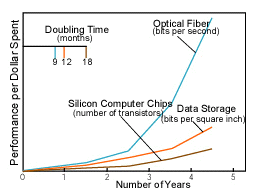
Рис. 2. Скорость улучшения характеристик различных элементов
(синий – сеть, красный – устройства
хранения инф, коричневый – компьютерные чипы)
Третьей, очень важной причиной бурного развития концепции GRID сегодня является то, что она позволяет получить результат быстрее и дешевле. Действительно, запросив больший чем раньше вычислительный ресурс, мы можем реализовать более сложные и точные алгоритмы расчета и получать более точные результаты гораздо быстрее. Более эффективное использование оборудования и исключение простаивающего оборудования снизят стоимость эксплуатации и количество закупаемого и поддерживаемого оборудования.
GRID дает возможность объединить вычислительные ресурсы в единое множество и управлять этим множеством как единой системой, что снижает затраты на администрирование. Поскольку невозможно администрировать программное обеспечение на сотнях и тысячах компьютеров одновременно, компания Oracle в своем продукте Oracle 10G реализовала целую инфраструктуру самонастройки, самотестирования, самоконфигурации. Т. е необходимость сложного администрирования отдельных узлов отпадает и это тоже снижает затраты на администрирование. Управление всей GRID системой возможно с единого пульта.
Еще одним важным преимуществом GRID является то, что в качестве ее элементов можно использовать дешевые компьютеры и операционные системы. Так Oracle строит свои GRID для разработки на основе очень дешевых блэйд (Blade - лезвие) компьютеров с ОС Linux. Каждый такой блэйд-компьютер – это практически одна упрощенная плата. Она не содержит избыточных элементов (таких как графические адаптеры, звуковые адаптеры и т д). Однако из этих плат-компьютеров можно собирать блэйд-фермы – т е целые шкафы, состоящие из множества таких плат-компьютеров. Причем добавление таких новых компьютеров не намного сложнее, чем добавление книжек в книжную полку.
Четвертой причиной наступления GRID эпохи являются экономические реалии. Кризисы и замедление развития экономики заставляют компании более тщательно считать деньги и сокращать расходы и персонал. В первую очередь часто сокращаются расходы на IT. Поэтому GRID технологии, позволяющие экономить деньги на эксплуатации систем, сейчас очень популярны среди тех, кто умеет считать свои деньги.
Пятой причиной является то, что растет количество людей, знакомых с терминами GRID, виртуализация, вычисления как коммунальная услуга и т д. Увеличилось число публикаций, концепция достаточно понятна и уже сами заказчики и отделы IT требуют внедрения GRID технологий.
В качестве шестой причины можно отметить то, что уже разработаны стандарты GRID. Многие крупные фирмы – производители компьютеров и программного обеспечения участвуют в Global Grid Forum – некоммерческой организации, разрабатывающей стандарты построения GRID. Причем разрабатываются не только стандарты, но и инструментарий для реализации этих стандартов. Так сейчас приобрел большую популярность пакет Globus Toolkit и идет разработка новой версии GRID-архитектуры – OGSA (Open Grid Service Architecture).
В качестве седьмой причины следует отметить появление опыта реализации концепции GRID и реальных проектов, построенных на основе этой концепции. Первыми были такие проекты научной GRID, как SETI (поиск следов внеземных цивилизаций), проект поиска простых чисел, проект CERN (обработка результатов физических исследований). Сейчас реализуется множество новых GRID-проектов, например: TeraGrid, NASA Information Power Grid, US Grids center, Grid Electronic Art и т д.
И наконец последняя, но пожалуй наиболее важная причина бурного развития GRID сегодня – это то, что основные производители компьютеров и программного обеспечения начали промышленную реализацию и продажу продуктов, позволяющих строить GRID. Мы уже упоминали про блэйд-компьютеры, их выпускают различные производители. Компания HP начала продажу продукта HP Utility Data Center, который позволяет объединять в GRID компьютеры фирмы HP и управлять ими из единого центра [3]. Похожие решения есть и у компании SUN, это Sun One Grid Engine [4]. Очень много в области GRID делает компания IBM. Она даже создала в Монпелье (Франция) центр компетенции по решениям GRID.
Таким образом видно, что разработчикам и пользователям GRID-приложений не хватало только программного обеспечения, которое позволило бы обычным коммерческим информационно-управляющим приложениям работать в среде GRID. И теперь такое программное обеспечение появилось. Компания Oracle создала Oracle 10G (буква G как раз и означает GRID), который является платформой для реализации приложений в среде GRID. Причем Oracle 10G позволяет не только создавать новые приложения для GRID, но и перенести в среду GRID старые приложения, работающие на Oracle.
Если у Вас есть GRID на которой работают несколько приложений и каждое приложение использует свой набор компьютеров (например, несколько компьютеров – узлы кластера сервера БД, несколько компьютеров – узлы кластера сервера приложений, часть компьютеров используется как Web-кэши и т д), то Вы легко с единого пульта можете добавлять или удалять компьютеры в/из пула серверов, переместить часть компьютеров серверов приложений в пул серверов или кэши и т д. Т е Вы можете увеличивать мощность тех пулов, у которых сейчас нагрузка максимальна.
Некоторые производители блэйд-компьютеров, например, позволяют при перемещении компьютера в новый пул автоматически менять его программную среду и конфигурацию программного обеспечения, т е при перемещении в серверный пул на блэйде запустится еще один узел кластера Oracle, который подключится на лету к работающим узлам и разгрузит их.
Кстати, кластеры на основе блэйд-серверов и ОС Linux являются сегодня наиболее эффективными по критерию цена/производительность. Oracle 10G поддерживает быстрый обмен данными между серверами и между сервером и областью хранения данных используя технологию InfiniBand.
Что касается ОС, то Oracle отлично работает на Linux и компания Oracle совместно с компанией Red Hat модифицировала OC Red Hat Advanced Server так, что надежность и производительность этой связки сильно возросла.
Многие аналитики рассматривают сегодня концепцию GRID, как второй этап развития концепции интернет. Если первый этап – Web – был связан с презентационным слоем, т е позволял из любой части света обращаться к ресурсу и получать стандартные HTML представления страницы, то GRID связан с вычислительным слоем, поскольку позволит использовать любой вычислительный ресурс, включенный в GRID.
Выпускаемая компанией Oracle платформа для поддержки коммерческих GRID-приложений – Oracle 10G – использует как прежние преимущества Oracle – кластерные архитектуры, высокая надежность, масштабируемость, защита данных, хорошая работа в среде Linux, мощные средства разделения информации, такие как Oracle Streams [5], Distributed Database, Transported Tablespace [6], так и новые возможности. Среди них следует выделить такие важные для GRID вещи, как самоуправляемость и самонастройка, автоматическое управление виртуальной областью хранения данных (Automatic Storage Management), балансировка загрузки узлов кластера и выделение групп узлов под конкретные приложения, работа с внешними файлами ОС и таблицами БД в едином режиме, клонирование БД, управление патчами и конфигурациями и т д.
Кстати, для тех, кто разрабатывает приложения в среде Globus, пакет Oracle Globus Toolkit позволит использовать СУБД Oracle как ресурс в среде Globus. Компонента Globus Resource Information Service (GRIS) видит и контролирует ресурсы Oracle, а команды Globus позволяют выполнять PL/SQL-процедуры, специфицированные в Globus Resource Specification Language и использовать систему выполнения заданий и расписания (Oracle Scheduling).
3. Типы GRID-проектов
Сегодня можно выделить три типа GRID-проектов:
- GRID на основе использования добровольно предоставляемого свободного ресурса персональных компьютеров (Desktop GRID);
- Научная GRID;
- GRID на основе выделения вычислительных ресурсов по требованию (Enterprise GRID);
Вначале появились проекты первого типа. Наиболее известными из них были проект SETI (поиск следов внеземных цивилизаций) и проект поиска новых простых чисел.
Для решения этих задач нужно было обеспечить огромный вычислительный ресурс и обработать большой объем слабо связанных данных. Проекты осуществлялись на добровольной основе. Все люди, желавшие участвовать в проекте, выкачивали на свой персональный компьютер небольшую программку и порцию данных. Далее эта программка работала в фоновом режиме на этом персональном компьютере, когда он простаивал (примерно так, как работает программа заставки на ПК) и обрабатывала эту порцию данных. Результат возвращался в единый центр. Такой подход позволил объединить для решения этих задач огромное число персональных компьютеров, обработать большой объем данных. Проект “Простые числа” позволил найти несколько новых простых чисел.
Недостатками проектов такого типа является то, что они не гарантируют достоверность и сроки получения результатов от личных персональных компьютеров, и то, что они пригодны только для решения очень специфических задач (большой объем независимых вычислений на слабо связанном массиве данных).
В последнее время появилось большое число реализаций проектов второго типа – научная GRID. Наиболее ярким примером такой GRID является проект, реализованный в европейском ядерном центре CERN. Там накопился огромный объем данных по результатам физических исследований и для его обработки также нужны были огромные вычислительные мощности, которых у CERN не было.
Были написаны специальные программы, которые устанавливались на многих серверах по всему миру. Эти программы могли работать с единой БД CERN. Поскольку данные в этой БД тоже были слабо связаны (разбиты на множество небольших по объему слабо связанных между собой групп), то каждый такой сервер выкачивал свою порцию данных, перерабатывал ее и возвращал в единую БД результат переработки.
Существует множество таких научных GRID-проектов. Многие из них были реализованы на базе СУБД Oracle. Далеко не полный перечень этих проектов можно видеть на рисунке 3.
-
•CERN
•UKHEC Grid Testbeds
•Electronic Arts
•Netherlands Data Grid Initiative NASA
•The Hartford
•NPACI: Metasystems
•UK eScience
•Asia Pacific Bioinformatics Network
•San Diego Super Computing Lab
•The Distributed ASCI Supercomputer (DAS)
•Argonne National Lab
•G-WAAT
•Bio-GRID - часть EUROGRID
•Micro Grid
•North Carolina Bio-Grid
•Alliance Grid Technologies
•TeraGrid
•The Alliance Virtual Machine Room
•World Wide Grid (WWG)
•EuroGrid
•US ATLAS Grid
•Internet Movie Project
•DAME
•Nordic Grid
•MyGrid
Information Power Grid (IPG)
•AstroGrid
. . . .
Рис. 3.GRID-проекты на базе СУБД Oracle
Общим недостатком GRID-проектов первого и второго типов было то, что они не были предназначены для реализации стандартных информационно-управляющих систем предприятия (кадры, зарплата, управление производством, CRM и т д), требовали создания специализированного системного программного обеспечения для решения каждой новой задачи, были пригодны только для обработки специфических данных (массивы слабо связанных данных). Поэтому эти подходы не годились для создания GRID предприятия.
Третий тип GRID-проектов называют Enterprise GRID (GRID предприятия, коммерческая GRID). Он несколько сужает идеальную концепцию GRID, однако позволяет реализовать стандартные информационно-управляющие системы предприятия в GRID среде уже сегодня. Этот подход позволяет динамически выделять/забирать вычислительные ресурсы для решения задач предприятия, минимизировать перемещение данных между узлами, упростить администрирование систем. Примером платформы для реализации коммерческой GRID является Oracle 10G.
4. Механизмы Oracle 10G для реализации коммерческой GRID
Все механизмы Oracle 10G для реализации коммерческой GRID мы разобъем на следующие группы (рис. 4):
Storage GRID – GRID хранения данных;
Database GRID – GRID серверов БД;
Application GRID – GRID серверов приложений;
Средства самонастройки узлов БД;
GRID Control – система управления GRID;
Средства для разделения информации между узлами GRID.
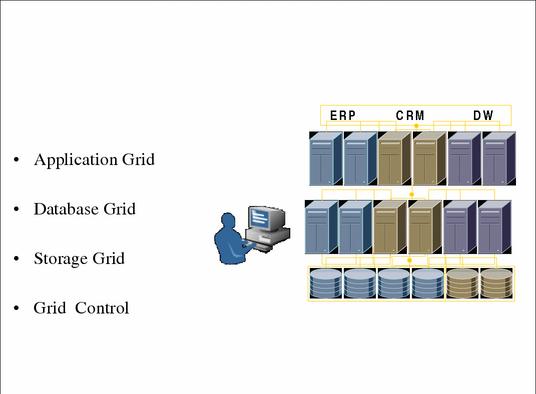
Рис 4. Архитектура Oracle GRID
Управление хранением данных в GRID
Oracle 10G позволяет реализовать новый подход к управлению хранением данных. Функция ASM (Automatic Storage Manager) позволяет виртуализировать наборы дисков в единый виртуальный диск, возложить на Oracle функции менеджера файлов и томов. Теперь администратор должен только выполнить команду создания группы дисков (это и есть виртуальный диск) и добавлять вновь подключаемые к системе диски в группу (это тоже одна команда). Oracle сам работает с этой группой дисков (виртуальным диском), размещая на нем свои файлы и управляя ими. Также легко одной командой можно удалять диск из группы.
На самом деле Oracle разбивает все пространство этого виртуального диска на равные кусочки размером в 1 Мб и создает из этих кусочков виртуальные файлы БД, табличные пространства, тома и т д. Администратор БД еще может видеть такие знакомые ему элементы, как диски, файлы, хотя на самом деле это только логическое представление этих объектов. Oracle не только создает файлы БД на этом виртуальном диске. Он также обеспечивает на нем зеркалирование (mirroring) и расщепление (striping) данных. Это делается автоматически, без вмешательства администратора БД и позволяет, в случае сбоев блоков на диске, быстро автоматически восстанавливать испорченные блоки данных.
Еще одна важная оссобенность ASM, это то, что он автоматически балансирует загрузку дисков. Во время работы ASM измеряет нагрузку по вводу/выводу на различные физические диски и автоматически перемещает наиболее интенсивно используемые данные на наименее загруженные части виртуального диска. Т е работа по настройке ввода/вывода, требовавшая ранее больших усилий от администратора БД, теперь выполняется автоматически.
Если администратор БД решил увеличить размер дискового пространства для БД Oracle, он может просто подключить новый диск к системе и выполнить команду добавления этого диска в группу. После этого Oracle сам переместит часть данных на вновь появившееся пространство, чтобы сбалансировать нагрузку. Если администратор хочет отключить диск от системы, он выполняет соответствующую команду и Oracle перемещает все данные с этого диска на другие диски группы, после чего диск может быть отключен.
ASM частично подменяет файловую систему и кардинально снижает сложность управления хранением данных. Трудоемкость таких операций, как инсталляция БД, добавление/удаление дисков для хранения БД, перемещение данных, восстановление данных уменьшилась в несколько раз. А такие операции, как настройка ввода/вывода и управление пространством на дисках теперь выполняются автоматически.
Кроме того, в Oracle 10G реализована функция Flash Backup, которая позволяет на дешевых дисках (например, ATA) хранить копию эксплуатационной БД и автоматически обновлять ее (быстрый инкриментальный Backup) (например, это можно делать ночью). Это позволяет иметь под рукой на устройствах быстрого доступа версию БД, мало отстающую от эксплуатационной БД. В случае сбоя основной БД, восстановление на основе Flash Backup будет выполнено очень быстро и не потребует работы с лентами. Кстати, создание ленточных копий БД (или ее частей) в случае использования Flash Backup, можно производить на основе Flash Backup БД, не загружая основную БД (например, это можно делать 1 раз в неделю).
GRID серверов БД
GRID серверов БД является развитием кластерной архитектуры Oracle. Oracle Real Application Clusters (RAC) хорошо зарекомендовал себя во многих организациях. Если раньше для установки кластера требовалось установить поверх стандартной операционной системы дополнительное специализированное программное обеспечение третьих фирм, то теперь Oracle сам написал такое программное обеспечение (Clasterware) и поставляет его с версией 10G для любых платформ (а не только для Windows и Linux). Теперь установка кластера Oracle может производиться на стандартные операционные системы. Кроме того, Oracle поставляет в составе RAC кластерную файловую систему – Cluster File System. Это позволяет реализовать кластер не на сырых устройствах (Raw device), а на обычной ОС, где могут храниться и данные кластерной БД и программное обеспечение и другие файлы.
Для создания GRID серверов БД необходимо обеспечить возможность автоматического динамического подключения и отключения дополнительных вычислительных ресурсов сервера БД. Это делается на основе понятия “сервис”. Каждое приложение (например, CRM, ERP, кадры, зарплата и т д) можно рассматривать как сервис, работающий на нескольких узлах GRID. Администратор GRID может для каждого сервиса определить узлы GRID (кластера), на которых этот сервис запускается сразу при старте сервиса (так называемые PREFERED узлы) и узлы, которые этот сервис будет использовать дополнительно при определенных условиях (так называемые AVAILABLE узлы). На остальных узлах GRID этот сервис запускаться не может.
Oracle RAC 9.2 позволяет динамически (не останавливая работу приложения) подключать/отключать новые экземпляры (instance) Oracle. Эта технология используется и здесь. Администратор описывает правила (policy) “переползания” сервиса на дополнительные узлы. Например, сервис CRM приложения запустился на двух узлах GRID и работает с БД. Oracle постоянно измеряет нагрузку на узлы и если она превысит заданный в policy предел, то на одном из разрешенных дополнительных узлов автоматически запустится новый экземпляр Oracle, работающий с этой БД, для обслуживания этого сервиса. Часть сеансов пользователей автоматически “переползет” на новый узел. Тем самым вычислительный ресурс для сервиса увеличится.
При дальнейшем увеличении нагрузки будут запускаться новые экземпляры Oracle на AVAILABLE узлах. При снижении нагрузки узлы будут освобождаться и их смогут использовать другие сервисы (один и тот же узел может быть описан как дополнительный для нескольких сервисов).
В случае выхода из строя одного из обязательных или дополнительных узлов, обслуживающих сервис, также запускается экземпляр Oracle на новом дополнительном узле и вычислительный ресурс сервиса восстанавливается. Oracle постоянно измеряет загрузку узлов, поэтому вновь подключаемые пользователи направляются на наименее загруженные узлы, и уже работающие сеансы также перемещаются на менее загруженные узлы сервиса. Тем самым достигается балансировка загрузки узлов.
Администратор GRID может легко подключать новые компьютеры к GRID и добавлять их в список основных и дополнительных узлов сервиса. Можно создать несколько вариантов списков узлов и политик для сервисов и активизировать разные варианты в разные периоды времени (например, можно создать отдельный вариант для конца квартала). Администратор GRID, используя компоненту GRID Control Enterprise Manager, управлять сервисами (стартовать, останавливать, подключать узлы, конфигурировать узлы и т д). Добавление компьютерного узла в GRID серверов осуществляется путем всего лишь одного нажатия на клавишу мыши.
Перенос обычных приложений Oracle
в среду GRID не требует их переписывания.
Достаточно указать, что приложение работает не с конкретным узлом, а
с сервисом. Например, при соединении клиента SCOTT
с паролем TIGER с сервисом myservice
надо просто написать в строке связи SCOTT/TIGER@//myVIP/myservice.
GRID серверов приложений
Ситуация с серверами приложений похожа на то, что мы видели с серверами БД. Уже в Oracle 9i мы могли организовать кластеры серверов приложений, т е транзакция, начавшаяся на одном сервере приложений, могла, в случае его остановки, продолжиться на других серверах приложений кластера. GRID Control Enterprise Manager позволяет добавлять новые узлы в кластер сервера приложений, управлять этими узлами и кластером, стартовать и останавливать эти узлы. При необходимости узлы могут быть исключены из кластера и отданы под другие нужды (web кэш, сервер БД и т д).
GRID Control позволяет управлять всеми компонентами сервера приложений (кэшем, инфраструктурой, J2EE, EJB и т д). Сервер приложений тесно связан с узлами сервера БД и при выходе из строя узла сервера БД, сервер приложения тут же узнает об этом и переключается на оставшиеся узлы (все это занимает несколько секунд).
Самонастройка СУБД
GRID подразумевает одновременную работу множества серверных узлов и баз данных. Если несколькими узлами администратор БД мог управлять вручную, используя графические средства администрирования, то десятками, сотнями и тысячами серверов БД управлять вручную невозможно. Поэтому Oracle встроил в сервер 10G целую инфраструктуру автоматической диагностики и самонастройки.
Во время работы сервера БД, Oracle автоматически собирает большой объем статистики о работе всех компонентов системы. Эта информация сохраняется в специальном хранилище в БД – автоматическом репозитории загрузки системы (AWR – Automatic Workload Repository). Собирается статистика о выполняемых операциях, ожиданиях, объектах БД и использовании пространства в БД, используемых ресурсах и т д. Сбор статистики не сильно нагружает экземпляр Oracle, а частоту записи собранной статистики в AWR можно регулировать (по умолчанию – запись осуществляется каждые 30 минут).
Собранная статистика анализируется компонентой ADDM (монитор автоматической диагностики БД). Она реализует опыт специалистов Oracle по настройке СУБД и в результате анализа выявляет проблемы производительности, доступа к данным, использования ресурсов и т д. ADDM может также выявлять проблемы, которые возникнут в будущем. Основой для работы ADDM является информация о времени выполнения тех или иных операций и времени ожидания. Выявив наиболее критичные моменты, ADDM детализирует эту информацию и выявляет суть и причины проблемы. Далее он либо автоматически перенастраивает СУБД (изменяет размеры областей памяти SGA, перенастраивает ввод/вывод и т д), либо формирует извещения (алерты), которые пересылает администратору. Администратор БД видит не только извещения, но и описание причин, вызвавших проблему, и предложения по исправлению проблемы. Если он согласен с этими предложениями, то ему достаточно подтвердить это и СУБД Oracle выполнит перенастройку. Т е часть проблем снимается в автоматическом режиме, а часть – в автоматизированном режиме.
Кроме того, в состав инфраструктуры настройки входит набор предустановленных программ анализа и фиксации проблем (Automatic Maintenance Tasks). Они могут запускаться по расписанию (ДБА регулирует частоту запуска) или по запросу администратора, анализировать накопленные за длительное время данные из AWR и выполнять более тонкие настройки СУБД, SQL и т д
Вся эта инфраструктура устанавливается и
включается сразу же при установке сервера БД и информация о проблемах
или потенциальных проблемах поступает к ДБА по мере ее возникновения
(а не тогда, когда он сам решит настроить БД). Инфраструктура
самодиагностики и самонастройки сильно снизила нагрузку на ДБА.
Например, если раньше приходилось вручную управлять размерами
областей памяти, анализировать использование этих областей и
определять последствия изменения размеров, то теперь ДБА задает
только общий размер оперативной памяти, отведенной экземпляру Oracle,
и далее СУБД сама обеспечивает оптимальное использование памяти
Управление GRID (GRID Control)
Для управления, конфигурирования, диагностики множества разнородных узлов, составляющих GRID, в составе стандартного средства управления Oracle Enterprise Manager (OEM) появилась компонента GRID Control. OEM позволяет управлять всеми компонентами GRID – серверами БД, серверами приложений, кэшами, Java машинами, устройствами хранения, сетевыми компонентами, RAC, Standby, распространением данных и т д.
Причем, поскольку индивидуально управлять каждой компонентой сложно, их можно объединить в группы. Например, группа серверов БД отдела или группа компонент, на которых работает приложение (она может включать и сервера БД и сервера приложений и кэши и т д). Для группы можно установить суммарные характеристики (например, работоспособность всех компонент, наличие проблем или аллертов в группе и т д). ДБА будет отслеживать не состояние отдельных объектов, а состояние групп объектов и проводить операции с группами. При желании можно спуститься и до уровня отдельного компонента группы (например, узла сервера БД).
Используя GRID Control, ДБА может анализировать работу приложения в целом и лишь потом переходить к анализу работы отдельных компонент. Например, если время отклика некоторых приложений или запросов превышает установленный предел, то ДБА может посмотреть, как это время распределяется между отдельными компонентами приложения (например, какой процент времени уходит на работу с сетью, выполнение компонент Java, выполнение доступа к БД (SQL) и т д). Найдя, таким образом, критическое место, ДБА может перейти на уровень анализа и настройки этого узкого места. Так, если основное время уходит на выполнение SQL, то можно перейти к настройке этого SQL оператора.
Одной из главных операций управления GRID является добавление/удаление и мониторинг загрузки элементов GRID. Компонента GRID Control позволяет с помощью мышки подключать к GRID и отключать от GRID диски, узлы сервера БД, узлы сервера приложений, Web кэши и т д. Всегда можно также посмотреть их состояние.
Если у нас есть очень большое число компьютеров, составляющих GRID, то трудно проконтролировать, какое системное и прикладное программное обеспечение стоит на этих узлах и как оно сконфигурировано. Oracle GRID Control включает компоненту для управления конфигурациями. Она периодически (по умолчанию 1 раз в сутки) опрашивает все узлы и собирает в БД информацию о конфигурации этих узлов. Собирается информация о версиях ОС на этих узлах, примененных патчах, установленных продуктах Oracle, их конфигурации, версиях и патчах. Эта информация накапливается и обновляется. На ее основе ДБА может проследить историю изменения конфигурации, легко узнать на каких узлах не применялись те или иные патчи, запросить информацию об узлах со старой версией программного обеспечения и т д.
Кроме того, всегда можно сравнить две конфигурации и выявить различия. Например, если один из узлов в результате изменения конфигурации стал работать хуже, то его всегда можно сравнить с хорошо работающим аналогом и выявить отличия в конфигурации. Можно создать эталонные конфигурации и сравнивать с ними. Можно эти эталонные конфигурации “клонировать” на другие узлы. Клонирование программного обеспечения и конфигураций выполняется быстро и просто и позволяет создать GRID однотипных узлов.
При сборе информации о конфигурации узлов, компонента Менеджер конфигурации анализирует эти конфигурации на предмет соблюдения правил Oracle. Если выявляется несоответствие (например, пользовательские объекты в System Tablespace или отключение дублирования управляющих файлов – Control File), то ДБА немедленно извещается об этом. Это позволяет снизить число проблем, которые могут возникнуть в будущем.
Улучшен и механизм применения патчей. Все патчи для разных продуктов, платформ и версий выкладываются в интернет (на сайт metalink). GRID Control может обратиться к этому сайту, проанализировать наличие еще не установленных патчей для тех платформ и версий, которые у Вас используются, и сообщить об этом. Далее, если ДБА “даст добро”, система управления патчами выгрузит их и применит к тем узлам, где это необходимо. Соответствующая информация о применении патчей отобразится и в БД конфигураций.
Поскольку в GRID работает множество пользователей, множество приложений, множество БД и серверов приложений, встает проблема управления правами доступа пользователей к этим ресурсам. GRID Control обеспечивает единый вход (Single Sign-On) для пользователей многих ресурсов. Понятие пользователя отделено от понятия Account (пользователь конкретной БД, конкретного сервера приложений м т д). Информация о пользователях GRID (Enterprise User) хранится в LDAP директории, где для пользователя определены его права для входа в различные компоненты GRID.
Когда система самонастройки сервера выявляет проблемы, требующие вмешательства ДБА, она посылает аллерты в компоненту GRID Control. Здесь ДБА, используя простой графический интерфейс, может узнать о возникновении проблем и исправить ситуацию. Мощная система советов и подсказок (Advisory Infrastructure) практически выполняет за ДБА работу по решению проблемы и часто ему остается лишь подтвердить свое согласие на внесение изменений в настройку.
Oracle GRID
Control позволяет управлять ресурсами
сервера, доступными пользователю. Oracle
Resource Manager
позволяет ограничить максимальное время выполнения запросов, степень
использования процессоров, максимальное количество одновременных
сеансов, степень распараллеливания при выполнении запросов и т д.
Планы использования ресурсов (Resource
Plan) можно быстро переключать (например,
включать дневной или ночной план).
Разделение информации в GRID
Информация хранится в GRID в базах данных и файлах. Множество узлов GRID должно иметь доступ к этой информации, поэтому необходимо организовать разделение информации между узлами. Существует три способа разделения информации:
централизация информации в единой БД;
работы с множеством самостоятельных независимых БД и файлов (федерирование);
временный вынос необходимой информации на узлы, где она будет обрабатываться (propelling);
Централизация информации – самый простой способ. Вся информация из различных источников собирается в одной БД Oracle и далее кластер Oracle прекрасно решает множество задач, работая с этой БД.
Работа с множеством самостоятельных БД тоже хорошо реализована в Oracle. Механизм работы с распределенными БД реализован в Oracle давно, причем узлы этой распределенной БД могут быть реализованы не только на основе СУБД Oracle, но и на основе других СУБД, с использованием шлюзов Oracle Gateway к этим СУБД. При этом каждая БД существует самостоятельно в своей части GRID, живет, обновляется, администрируется своими приложениями, но если необходимо в одном приложении работать с информацией из различных БД, то пользователь (или приложение) просто выполняет распределенный запрос к этой распределенной БД. Если какие-либо объекты данных (таблицы) переносятся из одной БД в другую или из централизованной БД разносятся по различным БД, то доступ к ним не требует переписывания запроса (приложения). Администратору БД достаточно лишь создать синонимы для перенесенных данных и приложение продолжит работу.
Согласованность работы с распределенной БД обеспечивается за счет реализации алгоритмов двухфазной фиксации изменений (2 phase commit), который Oracle реализует автоматически (при создании пользовательских приложений не надо заботиться о том, в единой или разных БД находятся объекты). Тем самым обеспечивается “прозрачность” работы с распределенной БД [7].
Oracle умеет распознавать распределенные запросы и оптимизировать их выполнение с учетом характеристик используемых узлов и БД. Если надо организовать работу с структурированным объектом (таблицей), части которого хранятся в различных БД, то с помощью оператора объединения UNION можно создать виртуальное представление всего объекта и работать с ним, а уж Oracle преобразует операции с объектом в операции с его частями в разных БД.
Работа с распределенной БД требует, чтобы в момент выполнения операций существовала хорошая связь со всеми используемыми БД. Если связь прервется, то запрос выполнен не будет. Кроме того, если БД сильно удалены друг от друга, необходимо иметь очень хорошие быстрые сети передачи данных для доступа к этим БД.
Поэтому часто используется механизм создания в каждой группе узлов GRID своей локальной БД, содержащей копии объектов основной БД. Для создания таких локальных БД надо обеспечить две вещи:
быстрый перенос части данных из одной БД в другую;
постоянную синхронизацию данных.
Быстрый перенос из одной БД в другую больших объемов данных можно осуществить в Oracle с помощью механизма транспортируемых табличных пространств (Transportable tablespace). Вместо того, чтобы экспортировать данные из БД в файл, перемещать файл к другой БД, импортировать данные из файла в новую БД (а все это занимает очень много времени), мы можем просто скопировать (например, с помощью средств FTP) файлы операционной системы, которые образуют табличное пространство, содержащее необходимые нам большие объекты данных. Далее достаточно перенести с помощью экспорта-импорта из одной БД в другую лишь маленький объем метаинформации о перемещенном табличном пространстве. Механизм транспортируемых табличных пространств работает намного быстрее, чем экспорт-импорт.
Перемещаемые файлы можно, например, записать на СD диск и подключать к различным БД в виде набора открытых только на чтение таблиц (например, справочников). В Oracle 10G реализована возможность транспортировки табличных пространств между различными операционными системами. Например, мы можем со скоростью работы по FTP протоколу переместить большие таблицы из БД на Windows в БД на Linux или Unix. Это делается с помощью утилиты RMAN.
Для переноса небольших таблиц из БД в БД в Oracle 10G можно использовать новую утилиту Data Pump. Ее функциональность аналогична тому, что умели делать старые утилиты экспорта-импорта, но работает она намного быстрее. Так импорт данных выполняется в Data Pump в 20-30 раз быстрее, чем раньше, используется механизм распараллеливания вычислений, возможен рестарт работы утилиты с той точки, где она прервала свою работу. Data Pump позволяет выполнить прямой перенос данных из одной БД в другую без создания промежуточных файлов на диске.
Для синхронизации данных, хранящихся в различных БД, может использоваться как старый механизм репликации, так и новый, более универсальный механизм Oracle Streams [5]. Streams позволяет разделять между узлами как сообщения (messaging), так и операции с БД на основе единого универсального механизма. Все заказанные изменения в исходной БД захватываются из журналов БД (это не нагружает эксплуатационную БД) и складируются в едином универсальном формате в области хранения (Stage). Все узлы, которым необходимо получить и применить эту информацию об изменениях, подписываются на получение информации об изменениях из области хранения. При появлении новой информации об изменениях в области хранения, подписавшиеся узлы получат нужную им информацию и смогут ее применить.
Захват и применение информации об изменениях могут быть легко сконфигурированы и далее выполняются автоматически. При захвате, перемещении и применении информации об изменениях, она может быть преобразована с помощью пользовательских процедур.
Единый универсальный механизм Oracle Streams позволяет реализовать репликацию нужных таблиц, передачу сообщений (Advanced Queuing), передачу извещений о событиях (Notification), оперативную подпитку хранилищ данных, упрощая конфигурирование и администрирование этих механизмов. В случае захвата информации обо всех изменениях в исходной БД и применения их к копии этой БД, мы можем реализовать механизм поддержания резервной БД (StandBy Database).
Механизм StandBy Database позволяет поддерживать в нескольких частях GRID копии одной и той же БД. Причем в случае логического StandBy эти копии могут использоваться для выполнения операций чтения к этим БД. Например, на них можно печатать отчеты, выполнять приложения, связанные с анализом данных, и т д.
Oracle Streams позволяет исключить дублирование информации, передаваемой по сети в разные узлы, обеспечить гибкую маршрутизацию потоков данных, гарантированную доставку изменений. С помощью Oracle Streams легко обеспечить двустороннюю репликацию данных и разрешение возникающих конфликтов репликации (имеются встроенные алгоритмы разрешения конфликтов).
Часто необходимо перенести данные из целевой БД в удаленную БД лишь на время, для их обработки там. Это позволяет сделать механизм Self Propelling, реализованный в Oracle 10G. Практически это объединение механизма транспортируемых табличных пространств и механизма Oracle Streams. С помощью всего одной команды можно организовать перенос информации в другую БД и запуск механизма ее синхронизации с копией в источнике. Таким образом мы можем вынести данные и их обработку на менее загруженные узлы GRID.
Механизм Self Propelling позволяет оперативно приблизить данные к месту их обработки, снизить нагрузку на сеть, уменьшить число проблем и ошибок, связанное с работой в среде распределенной БД.
В GRID часто информация может храниться не в БД, а в файлах операционной системы. Механизм Oracle External Table позволяет использовать средства работы с БД для работы с информацией файлов. Файлы определяются в словаре БД как внешние (external) таблицы и далее с ними можно работать на чтение (и на запись в Oracle 10G) как с обычными таблицами БД. Более того, можно выполнять операции, одновременно работающие с реляционными таблицами БД и информацией файлов операционной системы.
СУБД Oracle
поддерживает тип данных Bfiles. Если Вы создадите в БД
таблицу с колонкой типа Bfile, то в этой
колонке будут храниться лишь ссылки на файлы операционной системы, а
сами данные, помещаемые в эту колонку, будут храниться в файлах ОС.
Это еще один механизм для работы с файлами операционной системы.
Понятно, что и файлы ОС и их описания в словаре БД можно копировать и
перемещать между узлами GRID, обеспечивая
разделение информации.
5. Заключение. Концепция GRID и реальность
Итак, в этой статье мы рассмотрели концепцию GRID и попытки ее реализации компанией Oracle с помощью продукта Oracle 10G. Понятно, что 10G – только первый шаг на длинном пути реализации GRID-вычислений. Из статьи видно, что сегодняшние предложения по реализации GRID сильно отличаются от идеальной концепции и сужают ее, однако они позволяют уже сейчас начать пользоваться преимуществами GRID. Почему же реальность так далека от концепции? Дело в том, что многие идеи концепции пока еще неосуществимы в промышленном масштабе.
Идеальная GRID должна быть географически распределена (объединять компьютеры всего мира, независимо от расстояния между ними). К сожалению, сегодняшние сети передачи данных не позволяют это реализовать. Невозможно осуществить быструю и надежную работу американских серверов с БД, размещенными в России, так, как будто все они находятся в одном здании. Невозможно быстро перебрасывать большие объемы информации и огромные БД из Америки в Россию для выполнения вычислений, требующих дополнительного вычислительного ресурса.
Концепция GRID подразумевает объединение в единый вычислительный ресурс самых разных типов компьютеров с различными операционными системами. Сегодня большинство фирм-производителей программного обеспечения для GRID позволяет объединить в GRID только компьютеры одного типа (например, GRID HP серверов, GRID Intel компьютеров с Linux, GRID Blade ферм и т д). Конечно мы можем уже сегодня создать большую распределенную GRID, состоящую из однородных участков (например, участок Blade ферм с Linux и участок серверов Sun Solaris), но обмен данными между участками будет сложен, а объединение их в единый ресурс пока невозможно. Т е эта GRID будет состоять из нескольких слабо связанных между собой участков.
Еще одна проблема GRID – это смешивание двух разных понятий: GRID как единый суперкомпьютер и GRID как коммунальная услуга. Если первое пока невозможно, то элементы второго мы можем видеть уже сегодня.
Идею “заплати и получи нужный объем услуг” реализует сегодня услуга по аутсорсингу или хостингу приложений. Компьютеры, операционные системы, СУБД, услуги по администрированию, установке ПО, сопровождению, настройке приложений предоставляет компания, продающая услуги аутсорсинга. Пользователь лишь оплачивает услугу и через интернет или канал связи работает с приложением, не заботясь о том, где и как оно установлено. Кстати, Oracle имеет ряд механизмов для использования его в таком режиме (это, например, механизмы аутентификации, виртуальной частной БД (VPD), Connection Pooling, трехуровневая архитектура и т д). В России компания DataFort обеспечивает услуги по аутсорсингу приложений на Oracle.
Идею получения информации в любое время и из любого места в мире, тоже сегодня можно реализовать, используя интернет доступ к ресурсам. Действительно, работая с интернет-приложениями, мы можем в любое время и в любой части света выйти с компьютера, имеющего Web броузер, в интернет и работать с приложением. Конечно это пример разделения доступа (интернета), а не вычислительных ресурсов (это обеспечивает GRID), но идею доступа отовсюду реализует успешно.
Таким образом, понятно, что элементы однородной корпоративной GRID можно начать реализовывать уже сегодня, причем для экономии средств это лучше делать на основе дешевых Intel машин или Blade компьютеров.
Для реализации же идеальной концепции GRID придется еще решить огромное множество проблем (кроме выше перечисленных), и не факт, что некоторые из них разрешимы. Среди этих проблем хотелось бы упомянуть такие, как:
единая авторизация и аутентификация пользователей (если в рамках ЦОД и однородной GRID это осуществимо, то на глобальном уровне реализовать это более сложно;
создание единого пространства имен (единого для всего мира);
учет использования вычислительных ресурсов и принципы их оплаты. Пока эти вопросы проработаны слабо;
управление правами использования ресурсов, выдача привилегий, установка приоритетов. Даже в рамках одной организации решить эту проблему сложно, а уж в мировом масштабе и подавно;
защита “своих” данных на компьютерах GRID. Немногие организации допустят даже потенциальную возможность доступа через GRID к их конфиденциальной информации.
А ведь еще есть масса нерешенных юридических и политических вопросов объединения вычислительных ресурсов различных владельцев. Они тоже навряд-ли разрешимы в ближайшее время. Поэтому представляется очевидным, что сегодня наиболее актуально говорить о GRID ЦОД или предприятия, но даже такая GRID позволит получить ряд конкурентных преимуществ и сэкономить деньги.
Литература
Foster, C. Kesselman, S. Tuecke. The Anatomy of the Grid: Enabling Scalable Virtual Organizations. // International Journal. Supercomputer Applications, 15(3), 2001.
http://www.globus.org/research/papers.html- Foster, C. Kesselman, J. Nick, S. Tuecke, The
Physiology of the Grid: An Open Grid Services Architecture for
Distributed Systems Integration. // Open Grid Service Infrastructure
WG, Global Grid Forum, June 22, 2002
http://www.globus.org/research/papers.html - Н Дубова. Учет и контроль для “коммунальных вычислений” // Открытые системы N1, 2003
- П Анни. Этот GRID – неспроста... // Открытые системы N1, 2003
- М Ривкин. Oracle Streams — универсальное средство обмена информацией //Byte, 2003, N 6
- M Ривкин. Новые возможности Oracle 9.2 //Открытые системы, 2002, N 11
- М. Ривкин. Распределенные СУБД // Мир ПК, 1993, N 5
- http://mrivkin.narod.ru/oracle.html