Резюме:
Данная статья посвящена проблемам, которые возникают в тех сферах деятельности, что связанны с технологиями интеграции данных, которые должны снабжать современный деловой мир ясной и достоверной информацией для создания преимущества над конкурентами.
В статье рассказано, как SQL Server 2005 Integration Services (SSIS) могут помочь департаментам информационных технологий выполнить требования их компании. Приведены практические примеры.
Авторские права
Этот документ является предварительным и может быть существенным образом переработан до финального коммерческого релиза программного продукта
Информация, содержащаяся в этом документе, представляет текущую точку зрения корпорации Microsoft на обсуждаемые вопросы на момент публикации. Поскольку Microsoft должна реагировать на изменяющиеся условия на рынке, документ не следует рассматривать как обязательство со стороны Microsoft; корпорация Microsoft не может гарантировать, что вся представленная информация сохранит точность после даты публикации.
Настоящий документ предназначен только для информационных целей. MICROSOFT НЕ ДАЕТ В ЭТОМ ДОКУМЕНТЕ НИКАКИХ ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ.
Если не оговорено противное, используемые в этом документе названия компаний и продуктов, имена людей, действующие лица и/или данные являются вымышленными, и их ни в коей мере не следует связывать с какими-либо реальными людьми, компаниями, продуктами или событиями.
© 2005 Microsoft Corporation. Все права защищены.
Microsoft, SharePoint, Visual Basic и Visual Studio являются товарными знаками или охраняемыми товарными знаками корпорации Майкрософт в США и/или в других странах.
Другие упоминаемые здесь названия продуктов или компаний могут представлять собой торговые марки соответствующих владельцев.
Содержание
Введение
Возможность преобразовывать корпоративные данные в ясную и позволяющую принимать решения информацию есть один и наиболее важных метод достижения преимущества над конкурентами в современном деловом мире.
Исследование быстрого роста данных для лучшего понимания прошлого и тенденций будущего оказалось одним из наиболее рискованных начинаний для департаментов информационных технологий мировых организаций.
Существуют три глобальных группы проблем, связанных с процессом интеграции данных:
- Технологические проблемы
- Организационные проблемы
- Экономические проблемы
В данной статье мы подробно исследуем эти проблемы и обсудим возможность их решения с помощью Microsoft® SQL Server™ 2005 Integration Services (SSIS). Для начала рассмотрим их на практическом примере.
Практический пример
В качестве примера возьмем крупную международную транспортную компанию, которая использует свою базу данных, как для анализа производительности своей деятельности, так и для прогнозирования несоответствий в уже запланированных доставках.
Источники данных
Важнейшие источники данных компании представляют собой данные заказов из системы ввода заказов на основе DB2, данные клиентов из системы взаимоотношений с клиентами (CRM) на основе SQL Server и данные поставщиков из системы планирования и управления ресурсами (ERP) на основе Oracle. В дополнение к этим источникам данных в базу данных включены электронные таблицы, которые наблюдатели за поставками могут заполнять вручную для отслеживания "особых" случаев.
На данный момент, внешние данные, такие как метеорологическая информация, состояние транспортной системы, и информация о поставщиках (для субподрядных поставок) вносится в систему с задержкой из текстовых файлов из различных источников.
Потребление данных
В дополнение к многообразию источников данных потребители данных также разняться как по своим требованиям, так и по географическому местоположению. Такое многообразие приводит к увеличению числа локальных систем. Поэтому одной из основных задач ИТ отдела будет являться создание "единственной и правдоподобной картинки", как минимум для своих же клиентов.
Требования к интеграции данных
Ввиду такого многообразия данных и требований, как бизнеса, так и конечных пользователей, ИТ отдел выработал следующий список требований к интеграции данных:
- Обязательно необходимо представлять достоверные и согласованные данные, собранные из различных внутренних и внешних источников.
- Для уменьшения задержек при сборе данных от поставщиков и продавцов эти данные должны быть доступны через Web-сервисы или другие механизмы прямого доступа, например, FTP.
- Необходимо повышать качество данных путем выявления и удаления дублирующихся данные, а также другими способами.
- Растущее число новых глобальных требований обуславливает ведения четкого аудита совершаемых действий. Недостаточно просто поддерживать достоверность данных, нужно также отслеживать данные и гарантировать их достоверность.
Проблемы интеграции данных
На первый взгляд задача интеграции данных для приведенного выше примера выглядит чрезвычайно простой. Нужно только взять данные из различных источников, очистить и преобразовать их и затем загрузить в соответствующие места для хранения для последующего анализа и построения отчетов. К сожалению, в типичном проекте по созданию хранилища данных или единой базы знаний предприятия 60-80% доступных ресурсов тратится на этапе интеграции данных. Почему же так происходит?
Технологические проблемы
Технологические проблемы берут начало от используемых систем. Мы переходим от сбора данных о завершенных транзакциях (когда клиенты подтвердили факт доставки, покупки или иного пути получения чего-либо) к сбору данных о планируемых транзакциях (когда действия клиента отслеживаются через механизмы на подобии Web clicks или RFID). Данные поступают уже не только из традиционных источников и в традиционных форматах, например, в виде баз данных или текстовых файлов, но все более и более во множестве разнообразных форматов (от файлов с патентованным форматом и документов Microsoft Office до XML файлов) и из источников, основанных на интернет технологиях (например, Web-сервисы или потоки RSS (Really Simple Syndication). Вот наиболее типичные возникающие при этом проблемы:
- Множественные источники с различными форматами данных.
- Структурированные, частично структурированные и неструктурированные данные.
- Порции данных от разных источников доставляются в разное время.
- Огромный объем данных.
В идеальном случае даже если мы каким-то образом сумеем собрать все эти данные в одном месте, то перед нами тут же возникнут новые проблемы. А именно:
- Качество данных.
- Необходимость понимать различные форматы данных.
- Преобразование данных в формат понятный бизнес-аналитикам.
Опять предположим, что каким-то волшебным способом мы справились с задачей сбора данных и можем эти данные очистить, преобразовать и отобразить в нужном нам формате. По-прежнему существует отступление от традиционных способов перемещения и интеграции данных. Это отступление выражается в переходе от фиксированных длительных пакетно-ориентированных процессов к изменчивым и коротким процессам, запускаемым по требованию. Пакетно-ориентированные процессы обычно работали в часы "простоя", когда нагрузка на систему со стороны пользователей мала. Обычно это заранее определенное "окно" в 6-8 часов в ночное время, когда не предполагается наличие кого-либо на рабочем месте. Но в условиях глобализации всех видов и типов бизнеса такое предположение уже не является неоспоримым. Время простоя системы становится малым или вообще исчезает, поскольку кто-нибудь из работников всегда находится на рабочем месте где-то по всему миру. Другими словами в глобальном бизнесе больше нет понятия конец рабочего дня. В результате чего мы имеем:
- Увеличенную потребность в скорейшей загрузке данных.
- Потребность в одновременной загрузке во множество приемников данных.
- Множество приемников данных.
Все перечисленное выше нам не только предстоит сделать, но предстоит сделать наиболее быстрым способом. В особо "тяжёлых" случаях, например, в онлайн бизнесе существует необходимость в непрерывной интеграции данных. В таком бизнесе не существует временных "окон" для пакетной обработки и время ожидания данных не может превышать нескольких минут. Во многих подобных системах процесс принятия решения автоматизирован с помощью программного обеспечения с непрерывной обработкой.
Масштабируемость и производительность становятся все более и более важными в тех сферах бизнеса, которые не могут позволить себе и малейшего времени простоя.
Без подходящей технологии система почти на каждом этапе процесса работы с хранилищем данных и интеграции данных нуждается в дополнительных действиях над данными. При использовании в ETL (Extract, Transform, and Load - система извлечения, преобразования и загрузки данных) различных (особенно нестандартных) источников данных, а также при сложных манипуляциях с данными (например, при data mining - нахождении трендов), потребность в дополнительной обработке данных возрастает. Как показано на Рисунке 1, с увеличением дополнительных этапов обработки данных возрастает и время "закрытия цикла" (т.е. время на анализ новых данных и выполнения действий над новыми данными). Традиционные архитектуры ETL (как противоположность "чистым" ETL процессам, т.е. происходящим до загрузки данных) накладывают серьёзные ограничения на способность системы соответствовать возникающим потребностям бизнеса.
Рисунок 1
И, наконец, вопрос о том, как проблема интеграции данных влияет на общую архитектуру интеграции предприятия становится более значимым,
когда одновременно требуется применять как транзакционную технологию интеграции приложений реального времени, так и пакетно-ориентированную высокообъемную технологию интеграции данных для решения бизнес проблем предприятия.
Организационные проблемы
В больших организациях существуют две большие проблемы, связанные с задачей интеграции данных. Это проблема "власти" и проблема "зоны комфорта"
Проблема "Власти": Данные имеют реальную силу, но обычно людей трудно заставить воспринимать данные как действительно ценный общий актив компании. Для успешной интеграции корпоративных данных необходимо, чтобы владельцы всех многочисленных источников данных искренне прониклись целями и задачами этого проекта. Недостаток взаимодействия между вовлечёнными сторонами является одной из главных причин неудач, постигающих проекты интеграции данных. Административная поддержка, достижение согласия и сильная команда, состоящая из представителей всех сторон - вот важнейшие факторы, влияющие на успех проекта и помогающие решать проблемы.
Проблема "Зоны комфорта": Проблемы интеграции данных, если их рассматривать только в контексте одной потребности, могут быть решены разными способами. Около 60% задач интеграции данных можно решить ручного кодирования. При этом для решения подобных задач может быть использован большой спектр средств, начиная с репликации, технологии извлечения, преобразования и загрузки данных(ETL), SQL запросов, и заканчивая интеграцией прикладных систем предприятия(EAI - Enterprise Application Integration).
Люди склонны к использованию тех технологий, которые им знакомы.
Хотя такие методы и имеют пересекающиеся возможности и могут, наверное, использоваться для решения отдельных задач, но все эти технологии все-таки изначально оптимизировались для решения задач разного типа. При реализации задачи корпоративной интеграции данных промах на этапе определения для выбранной архитектуры подходящих методов реализации может обернуться провалом проекта.
Экономические проблемы
В совокупности, описанные выше организационные и технологические проблемы, делают процесс интеграции данных одной из самых дорогостоящих частей проекта создания хранилища данных или проекта корпоративной базы знаний. Основными факторами, увеличивающими стоимость процесса интеграции данных, являются:
- Процесс получения данных в формате, необходимом для окончательной интеграции данных, становится медленным и мучительным из-за внутрикорпоративных игр вида "кто в доме хозяин".
- Процесс очистки и преобразования данных из многочисленных форматов в единый согласованный и четкий формат является чрезвычайно трудным.
- Большинство стандартных средств интеграции данных не обладают необходимой функциональностью или расширяемостью, чтобы удовлетворить все потребности проекта по преобразованию данных. Это может привести к большим затратам на консалтинг по созданию специальной ETL (системы извлечения, преобразования и загрузки данных) для решения этой задачи.
- Разные отделы компании рассматривают задачу интеграции данных по-разному. В этом случае совмещение этих разных точек зрения в единой корпоративной архитектуре интеграции данных потребует дополнительных затрат.
А если проект создания хранилища данных или проект корпоративной базы знаний потребует еще и реорганизации самой компании, то по мере развития проекта ошибочная архитектура интеграции данных будет становиться все более неуправляемой и цена ее владения взлетит до небес.
SQL Server 2005 Integration Services
Большинство хранилищ данных по-прежнему основываются на интеграции данных из различных источников с помощью традиционных ETL систем (систем извлечения, преобразования и загрузки данных). Однако, необходимость в получении данных из множества источников, динамически меняющиеся требования и наличие глобальных и онлайн операций очень быстро меняют и требования к процессу интеграции данных. В этих быстроменяющихся условиях потребность в извлечении ценности из данных и возможности доверять этим данным становится важнее, чем ранее.
Эффективная система интеграции данных является основой для эффективной же системы принятия решений. SQL Server Integration Services предлагает гибкую, производительную и масштабируемую архитектуру для эффективной интеграции данных в современных условиях ведения бизнеса.
В данной статье мы рассмотрим почему SQL Server Integration Services (SSIS) является эффективным средством как для реализации ETL систем с обычными требованиями, так и для решения растущих потребностей в рамках общего проекта интеграции данных. Мы также обсудим фундаментальные отличия SSIS от решений других производителей ETL систем. И убедимся, что он идеально подходит для удовлетворения меняющихся потребностей мирового бизнеса, как в больших корпорациях, так и в малых фирмах.
Архитектура SSIS
Механизмы потока задач и потока данных
SSIS совмещает в себе как ориентированный на операции механизм потока задач (task-flow), так и масштабируемый и производительный механизм потока данных (data-flow). Поток данных существует в контексте общего потока задачи. Существует механизм потока задач, который предоставляет механизму потока данных поддержку ресурсов и операций во время выполнения. Такое сочетание потоков задач и потоков данных позволяет эффективно использовать SSIS и проектах с традиционными системами ETL и в проектах по созданию хранилищ данных. А также и в более сложных проектах, например, в проектах центров данных. В этой статье главным образом рассматриваются примеры, связанные с потоками данных. Использованию SSIS в процессах, ориентированных на центры данных является темой для отдельной дискуссии.
Конвейерная архитектура
Ядром SSIS является конвейер преобразования данных. Этот конвейер имеет буферную архитектуру, которая дает ему большую производительность при манипуляции наборами данных за счет загрузки их в память. Такой подход позволяет производить все шаги преобразования данных в ETL системах как одну операцию, т.е. без получения промежуточных результатов. Хотя специфические преобразования, или требования к функционированию, или даже само оборудование могут послужить помехой для этого. Тем не менее, для максимально производительности выбранная архитектура избегает промежуточных результатов. Даже простое копирование данных в памяти избегается по мере возможностей. В этом состоит существенное отличие от традиционных средств ETL, которые очень часто создают промежуточные результаты почти на каждом шагу процесса заполнения хранилища или интеграции данных. Возможность обрабатывать данные без создания промежуточных результатов выходит за рамки традиционных реляционных данных и данных из плоских файлов, а также традиционных методов преобразования в системах ETL. В SSIS все типы данных (структурированные, неструктурированные, XML и т.д.) непосредственно загрузкой в буферы приводятся к табличному (т.е. состоящему из столбцов и строк) виду. Все виды операций, которые применимы к табличному представлению данных, могут быть применены к данным на любом шаге конвейера обработки данных. Это означает, что один конвейер обработки данных может объединять в себе множество различных источников данных и производить над этими данными сколь угодно сложные операции без создания промежуточных результатов.
Хотелось бы также отметить то, что если все же по соображениям бизнеса или оперативным причинам нам требуются промежуточные результаты, то SSIS обеспечивает нам хорошие возможности для их получения.
Такая архитектура позволяет использовать SSIS в большом числе проектов по интеграции данных, начиная от традиционных ETL систем для хранилищ данных и заканчивая нетрадиционными технологиями по интеграции информации.
Примеры интеграции данных
Пример заполнения традиционного хранилища данных
По своей сути SSIS является комплексным и полнофункциональным инструментом для систем ETL (систем извлечения, преобразования и загрузки данных). По функциональным возможностям, масштабу и производительности он стоит вровень с ведущими конкурентами в данной области, а по цене намного предпочтительнее их. Архитектура конвейерной обработки данных позволяет ему одновременно принимать данные из множества источников, производить над ними сложные множественные преобразования, а затем одновременно выгружать данные во множество приемников. Такая архитектура позволяет использовать SSIS не только для работы с большими наборами данных, но и для сложных потоков данных. На своем пути от источника(ов) к приемнику(ам) один поток данных можно разделить, соединить, смешать с другими потоками данных, или произвести еще какие-нибудь манипуляции. На Рисунке 2 показан пример такого потока:
Рисунок 2
SSIS может извлекать (а также выгружать) данные из различных источников, включая OLE DB, управляемые источники (ADO.NET), ODBC, плоские файлы, Excel, и XML, с помощью специального набора компонент, которые называются адаптерами (adapters). SSIS также может использовать для извлечения данных индивидуальные адаптеры (custom adapters), т.е. созданные самостоятельно или другими производителями для своих нужд. Это позволяет включить унаследованную логику загрузки данных непосредственно в источник данных, который, в свою очередь, без дополнительных действий может быть внедрен в поток данных SSIS. В SSIS включает в себя набор мощных средств преобразования данных, с помощью которых можно производить с данными все манипуляции, которые необходимы при создании хранилищ данных. Эти компоненты включают:
- Aggregate - позволяет вычислять всевозможные агрегаты за один проход.
- Sort - упорядочивает данные в потоке.
- Lookup - осуществляет гибкий кэшированный поиск в связанных наборах данных.
- Pivot и UnPivot - два отдельных преобразования смысл которых полностью совпадает с их именами.
- Merge, Merge Join, и Union All - выполняют операции по соединению и объединению.
- Derived Column - осуществляет манипуляции над столбцом данных. Такие как строковые, числовые, временные и прочие преобразования, а также перевод из одной кодировки в другую. Этот компонент может заменить несколько операций преобразования данных в продуктах других фирм.
- Data Conversion - преобразует данные в различные типы (числовой, строковый и т.д.).
- Audit - добавляет столбцы с построчными метаданными о происхождении или другими оперативными данными аудита
Вдобавок к этим основным преобразованиям данных для хранилищ данных SSIS включает поддержку расширенных хранилищ, таких как Slowly Changing Dimensions (SCD - Редко Обновляемые Размерности). Мастер SCD поможет пользователям в определении того, какие измерения являются редко обновляемыми, и на основе этой информации создаст полностью готовый к использованию поток данных с несколькими преобразованиями, реализующими загрузку медленно изменяющихся измерений. В дополнение к двум стандартным типам SCD (SCD Type 1 и SCD Type 2) предлагаются еще два новых типа - Fixed Attributes и Inferred Members (ФиксированныеПризнаки и ВыведенныеЭлементы). На Рисунке 3 отображен один из диалогов Мастера SCD.
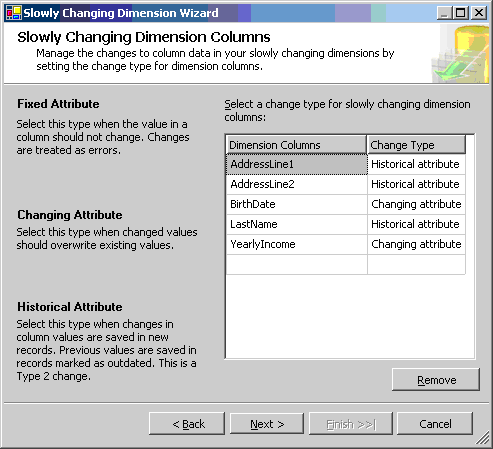
Рисунок 3
На Рисунке 4 показан поток данных, созданный этим Мастером.
Рисунок 4
SSIS также можно использовать для загрузки данных в многомерные OLAP кэши (MOLAP) Analysis Services непосредственно из конвейера обработки данных. Это значит, что SSIS пригоден не только для создания реляционных хранилищ данных, но и для загрузки многомерных кубов для аналитических аппликаций.
SSIS и качество данных
Одной из ключевых особенностей SSIS является его способность не только интегрировать данные, но также интегрировать методы обработки этих данных. Такой подход позволяет включить в него средства для очистки информации, основанные на передовой нечёткой логике ("fuzzy logic"). Эти средства были разработаны в исследовательских лабораториях Microsoft и представляют собой последние достижения в этой области. Данный метод является доменно-независимым, т.е. не зависит ни от одного конкретного типа данных, как, например, справочные данные об адресе/почтовом индексе. Это позволяет в таких преобразованиях очищать данные большинства типов, а не только данные об адресе.
SSIS глубоко интегрирован с методами Data Mining из Analysis Services. Анализ данных это процесс извлечения образцов из набора данных и формирования из них модели. Эта модель далее может быть использована для составления прогнозов о том, какие данные из набора являются типичными, а какие аномальными. Т.е. Data Mining можно использовать как механизм для повышения качества данных.
Поддержка комплексных методов передачи данных в SSIS позволяет не только обнаружить аномальные данные, но так же автоматически исправить их и заменить лучшими значениями. Т.е. возможно создать полный цикл очистки данных. На Рисунке 5 представлен пример такого полного цикла.
Рисунок 5
В дополнение к встроенным методам контроля качества данных SSIS может быть расширен за счет аналогичных решений от других производителей.
Применение SSIS за пределами традиционных ETL систем
Способность конвейера потока данных обрабатывать практический любой вид данных, тесная интеграция с Analysis Services, возможность расширения за счет большого числа различных технологий преобразования данных, наличие мощного механизма процессов - все это позволяет использовать SSIS во многих проектах, которые традиционно не воспринимаются как ETL задачи (задачи извлечения, преобразования и загрузки данных).
Архитектура, ориентированная на службы (Service Oriented Architecture)
SSIS включает поддержку извлечения XML данных в конвейере потока данных, как из файла на диске, так и непосредственно из URL-ов через HTTP. XML данные приводятся к табличному виду, что позволяет легко манипулировать ими в потоках данных. Такая возможность может быть использована для работы с Web-службами. SSIS может взаимодействовать с Web-службами в управляющем потоке, перехватывая XML данные от них.
Также XML данные могут быт получены из файлов, из Microsoft Message Queuing (MSMQ), и из Web через HTTP. SSIS позволяет обрабатывать XML данные с использованием XSLT, XPATH, diff/merge и т.д. А также направлять XML в поток данных.
Такая поддержка позволяет SSIS участвовать в гибкой архитектуре, ориентированной на службы (Service Oriented Architectures - SOA).
Data & Text Mining
SSIS не только имеет глубокую интеграцию с методами Data Minig Analysis Services, но также содержит средства Text Minig. Text Minig, также известная как систематизация текстов, представляет собой определение связей между видами бизнеса и текстовыми данными (словами и фразами). Этот метод позволяет находить в текстовых данных ключевые понятия и, опираясь на них, автоматически идентифицировать весь текст как представляющий определенный интерес. Это, в свою очередь, может инициировать полный цикл других действий для выполнения других бизнес задач. Например, для увеличения удовлетворенности потребителей или улучшения качества продукции и услуг.
Источники данных по требованию
Одной из уникальных особенностей SSIS является приемник данных DataReader, который выгружает данные в DataReader из ADO.NET. Когда этот компонент включается в конвейер обработки данных, то пакет, содержащий приёмник DataReader, может быть использован как источник данных, работающий как DataReader из ADO.NET. Что позволяет использовать SSIS не только в традиционных системах ETL для загрузки данных в хранилища, но и в качестве источника данных поставляющего единообразные, согласованные и очищенные данные, полученные из множества источников по требованию. Например, Reporting Services может использовать пакет SSIS в качестве источника данных для получения данных из множества различных источников.
Одним из возможных примеров, объединяющем в себе данные методы, может быть система, которая распознает полученные через RSS статьи на предмет статей с интересующей нас информацией и включает их в стандартный отчет. На Рисунке 6 показан SSIS пакет, получающий данные из Интернета посредством RSS, соединяющий эти данные с данными от Web-службы, производящий добычу текста для нахождения интересующей нас информации и записывающий эту информацию в DataReader приемник, который в итоге будет использован в отчете в Reporting Services.
Рисунок 6
Рисунок 7 показывает использование пакета SSIS в качестве источника данных в Мастере Отчётов.
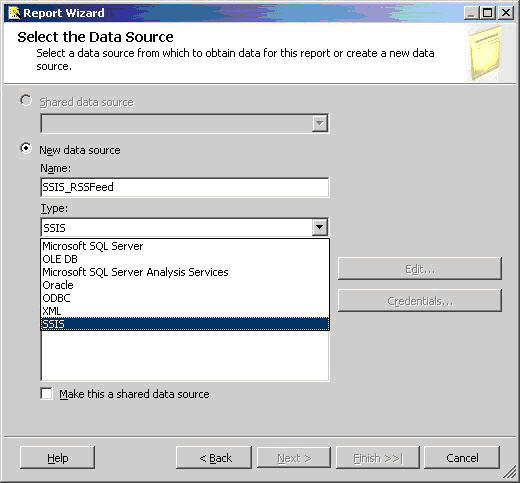
Рисунок 7
С точки зрения стандартных ETL средств, предложенный пример выглядит очень необычно, т.к. в действительности не содержит ни операций извлечения данных, ни операций по их преобразованию и сохранению.
SSIS как интеграционная платформа
SSIS выходит за рамки обычных ETL средств не только счет своей способности реализовывать необычные сценарии работы, но и за счет своей способности служить в качестве платформы для интеграции данных. SSIS является частью платформы SQL Server Business Intelligence (BI), которая позволяет создавать сквозные BI приложения.
Интегрированная платформа для разработки
И SQL Server Integration Services, и Analysis Services и Reporting Services используют единую, основанную на Visual Studio® среду разработки, получившие название SQL Server Business Intelligence (BI) Development Studio. BI Development Studio предоставляет интегрированную среду разработки (IDE) для создания BI приложений. Эта совместная инфраструктура позволяет интегрировать различные типы проектов (интеграция, анализ и составление отчетов) на уровне метаданных. Примером такой структуры может служить Data Source View (DSV), которое представляет собой оффлайн описание схемы источников данных и используется во всех трех типах BI проектах.
Эта интегрированная среда разработки (IDE) предлагает такие возможности как взаимодействие с приложением контроля версий (например, VSS) вместе с поддержкой особенностей командной разработки, например, "check-in/check-out", а также удовлетворяет потребности командных средств разработки корпоративного уровня для BI приложений. На Рисунке 8 одно из решений на основе BI Development Studio, содержащее проекты для интеграции данных, их анализа и получения отчетов.
Рисунок 8
Помимо единого места для создания BI приложений, можно создавать и другие проекты Visual Studio (с использованием Visual C#®, Visual Basic® .NET и т.д.), что даст разработчикам опыт в создании действительно сквозных приложений. Помимо интегрированной среды разработки, BI Development Studio обладает возможностью отладки SSIS пакетов во время выполнения. Что включает в себя возможность задания точек останова и поддержку таких стандартных приемов разработки как отслеживание значений переменных. А уникальной особенностью является Data Viewer, позволяющий просматривать строки данных в том виде, в каком они обрабатываются в конвейере потока данных. Просматривать данные можно как в виде обычной текстовой таблицы, так и в графическом виде, например, как диаграмму разброса данных или как гистограмму. Фактически же можно одновременно отображать данные в разных форматах с помощью разных средств просмотра. На Рисунке 9 показан пример одновременного отображения географических данных в виде диаграммы разброса и текстовой таблицы.
Рисунок 9
Программируемость
В дополнение к профессиональным средствам разработки SSIS предоставляет свою функциональность посредством богатого набора API. Эти API подразделяются на управляемые (.NET Framework) и неуправляемые (Win32) и позволяют разработчикам расширять функциональность SSIS путем создания собственных компонент на всех поддерживаемых в .NET Framework языках (Visual C#, Visual Basic .NET, и т.д.) а также на C++. Эти собственные компоненты могут реализовывать как потоки задач, так и преобразования данных, включая адаптеры для источников и приемников данных. Это позволяет унаследованным данным и функциональности легко включаться в процесс интеграции SSIS, позволяя эффективно использовать сделанные в прошлом вложения в технологии. Также можно легко использовать компоненты других производителей.
Собственный макроязык
Все описанные выше возможности расширения функциональности не ограничиваются только повторным использованием имеющихся собственных компонент, но включают расширяемость за счет собственного макроязыка. В SSIS имеется макроязык и для потоков задач и для потоков данных. Пользователи могут создавать скрипты на Visual Basic. NET для добавления специфической функциональности (включая источники и приемники данных) и для повторного использования уже существующей в виде .NET Framework сборки функциональности.
На Рисунке 10 показан пример скрипта манипулирующего строками данных внутри потока данных.
Рисунок 10
Такая расширяемая модель делает SSIS не только средством интеграции, но превращает его в интеграционную магистраль (Integration Bus) внутри которой технологии вида Data Mining, Text mining или UDM можно легко подключить для создания сложных сценариев интеграции включающих большое количество операций с произвольными данными и структурами.
Доступность интеграции данных
Гибкость и расширяемость архитектуры SSIS позволяет использовать для решения большинства технологических проблем процесса интеграции данных, которые были ранее оглашены в этой статье. Как показано на Рисунке 11, SSIS устраняет (или, по крайней мере, минимизирует) ненужные промежуточные результаты. Т.к. в рамках одной конвейерной операции производятся сложные преобразования данных, то становится возможным реагировать на изменения или появление данных поистине очень быстро, т.е. за такой промежуток времени, который действительно приемлем для завершения цикла обработки и принятия решения. В этом состоит отличие от традиционных архитектур, которые зависят от промежуточных данных и поэтому непригодны для завершения цикла обработки и выполнения осмысленных действий на основе полученных данных.
Рисунок 11
Расширяемая сущность SSIS позволяет организациям в полном объеме использовать уже сделанные вложения в специальный программный код проекта интеграции данных за счет включения этого кода в SSIS в виде повторно используемых расширений и получения в дополнение к этому средств ведения протокола, отладки, интеграции с BI и т.д. Все это действительно поможет в преодолении тех организационных трудностей, которые мы упомянули ранее в этой статье.
Включение SSIS в состав SQL Server делает стоимость покупки первого удивительно выгодной по сравнению с другими профессиональными средствами интеграции данных. Но мы имеем не только низкую начальную стоимость, а также из-за тесной интеграции с Visual Studio и другими средствами SQL Server BI значительно снижаются (в сравнении с другим аналогичным ПО) затраты на разработку и сопровождение. Действительно умеренная общая стоимость владения (total cost of ownership - TCO) SSIS (а в дополнение и SQL Server) делает вполне достижимой задачу корпоративной интеграции данных для всех сегментов рынка, а не исключительно для самых больших (и, разумеется, самых богатых) компаний. В тоже время архитектура SSIS приспособлена ко всем достижениям современного оборудования и предоставляет производительность и масштабируемость согласно самым высоким пользовательским требованиям. SSIS с его богатым и масштабируемым набором возможностей по интеграции данных подойдет всем пользователям от мала до велика - от самых больших корпораций до малого и среднего бизнеса. В связке с другими возможностями SQL Server, благодаря инфраструктуре поддержки клиентов фирмы Microsoft (начиная от всестороннего и тщательного бэта-тестирования и заканчивая множеством онлайн сообществ и примьер договорами о поддержке) и согласованности и интеграции с другими продуктами Microsoft, SSIS является поистине уникальным продуктом, который открывает новые горизонты в области интеграции данных



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС