Глава 10. Транзакции и параллелизм
В данной главе изучаются возможности параллельного выполнения транзакций несколькими пользователями, т.е. свойство (И) - изолированность транзакций.
Современные СУБД являются многопользовательскими системами, т.е. допускают параллельную одновременную работу большого количества пользователей. При этом пользователи не должны мешать друг другу. Т.к. логической единицей работы для пользователя является транзакция, то работа СУБД должна быть организована так, чтобы у пользователя складывалось впечатление, что их транзакции выполняются независимо от транзакций других пользователей.
Простейший и очевидный способ обеспечить такую иллюзию у пользователя состоит в том, чтобы все поступающие транзакции выстраивать в единую очередь и выполнять строго по очереди. Такой способ не годится по очевидным причинам - теряется преимущество параллельной работы. Таким образом, транзакции необходимо выполнять одновременно, но так, чтобы результат был бы такой же, как если бы транзакции выполнялись по очереди. Трудность состоит в том, что если не предпринимать никаких специальных мер, то данные измененные одним пользователем могут быть изменены транзакцией другого пользователя раньше, чем закончится транзакция первого пользователя. В результате, в конце транзакции первый пользователь увидит не результаты своей работы, а неизвестно что.
Одним из способов (не единственным) обеспечить независимую параллельную работу нескольких транзакций является метод блокировок.
Работа транзакций в смеси
Транзакция рассматривается как последовательность элементарных атомарных операций. Атомарность отдельной элементарной операции состоит в том, что СУБД гарантирует, что, с точки зрения пользователя, будут выполнены два условия:
- Эта операция будет выполнена целиком или не выполнена вовсе (атомарность - все или ничего).
- Во время выполнения этой операции не выполняются никакие другие операции других транзакций (строгая очередность элементарных операций).
Например, элементарными операциями транзакции будут считывание страницы данных с диска или запись страницы данных на диск (страница данных - это минимальная единица для дисковых операций СУБД). Условие 2 на самом деле является именно логическим условием, т.к. реально система может выполнять несколько различных элементарных операций в один и тот же момент. Например, данные могут храниться на нескольких физически различных дисках и операции чтения-записи на эти диски могут выполняться одновременно.
Элементарные операции различных транзакций могут выполняться в произвольной очередности (конечно, внутри каждой транзакции последовательность элементарных операций этой транзакции является строго определенной). Например, если есть несколько транзакций, состоящих из последовательности операций элементарных:
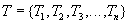 ,
,
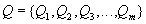 ,
,
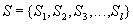
то реальная последовательность, в которой СУБД выполняет эти транзакции может быть, например, такой:
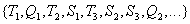 .
.
Определение 1. Набор из нескольких транзакций, элементарные операции которых чередуются друг с другом, называется смесью транзакций.
Определение 2. Последовательность, в которой выполняются элементарные операции заданного набора транзакций, называется графиком запуска набора транзакций.
Замечание. Очевидно, что для заданного набора транзакций может быть несколько (вообще говоря, достаточно много) различных графиков запуска.
Обеспечение изолированности пользователей, таким образом, сводится к выбору подходящего (в каком-то смысле правильного) графика запуска транзакций. Одновременно с этим график запуска должен быть оптимальным в некотором смысле, например, давать минимальное среднее время выполнения транзакций каждым пользователем.
Далее мы уточним понятие "правильного" графика и сделаем некоторые замечания об оптимальности.
Проблемы параллельной работы транзакций
Каким образом транзакции различных пользователей могут мешать друг другу? Различают три основные проблемы параллелизма:
- Проблема потери результатов обновления.
- Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание).
- Проблема несовместимого анализа.
Рассмотрим подробно эти проблемы.
Рассмотрим две транзакции, A и B, запускающиеся в соответствии с некоторыми графиками. Пусть транзакции работают с некоторыми объектами базы данных, например со строками таблицы. Операцию чтение строки  будем обозначать
будем обозначать 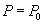 , где
, где 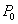 - прочитанное значение. Операцию записи значения
- прочитанное значение. Операцию записи значения 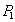 в строку будем обозначать
в строку будем обозначать 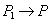 .
.
Проблема потери результатов обновления
Две транзакции по очереди записывают некоторые данные в одну и ту же строку и фиксируют изменения.
| Транзакция A |
Время |
Транзакция B |
| Чтение |
 |
--- |
| --- |
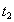 |
Чтение |
| Запись |
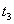 |
--- |
| --- |
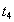 |
Запись 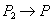 |
| Фиксация транзакции |
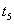 |
--- |
| --- |
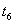 |
Фиксация транзакции |
| Потеря результата обновления |
|
|
Результат. После окончания обеих транзакций, строка содержит значение 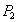 , занесенное более поздней транзакцией B. Транзакция A ничего не знает о существовании транзакции B, и естественно ожидает, что в строке содержится значение . Таким образом, транзакция A потеряла результаты своей работы.
, занесенное более поздней транзакцией B. Транзакция A ничего не знает о существовании транзакции B, и естественно ожидает, что в строке содержится значение . Таким образом, транзакция A потеряла результаты своей работы.
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Транзакция B изменяет данные в строке. После этого транзакция A читает измененные данные и работает с ними. Транзакция B откатывается и восстанавливает старые данные.
| Транзакция A |
Время |
Транзакция B |
| --- |
|
Чтение |
| --- |
|
Запись |
Чтение 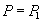 |
|
--- |
| Работа с прочитанными данными |
|
--- |
| --- |
|
Откат транзакции  |
| Фиксация транзакции |
|
--- |
| Работа с "грязными" данными |
|
|
С чем же работала транзакция A?
Результат. Транзакция A в своей работе использовала данные, которых нет в базе данных. Более того, транзакция A использовала данные, которых нет, и не было в базе данных! Действительно, после отката транзакции B, должна восстановиться ситуация, как если бы транзакция B вообще никогда не выполнялась. Таким образом, результаты работы транзакции A некорректны, т.к. она работала с данными, отсутствовавшими в базе данных.
Проблема несовместимого анализа
Проблема несовместимого анализа включает несколько различных вариантов:
- Неповторяемое считывание.
- Фиктивные элементы (фантомы).
- Собственно несовместимый анализ.
Неповторяемое считывание
Транзакция A дважды читает одну и ту же строку. Между этими чтениями вклинивается транзакция B, которая изменяет значения в строке.
| Транзакция A |
Время |
Транзакция B |
| Чтение |
|
--- |
| --- |
|
Чтение |
| --- |
|
Запись |
| --- |
|
Фиксация транзакции |
| Повторное чтение |
|
--- |
| Фиксация транзакции |
|
--- |
| Неповторяемое считывание |
|
|
Транзакция A ничего не знает о существовании транзакции B, и, т.к. сама она не меняет значение в строке, то ожидает, что после повторного чтения значение будет тем же самым.
Результат. Транзакция A работает с данными, которые, с точки зрения транзакции A, самопроизвольно изменяются.
Фиктивные элементы (фантомы)
Эффект фиктивных элементов несколько отличается от предыдущих транзакций тем, что здесь за один шаг выполняется достаточно много операций - чтение одновременно нескольких строк, удовлетворяющих некоторому условию.
Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора.
| Транзакция A |
Время |
Транзакция B |
Выборка строк, удовлетворяющих условию 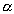 . .
(Отобрано n строк) |
|
--- |
| --- |
|
Вставка новой строки, удовлетворяющей условию . |
| --- |
|
Фиксация транзакции |
Выборка строк, удовлетворяющих условию .
(Отобрано n+1 строк) |
|
--- |
| Фиксация транзакции |
|
--- |
| Появились строки, которых раньше не было |
|
|
Транзакция A ничего не знает о существовании транзакции B, и, т.к. сама она не меняет ничего в базе данных, то ожидает, что после повторного отбора будут отобраны те же самые строки.
Результат. Транзакция A в двух одинаковых выборках строк получила разные результаты.
Собственно несовместимый анализ
Эффект собственно несовместимого анализа также отличается от предыдущих примеров тем, что в смеси присутствуют две транзакции - одна длинная, другая короткая.
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
| Транзакция A |
Время |
Транзакция B |
Чтение счета 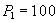 и суммирование. и суммирование.
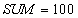 |
|
--- |
| --- |
|
Снятие денег со счета 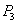 . .
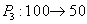 |
| --- |
|
Помещение денег на счет 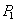 . .
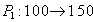 |
| --- |
|
Фиксация транзакции |
Чтение счета 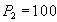 и суммирование. и суммирование.
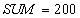 |
|
--- |
Чтение счета 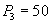 и суммирование. и суммирование.
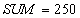 |
|
--- |
| Фиксация транзакции |
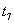 |
--- |
| Сумма $250 по всем счетам неправильная - должно быть $300 |
|
|
Результат. Хотя транзакция B все сделала правильно - деньги переведены без потери, но в результате транзакция A подсчитала неверную общую сумму.
Т.к. транзакции по переводу денег идут обычно непрерывно, то в данной ситуации следует ожидать, что главный бухгалтер никогда не узнает, сколько же денег в банке.
Конфликты между транзакциями
Итак, анализ проблем параллелизма показывает, что если не предпринимать специальных мер, то при работе в смеси нарушается свойство (И) транзакций - изолированность. Транзакции реально мешают друг другу получать правильные результаты.
Однако не всякие транзакции мешают друг другу. Очевидно, что транзакции не мешают друг другу, если они обращаются к разным данным или выполняются в разное время.
Определение 3. Транзакции называются конкурирующими, если они пересекаются по времени и обращаются к одним и тем же данным.
В результате конкуренции за данными между транзакциями возникают конфликты доступа к данным. Различают следующие виды конфликтов:
- W-W (Запись - Запись). Первая транзакция изменила объект и не закончилась. Вторая транзакция пытается изменить этот объект. Результат - потеря обновления.
- R-W (Чтение - Запись). Первая транзакция прочитала объект и не закончилась. Вторая транзакция пытается изменить этот объект. Результат - несовместимый анализ (неповторяемое считывание).
- W-R (Запись - Чтение). Первая транзакция изменила объект и не закончилась. Вторая транзакция пытается прочитать этот объект. Результат - чтение "грязных" данных.
Конфликты типа R-R (Чтение - Чтение) отсутствуют, т.к. данные при чтении не изменяются.
Другие проблемы параллелизма (фантомы и собственно несовместимый анализ) являются более сложными, т.к. принципиальное отличие их в том, что они не могут возникать при работе с одним объектом. Для возникновения этих проблем требуется, чтобы транзакции работали с целыми наборами данных.
Определение 4. График запуска набора транзакций называется последовательным, если транзакции выполняются строго по очереди, т.е. элементарные операции транзакций не чередуются друг с другом.
Определение 5. Если график запуска набора транзакций содержит чередующиеся элементарные операции транзакций, то такой график называется чередующимся.
При выполнении последовательного графика гарантируется, что транзакции выполняются правильно, т.е. при последовательном графике транзакции не "чувствуют" присутствия друг друга.
Определение 6. Два графика называются эквивалентными, если при их выполнении будет получен один и тот же результат, независимо от начального состояния базы данных.
Определение 7. График запуска транзакции называется верным (сериализуемым), если он эквивалентен какому-либо последовательному графику.
Замечание. При выполнении двух различных последовательных (а, следовательно, верных) графиков, содержащих один и тот же набор транзакций, могут быть получены различные результаты. Действительно, пусть транзакция A заключается в действии "Сложить X с 1", а транзакция B - "Удвоить X". Тогда последовательный график {A, B} даст результат 2(X+1), а последовательный график {B, A} даст результат 2X+1. Таким образом, может существовать несколько верных графиков запусков транзакций, приводящих к разным результатам при одном и том же начальном состоянии базы данных.
Задача обеспечения изолированной работы пользователей не сводится просто к нахождению правильных (сериальных) графиков запусков транзакций. Если бы этого было достаточно, то лучшим был бы простейший способ сериализации - ставить транзакции в общую очередь по мере их поступления и выполнять строго последовательно. Таким способом автоматически будет получен правильный (сериальный) график. Проблема в том, что этот график будет неоптимальным с точки зрения общей производительности системы. Получается ситуация, в которой борются противоположные силы - с одной стороны, стремление обеспечить сериальность за счет ухудшения общей эффективности работы, с другой стороны, стремление улучшить общую эффективность за счет ухудшения сериальности.
Один крайний случай (выполнение транзакций по очереди) мы рассмотрели. Рассмотрим другой крайний случай - попытаемся достичь оптимального графика - т.е. графика с максимальной эффективностью выполнения транзакций. Для этого сначала нужно уточнить понятие "оптимальность". С каждым возможным графиком запуска транзакций мы можем связать значение некоей стоимостной функции. В качестве стоимостной функции можно взять, например, суммарное время выполнения всех транзакций в наборе. Время выполнения одной транзакции считается от момента, когда транзакция возникла и до момента, когда транзакция выполнила свою последнюю элементарную операцию. Это время складывается из следующих компонентов:
- Время ожидания начала транзакции - то время, которое проходит от момента, когда транзакция возникла до момента, когда началась реально выполняться ее первая элементарная операция.
- Сумма времен выполнения элементарных операций транзакции.
- Сумма времен всех элементарных операций других транзакций, вклинившихся между элементарными операциями транзакции.
Оптимальным будет график, дающий минимум стоимостной функции. Очевидно, оптимальность графика запуска зависит от выбора стоимостной функции, т.е. график, оптимальный с точки зрения одних критериев (например, с точки зрения приведенной функции стоимости) не будет оптимальным с точки зрения других критериев (например, с точки зрения достижения максимально быстрого начала выполнения каждой транзакции).
Рассмотрим следующую гипотетическую ситуацию. Предположим, что нам заранее на некоторый промежуток времени наперед известно, какие транзакции в какие моменты поступят, т.е. заранее известна вся будущая смесь транзакций и моменты поступления каждой транзакции:
Транзакция 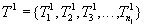 поступит в момент
поступит в момент 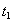 .
.
Транзакция 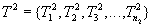 поступит в момент
поступит в момент 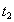 .
.
…
Транзакция 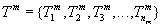 поступит в момент
поступит в момент 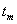 .
.
В этом случае, т.к. набор всех транзакций заранее известен, теоретически можно перебрать все возможные варианты графиков запусков (их конечное число, хотя и очень большое), и выбрать из них те графики, которые, во-первых, правильные, а во-вторых, оптимальны по выбранному критерию. В этом случае оптимальный график запуска транзакций достижим.
В реальной ситуации, однако, неизвестно не только какие транзакции будут поступать в какие моменты времени, но и неизвестна длительность периода времени, охватывающего набор транзакций. Реально, система может непрерывно работать несколько дней или месяцев и в этом случае набором транзакций будет набор всех транзакций за этот период. С другой стороны, прекращение работы сервера может произойти в любой момент либо по команде администратора системы, либо в результате сбоя. Необходимо, следовательно, чтобы система работала так, чтобы к любому моменту времени набор выполненных и выполняющихся в этот момент транзакций был бы правильным и не слишком далек от оптимального.
Т.к. транзакции не мешают друг другу, если они обращаются к разным данным или выполняются в разное время, то имеется два способа разрешить конкуренцию между поступающими в произвольные моменты транзакциями:
- "Притормаживать" некоторые из поступающих транзакций настолько, насколько это необходимо для обеспечения правильности смеси транзакций в каждый момент времени (т.е. обеспечить, чтобы конкурирующие транзакции выполнялись в разное время).
- Предоставить конкурирующим транзакциям "разные" экземпляры данных (т.е. обеспечить, чтобы конкурирующие транзакции работали с разными версиями данными).
Первый метод - "притормаживание" транзакций - реализуется путем использованием блокировок различных видов или метода временных меток.
Второй метод - предоставление разных версий данных - реализуется путем использованием данных из журнала транзакций.
Блокировки
Основная идея блокировок заключается в том, что если для выполнения некоторой транзакции необходимо, чтобы некоторый объект не изменялся без ведома этой транзакции, то этот объект должен быть заблокирован, т.е. доступ к этому объекту со стороны других транзакций ограничивается на время выполнения транзакции, вызвавшей блокировку.
Различают два типа блокировок:
- Монопольные блокировки (X-блокировки, X-locks - eXclusive locks) - блокировки без взаимного доступа (блокировка записи).
- Разделяемые блокировки (S-блокировки, S-locks - Shared locks) - блокировки с взаимным доступом (блокировка чтения).
Если транзакция A блокирует объект при помощи X-блокировки, то всякий доступ к этому объекту со стороны других транзакций отвергается.
Если транзакция A блокирует объект при помощи S-блокировки, то
- запросы со стороны других транзакций на X-блокировку этого объекта будут отвергнуты,
- запросы со стороны других транзакций на S-блокировку этого объекта будут приняты.
Правила взаимного доступа к заблокированным объектам можно представить в виде следующей матрицы совместимости блокировок. Если транзакция A наложила блокировку на некоторый объект, а транзакция B после этого пытается наложить блокировку на этот же объект, то успешность блокирования транзакцией B объекта описывается таблицей:
| |
Транзакция B пытается наложить блокировку: |
| Транзакция A наложила блокировку: |
S-блокировку |
X-блокировку |
| S-блокировку |
Да |
НЕТ
(Конфликт
R-W) |
| X-блокировку |
НЕТ
(Конфликт
W-R) |
НЕТ
(Конфликт
W-W) |
Таблица 1 Матрица совместимости S- и X-блокировок
Три случая, когда транзакция B не может блокировать объект, соответствуют трем видам конфликтов между транзакциями.
Доступ к объектам базы данных на чтение и запись должен осуществляться в соответствии со следующим протоколом доступа к данным:
- Прежде чем прочитать объект, транзакция должна наложить на этот объект S-блокировку.
- Прежде чем обновить объект, транзакция должна наложить на этот объект X-блокировку. Если транзакция уже заблокировала объект S-блокировкой (для чтения), то перед обновлением объекта S-блокировка должна быть заменена X-блокировкой.
- Если блокировка объекта транзакцией B отвергается оттого, что объект уже заблокирован транзакцией A, то транзакция B переходит в состояние ожидания. Транзакция B будет находиться в состоянии ожидания до тех пор, пока транзакция A не снимет блокировку объекта.
- X-блокировки, наложенные транзакцией A, сохраняются до конца транзакции A.
Решение проблем параллелизма при помощи блокировок
Рассмотрим, как будут себя вести транзакции, вступающие в конфликт при доступе к данным, если они подчиняются протоколу доступа к данным.
Проблема потери результатов обновления
Две транзакции по очереди записывают некоторые данные в одну и ту же строку и фиксируют изменения.
| Транзакция A |
Время |
Транзакция B |
S-блокировка 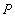 - успешна - успешна |
|
--- |
| Чтение |
|
--- |
| --- |
|
S-блокировка - успешна |
| --- |
|
Чтение |
| X-блокировка - отвергается |
|
--- |
| Ожидание… |
|
X-блокировка - отвергается |
| Ожидание… |
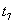 |
Ожидание… |
| Ожидание… |
|
Ожидание… |
Обе транзакции успешно накладывают S-блокировки и читают объект . Транзакция A пытается наложить X-блокирокировку для обновления объекта . Блокировка отвергается, т.к. объект уже S-заблокирован транзакцией B. Транзакция A переходит в состояние ожидания до тех пор, пока транзакция B не освободит объект. Транзакция B, в свою очередь, пытается наложить X-блокирокировку для обновления объекта . Блокировка отвергается, т.к. объект уже S-заблокирован транзакцией A. Транзакция B переходит в состояние ожидания до тех пор, пока транзакция A не освободит объект.
Результат. Обе транзакции ожидают друг друга и не могут продолжаться. Возникла ситуация тупика.
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Транзакция B изменяет данные в строке. После этого транзакция A читает измененные данные и работает с ними. Транзакция B откатывается и восстанавливает старые данные.
Результат. Транзакция A притормозилась до окончания (отката) транзакции B. После этого транзакция A продолжила работу в обычном режиме и работала с правильными данными. Конфликт разрешен за счет некоторого увеличения времени работы транзакции A (потрачено время на ожидание снятия блокировки транзакцией B).
Проблема несовместимого анализа
Неповторяемое считывание
Транзакция A дважды читает одну и ту же строку. Между этими чтениями вклинивается транзакция B, которая изменяет значения в строке.
| Транзакция A |
Время |
Транзакция B |
| S-блокировка - успешна |
|
--- |
| Чтение |
|
--- |
| --- |
|
X-блокировка - отвергается |
| --- |
|
Ожидание… |
Повторное чтение 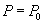 |
|
Ожидание… |
Фиксация транзакции
(Блокировка снимается) |
|
Ожидание… |
| --- |
|
X-блокировка - успешна |
| --- |
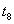 |
Запись |
| --- |
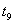 |
Фиксация транзакции
(Блокировка снимается) |
| Все правильно |
|
|
Результат. Транзакция B притормозилась до окончания транзакции A. В результате транзакция A дважды читает одни и те же данные правильно. После окончания транзакции A, транзакция B продолжила работу в обычном режиме.
Фиктивные элементы (фантомы)
Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора.
| Транзакция A |
Время |
Транзакция B |
S-блокировка строк, удовлетворяющих условию .
(Заблокировано n строк) |
|
--- |
Выборка строк, удовлетворяющих условию .
(Отобрано n строк) |
|
--- |
| --- |
|
Вставка новой строки, удовлетворяющей условию . |
| --- |
|
Фиксация транзакции |
S-блокировка строк, удовлетворяющих условию .
(Заблокировано n+1 строка) |
|
--- |
Выборка строк, удовлетворяющих условию .
(Отобрано n+1 строк) |
|
--- |
| Фиксация транзакции |
|
--- |
| Появились строки, которых раньше не было |
|
|
Результат. Блокировка на уровне строк не решила проблему появления фиктивных элементов.
Собственно несовместимый анализ
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
Результат. Обе транзакции ожидают друг друга и не могут продолжаться. Возникла ситуация тупика.
Разрешение тупиковых ситуаций
Итак, при использовании протокола доступа к данным с использованием блокировок часть проблем разрешилось (не все), но возникла новая проблема - тупики:
- Проблема потери результатов обновления - возник тупик.
- Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание) - проблема разрешилась.
- Неповторяемое считывание - проблема разрешилась.
- Появление фиктивных элементов - проблема не разрешилась.
- Проблема несовместимого анализа - возник тупик.
Общий вид тупика (dead locks) следующий:
| Транзакция A |
Время |
Транзакция B |
Блокировка объекта  - успешна - успешна |
|
--- |
| --- |
|
Блокировка объекта  -успешна -успешна |
| Блокировка объекта - конфликтует с блокировкой, наложенной транзакцией B |
|
--- |
| Ожидание… |
|
Блокировка объекта - конфликтует с блокировкой, наложенной транзакцией A |
| Ожидание… |
|
Ожидание… |
| Ожидание… |
|
Ожидание… |
Как видно, ситуация тупика может возникать при наличии не менее двух транзакций, каждая из которых выполняет не менее двух операций. На самом деле в тупике может участвовать много транзакций, ожидающих друг друга.
Т.к. нормального выхода из тупиковой ситуации нет, то такую ситуацию необходимо распознавать и устранять. Методом разрешения тупиковой ситуации является откат одной из транзакций (транзакции-жертвы) так, чтобы другие транзакции продолжили свою работу. После разрешения тупика, транзакцию, выбранную в качестве жертвы можно повторить заново.
Можно представить два принципиальных подхода к обнаружению тупиковой ситуации и выбору транзакции-жертвы:
- СУБД не следит за возникновением тупиков. Транзакции сами принимают решение, быть ли им жертвой.
- За возникновением тупиковой ситуации следит сама СУБД, она же принимает решение, какой транзакцией пожертвовать.
Первый подход характерен для так называемых настольных СУБД (FoxPro и т.п.). Этот метод является более простым и не требует дополнительных ресурсов системы. Для транзакций задается время ожидания (или число попыток), в течение которого транзакция пытается установить нужную блокировку. Если за указанное время (или после указанного числа попыток) блокировка не завершается успешно, то транзакция откатывается (или генерируется ошибочная ситуация). За простоту этого метода приходится платить тем, что транзакции-жертвы выбираются, вообще говоря, случайным образом. В результате из-за одной простой транзакции может откатиться очень дорогая транзакция, на выполнение которой уже потрачено много времени и ресурсов системы.
Второй способ характерен для промышленных СУБД (ORACLE, MS SQL Server и т.п.). В этом случае система сама следит за возникновением ситуации тупика, путем построения (или постоянного поддержания) графа ожидания транзакций. Граф ожидания транзакций - это ориентированный двудольный граф, в котором существует два типа вершин - вершины, соответствующие транзакциям, и вершины, соответствующие объектам захвата. Ситуация тупика возникает, если в графе ожидания транзакций имеется хотя бы один цикл. Одну из транзакций, попавших в цикл, необходимо откатить, причем, система сама может выбрать эту транзакцию в соответствии с некоторыми стоимостными соображениями (например, самую короткую, или с минимальным приоритетом и т.п.).
Преднамеренные блокировки
Как видно из анализа поведения транзакций, при использовании протокола доступа к данным не решается проблема фантомов. Это происходит оттого, что были рассмотрены только блокировки на уровне строк. Можно рассматривать блокировки и других объектов базы данных:
- Блокировка самой базы данных.
- Блокировка файлов базы данных.
- Блокировка таблиц базы данных.
- Блокировка страниц (Единиц обмена с диском, обычно 2-16 Кб. На одной странице содержится несколько строк одной или нескольких таблиц).
- Блокировка отдельных строк таблиц.
- Блокировка отдельных полей.
Кроме того, можно блокировать индексы, заголовки таблиц или другие объекты.
Чем крупнее объект блокировки, тем меньше возможностей для параллельной работы. Достоинством блокировок крупных объектов является уменьшение накладных расходов системы и решение проблем, не решаемых с использованием блокировок менее крупных объектов. Например, использование монопольной блокировки на уровне таблицы, очевидно, решает проблему фантомов.
Современные СУБД, как правило, поддерживают минимальный уровень блокировки на уровне строк или страниц. (В старых версиях настольной СУБД Paradox поддерживалась блокировка на уровне отдельных полей.).
При использовании блокировок объектов разной величины возникает проблема обнаружения уже наложенных блокировок. Если транзакция A пытается заблокировать таблицу, то необходимо иметь информацию, не наложены ли уже блокировки на уровне строк этой таблицы, несовместимые с блокировкой таблицы. Для решения этой проблемы используется протокол преднамеренных блокировок, являющийся расширением протокола доступа к данным. Суть этого протокола в том, что перед тем, как наложить блокировку на объект (например, на строку таблицы), необходимо наложить специальную преднамеренную блокировку (блокировку намерения) на объекты, в состав которых входит блокируемый объект - на таблицу, содержащую строку, на файл, содержащий таблицу, на базу данных, содержащую файл. Тогда наличие преднамеренной блокировки таблицы будет свидетельствовать о наличии блокировки строк таблицы и для другой транзакции, пытающейся блокировать целую таблицу не нужно проверять наличие блокировок отдельных строк. Более точно, вводятся следующие новые типы блокировок:
- Преднамеренная блокировка с возможностью взаимного доступа (IS-блокировка - Intent Shared lock). Накладывается на некоторый составной объект T и означает намерение блокировать некоторый входящий в T объект в режиме S-блокировки. Например, при намерении читать строки из таблицы T, эта таблица должна быть заблокирована в режиме IS (до этого в таком же режиме должен быть заблокирован файл).
- Преднамеренная блокировка без взаимного доступа (IX-блокировка - Intent eXclusive lock). Накладывается на некоторый составной объект T и означает намерение блокировать некоторый входящий в T объект в режиме X-блокировки. Например, при намерении удалять или модифицировать строки из таблицы T эта таблица должна быть заблокирована в режиме IX (до этого в таком же режиме должен быть заблокирован файл).
- Преднамеренная блокировка как с возможностью взаимного доступа, так и без него (SIX-блокировка - Shared Intent eXclusive lock). Накладывается на некоторый составной объект T и означает разделяемую блокировку всего этого объекта с намерением впоследствии блокировать какие-либо входящие в него объекты в режиме X-блокировок. Например, если выполняется длинная операция просмотра таблицы с возможностью удаления некоторых просматриваемых строк, то можно заблокировать эту таблицу в режиме SIX (до этого захватить файл в режиме IS).
IS, IX и SIX-блокировки должны накладываться на сложные объекты базы данных (таблицы, файлы). Кроме того, на сложные объекты могут накладываться и блокировки типов S и X. Для сложных объектов (например, для таблицы базы данных) таблица совместимости блокировок имеет следующий вид:
| |
Транзакция B пытается наложить на таблицу блокировку: |
| Транзакция A наложила на таблицу блокировку: |
IS |
S |
IX |
SIX |
X |
| IS |
Да |
Да |
Да |
Да |
Нет |
| S |
Да |
Да |
Нет |
Нет |
Нет |
| IX |
Да |
Нет |
Да |
Нет |
Нет |
| SIX |
Да |
Нет |
Нет |
Нет |
Нет |
| X |
Нет |
Нет |
Нет |
Нет |
Нет |
Таблица 2 Расширенная таблица совместимости блокировок
Более точная формулировка протокола преднамеренных блокировок для доступа к данным выглядит следующим образом:
- При задании X-блокировки для сложного объекта неявным образом задается X-блокировка для всех дочерних объектов этого объекта.
- При задании S- или SIX-блокировки для сложного объекта неявным образом задается S-блокировка для всех дочерних объектов этого объекта.
- Прежде чем транзакция наложит S- или IS-блокировку на заданный объект, она должна задать IS-блокировку (или более сильную) по крайней мере для одного родительского объекта этого объекта.
- Прежде чем транзакция наложит X-, IX- или SIX-блокировку на заданный объект, она должна задать IX-блокировку (или более сильную) для всех родительских объектов этого объекта.
- Прежде чем для данной транзакции будет отменена блокировка для данного объекта, должны быть отменены все блокировки для дочерних объектов этого объекта.
Понятие относительной силы блокировок можно описать при помощи следующей диаграммы приоритета (сверху - более сильные блокировки, снизу - более слабые):
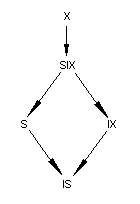
Таблица 3 Диаграмма приоритета блокировок
Замечание. Протокол преднамеренных блокировок не определяет однозначно, какие блокировки должны быть наложены на родительский объект при блокировании дочернего объекта. Например, при намерении задать S-блокировку строки таблицы, на таблицу, включающую эту строку, можно наложить любую из блокировок типа IS, S, IX, SIX, X. При намерении задать X-блокировку строки, на таблицу можно наложить любую из блокировок типа IX, SIX, X.
Посмотрим, как разрешается проблема фиктивных элементов (фантомов) с использованием протокола преднамеренных блокировок для доступа к данным.
Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора.
Транзакция B перед попыткой вставить новую строку должна наложить на таблицу IX-блокировку, или более сильную (SIX или X). Тогда транзакция A, для предотвращения возможного конфликта, должна наложить такую блокировку на таблицу, которая не позволила бы транзакции B наложить IX-блокировку. По таблице совместимости блокировок определяем, что транзакция A должна наложить на таблицу S, или SIX, или X-блокировку. (Блокировки IS недостаточно, т.к. эта блокировка позволяет транзакции B наложить IX-блокировку для последующей вставки строк).
| Транзакция A |
Время |
Транзакция B |
| S-блокировка таблицы (с целью потом блокировать строки) - успешна |
|
--- |
S-блокировка строк, удовлетворяющих условию .
(Заблокировано n строк) |
|
--- |
Выборка строк, удовлетворяющих условию .
(Отобрано n строк) |
|
--- |
| --- |
|
IX-блокировка таблицы (с целью потом вставлять строки) - отвергается из-за конфликта с S-блокировкой, наложенной транзакцией A |
| --- |
|
Ожидание… |
| --- |
|
Ожидание… |
S-блокировка строк, удовлетворяющих условию .
(Заблокировано n строк) |
|
Ожидание… |
Выборка строк, удовлетворяющих условию .
(Отобрано n строк) |
|
Ожидание… |
| Фиксация транзакции - блокировки снимаются |
|
Ожидание… |
| --- |
 |
IX-блокировка таблицы (с целью потом вставлять строки) - успешна |
| --- |
 |
Вставка новой строки, удовлетворяющей условию . |
| --- |
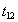 |
Фиксация транзакции |
Транзакция A дважды читает один и тот же набор строк
Все правильно |
|
|
Результат. Проблема фиктивных элементов (фантомов) решается, если транзакция A использует преднамеренную S-блокировку или более сильную.
Замечание. Т.к. транзакция A собирается только читать строки таблицы, то минимально необходимым условием в соответствии с протоколом преднамеренных блокировок является преднамеренная IS-блокировка таблицы. Однако этот тип блокировки не предотвращает появление фантомов. Таким образом, транзакцию A можно запускать с разными уровнями изолированности - предотвращая или допуская появление фантомов. Причем, оба способа запуска соответствуют протоколу преднамеренных блокировок для доступа к данным.
Предикатные блокировки
Другим способом блокирования является блокировка не объектов базы данных, а условий, которым могут удовлетворять объекты. Такие блокировки называются предикатными блокировками.
Поскольку любая операция над реляционной базой данных задается некоторым условием (т.е. в ней указывается не конкретный набор объектов базы данных, над которыми нужно выполнить операцию, а условие, которому должны удовлетворять объекты этого набора), то удобным способом было бы S или X-блокирование именно этого условия. Однако при попытке использовать этот метод в реальной СУБД возникает трудность определения совместимости различных условий. Действительно, в языке SQL допускаются условия с подзапросами и другими сложными предикатами. Проблема совместимости сравнительно легко решается для случая простых условий, имеющих вид:
{Имя атрибута {= | <> | > | >= | < | <=} Значение}
[{OR | AND} {Имя атрибута {= | <> | > | >= | < | <=} Значение}.,..]
Проблема фиктивных элементов (фантомов) легко решается с использованием предикатных блокировок, т.к. вторая транзакция не может вставить новые строки, удовлетворяющие уже заблокированному условию.
Заметим, что блокировка всей таблицы в каком-либо режиме фактически есть предикатная блокировка, т.к. каждая таблица имеет предикат, определяющий какие строки содержатся в таблице и блокировка таблицы есть блокировка предиката этой таблицы.
Метод временных меток
Альтернативный метод сериализации транзакций, хорошо работающий в условиях редких конфликтов транзакций и не требующий построения графа ожидания транзакций основан на использовании временных меток.
Основная идея метода состоит в следующем: если транзакция A началась раньше транзакции B, то система обеспечивает такой режим выполнения, как если бы A была целиком выполнена до начала B.
Для этого каждой транзакции T предписывается временная метка t, соответствующая времени начала T. При выполнении операции над объектом r базы данных транзакция T помечает его своей временной меткой и типом операции (чтение или изменение).
Перед выполнением операции над объектом r транзакция B выполняет следующие действия:
- Проверяет, не закончилась ли транзакция A, пометившая этот объект. Если A закончилась, B помечает объект r своей временной меткой и выполняет операцию.
- Если транзакция A не завершилась, то B проверяет конфликтность операций. Если операции неконфликтны, при объекте r остается или проставляется временная метка с меньшим значением (более ранняя), и транзакция B выполняет свою операцию.
- Если операции B и A конфликтуют, то если t(A) > t(B) (т.е. транзакция A является более "молодой", чем B), то транзакция A откатывается и, получив новую временную метку, начинается заново. Транзакция B продолжает работу.
- Если же t(A) < t(B) (A "старше" B), то транзакция B откатывается и, получив новую временную метку, начинается заново. Транзакция A продолжает работу.
В итоге система обеспечивает такую работу, при которой при возникновении конфликтов всегда откатывается более молодая транзакция (начавшаяся позже).
Очевидным недостатком метода временных меток является то, что может откатиться более дорогая транзакция, начавшаяся позже более дешевой.
К другим недостаткам метода временных меток относятся потенциально более частые откаты транзакций, чем в случае использования блокировок. Это связано с тем, что конфликтность транзакций определяется более грубо.
Механизм выделения версий данных
Использование блокировок гарантирует сериальность планов выполнения смеси транзакций за счет общего замедления работы - конфликтующие транзакции ожидают, когда транзакция, первой заблокировавшая некоторый объект, не освободит его. Без блокировок не обойтись, если все транзакции изменяют данные. Но если в смеси транзакций присутствуют как транзакции, изменяющие данные, так и только читающие данные, можно применить альтернативный механизм обеспечения сериальности, свободный от недостатков метода блокировок. Этот метод состоит в том, что транзакциям, читающим данные, предоставляется как бы "своя" версия данных, имевшаяся в момент начала читающей транзакции. При этом транзакция не накладывает блокировок на читаемые данные, и, поэтому, не блокирует другие транзакции, изменяющие данные. Такой механизм называется механизм выделения версий и заключается в использовании журнала транзакций для генерации разных версий данных.
Журнал транзакций предназначен для выполнения операции отката при неуспешном выполнении транзакции или для восстановления данных после сбоя системы. Журнал транзакций содержит старые копии данных, измененных транзакциями.
Кратко суть метода состоит в следующем:
- Для каждой транзакции (или запроса) запоминается текущий системный номер (SCN - System Current Number). Чем позже начата транзакция, тем больше ее SCN.
- При записи страниц данных на диск фиксируется SCN транзакции, производящей эту запись. Этот SCN становится текущим системным номером страницы данных.
- Транзакции, только читающие данные не блокируют ничего в базе данных.
- Если транзакция A читает страницу данных, то SCN транзакции A сравнивается с SCN читаемой страницы данных.
- Если SCN страницы данных меньше или равен SCN транзакции A, то транзакция A читает эту страницу.
- Если SCN страницы данных больше SCN транзакции A, то это означает, что некоторая транзакция B, начавшаяся позже транзакции A, успела изменить или сейчас изменяет данные страницы. В этом случае транзакция A просматривает журнал транзакция назад в поиске первой записи об изменении нужной страницы данных с SCN меньшим, чем SCN транзакции A. Найдя такую запись, транзакция A использует старый вариант данных страницы.
Рассмотрим, как решается проблема несовместного анализа с использованием механизма выделения версий.
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
| Транзакция A |
Время |
Транзакция B |
Проверка SCN счета - SCN транзакции больше SCN счета.
Чтение счета без наложения блокировки и суммирование.
|
|
--- |
| --- |
|
X-блокировка счета 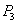 - успешна - успешна |
| --- |
|
Снятие денег со счета .
|
| --- |
|
X-блокировка счета 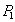 - успешна - успешна |
| --- |
|
Помещение денег на счет .
|
| --- |
|
Фиксация транзакции
(Снятие блокировок) |
Проверка SCN счета  - SCN транзакции больше SCN счета. - SCN транзакции больше SCN счета.
Чтение счета без наложения блокировка и суммирование.
|
|
--- |
Проверка SCN счета 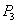 - SCN транзакции МЕНЬШЕ SCN счета. - SCN транзакции МЕНЬШЕ SCN счета.
Чтение старого варианта счета 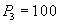 и суммирование. и суммирование.
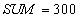 |
|
--- |
| Фиксация транзакции |
|
--- |
| Сумма на счетах посчитана правильно. |
|
|
Результат. Транзакция A, начавшаяся первой не тормозит конкурирующую транзакцию B. При обнаружении конфликта (чтение транзакцией A измененного счета 3), транзакции A предоставляется своя версия данных, которая была на момент начала транзакции A.
Теорема Есварана о сериализуемости
Концепция способности к упорядочению была впервые предложена Есвараном [50].
В этой работе был предложен протокол двухфазной блокировки:
- Перед выполнение каких-либо операций с некоторым объектом, транзакция должна заблокировать этот объект.
- После снятия блокировки, транзакция не должна накладывать никаких других блокировок.
Транзакции, используемые в этом протоколе, не различаются по типам и считаются монопольными. Описанные выше протоколы доступа к данным с использованием S- и X-блокировок и протокол преднамеренных блокировок являются модификациями протокола двухфазной блокировки для случая, когда блокировки имеют различные типы.
Есвараном сформулирована следующая теорема:
Теорема Есварана. Если все транзакции в смеси подчиняются протоколу двухфазной блокировки, то для всех чередующихся графиков запуска существует возможность упорядочения.
Протокол называется двухфазным, потому что он характеризуется двумя фазами:
- 1 фаза - нарастание блокировок. Во время этой фазы накладываются блокировки, и производится работа с заблокированными объектами.
- 2 фаза - снятие блокировок. Во время этой фазы блокировки только снимаются. Работа с ранее заблокированными данными может продолжаться.
Работа транзакции может выглядеть приблизительно, как на рисунке:
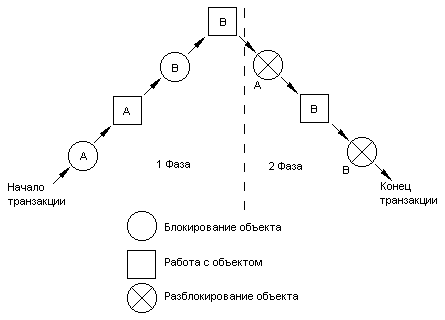
Рисунок 1 Работа транзакции по протоколу двухфазной блокировки
На следующем рисунке показан пример транзакции, не подчиняющийся протоколу двухфазной блокировки:
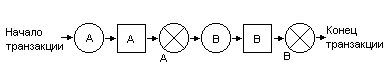
Рисунок 2 Транзакция, не подчиняющаяся протоколу двухфазной блокировки
На практике, как правило, вторая фаза сводится к одной операции завершения транзакции (или отката транзакции) с одновременным снятием всех блокировок.
Если некоторая транзакция A не подчиняется протоколу двухфазной блокировки (и, следовательно, состоит не менее чем из двух операция блокирования и разблокирования), то всегда можно построить другую транзакцию B, которая при чередующемся выполнении вместе с A приводит к графику, не подлежащему упорядочению и неверному.
Реализация изолированности транзакций средствами SQL
Уровни изоляции
Стандарт SQL не предусматривает понятие блокировок для реализации сериализуемости смеси транзакций. Вместо этого вводится понятие уровней изоляции. Этот подход обеспечивает необходимые требования к изолированности транзакций, оставляя возможность производителям различных СУБД реализовывать эти требования своими способами (в частности, с использованием блокировок или выделением версий данных).
Стандарт SQL предусматривает 4 уровня изоляции:
- READ UNCOMMITTED - уровень незавершенного считывания.
- READ COMMITTED - уровень завершенного считывания.
- REPEATABLE READ - уровень повторяемого считывания.
- SERIALIZABLE - уровень способности к упорядочению.
Если все транзакции выполняются на уровне способности к упорядочению (принятом по умолчанию), то чередующееся выполнение любого множества параллельных транзакций может быть упорядочено. Если некоторые транзакции выполняются на более низких уровнях, то имеется множество способов нарушить способность к упорядочению. В стандарте SQL выделены три особых случая нарушения способности к упорядочению, фактически именно те, которые были описаны выше как проблемы параллелизма:
- Неаккуратное считывание ("Грязное" чтение, незафиксированная зависимость).
- Неповторяемое считывание (Частный случай несовместного анализа).
- Фантомы (Фиктивные элементы - частный случай несовместного анализа).
Потеря результатов обновления стандартом SQL не допускается, т.е. на самом низком уровне изолированности транзакции должны работать так, чтобы не допустить потери результатов обновления.
Различные уровни изоляции определяются по возможности или исключению этих особых случаев нарушения способности к упорядочению. Эти определения описываются следующей таблицей:
| Уровень изоляции |
Неаккуратное считывание |
Неповторяемое считывание |
Фантомы |
| READ UNCOMMITTED |
Да |
Да |
Да |
| READ COMMITTED |
Нет |
Да |
Да |
| REPEATABLE READ |
Нет |
Нет |
Да |
| SERIALIZABLE |
Нет |
Нет |
Нет |
Таблица 4 Уровни изоляции стандарта SQL
Синтаксис операторов SQL, определяющих уровни изоляции
Уровень изоляции транзакции задается следующим оператором:
SET TRANSACTION {ISOLATION LEVEL
{READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SERIALIZABLE}
| {READ ONLY | READ WRITE}}.,..
Этот оператор определяет режим выполнения следующей транзакции, т.е. этот оператор не влияет на изменение режима той транзакции, в которой он подается. Обычно, выполнение оператора SET TRANSACTION выделяется как отдельная транзакция:
… (предыдущая транзакция выполняется со своим уровнем изоляции)
COMMIT;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
COMMIT;
… (следующая транзакция выполняется с уровнем изоляции REPEATABLE READ)
Если задано предложение ISOLATION LEVEL, то за ним должно следовать один из параметров, определяющих уровень изоляции.
Кроме того, можно задать признаки READ ONLY или READ WRITE. Если указан признак READ ONLY, то предполагается, что транзакция будет только читать данные. При попытке записи для такой транзакции будет сгенерирована ошибка. Признак READ ONLY введен для того, чтобы дать производителям СУБД возможность уменьшать количество блокировок путем использования других методов сериализации (например, метод выделения версий).
Оператор SET TRANSACTION должен удовлетворять следующим условиям:
- Если предложение ISOLATION LEVEL отсутствует, то по умолчанию принимается уровень SERIALIZABLE.
- Если задан признак READ WRITE, то параметр ISOLATION LEVEL не может принимать значение READ UNCOMMITTED.
- Если параметр ISOLATION LEVEL определен как READ UNCOMMITTED, то транзакция становится по умолчанию READ ONLY. В противном случае по умолчанию транзакция считается как READ WRITE.
Выводы
Современные многопользовательские системы допускают одновременную работу большого числа пользователей. При этом если не предпринимать специальных мер, транзакции будут мешать друг другу. Этот эффект известен как проблемы параллелизма.
Имеются три основные проблемы параллелизма:
- Проблема потери результатов обновления.
- Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание).
- Проблема несовместимого анализа.
График запуска набора транзакций называется последовательным, если транзакции выполняются строго по очереди. Если график запуска набора транзакций содержит чередующиеся элементарные операции транзакций, то такой график называется чередующимся. Два графика называются эквивалентными, если при их выполнении будет получен один и тот же результат, независимо от начального состояния базы данных. График запуска транзакции называется верным (сериализуемым), если он эквивалентен какому-либо последовательному графику.
Решение проблем параллелизма состоит в нахождении такой стратегии запуска транзакций, чтобы обеспечить сериализуемость графика запуска и не слишком уменьшить степень параллельности.
Одним из методов обеспечения сериальности графика запуска является протокол доступа к данным при помощи блокировок. В простейшем случае различают S-блокировки (разделяемые) и X-блокировки (монопольные). Протокол доступа к данным имеет вид:
- Прежде чем прочитать объект, транзакция должна наложить на этот объект S-блокировку.
- Прежде чем обновить объект, транзакция должна наложить на этот объект X-блокировку. Если транзакция уже заблокировала объект S-блокировкой (для чтения), то перед обновлением объекта S-блокировка должна быть заменена X-блокировкой.
- Если блокировка объекта транзакцией B отвергается оттого, что объект уже заблокирован транзакцией A, то транзакция B переходит в состояние ожидания. Транзакция B будет находиться в состоянии ожидания до тех пор, пока транзакция A не снимет блокировку объекта.
- X-блокировки, наложенные транзакцией A, сохраняются до конца транзакции A.
Если все транзакции в смеси подчиняются протоколу доступа к данным, то проблемы параллелизма решаются (почти все, кроме "фантомов"), но появляются тупики. Состояние тупика (dead locks) характеризуется тем, что две или более транзакции пытаются заблокировать одни и те же объекты, и бесконечно долго ожидают друг друга.
Для разрушения тупиков система периодически или постоянно поддерживает графа ожидания транзакций. Наличие циклов в графе ожидания свидетельствует о возникновении тупика. Для разрушения тупика одна из транзакций (наиболее дешевая с точки зрения системы) выбирается в качестве жертвы и откатывается.
Для решения проблемы "фантомов", а также для уменьшения накладных расходов, вызываемых большим количеством блокировок, применяются более сложные методы. Одним из таких методов являются преднамеренные блокировки, блокирующие объекты разной величины - строки, страницы, таблицы, файлы и др.
Альтернативным является метод предикатных блокировок
Имеются также методы сериализации, не использующие блокировки. Это метод временных меток и механизм выделения версий. Механизм выделения версий удобен тем, что он позволяет одновременно, и читать, и изменять одни и те же данные разными транзакциями. Это увеличивает степень параллельности, и общую производительность системы.
Стандарт SQL не предусматривает понятие блокировок. Вместо этого вводится понятие уровней изоляции. Стандарт предусматривает 4 уровня изоляции:
- READ UNCOMMITTED - уровень незавершенного считывания.
- READ COMMITTED - уровень завершенного считывания.
- REPEATABLE READ - уровень повторяемого считывания.
- SERIALIZABLE - уровень способности к упорядочению.
Транзакции могут запускаться с различными уровнями изоляции.
Назад |
Содержание |
Вперед

