Обработка запросов в DEC Rdb: основные аспекты и нерешенные проблемы
Геннадий Антошенков
Перевод: Сергей Кузнецов
Оригинал: Gennady Antoshenkov. Query Processing in DEC Rdb: Major Issues and Future Challenges. IEEE Bulletin of the Technical Committee on Data Engineering, Vol. 16, # 4, December 1993. Текст доступен здесь.
Содержание
- 1. Введение
- 2. Обзор обработки запросов
- 3. Оценка промежуточных потоков данных
- 4. Как справиться с высокой неопределенностью
- 5. Конкурентная модель
- 6. Архитектурные аспекты
- 7. Распространение технологии
- 8. Заключение
- Литература
- 2. Обзор обработки запросов
1. Введение
Явной текущей целью DEC Rdb является эффективная обработка сложных и простых запросов над очень большими базами данных для разнообразных приложений и типов данных. Сегодня работа с 50-гигабайтными базами данных является для Rdb обычным делом, и многие заказчики уже создали и продолжают создавать базы данных размером в несколько сотен гигабайт.
Взрывной рост размеров баз данных проиcходит в областях OLTP и поддержки принятия решений, которые часто совмещаются. Это оказывает давление на существующие механизмы выполнения запросов, слабости которых раскрываются по причине возрастания объемов обрабатываемых данных. Кроме того, возрастают требования поддержки больших объектов, текстов и мультимедийных данных тем же процессором баз данных, который управляет традиционными реляционными приложениями. В этой области мы часто предлагаем возможности двоичных объектов и мультимедиа, а сейчас в стадии разработки находятся расширяемые типы данных, определяемые пользователями функции и функциональность текстовой выборки.
Работая в условиях быстрого роста размеров баз данных, мы получили два урока:
- традиционная технология оптимизации запросов является слабой, и ее модели стоимости не отвечают требованиям оптимизации умеренно сложных запросов над базами данных, содержащими 100K, 1M и больше записей, поскольку ошибка оценки возрастает;
- всестороннее проникновение новых технологий в каждую область, где они могут быть применены, предотвращает дисбаланс оптимизации и потенциальное снижение производительности.
Первый урок был особенно тяжелым и плодотворным, поскольку до сих пор ни ручная оптимизация, ни сохранение/загрузка плана запроса не были доступны в нашем продукте. Вследствие этого в 1990 г. мы создали новый динамический оптимизатор для выборки из одной таблицы, который обладал намного более совершенной архитектурой с динамическими переключателями стратегии на основе новой «конкурентной» модели стоимости. Эта динамическая модель стоимости происходит из свойств преобразования распределений вероятности селективности/стоимости, вызываемой булевскими и реляционными операциями.
Возникающее преобразование диаметрально противоположно тому, которое подрадумевалось в традиционных статических оптимизаторах [SACL79]: вместо того, чтобы быть выпуклыми (например, колоколообразной одноточечной волной (bell-shape, single point surge)) и обеспечивать стабильность оценки стоимости, булевские и реляционные преобразования в действительности приносят очень вогнутые (например, гиперболические) распределения, которые выражают большую степень неопределенности и нестабильности оценок [Ant93].
В новой архитектуре, настроенной на неопределенность, делаются попытки параллельного применения нескольких вариантов выполнения для полного использования областей высокой вероятности процессов, что приводит к выработке результата или к сокращению неопределенности и надежному направлению выполнения выборки. Продвижение и переключение процессов контролируется динамическим оптимизатором в частых точках выполнения. Манипулирование множествами записей реализуется путем интенсивного использования списков ID записей, битовых фильтров (bitmap filters, Babb’s arrays [Babb79]) и структур, поддерживающих оценки.
Второй урок относится к интеграции новых технологий с существующим продуктом. Известно, что области обработки и оптимизации запросов являются сложными и глубоко взаимосвязанными. Поэтому стратегии выполнения, выбираемые с использованием заново введенного средства, имеют склонность основываться на схожих паттернах связности во всех областях, в которых это средство может оказать потенциальное влияние. Если данное средство не полностью распространено во всех таких областях, отсутствующие части могут привести к неоптимальной производительности и вместе с тем не нестабильной эффективности схожих процессов. Последняя возможность представляет собой наихудший образец поведения системы с точки зрения заказчика, поскольку непредвиденное замедление выполнения запроса при производственной рабочей нагрузке является наиболее разрушительным. В критических приложениях пользователь может допустить неоптимальное выполнение прототипа и начальных проб рабочей нагрузки, но нельзя это позволить во время производственного использования.
2. Обзор средств обработки запросов
В этом разделе приводится краткое описние средств обработки запросов в DEC Rdb выпуска V6.0 (в настоящее время находящегося в состоянии бета-тестирования) или в предыдущих выпусках (в настоящее время поставляемых заказчикам). Средства, реализованные в V6.0, явно выделяются.
Rdb работает на кластерах с разделяемыми дисками, составленными из любой смеси процессоров VAX и Alpha. Все операции над базой данных могут одновременно выполняться приложениями или утилитами с любой VAX- или AXP-машины. Страницы данных могут совместно использоваться в основной памяти процессора несколькими приложениями с применением средства «глобальных буферов». Распределенная обработка является частью другого продукта (не рассматриваемого в этой статье), в котором Rdb является сервером. В клиент-серверной архитектуре трафик сообщений может быть сильно сокращен путем использования средства «хранимых процедур» (V6.0), которое сохранять и интерпретировать сервером Rdb переделки в стиле языков программирования многих операторов SQL.
Записи данных и индексы сохраняются в нескольких файлах, где каждая область хранения может вмещать любую смесь таблиц/индексов, каждая таблица или индекс могут быть разделены между многими областями хранения и, таким образом, располагаться в нескольких файлах. Поддерживаются как отсортированные, так и хэшированные индексы с возможностью кластеризации записей через индекс любого типа. Для отсортированных индексов в соответствующих B+-деревьях поддерживается префиксное и хвостовое сжание во всех их узлах и, кроме того, сжатие повторяющихся байтов с сохранением порядка (V6.0), побитное схатие ключей и необратимое усечение длинных строк. Составные ключи могут храниться в любой комбинации по возрастанию или по убыванию последовательностей атрибутов. Каждый хранимый индекс может сканироваться в прямом и в обратном (V6.0) порядке.
Для более гибкой настройки производительности размер страниц, единиц хранения, не зависит от размера буферов ввода-вывода. Парраллелизм доступа к дискам достигается путем асинхронного упреждающего чтения при последовательном сканировании в процессе обработки запросов (V6.0) и при резервном копировании и восстановлении. Расслаивающие (striping) диски контроллеры поддерживаются прозрачно для процессора запросов (без специфичной для устройства оптимизации). Большие двоичные объекты сохраняются как сегментированные строки, указатели на которые помещаются в записи. Все части базы данных могут быть записаны на устройства с одноразовой записью, к которым впоследствии производится доступ для выборки данных.
Оптимизация выполнения запросов может потребоваться либо для сокращения общего времени выполнения, либо для быстрой доставки первых нескольких записей. Выбор, производимый оптимизатором, может значительно повлиять на эффективность. Для запросов на обновление имеется констролируемое пользователем согласование времени блокировок: (1) если ожидается, что все записи (или большая их часть), затронутых выборкой, будут обновляться, то пользователь может потребовать установку блокировок на обновление во время выборки записей; в противном случае, (2) во время выборки записи блокируются на чтение, и эти блокировки усиливаются до блокировок на обновление только для подмножества записей, которые будут реально обновляться.
Оптимизатор запросов Rdb выполняет комбинаторный поиск наилучшего плана, используя исчерпывающий поиск и производя «глубокие слева» (left-deep) деревья выполнения. Наилучший план может быть сохраняться, измененяться и повторно использоваться средством «query outline» (V6.0). Стратегии выполнения соединений включают вложенные циклы, слияние и специальные разновидности слияния для внешнего и полного соединения; соединение объединением (union-join) производится через полное соединение (последние три варианта в V6.0). Ограничения проталкиваются через соединения, объединения и агрегаты к обращениям к индексам и таблицам, включая дополнительные конъюнкты, порождаемые из классов эквивалентности (последняя особенность в V6.0).
Имеются следующие стратегии извлечения данных: последовательное сканирование таблицы, индексный доступ с чтением или без чтения записей, доступ по ID записи и стратегия Leaf, динамически оптимизирующая доступ через один или более индексов. OR-оптимизация соединяет потоки и удаляет дубликаты из сканов через несколько индексов, а также выполняет сканирование через единственный индекс над связанным через OR списком диапазонов с использованием загзагообразного обхода (zig-zag skip) (см. пример в разд. 7). AND-оптимизация является частью стратегии Leaf, описанной в [Ant93].
В Rdb используются две разные модели стоимости. Во время компиляции модель стоимости управляет выбором единого плана, основываясь на предположении о независимости и равномерности (иногда со скошенностью) распределений данных операндов для расчета селективности. Во время выполнения используется конкурентная стоимостная модель (см. разд.5) при предположении гиперболического распределения (см. разд. 3); оценки стоимости непрерывно обновляются, так что организация выполнения может радикально измениться в любой точке выполнения.
Статистика мощности таблиц и индексов поддерживается динамически с точностью O(log(n)) (запуск утилиты не являются обязательными, но может производиться в любое время для придания статистическим данным полной точности). Статистика оценки селективности собирается во время «начала выборки» (start retrieval) в течение выполнения быстрого «без блокировок» (no lock) индексного поиска.
Для сортировки используется быстрая сортировка в основной памяти и выборка с замещением для слияния отсортированных участков. Используется и подбирается автоматически как сортировка признаков, так и перестановка записей целиком (V6.0). Для ограничений целостности имеются опции проверки либо при обновлении, либо во время фиксации. Проверка ограничения целостности оптимизируется путем исключения избыточных проверок и использования списков ID модифицированных записей для сокращения области проверки.
Параллелизм в Rdb используется для упомянутого ранее асинхронного упреждающего чтения записей и для управления конкурирующими процессам в стратегии Leaf. В последнем случае параллелизм эмулируется путем очень быстрого переключения внутри одного процесса, поддержки пропорциональной скорости продвижения участвующих индексных сканов в соответствии с моделью конкуренции.
3. Оценка промежуточных потоков данных
Оптимальность производительности запросов сильно зависит от возможности оценивать размер и стоимость производимых промежуточных потоков данных запроса. Во всех основных коммерческих процессорах запросов используется одно скалярное значение для выражения этих оценок для потоков, производимых операциями плана выполнения. В дополнение к этому, обычно предполагается независимость данных операндов каждой операции. В стандартной для индустрии модели стоимости [SACL79] используются оценки из одного значения при предположении независимости операндов; и обычно считается, что эти оценки достаточно стабильны в реалистичных пределах ошибки оценки.
Наш производственный опыт с использованием Rdb противоречит этой уверенности в стабильности оценок. Почти половина всех проблем, связанных с компонентом обработки запросов, связана с нестабильностью оценок и последующим неправильным выбором плана, что приводит к отклонениям в оптимальности производительности на несколько порядков.
Нашему опыту не отвечает при предположение о независимости операндов. Резулярно изучая распечатки многих трасс выполнения запросов заказчиков, мы могли видеть реальное воздействие ANDing, ORing и т.д. на результаты запросов. 10% таблицы, соединенных через AND с другими 10% этой таблицы производили 0%, или 1%, или 10% этой таблицы, и каждый результат появлялся с достаточно большой вероятностью. Эти три случае соответствуют корреляции –1, 0, +1 соответственно, отражая тот факт, что вероятность разной корреляции данных операндов распределена в интервале корреляции [-1,+1] и не концентрируется около нулевой точки этого интервала.
Не выполняя крупного статистического эксперимент для определения вида распределения корреляции в отрезке [-1,+1], мы предположили, что равномерное распределение корреляции в этом интервале более реалистично, чем предположение о нулевой корреляции. Далее мы будем говорить о смешанной корреляции, предполагающей равную вероятность для каждой корреляции.
В поисках причины нестабильности оценок мы провели следующий эксперимент. При заданных распределениях для оценок на самом нижнем (сканирование таблиц/индексов) уровне дерева плана выполнения мы проверили распределения оценок промежуточных потоков данных с использованием предположения о смешанной корреляции. Чтобы обнаружить паттерны распространения распределения вверх по дереву выполнения, мы, прежде всего, исследовали преобразования, порождаемые различными операциями, а потом рассматривали общее влияние вложенных операций.
Результаты этого эксперимента (опубликованные в [Ant93]) демонстрируют следующие паттерны преобразований распределений:
- Равномерное распределение селективности операндов AND преобразуется путем ANDing в распределение, хорошо апроксимируемое усеченной гиперболой.
- ORing производит «зеркальную» гиперболу с пиком при селективности, равной 1.
- Соединения и объединения повторяют паттерны AND/OR соответственно, наличие дубликатных ключей соединения увеличивает скошенность гиперболы.
- Вкладывание AND и соединений производит гиперболы с быстро возрастающей скошенностью, для вложенных OR и объединений сохраняется зеркальная симметрия.
- В некоторой точке вложенного баланса AND/OR преобразованное распределение является близким к равномерному.
- Для любых исходных паттернов распределения, включая точную (с одним значением) оценку имеется тенденция к преобразованию к гиперболам, часто при наличии одной или нескольких вложенных операций.
Базовые паттерны преобразования равномерного распределения иллюстрируются на рис. 1. Для операндов операций AND/OR предполагается смешанная корреляция.
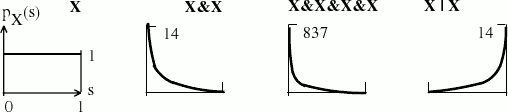
Равномерное распределение pX(s) селективности s для предиката X преобразуется в усеченную гиперболу для предиката X&X, в сильно скошенную гиперболу для предиката X&X&X&X и в зеркальную гиперболу для X|X.
Рис. 1. Преобразования равномерного распределения
На основе своего производственного опыта мы также обнаружили, что гиперболы с нулевым пиком (распределение Зипфа 1/n [Zipf49]) доминирует среди всех распределений промежуточных оценок. Простое объяснение этого состоит в том, что редко встречаются запросы, производящие поиск по всей базе данных, а часто обрабатываются небольшие запросы и подзапросы.
4. Как справиться с высокой неопределенностью
Гиперболическое распределение оценок делает явной высокую неопределенность и, таким образом, объясняет наблюдавшуюся нами нестабильность традиционной стоимостной модели. Действительно, область селективности/стоимости вблизи средней точки гиперболы будет покрывать реальные показатели селективности/стоимости с той же вероятностью, что и ограниченная область вблизи нуля и широкая область, простирающаяся к правому концу. Наличие этих экстремумов серьезно уменьшает достоверность традиционной стоимостной модели с одним значением (средней точкой). Аналогичные результаты экспоненциального распространения ошибки для n-сторонних соединений изложены в [IoCh91].
«Быстрое» решение для компенсации этого фундаментального ограничения оптимизатора предлагается многими поставщиками в форме средств ручной оптимизации, которые позволяют перекрыть решение оптимизатора планом выполнения, определенным пользователем. В Rdb теперь имеется аналогичное средство, называемое «query outline». В отличие от других средств ручной оптимизации, query outline допускает любые общие рекомендации по поводу желаемого плана выполнения и использует те из них, которые являются пригодными.
В query outline учитываются следующие пользовательские спецификации:
- полный или частичный порядок соединений;
- стратегии соединений и выборки;
- набор индексов, из которых следует выбирать кандидата для выборки.
Спецификации являются опциональными; любые неспецифицированные части плана вычисляются с использованием обычной процедуры оптимизации. Такая гибкость спецификаций query outline ускоряет и упрощает ручную оптимизацию. Сохранение частичных рекомендаций продлевает применимость и полезность query outline в случае модификации SQL-схемы.
Однако истинно удовлетворительным решением для ненадежной оптимизации является автоматическая оптимизация запросов, способная к эффективному устранению неопределенности оценок. Здесь первая задача состоит в том, чтобы отделить части выражения запроса с достаточно точными оценками от областей неопределенности. Для этого необходимо заменить традиционную оценку с единственным значением на функцию плотности вероятности оценки, представленную в численном виде (подход, использованный нами в экспериментах) или аналитической аппроксимацией (например, рядом, подобным [SunL93]). Задача отделения неопределенности на сегодняшний день не решена, и для ее решения требуются значительные усилия исследователей.
Использование методов оценки, которые основываются на данных, хранимых в индексах/таблицах, обеспечивает достаточную точность для нескольких вложенных операций над узлами выборки. Методы взятия образцов для разнообразных структур хранимых данных описаны в [OlRo89], [OlRo90], [Ant93], [OlRo93]. Алгоритмы и правила останова для оценки на основе взятия образцов соединений и ограничений представлены в [LiNS90], [HaSw92].
Чем больше операций включается в подзапрос, подлежащий непосредственной оценке на основе взятия образцов, тем более крупные области определенности могут потенциально остаться непокрытыми. Однако ограничения на размеры образцов, помогающие сохранить стоимость оценок более низкой, чем стоимость выполнения, ограничивают число вложенных операций до небольшого числа, при котором можно добиться разумной точности. Кроме того, при использовании комбинаторного поиска наилучшего решения требуется оценить n! подмножеств n-сторонней операции, чтобы найти наилучшее дерево выполнения. Для решения этой проблемы можно было бы применить совместные многоцелевые оценщики с общим правилом останова.
Предположим теперь, что мы эффективно отделили область неопределенности выражения запроса, применив желаемую процедуру многоцелевой оценки. Правильно оцененная часть запроса может оптимизироваться с применением известных методов, но как нам обработать операции, попадающие в область неопределенности? Ответ на этот вопрос можно вывести из вида преобладающего гиперболического распределения оценок. На основе свойств гиперболического распределения в 1990 г. мы разработали конкурентную модель [Ant91] для динамической оптимизации запросов и реализовали ее в Rdb release V4.0.
5. Конкурентная модель
Предположим, что подзапрос можно выполнять с использованием двух альтернативных стратегий s1 и s2, и, по крайней мере, у оценки стоимости одной из них (например, у s1) имеется гиперболическое распределение. При достаточно высокой скошенности гиперболы существенная вероятность стоимости концентрируется в небольшом интервале [0; ĉ] вблизи нулевой стоимости. Если в начале вычисления подзапроса всегда выполняется стратегия s1, пока не будет исчерпана стоимость или подзапрос не будет успешно выполнен, то при небольшой начальной инвестиции ≤ĉ существенная часть случаев быстрого завершения s1полностью исчерпывается. Если у обеих стратегий имеется гиперболическое распределение стоимости, то наилучшим способом действия является параллельный запуск s1 и s2 с пропорциональной скоростью продвижения стоимости с переключением в некоторой точке ĉ на единую стратегию s1 или s2 в зависимости от того, у какой из них меньше оцененная средняя стоимость.
Выше мы описали модель прямой конкуренции для выполнения двух альтернативных стратегий. При оптимальном выборе ĉ, определенном в [Ant91], прямая конкуренция гарантирует организацию вычисления s1/s2 с наименьшей средней стоимостью.
Стратегии выполнения запросов часто содержат две и большее число фаз, например, (фаза 1) сканирование индекса обеспечивает множество ID записей, (2a) это множество сортируется, (2b) записи данных выбираются в порядке физического расположения, и каждая страница считывается только один раз. В этом примере стоимость фазы 1 намного меньше общей стоимости фазы 2. Кроме того, при знании множества ID можно точно оценить стоимость фазы 2. Если доступны два индекса, может быть организована конкуренция между применениями описанной стратегии к двум индексам со временем завершения параллельного выполнения, определяемым эксраполированной стоимостью обеих фаз стратегии. По сравнению с прямой конкуренцией, эта двухфазная конкурений является намного более эффективной, поскольку стоимость ее «решающей» первой фазы составляет лишь долю от общей стоимости стратегии.
Аналогичный подход к параллельной оценке альтернативных стратегий, в котором извлекается выгода от сокращения неопределенности, предлагается в [Roy91]. Сокращение неопределенности в этом подходе достигается путем рандомизации выполнения стратегии и использования части промежуточных результатов в качестве случайных образцов для вычисления оценок стоимости. В сравнении с конкурентной моделью рандомизированне выполнение не покрывает несколько важных случаев:
- Из подзапроса запрашивается n записей при n < мощности результата – накакие рандомизация или взятие обзазцов не могут улучшить знание n, если n неизвестно, например, если n поставляется пользовательским приложением во время выполнения.
- Некоторые стратегии, такие как слияние с использованием индексов, обычно реализуются с использованием непрерывного сканирования, рандомизация которого зарушила бы порядок слияния.
- Короткие подзапросы, при выполнении которых производится небольшой объем ввода-вывода, взяли бы на себя слишком большую долю накладных расходов рандомизации.
Мы рассматривали возможность использования рандомизации в Rdb для ускорения конкурентного сокращения неопределенности в тех случаях, когда рандомизация применима. К сожалению, в соответствии с нашими экспериментами, рандомизированный индексный доступ, основанный на методе принятия/отклонения привел к трем тысячам отклонений на один спуск по B-дереву для таблицы с 1M записей. К счастью, мы решили эту проблему, введя псевдоупорядоченные B-деревья [Ant92], так что с накладными расходами в 1% на поддержание приблизительных мощностей ветвей скорость отклонения была сокращена до 50%. В дополнение к этому, для индексных диапазонов единственный спуск по псевдоупорядоченному дереву до наименьшей ветви, покрывающей диапазон, может иметь точность приблизительных мощностей, достаточную для принятия решения о переключении стратегии.
Параллельное выполнение альтернативных стратегий следует использовать с предосторожностями с средах с частыми обновлениями, потому что при этом устанавливается не минимально необходимое число блокировок. Пилотное взятие образцов без блокировок, при котором при встрече заблокированного объекта к нему повторяются попытки обращения, может разрешить некоторые неопределенности и сократить число альтернатив до начала реальной обработки В Rdb мы производим пилотное взятие образцов путем одиночного спуска по B-дереву к ветви, содержащей диапазон.