Расширяемая, управляемая правилами оптимизация путем перезаписи запросов в Starburst
Хамид Пирамеш, Джозеф Хеллерстейн, Вакар Хасан
Перевод: Сергей Кузнецов
3. Набор правил перезаписи для гарантирования поглощения SELECT
При разработке наших процессора и правил перезаписи мы стремились придерживаться следующей
Философии перезаписи:
Везде, где это возможно, запрос следует преобразовывать к одиночной операции SELECT.
Простая операция SELECT, действующая над базовыми таблицами, представляет базисный запрос, включающий простые ограничение, проецирование и соединение. Имеются разнообразные высокопроизводительные алгоритмы выполнения таких запросов, и хорошо понятны методы выбора среди этих алгоритмов. Кроме того, как отмечалось выше, наличие более сложных запросов часто навязывает оптимизатору планов выбор конкретного плана – например, наличие подзапросов заставляет применять особые методы и порядки соединений, а использование представлений (как мы увидим) излишне ограничивает возможный порядок соединений в запросе. Наконец, оптимизаторы планов обычно принимают решения на основе среды только одного блока запроса (т.е. одного QGM-блока). В результате запросы с несколькими операциями обычно не приводятся к оптимальным планам, и везде, где это возможно, их следует преобразовывать к одиночным операциям SELECT.
Конечно, имеется много оптимизаций, применимых к самим операциям SELECT. Но мы считаем, что преобразование к одиночной операции SELECT во всех возможных случаях находится среди наиболее важных целей преобразования запросов.
В результате мы концентрируемся в этой статье на тех правилах перезаписи в Starburst, которые гарантируют, что все представления (табличные выражения) и подзапросы с квантором существования сливаются всегда, когда это возможно. В Starburst к единой операции SELECT не могут быть переписаны только запросы, содержащие подзапросы не с кванторами существования или с не булевскими сомножителями, операции над множествами2, агрегаты и определяемые пользователями расширения (такие как OUTER JOIN). В системе допускается определение правил перезаписи и для таких запросов, так что, хотя они и не преобразуются к одиночной операции SELECT, к ним часто применяются полезные преобразования. Например, Розенталь (Rosenthal) [RGL90] определяет набор таких преобразований для внешнего соединения.
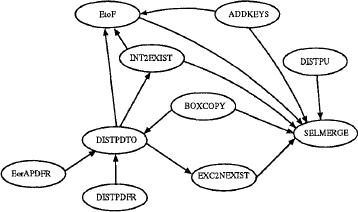
Рис. 2. Инициирующие взаимодействия между правилами
В этом разделе мы обсудим набор правил в Starburst, которые приводят к слиянию блоков SELECT. На рис. 2 показаны зависимости между правилами, возникающие в тех случаях, когда выполнение одного правила (хвостовая часть стрелки) приводит к удовлетворению условия другого правила (головная часть стрелки). Представляя эти зависимости, мы не утверждаем, что это полный набор. Мы преследуем цель представить наиболее важные зависимости, чтобы проиллюстрировать полезность каждого правила при слиянии блоков SELECT. Поскольку этот набор правил служит для слияния блоков SELECT, представляемое первым правило «SELECT merge» (SELMERGE) транзитивно зависит от каждого из других правил и образует фокус наших измерений.
Прежде чем продолжать изложение, следует заметить, что число требуемых нами правил поддерживается достаточно низким путем обеспечения локальности ссылок: каждое правило пишется со ссылкой на некоторый контекст (например, блок или квантификатор), и в результате правила, вовлекающие более одного блока, могут писаться в стиле «блок за блоком», а не для пар блоков. Это позволяет иметь число правил, зависящее от числа типов блоков, а не от квадрата этого числа или даже хуже. В наборе представляемых здесь правил мы увидим много примеров локальности правил, а в следующем разделе будет показано, как эти правила поддерживаются процессором правил.
3.1 Правила, гарантирующие поглощение представлений
Правило 1. SELECT Merge (слияние SELECT)
Правило SELMERGE (таб. 2) принимает два блока SELECT, соединенные квантификатором F (например, запрос над соединением), и сливает их в один блок. Польза этого преобразования состоит в том, что оно обеспечивает возможность большего числа порядков соединения; в результируещем одном блоке SELECT оптимизатор планов может выбрать в качестве порядка соединений любую перестановку таблиц под квантификаторами F, в то время как в исходном запросе таблицы, ссылки на которые содержатся в табличном выражении (нижний блок), не могут чередоваться с таблицами верхнего блока. Заметим, что если мы применим это правило ко всем блокам запроса, то закончим преобразования с единственным блоком SELECT, так что это правило непосредственно ведет к реализации нашей Философии Перезаписи. Чтобы обеспечить применимость этого правила, другие правила этого раздела пытаются удовлетворить условие этого правила во многих возможных ситуациях.3

Таб. 2. Правило 1 – SELMERGE
Некоторое усложение для обеспечения корректности правила нас заставляет ввести проблема дубликатов. Если временно проигнорировать дубликаты, должно быть ясно, почему это правило работает: это непосредственно следует из коммутативности соединений и применения предикатов. Поскольку соединения и предикаты коммутативны, мы можем чередовать их из нижнего и верхнего блоков, что эквивалентно тому, что мы можем их слить. Этот аргумент применяется напрямую в том случае, когда ни из верхнего, ни из нижнего блоков не удаляются дубликаты.
Чтобы убедиться в том, что это правило корректно работает с дубликатами, требуется некоторый анализ. Мы разобъем ситуацию на ряд случаев и докажем корректность в каждом случае:
- upper.head.distinct = TRUE: Это может произойти в одном из двух случаев:
Если upper.body.distinct = ENFORCE, то любые дубликаты, производимые нижним блоком в исходном запросе, будут удалены верхним блоком, и, следовательно, слияние не приводит ни к потери, ни к появлению дубликатов.
Если upper.body.distinct = PRESERVE, то все F-квантификаторы в верхнем блоке производят множества без дубликатов. Если lower.body.distinct = PRESERVE, то мы просто сливаем нижний и верхний блоки без какого-либо влияния на дубликаты. Если lower.body.distinct = ENFORCE, то мы должны установить в upper.body.distinct значение ENFORCE, чтобы гарантировать, что дубликаты не будут производиться после слияния. Заметим, что мы не можем иметь ситуацию lower.body.distinct = PERMIT – если ее допустить, то нижний блок мог бы производить любое число дубликатов, из-за чего следует, что мы не могли бы иметь upper.head.distinct = TRUE и upper.body.distinct = PRESERVE, что противоречит условиям данного случая.
upper.body.distinct = PERMIT: В этом случае мы можем игнорировать аспект дубликатов по определению.
lower.body.distinct != ENFORCE: В этом оставшемся случае условия двух предыдущих случаев должны не соблюдаться, т.е. upper.head.distinct = FALSE и upper.body.distinct = PRESERVE. В результате мы не можем слить блоки, если lower.body.distinct = ENFORCE, потому что мы не можем в одном блоке удалить дубликаты из квантификаторов нижнего блока и сохранить дубликаты оставшихся квантификаторов верхнего блока. Однако если lower.body.distinct != ENFORCE, то мы можем не беспокоиться об этой проблеме и производить слияние.
Заметим, что единственными случаями, в которых мы не можем применить правило SELMERGE к двум блокам SELECT, связанным F-квантификаторами, являются случаи, когда над нижним блоком имеется несколько квантификаторов, или когда upper. head.distinct = FALSE, upper.body.distinct = PRESERVE и lower.body.distinct = ENFORCE. Мы увидим, что с этими случаи справляются правила BOXCOPY и ADDKEYS соответственно, гарантируя, что, в конце концов, будет выполнено SELMERGE.
Мы выбрали относительно простой пример для измерения влияния этого правила на производительность среды, упомянутой в разд. 2. На практике запросы обычно бывают значительно более сложными, и правило слияния становится применимым только после применения многих правил, перечисленных ниже. Хотя этот пример прост, во многих коммерческих СУБД отсутствует такая оптимизация. Рассмотрим представление, которое выдает номер изделия и его производителя для изделий, которые начали поставляться их производителями позже 1985 г. В этом представлении используется запрос, обеспечивающий информацию о некоторых изделиях и их поставщиках.
Пример 1.
CREATE VIEW itpv AS
(SELECT DISTINCT itp.itemn, pur.vendn
FROM itp, pur
WHERE itp.ponum = pur.ponum AND pur.odate > '85');
SELECT itm.itmn, itpv.vendn FROM itm, itpv
WHERE itm.itemn = itpv.itemn
AND itm.itemn ≥ '01' AND itm.itemn < '20';
Логика перезаписи прежде всего распознает, что результат запроса является DISTINCT, применив правило DISTPU, разъясняемое ниже. Затем применяется правило слияния. Результирующим запросом является:
SELECT DISTINCT itm.itmn, pur.vendn FROM itm, itp, pur WHERE itp.ponum = pur.ponum AND itm.itemn = itp.itemn AND pur.odate >'85' AND itm.itemn ≥ '01' AND itm.itemn < '20';
В результате слияния представления с запросом оптимизатор планов сможет использовать индексы для доступа к таблицам внутри представления, и он выберет план, выполняющий соединения. Результаты выполнения этого запроса с перезаписью и без нее показаны в таб. 3. После применения правила перезаписи мы получаем уменьшение времени процессора в 1100 раз и уменьшение общего времени выполнения запроса в 200 раз.

Таб. 3. Пример 1 до и после перезаписи
Правило 2. Distinct Pullup (вытягивание Distinct)
В правиле DISTPU (таб. 4) для блока SELECT upper делается заключение, что не требуется какое-либо удаление дубликатов для гарантирования уникальности всех его результирующих кортежей. Это делается путем выделения следующих свойств:
- one-tuple-condition: для заданных квантификатора и набора предикатов это условие принимает значение TRUE в том и только в том случае, когда предикатам удовлетворяет, самое большее, один кортеж квантификатора.
- quantifier-nodup-condition: для заданных квантификатора F и набора предикатов это условие принимает значение TRUE в том и только в том случае, когда в результате появляется хотя бы один первичный или возможный ключ F.

Таб. 4. Правило 2 – DISTPU
В upper должны найтись либо условие quantifier-nodup-condition, либо условие one-tuple-condition, которые выдерживаются для всех F-квантификаторов этого блока и ассоциированных с ними предикатов. Если это неверно для некоторого F-квантификатора, то в проекции декартова произведения нижних блоков будут иметься дубликаты, и в upper требуется их удалять; если для каждого F-квантификатора верно хотя бы одно из двух условий, то дубликаты в проекции декартова произведения содержаться не будут.
Отметим «локальность» этого правила – при его написании мы не должны заботиться о типе нижних блоков, нас занимают только F-квантификаторы над этими блоками.
Правило 3. Distinct Pushdown From/To (проталкивание Distinct из/в)
В этой паре правил (таб. 5) блок информирует свои нижележащие блоки о том, что от них не требуется удаление дубликатов. Это делается путем «проталкивания» атрибута distinct из этого блока в его нижележащие блоки. Такое действие может предохранить нижние блоки от потребности сортировки или хэширования для удаления дубликатов, а также может позволить применять к нижним блокам правила, которые могут вводить дубликаты (например, описываемое ниже правило EtoF).

Таб. 5. Правило 3 – DISTPDFR/DISTPDTO
Для варианта DISTINCT операций над множествами (UNION, INTERSECT и EXCEPT) правило DISTPDFR является корректным по причине семантики удаления дубликатов в этих операциях. Операции над множествами с DISTINCT определяются как удаляющие дубликаты из всех своих операндов до какой-либо дальнейшей обработки [ISO91]. Так что эти блоки будут игнорировать любые дубликаты, производимые нижележащими блоками, и об этом можно безопасным образом сигнализировать, проталкивая DISTINCT сквозь квантификаторы.
В случае блока SELECT с body.distinct = PERMIT нас не беспокоит аспект дубликатов. Чтобы увидить корректность правила DISTPDFR для блока SELECT с body.distinct = ENFORCE, достаточно заметить, что любой кортеж, происходящий из такого блока, является конкатенацией кортежей t1, . . ., tn из n входных источников (под F-квантификаторами) блока. Независимо от того, сколько копий каждого ti имеется в соответствующей входной таблице tablei, в результате блока SELECT DISTINCT будет содержаться, самое большее, один кортеж, спроецированный из t1, . . ., tn. Поэтому в каждом источнике можно безопасно удалять или порождать дубликаты без воздействия на результат такого блока SELECT.
Правило DISTPDTO является достаточно простым – если во всех блоках, определенных над данным блоком, указано их безразличие к числу дубликатов, производимых их источниками, то в этом блоке могут каким угодно образом вводиться или удаляться дубликаты, и, следовательно, флаг distinct тела этого блока можно установить в PERMIT, а флаг distinct его заголовка – в FALSE.
Отметим использование локальности правила: в этой задаче участвуют два блока, и поэтому она разбивается на два отдельных правила с использованием информации, передаваемой между блоками через квантификатор. При выполнении проталкивания атрибута DISTINCT каждая операция должна заниматься только своим собственным поведением без потребности знать что бы то ни было про другие операции, участвующие в этой активности. Заметим также, что, если обработка останавливается после DISTPDFR, но перед DISTPDTO, граф OGM остается согласованным и допустимым.
Правило 4. E or A Distinct Pushdown From
Это правило (таб. 6) является частным случаем выталкивания distinct «из»; в правиле используется тот факт, что квантификация кванторами существования или всеобщности слепа к дубликатам. Другими словами, несущественно число кортежей в подзапросе, которые удовлетворяют предикату с квантором существования; для таких предикатов требуется соответствие только одного кортежа подзапроса. Аналогично, число дубликатов в подзапросе не имеет значения для предиката с квантором всеобщности; либо все кортежи в подзапросе удовлетворяют такому предикату, либо он в целом не удовлетворяется.
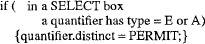
Таб. 6. Правило 4 – EorAPDFR
Пример 2.
CREATE VIEW richemps AS
(SELECT DISTINCT empno, salary, workdept
FROM employee
WHERE salary > 50000);
SELECT mgrno FROM department dept
WHERE NOT (EXISTS (
SELECT * FROM richemps rich, project proj
WHERE proj.deptno = rich.workdept
AND rich.workdept = dept.deptno));
В этом примере возвращаются данные о менеджерах, в отделах которых нет выскооплачиваемых служащих. Применяя EorAPDFR и DISTPDTO, мы делаем так, чтобы у подзопроса имелось body.distinct = PERMIT, что приводит к слиянию с подзапросом представления richemps. После перезаписи запрос выглядит следующим образом:
SELECT mgrno FROM department dept
WHERE NOT (EXISTS (
SELECT * FROM employee emp, project proj
WHERE proj.deptno = emp.workdept
AND emp.workdept = dept.deptno
AND emp.salary > 50000));
Правило 5. Common Subexpression Replication (репликация общих подвыражений)
Это правило (таб. 7) приводит к избавлению от общих подвыражений в графе OGM путем их репликации.Это позволяет произвести слияние одного или обеих полученных блоков.4

Таб. 7. Правило 5 – BOXCOPY
Правило 6. Add Keys (добавление ключей)
Для заданных двух блоков SELECT upper и lower, таких что lower является областью определения только F-квантификатора в upper, правило ADDKEYS (таб. 8) гарантирует, что upper и lower будут слиты. Это делается путем модификации любого блока, сохраняющего дубликаты, таким образом, чтобы в нем можно было безопасно удалять дубликаты. Мы достигаем этого путем добавления «ключевых» столбцов (или уникальных ID кортежей) к источникам входных данных, которые проходят в блок SELECT. После того, как это сделано, мы можем удалять дубликаты из блока SELECT безо всякого воздействия, поскольку для каждого кортежа в блоке имеется уникальный ключ, полученный путем конкатенации ключей входных источников.

Таб. 8. Правило 6 – ADDKEYS
Снова отметим «локальность» этого правила – данный блок ссылается на нижележащие блоки только через F-квантификаторы, областями определения которых они являются, и поэтому типы нижележащих блоков становятся несущественными.
В следующем примере определяется представление, предоставляющее различные договорные цены заказанных изделий. В запросе используется представление для вычисления договорной цены каждого типа изделия.
Пример 3.
CREATE VIEW itemprice AS (SELECT DISTINCT itp.itemno, itp.NegotiatedPrice FROM itp WHERE NegotiatedPrice > 1000); SELECT itemprice.NegotiatedPrice, itm.type FROM itemprice, itm WHERE itemprice.itemno = itm.itemno;
Правило ADDKEYS применяется к (верхнему) блоку SELECT запроса, позволяя правилу SELMERGE слить с запросом представление itemprice. Заметим, что SELMERGE меняет атрибут запроса body.distinct на ENFORCE, удаляя, таким образом, дубликаты, изначально удалявшиеся в представлении. Результирующий запрос выглядит следующим образом:
SELECT DISTINCT itp.NegotiatedPrice, itm.type, itm.itemno FROM itp, itm WHERE itp.NegotiatedPrice > 1000 AND itp.itemno = itm.itemno;
SQL-представление переписанного запроса не точно соответствует семантике преобразованного QGM. В реальном переписанном запросе результирующий столбец itm.itemno используется в течение удаления дубликатов, но его значения не поставляются в результат запроса.
2) Как мы покажем, даже некоторые из них поддаются преобразованию к одиночной операции SELECT!
3) Как отмечается в [HP88], важность инициации этого правила придает тот факт, что в ранних реляционных системах, таких как System R, поддерживались только подставляемые представления.
4) Если запросы коррелируют, логика копирования усложняется. Этот вопрос не рассматривается в данной статье, но в варианте Starburst этого правила обработка производится корректно.