2009 г.
Параллельные системы баз данных: будущее высоко эффективных систем баз данных
Дэвид Девитт, Джим Грэй
Источник: журнал Системы Управления Базами Данных # 2/1995, издательский дом «Открытые системы»
Новая редакция: Сергей Кузнецов, 2009 г.
Оригинал: David Dewitt and Jim Gray. Parallel database systems: the future of high performance database systems. Communications of the ACM, Volume 35, Number 6, June, 1992. Текст доступен здесь.
Содержание
- Основные технологии для реализации параллельных
машин баз данных
- Состояние дел
- Teradata
- Tandem Nonstop SQL
- Gamma
- Суперкомпьютер баз данных
- Bubba
- Другие системы
- Машины баз данных и закон Гроша
- Будущие направления и исследовательские проблемы
- Смешивание пакетных и OLTP запросов
- Оптимизация параллельных запросов
- Распараллеливание прикладных программ
- Физическое проектирование баз данных
- Реорганизация данных в режиме on-line и утилиты
- Заключение
- Литература
Параллельные системы баз данных начинают вытеснять традиционные компьютеры
основного класса, так как они позволяют работать со значительно более крупными
базами данных в режиме, поддерживающем транзакции. Успех таких систем опровергает
прогноз статьи 1983-го года [3], предрекавшей скорое исчезновение машин
баз данных. Десять лет назад будущее параллельных машин баз данных выглядело
неопределенным даже для самых верных их сторонников. Большинство проектов
разработки машин баз данных концентрировалось вокруг специализированного
аппаратного обеспечения, находящегося еще в стадии разработки, такого
как CCD-память (charge-coupled device, устройство с зарядовой связью), пузырьковая память (bubble memory), диски с фиксированными головками и
оптические диски. Ни одна из этих технологий себя не оправдала.
Таким образом, создалось впечатление, что традиционые центральные процессоры,
электронная основная память и магнитные диски с подвижными головками будут
доминировать в течение еще многих лет. В то время прогнозы сходились на
том, что пропускную способность диска удастся увеличить в два раза, а скорость
процессоров возрастет намного больше. Следовательно, скептики предрекали,
что многопроцессорные системы вскоре столкнутся с проблемами ограниченной
пропускной способности при вводе-выводе, если только не будет найден способ
расширения этого узкого места.
В то время как прогноз о будущем аппаратного обеспечения оказался достаточно
точным, скептики ошиблись в предсказании будущего параллельных систем баз
данных. За последние десять лет компании Teradata, Tandem и ряд новоявленных
компаний успешно разрабатывали и продавали параллельные машины.
Каким образом параллельным системам баз данных удалось избежать участи
экспоната в кунсткамере компьютерных неудач? Одно из объяснений – широкое
распространение реляционных баз данных. В 1983 году они только еще появлялись
на рынке, сегодня же доминируют. Реляционные запросы как нельзя лучше подходят
для параллельного выполнения; они состоят из однородных операций над однородным
потоком данных. Каждая операция образует новое отношение, так что из операций
могут быть составлены высокопараллельные графы потоков данных. Две операции
могут работать последовательно, если направить вывод одной операции на
вход другой. Это так называемый конвейерный параллелизм (pipelined parallelism). Если разделять
вводимые данные между несколькими процессорами и памятью, часто оказывается
возможным разбить операцию на несколько независимых операций, каждая
из которых работает с частью данных. Такое разделение данных и обработки
называется раздельным параллелизмом (partitioned parallelism) (рис. 1).
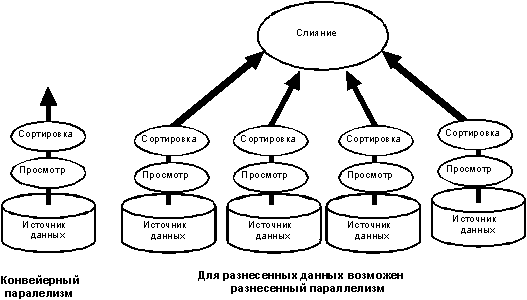
Рисунок 1.
Потоковый подход к реляционным операторам включает как конвейерный,
так и разделенный параллелизм. Реляционные операции принимают отношения
(однородные наборы записей) в качестве ввода и производят отношения на
выходе. Это позволяет составлять из них графы потоков данных, что делает
возможным конвейерный параллелизм (слева), при котором одна операция вычисляется
параллельно с другой, и раздельный параллелизм, при котором операции
(сортировка и просмотр на диаграмме справа) дублируются для каждого источника
данных и дубли выполняются параллельно.
При потоковом подходе к организации систем баз данных необходима операционная
система типа клиент-сервер, основанная на передаче сообщений для взаимосвязи
параллельных процессов, в которых выполняются реляционные операции. Для этого,
в свою очередь, требуется высокоскоростная сеть, обеспечивающая взаимосвязь
параллельных процессоров. Такие средства казались экзотическими еще десять
лет назад, теперь же они находятся в основном русле компьютерной архитектуры.
В парадигме "клиент-сервер" высокоскоростные локальные сети (LAN) рассматриваются
как основа для большей части персональных компьютеров, рабочих станций
и программного обеспечения рабочих групп. В то же время механизмы "клиент-сервер"
являются превосходным базисом для разработки распределенных баз данных.
Перед разработчиками машин основного класса встала трудноразрешимая
задача создания достаточно мощных компьютеров, способных удовлетворить
требования к ЦПУ и вводу/выводу, предъявляемые реляционными базами данных,
которые обслуживают одновременно большое число пользователей или осуществляют
поиск в терабайтных базах данных. Тем временем стали широко доступны мультипроцессоры
разных поставщиков, основанные на быстрых и недорогих микропроцессорах,
включая Encore, Intel, NCR, nCUBE, Sequent, Tandem, Teradata и Thinking
Machines. Эти машины обладают большей мощностью за меньшую цену, чем их
аналоги класса мэйнфрейм. Модульная архитектура мультипроцессоров позволяет
при необходимости наращивать систему, увеличивая скорость процессоров,
расширяя основную и внешнюю память для ускорения выполнения какой-либо
конкретной работы или для расширения системы с целью выполнить большую
работу за то же время.
История показывает, что узкоспециализированные машины баз данных оказались
несостоятельными, в то время как параллельные системы баз данных достигли
огромных успехов. Успешные параллельные системы баз данных строятся на
обычных процессорах, памяти и дисках. Именно в этих системах в основном
отразились идеи высоко параллельных архитектур, и они заняли наилучшую
позицию для потребления огромного числа быстрых и дешевых дисковых устройств,
процессоров и памяти, обещаемых прогнозами современной технологии.
Выработано единое мнение об архитектуре распределенных и параллельных
систем баз данных. Эта архитектура базируется на идее аппаратного обеспечения
без совместного использования ресурсов (shared-nothing) [29], когда процессоры поддерживают
связь друг с другом только посредством передачи сообщений через соединяющую
их сеть. В таких системах кортежи каждого отношения в базе данных разделяются (partitioned, dedustered)
между дисковыми запоминающими устройствами1),
напрямую подсоединенными к каждому процессору. Разделение позволяет нескольким
процессорам просматривать большие отношения параллельно, не прибегая к
использованию каких-либо экзотических устройств ввода/вывода. Такая архитектура
впервые была представлена компанией Teradata в конце 70-х годов, а также
была использована в нескольких исследовательских проектах. Теперь она используется
в продуктах Teradata, Tandem, NCR, Oracle-nCUBE и еще нескольких продуктах,
находящихся в стадии разработки. Исследовательское сообщество также использовало
архитектуру без совместного использования ресурсов в таких системах, как
Arbre, Bubba и Gamma.
Оставшаяся часть статьи организована следующим образом. В следующем
разделе описываются основные архитектурные концепции, используемые в таких
параллельных системах баз данных. Затем в разделе "Положение дел" следует
краткое описание специфических особенностей систем Teradata, Tandem, Bubba,
Gamma. Некоторые направления будущих исследований обозначены в разделе
"Будущие направления и нерешенные проблемы", предшествующем заключительному
разделу статьи.
Основные технологии для реализации параллельных
машин баз данных
Цели и параметры параллелизма: ускорение и масштабируемость
Идеальная параллельная система обладает двумя главными свойствами: (1)
линейное ускорение (linear speedup): при двойном увеличении объема аппаратного обеспечения та же задача выполняется
в два раза быстрее и (2) линейная масштабируемость (linear scaleup): при двойном увеличении объема аппаратного обеспечения вдвое большая задача выполняется за то же время
(см. рис.2 и рис. 3).
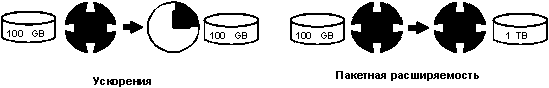
Рисунок 2.
Ускорение и масштабируемость. Ускорение позволяет выполнить часовую работу
за четверть часа на машине, которая крупнее в четыре раза. Масштабируемость
позволяет выполнить за то же время в десять раз большую работу на машине,
которая крупнее в десять раз.
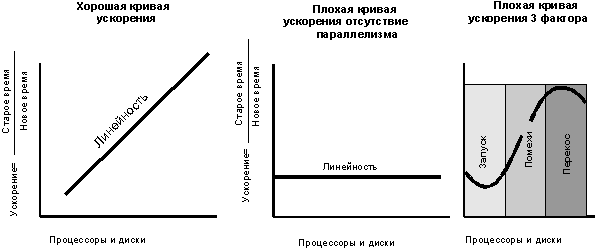
Рисунок 3.
Хорошие и плохие кривые ускорения. Стандартные кривые ускорения. Левая
кривая идеальна. Средняя диаграмма показывает отсутствие ускорения при
наращивании аппаратуры. На правой диаграмме показаны три основных угрозы
параллелизму. Прежде всего, могут доминировать затраты на запуск. По мере
увеличения числа процессов может расти число помех. Наконец, работа может
быть настолько мелко поделена, что задержку ее выполнения вызывают перекосы
времени обслуживания.
Более формально, если одна и та же работа выполняется сначала на меньшей системе, а затем на
более крупной, то ускорение, обеспечиваемое большей системой,
определяется таким образом:
ускорение = время_затраченное_меньшей_системой /
время_затраченное_большей_системой
Ускорение называется линейным, если в N раз большая или более дорогая
система обладает в N раз большим быстродействием.
Ускорение позволяет определить эффективность наращивания системы на
сопоставимых задачах. Масштабируемость позволяет измерять эффективность наращивания
системы на больших задачах. Масштабируемость определяется, как способность
в N раз большей системы выполнять в N раз большую работу за то же время,
что и исходная система. Коэффициент масштабируемости измеряется, как
коэффициент масштабируемости =
время_затраченное_меньшей_системой_на_ _решение_небольшой_задачи /
время_затраченное_большей_системой_ на_решение_большой_задачи
Если коэффициент масштабируемости равен 1, то масштабируемость называется
линейной2). Существуют два различных вида
масштабируемости: пакетная и транзакционная. Если суть работы состоит в выполнении
большого количества небольших независимых запросов от многих пользователей
к базе данных коллективного пользования, то свойство масштабируемости состоит
в удовлетворении в N раз большего числа запросов от большего в N раз числа
клиентов к большей в N раз базе данных. Такая масштабируемость характерна
для систем транзакционной обработки запросов и систем с разделением времени.
Этот вид масштабируемости используется Советом по оценке производительности обработки транзакций (Transaction Processing Performance Council) для определении масштабируемости при аттестации транзакционной
обработки запросов [36]. Соответственно этот вид масштабируемости называется
транзакционным. Транзакционная масштабируемость идеально подходит для
параллельных систем, так как каждая транзакция представляет собой небольшую
независимую работу, которая может выполняться на отдельном процессоре.
Второй вид масштабируемости, называемый пакетной масштабируемостью,
возникает, когда задача состоит в выполнении одной большой работы. Она
характерна для запросов к базам данных, а также для задач математического
моделирования. В этих случаях масштабируемость состоит в использовании в N
раз большего компьютера для решения в N раз большей задачи. Для систем
баз данных пакетная масштабируемость выражается во времени выполнения того
же запроса к в N раз более крупной базе данных, для научных задач пакетная
масштабируемость выражается во времени выполнения того же расчета на в N раз
более мелкой сетке или для в N раз более длительного моделирования.
Достижению линейного ускорения и линейной масштабируемости препятствуют следующие
три фактора:
Запуск: время, требуемое для запуска параллельной операции.
Если нужно запустить тысячи процессоров, то реальное время вычислений может
оказаться значительно меньше времени, требуемого для их запуска.
Взаимные помехи: появление каждого нового процесса ведет к замедлению
всех остальных процессов, использующих те же ресурсы.
Перекос: с увеличением числа параллельных шагов средняя продолжительность
выполнения каждого шага уменьшается, но отклонение от среднего значения
может значительно превзойти само среднее значение. Время выполнения работы
– это время выполнения наиболее медленного шага работы. Когда отклонение
от средней продолжительности превосходит ее саму, параллелизм позволяет
только слегка убыстрить выполнение работы.
В разделе "Подход к организации SQL-ориентированного программного обеспечения на основе параллельных
потоков данных" описывается несколько основных технологий, широко используемых
при создании машин параллельных баз данных без совместного использования
ресурсов для преодоления указанных барьеров. Эти технологии позволяют достичь
линейных ускорения и масштабируемости при выполнении реляционных операторов.
Аппаратная архитектура. Тенденция к применению машин без совместного использования ресурсов
Идеальная машина баз данных должна иметь один бесконечно быстрый процессор
с бесконечной памятью, обладающей бесконечной пропускной способностью, и быть бесконечно
дешевой (бесплатной). При наличии такой машины не надо заботиться об ускорениии,
масштабируемости и параллелизме. К несчастью, на современном уровне технологии
такой идеальной машины не существует, хотя имеющаяся технология обещает
нечто подобное в обозримом будущем. Современная технология обещает одночиповые
процессоры, быстрые диски большой емкости и электронную основную память
большой емкости. Эта технология также обещает, что каждое из таких устройств
будет весьма недорогим по сегодняшним меркам, всего несколько сотен долларов
каждое.
Таким образом, проблема состоит в создании бесконечно быстрого процессора
на основе бесконечно большого числа процессоров конечной скорости и создания
бесконечно большой памяти с бесконечной пропускной способностью на основе
бесконечного числа запоминающих устройств конечной скорости. Математически
эта проблема представляется тривиальной, однако на практике в большинстве
случаев при добавлении нового процессора все остальные начинают работать
чуть медленнее. Если замедление (помехи) равно 1%, то максимальное ускорение
равно 37, и эффективная мощность 1000-процессорной системы составляет лишь
4% эффективной мощности однопроцессорной системы.
Каким образом может быть построена масштабируемая многопроцессорная система?
Стоунбрейкер (Stonebraker) предложил следующую простую классификацию для целого спектра
разработок (см. рис. 4 и 5) [29]3).
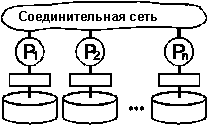
Рисунок 4.
Принципиальная схема аппаратного решения без совместного использования ресурсов. Каждый
процессор имеет свою память и один мли более дисков. Процессоры поддерживают
связь через высокоскоростную соединительную сеть. Примерами являются Teradata,
Tandem, nCUBE и последние модели VAXcluster.
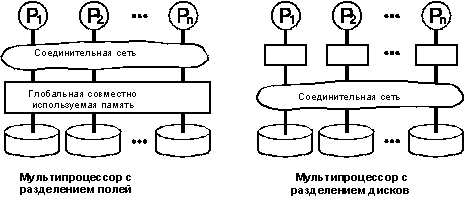
Рисунок 5.
Схема с совместным использованием памяти и дисков. Мультипроцессор с
общей памятью соединяет все процессоры с использованием глобальной совместно использумой
памяти. Типичными примерами машин с общей памятью являются многопроцессорные
компьютеры IBM/370, VAX и Sequent. Системы с совместным использованием дисков отводят
каждому процессору собственную память, но все процессоры могут непосредственно обращаться
к любому диску. Примерами являются VAXcluster компании Digital и Sysplex
компании IBM.
Совместно используемая память. Все процессоры имеют прямой доступ
к общей глобальной памяти и ко всем дискам. Примерами подобных систем являются
мультипроцессоры IBM/370, Digital VAX, Sequent Symmetry.
Совместно используемые диски. Каждый процессор имеет не только
свою собственную память, но и прямой доступ ко всем дискам. Примерами являются
IBM Sysplex и первоначальная версия Digital VAXcluster.
Отсутствие совместного использования ресурсов. Каждая память
и диск находятся в распоряжении какого-либо процессора, который работает
как сервер хранящихся в них данных. Массовое запоминающее устройство в
таких архитектурах распределено между процессорами посредством соединения
одного или более дисков. Примерами таких машин являются Teradata, Tandem
и nCUBE.
Архитектуры без совместного использования ресурсов сводят к минимуму
помехи посредством минимизации совместно используемых ресурсов. Кроме того,
при использовании массово производимых процессоров и памяти им не требуется
сверхмощная соединительная сеть. Как видно из рис. 5, при использовании другой архитектуры
через соединительную сеть передаются большие массивы данных, тогда как
при применении архитектуры без совместного использования ресурсов через сеть передаются
только вопросы и ответы. Непосредственные обращения к памяти и к дискам
обрабатывваются локальным процессором, и только отфильтрованные (урезанные)
данные передаются запрашивающей программе. Это позволяет реализовать более
масштабируемую архитектуру за счет минимизации трафика в соединительной сети.
Отсутствие совместного использования ресурсов характерно для систем
баз данных, используемых в проектах Teradata [33], Gamma [8, 9], Tandem
[32], Bubba [1], Arbre [21] и nCUBE [13]. Отметим, что VAXcluster компании
Digital эволюционировал в этом направлении. DOS- и UNIX-системы для рабочих
групп от 3com, Borland, Digital, HP, Novell, Microsoft и Sun также базируются
на архитектуре типа клиент-сервер без совместного использования ресурсов.
Реальные соединительные сети, используемые в этих системах, зачастую
совершенно не схожи друг с другом. Teradata использует избыточную древовидную
соединительную сеть. Tandem использует трехуровневую дуплексную сеть: два
уровня внутри кластера и кольца, соединяющие кластеры. Единственное требование,
которое предъявляют к соединительной сети Arbre, Bubba и Gamma, состоит
в существовании связи между любыми двумя узлами. Gamma работает на Intel
Hypercube. Прототип Arbre был реализован на основе процессоров IBM 4381,
соединенных друг с другом в сеть напрямую. Системы для рабочих групп переходят
с Ethernet на более высокоскоростные локальные сети.
Основным преимуществом мультипроцессоров без совместного использования
является то, что число процессов в них может наращиваться до сотен и даже тысяч без
возникновения каких-либо помех в работе одного со стороны другого. Компании
Teradata, Tandem и Intel запустили проекты систем с более чем 200 процессорами.
Intel разрабатывает гиперкуб с 2000 узлами. Максимальное число процессоров
в многопроцессорной системе с разделением памяти равно к настоящему моменту
32.
Эти архитектуры без совместного использования ресурсов позволяют достичь
почти линейного ускорения и масштабируемости на сложных реляционных запросах
и при транзакционной обработке запросов [9, 10, 32]. При наличии таких
результатов в качестве ориентира проектировщики машин баз данных не видят
смысла в выполнении сложных аппаратных и программных проектов с совместным
использованием памяти и дисков.
Системы с совместным использованием памяти и дисков не так то легко
масштабируются для приложений баз данных. Основная проблема для
мультипроцессоров с совместным использованием памяти – взаимные помехи. Соединительная
сеть должна иметь пропускную способность, равную сумме пропускных способностей
процессоров и дисков. Создать сеть, масштабируемую до тысячи узлов, – весьма
непростая задача. Для того чтобы уменьшить траффик в сети и свести к минимуму
время ожидания, каждому процессору придается большая собственная кеш-память.
Измерения мультипроцессоров с совместным использованием памяти, выполняющих
задачи с базами данных, показывает, что загрузка и выталкивание кэш-памяти
значительно снижает производительность процессоров [35]. При возрастании
параллелизма помехи при совместном использовании ресурсов ограничивают
рост производительности. Для уменьшения помех в многопроцессорных системах
часто используется механизм планирования в соответствии с родственностью,
предполагающий закрепление каждого процесса за конкректным процессором,
что является формой разделения данных и представляет собой переход к системам
без совместного использования ресурсов. Разделение системы с совместно используемой
памятью создает множество проблем, связанных с перекосом и балансировкой
нагрузки, которые характерны для машин без совместного использования ресурсов; но при
этом они не получают преимуществ более простой аппаратной связи. Опираясь
на этот опыт, мы считаем, что при работе с базами данных высокопроизводительные машины с совместным
использованием памяти экономически целесообразно масштабировать только до нескольких
процессоров.
Для борьбы с помехами во многих мультипроцессорах с совместным использованием
памяти применяется архитектура с совместным использованием дисков, что
является логическим следствием планирования по близости (affinity scheduling). Если дисковую
соединительную сеть можно масштабировать до тысяч дисков и процессоров, то схема
с совместным использованием дисков оказывается пригодной для больших баз данных,
предназначенных лишь для чтения, и для баз данных без совместного доступа.
Архитектура с совместным использованием дисков мало эффективна для прикладных
программ баз данных, которые считывают и записывает совместно используемые
данные. Если процессору нужно изменить какие-либо данные, он сначала должен
получить их текущую копию. Так как другие процессоры могут в это время
изменять те же самые данные, этот процессор должен заявить о своих намерениях.
Он может считать совместно используемые данные с диска и изменить их, только
когда его намерение одобрено всеми остальными процессорами. После этого
процессор должен записать совместно используемые данные на диск, чтобы
все остальные знали об этих изменениях при последующих чтении и записи.
Имеется множество оптимизаций этого протокола, но в конце концов они сводятся
к обмену сообщениями о резервировании данных и обмену большими физическими
массивами данных, что приводит к помехам и задержкам, а также к большому траффику
в совместно используемой соединительной сети.
Для прикладных программ с совместно используемыми данными подход с совместным
использованием дисков обходится значительно дороже, чем подход без совместного
использования ресурсов с обменом логическими вопросами и ответами высокого
уровня между клиентами и серверами. Один из способов избежать помех – закрепить
данные за процессором; другие процессоры, желающие получить доступ к данным,
посылают сообщения к серверам, управляющим данными. Такое решение возникло
на основе применения мониторов транзакций, которые разделяют
нагрузку между раздельными серверами. Кроме того, оно основано на механизме
вызова удаленных процедур. Подчеркнем еще раз, что тенденция к использованию разделения
данных и архитектуры без совместного использования ресурсов позволяет уменьшить
помехи в системах с совместно используемыми дисками. Поскольку соединительную
сеть системы с совместным использованием дисков практически невозможно
расширить до тысяч процессоров и дисков, многие сходятся на том, что лучше
с самого начала ориентироваться на архитектуру без совместного использования
ресурсов.
Почему проектировщики компьютеров не торопились взять на вооружение
подход без совместного использования ресурсов, зная о всех недостатках
совместного использования дисков? Первый ответ очень прост – высокопроизводительные
недорогие компоненты массового производства появились на рынке совсем недавно.
Как правило, ранее существовавшие компоненты этого рода отличались низкой
производительностью и низким качеством.
Сегодня основным барьером для
применения параллелизма является старое программное обеспечение. Такое программное обеспечение, написанное для
однопроцессорных машин, не дает ускорения или масштабируемости на многопроцессорных
машинах. Его необходимо переписать, чтобы извлечь выгоду из параллельной
обработки и возможности использования нескольких дисков. Прикладные программы
баз данных – редкое исключение. Сегодня большинство программ, связанных
с базами данных, написаны с примененем реляционного языка SQL, который был стандартизован
как ANSI, так и ISO. Программы на SQL, написанные для однопроцессорных
систем, можно выполнять параллельно на машинах баз данных без совместного
использования ресурсов. Системы баз данных могут автоматически распределять
данные между несколькими процессорами. При простом переносе прикладных
программ, основанных на стандартном SQL, в системы Teradata и Tandem достигается
почти линейные ускорение и масштабируемость. В следующем разделе разъясняются
основные технологии, используемые в подобных параллельных системах баз
данных.
Подход к организации SQL-ориентированного программного обеспечения на основе параллельных потоков данных
По мере уменьшения стоимости запоминающих устройств перестают быть
редкостью постоянно доступные
терабайтные базы данных, состоящие из миллиардов записей. Эти базы данных организуются и управляются на основе реляционной
модели языка SQL. В следующих нескольких абзацах дается элементарное введение
в концепцию реляционной модели, необходимое для понимания оставшейся части
статьи.
Реляционная база данных состоит из отношений (relation)
(или файлов в терминологии языка COBOL), которые в свою очередь содержат
кортежи (tuples) (записи в терминологии языка COBOL). Все
кортежи в отношении содержат один и тот же набор атрибутов (полей в терминологии
языка COBOL).
Отношения создаются, изменяются и запрашиваются посредством написания
операторов на языке SQL. Эти операторы являются синтаксическим облагораживанием
обычного набора операторов реляционной алгебры. Оператор выбора-проецирования
(select-project), называемый здесь просмотром (scan),
является простейшим и наиболее распространенным – он создает подмножество
строк и столбцов реляционной таблицы. Просмотр отношения R, используя предикат
P и список атрибутов L, обеспечивает на выходе реляционный поток данных.
Просмотр читает каждый кортеж t из R и применяет к нему предикат P. Если
P(t) истинно, то просмотр отбрасывает все атрибуты t, отсутствующие в L,
и вставляет результирующий кортеж в выходной поток просмотра. В терминах
SQL просмотр отношения телефонной книги для нахождения телефонных номеров
всех людей с фамилией Smith будет иметь вид, представленный на рис.
6. Выходной поток просмотра может быть послан другому реляционному оператору,
возвращен в прикладную программу, отображен на терминале или напечатан.
В этом красота и универсальность реляционной модели. Однородность данных
и операторов позволяет составлять из них графы потока данных произвольным
образом.
SELECT telephone_number /* атрибут(ы) вывода */
FROM telephone_book /* вводное отношение */
WHERE name = "Smith"; /* предикат */
Рисунок 6.
Пример просмотра отношения телефонной книги для нахождения телефонных номеров
всех людей по фамилии Smith.
Вывод просмотра может быть переслан оператору сортировки (sort),
который упорядочит кортежи в соответствии с критерием сортировки и удалит
дубликаты, если указана соответсвующая опция. SQL определяет несколько
агрегатных операций для свертывания атрибутов в одно значение, например,
для нахождения суммы, минимума или максимума атрибута, подсчитывания числа
различных значений атрибута. Оператор вставки (insert) добавляет
кортежи из потока данных в существующее отношение. Операторы изменения
(update) и удаления (delete) модифицируют, удаляют
кортежи в отношении при их совпадении с потоком просмотра.
В реляционной модели определяются несколько операторов для комбинирования
и сравнения двух или более отношений. В их число входят как обычные операции
объединения (union), пересечения (intersection)
и взятия разности (difference), так и более экзотичные операции,
такие как соединение (join) и деление (division).
Мы рассмотрим лишь оператор эквисоединения (equi-join, называемый
здесь просто соединением – join). Операция соединения производит
композицию двух отношений A и B по какому-либо атрибуту, образуя третье
отношение. Для каждого кортежа ta из отношения A соединение находит все
кортежи tb в отношении B, значения атрибутов которых равняются значению
ta. Для каждой найденной пары кортежей оператор соединения вставляет в
выходной поток кортеж, получаемый путем слияния двух исходных кортежей.
В классической статье Кодда показано, что любые виды данных могут быть
представлены в реляционном виде, и что перечисленные операции образуют полную систему
операций [5]. Сегодня прикладные программы на SQL, как правило, являются
комбинациями обычных программ и операторов SQL. Программы взаимодействуют
с клиентами, отображают данные и обеспечивают высокоуровневое направление
потока данных SQL.
Модель данных SQL была первоначально предложена с целью увеличить продуктивность
программистов посредством применения непроцедурного языка баз данных. Дополнительным
преимуществом стала независимость данных; поскольку программисты не определяют,
каким образом следует обрабатывать запрос, программы на SQL сохраняют работоспособность при изменении логических и физических схем баз данных.
Неожиданным преимуществом реляционной модели является параллелизм. Реляционные
запросы просто созданы для параллелизма, так как в действительности они
являются реляционными операциями, применяемыми к очень большим наборам
данных. Поскольку запросы представляются на непроцедурном языке, имеется
существенная свобода при выборе способа выполнения запросов.
Реляционные запросы могут выполняться в виде графов потоков данных. Такие
графы, как отмечалось в первом разделе данной статьи, могут использоваться как
при конвейерном, так и при разделенном параллелизме. Если одна операция
посылает свои результаты на вход другой операции, то эти две операции могут выполняться параллельно,
что в идеале обеспечивает ускорение в два раза.
Преимущества конвейерного параллелизма ограничены тремя факторами: 1)
Реляционные конвейеры редко бывает длинными – цепочки из десяти звеньев
встречаются редко. 2) Некоторые реляционные операторы не производят вывод,
пока не осуществят весь ввод. Таким свойством обладают агрегатные операторы
и операторы сортировки. Их невозможно поставить на конвейер. 3) Зачастую
стоимость выполнения одного оператора намного больше, чем других (пример перекоса).
В таких случаях ускорение, обеспечиваемое конвейеризацией, очень невелико.
Разделенный параллелизм предлагает лучшие возможности для ускорения
и масштабируемости. Беря большие реляционные операторы и разделяя их вводы
и выводы по принципу "разделяй и властвуй", можно превратить одну большую
работу во множество независимых небольших работ. Такая ситуация идеально
подходит для ускорения и масштабируемости. Разделение данных – ключ к раздельному
выполению.
Разделение данных. Разделение отношения подразумевает
распределение его кортежей между несколькими дисками. Разделение данных
происходит от централизованных систем, которые вынуждены разделять файлы, потому
что файл слишком велик для одного диска, или потому что невозможно обеспечить
приемлемую скорость доступа к файлу на одном диске. Разделение данных используется
в распределенных базах данных, когда части отношения помещаются в различные
узлы сети [23]. Разделение данных позволяет параллельным системам баз данных
использовать пропускную способность ввода/вывода нескольких дисковых устройств
путем параллельного чтения и записи. Такой подход обеспечивают более широкую
пропускную способность ввода/вывода, чем у систем, использующих RAID (дисковые
массивы), без применения какой-либо специальной аппаратуры [23, 24].
Простейшая стратегия разделения заключается в том, что кортежи распределяются
между фрагментами по принципу кольца (round-robin). Это разделенная версия классического
последовательного файла. Кольцевое разделение дает превосходные результаты,
если все прикладные программы нуждаются в получении доступа к отношению
путем полного последовательного просмотра его содержимого при каждом запросе.
Проблемой кольцевого разделения является то, что прикладным программам
часто бывает нужен ассоциативный доступ к кортежам в том смысле, что им требуется найти все кортежи, включающие заданное значение некоторого атрибута.
Запрос на языке SQL о всех людях по фамилии Smith в телефонной книге, представленный на рис. 6, является
примером ассоциативного поиска.
Разделение с хэшированием (hash partitioning) идеально подходит для прикладных программ,
которым требуется только последовательный и ассоциативный доступ к данным.
Кортежи размещаются в зависимости от значения хэш-функции, применяемой
к значению некторого атрибута каждого кортежа. Функция определяет конкретный диск,
на котором будет размещен кортеж. Ассоциативный доступ к кортежам с конкретным
значением атрибута может быть направлен к единственному диску, что исключает
накладные расходы на запуск запросов на нескольких дисках. Механизм разделения
с хэшированием используется в системах Arbre, Bubba, Gamma и Teradata.
В системах баз данных значительное внимание уделяется совместной кластеризации
родственных данных в физической памяти. Если кортежи какого-либо набора
кортежей обычно требуются вместе, то система баз данных пытается хранить
их в одной физической странице. Например, если к Smith'ам в телефонной
книге обычно обращаются в алфавитном порядке, то их записи следует хранить на
страницах в том же порядке; эти страницы следует совместно кластеризовать
на диске, чтобы можно было производить последовательную упреждающую
выборку и другие оптимизации. Кластеризация во многом зависит от специфики
прикладной программы. Например, в географических базах данных имеет
смысл кластеризовать кортежи, описывающие соседние улицы; в прикладной
программе управления инвентарными ведомостями кортежи, описывающие
пункты накладной, разумно кластеризовать с кортежем накладной.
Разделение с хэшированием ориентировано на случайное разделение данных,
а не на их кластеризацию. При разделении на основе диапазона значений (range partitioning)
в одном разделе совместно кластеризуются кортежи, имеющие одинаковые значения
атрибутов. Это подходит для последовательного и ассоциативного доступа
и дает хорошую основу для кластеризации. На рис. 7 показано такое разделение,
базирующееся на лексикографическом порядке, но возможен и любой другой
способ кластеризации. Разделение на основе диапазона значений получило
свое имя от типичного запроса на языке SQL с указанием диапазона значений
и специфицируется следующим образом:
latitute BETWEEN 38 AND 30
Разделение на основе диапазона значений используется в системах Arbre,
Bubba, Gamma, Oracle, Tandem.
При таком разделении возникает риск перекоса данных, когда все
данные помещаются в один раздел, и перекоса выполнения, когда все
выполнение происходит в одном разделе. Разделения на основе хэширования
и кольцевые разделения менее подвержены перекосам. При разделении на основе
диапазона значений перекосы можно свести к минимуму, используя критерий
разделения, в котором учитывается неравномерность распределения значений
атрибутов. В системе Bubba использование этой концепции основывается на
учете частоты обращений к каждому кортежу (" теплоты") при создании
разделов отношения. Цель заключается в том, чтобы сбалансировать частоту
доступа к каждому разделу (его " температуру"), а не реальное число
кортежей на каждом диске ("объем" раздела) [6].
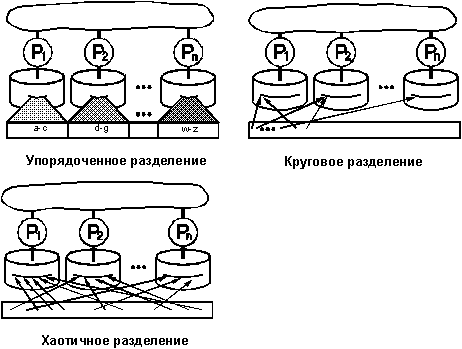
Рисунок 7.
Три основные схемы разделения. При разделении на основе диапазонов
значений смежные диапазоны атрибутов отношения отображаются на различные
диски. При круговом разделении i-ый кортеж отображается на диск с номером
i mod n. При разделении c хэшированием каждый кортеж отображается на место
на диске в зависимости от значения хэш-функции. При использовании каждой
схемы данные размещаются на нескольких дисках, что позволяет осуществлять
параллельный доступ и параллельную обработку.
Хотя концепция разделения проста и легко выполнима, она порождает ряд
новых вопросов, касающихся физического проектирования баз данных. Для каждого
отношения теперь должна быть стратегия разделения и набор дисковых фрагментов.
Увеличение степени разделения обычно уменьшает время ответа для отдельного
запроса и увеличивает общую пропускную способность системы. При последовательных
просмотрах время ответа уменьшается, потому что для выполнения запроса
используется большее число процессоров и дисков. При ассоциативных просмотрах
время отклика улучшается, потому что в каждом узле хранится меньшее число
кортежей и, следовательно, уменьшается размер индекса, который должен быть
использован для поиска.
Однако, начиная с некоторого момента при дальнейшем разделении время
ответа на запрос начинает возрастать. Это происходит, когда время запуска
запроса в узле становится существенной долей реального времени выполнения
запроса [6, 11].
Параллелизм внутри реляционных операторов. Разделение
данных является первым шагом к раздельному выполнению реляционных графов
потока данных. Основная идея состоит в использовании параллельных потоков
данных вместо написания новых параллельных операторов (программ). Этот
подход позволяет использовать без переделки существующие последовательные
программы для параллельного выполнения реляционных операций. Каждая реляционная
операция имеет набор портов ввода, на которые поступают входные
кортежи, и порт вывода, на который посылается выходной поток операции.
Параллельный поток данных разделяется и сливается в потоки данных через
эти последовательные порты. Такой подход позволяет параллельно выполнять
существующие последовательные реляционные операции.
Рассмотрим просмотр отношения A, которое было разделено между тремя
дисками на фрагменты A0, A1, A2. Этот просмотр можно реализовать с помощью
трех операций просмотра, которые направляют свой вывод на вход общей операции
слияния (merge operator). Операция слияния производит единый выходной поток данных и посылает
его прикладной программе или следующей реляционной операции. Управляющая
программа параллельного запроса создает три процесса просмотра, показанные
на рис. 8, и предписывает им вводить данные из трех различных последовательных
входных потоков (A0, A1, A2). Она также предписывает им послать вывод в
общий узел, где происходит слияние вывода. Каждый просмотр может выполняться
на отдельном процессоре и диске. Таким образом, первой нуждающейся в распараллеливании
операцией является операция слияния, который объединяет несколько
параллельных потоков данных в один последовательный поток.
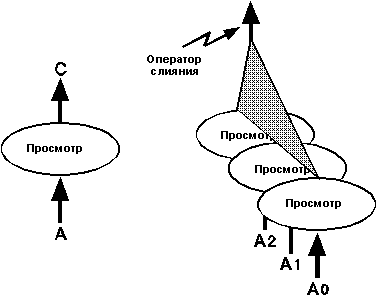
Рисунок 8.
Параллелизм разделенных данных. Простейший реляционный граф потока
данных, показывающий реляционный просмотр (выбор и проецирование), разложенный
на три просмотра по трем разделам входного потока или отношения. Эти три
просмотра посылают свой вывод в узел, где они сливаются в один выходной
поток данных.
Оператор слияния собирает данные в одном месте. Если требуется параллельно
выполнить многофазную параллельную операцию, то единый поток данных должен
быть расщеплен на несколько независимых потоков. Оператор расщепления (split operator)
используется для разделения или реплицирования потока кортежей, производимого
реляционным оператором. Оператор расщепления определяет отображение одного
или более значений атрибутов выходных кортежей на набор назначенных процессов
(см. рис. 9).
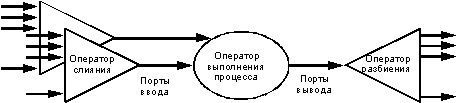
Рисунок 9.
Объединение ввода и разделение вывода оператора. Реляционный граф потока
данных, показывающий, как входные данные реляционного оператора сливаются
в последовательный поток через порт. Вывод оператора разделяется оператором
расщепления на несколько независимых потоков. Каждый поток может быть сдублирован
или разделен на множество несвязанных потоков. При помощи операторов расщепления
и слияния паутина узлов простого последовательного потока данных может
быть соединена в параллельный план выполнения.
В качестве примера рассмотрим два оператора расщепления (см. Таблицу
1) в связи с запросом на языке SQL, представленном на рис. 10. Предположим,
что три процесса используются для выполнения оператора соединения, а пять
других – для выполнения двух операторов просмотра – три просмотра разделов
отношения A при двух просмотрах разделов отношения B. В каждом из трех узлов
просмотра отношения A будет выполняться одна и та же операция разбиения, посылающая
все кортежи со значениями в промежутке "A-H" на порт 1 процесса слияния
0, все кортежи со значениями в промежутке "I-Q" – на порт 1 процесса слияния
1 и все кортежи со значениями в промежутке "R-Z" – на порт 1 процесса слияния
2. Аналогично, а двух узлах просмотра отношения B будет выполняться та же самая операция
расщепления с той разницей, что их вывод сливается портом 1 (не портом 0)
каждого процесса слияния. Каждый процесс слияния видит последовательный
входной поток кортежей A как слитый в порту 0 (левые узлы просмотра) и
другой последовательный поток кортежей B как слитый в порту 1 (правые узлы
просмотра). В свою очередь, выходные потоки каждого соединения разделяются
на три потока в соответствии с критерием разделения отношения C.
Таблица 1
Пример операторов расщепления
Каждая операция расщепления отображает кортежи на множество выходных
потоков (портов других процессов) в зависимости от порядкового значения
(предиката) входного кортежа. Оператор расщепления в левой части таблицы относится к просмотру
отношения A на рис. 10, а в правой – к просмотру отношения B. В таблице
кортежи разделены между тремя потоками данных.
|
Операция расщепления
|
просмотра отношения A
|
Операция расщепления
|
просмотра отношения B
|
|
Предикат
|
Назначенный процесс
|
Предикат
|
Назначенный процесс
|
|
"A-H"
|
(ЦПУ #5, Процесс #3,Порт #0)
|
"A-H"
|
(ЦПУ #5, Процесс #3, Порт #1)
|
|
"A-H"
|
(ЦПУ #5, Процесс #3,Порт #0)
|
"A-H"
|
(ЦПУ #5, Процесс #3, Порт #1)
|
|
"I-Q"
|
(ЦПУ #7, Процесс #8, Порт #0)
|
"I-Q"
|
(ЦПУ #7, Процесс #8, Порт #1)
|
|
"R-Z"
|
(ЦПУ #2, Процесс #2, Порт #0)
|
"R-Z"
|
(ЦПУ #2, Процесс #2, Порт #1)
|
insert into C
select *
from A, B
where A.x = B.y;
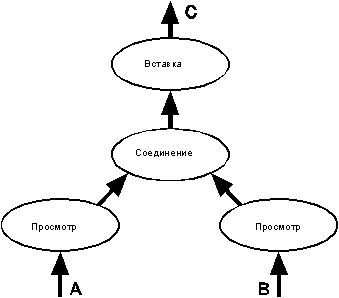
Рисунок 10.
Простой SQL запрос и реляционный граф этого запроса. Запрос указывает,
что необходимо произвести соединение отношения A и отношения B посредством
сравнения атрибута x каждого кортежа из отношения A со значением атрибута
y каждого кортежа из отношения B. Для каждой пары кортежей, удовлетворяющих
заданному предикату, формируется новый кортеж со всеми атрибутами двух
исходных кортежей. Полученный кортеж затем добавляется к формируемому отношению
C. На логическом графе этого запроса (каким его может создать оптимизатор
запроса) показаны три оператора – один для слияния, другой для вставки
и третий для просмотра каждого входного отношения.
Поясним этот пример. Рассмотрим первый процесс соединения на рис. 11
(процессор 5, процесс 3, порты 0 и 1 в таблице 1). Он будет получать все
кортежи отношения A в диапазоне "A-H" от трех операторов просмотра отношения
A, слитые в единый поток в порту 0, и все кортежи отношения B в диапазоне
"A-H", слитые в единый поток в порту 1. Затем процесс будет соединять эти
кортежи, используя соединение с хэшированием, соединение методом вложенных циклов
или даже соединение сортировкой-слиянием, если кортежи прибывают в
нужном порядке.
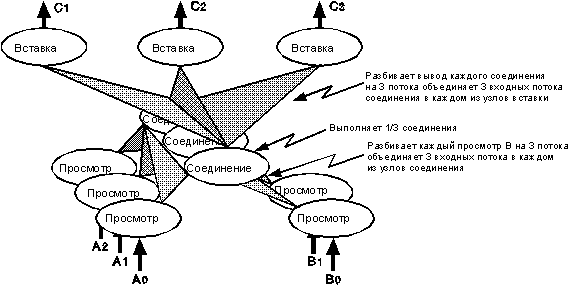
Рисунок 11.
Простейший реляционный граф потока данных. Показаны два реляционных
просмотра (проецирование и выбор), потребляющих два входных отношения A
и B и отдающих свой вывод оператору соединения, который в свою очередь
создает поток данных C.
Если каждый из этих процессов выполняется на независимом процессоре с
независимым диском, то помехи практически не возникнут. Такая схема потока
данных естественна для архитектуры машин без совместного использования
ресурсов.
Операция расщепления, показанный в таблице 1, является только примером.
Другие операции расщепления могли бы тиражировать входной поток или разделять
его по кругу или на основе хэширования. Функции разделения может выполнять
любая программа. Такой подход используется в системах Gamma, Volcano и
Tandem [14]. Он имеет несколько преимуществ,включая автоматическое распараллеливание
любого нового оператора, добавляемого к системе; к тому же он поддерживает
многие виды параллелизма.
Операции расщепления и слияния имеют встроенное управление потоками
и буферизацию. Это позволяет избежать ситуации, когда одна операция намного
опередит другую в своем выполнении. Когда буферы выходных данных операции расщепления
заполняются, он блокирует реляционную операцию до тех пор, пока из места
назначения данных не потребуют следующую порцию выходных данных.
Для простоты в этих примерах считалось, что одной операции соответствует
один процесс. Однако вполне возможно поместить в один
процесс несколько операций, что даст более грубый параллелизм. Основная идея состоит в том,
чтобы построить самоуправляемый граф потока данных и распределить его в
машине без совместного использования ресурсов таким образом, чтобы помехи
были минимальными.
Специальные параллельные реляционные операции. Некоторые
алгоритмы реляционных операций являются особенно подходящими для параллельного
выполнения, потому что они либо сводят к минимуму поток данных, либо более терпимы к перекосам в данных и выполнении. Для большинства
реляционных операций были найдены улучшенные алгоритмы. Как пример улучшения
алгоритмов здесь кратко описывается эволюция алгоритма операции соединения.
Напомним, что операция соединения комбинирует два отношения A и B таким
образом, что в результате получается отношение C, содержащее все пары кортежей
из A и B с совпадающими значениями заданных атрибутов. Обычный способ вычисления
соединения состоит в сортировке обоих отношений A и B с получением двух
новых отношений, упорядоченных по значениям атрибута соединения. Эти два
новых отношения затем сравниваются в отсортированном порядке, и соответствующие
кортежи вставляются в поток вывода. Такой алгоритм называется сортировкой-слиянием (sort-merge).
Возможны различные оптимизации соединения сортировкой-слиянием, но поскольку
стоимость сортировки равна nlog(n), то и стоимость выполнения соединения
сортировкой-слиянием равняется nlog(n). Алгоритм сортировки-слияния хорошо
работает в среде параллельных потоках данных, если нет перекоса данных.
Если имеется перекос данных, то некоторые разделы сортировки могут оказаться
гораздо больше других. Это в свою очередь приводит к перекосам в выполнении
и ограничивает ускорение и масштабируемость. При централизованном выполнении
соединений сортировкой-слиянием проблемы с перекосом не возникают.
Соединение с хэшированием (hash-join) является альтернативой соединению методом
сортировки-слияния. Стоимость выполнения соединения этим методом возрастает
линейно, а не как nlog(n), и метод более устойчив к перекосам данных. Соединение
с хэшированием предпочтительнее, чем сортировка-слияние, если только входные
потоки уже не отсортированы. Соединение с хэшированием работает следующим
образом. Каждое из отношений A и B сначала разделяется на основе хэширования
по атрибуту соединения. Хэш-раздел отношения A размещается в памяти. Просматривается
соответствующий раздел отношения B, и каждый кортеж сравнивается со всеми
кортежами хэш-раздела отношения A. Если установлено соответствие, то пара
кортежей посылается в выходной поток. Таким образом обрабатывается каждая
пара хэш-разделов.
Алгоритм соединения с хэшированием разбивает большое соединение на множество
мелких соединений. При выборе хорошей хэш-функции и наличии не слишком больших
перекосах в данных размеры блоков, содержащих кортежи с одинаковым значением
хэш-функции, отличаются незначительно. В этих случаях соединение с хэшированием
представляет собой линейный по времени алгоритм соединения с линейными
ускорением и масштабируемостью. За последнее десятилетие появилось множество
оптимизаций параллельного алгоритма соединения с хэшированием. В случае
патологических перекосов, когда многие или все кортежи имеют то же самое
значение атрибута, один блок может содержать все кортежи. Алгоритм, способный
обеспечить ускорение и масштабируемость в этих случаях, не известен.
Пример соединения с хэшированием показывает, что новые параллельные
алгоритмы могут улучшать производительность реляционных операторов. Это
благодатная область для исследований [4, 8, 18, 20, 25, 26, 38, 39]. Хотя
параллелизм может быть достигнут на основе традиционных последовательных
реляционных алгоритмов при помощи операторов расщепления и слияния, мы
надеемся, что в будущем будут изобретены многие новые алгоритмы.
Состояние дел
Teradata
Компания Teradata впервые выдвинула многие идеи, представленные в этой
статье. Начиная с 1978 года, они создают высокопараллельные, основанные
на языке SQL системы без совместного использования ресурсов на базе массово
производимых микропроцессоров, дисков и памяти. Системы Teradata действуют
как SQL-серверы для пользовательских программ, запущенных на обычных компьютерах.
Системы Teradata могут иметь свыше 1000 процессоров и много тысяч дисков.
Функционально процессоры Teradata делятся на две группы: интерфейсные процессоры
(IFP) и процессоры-модули доступа (AMP). Интерфейсные процессоры поддерживают
связь с основной машиной, осуществляют синтаксический разбор и оптимизацию
запросов, а также координацию AMP во время выполнения запросов. Процессоры-модели
доступа отвечают за выполнение запросов. Как правило, каждый AMP имеет
несколько дисков и большую кэш-память. IFP и AMP соединены двойной избыточной
древовидной сетью, называемой Y-сетью [33].
Каждое отношение разделено на основе хэширования между подмножествами
AMP. При вставке кортежа в отношение к первичному ключу кортежа применяется
хэш-функция для выбора AMP, где будет храниться этот кортеж. Как только
кортеж поступает в AMP, применяется вторая хэш-функция для определения
положения кортежа в его фрагменте отношения. Кортежи в каждом фрагменте
располагаются в соответствии со значением этой хэш-функции. При заданном
значении ключевого атрибута можно найти кортеж в единственном AMP. AMP
проверяет свою кэш-память, и если в ней такого кортежа нет, то выбирает
его за одно чтение диска. Поддерживаются также вторичные хэш-индексы.
Хэширование используется для расщепления вывода реляционных операторов
в промежуточные отношения. Операторы соединения выполняются с использованием
параллельного алгоритма сортировки-слияния. Вместо конвейерного параллельного
выполнения при обработке запроса используется следующая стратегия: каждый
оператор полностью выполняется во всех участвующих узлах, прежде чем начинается
выполнение следующего оператора.
Компания Teradata инсталлировала множество систем, содержащих свыше
100 процессоров и сотни дисков. Эти системы демонстрируют почти линейные
ускорение и масштабируемость на реляционных запросах и значительно превосходят
по скорости традиционные машины основного класса при обработке больших
(терабайтных) баз данных.
Tandem Nonstop SQL
Система Tandem Nonstop SQL составлена из кластеров процессоров, соединенных
квадраплексными волоконно-оптические кольцами. В отличие от большинства
других систем, обсуждаемых в данной статье, в системах Tandem прикладные
программы выполняются на тех же процессорах и в тех же операционных системах,
что и серверы баз данных. Не различаются внешние и внутренние программы
и машины. Системы сконфигурированы таким образом, что каждому процессору
MIPS соответствует отдельный диск, так что каждый кластер из 10 MIPS содержит
10 дисков. Как правило, диски дуплексные [2]. Каждый диск обслуживается
набором процессов, управляющих большой совместно используемой кэш-памятью
прямого доступа, набором блокировок и журналом записей для данных на этой
паре дисков. Затрачиваются значительные усилия на оптимизацию последовательного
просмотра путем предварительного считывания больших объемов данных и фильтрации
и обработки кортежей на этих дисковых серверах на основе предикатов SQL.
Это позволяет минимизировать траффик в совместно используемой соединительной
сети.
Можно разделить отношения между
несколькими дисками в соответствии с диапазонами значений. Поддерживаются последовательная, относительная организации
данных и организация на основе B-деревьев. Поддерживаются только вторичные
индексы, основанные на B-деревьях. Используются алгоритмы соединения, основанные
на вложенных циклах, сортировке-слиянии и хэшировании. Распараллеливание
операторов в плане запроса достигается включением операций расщепления
и слияния между узлами операторов в дереве запроса. Просмотры, агрегации,
соединения, обновления и удаления выполняются параллельно. Кроме того,
параллелизм используется и в некоторых утилитах (например, загрузка, реорганизация,
...) [31, 39].
Системы Tandem создавались, прежде всего, для обработки транзакций в режиме
on-line (OLTP) – обработки большого количества небольших транзакций в больших
совместно используемых базах данных. Помимо параллелизма, получаемого при
параллельном выполнении большого числа независимых транзакций, основной
возможностью OLTP является параллельное обновление индексов. Обычно на
SQL-отношении определяется около пяти индексов, хотя и десять индексов
для отношения отнюдь не редкость. Эти индексы позволяют ускорить чтение,
но замедляют вставки, обновления и удаления. При параллельном работе с
индексами время обработки нескольких индексов можно поддерживать практически
постоянным (независимо от числа индексов), если индексы распределены между
многими процессорами и дисками.
В целом системы Tandem демонстрируют почти линейную масштабируемость при
обработке транзакций и почти линейное ускорение и масштабируемость при выполнении
больших реляционных запросов [10, 31].
Gamma
Текущая версия системы Gamma работает на Intel iPSC/2 Hypercube с 32
узлами, каждый из которых имеет собственный диск. Помимо кольцевого, диапазонного
и хэшированного разделения, в системе Gamma используется гибридное разделение,
сочетающее лучшие черты стратегий диапазонного и хэшированного разделений
[12]. После того как отношение разделено, Gamma образует кластеризованные
и некластеризованные индексы как на атрибутах, на основе которых производилось
разделение, так и на других атрибутах. Индексы реализуются как B-деревья
или хэш-таблицы.
Gamma использует операторы расщепления и слияния для выполнения операций
реляционной алгебры с использованием и распараллеливания, и конвейеризации
[9]. Поддерживается метод соединения на основе сортировки-слияния и три
разных метода соединения с хэшированием [7]. Измерения, произведенные на
этой архитектуре, показывают наличие почти линейных ускорения и масштабируемости
при выполнении реляционных запросов [9, 25, 26].
Суперкомпьютер баз данных
Проект суперкомпьютера баз данных (Super Database Computer – SDC) токийского
университета обладает интересными отличиями от других систем баз данных
[16, 20]. В SDC используется комбинированный аппаратно-программный подход
к решению проблемы производительности. Основное устройство, называемое
обрабатывающим модулем (Processing Module – PM), состоит из одного или
более процессоров с совместно используемой памятью. Эти процессоры дополняются
специализированным устройством сортировки, которое производит сортировку
с высокой скоростью (3 Мб в секунду в настоящее время), и дисковой подсистемой
[19]. Кластеры обрабатывающих модулей соединены через омега-сеть, которая
обеспечивает как неблокирующее соединение N*N, так и некоторую динамическую
маршрутизацию, сводящую к минимуму перекосы в распределении данных при
соединениях с хэшированием. SDC может быть расширен до тысячи PM, и по
этому проблеме перекоса данных уделяется значительное внимание.
Данные разделяются между PM посредством хэширования. Программное обеспечение
SDC включает оригинальную операционную систему и управляющую программу
запросов к реляционным базам данных. SDC представляет собой машину без
совместного использования ресурсов с программной архитектурой потока данных.
Это согласуется с нашим утверждением о том, что современные параллельные
машины баз данных основываются на традиционных аппаратных средствах. Однако
наличие специализированной омега-сети и аппаратно реализованных средств
сортировки явно противоречат тезису, что специализированные аппаратные
средства не могут служить хорошей базой для дальнейших разработок. Время
покажет, смогут ли такие специализированные компоненты обеспечить лучшее
соотношение цены и производительности или более высокую пиковую производительность
по сравнению с разработками без совместного использования ресурсов, базирующимися
на традиционных аппаратных средствах.
Bubba
Прототип Bubba был реализован на основе мультипроцессора FLEX/32 с 40
узлами и 40 дисками [4]. Хотя сам мультипроцессор обладает общей
памятью, Bubba проектировалась как система без совместного использования
ресурсов, и общая память используется только для передачи
сообщений.
Узлы разделены на три группы: интерфейсные процессоры (Interface
Processors) для общения с процессорами внешней главной машины и координации
выполнения запросов, интеллектуальные хранилища (Intelligent Repositories)
для хранения данных и выполнения запросов и хранилища контрольных точек
и журнальной информации (Checkpoint\Logging Repositories).
Хотя в системе
Bubba также используются разделение в качестве механизма хранения данных
(используются диапазонное и хэшированное разделения) и механизмы обработки
потоков данных, система обладает несколькими уникальными особенностями.
Во-первых, в качестве интерфейсного языка используется FAD, а не SQL. FAD
является расширенным реляционным языком программирования, поддерживающим
стабильно хранимые данные. FAD обеспечивает поддержку сложных объектов
с помощью нескольких конструкторов типов, включающих возможности использования
разделяемых подобъектов, ориентированных на множества примитивов манипулирования
данными и более традиционные языковые конструкций. На компилятор FAD возложена
обязанность в соответствии с разделением требуемых объектов данных распознавать
операции, которые могут быть выполнены параллельно. Выполнение программ
основывается на парадигме потока данных. Задача компилирования и распараллеливания
FAD-программ значительно труднее, чем задача распараллеливания реляционного
запроса.
Другая особенность Bubba – использование одноуровневого механизма
хранения, когда стабильная база данных в каждом узле отображается в адресное
пространство виртуальной памяти каждого процесса, выполняющегося в этом
узле. Это отличается от традиционного подхода с применением файлов и страниц.
Аналогичные механизмы используются в AS400 компании IBM при отображении
основанных на языке SQL баз данных в виртуальную память, в системах компании
HP – при отображении Image Database в виртуальное адресное пространство операционной
системы и в отображаемой в виртуальную память файловой системы, реализованной
в операционной системе Mach [34]. Такой подход позволил упростить реализацию
верхних уровней программного обеспечения Bubba.
Другие системы
Среди других прототипов систем параллельных баз данных можно назвать
XPRS [30], Volcano [14], Arbre [21] и разрабатываемый исследовательскими
лабораториями IBM в Hawthorne и Almaden проект PERSIST. Хотя и Volcano,
и XPRS реализованы на основе мультипроцессоров с совместно используемой
памятью, XPRS отличается возможностью применения массивной общей
памяти. Кроме того, в системе XPRS используется несколько
новейших методов, позволяющих достичь чрезвычайно высокого уровня производительности
и доступности.
Недавно появилась система баз данных Oracle на основе системы без совместного
использования ресурсов nCUBE с 64 узлами. Эта система впервые в истории
достигла производительности более 1000 транзакций в секунду на стандартном
индустриальном тестовом наборе TPC-B. Продемонстрированные результаты существенно
превосходят показатели Oracle в системах, основанных на традиционных компьютерах
основного класса, как по пиковой производительности, так по соотношению
цена/производительность [13].
Корпорация NCR заявила о серии продуктов 3600 и 3700, в которых используется
архитектура без совместного использования ресурсов с примененением версии
ОС UNIX System V R4 на процессорах Intel 486 и 586. В связной сети для
серии 3600 используется усовершенствованный лицензионный продукт Y-net
компании Teradata, а серия 3700 базируется на новой многоуровневой сети,
разработанной совместно NCR и Teradata. Было заявлено о двух программных
продуктах. Первый продукт, произведенный путем переноса программного обеспечения
Teradata в среду ОС UNIX, ориентирован на применение в области принятия
решений. Второй продукт, основанный на параллельной версии СУБД Sybase,
предназначен прежде всего для обработки транзакций.
Машины баз данных и закон Гроша
Современные машины баз данных без совместного использования ресурсов
обладают максимальной произодительностью и обеспечивают наилучшее соотношение
цена/производительность. Например, при линейном масштабировании системы Tandem
на тестовом наборе TPC-A достигаются показатели, существенно превосходящие
наилучшие результаты, полученные при использовании компьютеров основного
класса. На этих тестовых наборах соотношение цена/производительность системы
Tandem в три раза меньше, чем аналогичные показатели для машин основного
класса. Oracle на nCUBE имеет наилучшие показатели на тестовом наборе TPC-B
и вполне приемлемое соотношение цена/производительность [13, 36]. Результаты
показывают линейную масштабируемость при применении тестовых наборов обработки
транзакций.
Системы Gamma, Tandem и Teradata демонстрируют линейные ускорение и
масштабируемость на тестовых наборах со сложными реляционными базами данных.
Системы масштабируются далеко за размеры наибольших компьютеров основного
класса. Их производительность и соотношение цена/производительность, как
правило, превосходят возможности систем, основанных на компютерах основного
класса.
Приведенные наблюдения не согласуется с законом Гроша. В шестидесятые
годы Герб Грош (Herb Grosch) обнаружил существование экономики масштабируемости
в области использования компьютеров. В то время дорогие компьютеры значительно
превосходили по мощности дешевые. Обеспечивались сверхлинейные ускорение
и масштабируемость. Это отражается в современные ценах для компьютеров основного
класса – $25000 за MIPS (за миллион инструкций в секунду) и $1000 за 1
MB основной памяти. В то же время для микропроцессоров установились цены
в $250 за MIPS и $100 за 1 MB памяти.
Комбинируя сотни и тысячи таких малых систем, можно построить чрезвычайно
мощную машину баз данных за гораздо меньшую цену, чем стоимость скромного
компьютера основного класса. Почти линейные ускорение и масштабируемость машин
без совместного использования ресурсов позволяют им при решении задач,
связанных с базами данных, превосходить современные компьютеры основного
класса с совместным использованием памяти и дисков.
Закон Гроша более не применим к проблемам баз данных и обработки транзакций.
Нет экономики масштабируемости. В лучшем случае можно ожидать линейного ускорения
и масштабируемости производительности и соотношения цена/производительность.
К счастью, архитектуры без совместного использования обеспечивают этот
почти линейный рост производительности.
Будущие направления и исследовательские проблемы
Смешивание пакетных и OLTP запросов
Во втором разделе этой статьи "Основные технологии для параллельных
машин баз данных" рассматривались основные технологии, используемые при
обработке сложных реляционных запросов в параллельных системах баз данных.
При одновременном выполнении как простых, так и сложных запросов, возникает
сразу несколько проблем, которые до сих пор не решены.
Во-первых, при выполнении больших реляционных запросов обычно устанавливается
много блокировок, и они удерживаются довольно долго. Это препятствует обновлению
данных простыми транзакциями. В настоящее время предлагаются два решения, первое из которых состоит в
предоставлении интерактивным запросам нечеткой картины базы данных без блокирования
данные во время просмотра. Такое "грязное чтение" не приемлемо для некоторых
прикладных программ. Некоторые системы предлагают механизм версий, который
обеспечивает согласованную (старую) версию базы данных при чтении и позволяет
создавать новые версии объектов при обновлении. Мы надеемся, что найдутся
лучшие решения этой проблемы.
Другая проблема – распределение приоритетов при смешанной рабочей загрузке.
Пакетные работы обладают тенденцией к монополизации процессора, заполнению
кэша и большой интенсивности ввода/вывода. Задачей операционной системы
становится умельчение и ограничение ресурсы, используемых пакетными работами,
для обеспечения быстрого отклика и небольших отклонений во времени отклика
для коротких транзакций. Очень сложна проблема инверсии приоритетов, когда
клиент с низким приоритетом обращается к серверу с высоким приоритетом.
Сервер должен выполняться с высоким приоритетом, так как он управляет жизненно
важными ресурсами. И если низкоприоритетный запрос обслуживается высокоприоритетным
сервером, работа низкоприоритетного клиента фактически становится высокоприоритетной.
Предпринимались попытки решения этой проблемы в конкретных ситуациях, но
приемлемые решения так и не были найдены.
Оптимизация параллельных запросов
Существующие оптимизаторы запросов к базам данных при оптимизации реляционного
запроса не рассматривают все возможные планы. Несмотря на то, что стоимостные
модели для реляционных запросов, выполняемых на одном процессоре, детально
разработаны [27], они по-прежнему зависят от оценок стоимости, которые
можно производить весьма и весьма приблизительно. В некоторых системах
выбор между несколькими планами производится динамически во время выполнения
в зависимости, например, от объема реально доступной физической памяти
и мощности промежуточных результатов [15]. В настоящее время ни один оптимизатор
запросов не учитывает все параллельные алгоритмы для каждой операции
и все возможные организации дерева запросов. Исследования в этой области
еще не завершены.
Другая задача оптимизации касается сильно скошенных распределений значений.
Перекос данных может привести к значительным отклонениям в размере промежуточных
отношений, что приводит к черезчур грубым оценкам стоимости плана запросов
и ускорению хуже линейного. Сейчас идет активный поиск решения этой проблемы
[17, 20, 37, 38].
Распараллеливание прикладных программ
Параллельные системы баз данных обеспечивают параллелизм на уровне системы
баз данных. В них отсутствуют средства для структурирования прикладных
програм, что позволило бы воспользоваться преимуществами параллелизма,
присущего таким системам. Хотя вряд ли возможно автоматически распараллелить
прикладные программы, написанные на COBOL, требуются библиотечные пакеты
для поддержки явно параллельных программ. В идеале в пакет следовало бы
включить операторы SPLIT (расщепление) и MERGE (слияние), чтобы ими могли
воспользоваться прикладные программы.
Физическое проектирование баз данных
Для заданных базы данных и рабочей нагрузки существует множество возможных
комбинаций индексирования и разделения. Необходимы средства проектирования
баз данных, которые помогли бы администратору системы выбрать между многочисленными
проектными вариантами. Такие средства могли бы получать на входе описание
запросов, из которых состоит рабочая нагрузка, частоту их выполнения, статистическую
информацию об отношениях в базе данных и описание процессоров и дисков,
а на выходе выдавали бы стратегию разделения для каждого отношения и индексы,
которые следует создать для каждого отношения. Сделаны первые шаги в этом
направлении.
Имеющиеся алгоритмы разделяют отношения по значению одного единственного
атрибута. Например, географические записи могут быть разделены по широте
или долготе. Разделение по долготе позволяет разместить выборки в некотором
диапазоне широт в ограниченном числе узлов, а выборки по широте должны
быть посланы во все узлы. Это приемлемо для небольших конфигураций, но
не годится для системы с тысячами процессоров. Многомерное разделение и
алгоритмы поиска нуждаются в дополнительных исследованиях.
Реорганизация данных в режиме on-line и утилиты
Загрузка, реорганизация и разгрузка терабайтной базы данных со скоростью
1 Мб в секунду занимает более 12 дней и ночей. Очевидна необходимость параллелизма
для завершения работы утилиты за несколько часов или дней. Однако и в этом
случае существенно, чтобы во время работы утилиты данные оставались доступными.
В мире SQL типичные утилиты создают индексы, добавляют или удаляют атрибуты,
добавляют ограничения целостности и физически реорганизуют данные, изменяя
их кластеризацию.
Не исследованной и трудной проблемой является обеспение нормальной работы
системы и доступности данных для чтении и записи другими программами и
пользователями при выполнении вспомогательных команд. Такие алгоритмы должен
обладать следующими основными свойствами: работа в режиме on-line (выполнение
утилит не должно приводить к недоступности данных), инкрементность (возможность
работать с частями большой базы данных), параллельность (использование
возможностей параллельных процессоров) и обратимость (возможность отмены
операции и возврата к предыдущему состоянию).
Заключение
Как и для большинства прикладных программ, для систем баз данных желательно
иметь дешевое и быстрое аппаратное обеспечение. Сегодня это означает типовые
процессоры, память и диски. Следовательно, аппаратная концепция машины
баз данных, основанной на экзотических аппаратных средствах, не отвечает
требованиям современной технологии. С другой стороны, доступность быстрых
микропроцессоров и небольших недорогих дисков, собранных в стандартные
недорогие, но быстрые компьютеры, служит идеальной платформой для параллельных
систем баз данных. Архитектура без совместного использования ресурсов сравнительно
проста в реализации и, что более важно, позволяет достичь ускорения и масштабируемости
до сотен процессоров. Кроме того, архитектура без совместного использования
ресурсов реально упрощает реализацию программного обеспечения. При применении
программных методов разделения данных, потока данных и внутриоператорного
параллелизма задача преобразования существующей СУБД в высоко параллельную
– сравнительно проста. Наконец, имеются некоторые прикладные программы
(связанные, например, с обработкой данных в терабайтных базах данных),
которые требуют таких вычислительных ресурсов и ресурсов ввода/вывода,
которые предоставляют только параллельные архитектуры.
В то время, как успехи коммерческих продуктов и прототипов демонстрируют
жизнеспособность высоко параллельных машин баз данных, несколько исследовательских
вопросов по-прежнему остаются нерешенными. Среди них методы смешивания
интерактивных запросов с обработкой транзакций в режиме on-line без серьезного
замедления скорости обработки транзакций, улучшение качества оптимизаторов
параллельных запросов, средства физического проектирования баз данных,
средства реорганизации данных в режиме on-line и алгоритмы обработки отношений
с сильно скошенными распределениями данных. В некоторых областях возможности
реляционной модели данных не являются достаточными. Похоже, необходим новый
класс систем баз данных на основе объектно-ориентированных моделей данных.
Такие системы ставят множество интересных исследовательских проблем, которые
нуждаются в дальнейшем изучении.
Литература
- Alexander, W., et al. Process and dataflow control in distributed data-intensive
systems. In Proceedings of ACM SIGMOD Conference (Chicago, Ill., June 1988)
ACM, NY, 1988.
- Bitton, D. and Gray, J. Disk shadowing. In Procceding of the Fourteenth
International Conference on Very Large Data Bases (Los Angeles, Calif.,
August, 1988).
- Boral, H. and DeWitt, D. Database machines: An idea whose time has
passed? A critique of the future of the database machines. In Proceedings
of the 1983 Workshop on Database Machines. H.-O. Leilich and M. Missikoff,
Eds., Springer-Verlag, 1983.
- Boral, H. et al. Prototyping Bubba: A highly parallel database system.
IEEE Knowl. Data Eng. 2,1,(Mar. 1990).
- Codd, E.F. A relational model of data for large shared databanks. Commun.
ACM 13, 6 (June 1970).
- Copeland, G., Alexander, W., Boughter, E., and Keller, T. Data placement
in Bubba. In Proceedings of ACM-SIGMOD International Conference on Management
of Data (Chicago, May 1988).
- DeWitt, D.J., Katz, R., Olken, F., Shapiro, D., Stonebraker, M. and
Wood, D. Implementation techniques for main memory database systems. In
Proceedings of the 1984 SIGMOD Conference, (Boston, Mass., June, 1984).
- DeWitt, D., etal. Gamma – A high performance dataflow database machine.
In Proceeding of the 1986 VLDB Conference (Japan, August 1986).
- DeWitt, D. et al. The Gamma database maching project. IEEE Knowl. Data
Eng. 2, 1, (Mar. 1990).
- Engelbert, S., Gray, J., Kocher, T., and Stah, P. A Benchmark of nonstop
SQL Release 2 demonstrating near-linear speedup and scaleup on large databases.
Tandem Computers, Technical Report 89.4, Tandem Part No.27469, May 1989.
- Grandeharizadeh, S., and DeWitt, D.J. Performance analysis of alternative
declustering strategies. In Proseedings of the Sixth International Conference
on Data Engineering (Feb. 1990).
- Ghandeharizadeh, S., and DeWitt, D.J. Hybrid-range partitioning strategy:
A new declustering strategy for multiprocessor database machines. In Proceedings
of the Sixth International Conference on Very Large Data Bases, (Melbourne,
Australia, Aug. 1990).
- Gibbs, J. Massively parallel systems, rethinking computing for business
and science. Oracle 6, 1 (Dec. 1991).
- Graefe, G. Encapsulation of parallelism in the Volcano query processing
system. In Proceedings of 1990 ACM-SIGMOD International Conference on Management
of Data (May 1990).
- Graefe, G., and Ward, K. Dynamic query evaluation plans. In Proceedings
of the 1989 SIGMOD Conference, (Portland, Ore., June 1989).
- Hirano, M.S. et al.Architecture of SDC, the super database computer.
In Proceedings of JSPP"90. 1990.
- Hua, K.A. and Lee, C. Handing data skew in multiprocessor database
computers using partition tuning. In Proceedings of the Seventeenth International
Conference on Very Large Data Bases. (Barcelona, Spain, Sept. 1991).
- Kitsuregawa, M., Tanaka H., and Moto-oka, T. Application of hash to
data base machine and its architecture. New Generation Computing 1, 1 (1983).
- Kitsuregawa, M., Yang, W., and Fushimi, S. Evaluation of 18-stage pipeline
hardware sorter. In Proceedings of the Third International Conference on
Data Engineering (Feb. 1987).
- Kitsuregawa, M., and Ogawa, Y. A new parallel hash join method with
robustness for data skew in super database computer (SDC). In Proceedings
of the Sixteenth Internatial Conference on Very Large Data Bases. (Melbourne,
Australia, Aug. 1990).
- Lorie, R., Daudenarde, J., Hallmark, G., Stamos, J., and Young, H.
Adding intra-transaction parallelism to an existing DBMS: Early experience.
IEEE Data Engineering Newsletter 12, 1 (Mar. 1989).
- Patterson, D.A., Gibson, G. and Katz, R.H. A case for redundant arrays
of inexpensive disks (RAID). InProceedings of the ACM-SIGMOD International
Conference on Management of Data. (Chicago, May 1988).
- Ries, D. and Epstein, R. Evaluation of distribution criteria for distributed
database systems. UBC/ERL Technical Report M78/22, UC Berkeley, May 1978.
- Salem, K. and Garcia-Molina, H. Disk-striping. Department of Computer
Science, Princeton University Technical Report EEDS-TR-322-84, Princeton,
N.J., Dec. 1984.
- Schneider, D. and DeWitt, D. A performance evaluation of four parallel
join algorithms in a sharednothing multiprocessor environment. In Proceedings
of the 1989 SIGMOD Conference (Portland, Ore., June 1989).
- Schneider, D. and DeWitt, D. Tradeoffs in processing complex join queries
via hashing in multiprocessor database machines. In Proceedings of the
Sixteenth International Conference on Very Large Data Bases. (Melbourne,
Australia, Aug., 1990).
- Selinger P.G., et al. Access path selection in a relational database
management system. In Proceedings of the 1979 SIGMOD Conference (Boston,
Mass., May 1979).
- Stonebraker, M. Muffin: A distributed database machine. ERL Technical
Report UCB/ERL M79/28, University of California at Berkeley, May 1979.
- Stonebraker, M. The case for shared nothing. Database Eng. 9,1 (1986).
- Stonebraker, M., Katz, R., Patterson, D., and Ousterhout, J. The Design
of XPRS. In Proceedings of the Fourteenth International Conference on Very
Large Data Bases. (Los Angeles, Calif., Aug. 1988).
- Tandem Database Group. NonStop SQL, a distributed, high-performance,
high-reliability implementation of SQL. Workshop on High Performance Transaction
Systems, Asilomar, CA Sept. 1987.
- Tandem Performance Group. A benchmark of non-stop SQL on the debit
credit transaction. In proceedings of the 1988 SIGMOD Conference (Chicago,
Ill., June 1988).
- Teradata Corporation. DBC/1012 Data Base Computer Concepts & Facilities.
Document No. C02-0001-00, 1983.
- Tevanian, A., et al. A Unix interface for shared memory and memory
mapped files under Mach. Dept. of Computer Science Technical Report, Carnegie
Mellon University, July, 1987.
- Thakkar, S.S. and Sweiger, M. Performance of an OLTP application on
symmetry multiprocessor system. In Proceedings of the Seventeenth Annual
International Symposium on Computer Architecture. (Seattle, Wash., May,
1990).
- The Performance Handbook for Database and Transaction Processing Systems.
J. Gray, Ed., Morgan Kaufmann, San Mateo, Ca., 1991.
- Walton, C.B., Dale, A.G., and Jenevein, R.M. A taxonomy and performance
model of data skew effects in parallel joins. In Proceedings of the Seventeenth
International Conference on Very Large Data Bases. (Barcelona, Spain, Sept.
1991).
- Wolf, J.L., Dias, D.M., and Yu, P.S. An effective algorithm for parallelizing
sort-merge joins in the presence of data skew.
In Proceedings of the Second International Symposium on Parallel and Distributed
Systems. (Dublin, Ireland, July, 1990).
- Zeller, H.J. and Gray, J. Adaptive hash joins for a multiprogramming
environment.
In Proceedings of the 1990 VLDB Conference (Australia, Aug. 1990).
1) Термин "диск" используется здесь
как сокращенное название дискового или другого устройства памяти, сохраняющего
информацию после выключения питания. По мере лет на смену обычным магнитным
дискам могут прийти электронные устройства, сохраняющие информацию после
выключения питания, или другие виды запоминающих устройств.
2) Стоимость выполнения некоторых операторов
увеличивает показатель супер-линейности. Например, функция стоимости сортировки
кортежей степени n возрастает как nlog(n). Если n измеряется в миллионах,
то показатель масштабируемости измеряется в тысячах, что приводит к возрастанию
nlog(n) в 3000 раз. Это 30% отклонение от линейности обосновывает использование
термина "почти линейная" масштабируемость.
3) Машины с одним потоком данных и несколькими
потоками команд (SIMD), подобные ILLIAC IV и берущими от нее начало MASSPAR
и "старой" Connection Machine, не принимаются здесь во внимание по причине
своего незначительного успеха в области баз данных. Похоже, что SIMD-машины
нашли свое применение в области моделирования, распознавания образов и
математического поиска, но не продемонстрировали возможности успешного
применения в сфере действия парадигмы многопользовательских, требующих
большого объема ввода/вывода и потоковой обработки систем баз данных.
4) По состоянию на июнь 1992г.

