Магия сохраняет силу
Индерпал Сингх Мумик, Шелдон Финкельштейн, Хамид Пирамеш, Раджу Рамакришнан
5. Набросок реализации расширенных магических множеств (EMS)
Мы реализуем EMS в Starburst. У нас имеется псевдокод, и C-код, выполняющий преобразования в простых случаях. В этом разделе мы приводим набросок своей реализации.EMS является частью фазы перезаписи запросов в оптимизаторе Starburst. Перезаписи выполняются (продукционной) системой, основанной на правилах, в которой каждое преобразование запроса кодируется в виде правила перезаписи [HP88]. Процессор прямого построения цепочек обходит граф запроса (обычно) в глубину, применяя правила перезаписи. EMS применяется к элементам графа, представляющим табличные выражения, к одному табличному выражению за раз. Многочисленные возбуждения правила EMS по мере обхода графа совокупно производят преобразованный запрос.
В системе правил Starburst, кроме правила магических множеств, имеется ряд других правил перезаписи. Правила проталкивания предикатов определяют, какие предикаты и в какой форме выталкиваются из табличных выражений в таблицы, на которые в них имеются ссылки. После этого правило EMS размещает предикаты в правильных местах (как магические множества).
Способ применения магических множеств к таблице может зависеть от операции в табличном выражении. Например, магия не может быть применена к такой операции как GROUPBY (к плохим операциям), а к такой операции как SELECT – применима (к хорошим операциям).
Когда производится магическая обработка табличного выражения для таблицы t, предыдущая обработка обеспечивает украшение заголовка t, наличие магической таблицы mt для t и (для хороших операций) то, что mt является опорной и присоединенной к телу табличного выражения. Кроме того, должен быть известен порядок SIPS внутри табличного выражения.11)
В течение магической обработки t все предикаты в табличном выражении проталкиваются в каждую таблицу r, на которую имеются ссылки из табличного выражения (с использованием правил проталкивания предикатов). Для каждой r определяется украшение α, и создается табличное выражение для rα с телом, идентичным телу табличного выражения для r. Для rα на основе его использования в t формируется магическое множество m_rα и, если r является хорошей, оно делается опорным и добавляется к табличному выражению для rα.
Магическая обработка производится для каждого табличного выражения, проходимого при обходе графа запроса. Мы избегаем повторной обработки табличного выражения, за исключением плохих табличных выражений при особых условиях. Для нашего алгоритма EMS справедлива следующая теорема (в предположении, что сначала мы избавляемся ото всех циклов в запросе Q, состоящем исключительно из плохих таблиц12)).
Теорема 5.1 Для любого графа запроса Q алгоритм EMS завершается, и EMS(Q) эквивалентен Q при применении стратегии выполнения Starburst.
Украшения и магические преобразования объединяются в однофазный алгоритм (разд. 4.3). По большей части используется простое bcf-украшение, хотя для плохих операций требуются специальные улучшенные украшения. Алгоритм EMS является расширяемым по отношению к (1) новым операциям в табличных выражениях и (2) стратегии обхода (в глубину, в ширину, снизу-вверх и т.д.).
6. Производительность
В этом разделе мы представляем результаты измерения производительности, которые иллюстрируют ускорение с помощью EMS выполнения сложных запросов (таких как запросы поддержки принятия решений), состоящих из нескольких блоков запросов. Выполнение таких запросов нередко занимает несколько часов (и даже дней). Преобразование запросов может повысить производительность на несколько порядков.Для исчерпывающей оценки производительности требуется определение тестовой базы данных и набора запросов для особой рабочей нагрузки. Мы концентрируемся на рабочей нагрузке из сложных запросов (с несколькими предикатами, соединениями, агрегацией и подзапросами), а не на транзакционной рабочей нагрузке с относительно простыми запросами. Хотя транзакционные тестовые наборы предложены [A+ 85, TPC89], рабочие нагрузки со сложными запросами все еще находятся на предварительной стадии ([TOB89, O'N89]). Чтобы измерить влияние на производительность преобразований методом магических множеств, мы используем масштабированную (в десять раз) версию тестовой базы DB2, описанной в [Loo86].
Преобразования методом магических множеств изучались в контексте рекурсивных запросов, и полезность магических множеств для рекурсивных запросов разъясняется в [BR86, BR87]. В этом разделе мы изучаем нерекурсивные запросы.
Наши измерения производительности выполнялись на реляционной СУБД IBM DB2 V2R2 с использованием средства мониторинга производительности DB2PM [DB88] для определения общего времени (общего времени, занимаемого у системы для выполнения запроса) и времени ввода/вывода (времени занятости устройств ввода/вывода). Мы измеряли эффективность выполнения каждого запроса до и после применения преобразований методом магических множеств. Оба представления запроса проходили процесс компиляции запроса, включая оценочную оптимизацию. Числовые показатели производительности для нескольких запросов, полученные при наших измерениях, описываются ниже.
Тестовая база данных DB2 основывается на приложении отслеживания и управления запасами. У рабочих центров, представленных таблицей wkc, имеются месторасположения (locatn). Изделия (itm) обработываются в месторасположениях внутри рабочих центров, и эта взаимосвязь фиксируется в таблице itl. Для каждого изделия может иметься несколько заказов (itp). Некоторые физические характеристики базы данных показаны в таб. 1.

Таб. 1. Тестовая база данных
Проталкивание предикатов и ориентированные на множества вычисления являются двумя ключевыми факторами оптимизации и выполнения запросов. Преобразование методом магических множеств обеспечивает оба эти преимущества. Хорошо известно проталкивание локальных предикатов, таких как (Job = 'Sr Programmer') в запросе D1 примера 2.1. Мы концентируемся на проталкивании предиктов соединения, которые передают информацию сторонним образом (SIPS-предикаты), такие как (emp.Dno = dep_avgsal.Dno) в запросе D1 примера 2.1.
Вычисления, ориентированные на множества, являются желательными, поскольку обычно приводят к повышению эффективности по сравнению с эквивалентными пофрагментными или покортежными вычислениями. Проталкивание предикатов соединения (или SIPS) путем использования корреляции фрагментирует вычисления, приводя к вычислению подзапроса для каждого переданного значения. В результате мы можем потерять преимущество последовательного упреждающего чтения ([TG84]), поскольку в каждом фрагменте вычислений не производится доступ к достаточному числу страниц, чтобы воспользоваться полным преимуществом упреждающего чтения для амортизации расходов ввода/вывода для большого числа страниц. Неэффективность может также возникать при доступе к данным через некластеризованные индексы.
Если вычисления не фрагментированны, мы извлекаем из такого индекса TID’ы требуемых кортежей, сортируем результаты по идентификаторам страниц и затем производим ввод/вывод ([MHWC90]). Следовательно, даже нужные страницы считываются только один раз. При фрагментированной обработке одна и та же страница может считываться много раз, по одному разу для каждого фрагмента, в котором требуется кортеж в данной странице.
Далее, для каждого фрагмента имеется некоторая фиксированная стоимость, связанная с такими операциями, как открытие и закрытие сканирования и инициализация сортировки (например, инициализация деревьев выборки при сортировке повторной выборкой). При обработке, ориентированной на множества, эти фиксированные расходы тратятся только один раз. При использовании корреляции эти фиксированные расходы тратятся по разу на каждое вычисление подзапроса. Поэтому, как мы увидим в разд. 6.3, преобразования запросов, приводящие к обработке, не ориентированной на множества, могут существенно ухудшить эффективность.
Оценка эффективности метода магических множеств основывается на двух обсуждавшихся выше ключевых факторах: проталкивание предикатов (или сторонняя передача информации) и ориентированная на множества обработка. Влияние проталкивания предикатов зависит от влияния связывания на план запроса (или части запроса). Например, преобразование методом магических множеств может обеспечить связывание для столбца, так что индекс на этом столбце становится эффективным путем доступа. Влияние обработки, ориентированной на множества, зависит от мощности связывающего множества (с дубликатами и без дубликатов). Чем больше мощность, тем сильнее преимущество использования ориентированной на множества передачи информации. Имеются многочисленные запросы, для которых важны оба фактора. Сейчас мы представим некоторые из многих запросов, использованных в наших экспериментах.
6.1. Эксперимент 1
В этом эксперименте выборочные связывания передаются в подзапрос. В наборе связываний отсутствуют дубликаты. В эксперименте используется представление V1, в котором для каждого изделия и каждого рабочего центра вычисляется среднее время обработки этого изделия13) в местоположениях внутри рабочего центра.
(V1): vitemtime(itemn, wkcen, avgtime) AS
(SELECT itemn, wkcen, AVG(loctime) FROM itl
GROUPBY itemn, wkcen)
Рассмотрим запрос Q1: Для каждого изделия, заказанного в количестве (qcopmp) 450 штук, найти среднее время обработки этого изделий в каждом рабочем центре, в котором оно обрабатывается.
(Q1): SELECT DISTINCT itm.*, wkcen, avgtime
FROM itp, itm, vitemtime
WHERE itp.qcomp = 450 AND itp.itemn = itm.itemn
AND itp.itemn = vitemtime.itemn
Для выполнения плана Q1 «вычислить представление vitemtime, сохранить результат во временной таблице и использовать ее для вычисления Q1» требуется около трех часов. Этот план является неэффективным, потому что представление вычисляется для всех изделий, хотя для запроса требуется небольшое подмножество изделий (предикат на qcopmp очень селективен). Мы можем избежать избыточных вычислений путем передачи в представление (путем перезаписи запроса) набора связываний на изделия, для которых требуется вычислить представление.
Связывания могут передаваться посредством корреляции или через магические множества. При использовании корреляции предикат (itp.itemn = vitemtime.itemn) проталкивается в табличное выражение corr_itemtime, отфильтровывая вычисления многих групп. Коррелированный запрос14) выглядит следующим образом:
(C1): SELECT DISTINCT itm.*, wkcen, avgtime
FROM itp, itm,
corr_itemtime(itemn, wkcen, avgtime) AS
(SELECT itemn, wkcen, AVG(loctime) FROM itl
WHERE itp.itemn = itl.itemn
GROUPBY itemn, wkcen)
WHERE qcomp = 450 AND itp.itemn = itm.itemn
В плане для C1 представление corr_itemtime вычисляется многократно. При каждом вычислении используется индекс на столбце itenm таблицы itl, и выбираются только релевантные строки. Предикат на itp.qcomp таков, что в связывании (itp_itemn) не передаются какие-либо дубликаты.
При использовании преобразования методом магических множеств вычисляется дополнительное магическое множество s_mag как временная таблица (Mla), s_mag используется для вычисления сокращенного представления mag_itemtlme (Mlb), и исходный запрос переписывается с использованием сокращенного представления (Mlc).
(Mla): s_mag AS
(SELECT DISTINCT itm.* FROM itp, itm
WHERE qcomp = 450 AND itp_itemn = itm_itemn)
(Mlb: mag_itemtlme (itemn, whcen, avgtime) AS
(SELECT itl_iltemn, itl_whcen, AVG(loctime)
FROM s_mag, itl WHERE s_mag.itemn = itl.itemn
GROUPBY itl.itemn, itl_whcen)
(Mlc): SELECT DISTINCT s_mag.*, whcen, avgtime
FROM s_mag, mag_itemtlme
WHERE s_mag.itemn = mag_itemtime.itemn
В плане для Ml представление mag_itemtlme вычисляется методом соединения вложенного цикла с использованием s_mag (менее мощной таблицы) как внешней таблицы и itl (более мощной таблицы) как внутренней таблицы и применением индекса на столбце itemn таблицы itl для извлечения только релевантных кортежей этой таблицы.
Сводка результатов производительности приведена в таб. 2. Для каждого запроса мы приводим общее время и время ввода/вывода. Числовые значения нормализованы с принятием значения 100 для общего времени выполнения исходного запроса. Таким образом, значение общего времени 0.40 для запроса с корреляцией в Эксперименте 1 означает, что для коррелированного запроса потребовалось 40% от времени исполнения исходного запроса, а значение 0.280 для ввода/вывода означает, что система ввода/вывода была занята 28% от общего времени выполнения исходного запроса.
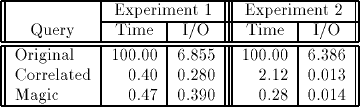
Таб. 2. Относительное общее время и время ввода/вывода запросов из экспериментов 1 и 2
Оба метода позволили повысить эффективность на два порядка, сократив общее время с трех часов до менее одной минуты. Ни один из методов не показал значительных преимуществ перед другим, поскольку оба привели к очень похожим планам вычисления представления vitemtime, которое является дорогостоящей частью запроса Q1. При использовании корреляции связывания на itemn прямо использовались для доступа к itl через индекс. При использовании метода магических множеств соединение вложенным циклом извлекало множество связываний из s_mag и использовало их для доступа к itl точно таким же образом. Коррелированный запрос оказался немного быстрее, потому что для магического запроса M1 требовалось вычисление дополнительного магического множества.
6.2. Эксперимент 2
В этом эксперименте изучается влияние на эффективность значений-дубликатов во множестве связываний. В Эксперименте 1 изменяется предикат наitp, чтобы он выдавал 95 изделий, для каждого из которых имеется 100 заказов. В результате имеется 100 копий каждого отдельного значения связывания (itemn). Сводка результатов измерения производительности показана в таб. 2.
Для запроса с корреляцией представление corr_itemtime вычисляется для каждой копии каждого значения связывания, поступающего из внешнего запроса. Магические множества работают значительно лучше, поскольку в переписанном запросе дублирующие связывания удаляются до их сохранения в s_mag. Метод корреляции можно усовершенствовать, чтобы устранить дублирующие вычисления представления. Результат каждого вычисления вместе с используемым в вычислении значении связывания можно сохранять во временной таблице, и дублирующие вычисления заменить на поиск в таблице. Мы полагаем, что такая модификация позволить методу корреляции конкурировать с методом магических множеств в Эксперименте 2.
6.3. Эксперимент 3
Этот эксперимент демонстрирует преимущества ориентированной на множества передачи информации с использованием метода магических множеств. Во множестве связываний отсутствуют дубликаты.Рассмотрим представление V3: Для каждого рабочего центра найти среднее время обработки изделий в местоположениях этого рабочего центра заданного типа. Представление V3 похоже на V1 за тем исключением, что мы отфильтровываем некоторые местоположения и исключаем из результата столбец itemn.
(V3): itlvagg(wkcen, avgtime) AS
(SELECT DISTINCT wkcen, AVG(loctime) FROM itl
WHERE locan ≥ 'loca50' AND locan ≤ 'loca55'
GROUPBY itemn, wkcen)
(Q3): SELECT wkc.deptn, wkc.wkcen, avgtime
FROM wkc, itlvagg
WHERE nmach ≤ 3 AND wkc.wkcen = itlvagg.wkcen
В запросе Q3 запрашивается информация из представления V3 о рабочих центрах, имеющих не более трех машин. Запрос выполняется путем вычисления полного представления itlvagg и соединения результата с таблицей wkc.
Запрос Q3 переписывается методами корреляции и магических множеств таким образом, чтобы использовать предикат (nmach ≤ 3) во избежание вычисления полного соединения. Предикату удовлетворяют только 10 рабочих центров; в представление передаются десять значений связывания – по одному в случае корреляции и как множество в случае магических множеств. Мы также использовали вариант Q3 с предикатом (nmach ≤ 6), которому удовлетворяют 100 рабочих центров.
При перезаписи методом корреляции предикат (wkc.wkcen = itlvagg.wkcen) проталкивается в представление. Магическое множество получается способом, аналогичным примененному в Эксперименте 1. Дополнительное магическое множество s_mag содержит релевантные рабочие центры и используется для ограничения представления (M3b). Сокращенное представление используется для формирования ответа на запрос (M3c).
(M3a): s_mag(deptn, wkcen) AS
(SELECT deptn, wkcen
FROM wkc WHERE nmach ≤ 3)
(M3b): mag_itlvagg(wkcen, avgtime) AS
(SELECT DISTINCT itl.wkcen, AVG(loctime)
FROM s_mag, itl
WHERE locan ≥ 'loca50' AND locan ≤ 'loca55'
AND s mag.wkcen = itl.wkcen
GROUPBY itl.wkcen, itl.itemn)
(M3c): SELECT deptn, s_mag.wkcen, avgtime
FROM s_mag, mag_itlvagg
WHERE s_mag.wkcen = mag_itlvagg.wkcen
Сводка результатов измерения производительности представлена в таб. 3. Метод корреляции дает очень плохие результаты. С 10 значениями связывания переписанный запрос работает в пять раз хуже исходного и ухудшает производительность в десять раз при увеличении числа значений связывания в 10 раз. Магический запрос работает достаточно хорошо; он безусловно предпочтительнее исходного запроса при 10 значениях связывания и конкурентоспособен при 100 значениях. При возрастании мощности множества связываний производительность метода магических множеств остается стабильной.
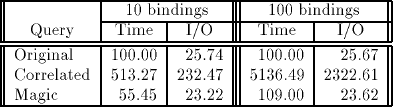
Таб. 3. Относительное полное время и время ввода/вывода для запросов Эксперимента 3
В запросе с корреляцией представление itlvagg вычисляется путем доступа к таблице itl через индекс на столбце locan. Однако во множестве связываний содержатся рабочие центры, а не месторасположения, и поэтому при каждом вычислении представления повторяется индексный доступ ко всем кортежам itl, удовлетворяющим предикату на столбце locan. Таблица itl обладает большой мощностью даже при ограничении несколькими месторасположениями, и стоимость доступа существенна. Поскольку большая часть расходов повторяется для каждого значения связывания, стоимость запроса почти линейно зависит от мощности множества связывания. В соответствующем магическом запросе доступ к таблице itl производится только один раз, и производится соединение с полным множеством связываний. Модификация метода корреляции, предложенная в подразделе 6.2, в данном эксперименте не повышает эффективность.
Результаты Эксперимента 3 показывают стабильность преобразования методом магических множеств – даже если он не приводит к оптимальному выбору (по причине неправильной оценки селективности предикатов), полученные результаты не будут намного хуже возможных альтернатив. Поскольку основной целью оптимизации является избежание плохих планов (и вторичной целью является нахождение достаточно хорошего плана), преобразование методом магических множеств часто отвечает целям оптимизации лучше методов корреляции и декорреляции, которые значительно менее стабильны. В связи с чрезвычайно высокой стоимостью процесса оптимизации роль стабильных эвристик становится все более важной ([Pir89]). По этой причине очень ценным фактором является стабильность магических множеств.
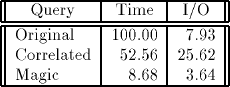
Таб. 4. Относительное полное время и время ввода/вывода для варианта Эксперимента 3
В таб. 4 приводится сводка результатов измерения производительности для Эксперимента 4, варианта Эксперимента 3 с 10 связующими значениями. Представление аналогично V3, но до группировки требуется соединение itl с itp и еще одной таблицей. В результате группируемая таблица становится большой, а стоимость группировки – значительной. Метод магических множеств приводит к лучшим результатам, чем у коррелированного варианта запроса (по причине обработки, ориентированной на множества) и у исходного запроса (по причине сокращения стоимости группировки), и является явным победителем.
7. Заключение
В этой статье мы показали, что преобразование методом магических множеств можно расширить для работы с конструкциями SQL. Мы привели набросок реализации Extended Magicsets как части компонента перезаписи прототипа реляционной системы баз данных, а также представили исследование эффективности, в котором подход магических множеств сопоставляется с подходами корреляции и декорреляции. Многие существенные результаты были лишь упомянуты или вовсе опущены, включая аспекты улучшенных украшений, простых украшений и детали реализации.Как мы полагаем, эта статья демонстрирует, что метод магических множеств (ранее служивший средством только для Datalog и логического программирования) следует рассматривать как практическое расширение существующих методов оптимизации путем перезаписи. Магия действительно «уместна» для систем реляционных баз данных; это общий метод (применимый как к рекурсивным, так и к не рекурсивным запросам) введения предикатов, которые как можно ранее отфильтровывают доступ к ненужным строкам таблиц. Ограниченные варианты этого метода долгие годы используются в системах баз данных.
Мы не предлагаем использовать преобразования методом магических множеств всякий раз, когда они возможны. Скорее, магия является ценной альтернативной, кажущейся более стабильной, чем методы корреляции и декорреляции, предметом выбора, который должен оцениваться стоимостным оптимизатором [SAC + 79, Loh88]. Магия особенно полезна для запросов (таких как запросы поддержки принятия решений), включающих большое число соединений, сложные вложения блоков запросов или рекурсию. Такие запросы могут быть невыполнимыми без применения магических множеств.
В литературе предлагался ряд специальных методов оптимизации. Некоторые из них можно считать альтернативами магических множеств, в которых делаются попытки использования специальных свойств некоторых запросов, таких как линейные запросы на ациклических данных (например, HenschenNaqvi [HN84], Counting [BMSU86]) или специальные операции для выражения ограниченного (и важного) класса запросов, таких как транзитивное замыкание (например, операция alpha [Agr87]). При наличии возможности их применения, эти методы иногда оказываются лучше преобразования магических множеств. Однако пример 1.2 иллюстрирует полезные запросы, не выразимые с использованием линейной рекурсии. Важность метода магических множеств состоит в том, что он применим ко всем (расширенным) SQL-запросам и обеспечивает общий каркас оптимизации с хорошей и стабильной эффективностью. Имеются также методы, в которых подход магических множеств развивается и совершенствуется для некоторых классов запросов (например, факторизация [NRSU89]). Эти методы дополняют подход магических множеств путем распознавания специальных свойств программ и соответствующей оптимизации преобразованных программ.
Хотя мы реализуем магию как расширение компонента оптимизации путем перезаписи прототипа расширяемой системы реляционных баз данных Starburst, остается много практических вопросов. Одной из трудных открытых проблем является интеграция оптимизации путем перезаписи с оценочной оптимизацией. Для оценочной оптимизации может требоваться время, экспоненциально зависящее от числа соединяемых таблиц. Преобразования, подобные магическим множествам, могут привести к экспоненциально большому числу альтернативных запросов, для каждого из которых требуется оценочная оптимизация, более сложная, чем для исходного запроса. Очевидно, что между многими преобразованиями запросов имеется структурная связь, но мы недостаточно хорошо понимаем эту проблему, чтобы перевести ее на управляемый уровень с применением алгебраических методов или инженерных эвристик.
8. Благодарности
Проект Starburst в IBM Almaden Research Center обеспечил стимулирующую среду для этой работы. Мы чрезвычайно благодарны Теду Мессиндеру (Ted Messinger) за помощь в установке тестовой базы DB2. Брюс Линдсей (Bruce Lindsay), Гай Лохман (Guy Lohman), Ульф Шрайер (Ulf Schreier), Джефф Ульман (Jeff Ullman) и рецензенты обеспечили полезные комментарии к начальному варианту этой статьи. Мы благодарны Джеффу Ульману и членам группы NAIL! В Стэнфорде за многочисленные глубокие обсуждения данного предмета.11) Открытой проблемой, упоминаемой в заключении статьи, является соответствующее взаимодействие между оценочной оптимизацией и оптимизацией на основе преобразующей перезаписи.
12) Путем вставки в цикл операции SELECT.
13) Время обработки изделия в данном местопложении loctime = finishtime – starttime.
14) Представление становится коррелированным табличным выражением. В стандарте SQL не допускаются коррелированные табличные выражения. Мы экспериментировали с вариантом C1, стоимость выполнения которого близка, но определенно ниже стоимости выполнения C1.