Модель "сущность-связь" – шаг к единому представлению о данных
Петер Пин-Шен Чен
Перевод: М.Р. Когаловский
Источник: журнал Системы Управления Базами Данных # 3/1995, издательский дом «Открытые системы»
Новая редакция: Сергей Кузнецов, 2009 г.
Оригинал: Peter Pin-Shan Chen. The Entity-Relationship Model-Toward a Unified View of Data. ACM Transactions on Database Systems, Volume 1, Number 1, 1976. Текст доступен здесь.
Содержание
- 2.1 Многоуровневые представления данных
- 2.2 Информация о сущностях и связях (уровень 1)
- 2.3 Структура информации (уровень 2)
- 3.1 Анализ систем с использованием диаграммы "сущность-связь"
- 3.2 Пример проектирования и описания базы данных
- 3.3 Целостность данных
- 3.4 Семантика и множественные операции запросов выборки информации
- 3.5 Семантика и правила вставки, удаления и модификации
Предлагается модель данных, называемая моделью сущность-связь (entity-relationship model). Эта модель основывается на некоторой важной семантической информации о реальном мире. Вводится специальный диаграммный метод как средство проектирования баз данных. Приводится пример проектирования и описания базы данных с использованием этой модели и диаграммного метода. Обсуждаются некоторые аспекты понятий целостности данных, поиска информации и манипуляций с данными.
Модель сущность-связь может использоваться в качестве основы для унификации различных представлений данных на основе сетевой модели, реляционной модели и модели множества сущностей. Анализируются семантические неоднозначности, возникающие в этих моделях. Представлены возможные способы порождения этих представлений данных из модели сущность-связь.
Ключевые слова и фразы: проектирование баз данных, локальное представление данных, семантика данных, модели данных, модель "сущность-связь", реляционная модель, Data Base Task Group, сетевая модель, модель множества сущностей, определение данных и манипуляция ими, целостность и согласованность данных.
1. ВВЕДЕНИЕ
В настоящее время важной проблемой является логическое представление данных. Были предложены три основных модели данных: сетевая модель [2,3,7], реляционная модель [8] и модель множества сущностей [25]. У этих моделей имеются свои сильные и слабые стороны. Сетевая модель обеспечивает более естественное представление данных за счет разделения (до определенной степени) сущностей и связей, однако возможности этой модели по обеспечению независимости данных подвергаются сомнению [8]. Реляционная модель основывается на теории реляционных баз данных и может обеспечить высокую степень независимости данных, но при ее использовании может утрачиваться некоторая важная информация о реальном мире [12,15,23]. Модель множества сущностей, основанная на теории множеств, также обеспечивает высокую степень независимости данных, но принятое в ней представление значений, таких как 3 или red, кому-то может показаться неестественным[25].
В этой статье представлена модель сущность-связь, которая обладает большинством преимуществ упомянутых выше моделей. В модели сущность-связь используется более естественное представление, в соответствии с которым реальный мир состоит из сущностей и связей. Эта модель основывается на некоторой важной семантической информации о реальном мире (описание других результатов, связанных с семантикой баз данных, могут быть найдены в [1,12,15,21,23 и 29]). Модель может обеспечить высокую степень независимости данных и основывается на теории множеств и реляционной теории.
Модель сущность-связь может использоваться в качестве основы унифицированного представления данных. В большинстве предыдущих работ подчеркивались различия между сетевой и реляционной моделями [22]. В настоящее время предпринимаются попытки сократить различия между тремя моделями данных [4,19,26,30,31]. В этой статье модель сущность-связь используется в качестве основы, из которой могут быть порождены три существующие модели данных. Читатель может рассматривать модель сущность-связь как обобщение или расширение существующих моделей.
Статья состоит из трех частей (разд. 2-4). В разд. 2 на основе использования многоуровневых представлений данных вводится модель сущность-связь. В разд. 3 описывается семантическая информация в этой модели и ее использование при описании данных и манипулировании ими. В качестве средства проектирования баз данных вводится специальный диаграммный метод – диаграммы сущностей-связей. В разд. 4 анализируются сетевая модель, реляционная модель и модель множества сущностей и описывается, как они могут быть выведены из модели сущность-связь.
2. МОДЕЛЬ СУЩНОСТЬ-СВЯЗЬ
2.1. Многоуровневые представления данных
При изучении модели данных следует выявить уровни логического представления данных, к которым имеет отношение эта модель. Расширяя набор положений, представленных в [18,25], мы можем определить четыре уровня представления данных (рис. 1):
- информация, относящаяся к сущностям и связям, которые существуют в нашем воображении;
- структура информации – организация информации, в которой сущности и связи представляются данными.
- структура данных, независимая от путей доступа, – структуры данных, которые не связаны со схемами поиска, индексации и т.д.
- структура данных, зависимая от путей доступа.
В следующих подразделах мы будем шаг за шагом разрабатывать модель сущность-связь для первых двух уровней. Как мы увидим позже, сетевая модель в том виде, в котором она существует в настоящее время, в основном относится к уровню 4, реляционная модель в основном относится к уровням 3 и 2, а модель множества сущностей в основном относится к уровням 1 и 2.
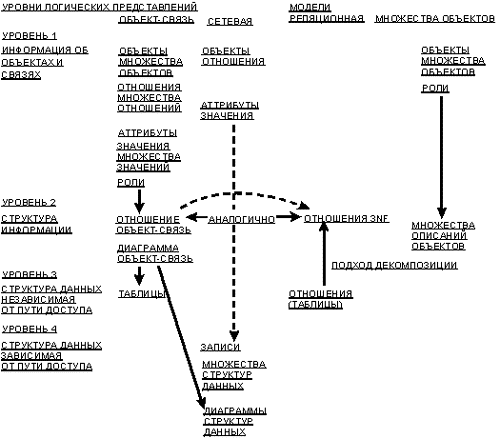
Рисунок 1. Анализ моделей данных с использованием нескольких уровней логических
представлений
2.2. Информация о сущностях и связях (уровень 1)
На этом уровне мы рассматриваем сущности и связи. Сущность (entity) – это предмет, который может быть идентифицирован некоторым способом, отличающим его от других предметов. Примерами сущности являются конкретный человек, компания или событие . Связь (relationship) – это ассоциация, устанавливаемая между сущностями. Например, отец-сын – это связь между двумя сущностями человек.1)
База данных предприятия содержит информацию о сущностях и связях, которые представляют интерес для этого предприятия. В базу данных предприятия не может быть занесено полное описание сущности или связи. Невозможно (и, по всей видимости, не обязательно) сохранять всю потенциально доступную информацию о сущностях и связях. Далее мы будем рассматривать только те сущности и связи (и информацию о них), которые должны войти в проект базы данных.
2.2.1 Сущность и множество сущностей. Пусть e обозначает некоторую сущность, которая существует в нашем воображении. Каждая сущность относится к некоторому отличному от других множеству сущностей (entity set), такому как EMPLOYEE, PROJECT или DEPARTMENT. С каждым множеством сущностей связывается предикат, позволяющий проверить, принадлежит ли данная сущность данному множеству. Например, если мы знаем, что сущность относится к множеству сущностей EMPLOYEE, то мы также знаем, что эта сущность обладает свойствами, общими с другими сущностями из множества сущностей EMPLOYEE. В число этих свойств входит упомянутый выше предикат. Пусть Ei обозначает множество сущностей. Заметим, что множества сущностей не обязаны быть непересекающимися. Например, сущность, принадлежащая множеству сущностей MALE-PERSON (МУЖЧИНЫ), принадлежит также и множеству сущностей PERSON (ЛЮДИ). В этом случае MALE-PERSON является подмножеством PERSON.
2.2.2 Связь, роль и множество связей. Рассмотрим ассоциации сущностей. Множество связей (relationship set) Ri – это математическое отношение [5] между n сущностями, каждая из которых относится к некоторому множеству сущностей:
{[e1, e2, ...,en] | e1 ∈ E1, e2 ∈ E2, ..., en ∈ En},
и каждый кортеж сущностей, [e1, e2,...,en], является связью (relationship). Заметим,что в этом определении Ei не обязаны быть различными наборами. Например, marriage (брак) – это связь между двумя сущностями из набора сущностей PERSON (ЧЕЛОВЕК).
Роль (role) сущности в связи – это функция, которую сущность выполняет в данной связи. Husband (муж) и wife (жена) – это роли. Упорядочивание сущностей в определении связи (заметим, что использовались квадратные скобки) может отсутствовать, если в связи явно указаны роли сущностей: (r1/e1, r2/e2 ,..., rn/en), где ri – это роль сущности ei в данной связи.
2.2.3 Атрибут, значение и множество значений. Информацию об сущности или связи получают путем наблюдения или измерения и выражают множеством пар атрибут-значение. 3, red, Peter и Johnson – это значения. Значения классифицируются в различные множества значений (value sets), такие как FEET, COLOR, FIRST-NAME и LAST-NAME. С каждым множеством значений связывается предикат для проверки того, принадлежит ли значение этому множеству. Значение из некоторого множества значений может быть эквивалентно другому значению из другого множества значений. Например, 12 из множества значений INCH (ДЮЙМЫ) эквивалентно 1 в множестве значений FEET (ФУТЫ).
Атрибут (attribute) может быть формально определен как функция, отображающая множество сущностей или множество связей в множество значений или декартово произведение множеств значений:
f: Ei or Ri → Vi or Vi1 × Vi2 × ... × Vin
На рис. 2 показано несколько атрибутов, определенных на множестве сущностей PERSON. Атрибут AGE (ВОЗРАСТ) производит отображение в множество значений NO-OF-YEARS (ЧИСЛО-ЛЕТ). Атрибут может задавать отображение в декартово произведение множеств значений. Например, атрибут NAME (ПОЛНОЕ-ИМЯ) задает отображение в множества значений FIRST-NAME (ИМЯ) и LAST-NAME (ФАМИЛИЯ). Заметим, что несколько атрибутов могут задавать отображение одного и того же множества сущностей в одно и то же множество значений (или одну и ту же группу множеств значений). Например, атрибуты NAME (ПОЛНОЕ-ИМЯ) и ALTERNATIVE-NAME (ДРУГОЕ-ПОЛНОЕ-ИМЯ) задают отображение из множества сущностей EMPLOYEE в множества значений FIRST-NAME и LAST-NAME. Тем самым, атрибут и множество значений являются разными понятиями, хотя в некоторых случаях они могут иметь одно и то же имя (например, атрибут EMPLOYEE-NO (НОМЕР-СЛУЖАЩЕГО) задает отображение из EMPLOYEE (СЛУЖАЩИЕ) в множество значений EMPLOYEE-NO (НОМЕР-СЛУЖАЩЕГО)). Это различие не является явным в сетевой модели и во многих существующих системах управления данными. Заметим также, что атрибут определяется как функция. Следовательно, он отображает данную сущность в одно значение (или один кортеж значений в случае декартова произведения множеств значений).
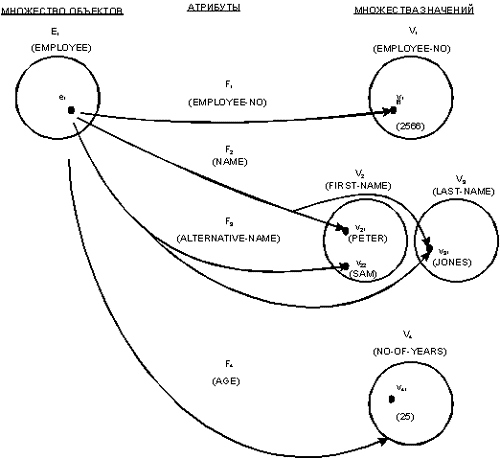
Рис. 2. Атрибуты, определенные на множестве сущностей PERSON
Заметим, что связи также имеют атрибуты. Рассмотрим множество связей PROJECT-WORKER (ИСПОЛНИТЕЛЬ-ПРОЕКТА) (рис. 3). Атрибут PERCENTAGE-OF-TIME (ПРОЦЕНТ-ВРЕМЕНИ), представляющий долю времени, выделенную конкретному служащему на конкретный проект,– это атрибут, определенный на множестве связей PROJECT-WORKER. Он не является ни атрибутом сущности EMPLOYEE, ни атрибутом сущности PROJECT, так как его смысл зависит и от служащего, и от проекта. Понятие атрибута связи важно для понимания семантики данных и определения функциональных зависимостей между данными.
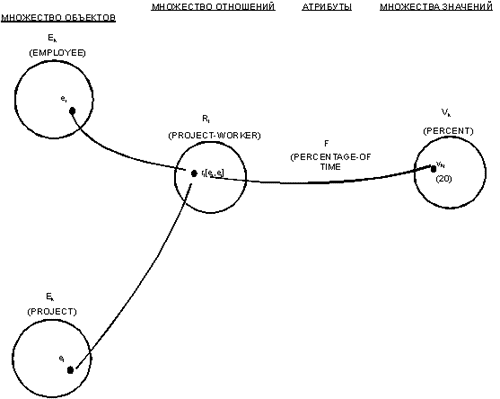
Рис. 3. Атрибуты, определенные на множестве связей PROJECT-WORKER
2.2.4 Концептуальная структура информации. Теперь мы обсудим, как можно организовать информацию о сущностях и связях. В этой статье предлагается метод разделения информации о сущностях и информации о связях. Мы покажем, что такое разделение полезно для идентификации функциональных зависимостей между данными.
На рис. 4 в форме таблицы приведена информация о сущностях в множестве сущностей. Каждая строка значений относится к одной и той же сущности, а каждый столбец относится к множеству значений, которое, в свою очередь, относится к атрибуту. Порядок строк и столбцов не является существенным.
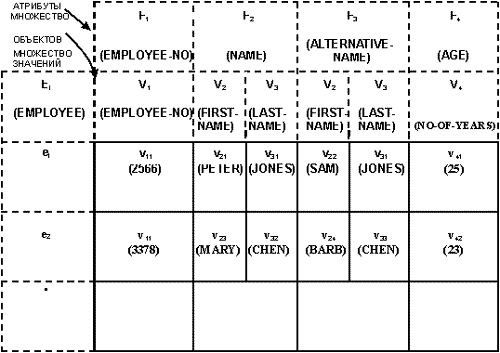
Рис. 4. Информация о сущностях из множества сущностей (табличная форма)

Рис. 5. Информация о связях из множества связей (табличная форма)
На рис. 5 приведена информация о связях в множестве связей. Заметим, что каждая строка значений относится к связи, которая указывается группой сущностей, каждая из которых имеет определенную роль и принадлежит определенному множеству сущностей.
Заметим, что на рис. 4 и 2 (а также на рис. 5 и 3) представлены различные формы одной и той же информации. Форма таблицы используется для упрощения связывания с реляционной моделью.
2.3. Структура информации (уровень 2)
Сущности, связи и значения на уровне 1 (см. рис. 2-5) являются концептуальными объектами, существующими в нашем воображении (т.е. мы находились в концептуальной сфере). На уровне 2 мы рассматриваем представления концептуальных объектов. Мы предполагаем, что существуют непосредственные представления значений. Далее мы опишем, как можно представить сущности и связи.
2.3.1 Первичный ключ. На рис. 2 значения атрибута EMPLOYEE-NO могут использоваться для идентификации сущностей в множестве сущностей EMPLOYEE, если у каждого служащего имеется уникальный номер служащего. Возможно, для идентификации сущностей в множестве сущностей понадобится более одного атрибута. Возможно также, что для идентификации сущностей будут использоваться несколько групп атрибутов. По существу, ключ сущности (entity key) – это группа атрибутов, такая, что отображение из множества сущностей в соответствующую группу множеств значений является взаимнооднозначным отображением. Если не удается найти такое отображение на доступных данных, или если желательна простота в идентификации объектов, то можно искусственно определить атрибут и множество значений, чтобы добиться наличия взаимнооднозначного отображения. В случае существования нескольких ключей обычно выбирается семантически значимый ключ в качестве первичного ключа сущности (entity primary key – PK).

Рис. 6. Представление сущностей значениями (номерами служащих)
Рис. 6 получен слиянием множества сущностей EMPLOYEE с множеством значений EMPLOYEE-NO с рис. 2. Обратим внимание на некоторые семантические следствия рис. 6. Каждое значение в множестве значений EMPLOYEE-NO представляет сущность (служащего). Атрибуты задают отображение из множества значений EMPLOYEE-NO в другие множества значений. Заметим также, что атрибут EMPLOYEE-NO задает отображение множества значений EMPLOYEE-NO в само его.
2.3.2 Отношения сущность/связь. Информация о сущностях в множестве сущностей теперь может быть организована в форме, показанной на рис. 7. Заметим, что рис. 7 похож на рис. 4, за исключением того, что сущности представлены значениями их первичных ключей. Вся таблица на рис. 7 представляет отношение сущностей (entity relation), а каждая строка представляет кортеж сущностей (entity tuple).
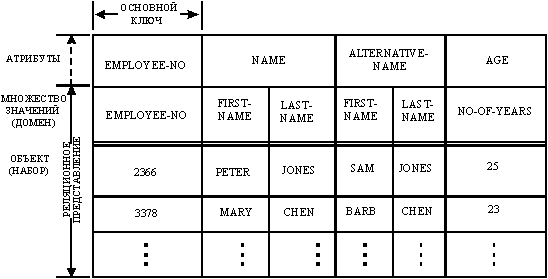
Рисунок 7. Регулярное отношение сущностей EMPLOYEE
Так как связь идентифицируется вовлекаемыми в нее сущностями, первичный ключ связи (primary key of a relationship) может быть представлен первичными ключами вовлеченных в связь сущностей. На рис. 8 вовлеченные сущности представлены их первичными ключами EMPLOYEE-NO и PROJECT-NO. Имена ролей задают семантический смысл значений в соответствующих столбцах. Заметим, что EMPLOYEE-NO – это первичный ключ вовлеченных в связь сущностей, а не атрибут связи. PERCENTAGE-OF-TIME – это атрибут связи. Таблица на рис. 8 представляет отношение связей (relationship relation), а каждая строка значений – кортеж связей (relationship tuple).

Рис. 8. Регулярное отношение связей PROJECT-WORKER
В некоторых случаях сущности в множестве сущностей нельзя уникально идентифицировать значениями их собственных атрибутов; следовательно, для их идентификации мы должны использовать связь(и). Например, рассмотрим сущности служащих-подчиненных (dependent) и служащих-начальников (supporter): подчиненные идентифицируются своими именами и значениями основного ключа служащих-начальников (т.е. своими связями с этими служащими). Заметим, что на рис. 9 EMPLOYEE-NO не является атрибутом сущностей в множестве DEPENDENT, а представляет собой первичный ключ служащих, которые имеют подчиненных. Каждая строка значений на рис. 9 – это кортеж сущностей с EMPLOYEE-NO и NAME в качестве первичных ключей. Вся таблица является отношением сущностей.
Теоретически, для идентификации сущностей может использоваться любой вид связи. Для простоты мы ограничимся только одним видом связи: бинарными связями с отображением 1:n, в которых существование n сущностей на одной стороне связи зависит от существования одной сущности на другой стороне связи. Например, один служащий может иметь n (n = 0, 1, 2,... ) подчиненных, и существование подчиненных зависит от существования соответствующего служащего-начальника.
Этот метод идентификации сущностей связями с другими сущностями можно применять рекурсивно до тех пор, пока не встретятся сущности, которые могут быть идентифицированы значениями своих собственных атрибутов. Например, первичный ключ департамента компании может состоять из номера департамента и первичного ключа отделения, который в свою очередь состоит из номера отделения и названия компании.
Следовательно, мы имеем две формы отношений сущностей. Если связи используются для идентификации сущностей, мы будем называть это слабым отношением сущностей (weak entity relation) (рис. 9). Если связи не используются для идентификации сущностей, мы будем называть это регулярным отношением сущностей (regular entity relation) (рис. 8). Если некоторые сущности в связи идентифицируются другими связями, мы будем называть это слабым отношением связей (weak relationship relation). Например, любые связи между сущностями DEPENDENT и другими сущностями приведут к образованию слабых отношений связи, так как сущность DEPENDENT идентифицируется своим именем и связью с сущностью EMPLOYEE. Проведение различия между регулярными и слабыми отношениями сущностей и связей будет полезно для поддержки целостности данных.
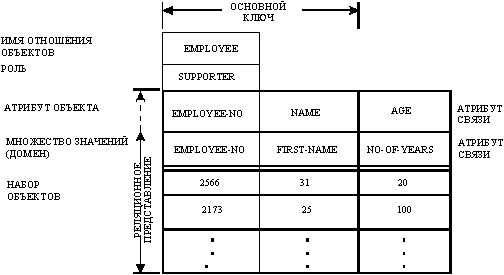
Рис. 9. Слабое отношение сущностей DEPENDENT
3. ДИАГРАММА СУЩНОСТЬ-СВЯЗЬ И ВКЛЮЧЕНИЕ СЕМАНТИКИ В ОПИСАНИЕ ДАННЫХ И МАНИПУЛИРОВАНИЕ ДАННЫМИ
3.1. Анализ систем с использованием диаграмм сущность-связь
В этом разделе мы вводим диаграммный метод для представления сущностей и связей – диаграмму сущность-связь.

На рис. 10 с использованием диаграммного метода демонстрируются множество связей PROJECT-WORKER и множества сущностей EMPLOYEE и PROJECT. Каждое множество сущностей представляется прямоугольником, а каждое множество связей – ромбом. Линии, соединяющие прямоугольники, демонстрируют тот факт, что множество связей PROJECT-WORKER определено на множествах сущностей EMPLOYEE и PROJECT. Указаны роли сущностей в связи.
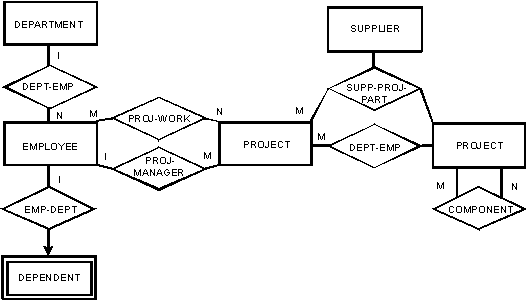
На рис. 11 приведена более полная диаграмма некоторых множеств сущностей и связей, которые могли бы представлять интерес для производственной компании. DEPARTMENT, EMPLOYEE, DEPENDENT, PROJECT, SUPPLIER и PART – это множества сущностей. DEPARTMENT-EMPLOYEE, EMPLOYEE-DEPENDENT, PROJECT-WORKER, PROJECT-MANAGER, SUPPLIER-PROJECT-PART, PROJECT-PART и COMPONENT – множества связей. Связь COMPONENT показывает, какие детали (и в каком количестве) требуются для создания составных деталей. Смысл других множеств связей не нуждается в объяснении.
На рис. 11 можно обнаружить несколько важных общих характеристик связей:
- Множество связей может быть определен на нескольких множествах сущностей. Например, множество связей SUPPLIER-PROJECT-PART определяется на трех множествах сущностей: SUPPLIER, PROJECT и PART.
- Множество связей может быть определено и только на одном множестве сущностей. Например, множество связей COMPONENT определяется на единственном множестве сущностей PART.
- Может существовать несколько множеств связей, определенных на заданных множествах сущностей. Например, множества связей PROJECT-WORKER и PROJECT-MANAGER определяются на множествах сущностей PROJECT и EMPLOYEE.
- В диаграмме могут различаться отображения 1:n, m:n и 1:1. Множество связей DEPARTMENT-EMPLOYEE является отображением 1:n, т.е. в одном департаменте может работать n (n = 0, 1, 2, ...) служащих, и каждый служащий работает только на один департамент. Множество связей PROJECT-WORKER является отображением m:n, т.е. в каждом проекте могут участвовать ноль, один и более служащих, и каждый служащий может участвовать в ноле, одном или более проектах. Можно выразить также отображение 1:1, такое, каким является множество связей MARRIAGE. Информация о допускаемом множеством связей числе сущностей в каждом множестве сущностей задается с помощью указания в диаграмме "1", "m", "n". Реляционная модель и модель множества сущностей2) не включают этот тип информации; в сетевой модели невозможно просто выразить отображение 1:1.
- В диаграмме можно показать зависимость существования (existence dependency) одного типа сущностей от другого. Например, стрелка в множестве связей EMPLOYEE-DEPENDENT показывает, что существование сущности в множестве сущностей DEPENDENT зависит от соответствующей сущности в множестве сущностей EMPLOYEE. Другими словами, если служащий покидает компанию, его подчиненные, возможно, больше не будут представлять интерес.
Заметим, что множество сущностей DEPENDENT показан специальным прямоугольником. Это значит, что на уровне 2 информация о сущностях из этого множества организована как слабое отношение сущностей (с использованием первичного ключа EMPLOYEE как части первичного ключа DEPENDENT).
3.2. Пример проектирования и описания базы данных
При проектировании базы данных с использованием модели сущность-связь выполняются четыре шага:
- идентификация представляющих интерес множеств сущностей связей;
- идентификация семантической информации в множествах связей, например, является ли некоторое множество связей отображением 1:n;
- определение множеств значений и атрибутов;
- организация данных в виде отношений сущность/связь и определение первичных ключей.
Будем использовать в качестве примера производственную компанию, рассмотренную в разд. 3.1. Результаты первых двух шагов проектирования базы данных отражены в диаграмме сущность-связь, показанной на рис. 11. Третий шаг состоит в определении множеств значений и атрибутов (см. рис. 2 и 3). На четвертом шаге принимается решение о первичных ключах сущностей и связей, и данные организуются в виде отношений "сущность/связь". Заметим, что для каждого множества сущностей на рис. 11 имеется соответствующее отношение сущность-связь. Мы будем использовать имена множеств сущностей (на уровне 1) как имена соответствующих отношений сущность-связь (на уровне 2), если только это не вызывает путаницы.
В конце этого раздела мы показываем схему (определение данных) небольшой части базы данных из упомянутого выше примера производственной компании (синтаксис определения данных не представляет особой важности). Заметим, что множества значений определяются с указанием представлений и допустимых значений. Например, значения в EMPLOYEE-NO представляются как целые из 4 цифр с диапазоном значений от 0 до 2000. Затем мы объявляем три отношения сущностей: EMPLOYEE, PROJECT и DEPENDENT. Указываются атрибуты и множества значений, определенные на множествах сущностей, а также первичные ключи. DEPENDENT – это слабое отношение сущностей, так как частью его первичного ключа является EMPLOYEE.PK. Мы также объявляем два отношения связей: PROJECT-WORKER и EMPLOYEE-DEPENDENT. Указываются роли и вовлекаемые в связи сущности. Мы используем EMPLOYEE.PK для именования отношения сущностей (EMPLOYEE), и подходящие пары атрибут-множество значений используются как первичные ключи в этом множестве сущностей. Устанавливается максимальное число сущностей из множества сущностей в отношении. Например, PROJECT-WORKER является отображением m:n. Мы можем указать значения m и n. Можно также задать не только максимальное число сущностей, но и их минимальное число. EMPLOYEE-DEPENDENT – это слабое отношение связей, так как одно из входящих в это отношение связей отношение сущностей DEPENDENT является слабым отношением сущностей. Заметим, что также указывается зависимость существования подчиненных от их начальника.
DECLARE VALUE-SETS REPRESENTATION ALLOWABLE-VALUES
EMPLOYEE-NO INTEGER(4) (0,2000)
FIRST-NAME CHARACTER(8) ALL
LAST-NAME CHARACTER(10) ALL
NO-OF-YEARS INTEGER(3) (0,100)
PROJECT-NO INTEGER(3) (1,500)
PERCENTAGE FIXED(5.2) (0,100.00)
DECLARE REGULAR ENTITY RELATION EMPLOYEE
ATTRIBUTE/VALUE-SET:
EMPLOYEE-NO/EMPLOYEE-NO
NAME(FIRST-NAME,LAST-NAME)
ALTERNATIVE-NAME/(FIRST-NAME,LAST-NAME)
AGE/NO-OF-YEARS
PRIMARY KEY:
EMPLOYEE-NO
DECLARE REGULAR ENTITY RELATION PROJECT
ATTRIBUTE/VALUE-SET:
PROJECT-NO/PROJECT-NO
PRIMARY KEY:
EMPLOYEE-NO
DECLARE WEAK RELATIONSHIP RELATION PROJECT-WORKER
ROLE/ENTITY-RELATION.PK/MAX-NO-OF-ENTITIES
WORKER/EMPLOYEE.PK/n
PROJECT/PROJECT.PK/m (отображение m:n)
ATTRIBUTE/VALUE-SET:
PERCENTAGE-OF-TIME/PERCETNTAGE
DECLARE WEAK RELATIONSHIP RELATION EMPLOYEE-DEPENDENT
ROLE/ENTITY-RELATION.PK/MAX-NO-OF-ENTITIES
SUPPORTER/EMPLOYEE.PK/1
DEPENDENT/DEPENDENT.PK/n
EXISTENCE OF DEPENDENT DEPENDENS ON:
EXISTENCE OF SUPPORTER
DECLARE WEAK ENTITY RELATION DEPENDENT
ATTRIBUTE/VALUE-SET:
NAME/FIRST-NAME
AGE/NO-OF-YEARS
PRIMARY KEY:
NAME
EMPLOYEE.PK THROUGH EMPLOYEE-DEPENDENT
3.3. Целостность данных
По поводу целостности данных была проделана некоторая работа в рамках других моделей [8,14,16,28]. При наличии в модели сущность-связь явных понятий сущности и связи эта модель будет полезна для понимания и спецификации ограничений, направленных на поддержки целостности данных. Например, имеется три основных типа ограничений на значения:
- Ограничения на допустимые значения (allowable values) в множестве значений. Этот вопрос обсуждался при определении схемы в разд. 3.2.
- Ограничения на разрешенные (permitted) значения для некоторого
атрибута. В некоторых случаях не все допустимые значения из множества значений
являются разрешенными для некоторых атрибутов. Например, возраст служащих
может быть ограничен диапазоном значений от 20 до 65, т.е.
AGE(e) ∈ (20,65), где e ∈ EMPLOYEE.
Заметим, что для более ясного выражения семантики мы используем нотации уровня 1. Так как для каждого множества сущность/связь имеется соответствующее отношение сущность/связь, приведенное выше выражение можно легко перевести в нотации уровня 2. - Ограничения на существующие значения (existing values) в
базе данных. Имеется два типа ограничений:
- Ограничения на множества существующих значений. Например:
{ NAME(e) | e ∈ MALE_PERSON } ⊆ { NAME(e) | e ∈ MALE_PERSON } - Ограничения на конкретные значения. Например:
TAX(e)≤SALARY(e), e ∈ EMPLOYEE или BUDGET(ei) = ∑ BUDGET(ej), где ei ∈ COMPANY ej ∈ DEPARTMENT и [ei,ej] ∈ COMPANY-DEPARTMENT.
- Ограничения на множества существующих значений. Например:
3.4. Семантика и множественные операции запросов выборки информации
Если запросы основываются на модели данных "сущность-связь", то становится совершенно очевидной семантика запросов выборки информации. Для ясности мы вначале обсудим ситуацию на уровне 1. Концептуально, элементы информации организованы так, как показано на рис. 4 и 5 (на рис. 2 и 3). Многие запросы выборки информации могут рассматриваться как комбинация следующих базисных типов операций:
- Выбор подмножества значений из множества значений.
- (2) Выбор подмножества сущностей из множества сущностей (т.е. выбор некоторых строк на рис. 4). Сущности выбираются с помощью указания значений некоторых атрибутов (т.е. подмножеств множеств значений) и/или их связей с другими сущностями.
- Выбор множества связей из множества связей (т.е. выбор некоторых строк на рис. 5). Связи выбираются с помощью указания значений некоторого(ых) атрибута(ов) и/или путем идентификации некоторых сущностей в связи.
- Выбор подмножества атрибутов (т.е. выбор столбцов на рис. 4 и 5).
Например, запрос выборки информации "Каков возраст служащих, чей вес больше 170 и которые работают над проектом со значением атрибута PROJECT-NO, равным 254?", может быть выражен следующим образом:
{AGE(e) | e ∈ EMPLOYEE, WEIGHT(e) > 170,
[e,ej] ∈ PROJECT-WORKER, ej ∈ PROJECT,
PROJECT-NO(ej) = 254};
или
{AGE(EMPLOYEE) | WEIGHT(EMPLOYEE) > 170,
[EMPLOYEE,PROJECT] ∈ PROJECT-WORKER,
PROJECT-NO(EMPLOYEE) = 254}.
Для выборки информации на уровне 2, организованной так, как показано на рис. 6, сущности и связи в ii и iii должны быть заменены первичными ключами (PK – Primary Key) сущностей и PK связей. Приведенный выше запрос выборки информации может быть выражен как:
{AGE(EMPLOYEE.PK) | WEIGHT(EMPLOYEE.PK) > 170,
(WORKER/EMPLOYEE.PK, PROJECT/PROJECT.PK) ∈ {PROJECT-WORKER.PK},
PROJECT-NO(PROJECT.PK) = 254};
Для выборки информации, организованной в виде отношений сущностей/связей (рис. 7, 8 и 9) мы можем использовать язык, подобный Sequel [6]:
SELECT AGE
FROM EMPLOYEE
WHERE WEIGHT > 170
AND EMPLOYEE.PK =
SELECT WORKER/EMPLOYEE.PK
FROM PROJECT-WORKER
WHERE PROJECT-NO = 254.
Можно выбирать информацию о сущностях из двух различных множеств сущностей без указания связи между ними. Например, запрос выборки информации "Перечислить имена служащих и названия кораблей (ship), которые имеют одинаковый возраст", в нотации уровня 1 может быть выражен следующим образом:
{(NAME(ei), NAME(ej))| ei ∈ EMPLOYEE, ej ∈ SHIP, AGE(ei)=AGE(ej)}.
Здесь мы больше не будем обсуждать синтаксис языка. Мы только хотим подчеркнуть, что запросы информации можно выразить, используя понятия множества и операции над множествами [17], и семантика запросов совершенно очевидна, если принять эту точку зрения.
3.5. Семантика и правила вставки, удаления и модификации
Поддержка согласованности данных после вставки, удаления и модификации данных в базе данных всегда представляет сложную проблему. Одна из основных причин заключается в том, что семантика и последствия операций вставки, удаления и модификации обычно четко не определяются; поэтому трудно найти набор правил, которые могут поддерживать согласованность данных. Мы покажем,что при использовании модели сущность-связь проблема согласованности данных упрощается.
В таблицах I-III мы обсуждаем семантику и правила3) операций вставки, удаления и модификации и на уровне 1, и на уровне 2. Уровень 1 используется для того, чтобы семантика была более понятной.
Таблица I. Вставка
|
|
|
|---|---|
|
|
|
|
|
|
Таблица II. Изменение
|
|
|
|---|---|
|
|
|
|
Таблица III. Удаление
|
|
|
|---|---|
|
|
|
|
4. АНАЛИЗ ДРУГИХ МОДЕЛЕЙ ДАННЫХ И ИХ ПОРОЖДЕНИЕ ИЗ МОДЕЛИ "СУЩНОСТЬ-СВЯЗЬ"
4.1. Реляционная модель
4.1.1 Реляционное представление данных и неоднозначность семантики. В реляционной модели отношение (relation) R – это математическое отношение, определенное на множествах X1, X2, ..., Xn:
R = {(x1,x2,...xn) | x1 ∈ X1, x2 ∈ X2, ..., xn ∈ Xn}
Множества X1, X2, ... , Xn называются доменами (domain), а (x1, x2, ..., xn) называется кортежем (tuple). На рис. 12 показано отношение EMPLOYEE. Доменами отношения являются EMPLOYEE-NO, FIRST-NAME, LAST-NAME, FIRST-NAME, LAST-NAME, NO-OF-YEAR. Порядок строк и столбцов в отношении не является существенным. Чтобы избежать неоднозначности столбцов отношения с одним и тем же доменом, имена доменов уточняются ролями (role) (для выделения роли домена в отношении). Например, в отношении EMPLOYEE, домены FIRST-NAME и LAST-NAME можно уточнить ролями LEGAL или ALTERNATIVE. Имя атрибута (attribute name) в реляционной модели – это имя домена и присоединенное к нему имя роли [10]. Сравнивая рис. 12 и 7, мы можем заметить, что домены почти эквивалентны множествам значений. Хотя может показаться, что роль и атрибут в реляционной модели служат той же цели, что и атрибут в модели сущность-связь, семантика этих терминов различается. Роль и атрибут в реляционной модели используются, главным образом, для того, чтобы различать домены с одним и тем же именем в одном и том же отношении, в то время как атрибут в модели сущность-связь – это функция, задающая отображение из множества сущностей (или связей) в множество(а) значений.
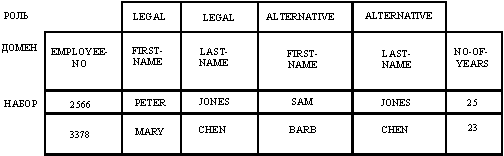
Рис. 12. Отношение EMPLOYEE
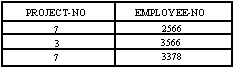
Рис. 13. Отношение EMPLOYEE-PROJECT
Использование реляционных операций в реляционной модели может вызывать семантические неоднозначности. Например, в результате соединения отношения EMPLOYEE с отношением EMPLOYEE-PROJECT (рис. 13) по домену EMPLOYEE-NO получается отношение EMPLOYEE-PROJECT' (рис. 14). Но какой смысл имеет соединение отношения EMPLOYEE с отношением SHIP по домену NO-OF-YEARS (рис. 15)? Проблема состоит в том, что одно и то же имя домена может иметь в разных отношениях разную семантику (заметим, что роль предназначена для различения доменов в данном отношении, а не во всех отношениях). Если не допускается, чтобы значения домена NO-OF-YEAR отношения EMPLOYEE были сравнимыми со значениями домена NO-OF-YEAR отношения SHIP, должны объявляться разные имена доменов. Но если такие сравнения допустимы, сможет ли система баз данных предупредить пользователя?
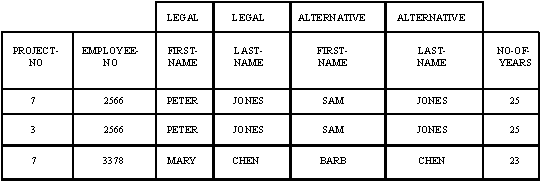
Рис. 14. Отношение EMPLOYEE-PROJECT' как "соединение" отношений EMPLOYEE
и EMPLOYEE-PROJECT
![]()
Рис. 15. Отношение SHIP
В модели сущность-связь семантика данных гораздо более очевидна. Например, один столбец в рассмотренном выше примере содержит значения AGE сущности EMPLOYEE, а другой столбец содержит AGE сущности SHIP. Если эта семантическая информация предоставлена пользователю, он может действовать более предусмотрительно (сошлемся на образцы запросов выборки информации из подраздела 3.4). Поскольку система баз данных содержит семантическую информацию, ей следует обладать возможностью предупреждать пользователя о потенциальных проблемах предложенной выше операции "типа соединения".
4.1.2 Семантика функциональных зависимостей между данными. В реляционной модели "атрибут" B отношения функционально зависит (functionally dependent) от "атрибута" A того же отношения, если каждому значению A соответствует не более, чем одно значение B. Семантика функциональных зависимостей между данными становится очевидной в модели сущность-связь. По существу, имеется два основных типа функциональных зависимостей:
- Функциональные зависимости, относящиеся к описанию сущностей или связей. Поскольку атрибут определяется как функция, он отображает сущность из множества сущностей в одно значение из множества значений (см. рис. 2). На уровне 2 для представления сущностей используются значения первичного ключа. Следовательно, неключевые множества значений (домены) функционально зависят от множества значений первичных ключей (например, на рис. 6 и 7 NO-OF-YEARS функционально зависит от EMPLOYEE-NO). Поскольку отношение может иметь несколько ключей, неключевые множества значений будут функционально зависить от любого ключевого множества значений. Ключевые множества значений будут взаимно функционально зависеть друг от друга. Аналогично, в отношении связей неключевые множества значений будут функционально зависеть от множеств значений первичных ключей (например, на рис. 8 PERCENTAGE функционально зависит от EMPLOYEE-NO и PROJECT-NO).
- Функциональные зависимости, относящиеся к сущностям в связи. Заметим, что на рис. 11 мы указываем для множеств связей типы отображений (1:n, m:n и т.д.). Например, PROJECT-MANAGER является отображением 1:n. Допустим, что PROJECT-NO – это первичный ключ в отношении сущностей PROJECT. В отношении связей PROJECT-MANAGER множество значений EMPLOYEE-NO будет функционально зависеть от множества значений PROJECT-NO (т.е. для каждого проекта имеется только один менеджер).
Проведение различия между уровнем 1 (рис. 2) и уровнем 2 (рис. 6 и 7) и разделение отношения сущностей (рис. 7) и отношения связей (рис. 8) вносит ясность в семантику функциональных зависимостей между данными.
4.1.3 3NF-отношения в сравнении с отношениями сущностей-связей. Из определения отношения следует, что любое группирование доменов можно рассматривать как отношение. Чтобы избежать нежелательных свойств в поддерживаемых отношениях, предлагается процесс нормализации, в ходе которого произвольные отношения преобразуются в первую нормальную форму, затем во вторую нормальную форму и, наконец, в третью нормальную форму (3NF) [9,11]. Мы покажем, что отношения сущностей и связей в модели сущность-связь похожи на 3NF-отношения, но обладают более ясной семантикой и не требуют выполнения операций преобразования.
Будем использовать упрощенную версию примера нормализации, описанного в [9]. Следующие три отношения находятся в первой нормальной форме (т.е. в них не используется домен, элементы которого сами являлись бы отношениями):
EMPLOYEE (EMPLOYEE-NO)
PART (PART-NO, PART-DESCRIPTION, QUANTITY-ON-HAND)
PART-PROJECT (PART-NO, PROJECT-NO, PROJECT-DESCRIPTION,
PROJECT-MANAGER-NO, QUANTITY-COMMITED)
Заметим, что домен PROJECT-MANAGER-NO (НОМЕРА МЕНЕДЖЕРОВ ПРОЕКТОВ) содержит EMPLOYEE-NO (номер служащего) менеджера проекта. В показанных выше отношениях первичные ключи подчеркнуты.
В соответствии с определенными правилами эти отношения преобразуются в третью нормальную форму:
EMPLOYEE' (EMPLOYEE-NO) PART' (PART-NO, PART-DESCRIPTION, QUANTITY-ON-HAND) PROJECT' (PROJECT-NO, PROJECT-DESCRIPTION, PROJECT-MANAGER-NO) PART-PROJECT' (PART-NO, PROJECT-NO, QUANTITY-COMMITED)Используя диаграмму "сущность-связь" с рис. 11, можно легко вывести следующие отношения сущностей и связей:
сущность PART'' (PART-NO, PART-DESCRIPTION, QUANTITY-ONHAND)
отношения PROJECT'' (PROJECT-NO, PROJECT-DESCRIPTION)
EMPLOYEE''(EMPLOYEE-NO)
связь PART-PROJECT''(PART/PART-NO, PROJECT/PROJECT-NO,
QUANTITY-COMMITED)
отношения PROJECT-MANAGER''(PROJECT/PROJECT-NO, MANAGER/EMPLOYEE-NO)
Указаны имена ролей сущностй в связях (такие как MANAGER). Имена отношений сущностей, ассоциированных с первичными ключами сущностей в связях, и имена множеств значений опущены.
Заметим, что в приведенном выше примере отношения сущностей-связей похожи на 3NF-отношения. При использовании подхода 3NF PROJECT-MANAGER-NO включается в отношение PROJECT', поскольку предполагается, что PROJECT-MANAGER-NO функционально зависет от PROJECT-NO. В модели сущность-связь PROJECT-MANAGER-NO (т.е. EMPLOYEE-NO менеджера проекта) включается в отношение связи PROJECT-MANAGER, так как в этом случае EMPLOYEE-NO рассматривается как первичный ключ сущности.
Заметим также, что при использовании подхода 3NF изменения функциональных зависимостей данных могут приводить к тому, что некоторые отношения перестают находиться в 3NF. Например, если мы делаем новое предположение, что для одного проекта могут быть несколько менеджеров, отношение PROJECT' больше не будет 3NF-отношением, и его нужно будет разбить на два отношения – PROJECT'' и PROJECT-MANAGER''. При использовании модели сущность-связь такие изменения не являются необходимыми. Следовательно, мы можем сказать, что используя модель сущность-связь мы можем привести данные к форме, аналогичной 3NF-отношениям, но с отчетливым семантическим смыслом.
Интересно отметить, что описанный выше подход декомпозиции (или преобразования) для нормализации отношений можно рассматривать как подход "снизу-вверх" в области проектировании баз данных4). При использовании этого подхода все начинается с произвольных отношений (уровень 3 на рис. 1), а затем используется некоторая семантическая информация (функциональные зависимости данных) для преобразования этих отношений в 3NF-отношения (уровень 2 на рис. 1). В модели сущность-связь принят подход "сверху-вниз", в котором используется семантическая информацию для организации данных в отношения сущностей/связей.
4.2. Сетевая модель
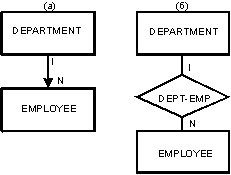
Рисунок 16. Связь DEPARTMENT-EMPLOYEE: (а) диаграмма структур данных ,(б) диаграмма сущность-связь
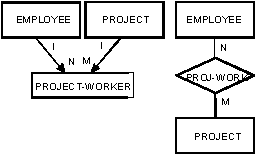
Рис. 17. Связь PROJECT-WORKER: (а) диаграмма структур данных, (б) диаграмма сущность-связь
4.2.1 Семантика диаграммы структур данных. Один из лучших способов объяснения сетевой модели состоит в использовании диаграммы структур данных (data-structure diagram) [3]. На рис. 16 показана диаграмма структур данных. Каждый прямоугольник представляет тип записи. Стрелка представляет набор структур данных, в котором запись DEPARTMENT является записью-владельцем (owner-record), и одной записи-владельцу может соответствовать n (n = 0, 1, 2, ...) записей-членов (member-records). На рис. 16(б) приведена диаграмма сущность-связь. Можно было бы заключить, что стрелка на диаграмме структур данных показывает связь между сущностями в двух множествах сущностей. Это не всегда верно. На рис. 17(а) и 17(б) показана диаграмма структур данных и диаграмма сущность-связь, выражающие связь PROJECT-WORKER между двумя типами сущностей – EMPLOYEE и PROJECT. На рис. 17(а) мы можем видеть, что связь PROJECT-WORKER становится другим типом записи, и что стрелки больше не представяют связь между сущностями. Каков реальный смысл стрелок на диаграммах структур данных? Ответ состоит в том, что стрелка представляет связь 1:n между двумя типами записи (а не сущности), и из ее наличия также следует существование пути доступа из записи-владельца к записям-членам. Диаграмма структур данных – это представление организации записей (уровень 4 на рис. 1); оно не является точным представлением сущностей и связей.
4.2.2 Порождение диаграммы структур данных. При каких условиях стрелка в диаграмме структур данных соответствует связи сущностей? Тщательное сравнение диаграмм структур данных с соответствующими диаграммами сущность-связь позволяет вывести следующие правила:
- Для бинарных связей 1:n стрелка используется для представления связи (см. рис. 16(а)).
- Для бинарных связей m:n для представления связи создается тип "запись связи", и рисуются стрелки из типа "запись сущности" к типу "запись связи" (см. рис. 16(а)).
- Для k-арных связей (k≥3) применяется то же правило, что и в случае (2) (т.е. создание типа "запись связи").

Рис. 18. Набор-структур-данных, определенных на одном типе записи
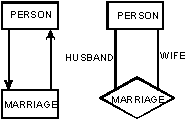
Рис. 19. Связь MARRIAGE: (а) диаграмма структур данных, (б) диаграмма сущность-связь
Поскольку в DBTG [7] не разрешается определить набор структур данных на одном типе записи (т.е. не допустим рис. 18, хотя он реализован в [13]), для реализации таких связей необходима "запись связи" (см. рис. 19(а)) [20]. Соответствующая диаграмма сущность-связь показана на рис. 19(б).
Теперь ясно, что стрелки на диаграмме структур данных не всегда представляют связи сущностей. Даже в том случае, когда стрелка представляет связь 1:n, она показывает только однонаправленную связь [20] (хотя имеется возможность найти запись-владельца по записи-члену). В модели сущность-связь представляются оба направления связи (специфицируются роли обеих сущностей). Помимо семантической неоднозначности стрелок, недостатком сетевой модели является неудобство обработки изменений семантики. Например, если связь между DEPARTMENT и EMPLOYEE из отображения 1:n превращается в отображение m:n (т.е. один служащий может принадлежать нескольким департаментам), в сетевой модели мы должны создать запись связи DEPARTMENT-EMPLOYEE. В модели сущность-связь все типы отображений обрабатываются единообразно.
Модель сущность-связь можно применять как средство при структурном проектировании баз данных с использованием сетевой модели. Вначале пользователь рисует диаграмму сущность-связь (рис. 11). Он может просто перевести ее в диаграмму структур данных (рис. 20), используя указанные выше правила. Пользователь может также следовать дисциплине, в соответствии с которой каждая сущность или связь должны отображаться в запись (то есть, "записи связей" создаются для всех типов связей, независимо от того, являются они отображениями 1:n или m:n). Таким образом, все, что нужно сделать на рис. 11 – это заменить ромбы на прямоугольники и добавить концы стрелок к соответствующим линиям. При использовании такого подхода на рис. 20 появятся еще три прямоугольника – DEPARTMENT-EMPLOYEE, EMPLOYEE-DEPENDENT и PROJECT-MANAGER (см. рис. 21). Также будут полезны ограничения, рассмотренные в подразделах 3.3-3.5.
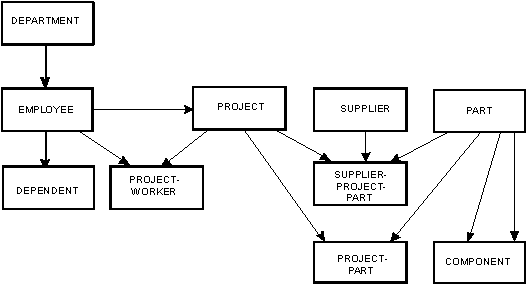
Рис. 20. Диаграмма структур данных, выведенная из диаграммы сущность-связь с рис. 11

Рис. 21. "Упорядоченная" диаграмма структур данных, выведенная из диаграммы сущность-связь с рис. 11
4.3. Модель множества сущностей
4.3.1 Представление множества сущностей. Базовый элемент модели множества сущностей – это сущность. Сущности имеют имена (имена сущностей), такие как Peter Jones, blue или 22. Имена сущностей, имеющих некоторые общие свойства, собираются в множества-имен-сущностей, которые именуются именами-множеств-имен-сущностей, например, NAME, COLOR и QUANTITY.
Сущность представляется парой имя-множества-имен-сущностей/имя-сущности, например, NAME/Peter Jones, EMPLOYEE-NO/2566 и NO-OF-YEARS/20. Сущность описывается своей связью с другими сущностями. Рис. 22 иллюстрирует представление данных в модели множества сущностей. DEPARTMENT сущности EMPLOYEE-NO/2566 – это сущность DEPARTMENT-NO/405. Другими словами, DEPARTMENT – это роль, которую играет сущность DEPARTMENT-NO/405 для описания сущности EMPLOYEE-NO/2566. Аналогично, NAME, ALTERNATIVE-NAME или AGE сущности EMPLOYEE-NO/2566 – это NAME/Peter Jones, NAME/Sam Jones или NO-OF-YEARS/20 соответственно. Описание сущности EMPLOYEE-NO/2566 – это набор связанных сущностей и их ролей (сущности и роли обведены пунктирной линией). Пример описания сущности EMPLOYEE-NO/2566 представлен на рис. 23 набором триплетов имя-роли/имя-множества-имен-сущностей/имя-сущности. Концептуально, модель множества сущностей отличается от модели сущность-связь следующим:
- В модели множества сущностей все трактуется как сущности. Например, COLOR/BLACK и NO-OF-YEARS/45 – это сущности. В модели сущность-связь blue и 36 обычно трактуются как значения. Заметим, что обработка значений как сущностей может порождать семантические проблемы. Например, на рис. 22, какова разница между EMPLOYEE-NO/2566, NAME/Peter Jones и NAME/Sam Jones? Представляют ли они различные сущности?
- В модели множества сущностей используются только бинарные связи5), в то время как в модели сущность-связь можно использовать n-арные связи.
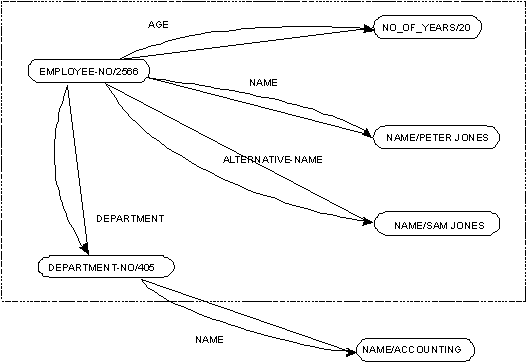
Рис. 22. Представление множества сущностей
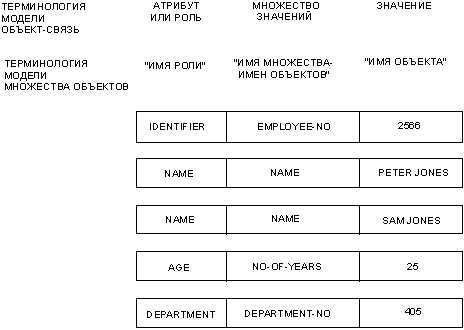
Рис. 23. Описание сущностей в модели множества сущностей
4.3.2 Вывод представления множества сущностей. Одна из главных трудностей в понимании модели множества сущностей вытекает из ее представления мира (т.е. идентификации значений с помощью сущностей). Модель сущность-связь, предложенная в этой статье, полезна в понимании и выводе представления данных в модели множества сущностей. Рассмотрим рис. 2 и 6. На рис. 2 сущности представлены как ei (которые существуют в нашем воображении или реально). На рис. 6 сущности представлены значениями. Модель множества сущностей работает и на уровне 1 и на уровне 2, но мы будем объяснять ее представление на уровне 2 (рис. 6). В модели множества сущностей все наборы значений, такие как NO-OF-YEARS, трактуются как множества-имен-сущностей, а все значения как имена сущностей. В модели множества сущностей атрибуты становятся именами ролей. Для бинарных связей перевод прост: роль сущности в связи (например, роль "DEPARTMENT" в связи DEPARTMENT-EMPLOYEE) становится именем роли сущности в описании роли другой сущности в связи (см. рис. 22). Для n-арных (n>2) связей мы должны искусственно создавать сущности для связей, чтобы трактовать эти связи как бинарные.
БЛАГОДАРНОСТИ
Автор хочет выразить свою благодарность Джорджу Мили (George Mealy), Стюарту Мэднику (Stuart Madnick), Мюрею Эдельбергу (Murray Edelberg), Сьюзан Брюер (Susan Brewer), Стефену Тоду (Stephen Todd) и рецензентам за их важные предложения (рис. 21 был предложен одним из рецензентов). Поводом к написанию этой статьи послужил ряд дискуссий с Чарльзом Бахманом (Charles Bachman). Автор также признателен Е.Ф.Кодду (E.F. Codd) и М.Е.Сенко (M.E. Senko) за их важные комментарии и обсуждения при проверке этой статьи.
Литература
- Abrial, J.R. Data semantics. In Data Base Management, J.W. Klimbie and K.L. Koffeman, Eds.,North-Holland Pub. Co., Amsterdam, 1974, pp. 1-60.
- Bachman, C.W. Software for random access processing. Datamation 11 (April 1965), 36-41.
- Bachman, C.W. Data structure diagrams. Data Base 1,2 (Summer 1969), 4-10.
- Bachman, C.W. Trends in database management – 1975. Proc., AFIPS 1975 NCC, Vol.44, AFIPS Press, Montvale, N.J., pp. 569-576.
- Birkhoff, G., and Bartee, T.C. Modern Applied Algebra. McGraw-Hill, New York, 1970.
- Chamberlin, D.D., and Raymond, F.B. SEQUEL: A structured English query language. Proc. ACM-SIGMOD 1974, Workshop, Ann Arbor, Michigan, May, 1974.
- CODASYL. Data base task group report. ACM, New York, 1971.
- Codd, E.F. A relational model of data for large shared data banks. Comm. ACM 13,6 (June 1970), 377-387.
- Codd, E.F. Normalized data base structure: a brief tutorial. Proc. ACM-SIGFIDET 1971, Workshop, San Diego, Calif., Nov. 1971, pp. 1-18.
- Codd, E.F. A data base sublanguage founded on the relational calculus. Proc. ACM-SIGFIDET 1971, Workshop, San Diego, Calif., Nov. 1971, pp. 35-68.
- Codd, E.F. Recent investigations in relational data base systems . Proc. IFIP Congress 1974, North-Holland Pub. Co., Amsterdam, pp. 1017-1021.
- Deheneffe, C., Hennebert, H., and Paulus, W. Relational model for data base. Proc. IFIP Congress 1974, North-Holland Pub. Co., Amsterdam, pp.1022-1025.
- Dodd, G.G. APL – a language for associate data handling in PL/I. Proc. AFIPS 1966 FGCC, Vol. 29, Spartan Books, New York, pp. 677-684.
- Eswaran, K.P. and Chamberlin, D.D. Functional specifications of a subsystem for data base integrity. Proc. Very Large Data Base Conf., Framingham, Mass., Sept. 1975, pp. 48-68.
- Hainaut, J.L. and Lecharlier, B. An extensible semantic model of data base and its data language. Proc. IFIP Congress 1974, North-Holland Pub. Co., Amsterdam, pp. 1026-1030.
- Hammer, M.M., and McLeod, D.J. Semantic integrity in a relation data base system. Proc. Very Large Data Base Conf., Framingham, Mass., Sept. 1975, pp.25-47.
- Lindgreen, P. Basic operations on information as a basis for data base design. Proc. IFIP Congress 1974, North-Holland Pub. Co., Amsterdam, pp.993-997.
- Mealy, G.H. Another look at data base. Proc. AFIPS 1967 FJCC, Vol. 31, AFIPS Press, Montvale, N.J., pp. 525-534.
- Nijssen, G.M. Data structuring in the DDL and the relational model. In Data Base Management, J.W. Klimbie and K.L. Koffeman, Eds., North-Holland Pub. Co., Amsterdam, 1974, pp. 363-379.
- Olle, T.W. Current and future trends in data base management systems. Proc. IFIP Congress 1974, North-Holland Pub. Co., Amsterdam, pp. 998-1006.
- Roussopoulos, N., and Mylopoulos, J. Using semantic networks for data base management. Proc. Very Large Data Base Conf., Framingham, Mass., Sept. 1975, pp. 144-172.
- Rustin, R. (Ed.). Proc. ACM-SIGMOD 1974 – debate on data models. Ann Arbor, Mich., May 1974.
- Schmid, H.A., and Swenson. J.R. On the semantic of the relational model. Proc. ACM-SIGMOD 1975, Conference, San Jose, Calif., May 1975, pp.211-233.
- Senko, M.E. Data description language in the concept of multilevel structured description: DIAM II with FORAL. In Data Base Description, B.C.M. Dougue, and G.M. Nijssen, Eds., North-Holland Pub. Co., Amsterdam, pp.239-258.
- Senko, M.E., Altman, E.B., Astrahan, M.M., and Fehder, P.L. Data structures and accessing in data base systems. IBM Syst. J. 12,1 (1973), 30-93.
- Sibley, E.H. On the equivalence of data base systems. Proc. ACM-SIGMOD 1974 debate on data models, Ann Arbor, Mich., May 1974, pp. 43-76.
- Steel, T.B. Data Base standartization – a status report. Proc. ACM-SIGMOD 1975, Conference, San Jose, Calif., May 1975, pp. 65-78.
- Stonebraker, M. Implementation of integrity constraints and views by query modification. Proc. ACM-SIGMOD 1975, Conference, San Jose, Calif., May 1975, pp. 65-78.
- Sundgren, B. Conceptual foundation of the infological approach to data bases. In Data Base Management, J.W. Klimbie and K.L. Koffeman, Eds., North-Holland Pub. Co., Amsterdam, 1974, pp. 61-95.
- Taylor, R.W. Observations on the attributes of database sets. In Data Base Description, B.C.M. Dougue and J.M. Nijssen, Eds., North-Holland Pub. Co., Amsterdam, pp.73-84.
- Tsichritzis, D. A network framework for relation implementation. In Data Base Description, B.C.M. Dougue and J.M. Nijssen, Eds., North-Holland Pub. Co., Amsterdam, pp. 269-282.
1) Возможно, некоторые люди могут относиться к чему-либо (например, браку) как к сущности, а другие могут считать это связью. Мы думаем, что в таких случаях решение должно приниматься администратором предметной области [27]. Он должен определить, что является сущностями, а что – связями, чтобы это разделение соответствовало особенностям конкретной среды.
2) Такая информация об отображениях поддерживается в DIAM II [24].
3) Наша основная цель состоит в том, чтобы проиллюстрировать семантику операций манипулирования данными. Поэтому эти правила могут быть неполными. Заметим, что последующие действия, указанные в таблицах, могут поддерживаться системой, а не пользователями.
4) Хотя подходу декомпозиции придается особое значение в литературе, посвященной реляционной модели, этот подход представляет собой процедуру получения 3NF и не является свойством, внутренне присущим 3NF.
5) В DIAM II [24] n-арные связи можно трактовать как специальные случаи идентификаторов.