Язык модификации данных формата XML функциональными методами
Д.А. Лизоркин
Труды Института системного программирования РАН
6. Реализация
Предложенный в данной статье язык модификации XML-документов был реализован фукнциональными методами программирования на языке функционального программирования Scheme.
Необходимо заметить, что функциональный стиль программирования подразумевает определенные правила, накладываемые на сделанную реализацию. А именно, чистый функциональный стиль запрещает использование в программе таких побочных эффектов, как изменение значений, однажды связанных с глобальными идентификаторами. В контексте выполненной реализации языка модификации функциональный стиль программирования означает сохранение в неизменном виде документа, подлежащего модификации, и конструирование нового документа, выражающего собой результат вычисление требуемого запроса на модификацию к исходному документу.
В отличие от процедурной и объектно-ориентированной парадигм программирования, в которых модификация обычно реализуется как принудительное изменение исходных данных, функциональная парадигма программирования позволяет гарантировать, что данные, однажды связанные с идентификатором, останутся постоянными на протяжении всего времени, пока к этим данным есть доступ из какой-либо области программы [9]. Это свойство функционального программирования обладает тем важным преимуществом, что конструирование дерева модифицированного документа не требует глубокого копирования дерева исходного документа, и части, являющиеся общими для обоих деревьев, автоматически хранятся в единственной физической копии.
Возможность использования физически разделяемого поддерева, общего для нескольких деревьев, иллюстрируется на рис. 2. Предположим, что некоторый запрос на модификацию затрагивает узел, обозначенный на рис. 2 буквой О. Тогда в результате выполнения запроса на модификацию будут переконструированы только те части дерева обрабатываемого документа, которые обозначены на рис. 2 жирными линиями, а остальные части дерева останутся неизменными и, таким образом, будут существовать в разделяемой физической копии для исходного и сконструированного деревьев.
Из рис. 2 легко видеть, что модификация в SXML-документе некоторого узла затрагивает изменение этого узла и всех его узлов-предков. Поскольку на практике глубина XML-документов и соответствующих им SXML-документов обычно бывает небольшой, выполнение запроса на модификацию, выбирающего в документе лишь несколько узлов в качестве обрабатываемых, требует переконструирования только небольшой части модифицируемого документа. Узлы, остающиеся неизменными для исходной и модифицированной версий документа, существуют в единственной физической копии, и обе версии документа адресуются к этим узлам по ссылкам.
В зависимости от конкретной прикладной задачи, приложение, использующее функциональную реализацию предлагаемого языка запросов, само определяет, каким образом обрабатывать исходную и сконструированную новую версию модифицируемого SXML-документа. Например, приложение может использовать исходную версию документа только в локальном блоке своего кода, и тогда узлы, специфичные для исходной версии документа и не используемые в других местах прикладной программы, будут освобождены автоматическим сборщиком мусора [10]. Соображения по вопросу обеспечения конкурентной обработки общего SXML-документа несколькими приложениями обсуждается в разделе 8.
В сделанной реализации вычисление запроса на модификацию SXML-документа осуществляется в следующие два этапа:
На первом этапе все обработчики сопоставляются с соответствующими им обрабатываемыми узлами, т.е. для каждой операции модификации вычисляется выражение_XPath этой операции относительно соответствующего базового узла. Заметим, что выработанный способ задания базовых узлов позволяет не вызывать ни одного обработчика при определении базовых узлов для всех операций модификации.
На втором этапе осуществляется обход дерева SXML-документа, для обрабатываемых узлов вызываются обработчики, и в соответствии с возвращаемыми результатами обработчиков конструируется дерево нового SXML-документа, соответствующего результату выполнения запроса на модификацию над исходным документом.
При вычислении выражений XPath, производимом на первом этапе обработки запроса на модификацию, желательно для каждого узла, выбранного выражением XPath, получить также все его узлы-предки, поскольку, как отмечалось выше, предков обрабатываемого узла в новой версии SXML-документа необходимо переконструировать. Для получения предков для узлов, адресуемых с помощью выражения XPath, была выбрана реализация XPath функциональными методами, обеспечивающая хранение предков контекстного узла в контексте вычисления и, благодаря этому, оптимизирующая вычисление обратных осей XPath [8]. Упомянутая реализация XPath позволяет получить результат вычисления выражения XPath в форме наборов контекстов, которые содержат всех предков для каждого из выбранных узлов SXML-документа.
Наличие известных предков каждого из обрабатываемых узлов позволяет организовать целенаправленный обход дерева SXML-документа на втором этапе обработки запроса на модификацию. А именно, благодаря тому, что корень дерева обрабатываемого документа является предком для каждого из обрабатываемого узлов, и обход дерева осуществляется сверху вниз, для любого поддерева можно сразу же установить, какие из обрабатываемых узлов располагаются внутри данного поддерева. Если в некотором поддереве не содержится ни одного обрабатываемого узла, то обход поддерева вниз может быть прекращен, потому что поддерево остается неизменным в результате выполнения запроса на модификацию.
Необходимо отметить, что семантика предлагаемого языка модификаций не противоречит тому, чтобы с одним и тем же узлом документа было ассоциировано сразу несколько обработчиков. Когда имеется несколько обработчиков, ассоциированных с одним узлом, результатом обработки данного узла служит суперпозиция применения обработчиков, и принимается следующая очередность применения обработчиков к узлу:
Если какие-то два обработчика относятся к разным операциям модификации, то эти обработчики применяются в том порядке, в каком они записаны в запросе на модификацию;
Если два обработчика относятся к одной операции модификации, то ввиду отсутствия совпадающих узлов в результате вычисления выражения XPath этим обработчикам с необходимостью соответствуют разные базовые узлы. Для обработчиков, относящихся к одной операции модификации, очередность их применения принимается совпадающей с очередностью, которую имеют соответствующие обработчикам базовые узлы в порядке документа [12], подлежащего модификации.
Введенная очередность применения обработчиков позволяет ввести логичную и интуитивно ясную семантику операции перемещения поддеревьев. А именно, ситуации, когда с одним узлом ассоциировано несколько обработчиков одной и той же операции модификации, соответствует такой запрос на перемещение, при котором несколько разных поддеревьев перемещается на общее новое место. Например, если все сноски в электронном представлении некоторой книги перемещаются в главу “Приложение”, то в соответствии с принятым соглашением об очередности применения обработчиков сноски попадут в эту главу в точности в том порядке, в котором они встречались по тексту, что полностью согласуется с интуитивным представлением об ожидаемом результате перемещения.
Выполненная реализация языка модификаций обеспечивает проверку корректности производимых модификаций в соответствии с условиями правильной сформированности XML-документов (XML well-formedness) [19]. В частности, производится проверка на отсутствие дублирующих атрибутов у данного элемента и атомарность значений атрибутов. По аналогии с языком запросов к XML-документам XQuery [2], сделанная реализация языка модификаций разрешает приложению в результате модификации элемента записывать его атрибуты и прочее содержимое в произвольном порядке. Поскольку в синтаксисе SXML атрибуты данного элемента должны быть вложены в общий список атрибутов, непосредственно следующий за именем элемента, реализация производит объединение списков атрибутов, если в результате модификации у данного элемента их получилось несколько, и переносит список объединенных атрибутов в позицию, непосредственно следующую за именем элемента и предшествующую всему прочего содержимому.
7. Алгоритмическая сложность
В отношении алгоритмической сложности вычисления языка модификаций, предлагаемого в данной статье, можно сформулировать следующую теорему.
Теорема 1 Введем следующие обозначения для характеристик запроса на модификацию и XML-документа, обрабатываемого с помощью данного запроса:
n — количество узлов в обрабатываемом документе;
m — количество операций модификации в запросе на модификацию;
kmax — максимальный размер выражения_XPath по всем операциям модификации [21];
T(n) — максимальное время работы каждого из обработчиков, присутствующих в запросе на модификацию. Время может зависеть от числа узлов в документе, например, в случае применения обработчика к корневому узлу документа;
N(n) — суммарное количество новых узлов, добавляемых в документ в результате выполнения запроса на модификацию.
Тогда время вычисления запроса на модификацию может быть оценено сверху следующим выражением:
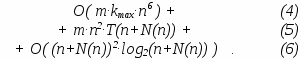
Замечание 1 Рассмотренные в разделах 3 и 4 обработчики для наиболее употребительных операций модификации вычисляются за константное время.
В справедливости данного замечания легко убедиться простым анализом реализаций рассмотренных обработчиков. Отметим, что те из обработчиков, которые требуют параметризации (например, узлом, добавляемым в документ, или новым именем узла), будучи параметризованы, выполняются за константное время. Сама параметризация относится к фазе статического анализа запроса на модификацию, равно как и разбор участвующих в запросе на модификацию выражений XPath.
Замечание 2 Данной теоремой устанавливается гарантированное полиномиальное от размера документа и от количества операций модификации время вычисления произвольного запроса на модификацию, при условии, что T(n) и N(n) полиномиальны от своих аргументов, т.е. время выполнения каждого обработчика полиномиально от размера документа, и суммарное количество новых узлов, добавленных в документ в результате выполнения запроса на модификацию, полиномиально от размера исходного документа.
Доказательство 1 (теоремы) Присутствующие в утверждении теоремы слагаемые, помеченные как (4), (5) и (6), относятся соответственно к следующим этапам вычисления запроса на модификацию:
к этапу сопоставления обработчиков с узлами;
к этапу обхода дерева документа и вызова обработчиков на обрабатываемых узлах;
к проверке корректности модификаций, произведенных по результатам вычисления обработчиков.
Доказательство теоремы заключается в последовательном рассмотрении каждого из обозначенных этапов и получении верхней оценки времени вычисления по каждому этапу.
Как обсуждалось в разделе 6, на этапе сопоставления обработчиков с узлами документа производится вычисление выражений_XPath всех операций модификации относительно базовых узлов этих операций.
Ключевым моментом на данном этапе обработки является то, что в соответствии с семантикой предлагаемого в настоящей статье языка запросов максимальное количество базовых узлов для произвольной операции модификации не зависит от количества операций модификации в запросе на модификацию. Даже в том случае, когда все операции модификации в некотором запросе на модификацию связаны посредством базовых узлов (т.е. базовыми узлами каждой последующей операции модификации являются обрабатываемые узлы предыдущей операции модификации), максимальное количество базовых узлов для любой операции модификации не может превосходить общее число узлов в обрабатываемом документе, т.е. число n .
Для вычисления выражений_XPath используется разработанная автором реализация XPath функциональными методами, которая включает в себя средства оптимизации [21], позволяющие получить гарантированную верхнюю оценку времени вычисления, равную:O( kmax·n5 ) .
Выражения XPath вычисляются относительно каждого из базовых узлов каждой из операции модификации. Умножая время вычисления выражения XPath на количество базовых узлов (которых, как показано выше, не больше n для каждой операции модификации) и на количество операций модификации m, получим (4).
На этапе обхода дерева SXML-документа производится вызов обработчиков на обрабатываемых узлах и формирование нового дерева в соответствии с возвращаемыми результатами обработчиков.
Количество обработчиков, которое может быть ассоциировано с одним узлом SXML-документа, не превосходит суммарного количества базовых узлов по всем операциям модификации, т.е. произведения m·n .
Поскольку по семантике предлагаемого языка запросов несколько обработчиков, ассоциированных с одним и тем же узлом, вызываются по правилам суперпозиции, на время выполнения одного обработчика влияют узлы, которые могли быть добавлены в результате вызовов предыдущих по порядку обработчиков, и поэтому это время оценивается сверху выражением T(n+N(n)).
Произведение максимального времени работы одного обработчика на максимальное количество ассоциированных с одним узлом обработчиков и на количество узлов в исходном документе и дает (5).Производимые проверки корректности сделанных модификаций уже не зависят от вида запроса на модификацию или количества операций модификации в нем, но зависят только от сконструированного результирующего SXML-документа. В терминах введенных в условии теоремы обозначений, данное соображение означает, что временная оценка этапа проверки корректности сделанных модификаций зависит только от числа (n+N(n)), т.е. от количества узлов в новом SXML-документе.
Среди производимых проверок асимптотически доминирует проверка на отсутствие у данного элемента нескольких атрибутов с одинаковыми именами.
Проверка на отсутствие совпадающих имен атрибутов у данного элемента производится с помощью известного алгоритма сортировки слиянием по именам атрибутов данного элемента. Время работы алгоритма сортировки слиянием оценивается выражениемO( (n+N(n))·log2(n+N(n)) ) .
Ввиду того, что данная проверка производится для каждого элемента в результирующем SXML-документе, записанная оценка умножается на число узлов в документе, что окончательно дает (6).
Сумма полученных временных оценок по каждому из этапов вычисления запроса на модификацию и обеспечивает утверждение теоремы.