2009 г.
Ориентированные на приложения методы хранения XML-данных
Максим Гринев, Иван Щеклеин
Труды Института системного программирования РАН
Назад Содержание Вперёд
3. Описание подхода
Для реализации предлагаемого подхода необходимо решить две основные задачи: разработать методы выбора структур хранения для наперед известной и неизменной рабочей нагрузки; разработать методы реорганизации структур хранения на случай изменения рабочей нагрузки. Как мы уже отмечали выше, предполагается, что для большинства приложений рабочая нагрузка (то есть запросы и операции модификации) известна заранее и не подвержена частым изменениям. В следующих подразделах мы рассматриваем каждый из этих методов.
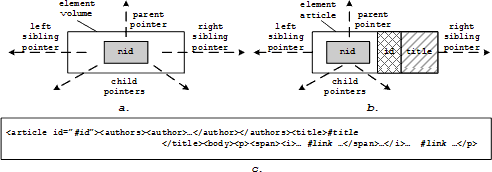
Рис. 3. Различные способы представления данных
3.1. Выбор структур хранения ориентированных на приложение
Имея заранее известную рабочую нагрузку, мы компилируем планы выполнения запросов и соответствующий план хранения данных для заданной нагрузки. В этих планах возможности языка XQuery, которые являются избыточными для поддержки требуемых запросов, не поддерживаются при выполнении. Для построения плана хранения мы используем следующие основные методы:
- Комбинирование структурного и текстового представления данных. Как уже упоминалось выше, большинство элементов в контент-ориентированных XML документах никогда не адресуются запросами. Нами был разработан метод анализа запросов, позволяющий выявить узлы документов, которые необходимо хранить в структурном представлении (т.е. поддерживая необходимые указатели для навигации между узлами документов) для возможности вычислить все запросы эффективным способом. Все остальные элементы (как правило, это элементы визуализации) сохраняются в текстовом представлении в виде текстовых узлов XML модели данных.
Разработанный метод является достаточно гибким и не ограничивается сохранением всего XML поддерева в виде текста. Элементы со структурным представлением могут иметь в качестве детей элементы с текстовым представлением, которые в свою очередь содержат в качестве детей элементы со структурным представлением. Мы также расширили этот подход для хранения в текстовом представлении некоторых элементов, адресуемых запросом, но по которым не производится поиск. Например, рассмотрим запрос «найти имена все сотрудников старше 60 лет». В этом запросе поиск производится по элементу «возраст» и этот элемент имеет смысл хранить в структурном виде. В то же время элемент «имя» можно хранить в текстовом виде как часть элемента «сотрудник», поскольку предполагается, что в результате поиска обычно возвращается небольшое число элементов, и для них извлечение имени из текстового представления через разбор на лету не является дорогостоящей операцией для всех найденных сотрудников. Для эффективного разбора на лету предлагается использовать методы потоковой обработки XML [18].
- Комбинирование методов кластеризации узлов в блоках внешней памяти. Кластеризация по описывающей схеме, используемая в Sedna XML Database [9], может быть использована совместно с методом хранения рядом детей и родителей, который используется в системах Natix и DB2 [2, 3]. Выбор способа кластеризации для различных групп узлов производится на основе анализа запросов. Комбинирование этих двух методов должно дать существенный выигрыш в производительности.
- Исключение избыточных структур и выравнивание вложенности. Анализируя запросы, можно установить, какие структуры являются избыточными для их выполнения. Главным образом, можно удалять излишние указатели и группирующие элементы. Например, реляционные XML-данные могут быть сохранены в виде компактных записей близко к тому, как они хранятся в реляционных системах. Такие записи не имеют такую же строгую структуру, как в реляционных системах, поскольку необходимо поддерживать возможность нерегулярности в данных, но группировка элементов в записи существенно повышает эффективность системы, так как сокращается количество блоков, которые необходимо прочитать.
Подобное «уплощение» данных можно проводить и в ряде других случаев для исключения промежуточных элементов. Например, если элемент «сотрудник» содержит элемент «адрес», содержащий, в свою очередь, элементы «улицы» и «дом», то элемент адрес может быть исключен, если на его уровне нет элементов с именем «улицы» и «дом», которые могут значить что-либо другое.
Обратим внимание, что метод не приводит к потере или размножению данных, а только исключает излишние структурные элементы, однако он может быть естественным образом расширен использованием проекции данных выполняемой при загрузке или модификации данных или поддержкой материализованных представлений. Проекции могут быть построены по анализу путевых выражений или предикатов с константами.
Кроме того, исключение избыточных структур (особенно указателей) имеет еще и потенциальное преимущество, связанное с тем, что узлы становятся менее связанными, что не только повышает скорость выполнения запросов и модификаций, но и открывает новые перспективы в улучшении гранулярности транзакционных блокировок и построении распределенных баз данных. Например, это создает предпосылки для реализации параллелизма по данным (data parallelism) на архитектуре shared-nothing.
3.2. Реорганизация структур хранения при изменении приложения
В случае изменения приложения (то есть изменения рабочей нагрузки) в общем случае необходимо полностью перестраивать хранимые данные с целью изменения структуры их хранения. При этом политика реорганизации может быть достаточно гибкой. Во-первых, частота, с которой производится реорганизация, может быть сделан зависимой от выбранного уровня оптимизации, который задается в приложении. Во-вторых, реорганизация будет требоваться не так часто, как это может показаться на первый взгляд. В самом деле, мало вероятно, что новые запросы, которые обращены к «реляционным» XML-данным начнут использовать ссылки на братьев (sibling pointers), которые были удалены на этапе компиляции плана хранения.
Тем не менее, в общем случае реорганизация все равно может потребоваться. Реорганизация может проводиться следующим образом. Вся база данных целиком может быть перестроена с использование массивно-параллельных распределенных вычислений. На современном оборудовании такое перестроение базы данных небольшого и даже среднего объема может быть осуществлено за приемлемое время, равное одному прочтению базы данных с диска.
Как отмечалось выше, «уплощение» структур хранения облегчает создание распределенных баз данных. Если база данных является распределенной, то такая перестройка может быть произведена еще быстрее. В простом случае (когда не были использованы методы оптимизации распределенных баз данных, например, collocated join [10]) перестройка может быть выполнена параллельно и независимо для каждого узла распределенной базы данных. В более сложном случае (данные распределены по узлам для возможности использовать collocated join) могут быть применены методы, подобные map-reduce [11], для перераспределения данных.
При реорганизации базы данных существует две основные альтернативы. Во-первых, простое решение состоит в остановке базы данных на время перестройки. Если предположить, что для малых и средних баз данных перестройка не займет много времени, то такое решение приемлемо для многих приложений и может осуществляться в ночное время. Более продвинутое решение состоит в использовании механизма теневых страниц (или snapshot isolation [12]) для реорганизации базы данных без ее остановки.
4. Представление данных физического уровня
В этом разделе мы даем обзор основных идей для создания перестраиваемого внутреннего представления XML-данных, оптимизированного под заданную рабочую нагрузку.
Вернемся к примеру, приведенному в разд. 2. Описывающая схема используется для группировки XML-узлов по путям в документе. Для каждой группы узлов оптимальный способ хранения выбирается с учетом нагрузки (рис. 3, a-c):
- Дискриптор узла (node descriptor). Каждый узел в группе может быть сохранен как дескриптор узла, который имеет прямые указатели на детей, родителей и братьев. Это дает возможность эффективной навигации для вычисления структурных путевых выражений [9]. Кроме того, в этом подходе может быть использована нумерующая схема [11, 9]. Каждый дескриптор узла содержит метку номерующей схемы (nid). Основное преимущество использования нумерующей схемы состоит в быстром определении связей предок-потомок между любой парой узлов. Нумерующая схема может быть также использована для определения связей, заданных порядком узлов в документе (document order relationship).
- Значения, упакованные в дескриптор узла. Для некоторых узлов могут быть использованы структуры, схожие с записями, используемыми при хранении реляционных данных [20]. Запись упаковывается в дескриптор узла (как значения id и title, показанные на рисунке 3, b). Такое “уплощение” данных дает несколько преимуществ. Во-первых, мы получаем практически максимально компактное представление за счет избавления от лишних указателей. Во-вторых, ускоряется выполнение путевых выражений. Особенно тех, которые накладывают условия на упакованные узлы (например, //article[@id eq “1”]). В-третьих, существенно ускоряется скорость сериализации данных.
- Узлы, упакованные в текст. Узлы, которые не адресуются запросами (например, элементы визуализации) могут храниться в сериализованном текстовом виде. Это позволяет существенно сэкономить место и увеличить скорость сериализации. Как упоминалось в разд. 3, этот подход не исключает полностью возможность запрашивать элементы из текстового представления, поскольку может быть использован механизм разбора текстового представления на лету. Тестовое представление может содержать заглушки (placeholders) для ссылок на узлы, сохраненные с использование двух приведенных выше методов.
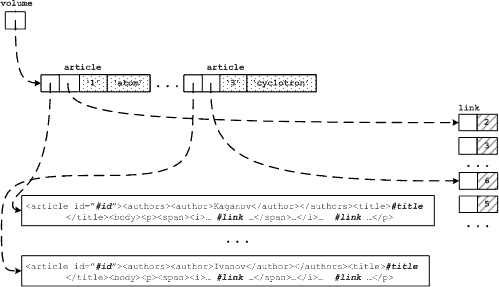
Рис. 4. Пример внутреннего представления данных
На рис. 4 показан план хранения для примера, приведенного в разд. 2. В соответствии с этим планом получается следующее:
- Узлы article и link представляются в структурном виде с использованием дескрипторов узлов. Это связано с тем, что эти узлы напрямую запрашиваются и сериализуются в запросах Q1-Q5. При этом метки описывающей схемы и указатели на братьев не хранятся, поскольку они не используются для выполнения запросов.
- Атрибуты id и idref упакованы в дескрипторы родительских узлов, поскольку по ним производится поиск для извлечения этих родительских узлов.
- Узел title запрашивается и сериализуется в путевых выражениях запросов Q1-Q5, поэтому он также «уплощается».
- Узлы author и другие дети узла article упакованы в текстовые представления. При сериализации узла article, заглушки #id, #title и #link заменяются полями id, title и link соответственно.
5. Близкие работы
Нам известно очень небольшое число работ посвященных методам хранения XML данных с возможность оптимизации под приложение. В системе OrientStore [13] был предложен подход, в котором комбинируются способы представления данных, предложенные в системах Natix [2] и Senda [4]. Однако подход системы OrientStore не предполагает анализ запросов и основан только на анализе схемы данных. Кроме того, внутреннее представление поддерживает все возможности модели данных XQuery, что зачастую является избыточным, как мы показали в этой статье.
Подходы к хранению данных, предложенные в системах LegoDB [14, 15] или XCacheDB [21], очень близки к подходам, предложенным в этой статье. Тем не менее, эти системы полностью построены над реляционными системами, что накладывает свои ограничения и вызывает дополнительные накладные расходы.
Предложенные в этой статье идеи не следует путать с так называемым подходом компонентных баз данных (component databases) [16, 17]. По нашему мнению, компонентные база данных являются общим подходом, который не допускает эффективной реализации на практике. В отличие от компонентных баз данных, мы не предлагаем общей системы, предназначенной для принципиально различных классов приложений (таких как OLTP, OLAP и другие) и принципиально различных аппаратных платформ (таких как PDA, персональные компьютеры, серверы и другие). Предложенные в этой статье идеи ограничиваются расширением оптимизации запросов на оптимизацию структур хранения с целью избавления от избыточных свойств модели данных XQuery.
6. Заключение и будущие работы
В данной статье были предложены методы оптимизации структур физического хранения XML данных для эффективного выполнения запросов из предопределенной рабочей нагрузки. Нами были описаны только предварительные результаты, однако предварительные эксперименты подтверждают действенность предложенного подхода. Он позволяет существенно сократить размер внутреннего представления, а также увеличить скорость выполнения запросов. Основным результатом данной работы должно стать создание системы, реализующей модель данных XQuery достаточно эффективно для использования XQuery-систем на практике. В будущих работах мы планируем разработать формальные методы анализа запросов, позволяющие автоматически строить планы хранения данных. Кроме того, мы планируем создать методы, позволяющие производить эффективную реорганизацию базы данных без необходимости ее остановки.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС