Концептуальное проектирование реляционных баз данных с использованием языка UML
С. Д. Кузнецов
Реляционная модель данных в подавляющем большинстве случаев вполне достаточна для моделирования любых данных. Однако проектирование базы данных в терминах схемы отношений на практике может вызвать большие затруднения, т.к. в этой модели изначально не предусмотрены механизмы описания семантики предметной области. С этим связано появление семантических моделей данных, которые позволяют описать конкретную предметную область гораздо ближе к интуитивному пониманию и, в то же время, достаточно формальным образом.
Часто семантическое моделирование используется только на первой стадии проектирования базы данных. Концептуальная схема будущей БД строится на основе некоторой семантической модели, а затем вручную преобразуется к реляционной схеме.
Существуют методики, четко описывающие все этапы такого преобразования.
При таком подходе отсутствует потребность в дополнительных программных средствах, поддерживающих семантическое моделирование. Требуется только владение основами выбранной семантической модели и правилами преобразования концептуальной схемы в реляционную.
Следует заметить, что многие начинающие проектировщики баз данных недооценивают важность семантического моделирования вручную. Зачастую это воспринимается как дополнительная и излишняя работа. Эта точка зрения является абсолютно неверной. Во-первых, построение мощной и наглядной концептуальной схемы БД позволяет более полно оценить специфику моделируемой предметной области и избежать возможных ошибок на стадии проектирования схемы реляционной БД. Во-вторых, на этапе семантического моделирования производится очень важная документация (хотя бы в виде вручную нарисованных диаграмм и комментариев к ним), которая может оказаться полезной не только при проектировании схемы реляционной БД, но и при эксплуатации, сопровождении и развитии уже заполненной БД.
Мне неоднократно приходилось наблюдать жизненные ситуации, когда отсутствие такого рода документации существенно затрудняло выполнение даже небольших изменений в схеме существующей реляционной БД. Конечно, это относится к случаям, когда проектируемая БД содержит не слишком малое число таблиц. Скорее всего, можно обойтись без семантического моделирования, если число таблиц не превышает десяти, но оно становится совершенно необходимым, если БД включает более сотни таблиц. Для справедливости заметим, что ручная процедура создания концептуальной схемы с ее последующим преобразованием к реляционной схеме БД в случае больших БД (несколько сотен таблиц) затруднительна. Причины, по всей видимости, не требуют пояснений.
История систем автоматизации проектирования баз данных (CASE-средств) начиналась с автоматизации процесса рисования диаграмм, проверки их формальной корректности, обеспечения средств долговременного хранения диаграмм и другой проектной документации. Конечно, компьютерная поддержка работы с диаграммами очень полезна для проектировщика БД. Наличие электронного архива проектной документации помогает при эксплуатации, администрировании и сопровождении базы данных. Но система, которая ограничивается поддержкой рисования диаграмм, проверкой их корректности и хранением, напоминает текстовый редактор, поддерживающий ввод, редактирование и проверку синтаксической корректности конструкций некоторого языка программирования, но существующий отдельно от компилятора. Кажется естественным желание расширить такой редактор функциями компилятора, и это действительно возможно, поскольку известна техника компиляции конструкций языка программирования в коды целевого компьютера. Но коль скоро имеется четкая методика преобразования концептуальной схемы БД в реляционную схему, то почему бы ни выполнить программную реализацию соответствующего “компилятора” и ни включить ее в состав системы проектирования баз данных?
Эта простая мысль, естественно, не могла не придти в головы производителей CASE-средств проектирования БД. Подавляющее большинство подобных систем, представленных на рынке, обеспечивает автоматизированное преобразование диаграммных концептуальных схем баз данных, представленных в той или иной семантической модели данных, в реляционные схемы, представленные чаще всего на языке SQL. У читателя может возникнуть вопрос, почему в предыдущем предложении говорится про “автоматизированное”, а не про “автоматическое” преобразование? Все дело в том, что в типичной схеме SQL-ориентированной БД могут содержаться определения многих объектов (ограничений целостности общего вида, триггеров и хранимых процедур и т.д.), которые невозможно сгенерировать автоматически на основе концептуальной схемы. Поэтому на завершающем этапе проектирования реляционной схемы снова требуется ручная работа проектировщика.
Еще раз обратите внимание на то, какой ход рассуждений привел нас к выводу о возможности автоматизации процесса преобразования концептуальной схемы БД в реляционную. Если создатели семантической модели данных предоставляют методику преобразования концептуальных схем в реляционные, достаточную для ее применения человеком, то почему бы ни реализовать программу, которая производит те же преобразования, следуя той же методике? Зададимся теперь другим, но, по существу, похожим вопросом. Если создатели семантической модели данных предоставляют язык (например, диаграммный), используя который проектировщики БД могут на основе исходной информации о предметной области сформировать концептуальную схему БД, то почему бы ни реализовать программу, которая сама генерирует концептуальную схему БД в соответствующей семантической модели, используя исходную информацию о предметной области? Хотя мне неизвестны коммерческие CASE-средства проектирования БД, поддерживающие такой подход, экспериментальные системы успешно существовали. Они представляли собой интегрированные системы проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области и последующим преобразованием концептуальной схемы в реляционную.
Существует много разных подходов к семантическому моделированию баз данных. В последние 10 лет одним из наиболее популярных языков семантического моделирования является UML. Проектирование реляционных БД – только одна и не слишком большая область применения этого языка, его возможности гораздо шире, однако подмножество UML (диаграммы классов) успешно применяется именно для таких целей.
По моему мнению, языковой механизм диаграмм классов по своей сути не отличается от существенно ранее внедренного в практику языкового механизма ER-диаграмм. Тем не менее, проектирование реляционных баз данных в среде UML дает одно существенное преимущество: можно выполнить весь проект создания информационной системы на основе одного общего инструмента (предвижу возражения сторонников ER-диаграмм).
Языку объектно-ориентированного моделирования UML (Unified Modeling Language) посвящено великое множество книг, многие из которых переведены на русский язык (а некоторые и написаны российскими авторами). UML разработан и развивается консорциумом OMG (Object Management Group) и имеет много общего с объектными моделями, на которых основана технология распределенных объектных систем CORBA, и объектной моделью ODMG (Object Data Management Group).
Основные понятия диаграмм классов UML
Диаграммой классов в терминологии UML называется диаграмма, на которой показан набор классов (и некоторых других сущностей, не имеющих явного отношения к проектированию БД), а также связей между этими классами (иногда термин relationship переводится на русский язык не как “связь”, а как “отношение”). Кроме того, диаграмма классов может включать комментарии и ограничения. Ограничения могут неформально задаваться на естественном языке или же могут формулироваться на языке OCL (Object Constraints Language), который является частью общей спецификации UML, но, в отличие от других частей языка, имеет не графическую, а линейную нотацию. Мы затронем эту тему ниже немного более подробно.
Классом называется именованное описание совокупности объектов с общими атрибутами, операциями, связями и семантикой. Графически класс изображается в виде прямоугольника. У каждого класса должно иметься имя (текстовая строка), уникально отличающее его ото всех других классов. При формировании имен классов в UML допускается использование произвольной комбинации букв, цифр и даже знаков препинания. Однако на практике рекомендуется использовать в качестве имен классов короткие и осмысленные прилагательные и существительные, каждое из которых начинается с заглавной буквы. Примеры описания классов показаны на рисунке:

Атрибутом класса называется именованное свойство класса, описывающее множество значений, которые могут принимать экземпляры этого свойства. Класс может иметь любое число атрибутов (в частности, не иметь ни одного атрибута). Свойство, выражаемое атрибутом, является свойством моделируемой сущности, общим для всех объектов данного класса. Так что атрибут является абстракцией состояния объекта. Любой атрибут любого объекта класса должен иметь некоторое значение.

Класс Человек с указанными именами атрибутов
Имена атрибутов представляются в разделе класса, расположенном под именем класса. Хотя UML не накладывает ограничений на способы формирования имен атрибутов (имя атрибута может быть произвольной текстовой строкой), на практике рекомендуется использовать короткие прилагательные и существительные, смысл которых соответствует смыслу соответствующего свойства класса. Первое слово в имени атрибута рекомендуется писать с прописной буквы, а все остальные слова – с заглавной буквы.
Операцией класса называется именованная услуга, которую можно запросить у любого объекта этого класса. Операция – это абстракция того, что можно делать с объектом. Класс может содержать любое число операций (в частности, не содержать ни одной операции). Набор операций класса является общим для всех объектов данного класса.
Операции класса определяются в разделе, расположенном ниже раздела с атрибутами. При этом можно ограничиться только указанием имен операций, оставив более детальную спецификацию выполнения операций на поздние этапы моделирования. Для именования операций рекомендуется использовать глагольные обороты, соответствующие ожидаемому поведению объектов данного класса. Описание операции может также содержать ее сигнатуру, т.е. имена и типы всех параметров, а если операция является функцией, то и тип ее значения. Класс Человек с определенными операциями показан на рисунке:

Для класса Человек мы определили три операции. Операция “выдатьВозраст” использует значение атрибута “датаРождения” и значение текущей даты. Операция “сохранитьТекущийДоход” позволяет зафиксировать в состоянии объекта сумму и дату поступления дохода данного человека. Операция “выдатьОбщийДоход” выдает суммарный доход данного человека за указанное время. Заметим, что состояние объекта меняется при выполнении только второй операции. Результаты первой и третьей операций формируется на основе текущего состояния объекта.
В диаграмме классов могут участвовать связи трех разных категорий: зависимость (dependency), обобщение (generalization) и ассоцирование (association). Для проектирования реляционных БД наиболее важны вторая и третья категории связей. Поэтому по поводу связей-зависимостей мы будет очень кратки.
Связи-зависимости
Зависимостью называют связь по использованию, когда изменение в спецификации одного класса может повлиять на поведение другого, использующего первый класса. Чаще всего зависимости применяются в диаграммах классов, чтобы отразить в сигнатуре операции одного класса тот факт, что параметром этой операции могут быть объекты другого класса. Понятно, что если интерфейс этого второго класса изменяется, то это влияет на поведение объектов первого класса. Простой пример диаграммы классов со связью-зависимостью показан на рисунке:
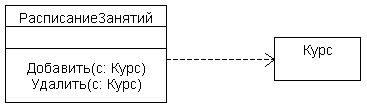
Зависимость показывается прерывистой линией со стрелкой, направленной к классу, от которого имеется зависимость. Легко видеть, что связи-зависимости существенны для объектно-ориентированных систем (в том числе и для ООБД). При проектировании реляционных БД непонятно, что делать с зависимостями (как воспользоваться этой информацией в реляционной БД?).
Связи-обобщения
Связью-обобщением называется связь между общей сущностью, называемой суперклассом, или родителем, и более специализированной разновидностью этой сущности, называемой подклассом, или потомком. Обобщения иногда называют связями “is a”, имея в виду, что класс-потомок является частным случаем класса-предка. Класс-потомок наследует все атрибуты и операции класса-предка, но в нем могут быть определены дополнительные атрибуты и операции.
Объекты класса-потомка могут использоваться везде, где могут использоваться объекты класса-предка. Это свойство называют полиморфизмом по включению, имея в виду, что объекты потомка можно считать включаемыми в класс-предок. Графически обобщения изображаются в виде сплошной линии с большой незакрашенной стрелкой, направленной к суперклассу. На рисунке показан пример иерархии одиночного наследования: у каждого подкласса имеется только один суперкласс.
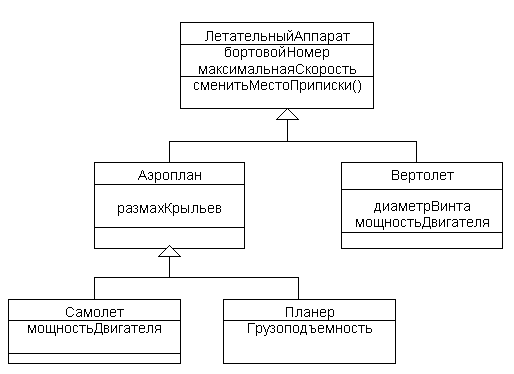
Иерархия одиночного наследования классов
Одиночное наследование является достаточным в большинстве практических случаев применения связи-обобщения. Однако в UML допускается и множественное наследование, когда один подкласс определяется на основе нескольких суперклассов. В качестве одного из разумных примеров рассмотрим следующую диаграмму классов (для упрощения диаграммы не будем указывать имена атрибутов и операций).
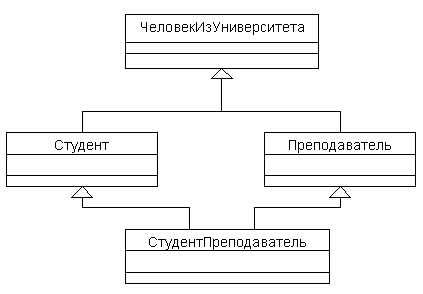
Пример множественного наследования классов
На этой диаграмме классы Студент и Преподаватель порождены из одного суперкласса ЧеловекИзУниверситета. Но как это часто случается, многие студенты уже в студенческие годы начинают преподавать, так что могут существовать такие два объекта классов Студент и Преподаватель, которым соответствует один объект класса ЧеловекИзУниверситета. Итак, среди объектов класса Студент могут быть преподаватели, а некоторые преподаватели могут быть студентами. Мы можем определить класс СтудентПреподаватель путем множественного наследования от суперклассов Студент и Преподаватель. Объект класса СтудентПреподаватель обладает всеми свойствами и операциями классов Студент и Преподаватель, и может быть использован везде, где могут использоваться объекты этих классов. Так что полиморфизм по включению продолжает работать.
Но множественное наследование, помимо того, что не слишком часто требуется на практике, порождает ряд проблем, из которых одной из наиболее известных является проблема именования атрибутов и операций в подклассе, полученном путем множественного наследования. Например, предположим, что при образовании подклассов Студент и Преподаватель в них обоих был создан атрибут с именем “номерКомнаты”. Очень вероятно, что для объектов класса Студент значениями этого атрибута будут номера комнат в студенческом общежитии, а для объектов класса Преподаватель – номера служебных кабинетов. Как быть с объектами класса СтудентПреподаватель, для которых существенны оба одноименных атрибута? На практике применяется одно из следующих решений:
- запретить образование подкласса СтудентПреподаватель, пока в одном из суперклассов не будет произведено переименование атрибута “номерКомнаты”;
- наследовать это свойство только от одного из суперклассов, так что, например, значением атрибута “номерКомнаты” у объектов класса СтудентПреподаватель всегда будут номера служебных кабинетов;
- унаследовать в подклассе оба свойства, но автоматически переименовать оба атрибута, чтобы прояснить их смысл; назвать их, например, “номерКомнатыСтудента” и “номерКомнатыПреподавателя”.
Ни одно из решений не является полностью удовлетворительным. Первое решение требует возврата к ранее определенному классу, имена атрибутов и операций которого, возможно, уже используются в приложениях. Второе решение нарушает логику наследования, не давая возможности на уровне подкласса использовать все свойства суперклассов. Наконец, третье решение заставляет использовать длинные имена атрибутов и операций, которые могут стать недопустимо длинными, если процесс множественного наследования будет продолжаться от полученного подкласса.
Но, конечно, сложность проблемы именования атрибутов и операций не идет ни в какое сравнение со сложностью реализации множественного наследования в реляционных БД. Поэтому при использовании UML для проектирования реляционных БД нужно очень осторожно использовать наследование классов и стараться вообще избегать множественного наследования.
Связи-ассоциации
Ассоциацией называется структурная связь, показывающая, что объекты одного класса некоторым образом связаны с объектами другого или того же самого класса. Допускается, чтобы оба конца ассоциации относились к одному классу. В ассоциации могут связываться два класса, и тогда она называется бинарной. Допускается создание ассоциаций, связывающих сразу n классов (они называются n-арными ассоциациями). Графически ассоциация изображается в виде линии, соединяющей класс сам с собой или с другими классами.
С понятием ассоциации связаны четыре важных дополнительных понятия: имя, роль, кратность и агрегация. Во-первых, ассоциации может быть присвоено имя, характеризующее природу связи. Смысл имени уточняется черным треугольником, располагаемым над линией связи справа или слева от имени ассоциации. Этот треугольник указывает направление, в котором должно читаться имя связи. Пример именованной ассоциации показан на рисунке. Треугольник означает, что именованная ассоциация должна читаться как “Студент учится в Университете”.

Пример именованной ассоциации
Другим способом именования ассоциации является указание роли каждого класса, участвующего в этой ассоциации. Роль класса задается именем, помещаемым под линией ассоциации ближе к данному классу. На следующем рисунке показаны две ассоциации между классами Человек и Университет, в которых эти классы играют разные роли. Как мы видим, объекты класса Человек могут выступать в роли РАБОТНИКОВ при участии в ассоциации, в которой объекты класса Университет играют роль НАНИМАТЕЛЯ. В другой ассоциации объекты класса Человек играют роль СТУДЕНТА, а объекты класса УНИВЕРСИТЕТ – в роли ОБУЧАЮЩЕГО.
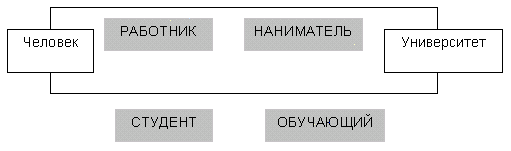
Две ассоциации с разными ролями классов
В общем случае, для ассоциации может задаваться и ее собственное имя, и имена ролей классов. Это связано с тем, что класс может играть одну и ту же роль в разных ассоциациях, так что в общем случае пара имен ролей классов не идентифицирует ассоциацию. С другой стороны, в простых случаях, когда между двумя классами определяется только одна ассоциация, можно вообще не связывать с ней дополнительные имена.
Кратностью (multiplicity) роли ассоциации называется характеристика, указывающая, сколько объектов класса с данной ролью может или должно участвовать в каждом экземпляре ассоциации (в UML экземпляр ассоциации называется соединением – link). Наиболее распространенным способом задания кратности роли ассоциации является указание конкретного числа или диапазона. Например, указание “1” говорит о том, что все объекты класса с данной ролью должны участвовать в некотором экземпляре данной ассоциации, причем в каждом экземпляре ассоциации может участвовать ровно один объект класса с данной ролью. Указание диапазона “0..1” говорит о том, что не все объекты класса с данной ролью обязаны участвовать в каком-либо экземпляре данной ассоциации, но в каждом экземпляре ассоциации может участвовать только один объект. Аналогично, указание диапазона “1..*” говорит, что все объекты класса с данной ролью должны участвовать в некотором экземпляре данной ассоциации, и в каждом экземпляре ассоциации должен участвовать хотя бы один объект (верхняя граница не задана). Толкование диапазона “0..*” является очевидным расширением случая “0..1”.
В более сложных (но крайне редко встречающихся на практике) случаях определения кратности можно использовать списки диапазонов. Например, список “2, 4..6, 8..*” говорит, что все объекты класса с указанной ролью должны участвовать в некотором экземпляре данной ассоциации, и в каждом экземпляре ассоциации должны участвовать два, от четырех до шести или более восьми объектов класса с данной ролью.
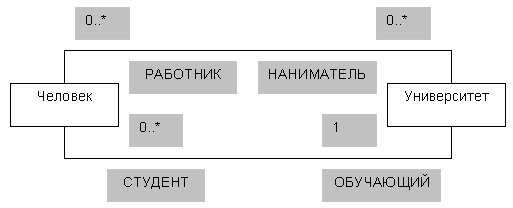
Ассоциации с указанными кратностями ролей
На диаграмме классов с рисунка показано, что произвольное (может быть, нулевое) число людей являются работниками произвольного числа университетов. Каждый университет обучает произвольное (может быть, нулевое) число студентов, но каждый студент может быть студентом только одного университета.
Обычная ассоциация между двумя классами характеризует связь между равноправными сущностями: оба класса находятся на одном концептуальном уровне. Иногда в диаграмме классов требуется отразить тот факт, что ассоциация между двумя классами имеет специальный вид “часть-целое”. В этом случае класс “целое” имеет более высокий концептуальный уровень, чем класс “часть”. Ассоциация такого рода называется агрегатной. Графически агрегатные ассоциации изображаются в виде простой ассоциации с незакрашенным ромбом на стороне класса-“целого”. Простой пример агрегатной ассоциации показан на рисунке:
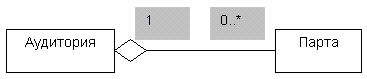
Пример агрегатной ассоциации
Объектами класса Аудитория являются студенческие аудитории, в которых проходят занятия. В каждой аудитории должны быть установлены парты. Поэтому в некотором смысле класс Парта является “частью” класса Аудитория. Мы умышленно сделали роль класса Парта необязательной, поскольку могут существовать аудитории без парт (например, класс для занятий танцами), и некоторые парты могут находиться на складе. Обратите внимание, что хотя аудитории, не оснащенные партами, как правило, непригодны для занятий, объекты классов Аудитория и Парта существуют независимо. Если некоторая аудитория ликвидируется, то находящиеся в ней парты не уничтожаются, а переносятся на склад.
Бывают случаи, когда связь “части” и “целого” настолько сильна, что уничтожение “целого” приводит к уничтожению всех его “частей”. Агрегатные ассоциации, обладающие таким свойством, называются композитными, или просто композициями. При наличии композиции объект-часть может быть частью только одного объекта-целого (композита). При обычной агрегатной ассоциации “часть” может одновременно принадлежать нескольким “целым”. Графически композиция изображается в виде простой ассоциации, дополненной закрашенным ромбом со стороны “целого”. Пример композитной агрегатной ассоциации показан на рисунке:
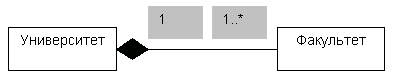
Пример композитной агрегатной ассоциации
Любой факультет является частью одного университета, и ликвидация университета приводит к ликвидации всех существующих в нем факультетов (хотя во время существования университета отдельные факультеты могут ликвидироваться и создаваться).
Заметим, что в контексте проектирования реляционных БД агрегатные и в особенности композитные ассоциации влияют только на способ поддержки ссылочной целостности. В частности, композитная связь является явным указанием того, что ссылочная целостность между “целым” и “частями” должна поддерживаться путем каскадного удаления частей при удалении целого. При наличии простой ассоциации между двумя классами предполагается возможность навигации между объектами, входящими в один экземпляр ассоциации. Если известен конкретный объект-студент, то должна обеспечиваться возможность узнать соответствующий объект-университет. Если известен конкретный объект-университет, то должна обеспечиваться возможность узнать все соответствующие объекты-студенты. Другими словами, если не оговорено противное, то навигация по ассоциации может проводиться в обоих направлениях. Однако бывают случаи, в которых желательно ограничить направление навигации для некоторых ассоциаций. В этом случае на линии ассоциации ставится стрелка, указывающая направление навигации. Возможный пример показан на рисунке:
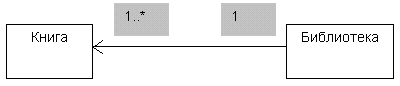
Ассоциация с указанным направлением навигации
В библиотеке должно содержаться некоторое число книг, но каждая книга должна принадлежать некоторой библиотеке. С точки зрения библиотечного хозяйства разумно иметь возможность найти книгу в библиотеке, т.е. произвести навигацию от объекта-библиотеке к связанным с ним объектам-книгам. Однако вряд ли потребуется по данному экземпляру книги узнать, в какой библиотеке она находится.
Ограничения и язык OCL
Как уже отмечалось, в диаграммах классов могут указываться ограничения целостности, которые должны поддерживаться в проектируемой БД. Имеются два способа определения ограничений: на естественном языке и на языке OCL. На рисунке показана простая диаграмма классов Студент и Университет с ограничением, выраженном на естественном языке.

Ограничение, выраженное на естественном языке
В данном случае накладывается ограничение на состояние объектов классов Студент и Университет, входящих в один экземпляр ассоциации. Объект класса Студент может входить в экземпляр связи с объектом класса Университет только при том условии, что размер стипендии данного студента находится в диапазоне, допустимом в данном университете.
Более точный и лаконичный способ формулировки ограничений обеспечивает язык OCL (Object Constraint Language). Приведем его сжатое описание.
К заимствованным из UML концепциям относятся, в первую очередь, следующие:
- Класс, операция, атрибут
- Объект (экземпляр класса)
- Ассоциация
- Тип данных (включая набор предопределенных типов Boolean, Integer, Real и String)
- Значение (экземпляр типа данных).
Существенными для понимания языка OCL являются определенные в UML отличия между объектом некоторого класса и значением некоторого типа, обычные для объектных моделей данных.
- Объект имеет уникальный идентификатор и может сравниваться с другими объектам только по значению идентификатора, следствием чего является возможность определения множественных операций над объектами в терминах их идентификаторов;
- Объект может быть ассоциирован через бинарную связь с другими объектами, что позволяет определить в OCL операцию перехода от объекта к связанным с ним объектам;
- В то же время значение является “чистым значением” в том смысле, что
- при сравнении двух значений проверяются сами эти значения, и, кроме того,
- значения никак не могут участвовать в связи, поскольку это понятие определено только для объектов классов.
В дополнение к скалярным типам данных, заимствованным из UML, в OCL предопределены структурные типы, которые являются разновидностями коллекций (collection):
- Математическое множество (set), т.е. неупорядоченная коллекция, не содержащая одинаковых элементов;
- Мультимножество (bag), т.е. коллекция, которая может содержать повторяющиеся элементы;
- Последовательность (sequence), т.е. упорядоченная коллекция, которая может содержать повторяющиеся элементы.
В OCL элементами каждого из трех типов коллекций могут быть либо объекты, либо значения.
Основной задачей, которую призван решить язык OCL, является определение ограничений на данные, соответствующие модели, которая представлена в терминах диаграммы классов. OCL может применяться для определения ограничений, описывающих пред- и постусловия операций классов, и ограничений, представляющих собой инварианты классов. При проектировании реляционных баз данных возможность определения пред- и постусловий операций вряд ли может оказаться существенной. С точки зрения определения ограничений целостности баз данных более важны средства определения инвариантов классов.
Под инвариантом класса в OCL понимается условие, которому должны удовлетворять все объекты данного класса. Более точно, инвариант класса - это логическое выражение, вычисление которого должно давать true при создании каждого объекта данного класса и сохранять это значение в течение всего времени существования объекта. При определении инварианта требуется указать имя класса и выражение, определяющее инвариант указанного класса. Синтаксически это выглядит следующим образом:
context <class_name> inv: <OCL выражение>
где <class-name> является именем класса, для которого определяется инвариант, inv – ключевое слово, говорящее о том, что определяется именно инвариант, а не другой вид ограничений, и context – ключевое слово, которое говорит о том, что контекстом следующего после двоеточия OCL-выражения являются объекты класса <class-name>, то есть OCL-выражение должно принимать истинное значение для всех объектов этого класса.
Отметим, что OCL является типизированным языком, поэтому у каждого выражения имеется некоторый тип. Естественно, что OCL-выражение в инварианте класса должно быть логического типа.
В общем случае OCL-выражение в определении инварианта основывается на композиции операций, которым посвящена большая часть определения языка. В спецификации языка эти операции условно разделены на следующие группы: операции над значениями предопределенных в UML (скалярных) типов данных, операции над объектами, операции над множествами, операции над мультимножествами, операции над последовательностями. Далее рассматриваются каждая из групп операций.
Операции над значениями предопределенных типов данных
Полагая очевидной семантику предопределенных скалярных типов данных и операций над ними, ограничимся лишь их перечислением. OCL поддерживает следующие заимствованные из определения UML скалярные типы данных: Boolean, Integer, Real и String.
Операции над объектами
Над объектами в OCL определены три операции: получение значения атрибута, переход по соединению, вызов операции класса (последняя операция несущественна для целей проектирования реляционных БД). Для записи этих трех операций используется “точечная нотация”.
Например, результатом выражения вида:
<объект>.<имя атрибута>
является текущее значение атрибута с именем <имя атрибута>, если объект имеет такой атрибут. В противном случае использование такого выражения приводит к возникновению ошибки типа.
Результатом применения к объекту операции перехода по соединению (экземпляру ассоциации) является коллекция, содержащая все объекты, которые ассоциированы с данным объектом через указываемое соединение. Это соединение идентифицируется именем роли, противоположной по отношению к данному объекту. Таким образом, синтаксис выражения перехода по соединению следующий:
<объект>.<имя противоположенной по отношению к объекту роли ассоциации>
Операции над множествами, мультимножествами и последовательностями
В OCL поддерживается богатый набор операций над значениями коллекционных типов данных. Обсудим только те из них, которые являются наиболее уместными в контексте данной статьи. Синтаксически операции над коллекциями записываются в нотации, аналогичной точечной, но вместо точки используется “®”. Таким образом, общий синтаксис применения операции к коллекции следующий:
<коллекция> ® <имя операции> ( <список фактических параметров> )
Операция select
В OCL определены три одноименных операции select, которые воздействуют на заданные множество, мультимножество или последовательность на основе заданного логического выражения над элементами коллекции. Результатом каждой операции является новое множество, мультимножество или последовательность соответственно из тех элементов входной коллекции, для которых результатом вычисления логического выражения является true.
Операция collect
Аналогично набору операций select, определены три операции collect, воздействующие на заданные множество, мультимножество или последовательность и некоторое выражение над элементами соответствующей коллекции. Результатом является мультимножество для операций collect, определенных над множествами и мультимножествами, и последовательность для операции collect, определенной над последовательностью. При этом результирующая коллекция соответствующего типа (коллекция значений или объектов) состоит из результатов применения выражения к каждому элементу входной коллекции. Операция collect используется, главным образом, в тех случаях, когда от заданной коллекции объектов требуется перейти к некоторой другой коллекции объектов, которые ассоциированы с объектами исходной коллекции через некоторое соединение. В этом случае выражение над элементом исходной коллекции основывается на операции перехода по соединению.
Операции exists, forAll, size
В OCL определены три одноименных операции exist над множеством, мультимножеством и последовательностью, дополнительным параметром которых является логическое выражение. Результатом каждой операции является true, если и только если хотя бы для одного элемента входной коллекции значением логического выражения является true. Операции forAll отличается от операций exist тем, что результатом каждой из них является true, если и только если для всех элементов входной коллекции результатом вычисления логического выражения является true. Операция size применяется к коллекции и выдает число элементов, которые в ней содержатся.
Операции union, intersect, symmetricDifference
Параметрами двуместных операций union, intersect, symmetricDifference являются две коллекции, причем в OCL операции определены почти для всех возможных комбинаций типов коллекции. Не будем рассматривать все определения этих операций и кратко упомянем только две из них. Результатом операции union, определенной над множеством и мультимножеством, является мультимножество, то есть из результата объединения таких двух коллекций дубликаты не исключаются. Результатом же операции union, определенной над двумя множествами, является множество, т.е. в этом случае возможные дубликаты должны быть исключены.
В заключение обзора языка OCL приведем примеры четырех инвариантов, выраженных на этом языке. Будем основываться на диаграмме классов, показанной на рисунке:
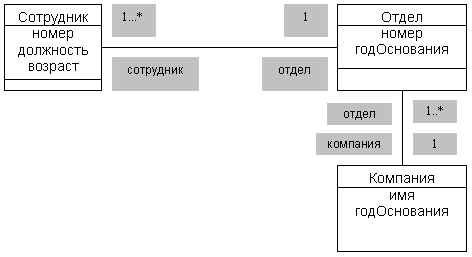
Диаграмма классов, используемая для примеров на языке OCL
Первый пример:
context Сотрудник inv: self.возраст >18 and self.возраст < 100
Этот инвариант указывает, что возраст сотрудников должен быть больше 18 и меньше 100, что выражается в виде ограничений на значения атрибута возраст, определенного в классе Сотрудник.
Второй пример:
Выразим на OCL то ограничение, что отделах с номерами больше 5 должны работать сотрудники старше 30 лет.
context Отдел inv: self.номер Ј 5 or self.сотрудник ® select (возраст Ј 30) ® size () = 0
Тот же инвариант можно сформулировать в контексте класса Сотрудник: context Сотрудник inv: self.возраст Ј 30 or self.отдел.номер > 5
Третий пример:
Третий инвариант определяет то ограничение, что у каждого отдела должен иметься менеджер ( между классами Сотрудник и Отдел имеется ассоциация, в которой роль конец класса Сотрудник имеет имя сотрудник), и что любой отдел должен быть основан не раньше основания соответствующей компании (между классами Отдел и Компания имеется ассоциация, в которой роль класса Компания имеет имя компания):
context Отдел inv: self.сотрудники ® exists (должность = “manager”) and self.компания.годОснования Ј self.годОснования
Здесь должность – атрибут класса Сотрудники, а атрибуты с именем годОснования имеются и у класса Отдел, и у класса Компания.
Обратите внимание на выражения self.отдел.номер во втором примере и self.компания.годОснования. Имя отдел является именем роли в ассоциации классов Сотрудник и Отдел, и компания – имя роли в ассоциации классов Отдел и Компания. Но в данном случае в OCL допускается точечная нотация, поскольку кратность обеих этих ролей равна единице (каждый сотрудник работает в одном и только одном отделе, и каждый отдел принадлежит одной и только одной компании), и результатом перехода по соединению в этом случае будет не коллекция, а в точности один объект.
Четвертый пример:
Четвертый инвариант ограничивает максимально возможное количество сотрудников компании числом 1000:
context Компания inv: self.отделы ® collect (сотрудники) ® size ( ) < 1000
Понятны плюсы и минусы использования языка OCL при проектировании реляционных БД. Язык позволяет формально и однозначно (без двусмысленностей, свойственных естественным языкам) определять ограничения целостности БД в терминах ее концептуальной схемы. Скорее всего, наличие проектной документации будет полезным для сопровождения БД даже если придется преобразовывать инварианты OCL в ограничения целостности SQL вручную.
К отрицательным сторонам использования OCL относится, прежде всего, сложность языка и неочевидность некоторых его конструкций. Кроме того, строгость синтаксиса и линейная форма языка в некотором роде противоречат наглядности и интуитивной ясности структурной части UML. Да, в инвариантах OCL используются те же понятия и имена, что и в соответствующей диаграмме классов, но используются совсем в другой манере. И последнее. Я не могу доказать или опровергнуть ни то, что на языке OCL можно выразить любое ограничение целостности, которое можно определить средствами SQL, ни то, что на языке OCL нельзя выразить такой инвариант, для которого окажется невозможным сформулировать эквивалентное ограничение целостности на языке SQL. Мне неизвестны работы, в которых бы сравнивалась выразительная мощность этих языков в связи с ограничениями целостности реляционных БД.
Получение схемы реляционной базы данных из диаграмм классов
Вообще говоря, переход от диаграммного представления концептуальной схемы базы данных к ее реляционной схеме не зависит от разновидности используемых диаграмм. В частности, методика, разработанная для классических диаграмм «Сущность-Связь» (Entity-Relationship), практически всегда пригодна для диаграмм классов UML. Эта методика широко известна (см., например, http://www.citforum.ru/cfin/prcorpsys/infsistpr_09.shtml), и мы не будем повторять ее в этой статье. Тем не менее, кажется целесообразным привести несколько рекомендаций, которые тесно связаны со спецификой диаграмм классов.
Рекомендация 1. Прежде, чем определять в классах операции, подумайте, что можно сделать с этими определениями в среде целевой РСУБД. Если в этой среде поддерживаются хранимые процедуры, то, возможно, некоторые операции могут быть реализованы именно с помощью такого механизма. Но если в среде РСУБД поддерживается механизм определяемых пользователями функций, он может оказаться более подходящим.
Рекомендация 2. Помните, что сравнительно эффективно в РСУБД реализуются только ассоциации видов “один-ко-многим” и “многие-ко-многим”. Если в созданной диаграмме классов имеются ассоциации “один-к-одному”, то следует задуматься о целесообразности такого проектного решения. Реализация в среде РСУБД ассоциаций с точно заданными кратностями ролей возможна, но требует определения дополнительных триггеров, выполнение которых понизит эффективность.
Рекомендация 3. Для технологии реляционных БД агрегатные и в особенности композитные ассоциации являются неестественными. Подумайте о том, что вы хотите получить в реляционной БД, объявив некоторую ассоциацию агрегатной. Скорее всего, ничего.
Рекомендация 4. В спецификации UML говорится, что, определяя однонаправленные связи, вы можете способствовать эффективности доступа к некоторым объектам. Для технологии реляционных баз данных поддержка такого объявления вызовет дополнительные накладные расходы и тем самым снизит эффективность.
Рекомендация 5. Не злоупотребляйте возможностями OCL.
Диаграммы классов UML – это хороший и мощный инструмент для создания концептуальных схем баз данных, но, как известно, все хорошо в меру.
6.4 Заключительные замечания
Нельзя сказать, что проектирование баз данных на основе семантических моделей в любом случае убыстряет и/или упрощает процесс проектирования. Все зависит от сложности предметной области, квалификации проектировщика и качества вспомогательных программных средств. Но в любом случае этап диаграммного моделирования обеспечивает следующие преимущества:
- на раннем этапе проектирования до привязки к конкретной РСУБД проектировщик может обнаружить и исправить логические огрехи проекта, руководствуясь наглядным графическим представлением концептуальной схемы;
- окончательный вид концептуальной схемы, полученной непосредственно перед переходом к формированию реляционной схемы, а может быть, и промежуточные версии концептуальной схемы должны стать часть документации целевой реляционной БД; наличие этой документации очень полезно для сопровождения и в особенности для изменения схемы БД в связи с изменившимися требованиями;
- при использовании CASE-средств концептуальное моделирование БД может стать частью всего процесса проектирования целевой информационной системы, что может способствовать правильной структуризации процесса, эффективности и повышению качества проекта в целом.
Хочу еще раз подчеркнуть, что в контексте проектирования реляционных БД структурные методы проектирования, основанные на использовании ER-диаграмм, и объектно-ориентированные методы, основанные на использовании языка UML, различаются, главным образом, лишь терминологией. ER-модель концептуально проще UML, в ней меньше понятий, терминов, вариантов использования. И это понятно, поскольку разные варианты ER-моделей разрабатывались именно для поддержки проектирования реляционных БД, и ER-модели почти не содержат возможностей, выходящих за пределы реальных потребностей проектировщика реляционной БД.
Язык UML принадлежит объектному миру. Этот мир гораздо сложнее реляционного мира. Поскольку UML может использоваться для унифицированного объектно-ориентированного моделирования всего, что угодно, в нем содержится масса различных понятий, терминов и вариантов использования, совершенно избыточных с точки зрения проектирования реляционных БД. Если вычленить из общего механизма диаграмм классов то, что действительно требуется для проектирования реляционных БД, то мы получим в точности ER-диаграммы с другой нотацией и терминологией.
Поэтому выбор конкретной концептуальной модели – это вопрос вкуса и сложившихся обстоятельств. Понятно, что если в организации уже имеется сложившаяся инфраструктура проектирования приложений, но разумно продолжать пользоваться именно ей до тех пор, пока это не станет тормозом. При построении же новой инфраструктуры больший вес имеют стратегические соображения высшего руководства компании, чем предпочтения технических специалистов, хотя эти предпочтения, с моей точки зрения, обязательно должны учитываться.
Рекомендуемая литература
- Чен П.П. Модель “сущность-связь” – шаг к единому представлению данных. СУБД, N3, 1995 г.
Я очень рекомендую прочитать эту классическую статью, изданную впервые в 1976 г. Мне кажется, что эта статья во многом проясняет процесс развития семантических диаграммных моделей. - Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем. М., Финансы и статистика, 1998.
- Вендров А.М. Проектирование программного обеспечения экономических информационных систем. М., Финансы и статистика, 2000.
В книгах А.М. Вендрова дается широкий обзор современных технологий проектирования информационных систем. Автор руководствуется собственным практическим опытом, и в его изложении сглаживаются терминологические и концессионные барьеры между разными подходами. Кроме того, эти книги изначально написаны на русском языке, а не переведены с английского, поэтому читаются без затруднений. - Фаулер М., Скотт К. UML в кратком изложении. Применение стандартного языка объектного моделирования. М., Мир, 1999.
Многие мои коллеги считают, что это лучшая книга про UML, переведенная на русский язык. Она написана четко, без повторов и философских отклонений от темы. Конечно, книга не может улучшить язык, но она помогает понять его в том виде, в каком он существует. Кстати, переводил книгу А.М. Вендров. - Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений на C++. 2-е изд. М., Издательство Бином, СПб., Невский диалект, 1999.
- Буч Г., Рамбо Д., Джекобсон А. Язык UML: руководство пользователя. М., ДМК, 2000.
Было бы просто неприлично не предложить в качестве дополнительной литературы про UML книги отцов-основателей этого языка. Хотя, честно говоря, я не в восторге от этих книг (как в русском переводе, так и на языке оригинала). Конечно, каждая книга полностью соответствует своему названию, но почему-то эти книги очень трудно и скучно читаются подряд, и в них очень трудно отыскать требуемую конкретную информацию. СУБД.