2009 г.
Тенденции развития универсальных коммерческих СУБД
Марк Ривкин
Назад Содержание Вперёд
III. Дюжина тенденций развития
Итак, мне кажется, что наиболее важными тенденциями развития современных универсальных коммерческих СУБД на ближайшее время будут следующие:
- Виртуализация ресурсов и GRID-технологии
- Встраивание Information Life Cycle Management (ILM) в СУБД
- Самоуправление, самодиагностика, самолечение
- Real Application Testing – механизмы промышленного тестирования версий и изменений
- Совершенствование архитектур максимальной доступности (разные режимы standby, Active standby, Snapshot standby, минимизация времени плановых простоев (модификация приложений и версий СУБД, online redefinition)
- Включение измерения времени в СУБД
- Поддержка новых типов данных (XML, RFID, Semantic Web, геном, медицина, быстрые LOB и т д)
- Умные механизмы сжатия и дедублирования
- Совершенствование методов защиты данных (DataVault, Audit Vault, A&I management
- In-memory СУБД реального времени как кэш для коммерческих СУБД
- Облачные вычисления (Cloud computing)
- Машины баз данных
Рассмотрим эти тенденции подробнее.
1. Виртуализация ресурсов и GRID-технологии
В настоящее время в большинстве организаций для каждого приложения выделяется свой компьютер (группа компьютеров) и свой набор дисков для хранения БД. Как правило, эти компьютеры и диски различными приложениями совместно не используются. Поскольку в реальной жизни нагрузка на приложения постоянно изменяется, мы часто имеем ситуацию, когда одни компьютеры сильно перегружены, в то время как другие недогружены или простаивают. В одних системах есть запас дисков, а в других дискового пространства катастрофически не хватает. Однако, к сожалению, мы не можем оперативно перебрасывать дисковые и процессорные ресурсы туда, куда надо. Например, если в течение квартала идет большой поток транзакций, а в конце квартала он спадает, но начинает возрастать нагрузка на систему создания корпоративной отчетности, то мы вынуждены на обе системы держать максимальные вычислительные мощности. Система получается дорогой, избыточной, негибкой.
Выходом является виртуализация ресурсов. При этом все диски центра обработки данных (ЦОД) объединяются в один большой виртуальный диск, на котором располагаются все данные всех приложений, и мы можем гибко на ходу увеличивать этот виртуальный диск, добавляя к нему новые физические диски, или легко отдавать место для хранения тем приложениям, которым оно сейчас необходимо. Та же картина и с процессорным ресурсом. Объединение множества компьютеров в один виртуальный компьютер, на котором одновременно работает множество приложений, мощность которого можно легко увеличивать, на лету добавляя новые компьютеры, и возможность перераспределения вычислительных ресурсов этого суперкомпьютера между приложениями по мере необходимости позволяют резко повысить гибкость вычислительной системы, снизить ее стоимость и увеличить эффективность использования оборудования. Примером такой виртуализации является Oracle GRID [10], где диски объединены в Storage Grid, а компьютеры в Database Grid – виртуальный сервер БД и Application Grid – виртуальный сервер приложений. Для управления таким множеством элементов используется ПО Grid Control, которое позволяет работать с множеством объектов как с единым целым (рис. 1).
Если в качестве элементов GRID используются дешевые элементы (дешевые диски, обычные Intel компьютеры), то стоимость такой вычислительной среды намного меньше, чем при использовании традиционных архитектур. Поскольку элементы виртуального диска или виртуального компьютера взаимозаменяемы, то система также обладает повышенной надежностью и живучестью, т.к. выход из строя одного или нескольких элементов не приводит к остановке работы. Система просто сама автоматически переконфигурируется и продолжает работу.
Такой подход очень привлекателен для организаций, он позволяет создавать вычислительный ресурс неограниченной мощности и не заботиться о том, на каких компьютерах реально работает ваше приложение. Главное – запросить и получить тот вычислительный ресурс, который вам сейчас нужен. Система сама выполнит балансировку нагрузки для вашего приложения, создаст, если надо, БД с учетом обеспечения зеркалирования данных и снижения нагрузки по вводу/выводу, задействует столько элементов GRID, сколько необходимо для обеспечения требуемой вам надежности и производительности. И, по мере изменения внешних условий и ваших требований, она будет подстраиваться под эти требования.
Сегодня уже реализованы такие Еntеrprise GRID первого поколения на Oracle (Amazon, e-Bay Латинской Америки, EDS ABNAMRO и т.д.), компания IBM активно проводит исследования в области GRID-технологий для научных вычислений, существует специальный инструментарий Globus Toolkit для использования Grid-технологий при разработке приложений. Однако подход Oracle, который не требует использования специальных инструментов и подходов для разработки корпоративных приложений, которые будут работать в среде GRID, кажется более перспективным.
Основой Database GRID у Oracle является архитектура Real Application Clusters, реализующая подход shared disk (все узлы кластера одновременно работают с единой БД). Еще одним подтверждением перспективности подхода послужила информация о разработке компанией Sybase продукта Sybase ASE Cluster Edition, который очень похож на Oracle RAC, похожую архитектуру реализует и IBM DB2 для Mainframe.
У Enterprise Grid первого поколения был ряд ограничений. Так, выделялось два виртуальных компьютера – Database Grid и Application Grid (вместо одного единого большого виртуального компьютера для СУБД, серверов приложений, Веб-серверов, HTTP-серверов и т.д.), ресурсы не перераспределялись автоматически в соответствии с заранее заданной политикой, система не адаптировалась автоматически к постоянно изменяющейся нагрузке, приложения не могли без остановки работы переезжать с более слабых узлов GRID на более мощные и т.д. Большинство из этих ограничений будет снято в архитектуре Enterprise GRID 2, примером которой будет Oracle 11.2.
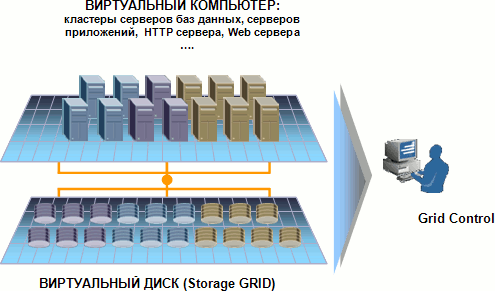
Рис 1. Oracle GRID 2
2. Встраивание Information Life Cycle Management (ILM) в СУБД
Как известно, данные и информация имеют свой цикл жизни (рис. 2). Вначале они поступают в систему (в БД) и являются активными, т.е. используются очень часто. Нужно обеспечить быстрый доступ к информации и хранить ее на быстрых дорогих дисках. Затем информация начинает устаревать, переходит в разряд менее активной. Она все еще должна быть под рукой, но ее уже можно переместить на более дешевые и медленные диски.
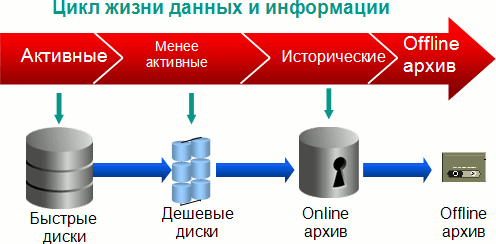
Рис. 2. Цикл жизни данных и информации
Затем информация переходит в разряд исторической. По закону мы должны хранить ее определенное количество лет (или вечно). После истечения срока хранения информацию надо удалять, чтоб освободить место в БД. Надо иметь возможность легко воссоздавать старые отчеты на базе этой информации. Кроме того, данные исторической информации нельзя менять (кто же хочет иметь непредсказуемую историю?), и надо гарантировать их неизменность. Надо также гарантировать их неудаляемость в течение заданного срока. Не всем пользователям и приложениям разрешается работать с исторической информацией, нужен контроль за тем, кто и как ее использует и т.д. и т.п. Поскольку запросы к историческим данным выполняются редко, а их объем достаточно велик, часто прибегают к сжатию исторических данных. Ну, и в конце своей жизни данные часто переносятся в оффлайновые архивы на лентах.
Поддержание жизненного цикла информации и данных разного типа, как правило, сегодня реализуется на уровне логики приложений. Это сложно, негибко, усложняет приложения и снижает качество управления информацией. В результате важные данные могут быть утеряны (пример - компания Энрон) или занимать большой объем на дорогих дисках.
Часто управление жизненным циклом данных реализуют производители систем хранения. Но, поскольку они работают именно с данными (а не с информацией) и не знают бизнес-логики и бизнес-характеристик информации, то реализуют поддержку именно жизненного цикла данных (DLM), а не информации (ILM)
Поэтому сегодня наметилась тенденция реализации механизма ILM на уровне самой СУБД. Администраторы или разработчики описывают различные области хранения данных с разными характеристиками (быстрые диски, медленные диски, ленты, флеш-память, CD и т.д.) и правила разделения данных одного типа на группы (например, по мере устаревания, по частоте использования и т.д.). Группы привязываются к областям хранения, и при изменении характеристик данных они автоматически перемещаются в другую группу, а следовательно, и в другую область хранения. При этом меняются характеристики этих данных, данные могут сжиматься, переводиться в режим “только для чтения” и т.д. Система будет следить, чтобы данные группы хранились требуемое время и затем уничтожались.
Разделение данных на группы должно учитывать бизнес-смысл данных (работаем с информацией) и должно быть независимым от оборудования, на котором данные хранятся и обрабатываются; оно должно быть прозрачным для приложений (приложения не знают о том, что эти данные разделены на группы и работают как обычно). Очень удобным средством такого логического разделения данных на группы является механизм секционирования (partitioning). Например, можно группировать данные по диапазону значений, по времени, по частоте использования, по географии размещения, по значению одного или нескольких полей записи. Возможно и смешанное секционирование (по нескольким измерениям). Графический инструментарий позволяет не только описать эти группы, области хранения, политики хранения/уничтожения и т.д. и отслеживать состояние данных. Он также подскажет, сколько денег и места на дисках вы сможете сэкономить, используя тот или иной вид сжатия данных, тот или иной тип устройств хранения. С помощью механизма ILM вы сможете переложить всю ответственность за поддержку жизненного цикла информации на СУБД.
3. Самоуправление, самодиагностика, самолечение
СУБД становятся все сложнее и сложнее, и для их быстрой и надежной работы требуется все более опытные администраторы. Но даже они не могут оперативно реагировать на постоянно меняющуюся нагрузку СУБД, изменение режима работы приложений и т.д. Кроме того, растет число СУБД в организации, которые надо администрировать.
Единственный выход решить эти проблемы – сделать СУБД самоуправляемыми, самодиагностирующимися, самолечащимися. Большинство производителей СУБД уже идут по этому пути, но возможностей развития остается еще много. Основная идея здесь проста. Во время работы СУБД постоянно собирает информацию о своей работе, анализирует ее (оперативно и в фоновом режиме), принимает решения, и либо автоматически их реализует (например, меняет размеры областей в памяти, выполняет процедуры, запрашивает у ОС дополнительные ресурсы, меняет планы выполнения запросов), либо информирует администратора о проблеме, рекомендует ему последовательность действий для решения проблемы и после одобрения выполняет эти действия. При анализе работы применяются лучшие практики и знания, накопленные лучшими администраторами этой СУБД. Их список постоянно совершенствуется. Системы учатся реагировать проактивно (т.е. заранее, до возникновения проблем), выявляют причины, а не следствия возникновения проблем, учитывают множество факторов, которые администратору в условиях стресса учесть трудно.
Системы контроля и самонастройки могут настраивать размеры областей памяти, ввод/вывод, давать рекомендации по оптимизации запросов, выявлять проблемы безопасности (например, незакрытые порты, неизмененные пароли и т.д.) и производительности, нехватки места и ресурсов, отклонения от заданных или типичных стандартов поведения и т.д.
В фоновом режиме СУБД постоянно проверяет свое состояние, целостность данных, ищет и исправляет сбойные блоки и файлы, сверяет контрольные суммы и т.д. Ведется работа по встраиванию алгоритмов data mining для выявления и контроля зависимостей между данными. Многие СУБД научились сегодня автоматически (без участия DBA) выполнять Backup и восстановление, собирать информацию о сбоях и отправлять ее в службу технической поддержки, отслеживать появление новых важных патчей. Продолжается совершенствование оптимизаторов SQL-запросов, они учитывают все больше важных факторов (например, взаимовлияние кардинальности столбцов, параметры оборудования и среды эксплуатации и т.д.). Детальная оптимизация, которая требует много вычислительных ресурсов, проводится в фоновом режиме, выявляя и тестируя новые, более перспективные планы выполнения запросов, автоматически выявляя и настраивая наиболее ресурсоемкие SQL.
Еще одной важной тенденцией является уменьшение количества “ручек”, которые может подкрутить не очень опытный администратор БД, и переход к заданию бизнес-критериев работы, таких как допустимое время простоя системы при сбоях, максимально допустимое время отклика, минимальная пропускная способность системы и т.д. На основе этих критериев СУБД сама регулирует свои параметры, чтобы обеспечить требуемый результат. Благодаря всему этому время обучения администратора мощных коммерческих СУБД снизилось до нескольких дней. Однако у опытного DBA все еще остается возможность детально контролировать и настраивать работу СУБД, поскольку ни один оптимизатор пока не может сравниться с гуру – администратором.
4. Real Application Testing – механизмы промышленного тестирования версий и изменений
Жизнь не стоит на месте, и вокруг нас все постоянно меняется. Чтобы не отстать от конкурентов, мы вынуждены менять компьютеры в ЦОД, добавлять процессоры и память, патчировать ОС и менять ее версию, патчировать СУБД и переходить к новым более мощным и современным версиям СУБД. В процессе работы приходится постоянно менять параметры работы СУБД и структуры данных, создавать новые объекты в БД (индексы, материализованные представления и т.д.), менять архитектуру вычислительной системы (например, переходить от одного компьютера к кластеру или GRID), выполнять рекомендации службы технической поддержки, опытных коллег, руководства и т.д.
К сожалению, любые из этих необходимых действий могут привести не к улучшению работы системы, а к ухудшению или остановке работы. Автор знает примеры совершенно безобидных изменений, которые резко ухудшали скорость работы системы. А уж апгрейд на новую версию СУБД – это хуже пожара. Зная все это, администраторы БД оттягивают внесение изменений до последнего момента, не желая рисковать. Единственная возможность решить эту проблему – позволить заранее протестировать любые из перечисленных изменений (ОС, оборудования, структур данных, архитектуры) на тестовой системе (до их выполнения на промышленной системе) и оценить последствия. Для этого используется тестовая копия БД; у некоторых производителей в качестве тестовой можно временно использовать резервную БД (Oracle Snapshot Standby).
Существует много пакетов, позволяющих имитировать нагрузку на тестовой системе для выполнения функционального и нагрузочного тестирования. Однако все эти пакеты создают не реальную, а синтетическую нагрузку, дороги, требуют длительного времени для анализа работы системы и создания тестовых скриптов. И в результате многие проблемы так и остаются не выявленными.
Появившийся у Oracle продукт RAT (Real Application Testing), очевидно, вскоре будет реализован в большинстве СУБД, т.к. он позволяет на реально работающей под нагрузкой производственной системе захватить (с минимальными накладными расходами) реальную нагрузку (с учетом времени выполнения, одновременности, зависимости операций) и воспроизвести эту нагрузку на тестовой БД, не устанавливая там приложение. Захват и проигрывание нагрузки легко выполнить, и они позволяют выявить появившиеся/ пропавшие/изменившиеся после выполнения изменений ошибки, изменения в планах и результатах выполнения реальных SQL, проблемы снижения производительности как всей системы, так и отдельных запросов. После анализа результатов система дает рекомендации по улучшению работы SQL, позволяет попробовать различные варианты оптимизации работы. Откатывая тестовую БД назад, можно тестировать различные изменения и их совокупность. И только после того, как все проблемы выявлены и решены, изменения можно произвести в производственной среде.
Поскольку захват, проигрывание, анализ, оптимизация проводятся в автоматическом или автоматизированном режиме, они не требуют много времени от администратора БД. Впервые появилась возможность значительно снизить риски перехода от старой версии СУБД к новой, более совершенной. Регулярный апгрейд СУБД становится обычным рутинным делом (рис 3).
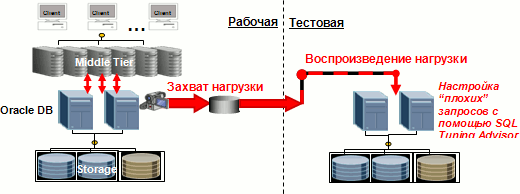
Рис. 3. Oracle Real Application Testing
5. Совершенствование архитектур максимальной доступности
Требования к непрерывности работы СУБД при любых видах сбоев и регламентных работ постоянно повышаются. Существует целый набор решений, которые все вместе реализуют архитектуру максимальной доступности. Это и кластеры, и возможность автоматического перезапуска СУБД на другом сервере, и создание резервных вычислительных центров (Standby). Все эти решения будут развиваться и совершенствоваться, обеспечивая и быструю синхронизацию узлов, и минимальное время переключения, и возможность синхронной/асинхронной синхронизации узлов, и возможность установки времени задержки синхронизации (чтобы успеть перехватить ошибки), и возможность отката баз, транзакций, операций DDL для борьбы с человеческими ошибками.
Особо хочется отметить тенденцию к более полному использованию возможностей резервной БД. Сегодня у большинства производителей она постоянно догоняет основную БД и используется только тогда, когда основная БД выйдет из строя. Это замораживает инвестиции в оборудование и не дает гарантии того, что, когда сбой наконец произойдет, переключение будет успешным. Поэтому производители начинают реализовывать механизм быстрого переключения основная–резервная и резервная–основная БД, чтобы этот механизм можно было легко и часто использовать при выполнении регламентных работ и для поэтапного апгрейда СУБД без остановки ее работы. Кроме того, появляются механизмы открытия резервной БД на чтение в то время, как она догоняет основную. Это позволяет разгрузить производственную системы, вынеся на резервную БД операции построения отчетности, анализа, backup. Также резервную БД можно переводить в режим тестирования и использовать для тестирования изменений. После окончания тестирования она возвращается в режим резервной БД и продолжает догонять основную БД. Это тем более удобно, что можно одновременно иметь несколько standby баз, иногда даже в разных городах.
Сегодня большинство сложных, ресурсоемких операций по изменению структуры БД или параметров работы СУБД может производиться online, в фоновом режиме. Т.е. изменение структуры таблиц и индексов, перемещение объектов не приводит к замедлению работы с этими объектами. Online патчи позволят модифицировать ПО без остановки работы системы.
В ближайшее время будет реализован и механизм версионности приложений БД, когда в БД существует несколько различных версий одной и той же процедуры, функции, таблицы, пакета, view и т.д. Это позволит на какое-то время обеспечить одновременную работу с базой двух разных версий приложения с плавным переключением со старой версии на новую. Таким образом, апгрейд приложений БД и версий БД станет еще более быстрым и безболезненным.
6. Включение измерения времени в СУБД
Для борьбы с человеческими ошибками, аудита, а также для восстановления старых версий данных и отчетов (что диктуется нормативными требованиями), надо иметь в СУБД штатную возможность откатываться в прошлое по оси времени, т.е. заказывать отчеты или запросы на текущем состоянии БД такими, какими они были на момент времени в прошлом. Часто требуется быстро и просто откатить всю базу, отдельные транзакции в прошлое или восстановить удаленные объекты БД и ошибочно измененные пользователем данные. Иногда надо посмотреть, как изменялись данные в течение некоторого интервала времени.
Для выполнения этих операций в СУБД встраиваются измерение времени и механизм для быстрого воссоздания старого состояния базы, объекта или запроса. В частности у Oracle это реализуется с помощью команды Flashback (Database, Table, Transaction, Query, Version Query). Развитием механизма Flashback стал механизм Flashback Data Archive, который позволяет компактно хранить след изменения данных и легко восстанавливать старое состояние данных таблиц. При этом можно откатиться на любой отрезок времени в прошлое, вплоть до момента создания этой таблицы, и восстановить старое состояние ее данных, даже если за это время изменилась структура таблицы
7. Поддержка новых типов данных (XML, RFID, Semantic Web, геном, медицина, быстрые LOB и т.д.)
По мере развития информационных технологий появляются приложения, работающие с новыми типами данных. Сегодня большинство СУБД умеет работать не только с алфавитно-цифровой информацией, но и с текстами, аудио, видео, геоинформацией, XML. Под словом “работать” мы подразумеваем не только быструю загрузку, эффективное хранение и быстрое извлечение этих данных, но и преобразование данных в разные форматы, специальные способы индексации и оптимизации, набор типичных для данного типа данных функций и т.д.
За последнее время началась реализация поддержки в универсальных СУБД таких специфических типов данных, как RFID, данные семантических сетей (Semantic Web), данные генома, специальные типы данных и алгоритмов для медицины, биологии, иммунологии, генетики. Практически все универсальные СУБД сегодня совершенствуют работу с XML. В ближайшее время, когда мы, наконец, перейдем к более умным веб-страницам, описывающим не только представление данных, но и их семантику, резко возрастет спрос на работу с семантическими сетями, поддержку стандартов OWL и RDF в СУБД, т.к. объем данных этих сетей будет огромен, и скорость извлечения и обработки таких данных будет очень важна.
Также наметилась тенденция к перемещению неструктурированных данных, ранее хранимых рядом с СУБД (в файловой системе), внутрь СУБД. Польза от использования единого механизма доступа, безопасности, надежности и т.д. для структурированных и неструктурированных данных была очевидна давно. Однако СУБД работали с неструктурированными данными медленнее, чем файловая система. Сегодня новые механизмы СУБД (такие как SecureFiles Oracle) позволят работать с такими неструктурированными данными не медленнее, а иногда и быстрее (за счет сжатия, дедублирования, работы по частям и т.д.), чем при их хранении в файловой системе. Хранение документов, изображений, видео, аудио и т.д. в БД позволит упростить разработку приложений и повысить их качество.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС