"Объектны" ли объектные расширения языка SQL?
Сергей Кузнецов
Институт системного программирования РАН
1. "Сближение" SQL и ODMG
Появление в стандарте SQL:1999 [1] новых возможностей – определяемых пользователями типов данных (User Defined Type, UDT) и типизированных таблиц, которые получили название объектных расширений языка SQL, многими было воспринято как сближение "реляционной"1 и объектной2 моделей данных. Этому способствуют особенности терминологии стандартов SQL:1999 и SQL:2003 [3], в которых значения UDT временами называют "экземплярами" (instance), различают "инстанциируемые" и "неинстанциируемые" UDT, а строки типизированных таблиц и вовсе иногда называют "объектами".
На "сближение" моделей SQL и ODMG, казалось бы, указывает и возрастающая синтаксическая близость языков запросов SQL и OQL [4]. Пусть, например, имеется простая концептуальная схема базы данных, представленная в виде диаграммы классов UML (рис. 1).
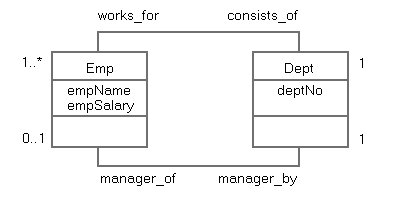
Рис. 1. Диаграмма классов "отделы-служащие"
На этой диаграмме классы Emp ("служащие") и Dept ("отделы") связаны двумя ассоциациями, одна из которых (верхняя) устанавливает двунаправленное соответствие "n-к-одному" между служащими и отделами, в которых они работают, а вторая – взаимнооднозначное соответствие между отделами и их руководителями, которые должны являться служащими.
Понятно, что в соответствии с диаграммой с рис. 1 можно определить как схему объектной базы данных в модели ODMG, так и схему "объектно-реляционной" базы данных в модели SQL. В первом случае могут быть определены атомарные объектные типы Emp и Dept с одноименными экстентами; во втором – структурные UDT Emp_T и Dept_T, а также типизированные таблицы Emp и Dept. Предположим, что требуется найти имена всех руководителей отделов, в которых работает хотя бы один служащий, получающий заработную плату свыше 20000 руб. Тогда мы могли бы получить следующие формулировки запроса на языках OQL и SQL соответственно:
OQL: SELECT DISTINCT Emp.works_for.managed_by.empName
FROM Emp
WHERE Emp.empSalary > 20000.00
SQL: SELECT DISTINCT Emp→works_for→managed_by→empName
FROM Emp
WHERE Emp.empSalary > 20000.00
В обоих случаях результатом запроса будет множество символьных строк, представляющих имена руководителей отделов. "Точечная" нотация в OQL-запросе и "стрелочная" нотация в SQL-запросе изображают переходы по ассоциациями исходной диаграммы классов. Условие в OQL-запросе ограничивает множество объектов-служащих в экстенте Emp. Условие в SQL-запросе ограничивает множество3 строк-служащих в типизированной таблице Emp.
Как кажется, этот пример заставляет придти к выводу, что строка типизированной таблицы SQL является прямым аналогом объекта ODMG, а типизированная таблица SQL – это прямой аналог экстента ODMG. Цель данной статьи состоит в том, чтобы показать, что это сходство является только внешним, чисто синтаксическим. На самом деле, между моделями ODMG и SQL имеются фундаментальные различия, которые невозможно преодолеть путем синтаксических расширений языка.
В основе обеих моделей лежит соответствующая система типов данных. Для обоснования основного утверждения данной статьи необходимо произвести краткий экскурс в системы типов ODMG и SQL.
2. Объектная модель ODMG 3.0
Консорциум ODMG (www.odmg.org) был образован в 1991 г. (тогда эта аббревиатура раскрывалась как Object Database Management Group, но впоследствии приобрела более широкую трактовку – Object Data Management Group). Консорциум ODMG был тесно связан с гораздо более многочисленным консорциумом OMG (Object Management Group, www.omg.org), который был образован двумя годами раньше. Основной исходной целью ODMG была выработка промышленного стандарта объектно-ориентированных баз данных (общей модели). За основу была принята базовая объектная модель OMG COM (Core Object Model). В течение десятилетнего существования4 ODMG опубликовала три базовых версии стандарта, последняя из которых называется ODMG 3.0 [4].5
Модель ODMG является объектной моделью данных, включающей возможность описания как объектов, так и литеральных значений. На разработку модели повлиял тот факт, что она предназначена для поддержки работы с базами данных, так что особо важной является эффективность доступа к данным. Модель ODMG подстраивается под специфику систем баз данных следующим образом:
- для баз данных, схем и подсхем обеспечивается набор встроенных объектных типов;
- модель включает ряд встроенных структурных типов, позволяющих применять традиционные методы моделирования баз данных;
- модель одновременно включает понятия объектов и литералов6; в модели связи между объектами отличаются от атрибутов объектов.
2.1 Объекты и литералы
Одним из важнейших отличий объектов от значений является наличие у объекта уникального идентификатора (объекты обладают свойством индивидуальности, или идентифицируемости – identity). Накладные расходы, требуемые для обращения к объекту по его идентификатору с целью получения доступа к базовым значениям данных, могут весьма сильно замедлить работу приложений. Поэтому в модели ODMG допускается описание всех данных в терминах объектов и использование традиционного вида значений, которые в модели называются литеральными значениями. Таким образом, возраст человека может задаваться целочисленным литералом, а не объектом, имеющим свойство7 возраст. В этом случае значение возраста будет сохраняться как часть структуры данных объекта человек, а не в отдельном объекте. Это, в частности, означает, что объект может входить в состав нескольких других объектов, а литерал – нет. Схема базы данных в модели ODMG главным образом состоит из набора объектных типов, но компонентами этих типов могут быть типы литеральных значений.
Другими словами, объект идентифицируется своим объектным идентификатором (OID – Object Identifier), который полностью отделен от значений компонентов объекта, а литерал полностью идентифицируется значениями своих компонентов.
2.2 Связи
В большинстве объектных систем связи неявно моделируются как свойства, значениями которых являются объекты. Например, если служащий работает в некотором отделе, то у каждого объекта-служащего должно иметься свойство, которое можно назвать worksFor, значением которого является соответствующий объект-отдел.8 Возникает проблема, если у объекта-отдела имеется свойство, которое затрагивает множество служащих этого отдела (например, consists_of – множество, включающее все объекты служащих данного отдела). Эти два свойства являются несвязными, и поддержка их согласованности может вызывать значительную программистскую проблему.
В модели ODMG, подобно диаграммам классов UML, различаются два вида свойств – атрибуты и связи. Атрибутами называются свойства объекта, значение которых можно получить по OID объекта, но не наоборот. Значениями атрибутов могут быть и литералы, и объекты, но только тогда, когда не требуется обратная ссылка. Связи – это инверсные свойства. В этом случае значением свойства может быть только объект, поскольку литеральные значения не обладают свойствами. Поэтому возраст служащего обычно моделируется как атрибут, а компания, в которой работает служащий, – как связь.
При определении связи должна быть определена ее инверсия. В приведенном выше примере, если worksFor определяется как связь, должно быть явно указано, что инверсией является свойство consists_of объекта-отдела, а при определении consists_of должна быть указана инверсия worksFor. После этого система баз данных должна поддерживать согласованность связанных данных, что позволяет сократить объем работы программистов приложений и повысить надежность их программ.9 Если в объекте-отделе свойство consists_of не требуется, то свойство объекта-служащего works_for может быть атрибутом.10
2.3 Литеральные типы
Литеральные типы данных в модели ODMG соответствуют традиционному пониманию типа данных как множества значений, над которыми определен набор операций и механизм внешнего представления (литералов в традиционном смысле этого термина). В модели поддерживается ряд литеральных типов – базовые скалярные числовые типы, символьные и булевские типы (атомарные литералы), конструируемые типы литеральных записей (структур) и коллекций. Конструируемые литеральные типы могут основываться на любом литеральном или объектном типе11, но считаются неизменными. Даты и время строятся как литеральные структуры.
Можно определить четыре разновидности литеральных типов коллекций. Типы категории set – это обычные типы множеств. Типы категории bag – эти типы мультимножеств (в значениях которых допускается наличие элементов-дубликатов). Значениями типов категории list являются упорядоченные списки значений (среди них допускаются дубликаты). Наконец, значениями типа dictionary являются множества пар <ключ, значение>, причем все ключи в этих парах должны быть различными. Все определения конструируемых литеральных типов имеют рекурсивную природу. Например, можно определить тип множества структур, элементами которых будут являться списки мультимножеств и т.д.12
Заметим, что конструкторы литеральных типов позволяют определять типы с произвольно сложной внутренней структурой. Но очень важно то, что в модели ODMG отсутствует возможность определения пользовательских структурных литеральных типов с собственным набором операций. По непонятным причинам авторы модели ODMG допустили эту возможность только для объектных типов.
2.4 Объектные типы
Объектный тип в модели ODMG похож, скорее, на класс в языках объектно-ориентированного программирования. В отличие от литерального типа с предопределенным множеством значений, объекты объектного типа создаются динамически при явном обращении к соответствующей операции типа. По сути дела, объект является контейнером, который может содержать литеральные значения (или ссылки на объекты) в соответствии со структурой данных, специфицированной при определении объектного типа. У каждого объекта имеется уникальный OID, который обеспечивает доступ к свойствам объекта через операции13, определенные для соответствующего объектного типа.
Точно так же, как имеются атомарные и конструируемые литеральные типы, существуют атомарные и конструируемые объектные типы. В стандарте ODMG 3.0 говорится, что атомарными объектными типами являются только типы, определяемые пользователями (UDT). Конструируемые объектные типы включают структурные типы (в действительности, только типы даты-времени, которые в этой статье не представляют интереса) и набор типов коллекций.
Наряду с набором конструкторов литеральных типов коллекций set
В модели ODMG UDT можно определить с помощью двух разных синтаксических конструкций языка ODL – interface и class. В обоих случаях в интерфейсной части определения UDT14 присутствуют следующие компоненты (некоторые из них не являются обязательными):
- имя;
- набор супертипов;
- набор атрибутов, каждый из которых может быть объектом или литеральным значением;
- набор связей, каждая из которых указывает на некоторый другой объект (или коллекцию объектов);
- набор сигнатур операций.
Определение класса отличается от определения интерфейса наличием двух необязательных разделов: extends и списка дополнительных свойств. В действительности, наиболее важным отличием класса от интерфейса является возможность наличия второго из этих разделов. В списке свойств могут присутствовать элементы extent и key. В спецификации модели данных ODMG 3.0 говорится, что для каждого класса может быть определен только один экстент, являющийся объектом-множеством всех объектов этого класса, которые после создания должны сохраняться в базе данных.
Другими словами, включение в определение UDT элемента extent приводит (а) к неявному определению объектного типа множества, элементами которого являются объекты (на самом деле, OID объектов) определяемого UDT; (б) к неявному созданию объекта этого типа множества, причем к этому объекту возможен доступ по имени UDT; (в) автоматическому обновлению состояния экстента при каждом создании/уничтожении объекта UDT. Заметим, что, во-первых, у UDT может отсутствовать экстент, и, во-вторых, объект (его OID) может входить в несколько объектных коллекций, любую из которых, наряду с экстентом UDT, можно использовать в OQL-запросах. Если объект можно трактовать как аналог стабильно хранимой переменной, а OID – как указатель на эту переменную, то объект-коллекцию можно воспринимать как контейнер коллекций OID объектов одного UDT, т.е. как контейнер коллекций указателей на переменные.
Ключ – это набор свойств объектного класса, однозначно идентифицирующий состояние каждого объекта, который входит в экстент класса (это аналог возможного ключа реляционной модели данных). Для класса может быть объявлено несколько ключей, а может не быть объявлено ни одного ключа даже при наличии определения экстента. В последнем случае в экстенте класса могут существовать разные объекты с одним и тем же состоянием.15
Далее, хотя и интерфейсы, и классы являются средствами определения объектных типов, между ними проводится жесткое различие. Допускается создание объектов только тех объектных типов, которые определены как классы. Объектные типы, определенные как интерфейсы, могут использоваться только для порождения новых объектных типов (интерфейсов и классов) на основании множественного наследования. Классы могут определяться на основе множественного наследования интерфейсов и одиночного наследования классов.
Механизм наследования от интерфейсов называется в ODMG наследованием IS-A, а механизм наследования от классов – extends. Прежде чем попытаться пояснить этот подход, приведем пример графа наследования интерфейсов и классов, в котором также показывается место существующих экстентов и объектов (рис. 2).
На рис. 2 "жирными" стрелками показаны связи объектных типов по наследованию IS-A. Обычные стрелки показывают связи по наследованию extends. Пунктирные стрелки соответствуют связям экстентов и соответствующих классов. Обратите внимание, что на этом рисунке у каждого из классов, входящих в иерархию, определен свой собственный экстент. Как демонстрирует рисунок, в модели ODMG поддерживается семантика включения, означающая, что экстент любого подкласса является подмножеством экстента любого своего суперкласса (прямого или косвенного). Кроме того, независимо от наличия или отсутствия поддержки экстентов, работает полиморфизм по включению: любой объект любого подтипа является объектом любого его супертипа.
Если у некоторого подкласса свой собственный экстент не определен, то с объектами этого подкласса можно работать только через экстент какого-либо суперкласса. Стандарт не требует обязательного определения экстента. В этом случае ответственность за поддержку работы с множествами объектов ложится на прикладного программиста (для этого можно использовать типы коллекций).
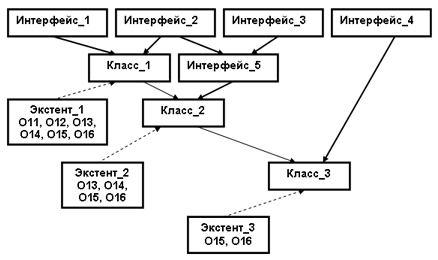
Рис. 2. Пример иерархии объектных типов и их экстентов
Итак, при порождении подкласса путем наследования extends от некоторого суперкласса подкласс наследует экстент и набор ключей суперкласса. Как уже отмечалось, для подкласса можно определить свой собственный экстент. Что же касается переопределения ключей, то в стандарте отсутствуют явные указания о возможности или невозможности этого действия. Однако очевидно, что если бы было разрешено полное переопределение набора ключей для экстента подкласса, то это противоречило бы семантике включения. По нашему мнению, по этому поводу можно трактовать ODL одним из двух способов.
- Если в некотором подклассе определен набор ключей, то в любом его подклассе определение ключей запрещается.
- Если в некотором подклассе определен набор ключей, то определение ключей в любом его подклассе приводит к расширению для этого подкласса набора ключей суперкласса.
3. "Объектная" модель SQL
Как и в предыдущем разделе, начнем с общего обзора системы типов данных языка SQL, а потом сосредоточимся на средствах, которые в [1] расцениваются как "объектные расширения". В основном будем основываться на стандарте SQL:1999, отмечая некоторые важные дополнения, появившиеся в стандарте SQL:2003 [3].
3.1 Система типов SQL
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов (а также переменных языка SQL/PSM16 и параметров процедур, функций и методов) разбиваются на следующие категории:
- точные числовые типы (exact numerics);
- приближенные числовые типы (approximate numerics);
- типы символьных строк (character strings);
- типы битовых строк (bit strings)17;
- типы даты и времени (datetimes);
- типы временных интервалов (intervals);
- булевский тип (Booleans);
- типы коллекций (collection types);
- анонимные строчные типы (anonymous row types);
- типы, определяемые пользователем (user-defined types);
- ссылочные типы (reference types).
К теме данной статьи не относятся особенности "встроенных" типов категорий (1)-(7). Обсудим четыре последние категории. Начиная с SQL:1999, в языке поддерживается возможность использования типов данных, значения которых являются коллекциями значений некоторых других типов. В SQL:1999 были специфицированы только типы массивов. В новом стандарте SQL:2003 появилась спецификация типа мультимножества.
Типы массивов
Любой возможный тип массива получается путем применения конструктора типов ARRAY. При определении столбца, значения которого должны принадлежать некоторому типу массива, используется конструкция dt ARRAY [mc], где dt специфицирует некоторый допустимый в SQL тип данных, а mc является литералом некоторого точного числового типа с нулевой длиной шкалы и определяет максимальное число элементов в значении типа массива (в терминологии SQL:1999 это значение называется максимальной кардинальностью массива). В стандарте SQL:1999 не поддерживались многомерные массивы и массивы массивов. Однако в стандарте SQL:2003 это ограничение было снято, и теперь типом элементов любого типа коллекций может быть любой допустимый в SQL тип данных, кроме самого конструируемого типа коллекции.
Элементам каждого значения типа массива соответствуют их порядковые номера, называемые индексами. Значение индекса всегда должно принадлежать отрезку [1, mc]. Значениями типа массива dt ARRAY [mc] являются все те массивы, состоящие из элементов типа dt, максимальное значение индекса которых cs не превосходит значения mc. При сохранении в базе данных значение типа массива занимает столько памяти, сколько требуется для сохранения cs элементов. Обеспечивается доступ к элементам массива по их индексам. В частности, можно объявить столбец типа INTEGER ARRAY [10] и при вставке строки в соответствующую таблицу задать значение только пятого элемента массива. Тогда в строку будет занесен массив из пяти элементов, причем первые четыре элемента будут содержать неопределенное значение (NULL).
Основными операциями над массивами являются выборка значения элемента массива по его индексу, изменение некоторого элемента массива или массива целиком и конкатенация (сцепление) двух массивов. Кроме того, для любого значения типа массива можно узнать значение его cs.
Типы мультимножеств
При определении столбца таблицы типа мультимножества используется конструкция dt MULTISET, где dt задает тип данных элементов конструируемого типа мультимножеств. Значениями типа мультимножеств являются мультимножества, т.е. неупорядоченные коллекции элементов одного и того же типа, среди которых допускаются дубликаты. Например, значениями типа INTEGER MULTISET являются мультимножества, элементами которых являются целые числа. Примером такого значения может быть мультимножество {12, 34, 12, 45, -64}.
В отличие от массива, мультимножество является неограниченной коллекцией; при конструировании типа мультимножеств не указывается предельная кардинальность значений этого типа. Однако это не означает, что возможность вставки элементов в мультимножество действительно не ограничена; стандарт всего лишь не требует наличия границы. Ситуация аналогична той, которая возникает при работе с таблицами, для которых в SQL не объявляется максимально допустимое число строк.
Для типов мультимножеств поддерживаются операции для преобразования типа значения-мультимножества к типу массивов или другому типу мультимножеств с совместимым типом элементов (операция CAST), для удаления дубликатов из мультимножества (функция SET), для определения числа элементов в заданном мультимножестве (функция CARDINALITY), для выборки элемента мультимножества, содержащего в точности один элемент (функция ELEMENT). Кроме того, для мультимножеств обеспечиваются операции объединения (MULTISET UNION), пересечения (MULTISET INTERSECT) и определения разности (MULTISET EXCEPT). Каждая из операций может выполняться в режиме с сохранением дубликатов (режим ALL) или с устранением дубликатов (режим DISTINCT).
Расширенные в SQL:2003 возможности работы с типами коллекций являются принципиально важными. Даже при наличии определяемых пользователями типов данных (см. ниже) и типов массивов SQL:1999 не предоставлял полных возможностей для преодоления ограничения "плоских" таблиц, исторически присущего реляционной модели данных вообще и SQL в частности. После появления конструктора типов мультимножеств и устранения ограничений на тип данных элементов коллекции, это историческое ограничение полностью ликвидировано. Мультимножество, типом элементов которого является анонимный строчный тип (см. ниже) является полным аналогом таблицы. Тем самым, в базе данных допускается произвольная вложенность таблиц. Возможности выбора структуры базы данных безгранично расширяются.
Анонимные строчные типы
Анонимный строчный тип – это конструктор типов ROW, позволяющий производить безымянные типы строк (кортежей). Любой возможный строчный тип получается путем использования конструктора ROW. При определении столбца, значения которого должны принадлежать некоторому строчному типу, используется конструкция ROW (fld1, fld2, …, fldn ), где каждый элемент fldi, определяющий поле строчного типа, задается в виде тройки fldname, fldtype, fldoptions. Подэлемент fldname задает имя соответствующего поля строчного типа. Подэлемент fldtype специфицирует тип данных этого поля. В качестве типа данных поля строчного типа можно использовать любой допустимый в SQL тип данных, включая типы коллекций, определяемые пользователями типы и другие строчные типы. Необязательный подэлемент fldoptions может задаваться для указания применяемого по умолчанию порядка сортировки, если соответствующий подэлемент fldtype указывает на тип символьных строк, а также должен задаваться, если fldtype указывает на ссылочный тип (см. ниже). Степенью строчного типа называется число его полей.
Типы, определяемые пользователем
Эта категория типов данных (вернее, подкатегория структурных UDT) наиболее тесно связана с "объектными" расширениями языка SQL. Более подробно мы обсудим структурные UDT в следующем подразделе статьи, а здесь для полноты картины приведем беглый набросок. В SQL поддерживаются две разновидности UDT.
- Индивидуальные типы (Distinct Types). Можно определить долговременно хранимый, именованный тип данных, опираясь на единственный предопределенный тип. Например, можно определить индивидуальный тип данных PRICE, опираясь на тип DECIMAL (5, 2). Тогда значения типа PRICE представляются точно так же, как и значения типа DECIMAL (5, 2). Однако в SQL:1999 индивидуальный тип не наследует от своего опорного типа набор операций над значениями. Например, чтобы сложить два значения типа PRICE требуется явно сообщить системе, что с этими значениями нужно обращаться как со значениями типа DECIMAL (5, 2). Другая возможность состоит в явном определении методов, функций и процедур, связанных с данным индивидуальным типом. Похоже, что в будущих версиях стандарта появятся и другие, более удобные возможности.
- Структурные типы (Structured Types). Соответствующие возможности SQL:1999 позволяют определять долговременно хранимые, именованные типы данных, включающие один или более атрибутов любого из допустимых в SQL типа данных18 – в том числе, другие структурные типы, типы коллекций, строчные типы и т.д. Стандарт SQL не накладывает ограничений на сложность получаемой в результате структуры данных, однако не запрещает устанавливать такие ограничения в реализации. Дополнительные механизмы определяемых пользователями методов, функций и процедур позволяют определить поведенческие аспекты структурного типа.
Ссылочные типы
Эта категория типов данных имеет смысл только в контексте "объектных" расширений языка SQL, и мы снова отложим подробное обсуждение этого механизма до следующих подразделов и обсудим его здесь очень коротко. Обеспечивается механизм конструирования типов (ссылочных типов), которые используются в качестве типа специального столбца некоторого вида таблиц (типизированных таблиц), а также в качестве типов обычных столбцов таблиц, атрибутов структурных UDT, переменных и параметров. Фактически, значения ссылочного типа указывают на строки соответствующей типизированной таблицы. Более точно, каждой строке типизированной таблицы приписывается уникальное значение (нечто вроде первичного ключа, назначаемого системой или приложением), которое может использоваться в методах, определенных для табличного типа, для уникальной идентификации строк соответствующей таблицы. Эти уникальные значения называются ссылочными значениями, а их тип – ссылочным типом. Ссылочный тип может содержать только те значения, которые действительно ссылаются на экземпляры указанного типа (т.е. на строки соответствующей типизированной таблицы).
Обратим внимание читателей на то, что все категории типов SQL, кроме ссылочных типов и, частично, структурных UDT содержат совершенно традиционные типы данных, никаким образом не связанные с объектной парадигмой ODMG. Каждый тип можно использовать при спецификации столбцов таблицы, и со значениями этих столбцов можно работать через операции соответствующего типа. Однако структурные UDT и связанные с ними ссылочные типы нагружаются в стандарте SQL некоторым особым смыслом, который объявляется "объектным". Об этом мы и будем говорить далее.
3.2 Структурные UDT
В синтаксической конструкции определения структурного UDT присутствуют следующие основные компоненты (некоторые из которых являются необязательными):
- имя;
- имя супертипа;
- набор атрибутов;
- набор сигнатур методов19;
- спецификация ссылочного типа;
- признак инстанциируемости.
При определении структурного UDT можно использовать одиночное наследование. Если в определении UDT присутствует раздел подтипизации, то в нем указывается имя ранее определенного UDT, атрибуты и методы которого будут наследоваться определяемым структурным типом. Поддерживается полиморфизм по включению: любое значение любого подтипа трактуется как значение любого супертипа этого подтипа.
Структурные типы, определяемые без использования наследования, называются максимальными супертипами (поскольку у любого из таких типов супертип отсутствует). В определениях максимального структурного супертипа обязан присутствовать раздел представления, в котором специфицируются атрибуты. Имя определяемого атрибута должно отличаться от имен всех других атрибутов определяемого типа, включая имена атрибутов, наследуемых от супертипа, и имена атрибутов типа данных определяемого атрибута. Тип данных может быть любым допустимым в SQL типом данных (включая конструируемые типы ARRAY, MULTISET и ROW, а также UDT), кроме самого определяемого структурного типа и его супертипов.
Можно определить инстанциируемый (instantiable) или неинстанциируемый (not instantiable) структурный тип. Для неистанциируемого типа не определяется конструктор, и поэтому невозможно создать значение этого типа.20 Поэтому такие типы применимы только для определения инстанциируемых подтипов. Назначение неинстанциируемых типов состоит в моделировании абстрактных концепций, на которых основываются более конкретные концепции. Неинстанциируемые типы могут быть типами атрибутов других структурных типов, типами столбцов, переменных и т.д. Однако в соответствующем местоположении21 всегда должно находиться либо значение инстанциируемого подтипа данного неинстанциируемого типа, либо неопределенное значение. При отсутствии явной спецификации по умолчанию тип считается инстанциируемым.
Все, что говорилось до сих пор в этом подразделе по поводу структурных UDT, не имеет никакой "объектной" специфики. Определенный пользователем структурный тип устроен как самый обычный тип: он обладает множеством значений и набором операций, а роль литералов играет метод-конструктор. Но у структурных UDT в SQL имеется одна особенность: при определении любого UDT автоматически образуется соответствующий ссылочный тип (ref type), причем можно явно указать, каким образом устроены значения этого типа. В "объектной" модели SQL значения ссылочного типа претендуют на роль аналога OID модели ODMG. Чтобы пояснить смысл спецификации ссылочного типа, забежим немного вперед и немного поговорим о типизированных таблицах, поскольку значения ссылочного типа имеют смысл только в этом контексте.
Типизированная таблица определяется на некотором ранее определенном структурном UDT, и атрибуты этого UDT становятся столбцами таблицы. Кроме того, у типизированной таблицы создается дополнительный "самоссылающийся" (self-referensing) столбец, содержащий значения соответствующего ссылочного типа. В "объектной" модели SQL утверждается, что строки типизированных таблиц обладают всеми характеристиками объектов в объектно-ориентированных системах, включая уникальные идентификаторы (значения ссылочного типа), которые могут использоваться для ссылок из других компонентов среды.
В SQL:1999 поддерживаются три различных механизма присваивания уникальных идентификаторов экземплярам структурных типов, ассоциированных с типизированными таблицами (для всех строк таблицы, ассоциированной с данным структурным типом, используется один и тот же механизм). Уникальные идентификаторы экземпляров структурного типа (значения самоссылающегося столбца) могут представлять собой следующее:
- значения, генерируемые системой автоматически;
- значения некоторого встроенного типа SQL, которые должны генерироваться приложением при сохранении экземпляра структурного типа как строки типизированной таблицы;
- значения, порождаемые из одного или нескольких атрибутов структурного типа.
Раздел спецификации ссылочного типа может присутствовать только в определении максимального структурного супертипа, т.е. соответствующая спецификация наследуется всеми подтипами этого супертипа. При отсутствии в определении супертипа явного раздела спецификации ссылочного типа по умолчанию предполагается автоматическая генерация ссылочных значений. Если в определении структурного типа указывается, что значения ссылочного типа будут генерироваться приложением, то в определении структурного типа должны присутствовать и спецификации преобразования ссылочных значений. Эти спецификации используются для преобразования поставленных приложением значений встроенного типа в значения, требуемые для реального выполнения ссылок на строки типизированной таблицы, и обратного преобразования.
Заметим, что хотя в SQL допускается использование ссылочного типа при определении столбца любой таблицы, атрибута структурного UDT, переменной или параметра, реальное применение ссылки (через операцию разыменования) для доступа к соответствующему "объекту" возможно только в том случае, когда при спецификации местоположения данных ссылочного типа указывается раздел SCOPE, своего рода область видимости "объектов", на которые указывают ссылки. Поскольку в качестве такой области видимости задается типизированная таблица, отложим более подробное обсуждение этого вопроса до конца следующего подраздела.
3.3 Типизированные таблицы
Хотя типизированные таблицы являются важнейшим элементом "объектной" модели SQL, с точки зрения синтаксиса оператор определения типизированной таблицы представляет собой частный случай оператора создания базовой таблицы CREATE TABLE22. Первой существенной особенностью оператора создания типизированной таблицы является обязательное наличие раздела, в котором указывается имя ранее определенного структурного типа. Строки типизированной таблицы называются "экземплярами" структурного типа, ассоциированного с таблицей.
Далее, при определении типизированной таблицы можно объявить ее подтаблицей некоторой другой типизированной таблицы. Супертаблица должна быть ассоциирована со структурным типом, являющимся непосредственным супертипом определяемой подтаблицы. В максимальной супертаблице (типизированной таблице, не имеющей супертаблицы) образуются столбцы, соответствующие атрибутам структурного UDT, с которым ассоциирована эта таблица (а также дополнительный "самоссылающийся" столбец). Каждый столбец указанной супертаблицы наследуется подтаблицей; наследуются и характеристики столбцов супертаблицы – значения по умолчанию, ограничения целостности и т.д. Эти столбцы называются унаследованными столбцами подтаблицы, и они соответствуют атрибутам UDT подтаблицы, унаследованным от UDT супертаблицы. Кроме того, подтаблица будет содержать по одному столбцу для каждого собственного атрибута ассоциированного структурного типа. Такие столбцы подтаблицы называются заново определенными.
Как это принято в SQL, столбцы типизированной таблицы имеют порядковые номера. При этом унаследованные столбцы нумеруются до заново определенных столбцов и имеют те же номера, которые имели столбцы супертаблицы.
В определении типизированной таблицы разрешается указывать табличные ограничения целостности. Если определяется максимальная супертаблица, то в ее определении допускается спецификация первичного ключа. В определении типизированной таблицы могут также содержаться спецификации ссылочных ограничений целостности. Ссылки могут вести как на типизированную, так и на обычную таблицу.
В определении максимальной супертаблицы должна присутствовать спецификация "самоссылающегося" столбца, и самоссылающийся столбец, определенный в максимальной супертаблице, наследуется любой ее подтаблицей. Как отмечалось в предыдущем подразделе, при определении любого максимального структурного супертипа явно или неявно задается спецификация ссылочного типа, и спецификация ссылочного типа наследуется всеми подтипами этого супертипа. При определении максимальной типизированной супертаблицы необходимо дополнительно указать соответствующую спецификацию самоссылающегося столбца (в этой спецификации, по сути, повторяются правила генерации значений ссылочного типа; она логически избыточна, и, по всей вероятности, в следующих версиях стандарта SQL требование спецификации самоссылающегося столбца будет ослаблено).
Наконец, в определении типизированной таблицы могут задаваться опции столбцов. Опции столбца можно указывать только для заново определенных столбцов, для унаследованных столбцов это не допускается. Можно указывать значение столбца по умолчанию, ограничения столбца, но в контексте этой статьи наиболее важным является раздел SCOPE. Этот раздел может входить в опции только заново определяемого столбца с типом REF.
Как отмечалось в конце предыдущего подраздела, раздел SCOPE может присутствовать в спецификации любого местоположения ссылочного типа. Поэтому стоит рассмотреть эту тему в общем виде. Для объявления местоположения ссылочного типа используется следующий синтаксис:
REF (UDT_name) [SCOPE table_name]
UDT_name должно задавать имя структурного UDT, на "экземпляры" которого будут указывать значения ссылочного типа. REF-тип может использоваться к качестве типа атрибута структурного типа, и в этом случае тип с именем UDT_name может быть тем же самым, что и определяемый структурный тип. Во всех остальных случаях UDT_name должно являться именем некоторого существующего структурного типа. В необязательном разделе SCOPE задается имя типизированной таблицы table_name. Ассоциированным структурным типом этой таблицы должен быть тип с именем UDT_name.
Если местоположение объявлено с указанием раздела SCOPE, над содержащимися в нем ссылочными значениями можно выполнять операции разыменования (взятия значения указанного атрибута "объекта", на который ведет ссылка, т.е. взятия значения указанного столбца той строки типизированной таблицы, значение самоссылающегося столбца которой совпадает со значением ссылки). Кроме того, в стандартах SQL:1999/2003 определены операции вызова метода "объекта" по ссылке (т.е. вызова метода структурного UDT, ассоциированного с указанной в разделе SCOPE типизированной таблицы, для значения, находящегося в соответствующей строке этой таблицы) и разрешения ссылки (т.е. взятия всего структурного значения, находящегося в соответствующей строке типизированной таблицы).
В соответствии со спецификациями SQL:1999 при объявлении местоположения ссылочного типа с разделом SCOPE можно было дополнительно потребовать от системы поддержки целостности ссылок, т.е. гарантирования того, что в местоположении никогда не будет содержаться ссылочное значение, для которого в типизированной таблице, указанной в разделе SCOPE, не найдется строка с таким же значением самоссылающегося столбца. В стандарте SQL:2003 эта возможность исключена, поскольку спецификации SQL:1999 были неточны. Скорее всего, исправленный вариант соответствующих конструкций появится в следующей версии стандарта.
Наконец, заметим, что если раздел SCOPE включается в определение атрибута структурного UDT, то в опциях столбца типизированной таблицы, соответствующего данному атрибуту, раздел SCOPE присутствовать не может – это считается синтаксической ошибкой.
4. Сопоставление моделей
В качестве аналога объекта в смысле модели ODMG в модели SQL выступает "экземпляр" структурного UDT, или строка типизированной таблицы, ассоциированной с этим UDT. Покажем, что эта аналогия является поверхностной и неточной. Действительно, в модели ODMG объект создается конструктором некоторого объектного типа. Объект обладает свойством индивидуальности (identity), которое выражается в том, что при создании объекта ему присваивается уникальный идентификатор (OID), отличающий его от любого другого объекта любого объектного типа. OID является внешней характеристикой объекта, значение OID не является частью состояния объекта. Объекты в модели ODMG больше всего похожи на динамические переменные в языках программирования; конструктор объектного типа похож на оператор new, создающий динамическую переменную соответствующего типа; OID, по своей сути, напоминает указатель на динамическую переменную. Операция разыменования в модели ODMG кажется аналогичной операции взятия значения элемента структуры по прямому адресу соответствующей структурной переменной.
Объекты ODMG индивидуальны и в том смысле, что каждый из них существует независимо от других, представляя собой независимо идентифицируемый (адресуемый) контейнер данных. Объекты, относящиеся к общему объектному типу, могут объединяться в коллекции. Объект может входить в несколько различных коллекций, и может не входить ни в одну коллекцию; это возможно исключительно за счет наличия OID, уникально представляющего объект. В модели ODMG экстент класса введен как дополнительное и необязательное понятие. То же можно сказать и про возможность указания возможного ключа класса: это понятие не является фундаментальным и вводится по техническим соображениям. Фундаментальными основами модели ODMG является система типов (включая, конечно, типы коллекций) и OID23.
Разработчики стандарта SQL утверждают, что и "объекты" SQL обладают свойством индивидуальности. Они обосновывают это тем, что строки типизированных таблиц обязательно различаются значениями самоссылающегося столбца. Другими словами, утверждается, что значение самоссылающегося столбца "экземпляра" структурного UDT (т.е. строки типизированной таблицы, ассоциированной с этим UDT) является аналогом OID. Действительно имеется некоторое сходство: ссылочные значения могут автоматически генерироваться системой при образовании нового "экземпляра" структурного UDT (вставке новой строки в типизированную таблицу), и система гарантирует уникальность каждого ссылочного значения.
Но первое важнейшее различие состоит в том, что в модели ODMG OID является внешней характеристикой объекта, не отражающейся в его состоянии, а ссылочное значение "экземпляра" структурного UDT в модели SQL является явным компонентом этого "экземпляра" (оно сохраняется в отдельном столбце типизированной таблицы). Если OID можно трактовать как абстракцию указателя, который можно использовать для прямой адресации объекта как контейнера значений (подобно тому, как производится доступ к переменной через указатель в языках программирования), то ссылочное значение в SQL можно использовать только для ассоциативной адресации (по совпадению ссылочного значения) соответствующей строки в указанной типизированной таблице (отсюда потребность в разделе SCOPE при объявлении местоположения ссылочного типа). "Экземпляры" структурного UDT в модели SQL не являются независимыми контейнерами значений; контейнером является типизированная таблица, которая представляет собой аналог именованной переменной, содержащей в каждый момент времени некоторое значение-множество с элементами-значениями соответствующего структурного UDT. Cтрока типизированной таблицы является элементом этого значения-множества. Таким образом, "экземпляр" структурного UDT в модели SQL – это совсем не объект в смысле ODMG.
Далее, в модели ODMG один объект может входить в несколько коллекций (в том числе, в экстент своего объектного типа). Нет какой-либо одной выделенной коллекции, все они образуются за счет наличия OID как полномочного внешнего представителя объекта. Запросы на языке OQL можно адресовать к любой коллекции (и к индивидуальному объекту, если известен его OID). Типизированную таблицу в модели SQL нельзя считать аналогом экстента объектного типа по двум причинам. Во-первых, можно создать несколько типизированных таблиц, ассоциированных с одним структурным UDT (этот довод не очень сильный, поскольку экстентом можно было бы считать объединение значений всех таких типизированных таблиц). Более важно то, что типизированная таблица в SQL содержит не множество объектов (т.е. OID), а множество значений структурного UDT. Конечно, в SQL можно построить коллекцию ссылочных значений строк типизированной таблицы, но к этой коллекции нельзя адресовать запросы. Другими словами, типизированная таблица в модели SQL – это совсем не экстент в смысле ODMG.
По нашему мнению, рассмотренный материал позволяет сделать вывод о том, что "объектная" модель SQL является всего лишь синтаксической надстройкой над традиционной "реляционной" моделью данных. Различия моделей SQL и ODMG гораздо более серьезны, чем синтаксическое сближение языков запросов SQL и OQL.
В заключение статьи сделаем два замечания. Во-первых, целью этой статьи не являлась критика подходов SQL и/или ODMG к организации баз данных (хотя, конечно же, такая критика возможна и, наверное, полезна). У обоих подходов имеются убежденные сторонники и противники, и эта статья написана не для них. Мы хотели лишь разъяснить реальное положение дел для людей, которые все еще надеются на возможность совершения чудес и, в частности, ожидают появления систем управления базами данных, действительно сочетающих традиционные возможности SQL с преимуществами ODMG. Похоже, что это не произойдет.
Во-вторых, еще до написания этой статьи в адрес автора звучала критика относительно завышения им роли OID в объектных моделях данных. В критических замечаниях указывалось, что на уровне модели фундаментальным абстрактным свойством является индивидуальность (identity) объектов, а OID – это техническая реализация поддержки индивидуальности. Возможно, эта критика была бы справедливой, если бы рассуждения велись в академической манере, не привязываясь к конкретной спецификации. Однако в этой статье обсуждалось соотношение модели SQL с конкретной объектной моделью ODMG 3.0. И вот цитата из [4] (стр. 17):
"Поскольку у всех объектов имеются идентификаторы, любой объект можно отличить ото всех других объектов в его домене хранения. … Все идентификаторы в объектной модели ODMG являются взаимно уникальными. Представление индивидуальности объекта называется его объектным идентификатором".
Литература
1 Jim Melton. "Advanced SQL:1999. Understanding Object-Relational and Other Advanced Features". Morgan Kaufmann Publishers, 2003.
2 Э.Ф. Кодд. Реляционная модель данных для больших совместно используемых банков данных. СУБД, № 1, 1995 г. http://www.osp.ru/dbms/1995/01/01.htm.
3 Сергей Кузнецов. Наиболее интересные новшества в стандарте SQL:2003.
4 The Object Data Standard: ODMG 3.0. Edited by R.G.G. Cattel, Douglas K. Barry. Morgan Kauffmann Publishers, 2000.
1 Конечно, в действительности нужно говорить о "модели данных SQL". Во-первых, стандарты языка SQL на самом деле специфицируют некоторую законченную модель данных. Во-вторых, эта модель существенно отличается от реляционной модели в том виде, в котором ее предложил д-р Эдгар Кодд [2]. Достаточно упомянуть возможность отсутствия возможного ключа в таблице и упорядоченность ее столбцов. Тем не менее, широкая публика по-прежнему называет модель SQL реляционной.
2 Под "объектной моделью данных" мы понимаем модель, специфицированную Object Data Management Group в [4]. К этой спецификации можно предъявлять много претензий (что мы не будем делать в этой статье), но она является единственной объектной моделью, по поводу которой имеется хотя бы относительное согласие.
3 А не мультимножество – как будет понятно далее, типизированная таблица не может содержать строки-дибликаты.
4 В 2001 г. ODMG официально прекратила свое существование.
5 Эти стандарты не являются официальными. Подход ODMG к стандартизации заключался в том, что после принятия очередной версии стандарта организациями-членами ODMG публиковалась книга, в которой содержался текст стандарта. Все издания стандарта ODMG публиковались издательством Morgan-Kauffman.
6 Термин литерал в модели ODMG используется в смысле, отличном от того, в котором он обычно используется в литературе, означая внешнее представление значения типа данных.
7 Под термином свойство в модели ODMG понимается атрибут объекта или его связь с некоторым другим объектом.
8 Конечно же, на самом деле значением атрибута worksFor будет являться OID объекта-компании, но обычно это явно не говорится.
9 Должно быть понятно, что таким образом выражается всем знакомое ограничение целостности по ссылкам.
10 Это очевидным образом наводит на мысль, что в реализации СУБД на основе модели ODMG для представления связей должны использоваться OID.
11 Снова стоит задуматься, что такое значение-объект компонента значения литерального структурного типа? Об этом ничего явно не говорится в [4], но кажется невозможным придумать что-либо иное, как снова использовать OID.
12 Можно определить литеральный тип коллекции с объектным типом элементов. На модельном уровне значением такого типа является литеральная коллекция объектов. Нам кажется, что единственной возможной интерпретацией такого понятия является коллекция OID объектов одного и того же объектного типа.
13 В модели ODMG не используется термин метод.
14 В этой статье мы не рассматриваем средства определения реализационного программного кода операций UDT (как в модели ODMG, так и в модели SQL).
15 В модели ODMG определение ключа рассматривается не как ограничение целостности (как в реляционной модели), а так средство повышения эффективности доступа к объектам экстента класса. В связи с этим не очень понятно, почему в ODL имеется средство определения только уникальных ключей.
16 Язык SQL/PSM (Persistent Storage Modules) является специфицированным в стандарте SQL процедурным расширением SQL, предназначенным для написания сохраняемых в базе данных серверных процедур, функций и методов.
17 Типы битовых строк были введены в стандарте SQL:1999 и исчезли в стандарте SQL:2003.
18 Требуется, чтобы в определении структурного типа A использовались только те типы, которые были определены ранее (с одним исключением, относящимся к спецификации атрибута ссылочного типа).
19 Как и в предыдущем разделе, мы не будем рассматривать особенности реализации тел методов.
20 Здесь мы используем оборот, принятый в стандарте SQL. Заметим, что, хотя смысл неинстанциируемого типа должен быть интуитивно понятен, приведенное определение является очень нечетким. Притом, что в SQL поддерживаются типы данных в традиционном смысле, основанные на паре <множество_значений, набор_операций>, нельзя создать значение типа, можно только выбрать его из соответствующего множества значений. Поэтому, строго говоря, в типе данных не может присутствовать "метод-конструктор", а может иметься (или не иметься) операция выборки значения. У неинстациируемых типов такая операция отсутствует.
21 В стандарте SQL термин местоположение (site) используется в качестве сокращения для оборота столбец, атрибут структурного UDT, переменная или параметр.
22 Кстати, это четвертый способ определения базовой таблицы. Можно создать таблицу традиционным образом с определениями каждого столбца, можно создать таблицу с одним столбцом анонимного строчного типа, и можно создать таблицу с одним столбцом, определенном на структурном UDT. Третий вариант отличается от второго возможностью применения методов UDT к строкам таблицы. Заметим, что третий вариант не приводит к созданию типизированной таблицы: создается обычная таблица с одним столбцом.
23 Кстати, хотя это и не делается в модели ODMG, можно было бы считать, что у каждого объектного типа имеется соответствующий ссылочный тип, и OID объектов этого типа являются значениями этого ссылочного типа. Тогда вся объектная модель ODMG полностью характеризовалась бы своей системой типов.