Система хранения и управление памятью
При разработке методов структуризации данных и управления памятью преследовалась
цель добиться эффективности работы системы при выполнении запросов и операций
обновления базы данных, а также “программ” XQuery , не связанных с интенсивным
потреблением данных и отражающих логику приложения [11]. Общие идеи заключаются
в том, что, во-первых, содержимое блоков базы данных не изменяется при перемещении
блока из внешней в основную память (т.е. не возникает известная проблема “настройки
по адресам” (swizzling), для решения которой требуются существенные
накладные расходы). Во-вторых, для представления связей между узлами XML -документа
почти всегда используются прямые указатели, которые можно использовать для
перехода от одного узла к другому сразу после перемещения блока базы данных
в основную память. При этом потенциальный размер базы данных не ограничивается.
Структуры данных
В СУБД Sedna в основе хранения XML -документа во внешней памяти лежит описывающая
( descriptive ) схема XML -документа, в соответствии с которой осуществляется
кластеризация узлов XML -документа в блоках базы данных. Описывающая схема
генерируется (и поддерживается) динамически на основе хранимых данных и представляет
собой краткое и точное описание структуры этих данных. Выражаясь формально,
для каждого пути в документе существует в точности один путь в описывающей
схеме, и каждый путь в описывающей схеме является путем в документе.
<library>
<book>
<title>Foundation of Databases</title>
<author>Abitboul</author>
<author>Hull</author>
<author>Vianu</author>
</book>
<book>
<title>An Introduction to Database Systems</title>
<author>Date</author>
<issue>
<publisher>Addison-Wesley</publisher>
<year>2004</year>
</issue>
</book>
...
<paper>
<title>A Relational Model for Large Shared Data Banks</title>
<author>Codd</author>
</paper>
</library>
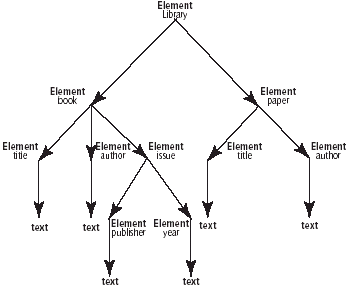
Рис. 2. Организация данных
Общие принципы организации хранения XML -документа иллюстрируются на рис. 2. Центральным компонентом является описывающая схема, представляемая в виде
дерева узлов. Каждый узел схемы помечается названием разновидности XML -узла
(например, element , attribute , text и т.д.) и
содержит указатель на блоки данных, в которых хранятся узлы XML -документа,
соответствующие данному узлу схемы. Некоторые узлы схемы, в зависимости от
вида узла, помечаются дополнительными именами.
Блоки данных, относящиеся к одному узлу схемы, связаны указателями в двунаправленный
список. Дескрипторы узлов в списке блоков частично упорядочены в соответствии
с порядком документа. Это означает, что каждый дескриптор узла в блоке i предшествует
каждому дескриптору узла в блоке j в соответствии с порядком
документа том и только в том случае, когда i < j (т.е.
блок i предшествует блоку j в списке).
Внутри блока узлы линейно не упорядочиваются, что сокращает накладные расходы
на поддержку порядка документа при выполнении операций обновления.
В системе хранения разделяются структурная часть узла и его текстовое значение,
являющееся содержимым текстового узла, или значением узла-атрибута и т.д. Длины
текстовых значений являются переменными, и они хранятся в отдельных блоках со
специальной структурой. В структурной части узла, представляемой в виде дескриптора
узла, отражаются его связи с другими узлами (предком, потомками, братьями и т.д.).
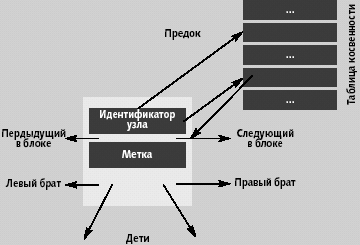
Рис. 3. Общая структура дескриптора узла
Общая структура дескриптора узла для всех разновидностей узлов показана на
рис. 3. Поле метки содержит метку нумерующей схемы (про нумерующую схему и
идентификаторы узлов см. ниже. Указатели на следующий и предыдущий узлы в том
же блоке служат для восстановления порядка документа между узлами документа,
соответствующими одному и тому же узлу схемы, а указатели на левого и правого
братьев по схеме – для поддержки порядка документа между узлами-братьями. В
дескрипторе хранятся ссылки только на первые дочерние узлы в соответствии с
описывающей схемой. Поддержка только указателя на первого потомка в соответствии
со схемой позволяет экономить память и, что более важно, сохранять фиксированный
размер дескриптора блока. Последнее свойство особенно существенно для эффективного
выполнения операций обновления, поскольку упрощается управление свободной памятью
внутри блока.
Использование прямых указателей способствует эффективному выполнению запросов,
но порождает проблемы эффективного выполнения операций обновления. Чтобы организация
данных была эффективно пригодна для обновлений, нужно минимизировать число
модификаций данных, производимых при выполнении операции обновления. Например,
выполнение некоторых операций обновления может привести к перемещению узла.
Если у узла, который требуется переместить, имеются узлы-потомки, то в каждом
из них необходимо поменять значения указателей на узел-предок. Чтобы избежать
этой массовой операции, для ссылок на узлы-предки используются косвенные указатели,
реализуемые через таблицу косвенности.
Нумерующая схема назначает уникальную метку каждому узлу XML -документа в
соответствии с присущими данной схеме правилами нумерации. Метки кодируют информацию
об относительной позиции узла в документе. Таким образом, основное назначение
нумерующей схемы состоит в обеспечении быстрых механизмов определения структурной
связи между парой узлов. При разработке СУБД Sedna требовалась нумерующая схема,
обеспечивающая обнаружение связи “потомок-предок” и сравнение узлов в порядке
документа. Первый механизм позволяет поддерживать планы выполнения запросов,
основанные на соединениях " включению” ( containment join )
[12-13]. Второй механизм используется для реализации операций XQuery ,
основанных на порядке документа (например, сравнение узлов, XPath и т.д.).
Основная проблема существующих нумерующих схем для XML (например, схемы, предложенной
в [5]) состоит в том, что вставка узлов может повлечь реконструкцию всего XML
-документа. В СУБД Sedna используется новая нумерующая схема, не требующая
подобной реконструкции. Идея этой нумерующей схемы основана на том наблюдении,
что для каждых двух заданных строк str 1 и str 2 , таких
что str 1 < str 2 (в лексикографическом
порядке), существует строка str , такая что str 1 < str < str 2 .
Например, для str 1 = " abn ", str 2 = " ghn " возможным
значением str является " bcb ", а для str 1 = " ab ", str 2 = " ac " значением str может
быть " abd ". Нумерующая схема, поддерживающая порядок документа,
может быть использована для реализации понятия уникального идентификатора ( unique identity ),
принятого в XQuery , потому что в такой схеме любые два узла с одинаковыми
метками являются одним и тем же узлом.
Для реализации некоторых операций и механизмов управления базой данных требуется
поддержка идентификатора узла, являющегося неизменным во все время существования
узла и обеспечивающего эффективный доступ к узлу. Например, идентификаторы
узлов могут использоваться для ссылки на узлы в индексных структурах. Эти идентификаторы
также требуются для корректной реализации операций обновления. Как отмечалось
выше, при выполнении некоторых операций обновления может потребоваться перемещение
узлов. Поэтому указатели на узлы не обладают свойством неизменности. Хотя метка
нумерующей схемы этим свойством обладает, для получения узла по известной метке
требуется обход дерева документа. Реализация идентификатора узла показана на
рис. 3. Она основана на поддержке специальной таблицы косвенности, которая
также используется для реализации косвенных указателей на узлы-потомки. Идентификатор
узла является указателем на запись в таблице косвенности, которая содержит
указатель на узел.
Управление памятью
Как уже говорилось, одним из основных проектных решений, имеющих отношение
к организации памяти в СУБД Sedna , является использование прямых указателей
для представления связей между узлами. Хотя использование обычных указателей
языков программирования, поддерживаемых механизмом управления виртуальной памяти
операционной системы, идеально с точки зрения эффективности и простоты программирования,
в данном случае это решение не является удовлетворительным. Во-первых, оно
накладывает ограничение на размер адресного пространства, свойственное стандартным
32-битовым архитектурам, которые превалируют в настоящее время. Во-вторых,
при обработке запросов над большими объемами данных СУБД не может полагаться
на механизм виртуальной памяти, обеспечиваемый ОС, потому что требуется собственное
управление процедурой замещения страниц для выталкивания страниц на диск в
соответствии логикой выполнения запроса [14].
Для решения этой проблемы в проекте Sedna был разработан собственный механизм
управления памятью, поддерживающий 64-битовое адресное пространство ( Sedna Address Space , SAS )
и тесно взаимодействующий с менеджером буферов. Каждой базе данных, управляемой
СУБД Sedna , соответствует свое SAS , полностью отображаемое на внешнюю
память, где реально хранится база данных, и частично отображаемое на виртуальное
адресное пространство каждого процесса, в котором выполняется транзакция с
соответствующей базой данных ( Process Virtual Address Space , PVAS ).
В отображенной части SAS можно использовать обычные указатели.
SAS разбивается на уровни одинакового размера.
Размер уровня выбирается таким, чтобы диапазон адресов уровня умещался в PVAS .
Уровень стоит из страниц (они соответствуют блокам внешней памяти, в которых
хранятся узлы XML -документа). Все страницы имеют один и тот же размер, что
облегчает работу менеджера буферов. В заголовке каждой страницы сохраняется
номер уровня, которому принадлежит данная страница. Адрес объекта в SAS (длиной
64 бита) состоит из номера уровня (первые 32 бита) и адреса внутри уровня (последние
32 бита). Адрес внутри уровня отображается в точно такой же адрес PVAS .
Диапазон адресов PVAS , на который отображаются уровни SAS ,
в свою очередь, отображается менеджером буферов Sedna в адреса основной памяти
с использованием средств управления памятью, обеспечиваемых ОС.
При использовании указателя ( layer _ num , addr )
в любом процессе-транзакции для перехода от дескриптора некоторого узла к узлу,
который потенциально может находиться в другом блоке (левый и правый братья,
потомки) выполняется процедура разыменования указателя. Эта процедура проверяет,
присутствует ли страница, на которую указывает адрес addr , в основной
памяти, и если да, то соответствует ли значение layer _ num данного
указателя соответствующему значению в заголовке страницы. Если оба эти условия
выполнены, то процедура завершается, и addr используется
как обычный указатель в PVAS . В противном случае происходит обращение
к менеджеру буферов, который находит в основной памяти требуемую страницу или
выделяет свободную страницу (возможно, выталкивая из основной памяти во внешнюю
некоторую занятую страницу), считывая на нее соответствующий блок внешней памяти,
и обеспечивает ее расположение по требуемому адресу в PVAS . После
этого в данной транзакции можно использовать addr как обычный
указатель в PVAS . Следует также заметить, что, помимо прочего, выполнение
процедуры разыменования в данном процессе приводит к фиксации соответствующей
страницы в основной памяти до явного указания возможности отмены фиксации.
Таким образом, в любом PVAS могут одновременно находиться страницы с
разными значениями layer _ num , а в пуле страниц основной памяти, управляемом
менеджером буферов, могут даже одновременно находиться заполненные страницы с
разными layer _ num , которым соответствует один и тот же виртуальный
адрес в PVAS (конечно, в одном PVAS может в одно и то же время
присутствовать только одна из этих страниц).
содержание назад вперед