2001 г
Основные концепции и подходы при создании контекстно-поисковых систем на основе реляционных баз данных
Автор: Евгений Игумнов, Геокад Плюс (Новосибирск)
Домашняя страничка: http://manager.olc.ru
Редактор: Денис Щеглов
Опубликовано: 31.05.2001
Версия текста: 1.0
Введение
Архитектура
ER-модель поискового механизма
Индексный механизм
Поисковый механизм
Комплексное функционирование
Заключение
Введение
Когда передо мной поставили задачу разработки поисковой системы, то мне пришлось изобретать велосипед. Эта статья имеет цель избавить Вас от необходимости изобретать велосипед и позволит Вам сконцентрироваться на расширении и совершенствовании предложенного мной механизма. Я не претендую на роль первоисточника и не утверждаю, что предложенный мною подход является самым оптимальным, но позже я исследовал несколько бесплатных пакетов, обеспечивающих сервис контекстного поиска, и могу Вам с уверенностью сказать, что в основной своей массе они используют этот же подход.
Архитектура
Рассмотрим классическую архитектуру, которая чаще всего реализована на корпоративных сайтах и информационных порталах. Такая архитектура изображена на рис. 1.
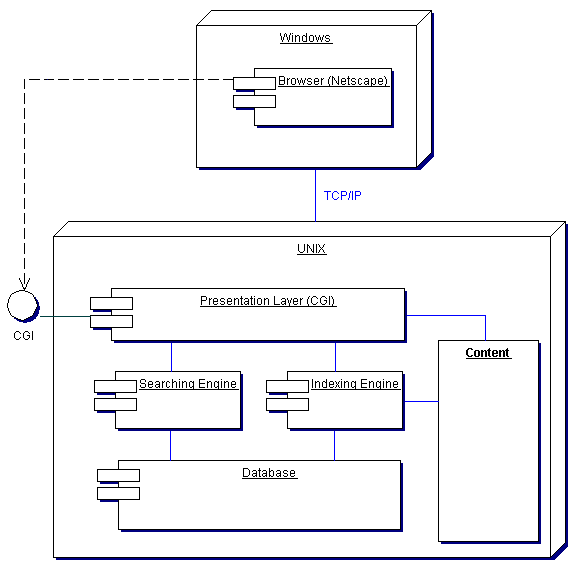
Рис.1
Разберем по частям то, что изображено на рисунке. Существует клиентская вычислительная машина под управлением ОС Windows и существует Web-сервер под управлением UNIX-подобной ОС. На стороне клиента запущен типичный браузер, такой как Netscape. На стороне сервера запущен web сервер, который обслуживает запросы от браузера, передавая запросы презентационному слою понимающему CGI. Презентационный слой передает запросы к поисковому механизму в случае вызова услуги поиска или отображает наполнение ( content) сайта. При работе администратора презентационный слой также может передавать запросы на инициализацию механизма индексации нового контента, который еще не индексирован. Это необходимо по той причине, что пока текст не индексирован, поиск в нем с помощью поисковой машины невозможен.
Идея заключается в следующем. Существуют мегабайты текстовой информации, и скорость поиска документов содержащих заданные ключевые слова отнимает очень много процессорного времени. Предположим, в 10 мегабайтах текстовой информации ключевое слово будет находиться в течение 10 секунд. И вот заходит посетитель на Ваш сайт, задает ключевые слова, вызывает услугу поиска и ждет 10 секунд, пока ваш сервер не выдаст ему результат. Предположим, случилось так, что одновременно запросило поиск 5 человек. Естественно, время ответа увеличится в 5 раз. Получается, что в среднем по 50 секунд пользователь будет ждать ответа от вашего сервера. Это не приемлемо, особенно если у Вас сотни мегабайт текстовой информации и время реакции системы будет катастрофически велико. Необходимо использовать другой подход при поиске ключевых слов в текстовой информации - время ответа сократить до миллисекунд.
ER-модель поискового механизма
Существует такая хорошая характеристика реляционных баз данных, как очень маленькое время выборки конкретной записи из миллионов других. Это достигается созданием так называемого индекса к таблице на какое-то из полей этой таблицы. Обычно индексы реализуются с применением алгоритма сбалансированного двоичного дерева. Предположим, у нас есть таблица, в которой всего один столбец и в каждой записи таблицы хранится фамилия человека. Предположим, мы загнали в такую таблицу 1 миллион фамилий. Нам необходимо проверить существует ли в этой таблице фамилия ИГУМНОВ. Предположим, что мы еще никаких индексов на эту таблицу не сделали, так же фамилия ИГУМНОВ стоит посередине таблице. Когда мы пошлем вот такой запрос: select surname from ourtable where surname='ИГУМНОВ' база данных переберет пол миллиона записей пока не дойдет до фамилии ИГУМНОВ и не выдаст результат. Получается слишком медленно. Но как только мы сделаем индекс на поле нашей таблицы, как сразу все наши запросы будут обрабатываться за миллисекунды, чего мы и добиваемся. Естественно, одной таблицы будет мало для решения нашей проблемы. Классическая структура базы данных, которая позволит решить нашу проблему, изображена на рис.2.
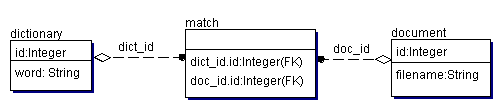
Рис.2
Начнем с таблицы document. В этой таблице хранятся имена файлов или URL'ы страниц и каждой такой записи сопоставлен уникальный ключ id. В таблице dictionary хранятся все слова, которые могут встретиться в наших документах, и каждому слову сопоставлен уникальный id. Естественно, создаются индексы на поле word в таблице dictionary и на поле id в таблице document. В нашем примере существует отношение многие ко многим. Это необходимо, так как в таблице match мы храним соответствие слова и документа. Другими словами, в таблице match хранится информация о том, какие слова есть в каждом документе. На таблицу match создают индекс, на поле dict_id.
Индексный механизм
Прежде чем ваши документы будут доступны для поиска, их необходимо проиндексировать. Объем индексной информации, полученной из текста, может быть в два раза больше чем сам тексте. А может еще больше, в случае если вы будете не оптимально использовать память. Алгоритм выглядит следующим образом.
1. Получаем документ для индексирования
2. Регистрируем его в таблице document, запоминаем полученный его уникальный id и будем его называть doc_id
3. Разбиваем документ на отдельные слова
4. Узнаем уникальные id этих слов из таблицы dictionary и будем их называть dict_id
5. Потом заносим записи с нашим одним doc_id и разными dict_id (для каждого слова в документе) в таблицу match.
Поисковый механизм
После того как мы проиндексировали наши документы, нужно понять какие запросы посылать в базу, что бы искать эти документы по ключевым словам. Предположим, есть поисковая фраза "река объ". Пользователю необходимо получить все документы содержащие эти два слова. Сначала нужно обратиться к таблице dictionary и узнать уникальные id этих слов, далее будем их называть $dict_id1 и $dict_id2. Потом необходимо послать такой запрос в таблицу match, который выдаст только те номера документов, которые содержат эти два слова. Вот пример этого запроса: SELECT doc_id FROM match where dict_id =$dict_id1 group by doc_id INTERSECT SELECT doc_id FROM match where dict_id=$dict_id2 group by doc_id. В случае если пользователь введет три слова, то вам придется добавить еще раз INTERSECT и третью часть SQL запроса. По полученным в результате запроса doc_id можно извлечь информацию об имени файла документа из таблицы document.
Комплексное функционирование
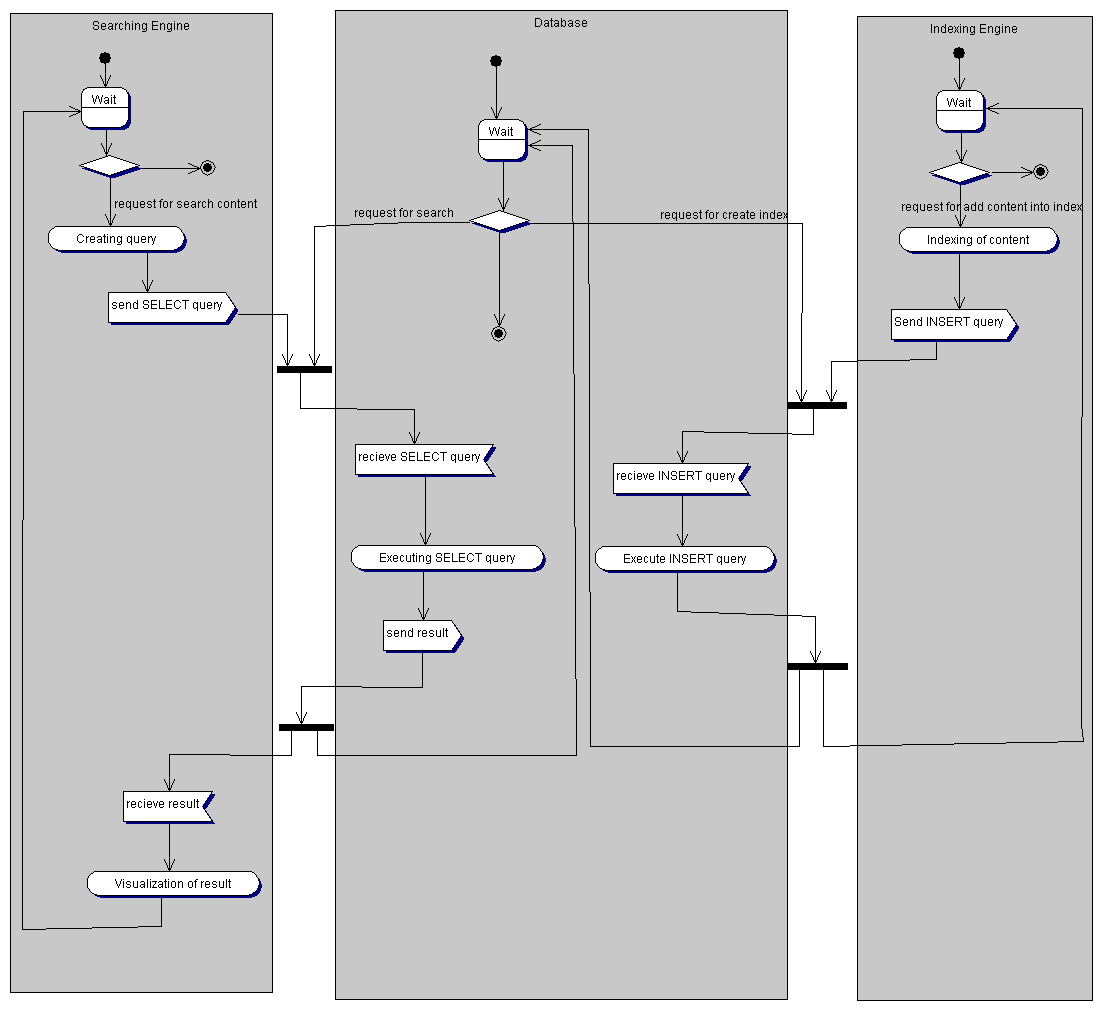
Что бы увидеть общее представление механизма взаимодействия с поисковой системой нужно взглянуть на рис. 3.
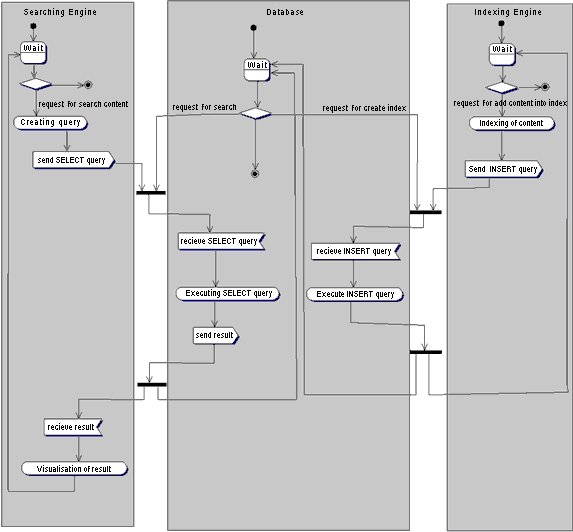
Рис.3
Как видно из рисунка, существует три потока управления. Первый обслуживает запросы пользователя, второй выполняет поисковые запросы, а третий занимается индексированием новых документов поступающих в систему. Первый поток - это скрипт на Perl, Servlet, ASP или PHP, который из ключевых слов пользователя формирует поисковые SQL запросы. Второй поток - это СУ базой данных, которая поддерживает целостность данных, индексный механизм и обслуживает SQL запросы. Третий поток - это тоже скрипт, который работает с новыми документами, индексирует их и посылает запросы в базу данных на внесения новой индексной информации.
Заключение
Разобранный пример является одним из наиболее популярных подходов. Он не претендует на полноту и оптимальность, так что у Вас могут возникнуть некоторые проблемы, которые придется Вам разрешать самим. Например: большая времяемкость процесса индексирования - при очень больших объемов текста (порядка 1Гб) необходимо распределять задачу, большое количество результатов запроса и т.д. и т.п. В свое время я решил большую часть этих проблем, но это уже тема отдельной статьи.
Copyright (C) 2001 Eugene Igumnov. Все права защищены.