|

2006 г.
Быть или не быть значению переменной
К. Дж. Дейт
Перевод - Сергей Кузнецов
Оригинал: To Be Is to Be a Value of a Variable
Все три статьи этого цикла построены в виде полемики с двумя анонимными критиками Третьего Манифеста. Однако данная статья особенно полемична. Местами она напоминает мне одну из любимых книг моего детства – «Материализм и эмпириокритицизм» В.И.Ленина (хотя стиль Дейта является гораздо более интеллигентным). На самом деле, в статье обсуждаются вопросы, играющие важнейшую роль в реляционной модели данных, как она представляется Дарвеном и Дейтом в Третьем Манифесте: значения, проявления значений, переменные отношений, присваивания, равенство и т.д. Вся статья читается исключительно увлекательно, но основной сюрприз запрятан в самом конце. Самое смешное, что если вы сразу начнете читать статью с конца, то можете и не найти этот сюрприз. Вернее, вы может не понять всю каверзность этого сюрприза. Так что читайте уж с начала до конца. Обещаю, не пожалеете.
С.Д. Кузнецов
Автор просит прощения у Джорджа Булос и его книги «Логика, логика и логика» (я позаимствовал название этой статьи из одного из эссе, включенного в эту книгу)*
Если мы хотим, чтобы мир оставался таким, как есть,
он должен изменяться
Джузеппе Томази ди Лампедуза
«Изменение» является научным понятием, а прогресс – понятием этическим,
наличие изменения несомненно, а наличие прогресса можно оспаривать
Бертран Рассел
Аннотация
В [1] два автора, именуемые далее Критиками A и B, критикуют Третий Манифест за поддержку реляционных переменных и реляционного присваивания. Эта статья является ответом на эту критику. Ожидается осведомленность читателей со следующими понятиями и терминам:
- Реляционная переменная (relation variable, сокращенно relvar) – это переменная, допустимыми значениями которой являются значения отношений (для краткости, отношения).
- Реляционное присваивание – это операция, при выполнении которой некоторое отношение r присваивается некоторой relvar R.
В [14] эти понятия разъясняются подробно с использованием языка Tutorial D в качестве основы примеров.
Почему мы нуждаемся в relvar?
Как отмечалось в аннотации, термин relvar является сокращением для термина реляционная переменная (relation variable). Он был введен нами с Хью Дарвеном в [9], первым опубликованном варианте Третьего Манифеста. Кодд в своих первых статьях о реляционной модели [3-4] использовал вместо него термин изменяемое во времени отношение (time-varying relation), но «изменяемые во времени отношения» – это те же relvar под другим именем. Конечно, мы не утверждаем, что были первыми, кто установил наличие этого факта, но мы полагаем, что были первым, уделившими ему серьезное внимание. Замечание: В публикации [2], появившейся на несколько лет ранее Третьего Манифеста, также проводится явное различие между отношениями и relvar (в ней они называются таблицами и табличными переменными соответственно). Однако это было сделано только под непосредственным влиянием моих комментариев, сделанных по поводу раннего варианта работы, в котором такое различие не проводилось.
Далее, мы полагаем, что понятие relvar и родственное понятие реляционного присваивания являются существенными, если нам требуется возможность обновления базы данных. Заметим, что переменные и присваивания действуют рука об руку (невозможно иметь одно без другого) – наличие переменной означает возможность присваивания этой переменной, а наличие возможности присваивания чему-либо означает, что это «что-либо» является переменной. Заметим также, что «возможность присваивания» («assignable to») и возможность обновления («updatable») означают ровно одно и то же; следовательно, возражения против relvar являются возражениями против реляционного обновления (эквивалентно, возражения против реляционного обновления являются возражениями против relvar).
По-видимому, здесь требуется небольшое дополнительное пояснение. Большая часть людей, говоря про реляционное обновление вообще, вероятно, имеет в виду традиционные операции INSERT, DELETE и UPDATE, а не реляционное присваивание – в особенности, в связи с тем, что, в частности, в SQL не поддерживается реляционное присваивание, хотя, конечно, поддерживаются INSERT, DELETE и UPDATE. Но, в конечном счете, оказывается, что INSERT, DELETE и UPDATE являются всего лишь сокращенными формами некоторых видов реляционного присваивания. Например, предположим, что имеется обычная база данных поставщиков и деталей (примерный набор значений см. на рис. 1).♦ Тогда оператор INSERT языка Tutorial D
INSERT SP RELATION
{ TUPLE { S# S#('S3'), P# P#('P1'), QTY QTY(150) },
TUPLE { S# S#('S5'), P# P#('P1'), QTY QTY(500) } } ;
является сокращенной формой оператора присваивания
SP := ( SP ) UNION ( RELATION
{ TUPLE { S# S#('S3'), P# P#('P1'), QTY QTY(150) },
TUPLE { S# S#('S5'), P# P#('P1'), QTY QTY(500) } } ) ;
Аналогично, оператор DELETE языка Tutorial D
DELETE S WHERE CITY = 'Athens' ;
является сокращенной формой оператора присваивания
S := S WHERE NOT ( CITY = 'Athens' ) ;
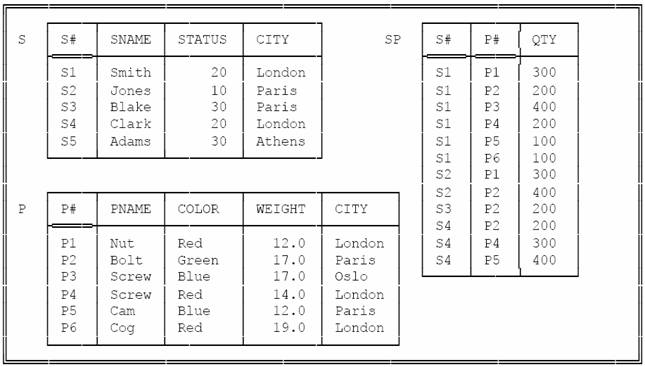
Рис. 1. База данных поставщиков и деталей – примерные значения
И оператор UPDATE языка Tutorial D
UPDATE P WHERE CITY = 'London'
( WEIGHT := 2 * WEIGHT, CITY := 'Oslo' ) ;
(немного более хитрым образом) является сокращенной формой оператора присваивания
P := WITH ( P WHERE CITY = 'London' ) AS T1,
( EXTEND T1
ADD ( 2 * WEIGHT AS NW, 'Oslo' AS NC ) ) AS T2,
( T2 { ALL BUT WEIGHT, CITY } ) AS T3,
( T3 RENAME ( NW AS WEIGHT, NC AS CITY ) ) AS T4,
( P MINUS T1 ) AS T5 :
T5 UNION T4 ;
Поэтому должно быть понятно, что реляционное присваивание, по существу, является единственной требуемой операцией реляционного обновления. По этой причине далее в этой статье я сфокусируюсь именно на реляционном присваивании. Кроме того, далее в статье я буду использовать (a) неуточненный термин присваивание в смысле реляционного присваивания и (b) неуточненный термин отношение в смысле значения отношения (за исключением, возможно, цитат из работ других авторов).
Возражения Критика A
Relvar и присваивание критикуются в длинном ряде сообщений Хью Дарвену от Критиков A и B [1]. Весь обмен сообщениями был вызван вопросом по теме, которая лишь отдаленно относится к обсуждаемой нами проблеме (и поэтому далее я буду игнорировать суть этой темы). В своем ответе на этот вопрос Критик A сказал следующее:♦♦
Мы с [Критиком B] не соглашаемся с relvar и думаем, что и Кодд не согласился бы.
Хью ответил:
Меня ставит в тупик ваше несогласие с relvar … Может быть, вы не согласны и с INSERT, DELETE, UPDATE и реляционным присваиванием? Кодд точно их признавал. Целевым операндом для всех этих операций является реляционная переменная (для краткости, relvar).
На это Критик A ответил:
Более точно, мы не согласны с явными relvar, и Кодд использовал «изменяемые во времени отношения», чтобы избежать этого понятия … Принимая во внимание, что одной из основных целей Кодда была простота, мы думаем, что он мог сознательно отказаться от введения понятия relvar. Очевидно, он был осведомлен о временном измерении баз данных, однако, насколько нам известно, он никогда не включал семантику изменения во времени в свою формальную модель. Если бы он это сделал, то язык множеств и математических отношений был бы деформирован, поскольку, как отмечает сам Дейт, у каждого объекта в языке имеется фиксированное значение. Поскольку связи внутри отношений Кодда и между ними вычисляются в фиксированной точке времени, становится возможным использование семантики множеств … Хотя концептуально «отношения, изменяемые во времени» Кодда должны быть в чем–то похожи на relvar, их «толкование» позволило Кодду придерживаться простых множеств (которые не могут изменяться) и при этом справляться с обновлениями … Возможно, существенным является то, что позже в своей статье про RM/T он называл insert-update-delete «правилами перехода» («transition rules»), а не операциями.
И в следующем электронном сообщений он (Критик A) продолжил:
Пожалуйста, обратите внимание, что не утверждается отсутствие relvar. Утверждается только то, что наличие их в явном виде в языке данных не является хорошей идеей, поскольку это порождает трудности из-за проблем с не фиксированными множествами. Трудно поверить, что Кодд не думал о переменных, и что он использовал термин «отношение, изменяемое во времени» необдуманным образом.
В этом месте я хотел бы вставить некоторые собственные подробные ответы на различные замечания Критика A. Для удобства ссылок я повторяю и переномеровываю эти замечания.
- Более точно, мы не согласны с явными relvar.
Как кажется, это утверждение означает, что Критик A соглашается с «неявными» relvar, какими бы они не были. Следовательно, похоже, что relvar плохи, только если они являются явными. Я не понимаю эту позицию.
- Кодд использовал «отношения, изменяемые во времени», чтобы избежать [явных переменных].
Это замечание можно интерпретировать двумя способами. Первая интерпретация: Кодд использовал понятие «отношений, изменяемых во времени», чтобы избежать потребности в понятии relvar (явных или каких-либо других). Если имелась в виду эта интерпретация, то мне хотелось бы точно знать, в чем состоит разница между этими двумя понятиями; наши критики утверждают, что это различие существует, но они никогда не говорят, в чем оно состоит.
Вторая интерпретация: Кодд использовал термин «отношение, изменяемое во времени», чтобы избежать потребности в использовании термина «relvar» (опять же явных или каких-либо других). Если имеется в виду эта интерпретация, то я просто ей не верю. Я работал с Коддом много лет, хорошо его знал и много раз обсуждал с ним именно этот вопрос. Хотя я не думаю, что полностью знаком с его позицией по этому поводу, могу с достаточной уверенностью заявить, что у него отсутствовали какие-либо скрытые намерения относительно использования термина «отношение, изменяемое во времени»; это был всего лишь используемый им термин, и я не думаю, что он придавал этому термину слишком большое значение.
Более детально (вопреки обеим приведенным выше возможным интерпретациям замечания Критика A), статьи [3-4], в которых Кодд впервые использовал данный термин, не содержат ни малейшего указания на то, что он ввел этот термин, чтобы избежать обсуждаемых переменных и/или обновлений. Напротив, в действительности, в обеих этих статьях он явно обсуждал вопрос реляционного обновления. Процитирую: «Вставки принимают форму добавления новых элементов к объявленным отношениям … Удаления … принимают форму удаления элементов из объявленных отношений». Более того (на случай, если вам непонятно, какой смысл вкладывал Кодд в термин объявленное отношение), и в [3], и в [4] явно говорилось, что объявленное отношение является именованным отношением (конечно, «изменяемым во времени»), которое (a) явно объявляется системе, (b) описывается в системном каталоге, (c) может обновляться (так что объявленное имя в разное время обозначает разные отношения – т.е. разные значения отношений), и (d) ссылки на него могут использоваться в запросах (и, вероятно, в ограничениях). По мне, это выглядит как relvar, причем явная relvar.
- Принимая во внимание, что одной из основных целей Кодда была простота, мы думаем, что он мог сознательно отказаться от введения понятия relvar.
Я не нахожу никаких доказательств в работах Кодда в пользу того, что он намеревался пойти на что-то подобное; на самом деле, я нахожу много доказательств в пользу обратного – не только в процитированных замечаниях про вставки, удаления и объявленные отношения, но и в многочисленных замечаниях из других его работ.
- Очевидно, он был осведомлен о временном измерении баз данных, однако, насколько нам известно, он никогда не включал семантику изменения во времени в свою формальную модель.
Если «семантика изменения во времени» означает всего-навсего то, что отношения Кодда, изменяющиеся во времени, изменяются во времени, то имеется очевидное доказательство (не только в самом используемом им термине) того, что он в действительности включал в свою модель такую семантику. В частности, он определенно включал «в свою формальную модель» реляционное присваивание; к этому моменту я еще вернусь позже.
- Если бы он это сделал, то язык множеств и математических отношений был бы деформирован, поскольку, как отмечает сам Дейт, у каждого объекта в языке имеется фиксированное значение.
Я не знаю, что это означает, а также не знаю, на какие мои работы здесь ссылаются.
- Поскольку связи внутри отношений Кодда и между ними вычисляются в фиксированной точке времени, становится возможным использование семантики множеств.
Фразы «семантика множеств» и «теоретико-множественная семантика» появляются в [1] неоднократно, но я плохо понимаю, что они означают. На основе других замечаний из [1] я могу догадываться, что имеется в виду нечто, включающее такие операции над множествами, как объединение и пересечение, но не включающее присваивание; но почему тогда нет речи про (например) «семантику арифметики», означающую нечто, включающее такие арифметические операции, как «+» и «*», но не включающее присваивание? (Я не буду повторять эти вопросы каждый раз при появлении непонятных фраз; пусть этому будет посвящен только один этот пункт.) В общем, я не думаю, что это замечание Критика A означает что-то иное, кроме того, что в каждый заданный момент времени значением relvar является отношение (тело которого, конечно, является множеством: а именно, множеством кортежей). Если имеется в виду именно это, то, конечно, я согласен, но я не могу считать этот факт очень существенным.
- Хотя концептуально «отношения, изменяемые во времени» Кодда должны быть в чем–то похожи на relvar, их «толкование» позволило Кодду придерживаться простых множеств (которые не могут изменяться) и при этом справляться с обновлениями.
Я согласен с ответом Хью на это замечание. Цитирую:
Хорошо, но кто-нибудь должен объяснить мне, в чем состоит разница [между relvar и «отношением, изменяемым во времени»] … Если кто-то ходит, как утка, плавает, как утка, летает, как утка, и крякает, как утка, то кто это на самом деле?
См. также мои собственные предыдущие комментарии на ту же тему. Замечание: Я мог бы добавить, что, на самом деле, я не понимаю, что здесь означает и термин «толкование» («gloss»), но, видимо, это не важно.
- Возможно, существенным является то, что позже в своей статье про RM/T он называл insert-update-delete «правилами перехода» («transition rules»), а не операциями.
Нет, он этого не делал. На самом деле, он говорил следующее [6]:
Все вставки в отношения, модификации отношений и удаления из отношений ограничиваются следующими двумя правилами [и он приступает к формулировке определений правил целостности сущности и ссылок. Затем он явно утверждает, что реляционная модель включает эти два правила, и называет их обобщенно] правилами insert-update-delete.
Отметим явное упоминание «вставок в отношения, модификаций отношений и удалений из отношений»! (Кстати, целевой объект таких операций в этой статье по-прежнему называется «отношением, изменяемым во времени».)
- Пожалуйста, обратите внимание, что не утверждается отсутствие relvar. Утверждается только то, что наличие их в явном виде в языке данных не является хорошей идеей, поскольку это порождает трудности из-за проблем с не фиксированными множествами.
Насколько я понимаю эти замечания (а я их понимаю не слишком хорошо), они выглядят всего лишь как протянутая мне рука. См. мой ответ на замечание Критика A no. 1.
- Трудно поверить, что Кодд не думал о переменных, и что он использовал термин «отношение, изменяемое во времени» необдуманным образом.
Нет, это не так. См. мои ответы на замечания Критика A no. 2 и 4.
Я уже цитировал часть ответа Хью на замечания Критика A. Далее в этом ответе говорится:
Я думаю, что «реляционное присваивание» является термином Кодда и одним из его двенадцати правил … Описания Кодда присваивания, вставки, модификации и удаления, приведенные на стр. 87-94 книги о RM/V2, выглядят неотличимыми от Tutorial D ...
Да, я могу подтвердить, что Кодд использовал термин реляционное присваивание в «книге о RM/V2» [8], хотя, на самом деле, не в статье о «двенадцати правилах» [7]. (Одно из этих правил действительно относится к INSERT, DELETE и UPDATE, но нет правила, относящегося к присваиванию как таковому.) Но он определенно включил понятие присваивания и явный синтаксис для этого понятия в существенно более ранние работы – в статью про RM/T (которая появилась в 1979 г.), а может быть, в еще более ранние публикации.
Отклоняясь от темы, я должен сказать, что совсем не очевидно то, что средства RM/V2 в этой области являются «неотличимыми от средств Tutorial D» (и на самом деле, это не так; например, в RM/V2 выполнение некоторых операций удаления приводит к появлению в базе данных неопределенных значений, и в то же время не поддерживается множественное присваивание). Более того, в тексте книги о RM/V2 на стр. 87-94 содержится много материала, не имеющего непосредственного отношения к семантике операций, включая многие детали, вообще не относящиеся к абстрактной модели – например, «Когда СУБД запрещает вставку строк (чтобы избежать появления в результате дублирующих строк), включается индикатор строк-дубликатов)»; «Если для целевого отношения существуют один или несколько индексов, то СУБД будет автоматически обновлять эти индексы для поддержки вставленных строк» и т.д. Имеется также несколько предписаний, непосредственно конфликтующих с Третьим Манифестом – например, «Домен любого столбца T, в котором значения порождаются посредством функции, определяются [в каталоге] как порождаемые функцией (function-derived), поскольку СУБД обычно не может быть более конкретной»; «Реляционная модель включает в некоторые манипуляционные операции опцию каскадирования (cascading option)♦♦♦ и т.д. При всем этом я, конечно, согласен с Хью в том, что общие функциональные возможности, определяемые в этой части книги про RM/V2, по существу, аналогичны соответствующим возможностям Tutorial D.
В дополнение ко всему сказанному выше замечу, что еще в 1971 г. Кодд предлагал явную поддержку INSERT, DELETE и UPDATE (хотя и не присваивания как такового; я имею в виду его статью про «Подъязык данных ALPHA» [5], в которой 12 примеров (из 32-х, т.е. почти 40%) являлись примерами операций обновления.
Возражения Критика B
После обсуждавшегося выше обмена сообщениями между Критиком A и Хью к переписке подключился Критик B (по сути дела, принявший дела у Критика A, который в переписке больше не участвовал). В своем первом сообщении, помимо прочего, Критик B сказал следующее:
Объединение теоретико-множественного языка (в котором имеется только операция эквивалентности) и вычислительного языка (в котором имеются как операция присваивания, так и операция эквивалентности) приводит к путаной семантике, которую ни Хью, ни Крис не обсуждали и даже не подтверждали. Кроме того, как кажется, к Третьему Манифесту не применялись какие-либо результаты из обширной литературы, посвященной неразрешимости и неполноте.
Да, действительно в Третьем Манифесте предписываются, а в Tutorial D (подобно любому известному мне императивному языку) поддерживаются «как операция присваивания, так и операция эквивалентности». На самом деле, в Манифесте предписываются, а в Tutorial D поддерживаются три следующие операции:
• Логическая эквивалентность: Если p и q – предикаты, то эквивалентность (p) EQUIV (q) – используется не реальный синтаксис Tutorial D – это также предикат, при вычислении которого получается TRUE в том и только в том случае, когда при вычислении p и q получается одно и то же истинностное значение.
• Равенство значений «=»: Значения v1 и v2 являются равными в том и только в том случае, когда они являются одним и тем же значением.
• Присваивание «:=» (реляционное или иное): Присваивание приводит к тому, что заданное значение v присваивается заданной переменной V (требуется, чтобы после этого результатом сравнения V = v было TRUE).
Я хотел бы особенно тщательно разъяснить сравнение значений, потому что некоторые дальнейшие замечания Критика B наводят на мысль о наличии некоторого разрыва в коммуникации в этой области. Как я уже говорил, значения v1 и v2 являются равными в том и только в том случае, когда они являются одним и тем же значением (и я замечу мимоходом, что для этого понятия вместо термина равенство можно было бы разумным образом использовать слово тождество (identity)). Наша позиция, отраженная в Манифесте, состоит в том, что любое значение – например, целое число 3 – существует (a) всегда и (b) в точности одно во вселенной (и всегда существовало), но одновременно может существовать много различных местонахождений (occurrence), или проявлений (appearance) этого значения, во многих разных местах. И если в двух таких «местах» в одно и то же время содержатся проявления одного и того же значения, то сравнение этих двух «мест» в этот момент времени на равенство выдаст TRUE (они «уподобятся равным»).♦♦♦♦ Вот некоторый текст из [10], проясняющий общую ситуацию:
<цитата>
Заметим, что имеется логическое различие между значением как таковым и проявлением этого значения – например, проявлением в качестве текущего значения некоторой переменной или значения некоторого атрибута внутри текущего значения некоторой relvar. Каждое такое проявление внутренне состоит из некоторого физического представления данного значения (и у различных проявлений одного и того же значения могут иметься разные физические представления). Таким образом, также имеется логическое различие между проявлением значения, с одной стороны, и физическим представлением этого проявления, с другой стороны; может иметься даже логическое различие между физическими представлениями, используемыми для различных проявлений одного и того же значения. Однако при всем этом обычно вместо оборота физическое представление проявления значения используется сокращенная форма проявление значения, или (чаще) просто значение, если это не приводит к двусмысленности. Заметим, что проявление значения является модельным понятием, а физическое представление проявления является понятием реализационным – например, пользователям, конечно, могло бы понадобиться знать, содержат ли две переменные проявления одного и того же значения, но им не нужно знать, используется ли в этих проявлениях одно и то же физическое представление.
Пример: Пусть N1 и N2 – это переменные типа INTEGER. Тогда после следующих присваиваний и N1, и N2 будут содержать проявление целого значения 3. Соответствующие физические представления могут быть, а могут и не быть одинаковыми (например, для N1 могло бы использоваться двоичное представление, а для N2 – упакованное десятичное представление), но это никак не затрагивает пользователя.
N1 := 3 ;
N2 := 3 ;
</цитата>
Есть ли что-нибудь неправильное в представленной выше ситуации? Замечание: Если (как это говорится в следующем утверждении Критика B) ответ на этот вопрос состоит в том, что такой подход приводит к неразрешимости, то я уже занимался этой проблемой в двух сопутствующих статьях [11-12] и не хотел бы больше ее здесь обсуждать. Но на основе приведенной выдержки из сообщений Критика B я не могу точно заключить, что имелась в виду именно эта проблема.
Мне также хотелось бы знать, в чем состоит «путаность» семантики Tutorial D. Хью задавал тот же вопрос:
Пожалуйста, покажите на конкретных примерах на Tutorial D, где наша семантика является «путаной». Пожалуйста, объясните также, что, по Вашему мнению, делает семантику путаной. Я понимаю под этим недетерминированность (обнаруживаемую, например, в SQL), но я полагаю, что у нас ее нет.
Насколько мне известно, Критик B так и не дал явного ответа на эти вопросы, если не считать следующего:
Ваша просьба, чтобы разъяснил ошибки Tutorial D на основе примеров, представленных на Tutorial D, является абсурдной! Ни на каком языке вы не можете привести примеры того, что этот язык НЕ позволяет делать!
Я вернусь к этим замечаниям Критика B немного позже.
Так или иначе, Хью написал пространный ответ на протест Критика B. Вот выдержка из этого ответа:
<цитата>
Если в языке баз данных отсутствуют именованные relvar, то как в нем выражаются обновления и ограничения? И как выражаются запросы? … Ответы должны сопровождаться примерами, представленными в некотором конкретном синтаксисе. Это требование является обязательным, и я мог бы не реагировать на ответ, в котором не предпринимается попытка выполнить это требование. Синтаксис должен основываться (там, где это уместно) на реляционной алгебре …
У нас имеется присваивание, чтобы базу данных можно было обновлять. В контексте баз данных достаточно иметь только реляционное присваивание, поскольку в базе данных допускаются только переменные отношений … В предложении избавиться от переменных отношений необходимо показать две очень важные вещи: во-первых (и это самое главное), альтернативный способ обновления базы данных; во-вторых, преимущества этого альтернативного способа над присваиваниями relvar.
</цитата>
Критик B снова вступил в перепалку:
<цитата>
Для ясности: я НЕ предлагал избавиться от понятия переменных отношений как таковых …
Ваш вопрос затрагивает суть огромного различия в семантике теоретико-множественных и вычислительных языков … Теоретико-множественным аналогом семантики «обновления» являются два множества (например, {A} и {B}), соединенные правилом «преобразования множеств», или «перехода». С семантической точки зрения, это ОЧЕНЬ отличается от того, что {A} становится {B} путем выполнения некоторой операции обновления, поскольку – в теоретико-множественных языках – {B} не заменяет {A}, и поэтому нет никакого присваивания значений некоторой переменной. Вместо этого оба множества всегда существуют и связываются некоторым известным образом.
Проблема, порождаемая объединением семантики теоретико-множественного и вычислительного языков некоторым полностью неопределенным образом, делает Третий Манифест настолько же дефектным, насколько дефектен SQL по причине наличия проблемы неопределенных значений!
Ваша просьба, чтобы я разъяснил ошибки Tutorial D на основе примеров, представленных на Tutorial D, является абсурдной! Ни на каком языке вы не можете привести примеры того, что этот язык НЕ позволяет делать!
Я не знаю, как в Tutorial D интерпретировать «эквивалентность» – иногда, как кажется, вам требуется теоретико-множественное понятие (т.е. установление тождественности), а иногда – вычислительное понятие (установление эквивалентности значений). Если отказаться от первого понятия, то как в Tutorial D будет поддерживаться вывод? А если не отказываться, то как согласовать это с присваиванием, являющимся чуждым для теоретико-множественной семантики, в которой отсутствует понятие переменной?
</цитата>
На все это у меня имеются собственные подробные ответы:
- Для ясности: я НЕ предлагал избавиться от понятия переменных отношений как таковых.
Это утверждение кажется родственным замечанию Критика A о том, что (по-видимому) явные relvar являются плохими, а с неявными relvar все в порядке. Я по-прежнему не могу понять, о чем здесь говорится.
- Ваш вопрос затрагивает суть огромного различия в семантике теоретико-множественных и вычислительных языков.
Я полагаю, что имеется в виду вопрос, в котором Хью спрашивал, как выполнять обновления без поддержки relvar; в противном случае я не понимаю это предложение.
- Теоретико-множественным аналогом семантики «обновления» являются два множества (например, {A} и {B}), соединенные правилом «преобразования множеств», или «перехода».
Замечу, что Критик A также ссылался на правила перехода (хотя его ссылка была неправильной).
- С семантической точки зрения, это ОЧЕНЬ отличается от того, что {A} становится {B} путем выполнения некоторой операции обновления, поскольку – в теоретико-множественных языках – {B} не заменяет {A}, и поэтому нет никакого присваивания значений некоторой переменной. Вместо этого оба множества всегда существуют и связываются некоторым известным образом.
Во-первых, в Третьем Манифесте никогда не используется оборот «одно множество становится другим»; в нем говорится о переменной, у которой имеется одно значение в один момент времени и другое значение в другой момент. Во-вторых, в Манифесте никогда не говорится, что одно множество заменяет другое; поскольку все значения «существуют всегда», «всегда существуют» и все множества (в действительности, множества являются значениями). Однако в Манифесте действительно говорится об обновлении переменной, когда проявление одного значения (в этой переменной) заменяется проявлением другого значения. На самом деле, мы очень стремились добиться в Манифесте четкости в изложении этих аспектов – в частности, четкости в проведении логического различия между значением как таковым и проявлением этого значения в некотором контексте, что я и пытался разъяснить несколькими страницами выше. Меня искренне расстраивает такое полное непонимание. В целом, в этих двух предложениях Критик B пытается смутно сформулировать то, что формулируется в Манифесте предельно четко.
- Проблема, порождаемая объединением семантики теоретико-множественного и вычислительного языков некоторым полностью неопределенным образом, делает Третий Манифест настолько же дефектным, насколько дефектен SQL по причине наличия проблемы неопределенных значений!
Что это в Третьем Манифесте является «полностью неопределенным»? Вот в приведенном замечании неопределенным является смысл «семантики вычислительных языков» – не говоря уже про «теоретико-множественную семантику», понятие, которое я уже комментировал. Кроме того, что означает фраза «настолько же дефектным, насколько дефектен SQL по причине наличия проблемы неопределенных значений»? Неопределенные значения ведут к появлению многозначной логики, которая в большинстве авторитетных источников признается ужасной проблемой; но мне неизвестно, каким образом настойчивое требование Манифеста наличия «семантики вычислительных языков» порождает потребность отхода от традиционной двухзначной логики. Так что ссылка на неопределенные значения – это всего лишь отвлекающий маневр, а утверждение о том, что Манифест «настолько же дефектен, насколько дефектен SQL по причине наличия проблемы неопределенных значений» похоже на сравнение яблок с апельсинами.
Замечание, добавленное позже: Мне пришло на ум, что фраза «проблема, порождаемая объединением семантики теоретико-множественного и вычислительного языков» может относиться к тому, что мы категорически запрещаем: к возможности присваивания некоторой переменной нового значения в процессе вычисления некоторого выражения, включающего эту переменную. Мы согласны, что допущение такой возможности может привести к вредным последствиям (хотя в некоторых языках она допускается). По этой причине от любого языка, соответствующего Третьему Манифесту, требуется, помимо прочего, удовлетворение следующим предписаниям (и, конечно, Tutorial D удовлетворяет этим предписаниям):
- С синтаксической точки зрения, никакое присваивание не является выражением; в более общем смысле, никакой вызов операции обновления не является выражением.
- Следовательно, с синтаксической точки зрения, никакое выражение (в частности, никакое реляционное выражение) не может включать присваивание или, в более общем смысле, вызовов операции обновления любого вида.
- В отличие от этого, выражение (в частности, реляционное выражение) может включать вызов операции только чтения. Однако сам такой вызов, по сути, является всего лишь сокращенной формой другого выражения; поэтому, по определению, он не включает присваиваний и вызовов операций обновления какого-либо вида.♦♦♦♦♦
Из всего этого следует, что если заданное реляционное выражение exp включает какие-либо ссылки на некоторую relvar R, то в ходе вычисления exp все эти ссылки обозначают одно и то же: отношение r, являющееся значением R перед началом вычисления exp.
- Ваша просьба, чтобы разъяснил ошибки Tutorial D на основе примеров, представленных на Tutorial D, является абсурдной! Ни на каком языке вы не можете привести примеры того, что этот язык НЕ позволяет делать!
Я думаю, что речь идет о том (см. [11-12]), что в Tutorial D допускаются выражения, которые невозможно вычислить. Если это так, то должна иметься возможность привести пример такого выражения. Я согласен, что это может быть трудно сделать – в том смысле, что может получиться очень сложное выражение, – но Критик B говорит, что это невозможно. Так что, по-видимому, имеется в виду что-то другое, являющееся «неправильным» в Tutorial D. Скорее всего, это именно так, поскольку далее Критик B упоминает нечто такое, что язык «НЕ позволяет делать», а как раз формулировать выражения, которые невозможно вычислить, он позволяет (по крайней мере, по мнению Критика B).
Теперь, после всего сказанного, мне хотелось бы знать, почему аналогичные критические замечания не предъявлялись к оригинальным статьям Кодда [3-4] или его языку ALPHA [5]? И если я прав в том, что подобные замечания применимы к работами Кодда, то мне хотелось бы увидеть язык, к которому они не применимы.
- Я не знаю, как в Tutorial D интерпретировать «эквивалентность» – иногда, как кажется, вам требуется теоретико-множественное понятие (т.е. установление тождественности), а иногда – вычислительное понятие (установление эквивалентности значений). Если отказаться от первого понятия, то как в Tutorial D будет поддерживаться вывод? А если не отказываться, то как согласовать это с присваиванием, являющимся чуждым для теоретико-множественной семантики, в которой отсутствует понятие переменной?
Боюсь, что я далек от полного понимания этих замечаний. Я думаю, что Критик B называет здесь «установлением тождественности» то, что мы называем равенством. Я думаю, что Критик B называет здесь «установлением эквивалентности значений» то, что я ранее упоминал (в сноске) под условным названием «равенства проявлений». Я уже пытался пояснить эти конструкции (а именно, равенство и «равенство проявлений») и полагаю, что в Манифесте совершенно явно написано, когда и где они используются, и в чем состоит их семантика. Что касается «поддержки вывода [в Манифесте]», то я думаю, что Критик B имеет здесь в виду процесс определения значения реляционного выражения (в частности, процесс формирования ответа на запрос). Если это действительно так, в Манифесте то этот процесс описан совершенно явным образом.
Более того, я не вижу, в каком качестве на этой картине фигурируют присваивание и «понятие переменной», поскольку – как я постараюсь пояснить немного позже – ни то, ни другое не играет никакой роли в этом процессе.
В одном из последующих сообщений Критик B говорит следующее:
Мое пожелание состоит не в том, чтобы ввести язык баз данных без имен переменных и т.д., а в том, чтобы в Tutorial D явным образом разделялась теоретико-множественная и вычислительная семантика. Вы стремитесь к единому языку с обоими видами семантики, а я не уверен, что это возможно хотя бы потому, что (например) эквивалентность истинностных значений отличается от эквивалентности кардинальных и ординальных значений.
Как я говорил ранее, в Tutorial D имеется логическая эквивалентность (которая, возможно, является тем же самым, что Критик B называет здесь эквивалентностью истинностных значений), а также равенство значений♦♦♦♦♦♦, а также присваивание (которое ранее Критик B также выдвигал в качестве некоторой разновидности эквивалентности). Теперь он говорит еще и об «эквивалентности кардинальных и ординальных значений». Я не знаю, относится ли эта эквивалентность к одному из трех видов, поддерживаемых в Tutorial D; я не знаю, один или два вида эквивалентности соответствуют «эквивалентности кардинальных и ординальных значений»; я даже не знаю, положительно или отрицательно оценивает поддержку в Tutorial D (если она имеется) этого вида (или этих видов) эквивалентности. Так или иначе, Хью ответил следующее:
Я объяснил, что мы имеем в виду под «равенством», в ответ на несколько Ваших утверждений, показывающих, что Вас беспокоит наличие к нас двух разных видов. (Я не понимаю оба этих вида, но наша единственная разновидность равенства – это, по-видимому, именно то, наличие чего Вы желаете. См. RM-предписание 8.)
Здесь Хью называет «нашим единственным видом» именно равенство значений, семантика которого точно определена в RM-предписании 8 Третьего Манифеста. На это Критик B ответил следующим образом:
Я осознаю Ваше непонимание того, что имеются два вида «равенства» (на самом деле, много видов) … В лучшем случае, я могу предположить, что в разговорах про Tutorial D у Вас блокируется способность к мышлению в чисто теоретико-множественном духе. Позвольте мне просто сказать, что эквивалентность значений – это не то же самое, что тождественность. Значение имеет отношение к сравнению измерений количественных свойств, в то время как тождественность относится к тому, что математики часто называют сущностями («вещами»).
Хорошо, я вынужден повторить некоторые вещи, которые уже говорил (и я приношу извинения за многословность) … но эти замечания заставляют меня заподозрить, что Критик B не понял, какой смысл вкладывается в Третьем Манифесте в термин значение. Я также подозреваю, что он называет «эквивалентностью значений» то, что мы имеем в виду, говоря про равенство различных проявлений одного и того же значения (а в этом случае мы сказали бы, что – по определению – имеется только одно значение как таковое). Еще я подозреваю, что это его непонимание (нашего использования терминов) приводит его к необоснованной критике. Я также думаю, в противоположность тому, что говорит здесь Критик B, что наша «эквивалентность значений» (раньше я использовал термин «равенство значений») является «тем же самым, что и тождественность»: два проявления являются равными («равными по значению»?) тогда и только тогда, когда они являются проявлениями тождественных значений. Теперь насчет того, что имеется много видов равенства: Может быть, действительно можно определить много видов равенства (на самом деле, я не знаю этого), но я думаю, что важным является то, которое мы определяем в RM-предписании 8 – и именно к этому виду сравнения мы обращаемся (явно или неявно), когда говорим о равенстве в контексте Третьего Манифеста.
В этом же сообщении Критик B также сказал следующее:
Я не определяю, как, по моему мнению, должны выражаться обновления базы данных, за исключением того, что мы можем безопасно использовать теоретико-множественное представление, для которого имеются и «канонический» метод, и «каноническая» семантика. Я возражаю против присваивания, поскольку считаю его чуждым теоретико-множественному представлению и заимствованному из «семантики ‘до и после’», являющейся в своей основе процедурной.
Мои ответы:
- Я не определяю, как, по моему мнению, должны выражаться обновления базы данных.
Как я говорил раньше (цитируя Хью), в предложении по отказу от переменных отношений должны демонстрироваться две важные вещи: во-первых (и это наиболее важно), альтернативный способ обновления базы данных; во-вторых, преимущества этого альтернативного способа над присваиваниями relvar. Меня просто расстраивает, когда нам говорят снова и снова, что наш подход не работает – в особенности, когда при этом явным образом не говорят, почему он не работает; в особенности, когда, по существу, тот же самый подход поддерживается во всех императивных языках с момента появления языков программирования, – и в то же время не предлагают никакого альтернативного подхода, который бы работал.
- Мы можем безопасно использовать теоретико-множественное представление, для которого имеются и «канонический» метод, и «каноническая» семантика.
Мне неясен смысл этих наблюдений.
- Я возражаю против присваивания, поскольку считаю его чуждым теоретико-множественному представлению и заимствованному из «семантики ‘до и после’», являющейся в своей основе процедурной.
Предположим в целях дискуссии, что (a) в теории множеств действительно нет понятия присваивания, и (b) имеется потребность в обновлениях. (Со своей стороны я не испытываю трудностей в принятии этих предположений.) Тогда очевидным выводом является не врожденная дефектность присваивания; скорее, можно счесть, что сама теория множеств не подходит в качестве теоретической основы языков программирования баз данных. Однако Критик B утверждает, что присваивание и теория множеств (или «теоретико-множественное представление») не согласуются друг с другом – т.е. они действительно конфликтуют, и если мы поддерживаем одно из них, то не можем поддерживать другое. Если это утверждение истинно, то тем хуже для теории множеств; но, честно говоря, я не вижу причин, по которым это может быть правдой. Замечание: замените в приведенных выше замечаниях «теорию множеств» на «логику», и я подпишусь и под этой формой своего заключительного довода.
Более того, понятие «семантики ‘до и после’» на самом деле подразумевается наличием присваивания. Однако более важно то, что она подразумевается тем, как работает время в нашей вселенной – лучше сказать, порождается основными свойствами времени! (Я думаю, что и «врожденная процедурность» порождается свойствами времени в нашей вселенной, если мы согласимся, что «процедурность» означает всего лишь выполнение одного действия за другим, последовательно; однако здесь проблема состоит в том, что ярлык «процедурности» обычно применяется в смысле «низкоуровневой процедурности» и поэтому почти всегда используется с уничижительным оттенком.) Если теория множеств не может справиться с «семантикой ‘до и после’», то тем хуже для теории множеств. Замечание: замените в приведенных выше замечаниях «теорию множеств» на «логику», и я подпишусь и под этой формой своего заключительного довода.
Множественное присваивание
В Третьем Манифесте предписывается не только присваивание, но и то, что называется в нем множественным присваиванием. Множественное присваивание – это операция, которая позволяет «одновременно» выполнить несколько индивидуальных присваиваний без какой-либо проверки целостности до конца выполнения всех индивидуальных присваиваний. Например, показанная ниже операция «двойного DELETE» с логической точки зрения является множественным присваиванием:
DELETE S WHERE S# = S#('S1') ,
DELETE SP WHERE S# = S#('S1') ;
Обратите внимание на запятую после первой операции DELETE, синтаксически указывающую, что это еще не конец всего оператора.
В [1] поднимает несколько вопросов относительно множественного присваивания. Вот соответствующая цитата:
Я не понимаю, как вы собираетесь реализовывать множественное присваивание. Если имеется, например, пять индивидуальных присваиваний, то они будут выполняться в заданном порядке сверху вниз, или же этот порядок произволен, или же считается, что они будут выполняться в параллель? Ваш алгоритм перезаписи для устранения нескольких ссылок на одну и ту же переменную порождает больше проблем, чем разрешает. В лучшем случае, можно было бы предположить, что между индивидуальными присваиваниями отсутствуют побочные эффекты, так что порядок не имеет значения. Но если принять это предположение, то, очевидно, будут существовать некоторые упорядоченные множества присваиваний (обычно оформляемые в виде транзакций), которые невозможно переписать в виде множественного присваивания, поскольку это приведет к результату, отличному от ожидаемого … Мне нравится идея множественного присваивания, но не за счет отказа от транзакций и, следовательно, не за счет отказа от отложенной проверки ограничений.
Мои подробные ответы:
- Я не понимаю, как вы собираетесь реализовывать множественное присваивание.
Мы полагаем, что оно будет реализовываться в соответствии с определением. Семантика операции определяется в Третьем Манифесте [14] и в отдельной статье [13].
- Если имеется, например, пять индивидуальных присваиваний, то они будут выполняться в заданном порядке сверху вниз, или же этот порядок произволен, или же считается, что они будут выполняться в параллель?
Полный ответ на этот вопрос содержится в [13] и [14]. При небольшом упрощении основная идея состоит в том, что (a) вычисляются выражения из правых частей индивидуальных присваиваний (в произвольном порядке, поскольку порядок не является существенным), а затем (b) выполняются присваивания переменным из левых частей в том порядке, в каком они написаны.
- Ваш алгоритм перезаписи для устранения нескольких ссылок на одну и ту же переменную порождает больше проблем, чем разрешает.
Работы [13] и [14] действительно включают некоторый «алгоритм перезаписи» для объединения – не устранения! – «нескольких ссылок на одну и ту же переменную». Если этот алгоритм действительно порождает «больше проблем, чем разрешает», было бы полезно привести конкретные черты этих проблем.
- В лучшем случае, можно было бы предположить, что между индивидуальными присваиваниями отсутствуют побочные эффекты, так что порядок не имеет значения.
Фраза «можно было бы предположить» здесь, по-видимому, относится к алгоритму перезаписи. В этом алгоритме, конечно, не предполагается, что «между индивидуальными присваиваниями отсутствуют побочные эффекты». На самом деле, все наоборот: основная суть алгоритма состоит в том, чтобы точно соблюсти действие побочных эффектов, а не в том, чтобы их утратить.
- Если принять это предположение, то, очевидно, будут существовать некоторые упорядоченные множества присваиваний (обычно оформляемые в виде транзакций), которые невозможно переписать в виде множественного присваивания, поскольку это приведет к результату, отличному от ожидаемого …
Я не могу слегка не упрекнуть Критика B за его использование фразы «упорядоченные множества» … Однако более важно то, что мы хотели бы увидеть пример последовательности присваиваний, которую было бы нельзя переписать в виде множественного присваивания. Очевидно, что можно было бы попытаться написать что-то вроде следующего:
X := x ;
Y := f(X) ;
Но следующее множественное присваивание приведет к тому же ожидаемому результату:
X := x ,
Y := f(x) ;
- Мне нравится идея множественного присваивания, но не за счет отказа от транзакций и, следовательно, не за счет отказа от отложенной проверки ограничений.
Нам тоже нравится множественное присваивание; на самом деле, мы считаем эту операцию абсолютно обязательной. Однако обратите внимание, что мы не предлагаем ее в качестве замены транзакций. В [1] Хью говорит следующее (и я согласен с этими замечаниями):
Я полагаю, что теоретически можно было бы обойтись без транзакций, но предпочитаю их сохранить по соображениям удобства. Я знаю людей, которые не согласны со мной по этому поводу и предпочли бы вовсе избавиться от транзакций. Я отвечаю им, соглашаясь, что это было бы хорошо, но отмечая, что для этого нужны конкретные языковые конструкции, обеспечивающие те же удобства, что и транзакции.
Значения и переменные базы данных
Вопреки всему, что я говорил в статье до сих пор, в некотором смысле relvar и реляционное присваивание являются ошибкой, что я и постараюсь сейчас объяснить.
Мы стремимся к тому, чтобы иметь возможность обновлять базу данных. Ранее я говорил, что «обновляемость» и «возможность присваивания» означают одно и то же; я также говорил, что присваивать можно только переменной, и для каждой переменной имеется возможность присваивания. Не следует ли из этих замечаний, что и база данных является переменной? И поскольку понятие переменных, содержащих переменные, является логически абсурдным, следует ли из этого, что база данных, будучи переменной, не может содержать переменные отношений?
В действительности, на оба вопроса я отвечаю да. База данных является переменной, и она не может содержать другие, вложенные в нее переменные (ни переменные отношений, ни какие-либо другие). Вот выдержка из Приложения D к [14]:
В первом варианте Третьего Манифеста проводилось различие между значениями базы данных и переменными базы данных, аналогичное различию между значениями и переменными отношений. Вводился термин dbvar как сокращенная форма от database variable. В дальнейшем, хотя мы по-прежнему полагали, что это различие является обоснованным, мы сочли, что оно не слишком существенно для других аспектов Манифеста. Поэтому для поддержки дружеских отношений с миром баз данных мы решили вернуться к более традиционной терминологии.
После некоторой конкретизации этих замечаний в Приложении D к [14] говорится следующее:
Теперь мы отказываемся от этого плохого решения! Оглядываясь в прошлое, мы видим, что нужно было «стиснуть зубы» и использовать более корректные с точки зрения логики термины значение базы данных и переменная базы данных (или dbvar), несмотря на подрыв дружеских отношений.
И далее демонстрируется, что (a) переменная базы данных – это в действительности кортежная переменная с одним атрибутом (со значениями-отношениями) для каждой «переменной отношения», содержащейся в этой переменной базы данных; (b) переменные отношений в действительности являются псевдопеременными, позволяющими операциям обновления «затирать» («zap») индивидуальные компоненты объемлющей переменной базы данных. В [1] Хью говорит следующее:
Мы с Крисом обдумывали идею представления базы данных в виде единственной переменной, [но] не могли придумать удобный синтаксис для необычных видов … обновления, которые ожидались (присваивание всей базе данных для каждого требуемого обновления считалось невообразимым). Мы смогли добиться удобного синтаксиса только путем разделения базы данных на именованные «части», которые назвали переменными отношений.
Я упоминаю об этом только для полноты и для отражения возможных нападок на нашу позицию со стороны некоторых читателей. Хотя база данных в действительности является переменной, а relvar – это в действительности псевдопеременные, по моему убеждению, это ни коим образом не делает недействительными все аргументы, приведенные мною ранее в этой статье.
Заключительные замечания
Я хотел бы завершить статью парой наблюдений:
- Прежде всего (и это самое главное), позиция Критиков A и B по поводу relvar остается исключительно неясной. Как кажется, они считают понятие relvar дефектным по своей сути, но в то же время желают их сохранить, по крайней мере, «неявно» (?). Они также не могут объяснить, в чем состоит логическое различие между relvar как таковыми и «изменяемыми во времени отношениями».
- Верно, что некоторые языки программирования – конкретно, так называемые логические языки (например, Prolog) и функциональные языки (например, LISP) – умудряются существовать без присваивания: на самом деле, вообще без понятия «постоянной памяти» («persistent memory»). Однако, насколько мне известно, все такие языки «ловчат», когда требуется обновить базу данных; в действительности, они выполняют некоторую разновидность присваивания, возможно, в качестве побочного эффекта, хотя присваивание не является частью логического или функционального стиля.
Литература
1. Anon.: Private correspondence with Hugh Darwen (December 2005 - January 2006).
2. E. O. de Brock: "Tables, Table Variables, and Static Integrity Constraints." University of Technology, Eindhoven, Netherlands (1980).
3. E. F. Codd: "Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks," IBM Research Report RJ599 (August 19th, 1969).
4. E. F. Codd: "A Relational Model of Data for Large Shared Data Banks," CACM 13, No. 6 (June 1970). Republished in Milestones of Research—Selected Papers 1958-1982 (CACM 25th Anniversary Issue), CACM 26, No. 1 (January 1983). Есть русский перевод М.Р. Когаловского: Е.Ф. Кодд. Реляционная модель данных для больших совместно используемых банков данных, СУБД, N 1, 1995, http://old.osp.ru/dbms/1995/01/01.htm
5. E. F. Codd: "A Data Base Sublanguage Founded on the Relational Calculus," Proc. 1971 ACM SIGFIDET Workshop on Data Description, Access and Control, San Diego, Calif. (November 1971). (По поводу языка ALPHA можно также прочитать пересказ С.Д. Кузнецова двух статей Дейта: http://www.citforum.ru/database/digest/data_sub_alpha.shtml и http://www.citforum.ru/database/digest/ie990903.shtml.)
6. E. F. Codd: "Extending the Database Relational Model to Capture More Meaning," ACM TODS 4, No. 4 (December 1979). Есть русский перевод М.Р. Когаловского: Е.Ф. Кодд. Расширение реляционной модели для лучшего отражения семантики. СУБД, N 5, 1996, http://old.osp.ru/dbms/1996/05/163.htm
7. E. F. Codd: "Is Your DBMS Really Relational?" (Computerworld, October 14th, 1985); "Does Your DBMS Run By The Rules?" (Computerworld, October 21st, 1985).
8. E. F. Codd: The Relational Model for Database Management Version 2. Reading, Mass.: Addison-Wesley (1990).
9. Hugh Darwen and C. J. Date: The Third Manifesto. ACM SIGMOD Record 24, No. 1 (March 1995). Есть русский перевод М.Р. Когаловского: Х. Дарвин и К. Дэйт. Третий манифест. СУБД, N 1, 1996, http://old.osp.ru/dbms/1996/01/23.htm
10. C. J. Date: The Relational Database Dictionary. Sebastopol, Calif.: O'Reilly Media Inc. (2006, to appear).
11. C. J. Date: "Gödel, Russell, Codd: A Recursive Golden Crowd," www.thethirdmanifesto.com (July 2006). Имеется перевод на русский язык С.Д. Кузнецова: К. Дж. Дейт. Гедель, Рассел, Кодд: Рекурсивная золотая чехарда
12. C. J. Date: "And Now for Something Completely Computational," www.thethirdmanifesto.com (July 2006). Имеется перевод на русский язык С.Д. Кузнецова: К. Дж. Дейт. А теперь про нечто полностью вычислительное
13. C. J. Date and Hugh Darwen: "Multiple Assignment," www.dbdebunk.com (February 2004).
14. C. J. Date and Hugh Darwen: Databases, Types, and the Relational Model: The Third Manifesto (3rd edition). Reading, Mass.: Addison-Wesley (2006). (Второе издание книги опубликовано в переводе на русский язык: К. Дж. Дейт, Хью Дарвен. Основы будущих систем баз данных: третий манифест. Перевод под ред. С.Д.Кузнецова, Янус-К, 2004.)
* Logic, Logic, and Logic by George Boolos (Author), Richard Jeffrey (Introduction), John P. Burgess (Editor). Harvard University Press; Reprint edition, 1999. (Прим. переводчика)
♦ Следующие далее примеры и обсуждение взяты из [10].
♦♦ В целях придания большей ясности я отредактировал (иногда радикально) большую часть цитат, используемых в этой статье.
♦♦♦ В Третьем Манифесте не запрещаются «опции каскадирования», которые определяются декларативным образом, но Кодд утверждает здесь, что их можно было бы задавать в процедурном стиле.
♦♦♦♦ Так что мы могли бы сказать, что здесь имеется пример еще одной разновидности равенства, которую можно было бы назвать равенством проявлений. Однако в Манифесте такой термин не используется.
♦♦♦♦♦ Код, реализующий данную операцию только чтения всегда логически эквивалентен одиночному оператору RETURN, операнд которого формулируется в виде выражения. (Хотя такой реализационный код можно написать с применением обновления некоторых переменных, являющихся полностью локальными для рассматриваемой операции, такие обновления не приводят к возникновению длительных эффектов.) Таким образом, такая операция не может обновить что-либо в своей внешней среде; в частности, она не может обновить что-либо в базе данных.
♦♦♦♦♦♦ А также, возможно, и равенство проявлений.
|
 |
|
|
|
|
|
|
|
Новости мира IT:
- 25.07 - В России выросла популярность отечественных облачных хранилищ, хотя молодёжь предпочитает иностранные
- 25.07 - Microsoft добавила сгенерированные ИИ сводки в результаты поиска Bing
- 25.07 - Apple выпустила веб-версию своего картографического сервиса
- 23.07 - Google передумала отказываться от сторонних cookie в Chrome, но обещает повысить конфиденциальность
- 23.07 - Аудитория Telegram достигла 950 миллионов пользователей в месяц
- 23.07 - Alphabet провалила сделку по поглощению Wiz за $23 млрд — стартап счёл предложенные условия унизительными
- 23.07 - Intel признала вину в нестабильности Raptor Lake, но уже знает как всё исправить
- 18.07 - Еврокомиссия выяснит, не мешает ли конкурентам Samsung наличие ИИ-модели Gemini Nano в Galaxy S24
- 18.07 - Huawei будет внедрять искусственный интеллект в тяжёлое машиностроение
- 18.07 - В Китае создали сверхлёгкий дрон, который будет летать, пока светит Солнце
- 18.07 - Дефицит ИИ-чипов сохранится до 2026 года, прогнозируют в TSMC
- 18.07 - Google стала показывать меньше ответов ИИ в поиске после серии «странных» ответов
- 16.07 - Oppo и Ericsson подписали соглашение о перекрёстном лицензировании в сфере сетей 5G
- 16.07 - Акции Apple достигли исторического максимума благодаря ИИ
- 16.07 - Nvidia столкнулась с антимонопольным расследованием во Франции — компании грозит крупный штраф
- 16.07 - ИИ и глобальные амбиции: Аркадий Волож рассказал, чем займётся зарубежная часть «Яндекса» после разделения
- 16.07 - Разработку российской консоли оценили всего в 1 млрд рублей, но в целом денег понадобится куда больше
- 16.07 - Yandex закрыл сделку по продаже «Яндекса»
- 10.07 - Представлен релиз Firefox 128
- 10.07 - Доступна платформа OpenSilver 3.0, продолжающая развитие технологии Silverlight
Архив новостей

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
