Патологии больших данных
Адам Якобс
Перевод: Сергей Кузнецов
Оригинал: Adam Jacobs. The Pathologies of Big Data. ACM Queue, Volume 7 , Issue 6 (July 2009)
От переводчика
Так получилось, что к переводу этой статьи мне захотелось написать как что-то типа предисловия (которое нужно читать до статьи), так и нечто вроде критического послесловия (которое стоит читать только после статьи). В результате родилась отдельная заметка "О точности диагностики патологий".
Что же такое «большие данные»? Гигабайты? Терабайты? Петабайты? Чтобы понять это, вспомним недавнее прошлое. В конце 1980-х в Колумбийском университете у меня имелась возможность позабавиться с тем, что в то время представляло собой поистине огромный «диск»: IBM 3850 MSS (Mass Storage System). На самом деле, устройство MMS являлось полностью автоматической роботизированной ленточной библиотекой, к которой были подсоединены вспомогательные диски, обеспечивающие произвольный доступ к данным – не то чтобы мгновенный, но полностью прозрачный для пользователей. В конфигурации Колумбийского университета в MSS сохранялось около 100 гигабайт данных. К тому времени, когда я освоился с этой системой, она уже выводилась из использования, но в пору ее расцвета, в середине 1980-х, она применялась для поддержки доступа социологов к тому, что, несомненно, в то время являлось «большими данными» – базе данных переписи США [2].
По-видимому, в то время не было другого практически пригодного способа обеспечить исследователям простой доступ к настолько крупному набору данных. При стоимости около 40000 долларов на гигабайт дисковый пул объемом в 100 гигабайт стоил бы слишком дорого, а использование тысяч 40-мегабайтных магнитных лент, вручную устанавливаемых и снимаемых операторами, чрезвычайно замедлило бы ход выполнения исследований или, по крайней мере, серьезно ограничило бы виды запросов, которые можно было бы задавать по поводу данных переписи.
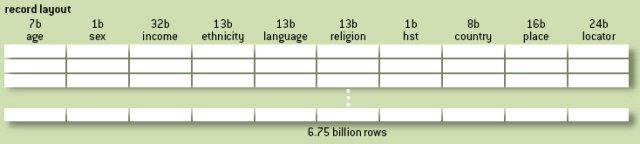
База данных объемом порядка 100 гигабайт не считается совсем небольшой даже сегодня, хотя дисковые накопители с возможностью сохранения в десять раз больше данных можно купить в любом компьютерном магазине дешевле, чем за 100 долларов. База данных переписи США включала много разных наборов данных различных размеров, но если немного упростить, оказывается, что 100 гигабайт достаточно для сохранения, по крайней мере, базовой демографической информации (данных о возрасте, поле, заработке, этнической принадлежности, языке, религии, жилищных условиях и месте проживания, упакованных в 128-битную запись) обо всех здравствующих жителях Земли. Для этого понадобилось бы создать таблицу с 6,75 миллиардами строк и, вероятно, с 10 столбцами. Следует ли по-прежнему считать это «большими данными»? Конечно, это зависит от того, что вы пытаетесь делать с этими данными. Несомненно, их можно сохранить в дисковой памяти стоимостью в 10 долларов. Но более важно то, что любой грамотный программист за несколько часов может написать простое, неоптимизированное приложение для персонального компьютера стоимостью в 500 долларов с минимальными ресурсами процессора и основной памяти, которое перерабатывает эти данные и с достаточно разумной производительностью возвращает ответы на простые агрегатные запросы типа «для каждой страны найти возрастную медиану1 ее жителей мужского и женского пола».
Чтобы это продемонстрировать, я попытался создать такое приложение, используя, конечно, фиктивные данные – файл из 6,75 миллиардов 16-байтовых записей, содержащий равномерно распределенные случайные данные (рис. 1). Поскольку в семибитном поле возраста может содержаться 128 разных значений, в однобитном поле пола – два значения (предполагается, что неопределенные значения отсутствуют), а в восьмибитном поле кода страны – 256 значений (в ООН состоит 192 государства), средний возраст можно вычислить с использованием стратегии пересчета: просто создать 65536 бакетов (по одному для каждой возможной комбинации возраста, пола и кода страны) и подсчитать, сколько записей попадает в каждый бакет. Для нахождения возрастной медианы для заданной комбинации пола и кода страны сначала подсчитывается общее число записей tot в соответствующих 128 бакетах, относящимся к возможным значениям возраста. Затем эти бакеты еще раз просматриваются в порядке увеличения возраста, подсчитывается общее число записей acc, и цикл завершается на том бакете, для которого acc оказывается не меньше tot/2. Тесты показали, что скорость выполнения этого алгоритма в основном ограничивается скоростью считывания данных с диска: немногим более 15 минут на один проход по данным при типичной скорости последовательного чтения в 90 мегабайт в секунду. Центральный процессор при этом все время постыдно недоиспользуется.
Чтобы найти возрастную медиану по странам и полу:
int age, sex, country; int cnt[2][256][128]; int tot,acc; byte r[16]; fill cnt with 0; do read 16 bytes into r; age = r[0] & 01111111b; sex = r[1] & 10000000b; ctry = r[11] & 11111111b; cnt[sex][ctry][age] += 1; until end of file;Затем:
for sex = 0 to 1 do
for ctry = 0 to 255 do
output ctry, sex;
tot = sum (cnt[sex][ctry][age]);
acc = 0;
for age = 0 to 127 do
acc += cnt[sex][ctry][age];
if(acc >= tot/2)
output age;
go to next ctry;
end if;
next age;
next ctry;
next sex;
Рис. 1. Вычисление возрастной медианы для жителей мужского и женского пола каждой страны мира за время, исчисляемое минутами
На самом деле, наша таблица "всех людей мира" поместится в основной памяти объемом в 128 гигабайт одного сервера Dell стоимостью в 15000 долларов. При работе с данными в основной памяти моя простая программа подсчета возрастной медианы по странам и полам выполнялась менее минуты. При таких показателях я бы усомнился называть эти данные "большими", учитывая, в частности, что мы живем в мире, в одном из исследовательских центров которого (LHC (Large Hadron Collider) в ЦЕРНе (CERN, European Organization for Nuclear Research)) преполагается ежегодно производить данные объемом в 15000 больше [10].
Однако для многих широко используемых приложений наш гипотетический набор данных из 6,75 миллиардов строк в действительности ставит серьезную проблему. Я пробовал загрузить свою фиктивную 100-гигабайтную всемирную перепись в широко используемую систему баз данных корпоративного уровня (PostgreSQL [6]), работающую на относительно мощной аппаратуре (восьмиядерная рабочая станция Mac Pro с 20 гигабайтами основной памяти и двухтерабайтным диском RAID 0), но был вынужден прервать процесс загрузки после шести часов работы, поскольку объем области хранения базы данных уже во много раз превышал объем исходного набора данных, и диск рабочей станции был почти полон. (Конечно, отчасти так получилось из-за "распаковки" данных. В исходном файле поля хранились упакованными с точностью до бита, а не как отдельные целые числа, но последующие тесты показали, что в базе данных использовалось в 3-4 раза больше внешней памяти, чем потребовалось бы для хранения каждого поля в виде 32-разрядного целого числа. Этот вид "раздувания" данных типичен для традиционных РСУБД, и его не обязательно следует считать проблемой, особенно в тех случаях, когда это является частью стратегии повышения производительности. В конце концов, дисковая память относительно дешева.)
Мне удалось успешно загрузить поднабор данных, состоящий из около миллиарда строк с всего тремя столбцами: код страны (8 бит, 256 возможных значений), возраст (7 бит, 128 возможных значений) и пол (1 бит, два значения). Объем этого поднабора составлял всего 2% от объема полных исходных данных, хотя СУБД для хранения базы данных использовала более 40 гигабайт дисковой памяти. Затем я попробовал выполнить следующий запрос, производящий, по сути, те же вычисления, что и верхняя часть программы с рис. 1:
SELECT country,age,sex,count(*) FROM people GROUP BY country,age,sex;
Этот запрос на небольших поднаборах данных выполнялся за считанные секунды, но время выполнения быстро выросло, когда число строк превысило один миллион (рис. 2). При применении ко всему миллиарду строк запрос выполнялся более 24 часов, что наводит на мысль о немасштабируемости PostgreSQL к этому "большому" набору данных, по-видимому, из-за плохого выбора алгоритма выполнения запроса на этих данных. Проблема прояснилась после вызова встроенного средства этой СУБД EXPLAIN: в то время как планировщик запросов для небольших таблиц выбирал разумную стратегию агрегации на основе хэширования таблицы, для более крупных таблиц он переключался на стратегию сортировки по столбцам группировки. Последняя стратегия близка к оптимальной при обработке нескольких миллионов строк, но очень плоха при наличии миллиарда строк. PostgreSQL отслеживает статистику, такую как минимальное и максимальное значения каждого столбца таблицы (и я проверял, что система правильно определяет диапазоны значений всех трех столбцов), так что она могла бы уверенно выбирать стратегию с хэшированием таблицы. Однако стоит отметить, что, даже если бы статистика не была известна, при наличии миллиона строк процедура определения распределений значений столбцов занимает гораздо меньше времени, чем сортировка всей таблицы.
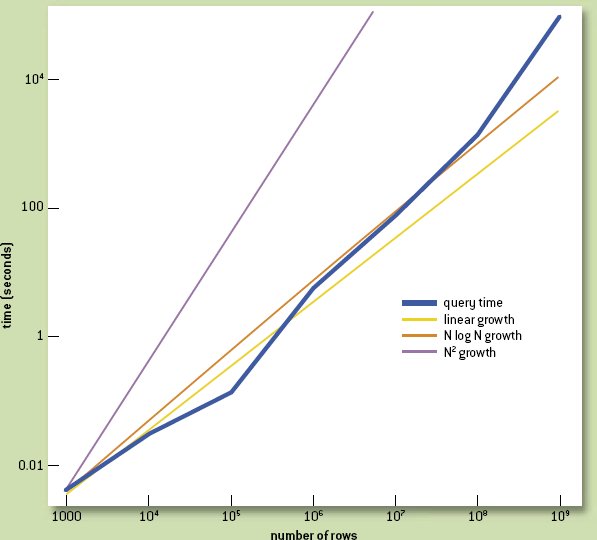
Замечание: Для сравнения показаны графики линейного, линейно-логиарифмического и квадратичного роста
Рис. 2. Производительность PostgreSQL на запросе SELECT country,age,sex,count(*)
FROM people GROUP BY country,age,sex
Здесь PostgreSQL испытывала трудности при анализе данных, а не при их хранении. Система не отказывалась загружать или поддерживать базу данных с миллиардом записей; по-видимому, не возникли бы какие-либо трудности с хранением всей десятиколоночной таблицы и 6,75 миллиардами строк, если бы у меня имелся достаточный объем дисковой памяти.
Вот большая правда о больших данных в традиционных базах данных: данные в них проще засунуть, чем из них вытащить. Большая часть СУБД разрабатывается для эффективной обработки транзакций: для добавления, модификации, поиска и выборки небольших объемов информации в крупных базах данных. Данные обычно собираются в транзакционном стиле: представьте себе пользователя, входящего в некоторый Internet-магазин (выбираются учетные данные; в журнал добавляется информация о сессии), ищущего товары (данные о товарах ищутся и извлекаются, накапливается дополнительная информация о данной сессии) и производящего покупку (в базу данных заказов наносятся детальные данные о покупке, обновляется инфоормация о пользователе). Изрядное количество данных играючи добавляется в базу данных, которая (если этот магазин достаточно крупный и функционирует уже в течение некоторого времени), вероятно, уже содержит "большие данные".
Здесь нет никакой патологии; эта история повторяется повсюду в мире бесчетное число раз, каждую секунду. Неприятности начинаются, когда нам нужно взять эти данные, накопленные в течение месяцев или годов, и что-нибудь узнать на их основе – и, конечно, мы хотим получить ответ за секунды или минуты! Патологии больших данных – это патологии их анализа. Хотя моя точка зрения может показаться несколько спорной, но я считаю, что проблемы обработки транзакций и хранения данных в значительной степени уже решены. Если не считать научные проекты масштаба LHC, немногие предприятия генерируют данные с такой скоростью, что их сбор и хранение представляют сегодня серьезную проблему.
По крайней мере, в бизнес-приложениях решением проблемы баз данных (данные поступают, но ими трудно воспользоваться) считаются хранилища данных. В соответствии с классическим определением хранилище данных – это "копия транзакционных данных, специальным образом структурированная для поддержки выполнения запросов и анализа данных" [4]. В качестве общего подхода принято массовое извлечение данных из оперативной базы данных с их последующим преобразованием в некоторой другой базе данных к форме, более пригодной для выполнения аналитических запросов (так называемый процесс "извлечения, преобразования, загрузки" ("extract, transform, load" – ETL), а иногда "извлечения, загрузки, преобразования"). При наличии по-настоящему огромной совокупности данных недостаточно просто сказать "Мы создадим хранилище данных". Как должны быть структурированы данные для поддержки запросов и анализа, как должны быть спроектированы аналитические СУБД и инструментальные средства, чтобы с этими данными можно было эффективно работать? При наличии больших данных ответы на эти вопросы изменяются, поскольку традиционные методы, такие как организация многомерных данных на основе РСУБД и OLAP на основе многомерных кубов, оказываются либо слишком медленными, либо слишком ограничительными при поддержке действительно интересных вопросов по поводу сохраняемых данных. Чтобы понять, как можно избежать патологий больших данных в контексте хранилищ данных или в контексте естественных или общественных наук, нужно разобраться, что же на самом деле делает данные "большими".
Как справиться с большими данными?
На латыни "data" означает "дары" (хотя в английском языке имеется тенденция к использованию этого слова как неисчисляемого существительного2, как если бы оно обозначало некоторое вещество), и, в конечном счете, почти все полезные данные "даруются" нам либо природой в качестве поощрения тщательных наблюдений за физическими процессами, либо другими людьми, обычно непредумышленно (в частности, распространенными источниками больших данных являются журналы посещений Web-сайтов или розничных сделок). В результате в реальном мире данные – это не просто большой набор случайных чисел; им свойственно проявление предсказуемых характеристик. Прежде всего, как правило, мощность большинства наборов данных (более точно, число различных объектов, по поводу которых производились наблюдения) мала по сравнению с общим числом наблюдений.Вряд ли это удивительно. В зависимости от обстоятельств наблюдения производят или подвергаются наблюдениям человеческие существа, а их в настоящее время не больше 6,75 миллиардов, что позволяет установить, скорее, верхнюю границу. Объектов, о которых мы собираем данные, если они относятся к человеческому миру, – Web-страниц, магазинов, товаров, счетов, служб безопасности, стран, городов, домов, телефонов, IP-адресов – все-таки меньше численности населения планеты. Даже в научных наборах данных практическое ограничение мощности часто диктуется такими факторами, как число доступных датчиков (например, современные нейрофизиологические наборы данных основываются на использовании 512 каналов записи [5]) или просто число различных объектов, которае люди способны опознавать и иденифицировать (самый крупный астрономический каталог, например, включает несколько сотен миллионов объектов [8]).
Большие данные становятся действительно большими благодаря повторению наблюдений во времени и пространстве. В журнал Web-сайта ежедневно записываются данные о миллионах визитов к горстке страниц; в базу данных о мобильных телефонах каждые 15 секунд записываются время и пространственные координаты каждого из нескольких миллионов телефонов; у компании по розничной торговле имеются тысячи магазинов, десятки тысяч товаров и миллионы клиентов, но каждый год регистрируются миллиарды и миллиарды отдельных транзакций. Научные измерения часто производятся с высоким временным разрешением (тысячи замеров в секунду в нейропсихологии, гораздо больше в физике элементарных частиц), и данные реально начинают становиться огромными, когда замеры производятся еще и в двух или трех пространственных координатах; при исследованиях в области нейровизуализации с применением функциональной магнито-резонансной томографии (fMRI, Functional Magnetic Resonance Imaging) в одном эксперименте могут генерироваться сотни и даже тысячи гигабайт данных. Вообще, визуализация – это источник самых больших данных, но проблемы крупных данных изображений – это тема отдельной статьи; здесь я рассматривать их не буду.
Тот факт, что у большей части крупных наборов данных имеются неотъемлемые временные и/или пространственные измерения, крайне важен для понимания того, каким образом большие данные могут вызывать проблемы производительности, особенно при применении баз данных. Например, кажется интуитивно очевидным, что данные, обладающие временным измерением, в большинстве случаев следует сохранять и обрабатывать с поддержкой хотя бы частичной упорядоченности по времени, чтобы, по мере возможности, сохранять локальность ссылок в тех случаях, когда данные используются в порядке времени. В конце концов, в большинстве случаев нетривиального анализа потребуется, как минимум, агрегировать результаты наблюдений за один или несколько непрерывных временных интервалов. Например, более вероятно может понадобиться посмотреть на покупки случайным образом выбранного набора клиентов, сделанные в течение некоторого периода времени, чем на покупки некоторого "непрерывного диапазона" клиентов (как бы он ни определялся) в случайным образом выбранные моменты времени.
Эта мысль становится еще более понятной при учете потребностей анализа временных рядов и прогнозирования, где данные агрегируются с применением методов, зависящих от порядка (например, кумулятивных агрегатных функций и функций с подвижным окном, операций упреждения и запаздывания (lead и lag) и т.д.). Такой анализ необходим для обеспечения ответов на действительно интересные вопросы о темпоральных данных: "Что случилось?", "Почему так случилось?", "Что произойдет дальше?".
Однако сегодня превалируют базы данных, основанные на реляционной модели, и в этой модели явно игнорируется порядок строк в таблицах [1]. В реализациях СУБД, следующих этой модели, избегается идея внутренней упорядоченности таблиц, и это неизбежно приводит к неупорядоченной выборке данных, когда их размер становится настолько большим, что они не помещаются в основной памяти. По мере роста объема данных, хранимых в базе данных, эта проблема только усугубляется. Для достижения приемлемой эффективности выполнения запросов, в высокой степени зависящих от порядка данных, требуется отказаться от чисто реляционной модели данных в пользу модели, опирающейся на концепцию внутренней упорядоченности данных вплоть до уровня реализации. К счастью, эта мысль постепенно начинает признаваться в области аналитических баз данных.
Не только в базах данных, но и в программировании приложений в целом наличие больших данных существенно увеличивает влияние на производительность неоптимальных схем доступа. По мере роста размеров наборов данных становится все более важно выбирать алгоритмы, максимально опирающиеся на эффективный поледовательный доступ на всех фазах обработки. Не говоря уже о том, что десятикратное увеличения времени обработки (что может легко произойти при большом числе не последовательных обращений к данным) является гораздо более болезненным, когда речь идет о часах, а не минутах, возрастание размеров данных означает, что доступ к ним становится все менее и менее эффективным. Потери, вызываемые применением неэффективных схем доступа, возрастают непропорционально при исчерпании ресурсов последовательных уровней аппаратуры: при переходе от использования кэша процессора к использованию основной памяти, от основной памяти – к локальным дискам и (теперь уже редко!) от дисковой памяти – к офлайновой системе хранения данных.
В аппаратуре типичного современного сервера полностью случайный доступ к основной памяти в диапазоне адресов, намного превышающем размер кэша, может быть на порядок более медленным, чем полностью последовательный доступ, но полностью случайный доступ к диску может оказаться на пять порядков медленнее последовательного доступа (рис. 3). Даже у новейших твердотельных (флэш) дисков (solid-state disk, SSD), хотя они обеспечивают намного меньшую задержку поиска (seek latency), чем магнитные диски, скорость произвольного и последовательного доступа может различаться примерно на четыре порядка. На рис. 3 показано число четырехбайтовых целых чисел, считываемых за одну секунду из массива миллиарда целых чисел (4 гигабайта), располагаемого в дисковой или основной памяти; произвольные чтения с дисков выполнялись для 10000 индексов, выбираемых случайным образом из диапазона от единицы до одного миллиарда.
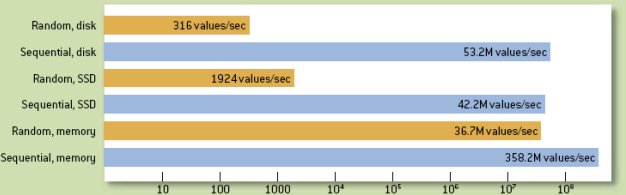
Замечание: Для устранения воздействия кэширования дисковых блоков на уровне операционной системы тесты с дисками выполнялись на только что перезагруженной машине (сервер Windows 2003 с 64 гигабайтами основной памяти и восемью дисками 15000-RPM SAS в конфигурации RAID5). При тестировании SDD использовался новейший высокопроизводительный накопитель компании Intel с интерефейсом SATA
Рис. 3. Сравнение произвольного и последовательного доступа к данным в дисковой и основной памяти
Еще один факт, не получивший достаточного признания, состоит в том, что (как это показано на рис. 3) в современных системах произвольный доступ к основной памяти обычно выполняется медленнее последовательного доступа к дисковой памяти. Заметим, что произвольное чтение с диска выполняется более чем в 150000 раз медленнее последовательного чтения; SDD улучшает это соотношение менее чем на один порядок. По сути дела, у всех современных разновидностей устройств хранения данных совершенствуются только количественные показатели, а не основные качества наиболее заслуженного и самого последовательного накопителя данных – магнитной ленты.
Огромная стоимость произвольного доступа имеет важные следствия для анализа крупных наборов данных (при анализе небольших наборов данных эта проблема очычно смягчается благодаря применению разных видов кэширования). Рассмотрим, например, соединение двух крупных таблиц, которые обе сохраняются не отсортированными по значениям ключа соединения, скажем, последовательность Web-транзакций и список учетных данных пользователей. Таблица транзакций сохраняется в порядке времени, поскольку, во-первых, именно в этом порядке данные собираются, и, во-вторых, с этим порядком связаны основные аналитические потребности (скажем, отслеживание навигационных маршрутов пользователей). У таблицы пользователей, конечно, временное измерение отсутствует.
Поскольку записи из таблицы транзакций используются в порядке времени, доступ к соединяемой с ней таблицей пользователей будет, по сути дела, произвольным – и весьма дорогостояшим, если эта таблица большая и сохраняется на диске. Если имеется основная память достаточного объема, чтобы можно было полностью размесить в ней таблицу пользователей, производительность будет улучшена. Но поскольку произвольный доступ к основной памяти сам стоит недешево, а основная память – это дефицитный ресурс, который может быть просто недоступен для кэширования крупных таблиц, наилучшим решением при построении крупных баз данных для аналитических целей (например, хранилищ данных) может, как это ни удивительно, оказаться использование полностью денормализованной таблицы, т.е. таблицы, включающей все данные о каждой транзакции, а также информацию обо всех пользователях, уместную для выполнения анализа (рис. 4). Совместная денормализация таблицы пользователей с 10 миллионами строк и 10 столбцами и таблицы транзакций с четырьмя столбцами существенно увеличит размер данных, которые требуется хранить (размер денормализованной таблицы в три раза превышает общий размер исходных таблиц). Если выполняется анализ данных в порядке времени, но при этом тредуется информация из обеих таблиц, то устранение произвольного доступа к таблице пользователей позволит значительно повысить производительность. Хотя при этом неизбежно требуется намного больше дисковой памяти, и, что более важно, при выполнении анализа придется прочитать больше данных с диска, преимущества, получаемые от перехода к чисто последовательному доступу к данным, часто бывают огромными.
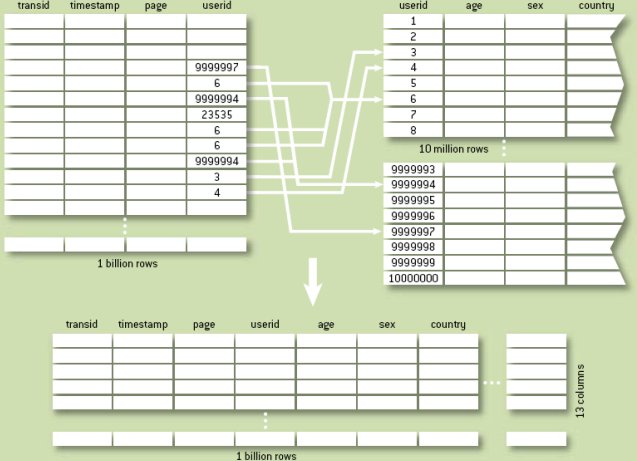
Рис. 4. Денормализация таблицы с информацией о пользователях
Жесткие ограничения
Еще одну проблему для анализа данных представляют приложения с жесткими ограничениями на размеры данных, с которыми они могут работать. Здесь речь идет, главным образом, об аналитических приложениях уровня конечного пользователя, которые используются на завершающей фазе анализа. Порою эти пределы относительно произвольны. Например, вплоть до самой последней версии размер таблицы в Microsoft Excel был ограничен 65536 строками и 256 столбцами. Такое ограничение могло бы казаться допустимым в те дни, когда объем основной памяти исчислялся мегабайтами, но оно, несомненно, устарело к 2007 г., когда Microsoft обновила Excel таким образом, что появилась возможность работы с таблицами с миллионом строк и 16384 столбцами. Достаточно ли этого для всех? Excel не предназначается для пользователей, перерабатывающих действительно огромные наборы данных, но, очевидно, что тот, кто сегодня работает с набором данных из миллиона строк (например, списком клиентов и их покупок в крупном сетевом магазине), вероятно, рано или поздно столкнется с потребностью обрабатывать набор данных с двумя миллионами строк, а Excel этого не позволит.
При создании приложений, которые должны справляться со все возрастающими объемами данных, разработчикам следует помнить, что совершенствуются и спецификации аппаратуры, а также не забывать так называемое правило ZOI (zero-one-infinity – ноль-один-бесконечность), которое гласит, что в программе следует "не допускать ни одного foo, допускать одно foo или же допускать любое число foo" [11]. Другими словами, ограничения не должны быть произвольными; в идеале программное обеспечение должно позволять делать столько же, сколько позволяет аппаратура.
Конечно, основным фактором программных ограничений на размеры наборов данных часто является аппаратура (и, прежде всего, ограничения основной памяти и центральных процессоров). Многие приложения разрабатываются в расчете на считывание в основную память наборов данных целиком и работу с ними в этой памяти; хорошим примером подобного приложения является популярная статистическая вычислительная среда R [7]. Приложения, ограниченные основной памятью, естественно, демонстрируют более высокую производительность, чем приложения, работающие с дисковой памятью (по крайней мере, до той степени, в которой выполняемая ими переработка данных опережает однопроходную чисто последовательную обработку), но требование размещения всех данных в основной памяти означает, что соответствующее приложение просто не сможет работать с набором данных, объем которого превосходит объем установленной основной памяти. На большинстве аппаратных платформ ограничения на расширение основной памяти являются гораздо более жесткими, чем ограничения на расширение дисковой памяти: все определяется числом слотов на системной плате.
Однако часто проблема является более глубокой. Подобно другим аспектам компьютерной аппаратуры, со временем возрастает предельно допустимый объем основной памяти; нередки конфигурации настольных рабочих станций с 32 гигабайтами основной памяти, а серверы часто конфигурируются с основной памятью гораздо большего объема. Но нет никакой гарантии, что приложение, ориентированное на работу с данными в основной памяти, сможет использовать всю установленную память. Даже при использовании современных 64-разрядных операционных систем у многих сегодняшних приложений (например, R под Windows) имеются только 32-битные исполняемые программы, и они ограничены 4-гигабайтным адресным пространтством – это часто выражается в ограничении рабочего набора 2-мя или 4-мя гигабайтами.
Наконец, даже в тех случаях, когда имеется 64-битный исполняемый код (что устраняет абсолютное ограничение на размер адресного пространства), в программном обеспечении очень часто присутствует многочисленное наследие 32-битной эпохи, в частности, использование в качестве индексов массивов 32-битных целых чисел. Например, в 64-битных версиях R (имеющихся для Linux и Mac) для представления длины используются 32-битные целые числа со знаком, и, тем самым, длина порции данных не может превышать 231-1, около 2 миллиардов строк. Следовательно, даже в 64-битной системе с основной памятью достаточного объема набор данных из 6,75 строк из приведенного ранее примера мировой переписи оказывается для R слишком большим.
Распределенная обработка как стратегия для больших данных
У любого компьютера имеется ряд абсолютных и практических ограничений: размер основной памяти, размер дисковой памяти, скорость процессора и т.д. При исчерпании ресурсов одного вида мы опираемся на ресурсы следующего вида, но за счет падения производительности: СУБД с хранением данных в основной памяти быстрее СУБД с хранением данных на диске, но при использовании персонального компьютера с двухгигабайтной основной памятью невозможно полностью хранить в памяти 100-гигабайтный набор данных. Это можно сделать на сервере со 128-гигабайтной основной памятью, но объем данных может благополучно вырасти до 200 гигабайт до появления серверов следующего поколения с удвоенным числом слотов памяти.Тем не менее, достоинствами сегодняшней массовой компьютерной аппаратуры являются ее дешевизна и почти бесконечная тиражируемость. Сегодня намного рентабельнее купить восемь серийных серверов категории "массового спроса" с основной памятью в 128 гигабайт на каждом, чем приобрести одну систему с 64 процессорами и терабайтом основной памяти. Если архитектуры компьютеров не изменятся коренным образом, то этот общий принцип, вероятно, останется актуальным в обозримом будущем, хотя абсолютные цифры со временем будут меняться. Поэтому неудивительно, что наиболее успешной из всех известных стратегий анализа сверхбольших наборов данных является распределенная обработка.
Распределенному анализу с использованием нескольких компьютеров свойственны существенные эксплуатационные издержки: даже при использовании гигабитного и 10-гигабитного Ethernet как пропускная способность (скорость последовательного доступа), так и задержка (определяющая скорость произвольного доступа) на несколько порядков хуже, чем у основной памяти. Однако в то же время технологии высокоскоростных локальных сетей теперь превосходят большинство локально подключаемых дисковых систем по пропускной способности, а сетевые задержки, естественно, намного ниже дисковых задержек.
В результате эксплуатационные издержки хранения и выборки данных в других узлах сети сравнимы с издержками при использовании дисков (а в случае произвольного доступа они потенциально значительно меньше). Однако при распределении большого набора данных по узлам сети можно получить огромное преимущество за счет того, что можно распределить и обработку этих данных (при условии, что анализ поддается распараллеливанию).
На эту тему многое говорилось, и многое можно еще сказать, но в контексте распределенного крупного набора данных критерии в основном схожи с теми, что обсуждались ранее: точно так же, как поддержка локальности ссылок на основе последовательного доступа критична для процессов, опирающихся на обмены с дисками (поскольку операции подвода дисковых головок являются дорогостоящими), в распределенном анализе должен присутствовать некоторый важный компонент, локальный по отношению к данным, т.е. не требующий одновременной обработки многих разрозненных частей набора данных (поскольку коммуникации между разными областями обработки являются дорогостоящими). К счастью, в большинстве аналитических приложений такой компонент присутствует. Операции поиска, подсчета, частичной агрегации, комбинирования полей одной записи, а также многие операции анализа временных рядов могут независимо выполняться в каждом узле сети.
Кроме того, коммуникации между узлами часто требуются после того, как данные тщательно агрегированы. Рассмотрим, например, операцию взятия среднего значения некоторого поля набора данных из миллиарда записей, хранимых в нескольких узлах. Каждому узлу требуется передать только два значения (сумму и число значений) в узел, производящий окончательный результат. Не каждую агрегацию можно вычислить так просто – как глобальную агрегацию локальных подагрегаций (например, так невозможно подсчитать общую медиану), но во многих важных случаях это возможно, и имеются распределенные алгоритмы решения других, более сложных задач, минимизирующие коммуникации между узлами.
Естественно, в распределенном анализе больших данных имеются свои "фокусы". Одной из основных проблем является неравномерное распределение работы по узлам сети. В идеале у каждого узла имеется один и тот же объем независимых вычислений, которые требуется проделать до объединения результатов всех узлов. Если это не так, то от наиболее нагруженного узла будет зависеть, как долго нам придется дожидаться результатов, и, очевидно, это время ожидания будет больше, чем если бы нагрузка распределялась равномерно. В худщем случае вся работа будет выполняться на одном узле, и мы не получим никакой выгоды от параллелизма.
Является ли это проблемой или нет, обычно можно определить на основе распределения данных по узлам; к несчастью, во многих случаях требование равномерного распределения нагрузки может прямо противоречить требованию распределять данные таким образом, чтобы их обработка на каждом узле производилась локально. Например, рассмотрим набор данных, которые собирались от 1000 датчиков в течение 10 лет с 15-секундным интервалом. Для каждого датчика имеется более 20 миллионов записей. Поскольку при типичном анализе производятся вычисления над временными рядами (например, ищутся значения, являющиеся необычными по отношению к скользящему среднему и среднему квадратичному отклонению), мы принимаем решение хранить данные каждого датчика в порядке времени (рис. 5) и распределить их по 10 вычислительным узлам, чтобы каждый из них содержал все данные от 100 датчиков (всего 2 миллиарда записей на узел). К несчастью, это означает, что во всех случаях, когда нас интересуют результаты только одного или нескольких датчиков, большая часть вычислительных узлов будет полностью простаивать. Выбор способа кластеризации строк по датчикам или по времени приводит к большой разнице в уровне параллелизма, на котором могут выполняться разные запросы.
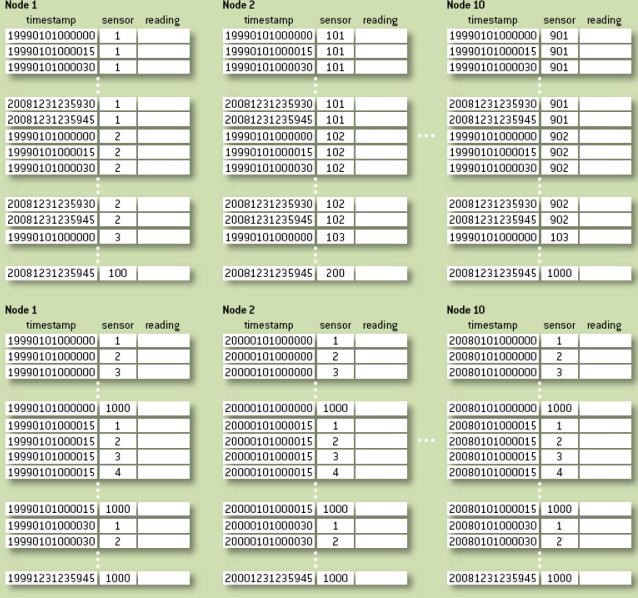
Рис. 5. Два способа распределения по десяти машинам данных, собранных за 10 лет от 1000 датчиков
Конечно, можно было бы хранить данные упорядоченными по времени, чтобы в каждом узле были представлены данные всех датчиков за один год (в начале вычисления нам понадобились бы некоторые коммуникации между последовательными узлами, чтобы подготовиться к обработке временных рядов). Но и при этом подходе можно было бы столкнуться с трудностями, если бы вдруг понадобился интенсивный анализ данных только за один прошлый год. Оптимальную эффективность обоих видов анализа обеспечило бы одновременное хранение данных обоими способами, но чем крупнее набор данных, тем более вероятно, что в двух копиях содержалось бы слишком много данных, чтобы их можно было поддерживать при наличии доступных аппаратных ресурсов.
Еще одной важной проблемой распределенных систем является надежность. Точно так же, как у самолета с четырьмя двигателями вероятность выхода из строя одного двигателя выше, чем у самолета с двумя такими же двигателями, вероятность потребности в техническом обслуживании кластера из 10 машин в 10 раз выше, чем при наличии одной машины. К сожалению, многие компоненты, тиражируемые в кластерах (блоки питания, диски, вентиляторы, кабели и т.д.) обычно бывают ненадежными. Конечно, можно сделать кластер абсолютно устойчивым к выходу из строя любого одного узла, в основном, путем репликации данных в узлах. К счастью, здесь, по-видимому, возможна некоторая синергия: данные, реплицируемые для повышения эффективности разных видов анализа, могут также обеспечить избыточность, позволяющую системе выжить при неизбежных отказах узлов. Однако снова, чем крупнее набор данных, тем сложнее поддерживать несколько копий данных.
Метаопределение
Я постарался привести здесь обзор нескольких проблем, которые могут возникнуть при анализе больших данных: неспособность многих типовых пакетов масштабироваться к крупным проблемам; первостепенная важность избежания неоптимальных схем доступа при перемещении основного объема обработки вниз по иерархии систем хранения данных; репликация данных для повышения надежности и эффективности распределенных систем. Но я так и не ответил на вопрос, с которого начал статью: так что же такое "большие данные"?Я попытаюсь привести метаопределение: в любой момент времени большие данные следует понимать как "данные, размер которых вынуждает нас выходить за пределы проверенных временем методов, широко распространенных в данное время". В начале 1980-х имелся набор данных, который был настолько крупным, что для установки и снятия тысяч магнитных лент требовалась роботизированная "ленточная обезьяна" ("tape monkey"). В 1990-е гг., вероятно, имелись данные, размер которых не укладывался в ограничения Microsoft Excel и настольных персональных компьютеров, и для их анализа требовалось серьезное программное обеспечение на рабочих станциях с Unix. Теперь этот термин может означать данные, являющиеся слишком большими, чтобы можно было размещать их в реляционной базе данных и анализировать с помощью настольных пакетов статистики/визуализации, данные, для анализа которых, вероятно, требуется массивно параллельное программное обеспечение, выполняющеся на десятках, сотнях или даже тысячах серверов.
В любом случае, по мере того как в повседневную практику будет входить анализ наборов данных все большего размера, это определение будет продолжать изменяться. Но одно останется неизменным: успеха на переднем крае будут добиваться те разработчики, которые не ограничиваются стандартными, типовыми методами и понимают истинную природу аппаратных ресурсов и все многообразие доступных им алгоритмов.
Еще раз от переводчика
Вот теперь я настоятельно рекомендую прочитать мои критические замечания в заметке "О точности диагностики патологий". Иначе у вас могут сложиться несколько искаженные представления о действительности.
Литература
1. Codd, E. F. 1970. A relational model for large shared data banks. Communications of the ACM 13(6): 377-387. Имеется перевод на русский язык: Реляционная модель данных для больших совместно используемых банков данных2. IBM 3850 Mass Storage System
3. IBM Archives: IBM 3380 direct access storage device
4. Kimball, R. 1996. The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses. New York: John Wiley & Sons
5. Litke, A. M., et al. 2004. What does the eye tell the brain? Development of a system for the large-scale recording of retinal output activity. IEEE Transactions on Nuclear Science 51(4): 1434-1440
6. PostgreSQL: The world’s most advanced open source database
7. The R Project for Statistical Computing
8. Sloan Digital Sky Survey
9. Throughput and Interface Performance. Tom’s Winter 2008 Hard Drive Guide
10. WLCG (Worldwide LHC Computing Grid)
11. Zero-One-Infinity Rule
1 В демографии под термином возрастная медиана (или медиана возрастного состава населения) понимают возраст, разделяющий население на две равные по численности половины (примечание переводчика).
2 К неисчисляемым существительным относятся названия веществ и понятий, которые нельзя пересчитать. К ним принадлежат вещественные и абстрактные (отвлеченные) имена существительные. Неисчисляемые существительные употребляются только в единственном числе и не употребляются с неопределенным артиклем. Подробнее см. здесь (примечание переводчика).