4. Исследование производительности
Этот раздел организован следующим образом. Сначала авторы описывают свой вариант тестового набора TPC-C (подраздел 4.1). В подразделе 4.2 приводятся детали аппаратной платформы – экспериментальной установки, а также описываются инструментальные средства, которые использовались для сбора данных о производительности. В подразделе 4.3 представлена серия результатов, уточняющих повышение производительности Shore по мере применения оптимизаций и удаления компонентов.
4.1 Рабочая нагрузка OLPTP
Тестовый набор, используемый авторами, происходит от TPC-C [TPCC], в котором моделируется оптовый поставщик запасных частей, работающий с несколькими складами и связанными с ними торговыми участками. Тестовый набор TPC-C разработан для представления любой прикладной области, в которой требуется регулировать, продавать или распространять некоторые продукты или услуги. В нем учитывается потребность в масштабировании, когда поставщик расширяет свой бизнес и создаются новые склады. С каждого склада продукция должна поставляться в 10 торговых участков, и каждый торговый участок должен обслуживать 3000 заказчиков. Схема базы данных, в которой учитываются требования масштабирования (число складов W является параметром), показана на рис. 3. Размер базы данных для одного склада составляет около 100 мегабайт (авторы экспериментировали с пятью складами, т.е. с базой данных общим размером в 500 мегабайт).
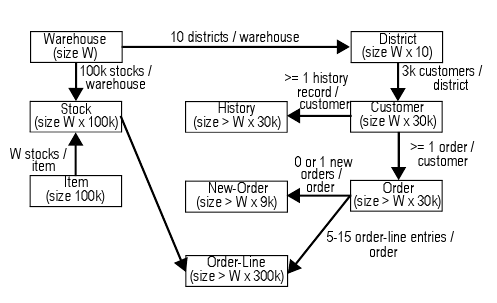
Рис. 3. Схема TPC-C
TPC-C включает смесь из пяти параллельных транзакций разных типов и сложности. В их число входят транзакции регистрации заказов (New Order), учета платежей (Payment), доставки заказов, проверки состояния заказов и отслеживания уровня запасов на складах. В TPC-C также специфицируется, что около 90% времени выполняются первые две транзакции. Для лучшего понимания эффекта своих оптимизаций и модификаций авторы экспериментировали со смесью только первых двух транзакций. Структура их кода (вызовов Shore) показана на рис. 4. Для достижения повторяемости экспериментов в исходные спецификации внесены следующие небольшие изменения.

Рис. 4. Вызовы методов Shore в транзакциях New Order и Payment
New Order. Каждая транзакция New Order размещает заказ из 5-15 пунктов, и 90% заказов полностью удовлетворяется за счет запасов «соседнего» склада заказчика (для 10% заказов требуется доступ к запасам удаленного склада). Чтобы избежать изменчивости результатов авторы установили число пунктов заказа в 10 и всегда обслуживают заказы из локального склада. Эти два изменения не влияют на пропускную способность. Код на рис. 4 демонстрирует двухфазную оптимизацию, упоминавшуюся в подразделе 2.5, которая позволяет избежать аварийного завершения транзакции. Сначала читаются все пункты заказа, и если среди них обнаруживается что-то недопустимое, то приложение аварийно завершается без потребности в откате базы данных.
Payment. Это легковесная транзакция. Она обновляет баланс заказчика и поля «склад/торговый участок», а также генерирует запись истории. Здесь снова имеется выбор между соседним и удаленным складами, и авторы всегда выбирают соседний склад. Еще одна возможность случайного выбора состоит в том, ищется ли заказчик по имени, или же по идентификатору, и авторы всегда используют идентификаторы.
4.2 Экспериментальная установка и методология измерений
Все эксперименты выполнялись на одноядерном процессоре Pentium 4 3.2GHz с кэшем L2 емкостью 1 мегабайт, отключенным гипертредингом, основной памятью в 1 гигабайт. Система работала под управлением Linux 2.6. Для компиляции использовался компилятор gcc версии 3.4.4 с оптимизацией уровня O2. Для отслеживания активности дисков и проверки того, что во время экспериментов с базами данных не генерировался дисковый трафик, использовалась стандартная утилита Linux iostat. Во всех экспериментах база данных целиком предварительно загружалась в основную память. Затем пропускалось большое количество транзакций (40000). Пропускная способность измерялась напрямую делением прошедшего времени на число завершенных транзакций.
Для детального подсчета числа команд и циклов процессора в код тестового приложения были встроены вызовы библиотеки PAPI [MBD+99], которая обеспечивает доступ к измерителям производительности центрального процессора. Поскольку вызов PAPI производится после каждого вызова Shore, авторы должны были компенсировать расходы на вызовы PAPI в своих итоговых результатах. На используемой машине на эти вызовы расходовалось 535-537 команд и 1350-1500 циклов процессора. Авторы измеряли расходы на вызовы Shore для всех 40000 транзакций и вычисляли средние значения показателей.
Большинство диаграмм, представленных в этой статье, основывается на измерениях числа команд процессора (полученных с использованием измерителей производительности ЦП), а не на астрономическом времени. Причиной является то, что показатели числа команд отображают длину выполняемых участков кода, и они детерминированы. Конечно, одно и то же число выполненных команд в разных компонентах может привести к разным астрономическим временам выполнения (числу циклов процессора) из-за разного поведения на уровне микроархитектуры процессора (отсутствие данных в кэше, отсутствие требуемых элементов в буфере быстрого преобразования адресов (translation lookaside buffer, TLB) и т.д.). В п. 4.3.4 сравниваются показатели числа команд и числа циклов процессора и демонстрируются компоненты, для которых обеспечивается высокая эффективность на микроархитектурном уровне за счет редкого отсутствия данных в кэше L2 и хорошего распараллеливания на уровне команд.
Однако на число циклов влияют различные параметры, начиная от характеристик процессора, таких как размер/ассоциативность кэша, качество предсказания переходов, особенности функционирования TLB, и заканчивая переменными времени исполнения, такими как параллельно выполняемые процессы. Поэтому число циклов следует воспринимать, как относительный временной показатель. В этой статье авторы не углубляются в проблематику эффективности кэшей процессоров, поскольку основной задачей является идентификация набора компонентов СУБД, удаление которых может привести к увеличению на два десятичных порядка производительности некоторых видов рабочих нагрузок OLTP. Более подробную информацию о микроархитектурном поведении систем баз данных можно найти, например, в [Ail04]. В следующем подразделе авторы переходят к описанию полученных ими результатов.
4.3 Экспериментальные результаты
Во всех экспериментах основная платформа Shore представляла собой систему баз данных, полностью сохраняемых в основной памяти, без каких-либо выталкиваний данных на диск (обмены с дисковой памятью могли инициироваться только менеджером журнала). Имелся только один поток управления, в котором транзакции выполнялись по одной. Маскирование ввода-вывода (в случае журнализации на диске) не являлось проблемой, поскольку этот ввод-вывод влиял только на общее время отклика и не увеличивал число команд и циклов, реально затрачиваемых на выполнение транзакций.
В Shore было вставлено 11 различных разновидностей изменений, позволявших авторам устранить функциональные возможности (или произвести оптимизацию). При представлении экспериментальных результатов эти разновидности объединены в шесть компонентов. Список 11-ти разновидностей изменений (и соответствующих компонентов) и порядок их применения показан на рис. 7. Более подробно эти модификации были описаны в подразделе 3.2. Последнее изменение состоит в полном отказе от использования Shore и запуске разработанного авторами ядра с минимальными накладными расходами, которое в этой статье называется «оптимальным». По сути, это ядро представляет собой построенный вручную пакет для работы с B-деревьями в основной памяти без какой-либо поддержки транзакций или обработки запросов.
4.3.1 Воздействие на пропускную способность
После всех удалений компонентов и оптимизаций в полученном варианте Shore остался код, при выполнении которого процессор занимается полностью, поскольку отсутствует какой-либо ввод-вывод. Среднее время выполнения транзакции составляет 80 микросекунд (для смеси 50/50 транзакций New Order и Payment); выполняется около 12700 транзакций в секунду.
Для сравнения, полезная работа в оптимальной системе занимала около 22 микросекунд на одну транзакцию, что позволяло выполнять около 46500 транзакций в секунду. Основными причинами этого различия является более глубокий стек вызовов в ядре, разработанном авторами, и невозможность устранения некоторых остаточных явлений управления транзакциями и вызовов буферного пула без разрушения Shore. В качестве точки отсчета бралась стандартная версия Shore с разрешенной журнализацией, но базой данной, целиком кэшированной в основной памяти. Эта система обеспечивала выполнение примерно 640 транзакций в секунду (1.6 миллисекунд на транзакцию). Вариант Shore с базой данных в основной памяти без выталкивания буфера журнала позволил добиться пропускной способности в 1700 транзакций в секунду (около 588 микросекунд на транзакцию). Тем самым, модификации, произведенные авторами, позволили увеличить общую пропускную способность в 20 раз.
Представив эти базовые измерения пропускной способности, авторы переходят к детальному анализу числа команд, затраченных системой на выполнение двух транзакций из тестового набора. В анализе числа команд и циклов процессора, представленном в следующих пунктах, не учитывается какое-либо влияние дисковых операций, хотя в показателях для исходного варианта Shore некоторые операции записи в журнал учитывались.
4.3.2 Payment
На рис. 5 (слева) показано уменьшение числа команд, затрачиваемых на выполнение транзакции Payment, за счет оптимизации сравнения ключей B-дерева и удаления функциональности журнализации, блокировок, защелок и менеджера буферов.
В правой части рисунка для каждого действия по оптимизации или удалению компонентов показано его воздействие на число команд, затрачиваемых на разные части выполняемой транзакции. Для транзакции Payment эти части включают вызов метода начала транзакции, три поиска в B-дереве, три соответствующих операции pin/unpin, три операции модификации (через B-дерево), одно создание записи и вызов метода фиксации транзакции. Высота каждого прямоугольника соответствует общему числу выполненных команд. Самый правый прямоугольник показывает производительность ядра с минимальными накладными расходами.
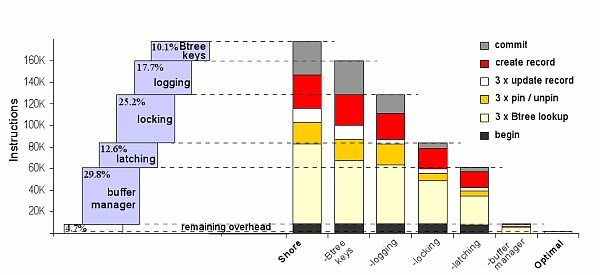
Рис. 5. Детальный анализ числа команд для транзакции Payment
По имеющейся у авторов информации, выполненная ими оптимизация сравнения ключей B-дерева является стандартной практикой в высокопроизводительных архитектурах СУБД, и для Shore эта оптимизация была произведена первой, поскольку ее следует делать в любой системе.
Удаление журнализации влияет, главным образом, на операции фиксации транзакций и модификации, поскольку именно в их коде генерируются журнальные записи; в меньшей степени это действие затрагивает поиск в B-деревьях и каталогах. Произведенные модификации позволили сократить общее число команд на 18%.
На поддержку блокировок тратится около 25% от общего числа команд. Удаление блокировок влияет на весь код, но в особенности на операции pin/unpin, поиска в B-деревьях и каталогах, а также фиксации транзакций, т.е. на операции, устанавливающие и освобождающие блокировки (транзакция всегда имеет требуемые блокировки модифицируемых записей к моменту выполнения операций модификации).
Механизм защелок занимает примерно 13% от общего числа команд, и он, прежде всего, затрагивает части транзакций, создающие запись и производящие поиск в B-дереве. Это связано с тем, что буферный пул (используемый при создании записи) и B-деревья являются основными общими структурами данных, при доступе к которым должна производиться синхронизация.
Наконец, модификации, относящиеся к буферному пулу, позволили сократить общее число команд еще на 30%. Как говорилось ранее, после выполнения этих модификаций память под новые записи получается непосредственно вызовом функции malloc, и в большинстве случаев поиск страниц не проходит через буферный пул. Это делает операцию создания новой записи очень дешевой, а также существенно улучшает производительность других компонентов, часто осуществляющих поиск.
К этому моменту в оставшемся ядре выполняется 5% от исходного числа команд (что дает двадцатикратный выигрыш в производительности), что в шесть раз превышает число выполняемых команд в «оптимальной» системе. Этот анализ приводит к двум наблюдениям. Во-первых, существенны все шесть основных компонентов, для каждого требуется выполнение не менее 18 тысяч команд из исходных 180 тысяч. Во-вторых, до применения всех оптимизаций сокращение числа выполняемых команд не является слишком существенным: до последнего шага по удалению менеджера буферов в оставшихся компонентах выполняется примерно треть от исходного числа команд (а после удаления менеджера буферов достигается 20-кратное повышение пропускной способности).
4.3.3 New Order
Аналогичный анализ числа команд, затрачиваемых при выполнении транзакции New Order, показан на рис. 6. На рис. 7 показан детальный расчет влияния всех одиннадцати выполненных модификаций и оптимизаций. В этой транзакции используется примерно в 10 раз больше команд, чем в транзакции Payment, для выполнения 13 вставок в B-дерево, 12 операций создания записи, 11 операций модификации, 23 операций pin/unpin и 23 поисков в B-дереве. Основное отличие между New Order и Payment по влиянию оптимизаций на сокращение числа выполняемых команд в разных компонентах относится к коду сравнения ключей B-дерева, журнализации и блокировкам. Поскольку в New Order к смеси операций добавляются вставки в B-дерево, относительно более выигрышной оказывается оптимизация сравнения ключей (около 16%). Удаление журнализации и блокировок теперь приводит к сокращению общего числа выполняемых команд только на 12 и 16% соответственно. В основном, это связано с тем, что в этом случае значительно меньшее время занимает выполнение операций, для которых требуется большая работа по журнализации и управлению блокировками.
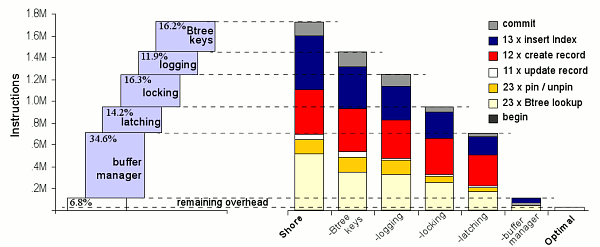
Рис. 6. Детальный анализ числа команд для транзакции New Order
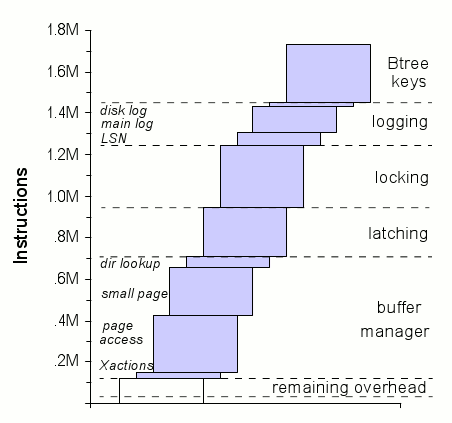
Рис. 7. Расширенный анализ для транзакции New Order (пояснения по поводу надписей в левой колонке см. в подразделе 3.2)
Оптимизации менеджера буферов и здесь обеспечивают наиболее существенный выигрыш, снова по той причине, что удается избежать высоких накладных расходов на создание записи. Показатели для оптимизации менеджера буферов, представленные на рис. 7, демонстрируют нечто поразительное: увеличение размера страницы с 8 килобайт до 32 килобайт (см. блок «small page») обеспечивает сокращение общего числа выполняемых команд на 14%. Эта простая оптимизация (служащая для сокращения частоты выделения страниц и уменьшения глубины B-дерева) дает значительный выигрыш.
4.3.4 Команды по сравнению с тактами
Имея детальный анализ числа выполняемых команд в транзакциях Payment и New Order, авторы теперь сравнивают долю астрономического времени (число тактов процессора), затраченного на выполнение каждой фазы транзакции New Order, с долей числа команд, выполненных на каждой фазе. Результаты демонстрируются на рис. 8. Как уже отмечалось, авторы не ожидали, что эти доли будут идентичны, поскольку в кэше могут отсутствовать требуемые данные, конвейер команд может тормозиться (обычно из-за условных переходов), и для выполнения некоторых команд может потребоваться больше тактов, чем для других команд.
Например, оптимизации B-дерева в меньшей степени сокращают число тактов, чем число выполняемых команд, поскольку устраняемые накладные расходы в основном касаются вычисления смещений, при которых данные обычно содержатся в кэше. И наоборот, в оставшемся после всех оптимизаций ядре используется намного больше тактов, чем команд, поскольку в нем много переходов, происходящих, в основном, от вызовов функций. Аналогично, значительно больше тактов используется в компоненте журнализации, поскольку он работает с разными адресами при создании и записи журнальных записей (время обмена с диском не включается ни в одну из диаграмм). Наконец, компоненты управления блокировками и буферами потребляют примерно такую же долю тактов, что и команд.
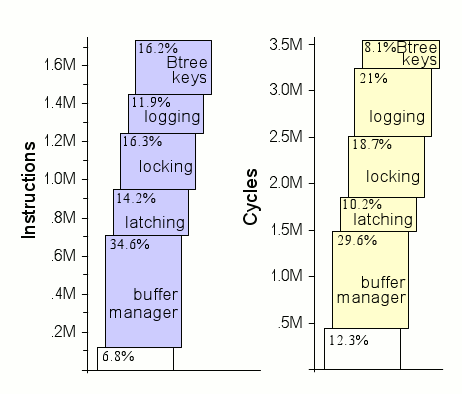
Рис. 8. Команды (слева) и такты (справа) для транзакции New Order
Назад Оглавление Вперёд

