3. Shore
СУБД Shore (Scalable Heterogeneous Object Repository) разрабатывалась в Висконсинском университете в начале 1990-х гг. как типизированная система персистентных объектов, заимствовавшая черты технологий файловых систем и объектно-ориентированных баз данных [CDF+94]. Система обладала многоуровневой архитектурой, которая позволяла пользователям выбрать соответствующий уровень поддержки их приложений. Эти уровни (система типов, совместимость с UNIX, языковая неоднородность) обеспечивались поверх менеджера хранения данных Shore (Shore Storage Manager, SSM). В SSM поддерживались средства, типичные для всех современных СУБД: полное управление параллелизмом и восстановлением (свойства транзакций ACID) c применением двухфазных блокировок и журнализации с упреждающей записью в журнал, а также надежная реализация B-деревьев. Основные архитектурные решения основывались на идеях, описанных в основополагающей книге Грея и Рейтера про обработку транзакций [GR93], а также на использовании многочисленных алгоритмов, заимствованных из статей про ARIES [MHL+92, Moh89, ML89].
Поддержка проекта завершилась в конце 1990-х гг., но она продолжалась в отношении SSM; в 2007 г. вышла версия SSM 5.0 для использования в среде Linux на процессорах Intel x86. В этой статье под названием Shore понимается именно SSM. Информация по поводу Shore и исходные коды системы доступны на сайте проекта. В оставшейся части этого раздела обсуждаются ключевые компоненты Shore, структура кода системы, характеристики Shore, влияющие на сквозную производительность системы, а также набор модификаций системы, произведенных авторами данной статьи, и воздействие этих модификаций на код системы.
3.1 Архитектура Shore
В Shore имеется несколько компонентов, которые не описываются в данной статье, поскольку не являются для нее существенными. В их число входят управление дисковыми томами (авторы статьи загружают всю базу данных в основную память), восстановление (авторы не рассматривают ситуации аварийных отказов приложений), распределенные транзакции и методы доступа, отличные от B-деревьев (такие как R-деревья). Примерная организация оставшихся компонентов показана на рис. 2.
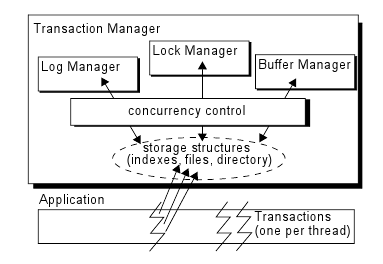
Рис. 2. Основные компоненты Shore (подробное описание см. в тексте)
Shore предоставляется пользователям в виде некоторой библиотеки. Пользовательский код (в данном случае – реализация тестового набора TPC-C) компонуется с этой библиотекой, и в нем должна использоваться библиотека потоков управления, которая используется и в Shore. Каждая транзакция выполняется в некотором потоке Shore, имея доступ как к локальным переменным пользовательского пространства, так и к поддерживаемым Shore структурам данных и методам. К OLTP имеют отношения методы, требуемые для создания и заполнения файла базы данных, загрузки его в буферный пул, начала, фиксации или аварийного завершения транзакции, выполнения операций уровня записи, таких как выборка, модификация, создание и удаление, а также связанных с ними операций над первичными и вторичными индексами в виде B-деревьев.
Внутри тела транзакции (ограниченного операторами начала и фиксации) прикладной программист использует методы Shore для доступа к структурам хранения – файлам и индексам, а также к каталогам для их поиска. Во всех структурах данных для хранения информации используются слоттированные страницы (slotted page). Методы Shore выполняются под управлением менеджера транзакций, который тесно взаимодействует со всеми другими компонентами. При доступе к структурам хранения производятся вызовы менеджера журнала, менеджера блокировок и менеджера буферного пула. Эти вызовы всегда проходят через уровень управления параллелизмом, который отслеживает попытки совместного и монопольного доступа к различным ресурсам. Этот уровень не является отдельным модулем; во всем коде все виды доступа к общим ресурсам производятся с синхронизацией на основе защелок. Защелки похожи на блокировки (в том, что они могут быть совместными и монопольными), но они являются легковесными и не сопровождаются механизмом обнаружения синхронизационных тупиков. Прикладной программист должен гарантировать, что синхронизация на основе защелок не приведет к тупику.
Далее авторы обсуждают архитектуру потока управления и приводят подробности блокировок, журнализации и управления пулом буферов.
Поддержка потоков управления. В Shore обеспечивается собственный пакет поддержки невытесняемых потоков управления на пользовательском уровне. Этот пакет был получен на основе пакета NewThreads (первоначально разрабатывавшегося в Университете Вашингтона). В пакете поддержки нитей Shore поддерживается API стандарта POSIX. Этот выбор пакета поддержки потоков управления повлиял на разработку кода и поведение Shore. Поскольку потоки поддерживаются на пользовательском уровне, приложение выполняется в рамках некоторого процесса, объединяющего все нити Shore. Блокировки этого процесса по причине ввода-вывода избегаются путем порождения отдельных процессов, ответственных за устройства ввода-вывода (все процессы общаются через разделяемую память). Тем не менее, приложения не могут напрямую пользоваться преимуществами многоядерных (или SMP) систем, если не входят в распределенные приложения. Однако последний вариант привел бы к избыточным накладным расходам для многоядерного центрального процессора в тех случаях, когда достаточно было бы использовать простой многопотоковый режим на системном уровне.
Поэтому при получении результатов, описываемых в этой статье, использовался однопотоковый режим. В системе, использующей многопотоковый режим работы, требовалось бы большее число команд и циклов процессора на выполнение каждой транзакции (поскольку в дополнение к коду транзакции нужно было бы выполнять еще и код, поддерживающий поток управления). Поскольку основной целью данной статьи является анализ числа команд процессора, потребляемого разными компонентами системы баз данных, отсутствие полной многопотоковой реализации Shore влияет только на общее число команд, выполняемых в исходном варианте системы до начала удаления из нее избыточных компонентов.
Блокировки и журнализация. В Shore реализована стандартная двухфазная схема блокировок для поддержки транзакций со стандартными свойствами ACID. Поддерживаются иерархические блокировки, эскалация которых (record, page, store, volume) по умолчанию выполняется менеджером блокировок. Для каждой транзакции поддерживается список удерживаемых ею блокировок, так что блокировки можно журнализовать при входе транзакции в состояние подготовки и освобождать в конце транзакции. В Shore также реализуется упреждающая запись в журнал (write ahead logging, WAL), для чего требуется тесное взаимодействие между менеджерами журнала и буферов. До выталкивания страницы из буферного пула должна быть вытолкнута соответствующая журнальная запись. Для этого требуется тесное взаимодействие между менеджерами транзакций и журнала. Все три мененджера понимают смысл последовательных номеров журнальных записей (log sequence numbers, LSN), которые служат для идентификации и обнаружения записей в журнале, расстановки в страницах временных меток, определения последней модификации, выполненной данной транзакцией, и нахождения последней журнальной записи, записанной транзакцией. С каждой страницей связывается LSN последней модификации, воздействовавшей на эту страницу. Страница не может быть записана на диск, пока журнальная запись с LSN, ассоциированным с этой страницей, не попадет в стабильную память.
Менеджер буферов. С помощью менеджера буферов все остальные модули (за исключением менеджера журнала) читают и записывают страницы. Страница читается путем вызова метода fix менеджера буферов. Если база данных целиком размещается в основной памяти, любая страница всегда будет располагаться в буферном пуле (в противном случае, если запрашиваемая страница не содержится в буферном пуле, соответствующий поток покидает процессор и ожидает, пока процесс, ответственный за ввод-вывод не поместит эту страницу в буферный пул). Метод fix обновляет отображение между идентификаторами страниц и буферными фреймами и статистическую информацию буферного пула. Для обеспечения согласованности имеется защелка, регулирующая доступ к методу fix. При чтении записи (после того, как ее идентификатор найден путем поиска в индексе) происходит следующее:
- эта запись блокируется (как и содержащая ее страница, посредством иерархической блокировки);
- страница фиксируется в буферном пуле;
- вычисляется смещение от начала этой страницы до начала записи.
Чтение записи выполняется путем вызова методов pin/unpin. Модификация записей выполняется посредством копирования части записи или записи целиком из буферного пула в пользовательское адресное пространство, выполнения там требуемой модификации и передачи новых данных менеджеру хранения данных.
Подробности архитектуры Shore можно найти на Web-сайте проекта. В следующем подразделе описываются дополнительные механизмы и возможности системы; в этом же подразделе обсуждаются модификации системы, произведенные авторами статьи.
3.2 Удаление компонентов Shore
В табл.1 резюмируются свойства и характеристики современных систем OLTP (левый столбец), позволяющие удалить из СУБД некоторые функциональные возможности. Эти оптимизации использовались авторами в качестве руководства по модификации Shore. Из-за тесной интеграции всех менеджеров Shore было невозможно точно разделить все компоненты, чтобы их можно было удалять в произвольном порядке. Наилучшим возможным подходом было удаление функциональных возможностей в порядке, диктуемом структурой кода, что обеспечивало некоторую гибкость. Это порядок был следующим:
- удаление журнализации;
- удаление блокировок ИЛИ защелок;
- удаление защелок ИЛИ блокировок;
- удаление кода, относящегося к менеджеру буферов.
Таблица 1. Возможный набор оптимизаций для OLTP
| Свойства OLTP и новые платформы |
Модификация СУБД |
| архитектуры без поддержки журнала |
удаление журнализации |
| разделение, коммутативность |
удаление блокировок (когда это возможно) |
| поочередное выполнение транзакций |
однопотоковый режим выполнения, удаление блокировок, удаление защелок |
| хранение в основной памяти |
удаление менеджера буферов |
| нетранзакционные базы данных |
устранение учета транзакций |
Кроме того, авторы обнаружили, что в любой точке процесса удаления компонентов возможны следующие оптимизации:
- ускорение и жесткое кодирование логики сравнения ключей B-деревьев, как это делается в большинстве коммерческих систем;
- ускорение поиска в каталогах;
- увеличение размера страницы для устранения потребности в частом распределении памяти (это предполагается указанным выше Шагом 4);
- удаление транзакционных сессий (начала транзакции, фиксации, различных проверок).
Далее описывается подход, примененный авторами для реализации упомянутых действий. Вообще говоря, для удаления из системы некоторого компонента либо добавлялись условные операторы, которые позволяют избежать выполнения кода, относящегося к этому компоненту, либо, если добавление условного оператора приводило к ощутимым накладным расходам, методы переписывались целиком для полного устранения вызовов удаляемого компонента.
Удаление журнализации. Удаление журнализации состоит из трех шагов. Первый шаг заключается в устранении генерации запросов ввода-вывода, а также тех точек работы системы, которые ассоциированы с выполнением этих запросов (позже, на рис. 7 эта модификация называется устранением «дисковой журнализации» («disk log»)). Это достигается путем установки режима групповой фиксации транзакций и увеличения размера буфера журнала в такой степени, чтобы он не выталкивался в течение экспериментов. Потом «закомментированию» подвергаются все функции, используемые для подготовки и записи в буфер журнальных записей (на рис. 7 это называется «журнализацией в основной памяти» «main log»). Последний шаг состоит в добавлении условных операторов в разных местах кода для устранения обработки LNS.
Удаление блокировок (а также и защелок). В ходе своих экспериментов авторы обнаружили, что можно безопасно чередовать порядок удаления блокировок и защелок (если уже удалена журнализация). Поскольку защелки используются и внутри кода обработки блокировок, устранение одного механизма снижает уровень накладных расходов другого. Для удаления блокировок авторы, прежде всего, поменяли все методы менеджера блокировок таким образом, чтобы сразу после обращения из них происходил возврат, как если бы запрос блокировки был успешно обработан, и все проверки блокировок были удовлетворены. После этого они модифицировали методы чтения записей, поиска их в каталоге и доступа к ним через B-дерево. В каждом случае удалялся код, относящийся к неудовлетворенным запросам блокировок.
Удаление защелок (а также и блокировок). Удаление защелок было похоже на удаление блокировок. Сначала код реализации мьютексов был изменен таким образом, чтобы все запросы немедленно удовлетворялись. Затем в код были добавлены условные операторы, позволяющие избежать запросов защелок. Потребовалось заменить методы B-дерева на такие, в которых не используются защелки, поскольку добавление условных операторов вызвало бы существенные накладные расходы по причине тесной интеграции кода защелок в методах B-дерева.
Удаление вызовов менеджера буферов. Наиболее пространной модификацией выполненной авторами, являлось удаление методов менеджера буфера, притом что журнализация, блокировки и защелки уже не действовали. Для создания новых записей авторы отказались от механизма выделения страниц Shore и вместо этого воспользовались стандартной библиотекой malloc. Malloc вызывается для каждой новой записи (записи больше не располагаются в страницах), и для будущего доступа используются указатели. Потенциально распределение памяти может производиться более эффективно, в особенности, если заранее известны размеры размещаемых объектов. Однако дальнейшая оптимизация распределения основной памяти является следующим этапом сокращения накладных расходов, и авторы оставили эту работу на будущее. Оказалось, что невозможно полностью удалить страничный интерфейс к буферным фреймам, поскольку его удаление привело бы к несостоятельности большей части оставшегося кода Shore. Вместо этого авторы ускорили отображение между страницами и буферными фреймами, сократив накладные расходы до минимума. Аналогично, чтение и модификация записи по-прежнему проходит через уровень менеджера буферов, хотя и очень тонкий (на рис. 7 этот набор модификаций называется «страничным доступом» («page access»)).
Прочие оптимизации. Выполнены еще четыре вида оптимизации, которые можно производить в любой точке процесса удаления упомянутых выше компонентов. Они состоят в следующем.
- Ускорение выполнения кода пакета B-дерева путем ручного кодирования сравнения ключей для того распространенного случая, когда ключи являются несжатыми целыми числами (эта оптимизация называется «ключами B-дерева» («Btree keys») на рис. 5-8).
- Ускорения поиска в каталоге за счет использования единого кэша для всех транзакций (эта оптимизация на рис. 7 называется «поиском в каталоге» («dir lookup»)).
- Увеличение размера страницы от 8 до 32 килобайт, что является предельно возможным размером в Shore (на рис. 7 эта оптимизация называется «небольшие страницы» («small page»)). Более крупные страницы, хотя и непригодны для систем баз данных OLTP с хранением баз данных на дисках, могут помочь в системе с хранением баз данных в основной памяти за счет уменьшения числа уровней в B-деревьях (из-за укрупненных узлов), а также позволяют сократить частоту выделения страниц для вновь создаваемых записей. Альтернативным подходом было бы уменьшение размера узла B-дерева до размера блока кэша, как это предлагалось в [RR99], но тогда потребовалось бы отказаться от того, что размер узла B-дерева совпадает с размером страницы Shore, или сделать размер страницы Shore меньшим одного килобайта (что в Shore не допускается).
- Устранение накладных расходов на подготовку и завершение сессии для каждой транзакции, а также на соответствующее отслеживание выполняемых транзакций путем объединения всех транзакций в одну сессию (на рис. 7 это называется «Xactions»).
Полный набор изменений/оптимизаций, произведенных авторами над Shore, а также набор эталонных тестов и документация по организации экспериментов доступны на сайте проекта H-Store.
В следующем разделе авторы переходят к обсуждению вопросов производительности.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

