2005 г.
Многоверсионность данных и управление параллельными транзакциями
Петр Чардин, ф-т ВМиК МГУ
Сокращенный вариант статьи опубликован в журнале "Открытые системы"
Содержание
1. Введение
2. Временные метки (Multiversion Timestamp Ordering, MVTO)
3. Многоверсионный вариант двухфазного протокола синхронизации (Multiversion Two-Phase Locking Protocol, MV2PL)
4. Многоверсионный протокол для транзакций, не изменяющих данные (Multiversion Protocol for Read-Only Transactions, ROMV)
5. MVSG-планировщики
6. Проблемы, возникающие при реализации версионных алгоритмов
7. Заключение
Литература
1. Введение
Идея использования версий для организации управления параллельными транзакциями появилась достаточно давно. Первые работы, посвященные управлению параллельными транзакциями на основе многоверсионности (MultiVersion Concurrency Control, MVCC), появились в конце 70-х – начале 80-х гг. Исходные статьи [1,2,3] были написаны Ридом и коллективом авторов во главе с Байером. Развили эту идею работы Стернса и Розенкранца [10], а также Бернштейна и Гудмена [6]. Настоящая статья представляет собой обзор основных алгоритмов управления параллельными транзакциями, основанных на концепции версионности.
Основная идея MVCC заключается в том, что в базе данных допускается существование нескольких «версий» одного и того же элемента данных. Это позволяет улучшить ряд характеристик СУБД, наиболее важных для приложений, относящихся к следующим категориям:
- Приложения, для которых требуется эффективное выполнение запросов, не изменяющих данные. Чаще всего подобные требования исходят от Web-приложений. Специфика такого рода систем в том, что в подавляющем большинстве транзакций осуществляется лишь выборка данных. При этом система должна минимизировать время ожидания результата пользователем.
- Приложения, ориентированные на поддержку совместной работы. В таких системах для многих людей требуется одновременное выполнение операций чтения и изменения одних и тех же данных. В этом случае использование обычного двухфазного протокола синхронизации транзакций может привести к тому, что почти любое действие будет вызывать появление тупика.
- Приложения реального времени, для которых требуется быстрый отклик и должна поддерживаться высокая степень параллельности. В качестве примера такого приложения рассмотрим систему резервирования авиабилетов. В такой системе число параллельно выполняемых транзакций может быть весьма велико. Типичная транзакция для такой системы проверяет наличие свободных мест на некоторый рейс. Заметим, что конфликт двух транзакций (в одной из которых изменяется количество свободных мест, а во второй выясняется, есть ли еще свободные места на рейс) не обязательно является серьезным. Вместо блокировки данных о рейсе, которая может привести к длительному ожиданию со стороны оператора, можно позволить второй транзакции прочитать старую версию данных. Это не вызовет ошибки, если только первая транзакция не обнуляет число свободных мест.
Многоверсионные методы управления параллельными транзакциями наилучшим образом соответствуют требованиям приложений первого типа. Поскольку такие методы сохраняют версию данных, подлежащих изменению, в большинстве случаев можно производить чтение данных без соответствующей синхронизационной блокировки. Это позволяет упростить логику системы, повысить скорость выполнения запросов на чтение и снизить вероятность появления синхронизационных тупиков.
В приложениях второго и третьего типа требуется возможность параллельной работы с одними и теми же данными. При этом природа требуемых действий такова, что часто требуется читать именно тот элемент данных, который в этот момент находится в процессе изменения. В этом случае применение многоверсионных методов оказывается наиболее удачным. Но помимо чтения изменяемого элемента данных для подобных приложений зачастую требуется параллельное изменение одних и тех же данных. Для этой цели несколько лучше подходят оптимистические методы управления параллельными транзакциями (optimistic concurrency control). Мы не будем их рассматривать в этой статье, однако отметим, что их использование связано с рядом трудностей. Поэтому на практике они используются достаточно редко и применяются главным образом при решении специальных задач.
Заметим, что применение концепции версионности не ограничивается областью СУБД. Управление версиями является одной из основополагающих задач в области систем управления конфигурацией программного обеспечения (Software Configuration Management Systems). Сейчас также ведется интересная работа по применению версий в системах совместной работы над мультимедиа проектами. Доклад [8] на эту тему был сделан на «весеннем коллоквиуме молодых исследователей в области баз данных и информационных систем» (SYRCoDIS’2004). На этом коллоквиуме был сделан еще один доклад, связанный с темой версионности. Работа [9] посвящена версионной модели для распределенных мобильных баз данных. В контексте таких систем приходится решать проблемы, связанные главным образом с медленными и нестабильными каналами связи. Поэтому алгоритмы работы подобных систем несколько сложнее тех, которые будут рассмотрены в этой статье.
Далее приводится обзор многоверсионных алгоритмов управления параллельными транзакциями. Эти алгоритмы широко распространены в области РСУБД. В частности, версионные алгоритмы были реализованы в Oracle, Postgres и MySQL (InnoDB engine). В конце этого обзора мы сравним эти алгоритмы и обсудим трудности, с которыми приходится сталкиваться при их применении. Перед тем, как обратится к конкретным алгоритмам, сделаем два замечания. Мы будем говорить об алгоритмах работы (многоверсионного) планировщика (multiversion scheduler), поскольку именно этот компонент СУБД отвечает за сопоставление конкретных данных логическим операциям над ними. Мы также будем рассматривать только такие планировщики, которые имитируют поведение обособленных транзакций.
К содержанию
2. Временные метки (Multiversion Timestamp Ordering, MVTO)
В [6] Бернштейн и Гудмен пишут, что наиболее ранний известный им алгоритм работы планировщика для версионной СУБД основан на временных метках. Этот планировщик обрабатывает операции таким образом, чтобы суммарный результат выполнения операций был эквивалентен последовательному выполнению транзакций. При этом их порядок задается порядком временных меток, которые получают транзакции во время старта. Временные метки также используются для идентификации версий данных при чтении и модификации – каждая версия получает временную метку той транзакции, которая ее записала. Планировщик не только следит за порядком выполнения действий транзакций, но также отвечает за трансформацию операций над данными в операции над версиями, т.е. каждая операция вида “прочитать элемент данных x”, должна быть преобразована планировщиком в операцию: “прочитать версию y элемента данных x”.
Для описания алгоритма введем ряд обозначений. Временную метку, полученную транзакцией ti в начале ее работы, будем обозначать как ts(ti). Операция чтения транзакцией ti элемента данных x будет обозначаться как ri(x). Для обозначения того, что транзакция ti читает версию элемента данных x, созданную транзакцией tk, будем писать ri(xk). Для обозначения того, что транзакция ti записывает версию элемента данных x, будем использовать запись wi(x).
Теперь опишем алгоритм работы MVTO-планировщика:
- Планировщик преобразует операцию ri(x) в операцию ri(xk), где xk – это версия элемента x, помеченная наибольшей временной меткой ts(tk), такой что ts(tk) <= ts(ti).
- Операция wi(x) обрабатывается планировщиком следующим образом.
- Если планировщик уже обработал действие вида rj(xk), такое что ts(tk) < ts(ti) < ts(tj), то операция wi(x) отменяется, а ti откатывается.
- В противном случае wi(x) преобразуется в wi(xi).
- Завершение транзакции ti (commit) откладывается до того момента, когда завершатся все транзакции, записавшие версии данных, прочитанные ti.
Заметим, что последний шаг нужен только в том случае, когда мы хотим предотвратить “грязное” чтение. Теперь рассмотрим пример работы такого планировщика:
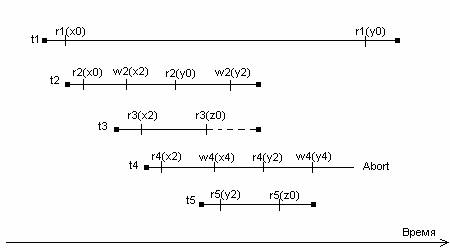
Рис 1. Пример работы планировщика MVTO
Взаимодействие транзакций t1 и t2 отличным образом иллюстрирует плюсы использования версий. В случае подобного плана выполнения транзакций при отсутствии версионности мы получили бы классический случай чтения несогласованных данных. Однако в нашем примере эта ситуация вполне приемлема из-за того, что первая транзакция читает «старую» версию элемента данных y. Транзакция t3 ожидает окончания работы t2 перед собственным завершением (на рисунке это показано пунктирной линией). Это происходит потому, что t3 прочитала незавершенную (uncommited) версию x2.
Транзакция t4 является примером “поздней” транзакции изменения (“late” writer). Она создает версию y4, в то время как транзакция t5 (стартовавшая позднее) уже прочитала более раннюю версию y2. То есть транзакция t5 “не видит” некоторых изменений, внесенных t4. Таким образом, сериализация транзакций в порядке получения ими временных меток становится невозможной. Именно поэтому мы вынуждены произвести откат. Это поясняет пункт 2a алгоритма.
К содержанию
3. Многоверсионный вариант двухфазного протокола синхронизации (Multiversion Two-Phase Locking Protocol, MV2PL)
В этом разделе мы рассмотрим вариант широко известного двухфазного протокола синхронизации транзакций (2PL), адаптированного для применения в версионной базе данных.
Рассматривая алгоритм работы MVTO-планировщика, мы использовали ряд терминов, которые теперь определим строго. Будем различать три типа версии элемента данных.
- Завершенные версии (commited versions). Эти версии, созданные теми транзакциями, которые уже успешно закончили свою работу.
- Текущая версия (current version). Это последняя из завершенных версий.
- Незавершенные версии (uncommited versions). Это версии, созданные теми транзакциями, которые еще находятся в работе.
В MV2PL планировщик следит за тем, чтобы в каждый момент времени существовало не более одной незавершенной версии. В зависимости от того, позволяется ли мы транзакциям читать незавершенные версии данных, различаются два варианта этого алгоритма. Мы будем одновременно рассматривать оба варианта MV2PL (с чтением незавершенных данных и без него). Сначала рассмотрим схему работы MV2PL в предположении, что все версии элементов данных сохраняются в базе. Затем обсудим вариант этого алгоритма, в котором допускается одновременное существование не более двух версий одного и того же элемента данных.
Все операции, которые обрабатывает планировщик, разделяются на два класса: обычные операции и финальные операции. Под финальной операцией понимается последняя операция транзакции перед ее завершением или же сама операция завершения (commit). Обе интерпретации допустимы. При этом каждая отдельная операция транзакции обрабатывается следующим образом.
- Если операция не является финальной, то:
- операция r(x) выполняется незамедлительно; ей сопоставляется последняя из завершенных к данному моменту версий x (или последняя из незавершенных версий x во втором варианте алгоритма);
- операция w(x) выполняется только после завершения транзакции, записавшей последнюю версию x.
- Если операция является финальной для транзакции ti то она откладывается до тех пор, пока не завершатся следующие транзакции:
- все транзакции tj, прочитавшие текущую версию данных, которую должна заменить версия, записанная ti (таким образом устраняется возможность неповторяющегося чтения);
- все транзакции tj, которые записали версии, прочитанные ti (это требуется только во втором варианте алгоритма).
Как видно, этот алгоритм ничего не говорит о числе версий одного и того же элемента, которые могут одновременно существовать в базе данных. Это вызывает проблемы с хранением версий. Во-первых, они могут занимать слишком много места (легко вообразить себе ситуацию, когда объем старых версий становится в несколько раз больше, чем объем всей “текущей” базы данных). Во-вторых, возникают трудности с размещением этих “старых” данных. Учитывая, что количество версий заранее не известно, сложно придумать эффективную структуру их хранения, которая бы не вызывала заметных накладных расходов. И, наконец, такая система слишком сложна в реализации.
Вероятно, именно из-за этих проблем на практике чаще всего используется протокол 2V2PL, предложенный впервые в работе Байера и др.[3]. В этом протоколе возможно одновременное существование двух версий элемента данных: одной текущей версии данных и не более одной незавершенной. Такая организация версий выгодна, прежде всего, для транзакций, выполняющих операцию чтения.
В 2V2PL используются три типа блокировок. Каждая блокировка удерживается до конца транзакции.
- rl (read lock): эта блокировка устанавливается на текущую версию элемента данных x непосредственно перед ее прочтением;
- wl (write lock): блокировка устанавливается перед тем, как создать новую (незавершенную) версию элемента x;
- cl (commit lock): блокировка устанавливается перед выполнением последней операции транзакции (обычно перед операцией commit) по отношению к каждому элементу данных, который она записала. Эта блокировка играет роль монопольной блокировки для обычного протокола 2PL. Она необходима для корректной смены версий.
Приведем таблицу совместимости блокировок для 2V2PL:
| |
rl(x) |
wl(x) |
cl(x) |
rl(x) |
+ |
+ |
- |
wl(x) |
+ |
- |
- |
cl(x) |
- |
- |
- |
Очевидно, что использование блокировок rl и wl обеспечивает выполнение правил (1)a и (1)b алгоритма MV2PL (с учетом того, что одновременно позволяется поддерживать не более одной незавершенной версии). Блокировка cl, в свою очередь, обеспечивает выполнение правил (2)a и (2)b.
К содержанию
4. Многоверсионный протокол для транзакций, не изменяющих данные (Multiversion Protocol for Read-Only Transactions, ROMV)
В работе многих приложений преобладают транзакции, не изменяющие данные (read-only transactions). Такие приложения считывают и анализируют большие объемы данных. В случае наличия хотя бы небольшого числа параллельно выполняемых транзакций, производящих изменения, компонент, который отвечает за управление параллельными транзакциями, должен обеспечить согласованность прочитанных данных. В случае использования алгоритмов планирования без поддержки версий такие долговременные транзакции могут привести к чрезвычайному падению производительности системы. Например, при использовании 2PL станет крайне велика вероятность блокировки транзакций, производящих обновления данных. В результате у этих транзакций будет иметься очень большое время отклика.
Многоверсионные алгоритмы позволяют избежать подобных проблем благодаря тому, что транзакция, вносящая изменения в базу данных, не конфликтует с транзакциями чтения. Но в то же время многоверсионные алгоритмы обычно сложны в реализации и запросы к версионным СУБД вызывают заметные накладные расходы.
Рассматриваемый в этом разделе протокол ROMV является гибридным, основанным на MVTO и 2PL. Он ориентирован на приложения, для которых наиболее важна скорость выполнения транзакций, не производящих изменений данных. Заметим, в литературе отсутствует согласие по поводу названий алгоритмов. Так, Пол Боббер и Майкл Кэри в [7] называют обсуждаемый здесь протокол MV2PL. Мы следуем терминологии, принятой в книге Вейкума и Воссена [4]. В ней под термином MV2PL понимается протокол, рассмотренный в разд. 3. Интересно, что после этого Вейкум и Воссен ссылаются на статью Боббера и Кэри.
ROMV-планировщик разделяет все транзакции во время их создания на две группы – запросы (queries) и транзакции, изменяющие данные (update transactions). Соответственно, транзакции разных типов обрабатываются по-разному. Такой протокол оказывается проще в реализации и позволяет получить большую часть выгод, предоставляемых чисто версионными протоколами.
Транзакции обрабатываются следующим образом.
- Транзакции, модифицирующие данные, выполняются в соответствием с протоколом S2PL. Этот протокол является вариантом 2PL. В нем все монопольные блокировки отпускаются лишь в конце транзакции. Каждая операция, изменяющая элемент данных, создает новую версию этого элемента. При завершении транзакции каждая такая версия помечается временной меткой, соответствующей времени завершения транзакции.
- Запросы (read-only transactions) обрабатываются подобно тому, как это происходит в протоколе MVTO. Каждому запросу также ставится в соответствие временная метка. Но в данном случае она соответствует времени начала транзакции. При выборе версии для чтения запрос выбирает последнюю, завершенную к моменту старта запроса версию.
Несмотря на идейную простоту, этот подход вызывает некоторые сложности при реализации. Например, он требует создания специального сборщика мусора. Этот компонент СУБД должен удалять ненужные версии данных. Простейший сборщик мусора удаляет все версии (не являющиеся текущими), значения временных меток которых меньше времени начала старейшей из активных только читающих транзакций.
К содержанию
5. MVSG-планировщики
Последний рассматриваемый нами класс многоверсионных алгоритмов планирования обобщает широко известную моноверсионную технику SGT (Serialization Graph Testing). Планировщики, основанные на SGT, работают по следующему принципу.
Планировщик поддерживает граф конфликтов, в котором вершины и дуги добавляются динамически в зависимости от операций, которые получает на вход планировщик. При этом конфликтующими называются любые две операции над одним и тем же элементом данных, если хотя бы одна из них является операцией модификации. Другими словами, для конфликтующих операций существенен порядок их выполнения. Таким образом, планирование конфликтующих операций накладывает ограничение на порядок сериализации транзакций. Эти ограничения и выражает граф конфликтов. Теперь рассмотрим, как происходит планирование очередной операции pi(x) с помощью SGT-планировщика.
- Если это первая операция транзакции ti, поступившая планировщику, то создается новый узел в графе сериализации.
- В граф добавляются дуги вида (tj, ti) для каждой запланированной ранее операции qj(x) (i ≠ j), конфликтующей с pi(x). Теперь возможны два варианта:
- Результирующий граф содержит циклы. В этом случае транзакция ti откатывается.
- Полученный граф ацикличен. В этом случае действие добавляется к списку запланированных.
Остановимся подробнее на пункте 2a. Что означает то, что в графе появился цикл? Это означает, что полученное расписание больше не будет сериализуемым. Это утверждение становится очевидным, если заметить, что дуга из ti в tj фиксирует порядок следования транзакций в эквивалентном последовательном расписании. Т.е. результат нашего расписания должен быть таким же, как и последовательное выполнения сначала всех действий транзакции ti, а затем tj. Поскольку транзакция не может следовать раньше самой себя, граф с циклами не будет иметь соответствующего последовательного расписания.
Теперь мы можем перейти к более общему многоверсионному случаю. Cоответственно, будем рассматривать многоверсионный граф конфликтов (MVSG). Покажем что ограничения, которые мы накладывали на граф сериализации в моноверсионним случае, недостаточны. Рассмотрим следующий пример:
S = w1[x1]w1[y1]r2[y1]r3[x1]w2[z2]r3[z2]w2[x2]
Граф, составленный по правилам алгоритма SGT, будет содержать дуги (t1, t2), (t1, t3), (t2, t3):
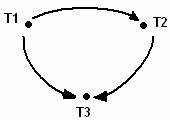
Рис 2. Граф сериализации для плана S, составленный по правилам SGT.
Этот граф ацикличен. Однако для S не существует эквивалентного моноверсионного последовательного расписания. Действительно, Поскольку t3 читает версию x, записанную t1 (r3[x1]), то t2, которая тоже пишет элемент x (w2[x2]), должна следовать в моноверсионном последовательном расписании либо после t3, либо перед t1. Но первый вариант невозможен из-за шага r3[z2], а второй – из-за r2[y1].
Таким образом, многоверсионный планировщик должен также специальным способом проверять согласованность шагов, создающих новые версии. Для этого в граф добавляются дополнительные дуги, которые фиксируют “позиции записи” в соответствующем последовательном расписании.
Теперь мы можем описать общую схему работы MVSG-планировщика. Когда очередной шаг pi(x) поступает планировщику, он предпринимает следующие действия:
- Если это первое действие транзакции ti, поступившее планировщику, то соответствующий узел добавляется к графу конфликтов.
- Если это шаг ri(x), то выбирается подходящая версия xj, и в граф добавляется дуга (tj, ti) (поскольку, согласно нашим обозначениям, версию xj записала транзакция tj). Для всех других k, таких что wk(xk) является шагом tk, в граф добавляется либо дуга (tk, tj), либо дуга (ti, tk). В этом и состоит выбор “позиции записи”.
- Если это шаг wi(xi), то для каждой транзакции tk, которая прочитала, скажем, версию xj, нужно добавить либо дугу (ti, tj), либо дугу (tk, ti). Т.е. ti должна следовать либо до tj, либо после tk в соответствующем последовательном расписании.
- Если граф остается ацикличным, то изменения в графе фиксируются, а действие добавляется к списку запланированных. Иначе транзакция откатывается.
Следует обратить внимание на “выборе подходящей версии” для чтения. Версия xj не является подходящей в двух случаях: во-первых, если существует путь из ti в tj (т.е. tj следует после ti по порядку сериализации); во-вторых, если существует путь (tj, tk, ti), где tk пишет x – wk(xk). В этих случаях отсутствует способ выбора места для wk(xk) в эквивалентном моноверсионном последовательном расписании.
Как уже отмечалось, выбор дуги для добавления в графе – “(ti, tj) либо (tk, ti)” – по сути, является выбором “позиции записи”. Выбирается порядок следования других транзакций, которые пишут x. В некоторых случаях будет иметься несколько альтернативных путей, а в некоторых уже существующие дуги не оставят возможности выбора.
В рассмотренном нами примере в графе образуется цикл на последнем шаге – w2[x2]. Выполняя этот шаг, мы должны будем согласно правилу 3 алгоритма добавить одну из дуг – (t2, t1) или (t3, t2). Обе ведут к образованию цикла.
Это семейство алгоритмов описано в книге [11] и статье [12]. Оно также описано в книге [4] под названием MVSGT. Заметим, что его описание в [4] весьма путано. Кроме того, сам термин MVSGT впервые вводится Веикумом и Воссеном именно в этой книге. Чтобы прояснить ситуацию вокруг MVSGT, автору даже пришлось связаться с Готфридом Воссеном, который любезно согласился предоставить материалы, использованные им при подготовке книги.
К содержанию
6. Проблемы, возникающие при реализации версионных алгоритмов
Мы рассмотрели основные алгоритмы, описывающие работу подсистемы управления параллельными заданиями в многоверсионной СУБД. Однако совсем не все рассмотренные алгоритмы активно применяются на практике. Какие же трудности встают на пути создателей многоверсионной СУБД?
Возникают проблемы здесь двух типов. Во-первых, требуется устроить физическую организацию данных так, чтобы можно было обеспечить эффективное управление версиями. Здесь следует учесть и разрастание объема базы данных при добавлении версий. То есть в идеале при организации данных должны учитываться возможные ограничения на количество версий. Заметим, что на практике ограничение на число версий зачастую отсутствует. Вместо этого система просто удаляет ненужные версии по мере завершения соответствующих транзакций.
Подобная ситуация наблюдается в СУБД MySQL. Речь идет о той конфигурации системы, при которой низкоуровневая работа с таблицами возлагается на подсистему InnoDB. В InnoDB используется одна из разновидностей протокола ROMV. Поскольку в этом протоколе все транзакции, вносящие изменения в базу данных, создают новые версии данных, то проблема ограничения числа версий стоит так же остро, как и в большинстве других версионных алгоритмов. В InnoDB удаление версий происходит в тот момент, когда они оказываются ненужными ни одной из активных транзакций. Таким образом, ответственность за поддержание умеренного количества версий ложится на пользователей СУБД. Они должен следить за тем, чтобы в системе не появлялись «длинные транзакции». В противном случае версии будут оставаться в базе данных, что приведет к нефункциональному увеличению ее объема.
Вторая проблема, возникающая при добавлении версий в архитектуру СУБД, имеет логический характер. Наличие версий должно приниматься во внимание во многих компонентах СУБД, помимо планировщика. В связи с этим, необходимо обеспечить корректное взаимодействие этих компнентов. Очевидным образом, с учетом версий должно происходить поддержание поисковых структур. С учетом версий должна строиться и журнализация. Более того, поскольку и журнал и версии содержат информацию о старом состоянии базы данных, возможно объединение этих сущностей.
Еще одной подсистема СУБД, которая существенным образом меняется при добавлении версий, является подсистема управления памятью. Поскольку много версий одного и того же элемента данных могут использоваться параллельно, необходимо эффективное размещение версий в основной памяти. Это требование трудно, если заранее неизвестно максимальное число версий, допустимых для одного элемента данных.
Все эти трудности проявляются различным образом в зависимости от выбора одного из рассмотренных нами алгоритмов. Такая зависимость объясняется тем, что эти алгоритмы фиксируют порядок создания и поддержания версий. Поэтому они влияют как на физическую сторону организации многоверсионной СУБД, так и на логическую.
На практике наиболее часто используются протоколы ROMV и 2V2PL. С одной стороны, эти протоколы достаточно просты в реализации, а с другой предоставляют пользователю большую часть выгод версионной СУБД. В случае протокола 2V2PL существенную роль также играет его сходство с обычным 2PL. Помимо этого, в 2V2PL решается проблема ограничения числа версий.
Сложность решения этой проблемы в случае протокола MVTO, по-видимому, служит одной из причин его малой распространенности. Можно предположить, что та же причина объясняет небольшое количество реализаций, использующих MV2PL. Автору также не известно о реализациях, применяющих MVSG-планировщики.
К содержанию
7. Заключение
В настоящей работе был сделан обзор наиболее известных версионных алгоритмов, применяемых для организации управления параллельными заданиями. Также были рассмотрены основные проблемы, возникающие при внедрении этих методов.
Обзор был подготовлен в процессе поиска возможного пути организации версий в XML СУБД Sedna, разрабатываемой в ИСП РАН группой MODIS.
Автор также выражает глубокую признательность Готфриду Воссену за материалы, предоставленные во время подготовки обзора, и Сергею Кузнецову за многочисленные советы и замечания, сделанные в ходе работы.
К содержанию
Литература
1. Reed, D. Naming and Synchronization in a Decentralized Computer System, Ph.D. Thesis, MIT, September 1978.
2. Reed, D. Implementing atomic actions on decentralized data. ACM Trans. Comp. Syst. 1, 1 (Feb. 1983), 3-23.
3. Bayer, R., Heller, H., and Reiser, A. Parallelism and recovery in database systems. ACM Trans. Database Syst. 5, 2 (June 1980), 139-156.
4. Weikum, G., Vossen, G. Transactional information systems. Morgan Kaufmann, 2002.
5. Unland, R. Optimistic Concurrency Control Revisited. Arbeitsberichte des Instituts für Wirtschaftsinformatik, 1994.
6. Bernstein, P. A., and N. Goodman. Multiversion concurrency control – theory and algorithms. ACM Transactions on Database Systems, Vol. 8, No. 4, December 1983, Pages 465-483.
7. Bober, P.M., and M.J. Carey. Multiversion Query Locking. Proceedings of the 18th VLDB Conference Vancouver, British Columbia, Canada, 1992.
8. Proskurnin, O. Concurrent Video: Versioning Concepts. Proceedings of the Spring Young Researcher’s Colloquium on Database and Information Systems SYRCoDIS, St.-Petersburg, Russia, 2004.
9. Yakovlev, A. A Multi-Version Concurrency Control Model for Distributed Mobile Databases. Proceedings of the Spring Young Researcher’s Colloquium on Database and Information Systems SYRCoDIS, St.-Petersburg, Russia, 2004.
10. Stearns, R. E., and Rosenkrantz, D. J. Distributed database concurrency control using before-values. In Proc. 1981 ACM SIGMOD Conf. Management of Data, ACM, New York, 1981, pp. 74-83.
11. Papadimitriou, C. The theory of database concurrency control. Computer Science Press, 1986.
12. Hadzliacos. T. Serialization graph algorithms for multiversion concurrency control. Proceedings of the seventh ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems, 1988. pp. 135-141.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
