2009 г.
Сравнение подходов к крупномасштабному анализу данных
Эндрю Павло, Эрик Паулсон, Александр Разин, Дэниэль Абади, Дэвид Девитт, Сэмюэль Мэдден, Майкл Стоунбрейкер
Пересказ: Сергей Кузнецов
Оригинал: Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt, Samuel Madden, Michael Stonebraker. A Comparison of Approaches to Large-Scale Data Analysis. Proceedings of the 35th SIGMOD International Conference on Management of Data, 2009, Providence, Rhode Island, USA
Назад Содержание Вперёд
4.3. Аналитические задачи
Для изучения случаев более сложного использования систем обоих типов были разработаны четыре задачи, относящиеся к обработке HTML-документов. Сначала генерировалась коллекция случайных HTML-документов, похожих на те, которые мог бы найти поисковый робот. Каждому узлу назначался набор из 600000 уникальных HTML-документов, каждый со своим уникальным URL. В каждом документе случайным образом с использованием распределения Зипфа генерировались ссылки на другие страницы.
Также генерировались два дополнительных набора данных, предназначенных для моделирования файлов журналов трафика HTML-сервера. Эти наборы данных состояли из значений, извлеченных из HTML-документов, а также нескольких случайным образом сгенерированных атрибутов. Эти три таблицы имеют следующую схему:
CREATE TABLE Documents (
url VARCHAR(100)
PRIMARY KEY,
contents TEXT );
CREATE TABLE Rankings (
pageURL VARCHAR(100)
PRIMARY KEY,
pageRank INT,
avgDuration INT );
CREATE TABLE UserVisits (
sourceIP VARCHAR(16),
destURL VARCHAR(100),
visitDate DATE,
adRevenue FLOAT,
userAgent VARCHAR(64),
countryCode VARCHAR(3),
languageCode VARCHAR(6),
searchWord VARCHAR(32),
duration INT );
Генератор файлов создавал уникальные файлы со 155 миллионами записей UserVisits (20 гигабайт на узел) и 18 миллионами записей Rankings (1 гигабайт на узел) в каждом узле. Поля visitDate, adRevenue и sourceIP подбирались равномерным образом из соответствующих диапазонов значений. Все остальные поля подбирались равномерным образом из наборов данных, представляющих собой выборки из реальных данных. Каждый файл данных хранился в каждом узле в виде текстового файла со столбцами, разделяемыми специальными символами.
4.3.1. Загрузка данных
Опишем процедуры загрузки наборов данных UserVisits и Rankings. По соображениям, обсуждаемым в п. 4.3.5, только для Hadoop требовалось непосредственно загружать файлы Documents во внутреннюю систему хранения. И в СУБД-X, и в Vertica выполнялась UDF, которая обрабатывала Documents в каждом узле во время выполнения и загружала данные во временную таблицу. Накладные расходы этого подхода учитываются во времени прогона тестов, а не во времени загрузки данных. Поэтому результаты загрузки этого набора данных в статье не приводятся.
Hadoop: В отличие от набора данных задачи Grep, который загружался в HDFS в неизменном виде, наборы данных UserVisits и Rankings требовалось модифицировать, чтобы первый и второй столбцы разделялись символом табуляции, а все остальные поля каждой строки – некоторым уникальным разделителем полей. Поскольку в модели MR нет схем, для обеспечения доступа к различным атрибутам во время выполнения функции Map и Reduce в каждой задаче должны вручную разбивать значение в массив строк, руководствуясь символом-разделителем.
Был написал специальный загрузчик данных, выполняемый параллельно в каждом узле; этот загрузчик считывал строки наборов данных, подготавливал данные, как требовалось, и затем записывал полученный кортеж в плоский текстовый файл в HDFS. Загрузка данных таким способом происходила примерно в три раза медленнее, чем если бы использовалась утилита командной строки, но зато не потребовалось писать для Hadoop специальные обработчики ввода; имеется возможность использовать в MR-программах интерфейс KeyValueTextInputFormat, позволяющий автоматически расщеплять строки текстовых файлов на пары «ключ/значение» по символу табуляции. Было обнаружено, что использование других вариантов форматирования данных, таких как SequenceFileInputFormat или специальные Writable tuples, замедляет и загрузку, и исполнение программы.
СУБД-X: Использовались те же процедуры загрузки, что обсуждались в подразделе 4.2. Таблица Rankings хэш-разделялась по узлам кластера по значениям pageURL, и данные в каждом узле сортировались по значениям pageRank. Аналогично, таблица UserVisits хэш-разделялась по destinationURL и сортировалась в каждом узле по visitDate.
Vertica: Аналогично СУБД-X, в Vertica использовались те же команды массовой загрузки, что обсуждались в подразделе 4.2, и таблицы UserVisits и Rankings сортировались по столбцам visitDate и pageRank соответственно.
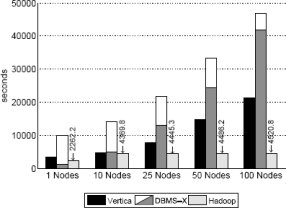
Рис. 3. Время загрузки – набор данных UserVisits (20 гигабайт на узел)
Результаты и обсуждение: Поскольку результаты загрузки наборов данных UserVisits и Rankings схожи, на рис. 3 приводятся только результаты загрузки более крупного набора UserVisits. Как и при загрузке набора данных Grep в 535 мегабайт на узел (рис. 1), время загрузки для каждой системы возрастает пропорционально числу используемых узлов.
4.3.2. Задача Selection
Задача Selection – это легковесный фильтр, предназначенный для нахождения значений pageURL в таблице Rankings (1 гигабайт на узел), для которых значение pageRank превышает заданное пользователем пороговое значение. В описываемых экспериментах в качестве значения порогового параметра использовалось 10, что приводило к выборке примерно 36000 записей в каждом узле.
Команды SQL: В обеих СУБД задача выборки исполнялась с использованием следующего простого оператора SQL:
SELECT pageURL, pageRank
FROM Rankings WHERE pageRank > X;
Программа MapReduce: В MR-программе использовалась одна функция Map, которая расщепляла входное значение на основе поля-разделителя и выводила значения pageURL и pageRank в качестве новой пары «ключ/значение», если значение pageRank превышало заданное пороговое значение. Для выполнения этой задачи не требуется функция Reduce, поскольку все значения pageURL в наборе данных Rankings уникальны во всех узлах.
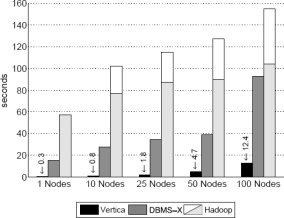
Рис. 6. Результаты задачи Selection
Результаты и обсуждение: Как уже говорилось по поводу задачи Grep, результаты этих экспериментов, показанные на рис. 6, снова демонстрируют, что параллельные СУБД значительно превосходят Hadoop на всех уровнях масштабирования кластера. Хотя относительная производительность всех систем деградирует при возрастании числа узлов и общего объема данных, на Hadoop это действует сильнее всего. Например, время выполнения в экспериментах с одним узлом и 10 узлами различается почти на 50%. Это опять объясняется возрастающими накладными расходами на запуск системы при добавлении узлов к кластеру. При выполнении быстро обрабатываемых запросов эти накладные расходы занимают значительную часть общего времени выполнения.
Еще одной важной причиной, по которой параллельные системы могут превосходить Hadoop, является то, что и в Vertica, и в СУБД-X используется индекс на столбце pageRank, и таблица Rankings сохраняется уже отсортированной по значениям pageRank. Поэтому выполнение этого запроса тривиально. Следует также заметить, что хотя у Vertica абсолютное время выполнения задачи остается небольшим, относительная производительность системы деградирует при увеличении числа узлов. И это несмотря на тот факт, что в каждом узле запрос продолжает выполняться одно и то же время (около 170 микросекунд). Но, поскольку узлы завершают выполнение запроса настолько быстро, система становится заполненной управляющими сообщениями, передаваемыми из слишком многих узлов, и обработка этих сообщений занимает большее время. В Vertica используется надежный механизм передачи сообщений для распределения запроса по узлам и обработки протокола фиксации [4], и этот механизм порождает значительные накладные расходы при использовании для обработки запросов более нескольких десятков узлов.
4.3.3. Задача Aggregation
В следующей задаче требуется, чтобы каждая из систем вычислила суммарное значение adRevenue для каждой группы кортежей таблицы UserVisits (20 гигабайт на узел) с одним и тем же значением столбца sourceIP. Кроме того, запускался вариант этого запроса, в котором группировка производилась по первым семи символам значений столбца sourceIP, чтобы выяснить, как влияет на эффективность выполнения запроса сокращение числа групп. Эта задача была разработана для определения эффективности параллельной аналитики над единственной только читаемой таблицей. В этом случае для вычисления окончательного результата узлам требуется обмениваться промежуточными данными. Независимо от числа узлов в кластере эта задача всегда производит 2.5 миллиона записей (53 мегабайта); при выполнении варианта запроса с меньшим числом групп производится 2000 записей (24 килобайта).
Команды SQL: команды SQL для вычисления общего значения adRevenue просты:
SELECT sourceIP, SUM(adRevenue)
FROM UserVisits GROUP BY sourceIP;
Запрос с сокращенным числом групп формулируется следующим образом:
SELECT SUBSTR(sourceIP, 1, 7), SUM(adRevenue)
FROM UserVisits GROUP BY SUBSTR(sourceIP, 1, 7);
Программа MapReduce: В отличие от предыдущих задач, MR-программа для этой задачи включает и функцию Map, и функцию Reduce. Функция Map сначала расщепляет сходное значение в соответствии с разделителем, а затем выводит значения поля sourceIP (бывшего ключом во входной паре) и поля adRevenue как новую пару «ключ/значение». Для вариантного запроса используются только первые семь символов sourceIP (представляющие первые два октета адреса, каждый из которых хранится в виде трех цифр). Эти две функции Map используют одну и ту же функцию Reduce, которая просто складывает все значения adRevenue с одним и тем же значением sourceIP, а затем выводит префикс и суммарное значение adRevenue. Для выполнения предварительной агрегации до передачи данных экземплярам Reduce также использовалось средство MR Combine, что позволило повысить эффективность выполнения первого запроса в восемь раз [8].
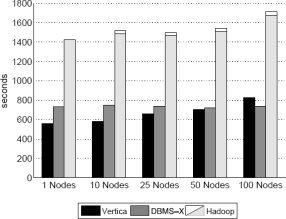
Рис. 7. Результаты задачи Aggregation (2.5 миллиона групп)
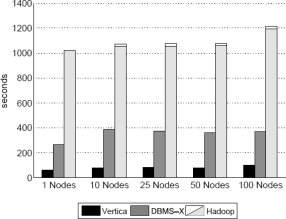
Рис. 8. Результаты задачи Aggregation (2000 групп)
Результаты и обсуждение: результаты экспериментов с задачей агрегации, представленные на рис. 7 и 8, снова показывают превосходство двух СУБД над Hadoop. СУБД выполняют эти запросы путем сканирования в каждом узле соответствующей локальной таблицы, извлечения значений полей sourceIP и adRevenue и выполнения локальной группировки. Затем эти локальные группы объединяются координатором запроса, который выводит результаты пользователю. Результаты на рис. 7 демонстрируют, что при большом числе групп две СУБД показывают примерно одинаковую производительность, поскольку значительная часть времени тратится на передачу большого числа локальных групп и их объединение координатором. В экспериментах с меньшим числом узлов Vertica работает немного лучше, поскольку в ней читается меньше данных (имеется прямой доступ к столбцам sourceIP и adRevenue), но при увеличении числа узлов система слегка замедляется.
Результаты на рис. 8 показывают, что поколоночную систему выгоднее использовать при обработке для решения данной задачи меньшего числа групп. Это объясняется тем, что значения двух требуемых столбцов (sourceIP и adRevenue) состоят всего из 20 байт, а весь кортеж таблицы UserVisits занимает более 200 байт. Поэтому при наличии относительно небольшого числа групп, которые требуется объединять, коммуникационные расходы существенно ниже, чем при выполнении первого варианта запроса. Таким образом, Vertica обгоняет по производительности две другие системы за счет того, что не читает неиспользуемые части кортежей UserVisits. Заметим, что время выполнения запроса на всех системах почти одно и тоже для любого числа узлов (с учетом того, что Vertica при росте числа узлов слегка замедляется). Поскольку в этой задаче требуется, чтобы система просматривала весь набор данных, время выполнения всегда определяется эффективностью последовательного сканирования и сетевыми накладными расходами каждого узла.
4.3.4. Задача Join
Задача соединения состоит из двух подзадач, выполняющих сложные вычисления над двумя наборами данных. В первой части задачи каждая система должна найти sourceIP, которые принесли наибольшую выручку в заданном интервале времени. После образования этих промежуточных записей система должна вычислить среднее значение pageRank для всех страниц, посещенных в течение этого интервала. В экспериментах использовался интервал от 15 до 22 января 2000 г., которому соответствует примерно 134000 записей в таблице UserVisits.
Основной особенностью этой задачи является то, что она должна использовать два разных набора данных и соединить их для нахождения пар записей Ranking и UserVisits, у которых совпадают значения pageURL и destURL. Для решения этой задачи в каждой системе приходится использовать достаточно сложные операции над данными большого объема. Результаты эффективности также позволяют установить, насколько хорошо оптимизаторы запросов СУБД производят эффективные планы выполнения запросов.
Команды SQL: В отличие от сложной MR-программы, описываемой ниже, для выполнения задачи на СУБД требуются только два довольно простых запроса. Первый оператор создает временную таблицу и использует ее для сохранения результатов оператора SELECT, который выполняет соединение таблиц UserVisits и Ranking и вычисляет агрегаты. После заполнения этой таблицы тривиальным образом используется второй запрос, выводящий запись с наибольшим значением поля totalRevenue.
SELECT INTO Temp sourceIP,
AVG(pageRank) as avgPageRank,
SUM(adRevenue) as totalRevenue
FROM Rankings AS R, UserVisits AS UV
WHERE R.pageURL = UV.destURL
AND UV.visitDate BETWEEN Date(‘2000-01-15’)
AND Date(‘2000-01-22’)
GROUP BY UV.sourceIP;
SELECT sourceIP, totalRevenue, avgPageRank
FROM Temp
ORDER BY totalRevenue DESC LIMIT 1;
Программа MapReduce: Поскольку в модели MR отсутствует внутренняя возможность соединять два или несколько разных наборов данных, MR-программу, реализующую задачу соединения, приходится разбивать на три разные фазы. Все эти фазы реализуются вместе, как одна MR-программа в Hadoop, но следующая фаза не начинает выполняться, пока не завершится предыдущая.
Фаза 1 – На первой фазе отсеиваются записи UserVisits, которые выходят за пределы требуемого временного интервала, и оставшиеся записи соединяются с записями из файла Rankings. Вначале MR-программе в качестве входных данных даются все файлы данных UserVisits и Rankings.
Функция Map Для каждой входной пары «ключ/значение» определяется тип записи путем подсчета числа полей, получаемых после расщепления значения по разделителям. Если это запись UserVisits, то к ней применяется фильтр, основанный на предикате вхождения во временной интервал. Эти отобранные записи выводятся с составными ключами вида (destURL, K1), где K1 указывает, что это запись UserVisits. Все записи Rankings выводятся с составными ключами вида (pageURL, K2), где K2 указывает, что это запись Rankings. Выходные записи заново разделяются с использованием поставляемой пользователем функции разделения, которая хэширует только часть URL составного ключа.
Функция Reduce: На входе функция Reduce получает единый отсортированный поток записей в порядке значений URL. Для каждого URL соответствующие ему значения разделяются на два множества на основе компонента-тега составного ключа. Затем функция образует декартово произведение этих двух множеств для вычисления соединения и выводит новые пары «ключ/значение» с ключом sourceIP и значением – кортежем (pageURL, pageRank, adRevenue).
Фаза 2 – На следующей фазе вычисляется суммарное значение adRevenue и среднее значение pageRank на основе значения ключа sourceIP записей, сгенерированных на Фазе 1. На второй фазе функция Reduce используется для того, чтобы собрать в одном узле все записи с одним и тем же значением sourceIP. Для доставки записей прямо в процесс разбиения используется тождественная функция Map из API Hadoop [1, 8].
Функция Reduce: Для каждого значения sourceIP эта функция складывает соответствующие значения adRevenue и вычисляет среднее значение pageRank, оставляя запись с максимальным значением суммы adRevenue. Каждый экземпляр Reduce выводит единственную запись с ключом sourceIP и значением – кортежем вида (avgPageRank, totalRevenue).
Фаза 3 – На этой заключительной фазе снова нужно определить только одну функцию Reduce, которая использует выходные данные предыдущей фазы для получения записи с наибольшим значением totalRevenue. Выполняется только один экземпляр этой функции в одном узле – просматриваются все записи, полученные на Фазе 2, и находится целевая запись.
Функция Reduce: Эта функция обрабатывает все пары «ключ/значение» и отслеживает запись с наибольшим значением поля totalRevenue. Поскольку от API Hadoop совсем не просто узнать общее число записей, которые будут обрабатываться экземпляром Reduce, функция Reduce никак не может узнать, что обрабатывает последнюю запись. Поэтому в своей реализации Reduce авторы переопределили заключительный метод обратного вызова, чтобы MR-программа выводила требуемую запись прямо перед своим завершением.
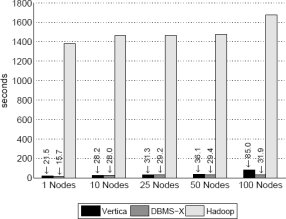
Рис. 9. Результаты задачи Join
Результаты и обсуждение: Производительность систем при выполнении этой задачи демонстрируется на рис. 9. Из-за ошибки в оптимизаторе запросов авторам пришлось немного изменить код SQL, использовавшийся в эксперименте со 100 узлами для Vertica. Из-за этого наблюдается такое значительное увеличение времени выполнения при переходе от 50 к ста узлам. Но даже при этом очевидно, что именно на этой задаче наблюдается наибольшее различие в производительности между Hadoop и двумя параллельными системами баз данных. Причина этого различия двояка.
Во-первых, несмотря на возросшую сложность запроса, производительность Hadoop по-прежнему ограничена скоростью, с которой может быть прочитана с диска крупная таблица UserVisits (20 гигабайт на узел). MR-программа вынуждена производить полное сканирование таблиц, в то время как параллельные системы баз данных могли успешно воспользоваться кластеризованным индексом на столбце UserVisits.visitDate для значительного сокращения объема данных, которые требовалось прочитать. Сравнивая временные расходы Hadoop на выполнение разных фаз программы, авторы обнаружили, что, независимо от числа узлов в кластере, на выполнение фаз 2 и 3 тратилось в среднем 24.3 и 12.7 секунды соответственно. В отличие от этого, на выполнение фазы 1, содержащей задачу Map, которая читает таблицы UserVisits и Rankings, в среднем тратилось 1434.7 секунды. Интересно, что примерно 600 секунд из этого времени было затрачено на примитивное чтение с диска таблиц UserVisits и Rankings, а 300 секунд – на разбиение, разбор и десериализацию различных атрибутов. Таким образом, накладные расходы ЦП, требуемые для разбора таблиц на лету, являются для Hadoop ограничивающим фактором.
Во-вторых, параллельные СУБД могут опираться на тот факт, что обе таблицы, UserVisits и Rankings, разделяются по столбцу соединения. Это означает, что обе системы могут производить соединение в каждом узле локально, без сетевых расходов на повторное разделение до выполнения соединения. Таким образом, им нужно просто выполнить в каждом узле локальную операцию хэш-соединения таблицы Rankings и отфильтрованной части таблицы UserVisits с последующим тривиальным выполнением раздела ORDER BY.
4.3.5. Задача UDF Aggregation
Последняя задача состоит в вычислении числа входящих ссылок для каждого документа. Эта задача часто используется в качестве компонента при вычислении PageRank. Конкретно, для решения этой задачи системы должны прочитать все файлы документов и произвести поиск всех URL, встречающихся в их содержимом. После этого системы должны для каждого уникального URL подсчитать число уникальных страниц, ссылающихся на этот URL, во всем наборе файлов. Эта задача именно того типа задач, для решения которых, как полагается, обычно используется MR.
Авторы вносят в постановку задачи две корректировки с целью облегчить ее выполнение в Hadoop. Во-первых, в агрегате допускается учет ссылок из документа на самого себя, поскольку в функции Map нетривиально обнаружить имя обрабатываемого файла. Во-вторых, в каждом узле HTML-документы конкатенируются в более крупные файлы при их сохранении в HDFS. Авторы обнаружили, что это позволяет повысить производительность Hadoop в два раза и помогает избежать проблем с основной памятью при использовании центрального контроллера HDFS, когда в системе сохраняется большое число файлов.
Команды SQL: Для выполнения этой задачи в параллельной СУБД требуется определяемая пользователем функция F, которая разбирает содержимое каждой записи таблицы Documents и записывает в базу данных найденные URL. Эту функцию можно написать на языке общего назначения, и она, по существу, идентична программе Map, обсуждаемой ниже. С использованием этой функции F во временную таблицу записывается список URL, а затем выполняется простой запрос, вычисляющий число входящих ссылок:
SELECT INTO Temp F(contents) FROM Documents;
SELECT url, SUM(value) FROM Temp GROUP BY url;
Несмотря на простоту предложенной UDF, авторы обнаружили, что на практике ее затруднительно реализовать в СУБД. Для СУБД-X MR-программа, использовавшаяся в Hadoop, транслировалась в эквивалентную C-программу, в которой для поиска ссылок в документе использовалась библиотека регулярных выражений POSIX. Для каждого URL, обнаруживаемого в документе, эта UDF возвращает серверу баз данных новый кортеж (URL, 1). Изначально авторы намеревались хранить каждый документ в СУБД-X в виде символьного BLOB, а затем выполнять UDF над каждым документом полностью внутри базы данных, но так сделать не удалось из-за известной ошибки в их версии системы. Взамен этого UDF была модифицирована для открытия каждого HTML-документа на локальном диске и обработки его содержимого таким образом, как если бы он хранился в базе данных. Хотя это похоже на подход, который пришлось применять для Vertica (см. ниже), UDF в СУБД-X выполняется не как внешний процесс по отношению к базе данных, и для ее выполнения не требуются какие-либо средства массовой загрузки для импорта извлекаемых URL.
В Vertica в настоящее время не поддерживаются UDF, и поэтому авторы были вынуждены реализовать данную тестовую задачу в две фазы. На первой фазе использовалась модифицированная версия UDF для СУБД-X для извлечения URL из файлов, но выходные данные писались в файлы локальной файловой системы каждого узла. В отличие от СУБД-X, эта программа выполнялась в отдельном процессе вне системы баз данных. Затем на каждом узле содержимое этих файлов загружалось в некоторую таблицу с использованием инструментов массовой загрузки Vertica. После завершения этой работы выполнялся описанный выше запрос для вычисления счетчика ссылок для каждого URL.
Программа MapReduce: Для обеспечения соответствия с моделью MR, в которой все данные должны определяться в терминах пар «ключ/значение», каждый HTML-документ разбивается на строки и передается функции Map в виде последовательности пар, в которых содержимое строки является значением, а номер строки – ключом. Затем функция Map использует некоторое регулярное выражение для нахождения всех URL в каждой строке. Для каждого находимого URL функция выводит этот URL и целое значение 1 в качестве новой пары «ключ/значение». При наличии этих записей функция Reduce затем просто подсчитывает число значений с данным ключом и выводит URL и вычисленный счетчик входящих ссылок как окончательный результат программы.
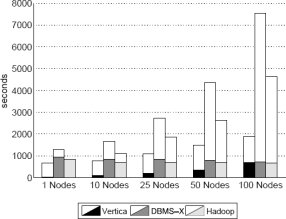
Рис. 10. Результаты задачи UDF Aggregation
Результаты и обсуждение: Результаты на рис. 10 показывают, что и у СУБД-X, и у Hadoop (не включая дополнительный процесс Reduce для объединения данных) для этой задачи обеспечивается почти константная производительность, поскольку в каждом узле хранится один и тот же объем данных Document, предназначенных для обработки, и этот объем данных остается константой (7 гигабайт) при добавлении узлов в проводившихся экспериментах. Как и ожидалось, дополнительная операция Hadoop по объединению данных работает все медленнее при добавлении узлов, поскольку объем выходных данных, которые должны обрабатываться одним узлом, увеличивается. Результаты для СУБД-X и Vertica на рис. 10 показаны в виде составных прямоугольников, в которых нижняя часть представляет время, затрачиваемое на выполнение UDF/парсера и загрузку данных в таблицу, а верхняя часть показывает время, затраченное на выполнение реального запроса. СУБД-X демонстрирует производительность хуже, чем у Hadoop, из-за дополнительных накладных расходов на покортежное взаимодействие между UDF и входным файлом, хранимым вне баз данных. Плохая производительность Vertica является следствием потребности в разборе данных вне СУБД и материализации промежуточных результатов на локальном диске до их загрузки в систему.
Назад Содержание Вперёд

