MapReduce и параллельные СУБД: друзья или враги?
Майкл Стоунбрейкер, Дэниэль Абади, Дэвит Девитт, Сэм Мэдден, Эрик Паулсон, Эндрю Павло и Александр Разин
Перевод: Сергей Кузнецов
Оригинал: Michael Stonebraker, Daniel Abadi, David J. Dawitt, Sam Madden, Erik Paulson, Andrew Pavlo and Alexander Rasin. MapReduce
and Parallel DBMSs: Friends or Foes?. Communications of the ACM, vol. 53, no. 1, January 2010
Содержание
- 1. Введение
- 2. Параллельные системы баз данных
- 3. Отображение параллельных СУБД на MapReduce
- 4. Возможные приложения
- 2. Параллельные системы баз данных
- 5. "Лакомые кусочки" для СУБД
- 6. Архитектурные различия
- 7. Взаимообучение
- 8. Заключение
- 9. Благодарность
- 10. Литература
- 8. Заключение
От переводчика: как ни крути, получается Vertica
Постепенно технология MapReduce начинает использоваться не в качестве конкурента технологии массивно-параллельных СУБД, а в качестве ее дополнения. Напомню, что все начиналось с достаточно интенсивной полемики между стронниками MapReduce и авторитетными представителями сообщества баз данных (см., например, статьи Майкла Стоунбрейкера и Дэвида Девитта (David J. DeWitt) из коллективного блога Database Column MapReduce: A major step backwards и MapReduce II).
На следующем этапе группа во главе со Стоунбрейкером выполнила отличную работу по сравнению производительности реализации MapReduce Hadoop с двумя массивно-параллельными СУБД (поколоночная Vertica и некая классическая система с хранением данных по строкам). В этом исследовании было показано, что при решении характерных аналитических задач паралельные СУБД показывают производительность, существенно более высокую, чем MapReduce, хотя параллельные СУБД тратят значительно больше времени на загрузку данных (см. статью Майкла Стоунбрейкера и др. Сравнение подходов к крупномасштабному анализу данных). Уже в этой статье отмечались в качестве положительного явления попытки интегрировать технологии SQL и MapReduce в нескольких начинающих компаниях.
За этим последовали интереснейшие, с моей точки зрения, публикации представителей компаний Greenplum (Джо Хеллерстейн и др. МОГучие способности: новые приемы анализа больших данных) и Asterdata (Эрик Фридман и др. SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями). В этих работах, хотя и с разными обоснованиями и с разных точек зрения, говорилось о применении парадигмы MapReduce для расширения возможностей серверного программирования в массивно-параллельных СУБД.
В дополнение к этим публикациям, возможно, стоит почитать мою обзорную статью Год эпохи перемен в технологии баз данных и заметку по поводу статьи про Asterdata SQL и MapReduce: новые возможности или латание старых дыр?.
И вот в январском номере журнала Communications of the ACM за 2010 г. вышла новая статья Стоунбрейкера и др., перевод которой предлагается вашему вниманию. Чем меня заинтересовала эта статья? Во-первых, это первая публикация относительно возможной интеграции технологий MapReduce и параллельных СУБД, вышедшая не в специализированном издании сообщества баз данных, а в популярнейшем компьютерном журнале широкого профиля. Значит, "процесс пошел", осталось его только "углубить". Во-вторых, эта статья хорошо дополняет статью Сравнение подходов к крупномасштабному анализу данных, поскольку основана на более свежих данных.
И наконец, что самое интересное, она отражает мнение самого СТОУНБРЕЙКЕРА о месте MapReduce поблизости от параллельных СУБД. И здесь очень интересными кажутся рассуждения о близости технологии MapReduce с существующими технологиями ETL и о возможности базировать на MapReduce будущие средства ETL, ориентированные на поддержку хранилищ данных, которые управляются массивно-параллельными СУБД. Это выглядит очень здраво и перспективно.
В общем, статья интересна и актуальна. Это еще один шаг к будущим системам управления данными. Это вообще, а в частности теперь понятно, каким путем движется Стоунбрейкеровская Vertica :).
Сергей Кузнецов
 Парадигма MapReduce (MR) [7] провозглашается как основа революционно новой платформы массивно-паралельного доступа к крупномасштабным данным [16]. Некоторые сторонники этого подхода утверждают, что исключительная масштабируемость MR приведет к тому, что системы управления реляционными базами данных (СУБД) станут унаследованными системами. По крайней мере, одна крупная компания (Facebook) реализовала крупную систему хранилищ данных с использованием MR, а не СУБД.
Парадигма MapReduce (MR) [7] провозглашается как основа революционно новой платформы массивно-паралельного доступа к крупномасштабным данным [16]. Некоторые сторонники этого подхода утверждают, что исключительная масштабируемость MR приведет к тому, что системы управления реляционными базами данных (СУБД) станут унаследованными системами. По крайней мере, одна крупная компания (Facebook) реализовала крупную систему хранилищ данных с использованием MR, а не СУБД.
В этой статье мы приводим доводы в пользу того, что использование систем MR при решении задач, для которых наилучшим образом подходят СУБД, приводит к не очень хорошим результатам [17]. Мы приходим к выводу, что системы MR больше похожи на системы извлечения-преобразования-загрузки (extract-transform-load, ETL), чем на СУБД, поскольку они быстро загружают и обрабатывают в заранее непредвиденном режиме данные большого объема. В этом качестве технология MR дополняет технологию СУБД, а не конкурирует с ней. Мы также обсуждаем различия в архитектурных решениях систем MR и баз данных и описываем, каким образом эти системы дополняют друг друга.
1. Введение
В настоящее время технология управления данными развивается под давлением парадигмы "облачных вычислений" ("cloud computing"), которая предполагает использование большого числа процессоров, работающих параллельно для решения вычислительных проблем. По сути, эта парадигма приводит к идее построения центров данных путем объединения большого числа недорогих серверов вместо того, чтобы использовать для этой цели меньшее количество высокопроизводительных серверов. Наряду с этим, интерес к кластерным архитектурам приводит к быстрому распространению соответствующих инструментальных средств программирования. MR является одним из таких инструментов, привлекательным для многих программистов, поскольку в нем обеспечивается простая модель, на основе которой пользователи могут строить относительно сложные распределенные программы.
При наличии коммерческого и академического интереса к MR естественно спросить, не придут ли системы MR на смену параллельных систем баз данных? Первые коммерческие параллельные СУБД появились примерно двадцать лет тому назад, и сегодня доступны системы примерно десяти поставщиков. Являясь надежными, высокопроизводительными вычислительными системами, они обеспечивают среду высокоуровневого программирования, являющуюся параллельной по своей природе. Хотя может показаться, что системы MR и параллельные СУБД сильно различаются, почти любую задачу параллельной обработки можно запрограммировать как в виде набора запросов к базе данных, так и в виде набора MR-заданий.
Наши обсуждения с пользователями MR приводят нас к выводу, что наиболее распространенный сценарий использования MR больше всего напоминает систему ETL. В этом качестве технология MR дополняет технологию СУБД, а не конкурирует с ней, поскольку системы баз данных не очень подходят для решения задач ETL. В этой статье мы описываем, каким образом, по нашему мнению, можно идеально использовать технологию MR, и выделяем различные рынки MR и параллельных СУБД.
Недавно мы провели сравнительное исследование с использованием популярной реализации MR с открытыми исходными текстами и двух параллельных СУБД [17]. Результаты показывают, что СУБД работают значительно быстрее, чем MR, после того, как данные загружены, но загрузка данных в системах баз данных занимает гораздо больше времени. В этой статье мы обсуждаем источники этих различий в производительности, включая ограничивающие архитектурные особенности, которые мы видим у этих двух классов систем. В заключение мы обсуждаем уроки, которые следует усвоить сообществам MR и СУБД, а также будущие тенденции в области анализа крупномасштабных данных.
2. Параллельные системы баз данных
В середине 1980-х гг. в проектах Teradata [20] и Gamma [9] были заложены основы парадигмы параллельных систем баз данных, которые базировались на кластерах недорогих компьютеров, называемых "узлами без общих ресурсов" ("shared-nothing nodes") (с собственными центральными процессорами, основной памятью и дисками). Эти узлы связываются высокоскоростным внутренним соединением [19]. Во всех более поздних параллельных системах баз данных использовались, по существу, те же методы, что были впервые разработаны в этих двух проектах: горизонтальное распределение реляционных таблиц и разделяемое выполнение SQL-запросов.Идея горизонтального разделения состоит в том, чтобы распределять строки реляционной таблицы по узлам кластера, чтобы их можно было обрабатывать параллельно. Например, при разделении таблицы с 10 миллионами строк в кластере из 50 узлов, в каждом из которых имеется четыре диска, на каждом из 200 дисков будет размещено 50000 строк. В большинстве параллельных систем баз данных поддерживаются разные стратегии разделения, включая хэш-разделение (hash-partitioning), разделение по диапазонам значений ключа (range-partitioning) и циклическое разделение (round-robin partitioning) [8]. При применении хэш-разделения при загрузке каждой строки к значениям ее одного или нескольких атрибутов применяется хэш-функция, значение которой определяет целевой узел и диск, на котором должна быть сохранена эта строка.
Использование горизонтального разделения таблиц между узлами кластера является критическим для получения масштабируемой производительности SQL-запросов [8] и естественным образом приводит к идее разделяемого выполнения операций SQL: селекции (selection), агрегации (aggregation), соединения (join), проекции (projection) и обновления (update). В качестве примера того, как разделение данных используется в параллельной СУБД, рассмотрим следующий SQL-запрос:
SELECT custId, amount FROM Sales WHERE date BETWEEN "12/1/2009" AND "12/25/2009";Если строки таблицы
Sales горизонтально разделены между узлами кластера, этот запрос можно тривиальным образом выполнить параллельно путем выполнения операции SELECT над записями Sales с применением заданного предиката в каждом узле кластера. Полученные в каждом узле промежуточные результаты затем посылаются в некоторый единственный узел, где выполняется операция MERGE, вырабатывающая окончательный результат, который возвращается в приложение, обратившееся с данным запросом.
Предположим, что нам требуется узнать общий объем продаж каждому покупателю (идентифицируемому своим custId) за установленный промежуток времени. Для этого можно использовать следующий запрос:
SELECT custId, SUM(amount) FROM Sales WHERE date BETWEEN "12/1/2009" AND "12/25/2009" GROUP BY custId;Если таблица
Sales циклически разделена между узлами кластера, то строки, соответствующие одному покупателю, будут разнесены по нескольким узлам. СУБД откомпилирует этот запрос в конвейер из трех операций, показанный на рис. 1(a), а затем параллельно выполнит этот план запроса во всех узлах кластера. Каждая операция SELECT сканирует фрагмент таблицы Sales, хранимый в данном узле. Все строки, удовлетворяющие предикату над датой, передаются операции SHUFFLE, которая динамически переразделяет строки. Это обычно делается путем применения некоторой хэш-функции к значению атрибута custId каждой строки для ее отображения на некоторый узел. Поскольку в операции SHUFFLE во всех узлах используется одна и та же хэш-функция, строки одного покупателя направляются в некоторый единственный узел, где они агрегируются для получения общего объема продаж данному покупателю.
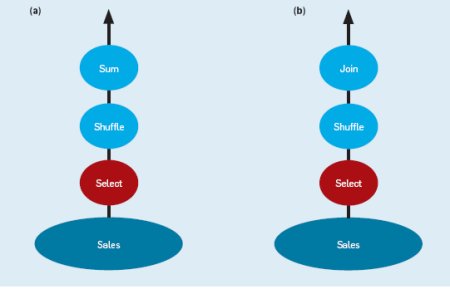
Рис. 1. Параллельные планы выполнения запросов к базе данных. (a) Примерный конвейер операций для вычисления агрегата на одной таблице. (b) Примерный конвейер операций для выполнения соединения двух разделенных таблиц.
В качестве последнего примера параллелизации SQL с использованием разделения данных рассмотрим запрос, который выдает имена и электронные адреса заказчиков, купивших товары на сумму больше $1000 в период рождественских каникул:
SELECT C.name, C.email FROM Customers C, Sales S WHERE C.custId = S.custId AND S.amount > 1000 AND S.date BETWEEN "12/1/2009" AND "12/25/2009";Снова предположим, что таблица
Sales разделена циклически, но пусть таблица Customers> хэш-разделена по атрибуту Customer.custId. СУБД откомпилирует этот запрос в конвейер операций, показанный на рис. 1(b), который выполняется параллельно во всех узлах кластера. Каждая операция SELECT сканирует соответствующий фрагмент таблицы Sales, отбирая строки, удовлетворяющие предикату
S.amount > 1000 AND S.date BETWEEN "12/1/2009" AND "12/25/2009".Отобранные строки в конвейерном режиме отправляются операции
SHUFFLE, которая переразделяет поступающие ей строки, хэшируя их по атрибуту Sales.custId. За счет использования той же хэш-функции, которая использовалась при загрузке строк таблицы Customers> (хэш-разделенной по атрибуту Customer.custId), операции SHUFFLE направляют каждую отобранную строку таблицы Sales в узел, где хранится соответствующая ей строка таблицы Customers>. Это позволяет параллельно во всех узлах выполнить операцию соединения (C.custId = S.custId).
Еще одно важное преимущество параллельных СУБД состоит в том, что система автоматически управляет различными альтернативными стратегиями разделения таблиц, над которыми выполняется запрос. Например, если обе таблицы Sales и Customers> были бы хэш-разделены по своим атрибутам custId, то оптимизатор запросов обнаружил бы, что обе таблицы хэш-разделены по атрибутам соединения, и не включил бы в план запроса операцию SHUFFLE. Аналогично, если бы обе таблицы были разделены циклически, то оптимизатор вставил бы в план операции SHUFFLE для обеих таблиц, чтобы соединяемые кортежи оказались в одном и том же узле. Все это делается прозрачным образом для пользователя и прикладных программ.
Доступно много коммерческих реализаций, включая Teradata, Netezza, DataAllegro (Microsoft), ParAccel, Greenplum, Aster, Vertica и DB2. Все они работают на кластерах, у узлов которых отсутствуют общие ресурсы; таблицы горизонтально разделяются между узлами.
3. Отображение параллельных СУБД на MapReduce
Привлекательной чертой модели программирования MapReduce является простота. MR-программа состоит всего из двух функцийMap и Reduce, программируемых пользователем для обработки пар элементов данных "ключ/значение" [7]. Входные данные хранятся в наборе разделов распределенной файловой системы, развернутой в каждом узле кластера. Затем программа включается в инфраструктуру распределенной обработки и выполняется в манере, которая будет описана ниже. Модель MR была впервые описана Google в 2004 г., и сегодня существует множество ее свободно доступных и коммерческих реализаций. Наиболее популярной MR-системой является Hadoop – проект с открытыми исходными текстами, выполняемый Yahoo! и Apache Software Foundation.
Семантика модели MR не уникальна. Фильтрация и преобразование отдельных элементов данных (кортежей таблиц) могут быть произведены современной СУБД с использованием SQL. В качестве аналога операций Map, которые не так легко выражаются средствами SQL, во многих СУБД поддерживаются функции, определяемые пользователями (user-defined
functions, UDF) [18]. Возможности наращивания функциональных возможностей UDF эквивалентны возможностям операции Map. Агрегаты SQL, дополняемые UDF и агрегатами, определяемыми пользователями, обеспечивают пользователей теми же функциональными возможностями, что и MR-операция Reduce. Наконец, перегруппировка данных, происходящая в MR между выполнением задач Map и Reduce, эквивалентна выполнению операции GROUP BY в SQL. Все это дает основания считать, что параллельные СУБД обеспечивают ту же вычислительную модель, что и MR, и сверх того — ещё и декларативный язык (SQL).
В течение двух десятилетий широко рекламировалась линейная масштабируемость параллельных СУБД [10]. Это означает, что при добавлении к кластеру узлов можно пропорционально увеличить размер базы данных, сохранив прежнее время реакции системы. Несколько производственных баз данных объемом в несколько петабайт очень крупных компаний, поддерживаются на кластерах, содержащих около 100 узлов [13]. Люди, управляющие этими системами, не сообщают о потребности в дополнительном параллелизме. Таким образом, параллельные СУБД обеспечивают отличную масштабируемость в диапазоне числа узлов, требуемом заказчикам. Не видно причин, по которым масштабируемость нельзя было бы увеличить до уровня, упоминаемого Джеффри Дином (Jeffrey Dean) и Санджаем Гемаватом (Sanjay Ghemawat) в [7], если это потребуется заказчикам.