2010 г.
Транзакционные параллельные СУБД: новая волна
Сергей Кузнецов
Назад Содержание Вперёд
4. Рационализация согласованности
Обсуждение этого направления лучше всего начать с работы
[38], в которой впервые был предложен новый подход к оптимизации систем управления базами данных. Отмечается наличие в мире баз данных нескольких новых тенденций.
-
Первой тенденцией является изменение приоритетов в требованиях приложений к системам управления данными. Для многих Web-приложений строгая согласованность данных в соответствии с парадигмой ACID не требуется. Зато им требуется возможность масштабирования приложения до миллионов пользователей, ни один из которых не должен блокироваться другими пользователями. Все запросы этих пользователей (и простые, и сложные) должны обрабатываться за гарантированное время в пределах секунды.
-
Вторая тенденция состоит в возрастании сложности приложений, насыщенных данными, и в использовании для их организации распределенной сервис-ориентированной архитектуры.
-
Наконец, имеются технологические тенденции, такие как "облачные" вычисления (cloud computing) и крупные центры данных, основанные на использовании дешевых аппаратных средств. Эти тенденции влияют на архитектуру программного обеспечения.
Если в "прошлой" жизни в системе управления данными при заданном наборе аппаратных ресурсов и полноценной поддержке ACID-транзакций требовалось минимизировать время ответов на запросы и максимизировать пропускную способность системы, то в новых условиях при заданных требованиях к производительности приложений (пиковая пропускная способность, максимально допустимое время ответа) требуется минимизировать требуемые аппаратные ресурсы и максимизировать согласованные данные. Сводка различий в формулировке проблемы оптимизации приведена в табл. 2.
Табл. 2. Сопоставление традиционной и новой проблем оптимизации
|
Характеристика |
Традиционные базы данных |
Новые базы данных |
| Денежные затраты |
фиксированные |
минимизируются |
| Производительность |
оптимизируется |
фиксированная |
| Масштабируемость (число машин) |
максимизируется |
фиксированная |
| Предсказуемость стоимости и производительности |
- |
фиксированная |
| Согласованность (в процентах) |
фиксированная |
максимизируется |
| Гибкость (число вариантов) |
- |
максимизируется |
Основным показателем системы баз данных, нуждающемся в оптимизации, является денежная оценка затрат. По мнению авторов, технология баз данных может удовлетворить любые требования к производительности и пропускной способности приложения, вопрос лишь в том, сколько для этого потребуется машин, т.е. сколько за это придется платить. При использовании "облачных" инфраструктур показатель расходов на аппаратные ресурсы становится непрерывным: чем больше их потребляется, тем больше приходится платить.
В большинстве случаев сегодня производительность является заданным ограничением приложения, а не целью оптимизации. В интерактивных приложениях для удовлетворения потребностей пользователей достаточно время ответа в несколько миллисекунд. Что касается пропускной способности, то реальным требованием является поддержка заданной пиковой рабочей нагрузки, причем проблемой является не возможность этой поддержки (возможно практически все), а ее стоимость. Кроме того, из-за сложности современных приложений многие проблемы их производительности вообще не связаны с управлением данными.
В настоящее время принято считать, что любую проблему приложений баз данных можно решить путем соответствующего выбора аппаратных средств (т.е. за счет определенных денежных затрат). Масштабируемость означает, что расходы на поддержку приложений возрастают линейно по мере роста бизнеса, и этот рост не ограничивается возможностями системы. Неограниченная масштабируемость приложений необходима для любой развивающейся компании. Мне кажется, что требование к маштабируемости нужно формулировать точнее: при росте числа аппаратных ресурсов должно соблюдаться линейное возрастание пропускной способности и стоимости с сохранением (или уменьшением) времени ответа. – С.К.
Во многих случаях предсказуемость производительности и стоимости поддержки приложений оказывается не менее важной, чем их масштабируемость. Критичные для компании показатели приложений, в том числе, пиковая пропускная способность, время ответа и стоимость, должны гарантироваться.
Что касается согласованности, на авторов [38] сильное влияние оказали идеи [24] и [39] (замечу, что в то время оба автора этих публикаций работали в Amazon.com). Утверждается, что ACID-транзакции плохо сочетаются с сервис-ориентированной архитектурой, которая диктует автономию сервисов, участвующих в транзакции. Кроме того, по утверждениям авторитетных практиков из Amazon.com, в современной Internet-практике ACID-транзакции требуются нечасто. Наконец, более приоритетным требованием является обеспечение стопроцентной доступности данных по чтению и записи всех пользователей. Оказывается лучше разрабатывать систему, которая умеет обращаться с несогласованными данными и помогает устранять их несогласованность, чем систему, которая предотвращает несогласованность в любых ситуациях. Одним словом, в подходе [38] согласованность данных является целью оптимизации системы, а не ее фиксированным ограничением.
Замечу, что в этих рассуждениях о согласованности одновременно имеются и здравый смысл (очевидно, что поддержка ACID-транзакций в распределенной среде стоит немалых расходов, и если целью оптимизации является минимизация расходов, то по поводу транзакций нужны какие-то компромиссы), и изрядная путаница (во многом напоминающая путаницу, с которой мы разбирались в разд. 2; один раз авторы [38], хотя и очень стеснительно, ссылаются и на теорему CAP). И мне кажется, что частично причины этой путаницы указывают сами авторы, обосновывая в своей более ранней работе [40], что "при разработке крупномасштабных распределенных систем определения уровней согласованности в духе предложений [41], а не определений, содержащихся в стандарте языка SQL и реализуемых в коммерческих системах баз данных текущего поколения".
Но если обратиться напрямую к [41], то видно, что сами Таненбаум (Andrew S. Tanenbaum) и Стеен (Maarten van Steen) используют термин согласованность (consistensy) как смысле, традиционном для области баз данных ("если у системы до начала транзакции имелись некие инварианты, которые она постоянно должна хранить, они будут сохраняться и после ее завершения" – разд. 5.6 "Распределенные транзакции"), так и в смысле, затрагивающем лишь репликацию данных ("Модель согласованности (consistency model), по существу представляет собой контракт между процессами и хранилищем данных. Он гласит, что если процессы согласны соблюдать некоторые правила, хранилище соглашается работать правильно." – Разд. 6.2 "Модели непротиворечивости, ориентированные на данные"). Легко (еще раз!) видеть, что понятие согласованности второго вида не имеет прямого отношения к транзакциям вообще и к ACID-транзакциям в частности. Оба понятия согласованности, безусловно, полезны и имеют право на жизнь, но предпочитать одно другому – это все равно, что предпочитать красное сладкому.
Возвращаясь к перечню характеристик систем баз данных из табл. 2, гибкость – это возможность настройки программной системы к индивидуальным требованиям пользователей. Гибкость системы измеряется числом ее внедренных вариантов. В традиционных системах OLTP требование гибкости отсутствует. При отсутствии гибкости проще добиться высоких значений показателей производительности и масштабируемости.
Следуя новым приоритетам характеристик систем управления данными, авторы [38] предлагают новую архитектуру, которую мы кратко опишем в следующем подразделе.
4.1 Архитектура, удовлетворяющая новым требованиям
На рис. 9 схематически показана традиционная трехзвенная архитектура организации приложений баз данных. Запросы инициируются пользователями на уровне представлений. В настоящее время для этого обычно используются Web-браузеры. На среднем уровне поддерживается логика приложений; обычно на этом же уровне работают Web-серверы. Управление базами данных целиком сосредоточено на низшем уровне, и для этого используются СУБД.
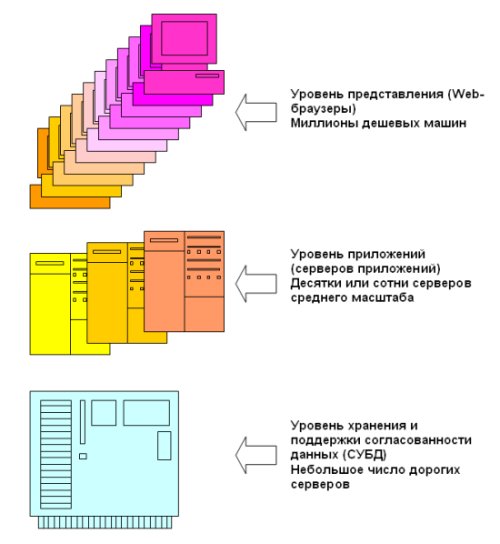
Рис. 9. Традиционная трехзвенная архитектура организации приложений баз данных.
Трехзвенная архитектура ориентирована на удовлетворение требований традиционных систем баз данных (средний столбец табл. 2). Согласованность данных поддерживается в нижнем звене сервером базы данных. Производительность обеспечивается за счет применения на всех трех уровней методов, разработанных в сообществе баз данных на протяжении десятилетий – кэширование, индексация, разделение данных и т.д. На верхних двух уровнях архитектура масштабируется почти неограниченно.
Однако эта архитектура не удовлетворяет новым требованиям (правый столбец табл. 1). Аппаратные средства сервера баз данных должны быть рассчитаны на поддержку пиковой, а не средней производительности, а эти показатели могут различаться в разы. С результате компаниям сразу приходится платить не за то, что реально им требуется, а за то, что может когда-то потребоваться (а может и не потребоваться). Традиционно используемые универсальные SQL-ориентированные СУБД обладают огромным числом функциональных возможностей, которые не нужны любому конкретному приложению, и за это тоже приходится платить. (Как видно, в этом отношении авторы [38], да и вообще практически все разработчики новых архитектур СУБД занимают позицию Майкла Стоунбрейкера [1], хотя он никогда не ставит на первое место проблемы денежных расходов – С.К.)
Классическая трехзвенная архитектура (при традиционной реализации СУБД) не отвечает требованию предсказуемости. Когда с базой данных одновременно работает много клиентов, практически невозможно понять, что происходит в СУБД (например, когда начинается активное замещение страниц в буферном пуле – С.К.). Возможности масштабирования на нижнем уровне архитектуры ограничены.
Гибкость в традиционной архитектуре тоже не поддерживается должным образом. Одной из причин является использование разных технологий на каждом из трех уровней: SQL на нижнем уровне, объектно-ориентированные методы на уровне приложений и XML/HTML и скриптовые языки на уровне представлений. Настройку нужно вести на всех трех уровнях с использованием разных технологий, что затруднительно и ненадежно. (Коротко можно сказать, что традиционной архитектуре присуща известная проблема потери соответствия (impedance mismatch) – С.К.)
Двумя основными принципами разработки приложений баз данных в классической трехзвенной архитектуре являются контроль и передача запросов (query shipping). Первый принцип означает, что на нижнем уровне СУБД контролирует все аппаратные ресурсы и весь доступ к данным. Передача запросов предполагает выталкивание на нижний уровень как можно больше функций приложений за счет использования хранимых процедур, определяемых пользователями типов данных и т.д. С одной стороны, эти принципы позволяют добиться согласованности данных и высокой производительности системы. С другой стороны, по мнению авторов [38] оба эти принципа стимулируются бизнес-моделью производителей СУБД и превращают системы управления данными в монолитных монстров, размеры и сложность которых непрерывно растут. Это наносит вред предсказуемости, гибкости и масштабируемости. Кроме того, они приводят к тому, что приложения баз данных становятся дорогостоящими, поскольку для поддержки таких СУБД требуется дорогая аппаратура. В предлагаемой авторами архитектуре используются противоположные принципы разработки.
Этот абзац кажется мне очень важным, поскольку, по моему мнению, отказ от указанных принципов в действительности вызывает очень важные последствия. Отказ от принципа контроля приводит к тому, что СУБД перестает быть системой, а превращается в набор утилит. Если у СУБД отсутствует контроль над обрабатываемыми ею данными, она, естественно, не сможет поддерживать ACID-транзакции. Как мы видели в предыдущем разделе, можно делать транзакционные СУБД массивно-параллельными (фактически, использовать для их разработки методы распределенных систем), оставляя их системами с точки зрения внешнего использования.
Если отнять у СУБД контроль над аппаратными средствами и данными, то для построения распределенных систем обработки данных на всех уровнях придется применять общие методы построения распределенных систем. Наверное, это хорошо с точки зрения повсеместного использования сервис-ориентированной архитектуры, но задачи, которые хорошо решаются традиционными СУБД (в том числе, обеспечение ACID-транзакций) становятся практически неразрешимыми. Кстати, такая организация напоминает мне архитектуру файл-серверных СУБД типа Informix SE (см. например, [42]), в которой данные контролировались файловым сервером, а запросы обрабатывались на клиентских рабочих станциях. В этой архитектуре поддерживались ACID-транзакции, но очень дорогой ценой – путем блокировки файлов целиком. И не просто так впоследствие компании-производители SQL-ориентированных СУБД перешли к использованию серверов баз данных, в которых данные контролируются СУБД.
Кстати, и отказ от второго принципа возвращает нас ко времени Informix SE, где для выполнения запросов на рабочие станции из файлового сервера передавались блоки данных. Вроде бы, вполне естественно было перейти на архитектуру, в которой из клиента в сервер баз данных передавались SQL-запросы, а возвращались только те данные, которые действительно нужны приложению. И механизмы хранимых процедур и определяемых пользователями типов данных во многом появились не из-за корысти производителей СУБД, а для того, чтобы еще сократить объемы данных, которыми приходится обмениваться клиенту и серверу. И как видно из разд. 3, все это совсем не обязательно наносит вред предсказуемости и масштабируемости (насчет гибкости ничего сказать не могу, поскольку отсутствуют точные критерии).
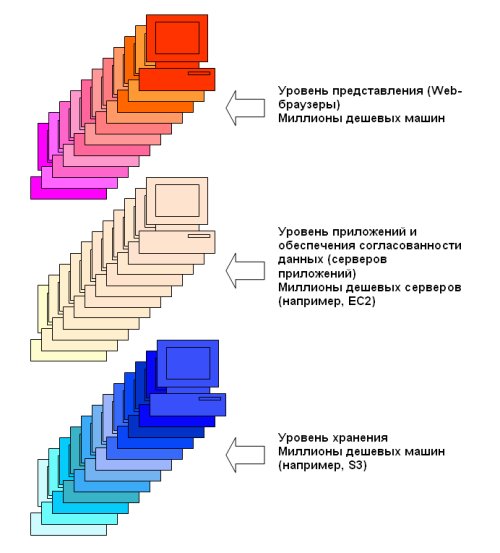
Рис. 10. Архитектура Sausalito.
Взамен традиционной архитектуре с рис. 9 в [38] предлагается новая архитектура, показанная на рис. 10. Эта архитектура реализована компанией 28msec в продукте Sausalito [43]. В архитектуре Sausalito основные функции СУБД – обработка запросов и управление транзакциями – переносятся на прикладной уровень. (В действительности, не очень понятно, что же такое транзакция в этой системе. Подробнее об этом см. следующий подраздел. – С.К.) На нижнем уровне поддерживается только распределенное хранение данных за счет использования службы Amazon S3 [44] (хотя теоретически можно использовать и другие аналогичные средства). Согласованность данных поддерживается не на уровне хранения, а на прикладном уровне. Отсутствует какой-либо объект, контролирующий весь доступ к данным, и согласованность данных обеспечивается за счет применения во всех серверах приложений общих протоколов в духе [41]. (Как уже отмечалось выше, в [41] эти протоколы направлены на поддержку согласованности реплик данных, так что здесь имеется в виду именно этот вид согласованности. – С.К.)
На всех уровнях можно использовать дешевые аппаратные средства, и каждый уровень может масштабироваться до тысяч машин. В любой момент времени допускается отказ любого узла. На нижнем уровне отказоустойчивость достигается за счет репликации и предоставления гарантий только согласованности в конечном счете (eventual consistency. На верхних уровнях все узлы работают без сохранения состояния, поэтому при отказе какого-либо узла в самом худшем случае могут потеряться некоторые активные транзакции.
В Sausalito все данные и заранее откомпилированный код приложения сохраняются в среде Amazon S3 в виде BLOB'ов. При обработке каждого HTTP-запроса (поступающего, например, по инициативе пользователя из Web-браузера) служба Amazon EC2 [45] с учетом балансировки нагрузки выбирает доступный сервер EC2. В этот сервер из S3 загружается код приложения, который затем интерпретируется подсистемой поддержки времени выполнения Sausalito с доступом при необходимости к объектам базы данных, хранимым в S3. Особенностью Sausalito является то, что для реализации логики приложений и доступа к базе данных в системе используется язык XQuery [46], расширенный средствами обновления данных и написания скриптов. Авторы [38] мотивируют этот выбор тем, что XQuery хорошо согласуется со стандартами Web, обладает развитыми средствами запросов, и возможностей этого языка достаточно для создания развитых Web-приложений. Однако мне кажется, что важную роль сыграла и личная близость Даниелы Флореску (Daniela Florescu) и Дональда Коссманна к процессам стандартизации и реализации этого языка. Не уверен, что (единственная) возможность использования XQuery в качестве языка разработки приложений приводит в восторг потенциальных пользователей Sausalito.
Как отмечается в [38], у системы с архитектурой с рис. 10 мало шансов сравняться с классическими системами баз данных в отношении производительности и согласованности данных (я уже говорил выше, что это обратная сторона отказа от принципов контроля над данными и пересылки запросов – С.К.). Однако эта архитектура хорошо соответствует требованиям правого столбца табл. 2. Архитектура экономически эффективно реализуется с использованием дешевых аппаратных средств, масштабируемость на всех уровнях обеспечивается автоматически. Гибкость достигается за счет упрощения платформы и использования на всех уровнях единой модели программирования и данных (XML/XQuery). Для многих рабочих нагрузок обеспечивается предсказуемость расходов и производительности.
В [38] изложены основные идеи "облачной" системы управления данными, хорошо согласующейся с сервис-ориентированной архитектурой, гибкой и масштабируемой на всех уровнях. На появление новой архитектуры систем баз данных повлияли сценарии интерактивных (транзакционных) Web-приложений – онлайновых магазинов и т.д. Однако, как отмечалось выше, идеология поддержки транзакций в [38] выглядит очень туманной. Некоторую ясность привносит более свежая работа [9], которой посвящен следующий подраздел.
Назад Содержание Вперёд

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
