2010 г.
Транзакционные параллельные СУБД: новая волна
Сергей Кузнецов
Назад Содержание Вперёд
3.1.4 Детерминированное выполнение транзакций
Как видно из материала предыдущих пунктов, в H-Store имеются две основные проблемы, обе связанные с поддержкой многораздельных транзакций: отображение результатов транзакции в репликах базы данных и двухфазная фиксация. В
[28] полагается, что эти проблемы можно решить путем перехода к полностью детерминированной схеме выполнения транзакций. (
Замечу, что при этом описываемое исследование выполнено не в контексте общей архитектуры H-Store, хотя имеет явное отношение к этому проекту. –С.К.) Связанное с поддержкой свойств ACID требование
сериализации транзакций, по мнению авторов
[28], традиционно формулируется слишком слабо, поскольку требуется эквивалентность плана выполнения смеси транзакций
какому-либо плану их последовательного выполнения, что оставляет простор для недетерминизма. При
детерминированной сериализации смеси транзакций {
T1,
T2, ...,
Tn} требуется эквивалентность плана выполнения этих транзакций некоторому
предопределенному последовательному плану их выполнения (
Ti1,
Ti2, ...,
Tin).
Простейшим способом детерминированного выполнения смеси транзакций, гарантирующим эквивалентность предопределенному последовательному плану было бы последовательное выполнение транзакций в порядке этого плана без какого-либо параллелизма. Однако в большинстве случаев это привело бы к неоптимальному использованию компьютерных ресурсов и, тем самым, к плохой производительности системы. Поэтому авторы предлагают использовать синхронизационные блокировки, но при соблюдении следующих ограничений, гарантирующих эквивалентность получаемого сериального плана предопределенному плану:
-
Если двум транзакции Ti и Tj требуются блокировки одной и той же записи r, и в предопределенном плане Ti находится раньше, чем Tj, то Ti должна запросить блокировку r раньше, чем Tj (т.е. должна использоваться схема упорядоченного запроса блокировок – помимо прочего, легко видеть, что при использовании такой схемы невозможно возникновение синхронизационных тупиков).
-
Каждая транзакция, не ожидающая удовлетворения запроса блокировки, должна продолжать выполняться до тех пор, пока не зафиксируется или не будет
аварийно завершена детерминированным образом (т.е. в соответствии с логикой приложения). Если выполнение какой-либо транзакции задерживается (например, из-за какого-то сбоя в системе), то система должна поддерживать эту транзакцию активной, пока она не завершится, или пока не будет ликвидирована сама система.
Эксперименты авторов показывают, что если возможны длительные задержки при выполнении какой-либо транзакции, то детерминированная схема приводит к быстрому "загромождению" системы блокированными транзакциями и резкому падению производительности. Поэтому, в частности, детерминированная схема непригодна для СУБД, работающих с базами данных в дисковой памяти. Однако в системах, обрабатывающих данные исключительно в основной памяти, ситуация меняется. В ряде случаев детерминизм позволяет повысить производительность систем, упрощая при этом репликацию и избавляя от потребности в двухфазном протоколе фиксации распределенных транзакций.
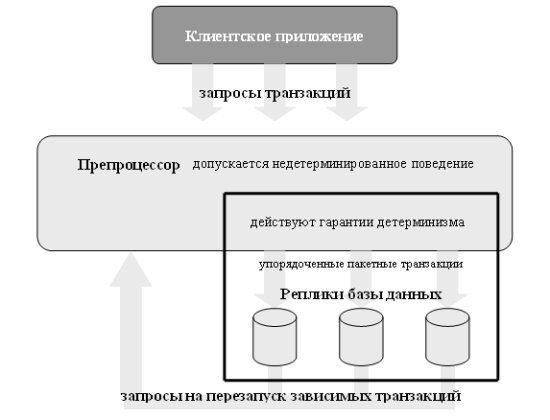
Рис. 3. Детерминированная система.
Возможная архитектура детерминированной реплицированной СУБД показана на рис. 3. Запросы на образование транзакций (как и раньше, транзакции являются заранее определенными и сохраняемыми в виде хранимых процедур) от пользовательских приложений поступают в препроцессор, являющий границей детерминированной системы. Препроцессор выполняет всю необходимую недетерминированную подготовительную работу (например, параметризует транзакции в соответствии с указаниями пользователей) и упорядочивает транзакции. После этого транзакции объединяются в пакет и надежно сохраняются. С этого момента система обязуется выполнить все поступившие транзакции, и все выполнение далее производится в соответствии с установленным в пакете порядком выполнения транзакций. Наконец, пакет транзакций надежным образом отсылается во все системы, содержащие реплики базы данных (в этой работе неявно полагается, что базы данных реплицируются целиком, так что любую транзакцию можно полностью выполнить в любой реплике).
От каждой системы-реплики требуется только то, чтобы в ней была реализована некоторая модель выполнения, гарантирующая отсутствие синхронизационных тупиков и эквивалентность порядку выполнения транзакций, установленному препроцессором. Все системы реплики работают полностью независимо (по всей видимости, сообщая препроцессору о завершении обработки полученного пакета транзакций – С.К.). В случае отказа какой-либо системы реплики ее восстановление производится на основе реплик, сохранивших работоспособность (кстати, в контексте [28] это не очень важно, поскольку эксперименты производились на прототипе, не поддерживающем репликацию, – С.К.).
Для поддержки упорядоченности запросов блокировок в [28] предлагается запрашивать все блокировки, требуемые для каждой транзакции, перед началом ее выполнения (заметим, что если, как в предыдущем пункте, для каждого раздела базы данных используется только один поток управления, то, как и раньше, до появления первой многораздельной транзакции все предшествующие однораздельные транзакции можно выполнять без синхронизационных блокировок – С.К.). Если это возможно, то после этого транзакция выполняется вплоть до своего завершения (над данным разделом), не освобождая блокировок. Однако не для всех транзакций заранее известно, какие записи в них будут читаться и изменяться. Например, возможна следующая транзакция:
T(x):
y := read(x)
write(y)
Здесь параметр x указывает на некоторую запись, содержащую значение первичного ключа той записи, которую требуется обновить.
В этом случае невозможно сразу запросить синхронизационную блокировку второй записи, поскольку значение ее первичного ключа неизвестно до выполнения первой операции чтения. Такие транзакции в [28] называются зависимыми. В предлагаемой схеме зависимые транзакции разбиваются на несколько транзакций, из которых все транзакции, кроме последней, занимаются исключительно выяснением состава наборов чтения и записи, а последняя транзакция начинает свое выполнение при наличии полного знания наборов записей, которые она будет читать и изменять. Например, транзакцию T можно разбить на следующие транзакции T1 и T2:
T1(x):
y := read(x)
запрос_следующей_транзакции(T2(x, y))
T2(x, y):
y´ := read(x)
if (y´ ≠ y)
запрос_следующей_транзакции(T2(x, y))
abort()
else
write(y)
Препроцессор не включает транзакцию
T2 в пакеты транзакций, пока не получит результат транзакции
T1. При начале выполнения
T2 блокируются записи с ключами, содержащимися в
x и
y, а затем проверяется, что за время, прошедшее между завершением
T1 и началом
T2 не изменилось содержимое записи, на которую указывает
x. Если эта проверка оказывается успешной, выполнение
T2 продолжается. В противном случае
T2 аварийно завершается с освобождением своих блокировок. Об этом оповещается препроцессор, который снова включает
T2 в следующий пакет транзакций. Все действия по аварийному завершению транзакций и выполнению новых попыток детерминированы; они одинаковым образом выполняются во всех системах-репликах.
В этом примере для разбиения транзакции T требуется только одна дополнительная транзакция (в T имеется зависимость первого порядка. По наблюдениям авторов [28], такие транзакции часто встречаются в реальных рабочих нагрузках OLTP. Транзакции с зависимостями более высокого порядка встречаются реже, но теоретически с ними можно справиться с помощью того же приема. Эксперименты и аналитическое моделирование показали, что наличие в рабочей нагрузке OLTP транзакций с зависимостями первого порядка не может служить основанием для отказа от детерминированной схемы выполнения транзакций.
Наиболее интересен детерминизм при выполнении многораздельных транзакций. Общая схема выполнения многораздельной транзакции в [28] не описывается, но идея состоит в том, что препроцессор разбивает каждую многораздельную транзакцию на фрагменты, каждый из которых затрагивает данные только одного раздела. Для каждого фрагмента обеспечивается информация о том, какие сообщения могут поступить от других фрагментов (включая сообщения, содержащие данные, и сообщения о детерминированном аварийном завершении). Фрагмент, получивший сообщение об аварийном завершении, освобождает свои синхронизационные блокировки и завершается. Фрагмент, получивший от других фрагментов все требуемые данные, выполняется до своего логического конца и освобождает синхронизационные блокировки. Не требуется использование какого-либо протокола фиксации транзакции, поскольку отказ любого узла означает отказ данной системы-реплики. Транзакция зафиксируется в какой-либо другой реплике, и на ее основе будет восстановлена отказавшая система.
Еще раз подчеркну, что это только идея. Думаю, что авторы [28] сами до конца не продумали эту схему, которая в общем случае может оказаться очень нетривиальной. В своих экспериментах, демонстрирующих преимущество детерминированного выполнения многораздельных транзакций они использовали очень простые транзакции из тестового набора TPC-C, а на общий случай пока не замахивались. В этой статье я не берусь разобраться со всеми возникающими сложностями, но нельзя не согласиться, что переспектива обойтись без двухфазного протокола фиксаций за счет детерминированного выполнения транзакций кажется очень привлекательной и потенциально достижимой. Как бы только не оказалось, что для этого требуется еще более сложный статический анализ транзакций, чем тот, который упоминался ранее в этом подразделе.
3.1.5 Автоматизация методов разделения и реплицирования баз данных
Понятно, что как не борись с двухфазной фиксацией распределенных транзакций, многораздельные транзакции останутся более дорогостоящими, чем однораздельные. И хотя в общем случае от многораздельных транзакций никуда не денешься, нужно стремится к тому, что в любой рабочей нагрузке OLTP их было как можно меньше. Понятно, что поскольку для любой системы баз данных рабочая нагрузка является независимым внешним фактором, можно лишь стремиться физическим образом организовать разделенную и реплицированную базу данных таким образом, чтобы среди транзакций именно этой рабочей нагрузки было по возможности меньше многораздельных транзакций.
Методы циклического разделения (каждый следующий кортеж направляется в следующий раздел) и хэш-разделения (кортежу назначается раздел в соответствии со значением некоторой хэш-функции от значения его атрибута разделения), часто с успехом применяемые в аналитических массивно-параллельных системах баз данных, как правило, не подходят для транзакционных массивно-параллельных систем баз данных, поскольку способствуют появлению большого числа многораздельных транзакций. Хорошие результаты может обеспечить разделение по диапазонам значений кортежей (выбор раздела для данного кортежа основывается на вычислении логического выражения, построенного на основе вхождений значений атрибутов кортежа в заданные диапазоны значений), но выбор соответствующих диапазонов с учетом заданной рабочей нагрузки вручную производить очень трудно.
Подход к решению этой проблемы представлен в [14]. В общих словах, на основе однораздельного представления базы данных и заданной рабочей нагрузки производится разделение базы данных на заданное число сбалансированных разделов с целью минимизации числа многораздельных транзакций в рабочей нагрузке. Далее система пытается аппроксимировать полученное разделение разделением по диапазонам значений на основе автоматически производимого условного выражения. Наконец, производится сравнение числа распределенных транзакций в исходной рабочей нагрузке, которые образуются при применении построенного метода разделения, с числом распределенных транзакций, которые возникают при использовании хэш-разделения и разделения на уровне таблиц, и для реального использования выбирается метод, обеспечивающий наилучший результат.
База данных
|
Рабочая нагрузка
|
ACCOUNT |
id |
name |
balance |
1 |
Carlo |
80K |
2 |
Evan |
100K |
3 |
Sam |
129K |
4 |
Eugene |
29K |
5 |
Yang |
12K |
|
I
|
BEGIN
UPDATE account SET bal=bal-1k
WHERE name="carlo";
UPDATE account SET bal=bal+1k
WHERE name="evan";
COMMIT
|
II
|
BEGIN
UPDATE account SET bal=60k
WHERE id=2;
SELECT * FROM account
WHERE id=5;
COMMIT
|
III
|
BEGIN
SELECT * FROM account
WHERE id IN {1,3};
ABORT
|
IV
|
BEGIN
UPDATE account SET bal=bal+1k
WHERE bal < 100k;
COMMIT
|
Рис. 4. Примерные база данных и рабочая нагрузка.
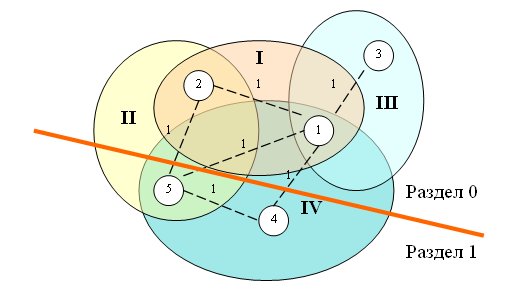
Рис. 5. Общая идея графа, использумого для разделения базы данных.
На первом этапе строится граф, в котором вершины соответствуют кортежам всех таблиц базы данных, и дуги связывают все кортежи, используемые в одной и той же транзакции. Вес каждой дуги – число транзакций, обращающихся к данной паре кортежей. На рис. 5 изображен граф для базы данных, состоящей из одной таблицы ACCOUNT с пятью кортежами, и рабочей нагрузки из четырех транзакций, показанных на рис. 4. На рис. 5 показаны четыре части графа, соответствующие четырем транзакциям с рис. 4.
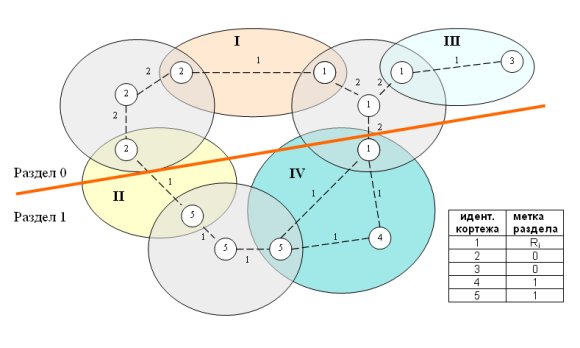
Рис. 6. Граф с учетом возможности репликации.
На рис. 6 показано расширенное представление графа с учетом возможности репликации на уровне кортежей. Для этого каждая вершина, соответствующая кортежу, к которому обращается n > 1 транзакций, заменяется "звездообразным" подграфом из n+1 вершин. Веса дуг, соединяющих вершины-реплики с центральной вершиной, характеризуют стоимость репликации данного кортежа и определяются как число транзакций в данной рабочей нагрузке, обновляющих данный кортеж. Например, на рис. 6 показано, что кортеж с id=1 представлен четырьмя вершинами, поскольку к нему обращаются три транзакции (I, III и IV). Веса дуг у соответствующего подграфа равны 2, поскольку только транзакции I и IV обновляют этот кортеж. Такая графовая структура позволяет алгоритму разделения соблюдать баланс между стоимостью репликации и выигрышем от ее применения.
Далее этот граф расщепляется на k разделов без общих вершин с минимизацией общей стоимости разрезания дуг (суммы весов дуг, концы которых оказываются в разных разделах графа). Другим ограничением является примерная балансировка весов разделов (допустимое отклонение является параметром системы). Весом раздела считается сумма весов вершин, входящих в этот раздел. Вес узла можно определять по-разному, и авторы [14] экспериментировали со случаями, когда вес вершины равен числу байт в соответствующем кортеже (в этом случае выполняется балансировка по размеру базы данных) и когда вес раздела равен числу обращений к кортежу (балансировка по рабочей нагрузке).
Расщепление графа на k частей при наличии подобных ограничений – это NP-полная проблема. Однако оказывается, что подобные задачи часто приходится решать в области автоматизации проектирования сверхбольших интегральных схем. За последние десятилетия были найдены сложные эвристические правила расщепления графов и созданы хорошо оптимизированные свободно доступные библиотеки программного обеспечения, позволяющие обрабатывать графы с сотнями миллионов дуг. В [14] использовались программные средства METIS [31]. Утверждается, что расщепление графа "производится быстро" (хотя абсолютные цифры не приводятся). Вместе с тем, отмечается, что при росте графа скорость обработки быстро возрастает, из-за чего авторы выработали ряд эвристик, позволяющих сдерживать размер графов (см. ниже).
В результате расщепления графа порождается отображение вершин-кортежей на набор меток разделов. Одним из способов использования этого результата является сохранение отображения в некоторой таблице типа той, которая показана в правом нижнем углу рис. 6. Как видно из этой таблицы, для нереплицируемых кортежей можно прямо указать номер раздела. Реплицируемые кортежи помечаются специальным образом, позволяющим понять, в каких разделах должны размещаться реплики.
В распространенном случае, когда в разделах WHERE операторов SQL содержатся условия сравнения на равенство с константой или вхождения в диапазон заданных значений, поисковые таблицы можно непосредственно использовать для направления операции в соответствующий(ие) раздел(ы). При наличии плотного множества идентификаторов кортежей и не более 256 разделов в 16 гигабайтной основной памяти можно хранить таблицу о разделении 15 миллиардов кортежей. Кортежи, заново вставляемые в базу данных, сначала могут помещаться в произвольные разделы, а после пересчета разделения графа их можно переместить в нужные разделы. Однако для очень крупных систем баз данных при наличии рабочей нагрузки с интенсивной вставкой кортежей этот подход может оказаться неудовлетворительным. Поэтому авторы [14] разработали дополнительное инструментальное средство, позволяющее аппроксимировать разделение, получаемое при обработке графа, методом разделения по диапазонам значений.
Это инструментальное средство основывается на методах машинного обучения, и в нем активно используются возможности свободно доступного пакета программных средств интеллектуального анализа данных WEKA [32]. Сначала на основе трассы рабочей нагрузки создается обучающая выборка. Для сокращения времени работы из трассы выделяется представительные образцы кортежей, которые помечаются метками разделов, полученными при расщеплении графа.
Затем разбираются операторы SQL, присутствующие в трассе рабочей нагрузке, и выделяются атрибуты кортежей, наиболее часто присутствующие в условиях разделов WHERE. Выбранные атрибуты обрабатываются компонентом отбора признаков (feature selection) пакета WEKA, которые отбирает атрибуты, коррелирующие с метками разделов.
Наконец, на основе обучающей выборки и отобранного набора атрибутов строится классификатор в виде дерева решений (используется реализация J48 из пакета WEKA). На выходе классификатора получается набор условий, аппроксимирующих разделение на уровне кортежей, которое было произведено при расщеплении графа.
Авторы называют процедуру получения аппроксимирующих условий толкованием (explanation) разделения графа. Отмечается, что получить разумное толкование не всегда возможно, и толкование является полезным только при выполнении следующих условий: (1) оно основывается на атрибутах, часто используемых в запросах; (2) не слишком снижает качество разделения за счет неправильной классификации кортежей; (3) успешно работает для операторов SQL, не использованных для построения обучающей выборки.
Последним шагом подхода Schism при выборе метода разделения является сравнение числа распределенных транзакций, которые обеспечиваются при заданной рабочей нагрузке схемой поисковой таблицы, полученной при разделении графа; схемой разделения по условиям вхождения в диапазоны значений, сгенерированной при толковании разделения графа; схемой хэш-разделения по наиболее часто используемым атрибутам и схемой репликации базы данных на уровне таблиц. Выбирается схема, приводящая к наименьшему числу распределенных транзакций, если несколько схем не обеспечивают близкие результаты. В последнем случае выбирается наименее сложная схема.
Поскольку с ростом графа, связывающего рабочую нагрузку с кортежами базы данных, значительно возрастает время его расщепления, в [14] предлагается ряд эвристик, позволяющих сократить размер графа без существенного влияния на результаты разделения, толкования и т.д. К числу этих эвристик относятся взятие образцов на уровне транзакций, взятие образцов на уровне кортежей, отбрасывание операций SQL, приводящих к сканированию больших частей таблиц и т.д. Эксперименты, описаннные в [14], показывают, что подход Schism позволяет добиться качества разделения баз данных, соизмеримого с качеством наилучших схем, получаемых вручную.
Подводя итог обсуждению разных аспектов проекта H-Store, еще раз отмечу его основные черты:
-
бескомпромиссное использование подхода shared-nothing – каждому разделу базы данных (основному или резервному) соответствует в точности один поток управления, и в потоках управления не используются общие ресурсы, даже если они реализуются ядрами одного и того же процессора;
-
поддержка баз данных в основной памяти; долговременность хранения обеспечивается только за счет репликации данных в разных узлах кластера;
-
выполнение транзакций поблизости от данных без потребности в передаче по сети операций SQL и их результатов;
-
стремление к минимизации числа распределенных транзакций за счет статического анализа и преобразований транзакций, а также за счет разделения данных с учетом рабочей нагрузки.
Последнее желание понятно, поскольку подход H-Store показывает чудеса производительности именно при наличии только однораздельных транзакций. К сожалению, даже если удастся реализовать все мыслимые и немыслимые преобразования транзакций, появление распределенных транзакций полностью исключить не удастся, и поэтому основной текущей задачей проекта H-Store является нахождение способов выполнения распределенных транзакций, которые позволили бы свести к минимуму накладные расходы на их фиксацию.
Несмотря на наличие ряда нерешенных проблем, на основе промежуточных результатов проекта H-Store успешно стартовала компания VoltDB. А это означает, что имеются пользователи, для которых новый уровень производительности транзакционных систем важнее технологической завершенности предлагаемых решений.
Назад Содержание Вперёд

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
