2010 г.
Анализ альтернативных архитектур управления транзакциями в "облачной" среде
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Назад Содержание Вперёд
3. Архитектуры распределенных систем баз данных
В этом разделе заново пересматриваются архитектуры распределенных систем баз данных, используемые в сегодняшних "облачных" вычислениях. В качестве отправной точки описывается
классическая многозвенная архитектура приложений баз данных. Затем обсуждаются четыре разновидности этой арихитектуры. Эти разновидности основаны на простых принципах распределенных баз данных – приниципах репликации, разделения и кэширования. Интересным аспектом является то, как эти понятия оформляются и применяются в коммерческих "облачных" службах (разд. 4).
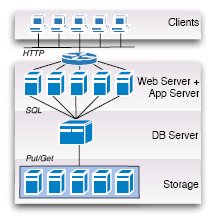
Рис. 1. Классическая архитектура системы баз данных
3.1 Классика
На рис. 1 показана
классическая архитектура, используемая в большинстве сегодняшних приложений баз данных (например, в SAP R/3 [5]). Запросы от клиентов направляются балансировщиком нагрузки (изображенным на рис. 1 в виде карусели) в одну из доступных машин, на которой выполняются Web-сервер и сервер приложений. Web-сервер обрабатывает (HTTP-) запросы, поступающие от клиентов, а сервер приложений выполняет указанную логику приложения с использованием, например, языков Java или C# со встроенным SQL (или LINQ, или какого-либо другого языка программирования баз данных). Операторы встроенного SQL доставляются на сервер баз данных, который интерпретирует запрос, возвращает результат и, возможно, изменяет базу данных. Для обеспечения персистентности сервер баз данных сохраняет все данные и журналы на устройствах хранения данных. Интерфейс между сервером баз данных и системой хранения данных предполагает пересылку физических блоков данных (например, блоков размером в 64 килобайта) с использованием запросов
get и
put. В традиционных системах хранения данных используются диски, подключаемые локально к машине, на которой работает сервер баз данных, или объединяемые в сеть устройства хранения данных (storage area network, SAN). На рис. 1 демонстрируется вариант архитектуры, в котором система хранения данных отделена от сервера баз данных (т.е. SAN). Вместо традиционных вращающихся дисков в системах хранения данных следующего поколения, возможно, будут использоваться твердотельные диски (solid-state disk), основная память или комбинация разных носителей.
Классическая архитектура обеспечивает ряд важных преимуществ. Во-первых, она позволяет использовать на всех уровнях компоненты, являющиеся "лучшими в своем классе" "best-of-breed"). В результате в расчете на каждый из этих уровней образовался жизнеспособный рынок конкурирующих продуктов. Во-вторых, классическая архитектура позволяет добиться масштабируемости и эластичности на уровнях хранения данных и серверов Web и приложений. Например, если требуется скорректировать пропускную способность приложения в соответствии с увеличившейся активностью пользователей, то можно легко увеличить число машин на уровне серверов Web и приложений, чтобы справиться с повысившейся рабочей нагрузкой. Аналогичным образом, при снижении рабочей нагрузки некоторые машины на этом уровне можно отключить или использовать для других целей. На уровне хранения данных можно увеличивать или уменьшать число машин (или дисков) для повышения пропускной способности системы хранения при возрастании рабочей нагрузки и/или для решения проблем, связанных с изменением размеров базы данных.
Потенциальным узким местом классической архитектуры является сервер баз данных. Если сервер баз данных становится перегруженным, единственным выходом из положения является покупка более мощной машины. Машины, используемые для поддержки серверов баз данных, обычно стоят недешево, поскольку они должны уметь справляться с пиковой рабочей нагрузкой. Поэтому классической архитектуре с рис. 1 свойственны ограничения по отношению и к масштабируемости, и к стоимости – двум важным целям "облачных" вычислений. В следующих подразделах этого раздела рассматриваются архитектуры, выбираемыми разработчиками "облачных" служб для преодоления этих ограничений на уровне сервера баз данных.
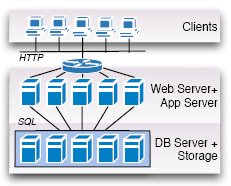
Рис. 2. Разделение
3.2 Разделение
На рис. 2 показано, как можно приспособить классическую архитектуру систем баз данных к использованию разделения данных. Идея проста: вместо того чтобы нагрузить один сервер баз данных управлением всей базой данных целиком, мы логически разделяем эту базу данных и обязываем управлять каждым разделом отдельный сервер баз данных. В литературе баз данных исследовалось много схем разделения; например, вертикальное и горизонтальное разделение, циклическое разделение (round-robin partitioning), разделение с хэшированием (hashing partitioning), разделение по диапазону значений (range partitioning) [8]. Все эти подходы работоспособны и могут быть применены к управлению данными "в облаках".
Варианты архитектуры, представленной на рис. 2, могут различаться не только схемами разделения. Во-первых, разделение может быть прозрачным или видимым для программиста приложений (очевидно, что предпочтительным является прозрачное разделение). Во-вторых, устройства хранения данных могут подключаться к машине, на которой работает сервер баз данных, или быть от нее отделены, например, в сеть устройств хранения данных (как показано на рис. 1). На рис. 2 представлен вариант, в котором доступ к распределенной базе данных является прозрачным, и устройства хранения данных подключаются к каждому серверу баз данных. На практике можно обнаружить использование и других вариантов (разд. 4).
По отношению к cloud computing архитектура с рис. 2 была впервые применена в Force.com – платформе, на которой выполнялось приложение Salesforce, и которая была открыта для выполнения заказных приложений. В Force.com ключом разделения является арендатор (tenant). Другими словами, данные распределяются в зависимости от приложения, которое генерирует эти данные и владеет ими. Разделение охватывает весь серверный стек приложений, включая Web-сервер и сервер приложений. Все запросы, направляемые к одному арендатору, обрабатываются одними и теми же Web-сервером, сервером приложений и сервером баз данных. В результате Force.com настраивается при увеличении числа приложений. Однако архитектура Force.com не поддерживает масштабируемость одного приложения сверх возможностей одного сервера баз данных. Поэтому мы не включили в свое исследование эксперименты с этой платформой. Мы полагаем, что Force.com продемонстрировала бы в наших экспериментах поведение, схожее с поведением вариантов, основанных на классической архитектуре.
Разделение данных и архитектура, представленная на рис. 2, обеспечивают эффективный путь к раскрытию потенциала cloud computing. Серверы баз данных могут функционировать на дешевых машинах, что приводит к использованию большого числа машин, каждая из которых работает с данными довольно небольшого объема, чтобы иметь возможность выдержать нагрузку. Однако у разделения имеются ограничения масштабируемости при наличии колеблющейся рабочей нагрузки: при увеличении или уменьшении числа машин в качестве реакции на возрастание (или снижение) интенсивности рабочей нагрузки запросов/операций обновления требуется перераспределение данных, т.е. пересылка данных между машинами. Чтобы добиться улучшенной масштабируемости и отказоустойчивости, требуется объеденить разделение с репликацией.
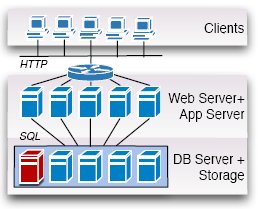
Рис. 3. Репликация
3.3 Репликация
На рис. 3 показано, каким образом в архитектуре систем баз данных может быть использована репликация. Опять же, эта идея проста и активно изучалась в прошлом. Как и в случае разделения, имеется несколько серверов баз данных. Каждый сервер баз данных управляет некоторой копией всей базы данных (или раздела базы данных, если репликация объединяется с разделением). При этом допустимо множество вариантов. На рис. 3 демонстрируется вариант, в котором репликация является прозрачной, и устройства хранения данных присоединены к серверам баз данных. Наиболее важным аспектом схемы репликации является механизм поддержания реплик в согласованном состоянии. Наиболее известен протокол ROWA (read-once, write all – чтение из любой реплики, запись во все реплики), основанный на поддержке эталонной копии (Master copy) [20]. Если репликация не является прозрачной, приложения направляют все запросы на обновление данных серверу баз данных, который управляет эталонной копией, а этот сервер (мастер-сервер, Master server) передает все обновления серверам-сателлитам после того, как эти обновления удается успешно зафиксировать. Приложения могут направлять запросы на чтение данных любому серверу баз данных (мастеру или сателлиту). Если репликация является прозрачной, то запросы автоматически направляются мастеру или сателлиту. На рис. 3 показана прозрачная репликация. Мастер сервер окрашен красным цветом (в левом нижнем углу рисунка).
Серверы баз данных могут работать на дешевом компьютерном оборудовании. В частности, серверы-сателлиты могут работать на дешевых стандартных машинах. Кроме того, архитектура с рис. 3 может хорошо масштабироваться при возрастании и сокращении рабочей нагрузки, если рабочая нагрузка в основном состоит из запросов на чтение данных. При сокращении рабочей нагрузки в любой момент времени любой сервер-сателлит может быть выведен из конфигурации системы. Если рабочая нагрузка возрастает, то при добавлении сервера-сателлита требуется скопировать в него базу данных с мастер-сервера (или какого-либо сервера-сателлита). Как показано в разд. 6, при наличии рабочих нагрузок с большим числом операций обновления мастер-сервер может стать узким местом системы.
Репликацию можно использовать для повышения уровня масштабируемости и надежности системы. Один из протоколов обеспечения надежности на основе репликации был разработан Oracle в составе продукта Oracle RAC [18].
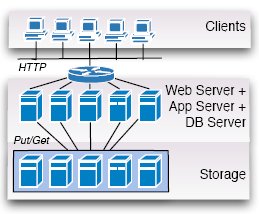
Рис. 4. Распределенное управление
3.4 Распределенное управление
На рис. 4 изображена архитектура, моделирующая систему баз данных как распределенную систему. На первый взгляд, эта архитектура кажется похожей на архитектуры с разделением и репликацией, показанные на рис. 2 и 3. Отличия едва уловимы, но они оказывают колоссальное влияние на реализацию, производительность и стоимость системы. Архитектуру с распределенным управлением можно также охарактеризовать, как
архитектуру с общими дисками (shared-disk architecture) [24] с поддержкой слабых связей между узлами для достижения масштабируемости.
В этой архитектуре система хранения данных отделяется от серверов баз данных, и серверы баз данных параллельно и автономно обращаются к совместно используемым данным, содержащимся в системе хранения. Чтобы синхронизовать доступ по чтению и записи к общим данным, могут применяться распределенные протоколы, обеспечивающие разные уровни согласованности. Как и случаях, рассмотренных в предыдущих подразделах, здесь потенциально применимы самые разнообразные протоколы. Обзор таких протоколов и уровней согласованности приведен в классическом учебнике [27]. Для сокращения накладных расходов уровень управления базами данных сливается с уровнем серверов Web и приложений; другими словами, доступ к базе данных обеспечивается некоторой библиотекой в составе сервера приложений, а не отдельными процессами сервера баз данных.
Потенциально эта архитектура лучше всего подходит для cloud computing. Она обеспечивает полную масштабируемость и эластичность на всех уровнях. Каждый HTTP-запрос может направляться любому серверу (связке "Web-сервер/сервер приложений/сервер баз данных"), так что на этом уровне можно достичь полной масштабируемости. Кроме того, на уровне хранения данные могут любым образом реплицироваться и разделяться, так что масштабируемости можно достичь и на этом уровне. Еще одной особенностью этой архитектуры является то, что на всех уровнях можно использовать дешевую аппаратуру. Однако за эту масштабируемость приходится платить. В соответствии с теоремой CAP [4], невозможно одновременно обеспечить согласованность, доступность и устойчивость к разделению сети. В исследованном нами варианте этой архитектуры (Amazon S3, разд. 4) согласованность принесена в жертву, и обеспечивается только уровень согласованности, называемый согласованностью в конечном счете (eventual consistency) [29]. В терминах баз данных поддержка согласованности в конечном счете обеспечивает долговечность (durability) и, при небольших изменениях, атомарность (atomicy) распределенных транзакций баз данных, но не согласуется с требованием их изоляции (isolation) (т.е. требованием сериализуемости).
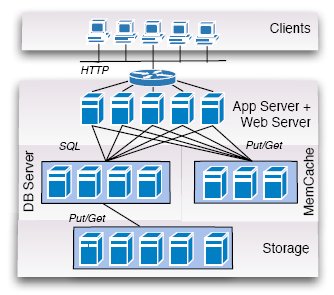
Рис. 5. Кэширование
3.5 Кэширование
На рис. 5 показано, как можно интегрировать кэширование на уровне сервера баз данных. Кэширование может объединяться с другими архитектурами (разделением, репликацией и распределенным управлением). И снова принцип прост: результаты запросов к базе данных сохраняются специальными серверами кэширования. Обычно эти серверы сохраняют результаты запросов в своей основной памяти (main memory), так что доступ к кэшу оказывается настолько быстрым, насколько это возможно. Соответственно, набор кэширующих серверов обычно называется
MemCache. Наиболее широко используемым программным обеспечением (с открытыми исходными текстами), поддерживающим такие распределенные кэши в основной памяти, является Memcached [9].
Как и в случае с репликацией, имеется много разных схем поддержки согласованности кэша при изменениях базы данных. На рис. 5 представлен подход, в котором согласованность кэша контролируется приложением. Этот подход используется в AppEngine компании Google, которая является единственным известным нам поставщиком "облачных" услуг, использующим "ферму" выделенных MemCache-серверов. К сожалению, Google не публикует какие-либо подробности о реализации MemCache.
Кэширование также может помочь в реализации потенциала cloud computing в отношении стоимости и масштабируемости. Для кэширования можно использовать дешевые машины. Кроме того, число кэширующих машин может тривиальным образом увеличиваться и уменьшаться в любой момент времени.
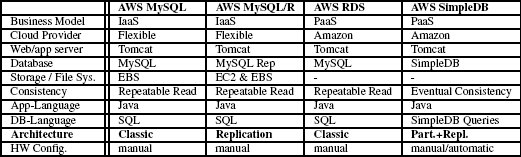
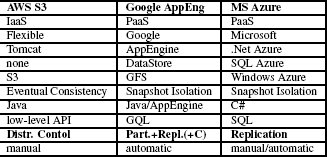
Табл. 1. Общие сведения об "облачных" службах

Назад Содержание Вперёд

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
