HadoopDB: архитектурный гибрид технологий MapReduce и СУБД для аналитических рабочих нагрузок
Азза Абузейд, Камил Байда-Павликовски, Дэниэль Абади, Ави Зильбершац, Александр Разин
Перевод: Сергей Кузнецов
6.2. Тестовые испытания для сравнения производительности и масштабируемости
В первой тестовой задаче ("задачеGrep") требуется просканировать набор данных, состоящий из 100-байтных записей, для нахождения записей, которые содержат заданный шаблон из трех символов. Это единственная задача, в которой требуется обработка большей частью неструктурированных данных, и она была включена в тестовый набор авторами [23], поскольку упоминалась в исходной статье про MapReduce [8].
Для изучения более сложных случаев использования сравниваемых систем в тестовый набор были включены четыре в большей степени аналитические задачи, связанные с анализом журнальных файлов и HTML-документов. Три задачи работают над структурированными данными, а последняя – как над структированными, так и над неструктурированными данными.
Набор данных, с которым работают эти четыре задачи, включает таблицу UserVisits, моделирующую журнальные файлы трафика HTTP-сервера, таблицу Documents, содержащую 600000 случайным образом сгенерированных HTML-документов, и таблицу Ranking, которая содержит некоторые метаданые, вычисленные на основе данных из таблицы Documents. Схемы таблиц тестового набора подробно описаны в [23]. Вкратце, таблица UserVisits содержит 9 атрибутов, наиболее крупным из которых является destinationURL, имеющий тип VARCHAR(100. Каждый кортеж включает примерно 150 байт. Таблица Documents содержит два атрибута: URL (VARCHAR(100)) и contents (произвольный текст). Наконец, таблица Ranking содержит три атрибута: pageURL (VARCHAR(100)), pageRank (INT) и avgDuration (INT).
Генератор данных производит по 155 миллионов записей UserVisits (20 гигабайт) и 18 миллионов записей Ranking (1 гигабайт) на каждый узел. Поскольку генератор данных не обеспечивает попадание в один узел кортежей Ranking и UserVisits с одним и тем же значением атрибута URL, во время загрузки данных производится их переразделение, как описывается ниже.
Записи наборов данных UserVisits и Ranking сохраняются в HDFS в виде плоского текста, по одной записи в строке с полями, разделяемыми специальным символом-разделителем. Для обеспечения доступа во время выполнения к разным атрибутам функции Map и Reduce расщепляют запись по разделителю, образуя массив строк.
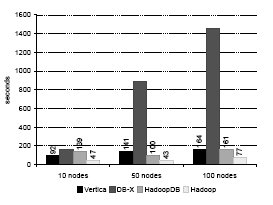
Рис. 3. Загрузка данных для задачи Grep (0,5 гигабайта на узел)
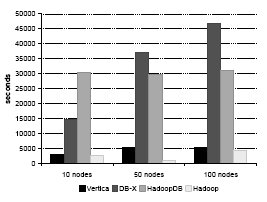
Рис. 4. Загрузка набора данных UserVisits (20 гигабайт на узел)
6.2.1 Загрузка данных
На рис. 3 и 4 показано время загрузки двух наборов данных –Grep и UserVisits. В то время как данные задачи Grep генерируются случайным образом, и для них не требуется какая-либо предварительная обработка, данные UserVisits нужно во время загрузки переразделять по destinationURL и индексировать во всех базах данных по visitDate, чтобы добиться лучшей производительности на аналитических запросах (системе Hadoop такое переразделение пользы бы не принесло). Кратко опишем процесс загрузки для всех систем.
Hadoop: Данные в каждом узле загружались в неизменяемом виде из файла UserVisits. HDFS автоматически разбивает файл на блоки размеров 256 мегабайт и сохраняет блоки в локальных DataNode. Поскольку все узлы загружали свои данные в параллель, для кластера каждого размера мы указываем максимальное время загрузки в его узлах. На время загрузки сильно влияют "отстающие". Этот эффект особенно заметен при загрузке UserVisits, где в 100-узловом кластере наличие одного медленного узла привело к увеличению общего времени загрузки до 4355 секунд, а в 10-узловом – до 2600 секунд при среднем времени загрузки по всем узлам всего 1100 секунд.
HadoopDB: В качестве максимального размера чанка мы установили 1 гигабайт. Каждый чанк размещался в отдельной базе данных PostgreSQL, и SQL-запросы к нему обрабатывались независимо от запросов к другим чанкам. Мы указываем максимальное время загрузки по всем узлам, имея в виду полное время загрузки и Grep, и UserVisits.
Поскольку для набора данных Grep не требуется какая-либо предварительная обработка, и на каждый узел приходится всего 535 мегабайт данных, все данные загружались с использованием стандартной команды SQL COPY в один чанк в каждом узле.
Global Hasher разделяет набор данных UserVisits по всем узлам кластера. После этого Local Hasher выбирает из HDFS 20-гигабайтный раздел и хэш-разделяет его на 20 более мелких чанков. Затем каждый чанк массовым образом загружается с использованием команды COPY. В заключение для каждого чанка создается индекс по visitDate.
Процесс загрузки UserVisits разбивается на несколько шагов. Наиболее дорогостоящим шагом этого процесса является первое переразделение, выполняемое Global Hasher. Оно занимает почти половину общего времени загрузки – 14000 секунд. Из оставшихся 16000 секунд 2500 секунд (15,6%) выполняется локальное разделение данных на 20 чанков; массовое копирование в таблицы занимает 5200 секунд (32,5%); на создание кластеризованных индексов (включая сортировку) тратится 7100 секунд (44,4%); и на завершающую очистку (vacuuming) баз данных уходит 7200 секунд (7,5%). Все шаги после глобального переразделения выполняются параллельно во всех узлах. Время загрузки в разных узлах различалось. В некоторых узлах загрузка UserVisits полностью завершалась всего за 10000 секунд после конца глобального переразделения.
Vertica: Процедура загрузки для Vertica аналогична той, которая описана в [23]. Время загрузки сократилось, поскольку для экспериментов использовалась более новая версия Vertica (3.0). Основное отличие состоит в том, что теперь команда массовой загрузки COPY выполняется во всех узлах кластера полностью параллельно.
СУБД-X: Мы указываем общее время загрузки, включая сжатие данных и построения индексов, взятое из [23].
В отличие от СУБД-X, возможности параллельной загрузки Hadoop, HadoopDB и Vertica обеспечивают масштабирование всех этих систем при увеличении числа узлов. Поскольку скорость загрузки ограничивается самой низкой скоростью записи на диск в кластере, загрузка – это единственный процесс, для которого естественная устойчивость Hadoop и HadoopDB к неоднородности среды не обеспечивает никаких преимуществ8.
6.2.2. Задача Grep
Каждая запись состоит из уникального ключа в первых 10 байтах и 90-байтной строки символов. Шаблон "XYZ" ищется в 90-байтном поле, и в каждых 10000 записей содержится одна такая подстрока. В каждом узле содержится 5,6 миллионов таких 100-байтных записей, или примерно 535 мегабайт данных. Общее число записей, обрабатываемых в кластере с заданным числом услов, составляет 5600000 × (число узлов).
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялся один и тот же SQL-запрос:
SELECT * FROM Data WHERE field LIKE ‘%XYZ%’;
Ни у одной из сравниваемых систем не было индекса на атрибуте символьной строки. Поэтому во всех системах требовалось полное сканирование таблицы, и производительность в основном органичивалась скоростью дисков.
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в [23] (одна функция Map, сравнивающая подстроки с "XYZ"). В этом случае функция Reduce не требовалась, и результаты Map напрямую записывались в HDFS.
Планировщик HadoopDB SMS проталкивал раздел WHERE в экземпляры PostgreSQL.
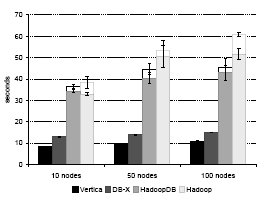
Рис. 5. Задача Grep
На рис. 5 показаны результаты (смысл столбцов с разрывом пояснялся в подразделе 6.1). Производительность HadoopDB немного выше, чем у Hadoop, поскольку наша система более эффективно производит ввод-вывод из-за отсутствия разбора данных во время выполнения. Однако обе системы проигрывают в производительности параллельным системам баз данных. Это объясняется тем, что и в Vertica, и в СУБД-X данные сжимаются, что существенно сокращает объем ввода-вывода (в [23] отмечается, что во всех экспериментах сжатие данных приводило к ускорению СУБД-X почти на 50%).
6.2.3. Задача фильтрации
В первой задаче над структурированными данными таблицаRankings фильтруется по простому условию на атрибуте pageRank. Этому условию удовлетворяют примерно 36000 кортежей в каждом узле.
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялся один и тот же SQL-запрос:
SELECT pageURL, pageRank FROM Rankings WHERE pageRank > 10;
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в [23]: функция Map разбирает кортежи Rankings с использованием поля-разделителя, применяет предикат на pageRank и помещает в результат pageURL и pageRank из кортежей, удовлетворяющих условию, в виде пара "ключ-значение". Функция Reduce в данном случае не требуется.
Планировщик HadoopDB SMS проталкивает разделы WHERE и SELECT в экземпляры PostgreSQL.
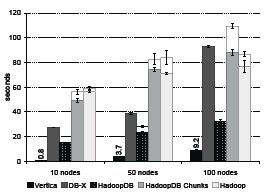
Рис. 6. Задача фильтрации
Производительность каждой системы показана на рис. 6. В Hadoop (с использованием и без использования Hive) применяется принцип грубой силы, полность сканируются все данные файла. Однако другие системы выигрывают от использования кластеризованных индексов на столбце pageRank. Поэтому в целом HadoopDB и параллельным системам баз данных удается превзойти HadoopDB по производительности.
Поскольку данные UserVisits разделяются по destinationURL, наличие связи по внешнему ключу между pageURL таблицы Rankings и destinationURL таблицы UserVisits приводит к тому, что Global Hasher и Local Hasher переразделяют Rankings по pageURL. Каждый чанк таблицы Rankings составляет всего 50 мегабайт (располагаясь совместно с соответствующим гигабайтным чанком таблицы UserVisits). Накладные расходы на планирование двадцати задач Map для обработки всего одного гигабайта данных на узел приводят к значительному снижению производительности HadoopDB.
Поэтому мы поддерживаем дополнительную, не разделенную на чанки копию таблицы Rankings, содержащую по одному гигабайту на узел. При работе с таким набором данных HadoopDB превосходит по производительности Hadoop, поскольку использование кластеризованного индекса по pageRank позволяет отказаться от последовательного сканирования всего набора данных. HadoopDB масштабируется лучше, чем СУБД-X и Vertica, в основном из-за возрастающих сетевых накладных расходов этих систем, которые выходят на первый план, когда время выполнения запроса в других отношениях является очень незначительным.
6.2.4. Задача агрегации
В следующей задаче вычисляются суммы значений атрибутаadRevenue (доходы от рекламы) для групп кортежей таблицы UserVisits, получаемых путем группировки этой таблицы либо по первым семи символам столбца sourceIP, либо по всему этому столбцу. В отличие от предыдущих задач, при решении этой задачи требуется обмен промежуточными результатами между разными узлами кластера (чтобы можно было вычислить окончательные агрегатные значения). При группировке по семибайтному префиксу образуется 2000 уникальных групп. При группировке по всему sourceIP число таких групп составляет 2500000.
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялись одни и те же SQL-запросы:
небольшой запрос:
SELECT SUBSTR(sourceIP, 1, 7), SUM(adRevenue) FROM UserVisits GROUP BY SUBSTR(sourceIP, 1, 7);
крупный запрос:
SELECT sourceIP, SUM(adRevenue) FROM UserVisits GROUP BY sourceIP;
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в [23]: функция Map выводит adRevenue и первые семь символов поля sourceIP (или все поле в случае крупного запроса), и эти данные передаются функции Reduce, которая выполняет требуемую агрегацию для каждого префикса (или всего значения) sourceIP.
В HadoopDB планировщик SMS проталкивает весь SQL-запрос в экземпляры PostgreSQL. Полученные результаты передаются задачам Reduce в Hadoop, которые выполняют окончательную агрегацию (после сбора всех предварительных частичных агрегатов от всех экземпляров).
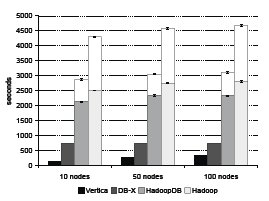
Рис. 7. Крупная задача агрегации
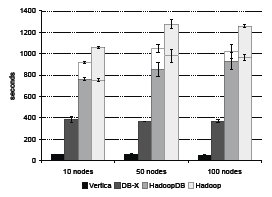
Рис. 8. Малая задача агрегации
Показатели производительности всех сравниваемых систем показаны на рис. 7 и 8. Аналогично задаче Grep, на время выполнения этого запроса влияет скорость чтения с диска. Поэтому обе коммерческие системы получают преимущества от сжатия данных и превосходят по производительности HadoopDB и Hadoop.
"Малая" (с группировкой по подстроке) задача агрегации демонстрирует исключение из того общего правила, что Hive добавляет накладные расходы к Hadoop, кодируемому вручную (на рис. 8 время, затраченное Hadoop при выполнении плана, который был подготовлен с использованием Hive, представлено нижней частью столбца Hadoop). План, подготовленный Hive, выполняется гораздо быстрее задания, закодированного вручную, потому что в нем используется стратегия хэш-агрегации (на фазе Map задания поддерживается внутренняя схема хэширования-агрегации), которая оказывается оптимальной при небольшом числе групп. При решении крупной задачи агрегации Hive переключается на стратегию агрегации путем сортировки, обнаруживая, что число групп превышает половину числа входных записей, помещающихся в одном блоке. В плане для Hadoop, закодированном нами (и авторами [23]) вручную, мы не смогли применить хэш-агрегацию для "малого" запроса, потому что общепринятой практикой MapReduce является использование агрегации путем сортировки (с применением комбинаторов (combiner)).
Эти результаты иллюстрируют преимущество использования оптимизаторов, которые присутствуют в системах баз данных и системах обработки реляционных запросов, подобных Hive, и могут использовать статистические данные из каталогов системы или простые правила оптимизации для выбора между хэш-агрегацией и агрегацией путем сортировки.
В отличие от комбинаторов Hadoop, Hive сериализует частичные агрегаты в строки, а не поддерживает их в естественном бинарном представлении. Поэтому при обработке крупного запроса план, построенный Hive, выполняется намного дольше плана, закодированного для Hadoop вручную.
В PostgreSQL при решении обеих задач используется хэш-агрегация, поскольку таблица хэш-агрегации для каждого гигабайтного чанка легко помещается в основной памяти. Из-за применения этой эффективной реализации агрегации HadoopDB превосходит по производительности Hadoop при решении обеих задач.
Эти запросы хорошо подходят для систем с поколоночным хранением таблиц, поскольку два атрибута, требуемые для выполнения запроса (sourceIP и adRevenue) включают всего 20 байт из более чем 200 байт каждой записи UserVisits. Из-за соответствующей экономии ввода-вывода производительность Vertica оказывается значительно выше производительности других систем.
6.2.5. Задача соединения
Задача соединения состоит в нахождении среднего значенияpageRank набора страниц, посещенных из sourceIP, которые принесли наибольший доход от рекламы в течение недели с 15 по 22 января 2009 г. Ключевое различие между этой и предыдущими задачами состоит в том, что теперь требуется считывать данные из двух разных наборов данных и соединять эти данные (информация о рейтинге станиц (pageRank) находится в таблице Rankings, а информация о доходе от рекламы (adRevenue) – в таблице UserVisits). В таблице UserVisits имеется примерно 134000 записей, у которых значение атрибута visitDate попадает в заданный интервал времени.
В отличие от трех предыдущих задач, мы не могли использовать одни и те же формулировки запросов на SQL и для параллельных систем баз данных, и для систем, основанных на Hadoop. Это связано с тем, что версия Hive, которую мы расширяли, требуемый запрос обработать не могла. Хотя эта версия принимала на обработку SQL-запрос, который соединял, отфильтровывал и агрегировал кортежи из двух таблиц, выполнить сгенерированный план в среде Hadoop не удавалось. Кроме того, мы заметили, что в плане запросов с соединениями данного типа использовалась исключительно неэффективная стратегия выполнения. В частности, операция фильтрации планировалась позже соединения таблиц. Поэтому для такого запроса мы можем представить только результаты выполнения планов, закодированых вручную.
В HadoopDB мы проталкивали в экземпляры SQL фильтрацию, соединение и частичную агрегацию с использованием следующего SQL-запроса:
SELECT sourceIP, COUNT(pageRank), SUM(pageRank), SUM(adRevenue) FROM Rankings AS R, UserVisits AS UV WHERE R.pageURL = UV.destURL AND UV.visitDate BETWEEN ‘2000-01-15’ AND ‘2000-01-22’ GROUP BY UV.sourceIP;
Затем мы использовали в Hadoop одну задачу Reduce, которая собирала все частичные агрегаты от всех экземпляров PostgreSQL и выполняла окончательную агрегацию.
Параллельные системы баз данных выполняли тот же SQL-запрос, что и в [23].
Хотя в Hadoop имеется поддержка операции соединения, для ее выполнения требуется, чтобы оба набора данных были отсортированы по ключу соединения. Это требование ограничивает применимость операции соединения, поскольку во многих случаях, включая рассматриваемый запрос, такая сортировка автоматически не обеспечивается, а выполнение сортировки до соединения добавляет существенные накладные расходы. Мы установили, что даже если бы мы отсортировали входные данные (и не включили бы время сортировки в общее время выполнения запроса), производительность запроса на основе Hadoop-соединения была бы ниже производительности запроса с использованием трехфазной MR-программы, применявшейся в [23] (которая основывалась на стандартных операциях 'Map' и 'Reduce'). Поэтому наши результаты получены путем использования той же MR-программы, которая использовалась (и подробно описывалась) в [23].
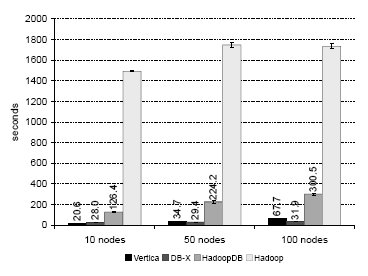
Рис. 9. Задача соединения
На рис. 9 приводится сводка результатов, полученных при прогонах этой тестовой задачи. Для Hadoop получены результаты, аналогичные приведенным в [23]: производительность системы ограничивается тем, что она полностью сканирует набор данных UserVisits в каждом узле для выполнения фильтрации данных.
HadoopDB, СУБД-X и Vertica показывают более высокую производительность за счет использования индексов для ускорения фильтрации и наличия естественной поддержки соединений. Эти системы демонстрируют незначительное ухудшение производительности при увеличении числа узлов из-за финальной одноузловой агрегации adRevenue и сортировки по полученным агрегатным значениям.
6.2.6. Задача агрегации с использованием UDF
В последней задаче для каждого документа из таблицыDocuments нужно посчитать число входящих в него ссылок из других документов из той же таблицы. Для Hadoop и Vertica HTML-документы объединяются в более крупные файлы, каждый размером в 256 и 56 мегабайт соответственно. Система HadoopDB могла хранить каждый документ по отдельности в таблице Documents с использованием типа данных TEXT. СУБД-X обрабатывала по отдельности каждый файл с HTML-документом, как описывается ниже.
Теоретически в параллельных системах баз данных следовало бы иметь возможность использования определяемой пользователями функции F для разбора содержимого каждого документа и порождения списка всех URL, обнаруживаемых в документе. Затем можно было бы поместить этот список во временную таблицу и выполнить над ней простой запрос с COUNT и GROUP BY, подсчитывающий число вхождений каждого уникального URL.
К сожалению, как было установлено в [23], внутри используемых параллельных систем баз данных реализовать такую UDF было затруднительно. В СУБД-X отсутствовала возможность сохранения каждого документа в базе данных в виде символьного BLOB и определения UDF, работающей прямо с такими BLOB'ами, по причине "известной ошибки в [данной] версии системы". Поэтому UDF была реализована внутри СУБД, но данные хранились в отдельных HTML-документах во внешней файловой системе, и UDF производила требуемые внешние вызовы.
В Vertica в настоящее время UDF не поддерживаются, и поэтому пришлось написать на Java простой парсер документов, работающий вне СУБД. Этот парсер параллельно выполнялся в каждом узле, разбирая файл с конкатенированными документами и записывая в файл на локальном диске обнаруживаемые URL. Затем этот файл загружался во временную таблицу с использованием средства массовой загрузки Vertica, и выполнялся второй запрос, который подсчитывался число входящих ссылок.
В Hadoop мы использовали стандартное средство TextInputFormat, которое разбирало внутри задачи Map каждый документ и выводило список обнаруженных в нем URL. Функции Combine и Reduce суммировали число экземпляров каждого уникального URL.
Что касается HadoopDB, то поскольку текстовая обработка значительно проще выражается в MapReduce, мы решили воспользоваться той возможностью, что в HadoopDB допускаются запросы либо на SQL, либо в терминах MapReduce, и применили в данном случае второй вариант. Все содержимое таблицы Documents в каждом узле PostgreSQL передавалось в Hadoop с использованием следующего оператора SQL:
SELECT url, contents FROM Documents;
После этого данные обрабатывались с использованием задания MR. На самом деле, в Hadoop и HadoopDB использовался один и тот же код MR.
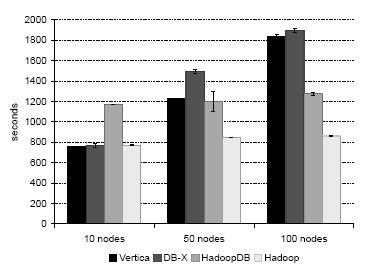
Рис. 10. Задача агрегации с применением UDF
Рис. 10 иллюстрирует преимущество использования гибридной системы, подобной HadoopDB. Уровень баз данных позволяет эффективно хранить текстовые HTML-документы, а среда MapReduce обеспечивает требуемую мощность их обработки.
Hadoop превосходит HadoopDB по производительности, если обрабатывает файлы, в которых склеено несколько HTML-документов. Однако в HadoopDB не утрачивается исходная структура данных, поскольку не требуется склейка файлов HTML-документов. Заметим, что общее время такой склейки составляет около 6000 секунд на узел. Эти накладные расходы на рис. 10 не учитываются.
Производительность СУБД-X и Vertica ниже, чем у систем, основанных на Hadoop, поскольку входные файлы хранятся вне базы данных. Кроме того, при решении этой задачи обе коммерческие СУБД не масштабируются линейным образом при увеличении числа узлов в кластере.
8 Диски EC2 медленно работают при начальной записи. Однако скорость записи не влияла на тестовые испытания производительности. Кроме того, до начала экспериментов диски инициализировались.