2009 г.
Управление параллелизмом с низкими накладными расходами для разделенных баз данных в основной памяти
Эван Джонс, Дэниэль Абади и Сэмуэль Мэдден
Перевод: Сергей Кузнецов
Назад Содержание Вперёд
5. Экспериментальная оценка
В этом разделе мы исследуем достоинства и недостатки описанных выше схем управления параллелизмом путем сравнения их эффективности на некоторых микротестах и тестовом наборе, основанном на TPC-C. Микротесты разрабатывались с целью выявления важных различий между подходами, в них могут не отражаться свойства каких-либо конкретных приложений. Наш тестовый набор TPC-C направлен на получение характеристик производительности более полного и реалистичного приложения OLTP.
Наш прототип написан на языке C++ и выполняется под управлением Linux. Мы используем шесть двухпроцессорных серверов с процессорами Xeon 3.20 GHz и двумя гигабайтами основной памяти каждый. Машины соединены одним коммутатором гигабайтного Ethernet. Клиенты выполняются в разных потоках управления на одной машине. Для каждого теста мы использовали 15 секунд "разогрева", после чего следовали 60 секунд измерений (более долгие тесты не приводили к изменению результатов). Мы измеряли число транзакций, завершенных всеми клиентами в период измерения. Каждое измерение повторялось три раза. Мы показываем только средние значения, поскольку расхождения между реальными результатами измерений составляют всего несколько процентов.
Для пропуска микротестов в качестве исполнительного механизма использовалось простое хранилище данных "ключ-значение", в котором ключами и значениями являлись произвольные строки байтов. Поддерживалась одна транзакция, которая читала и обновляла некоторый набор значений. Мы использовали небольшие 3-байтовые ключи и 4-байтовые значения, чтобы избежать сложностей, порождаемых временем передачи данных.
Для пропуска тестов TPC-C мы использовали специально разработанный исполнительный механизм, который выполнял транзакции прямо над данными в основной памяти. Каждая таблица представлялась в завимости от обстоятельств в виде либо B-дерева, либо двоичного дерева, либо хэш-таблицы.
На всех тестах сравнивались три схемы управления параллелизмом, описанные в разд. 4.
5.1. Микротесты
В нашем микротестовом наборе использовалась простая смесь однораздельных и многораздельных транзакций, поволяющая понять влияние на пропускную способность распределенных транзакций. Мы создали базу данных, состоящую из двух разделов, каждый из которых размещался в отдельной машине. В каждом разделе хранилась половина ключей. От каждого клиента поступали транзакции с операциями чтения и записи значений, связанных с 12 ключами. В этом тесте отсутствовало совместное использование: операции записи каждого клиента затрагивали свой набор ключей. В следующем подразделе описываются эксперименты при наличии совместно используемых данных. Для создания однораздельной транзакции в клиенте случайным образом выбирался раздел, и затем производился доступ к 12 ключам в этом разделе. Для создания многораздельной транзакции ключи делились поровну, чтобы в каждом разделе производился доступ к 6 ключам. С целью полной загрузки процессоров в обоих разделах мы использовали 40 одновременно работающих клиентов. Каждый клиент выдавал один запрос, ждал ответа, после чего выдавал следующий запрос.
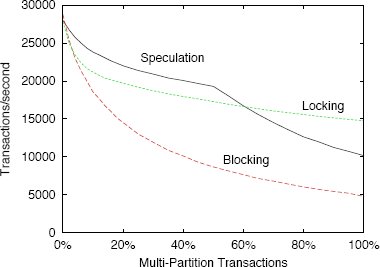
Рис. 4. Микротестирование без конфликтов
Мы изменяли долю многораздельных транзакций и измеряли пропускную способность системы. Результаты показаны на рис. 4. С точки зрения приложения многораздельные и однораздельные транзакции выполняют один и тот же объем работы, так в что идеале пропускная способность системы должна была бы оставаться постоянной. Однако накладные расходы на управление параллелизмом отклоняют нас от этого идеала. Производительность системы при использовании блокировок меняется линейно в диапазоне от 16 до 100% многораздельных транзакций. Это объясняется отсутствием конфликтов между этими транзакциями, так что все они могут выполняться одновременно. Небольшое снижение производительности при росте числа многораздельных транзакций связано с тем, что многораздельным транзакциям свойственны дополнительные коммуникационные накладные расходы, и поэтому производительность системы немного падает при росте доли таких транзакций в общей рабочей нагрузке.
Наиболее интересная часть результатов схемы синхронизационных блокировок относится к диапазону между 0 и 16% доли многораздельных транзакций. Как и следовало ожидать, производительность системы с использованием этой схемы очень близка к производительности системы при использовании других схем, поскольку, благодаря нашей оптимизации, при отсутствии многораздельных транзакций синхронизационные блокировки не устанавливаются. Далее производительность резко падает вплоть до правой границы диапазона (16%). При такой доле многораздельных транзакций обычно выполняется по крайней мере одна многораздельная транзакция, и, следовательно, почти все транзакции выполняются с установкой синхронизационных блокировок.
Производительность системы с использованием блокирующей схемы падает достаточно стремительно, так что она никогда не превышает производительность системы со схемой синхронизационных блокировок. Причина состоит в том, что преимущества выполнения транзакций без запросов синхронизационных блокировок перевешиваются потерями, вызываемыми временем простоя в ожидании завершения двухфазной фиксации. В нашей реализации схемы синхронизационных блокировок многие транзакции выполняются без блокировок, если многораздельных транзакций немного, так что у блокирующей схемы нет преимуществ. Если бы мы вынуждали транзакции всегда запрашивать синхронизационные блокировки, то система с применением блокирующей схемой превосходила бы по производительности систему с синхронизационными блокировками, когда доля многораздельных транзакций составляет от 0 до 6%.
При наличии доли многораздельных транзакций в диапазоне от 0 до 50% производительность систем со спекулятивной схемой и синхронизационными блокировками на графике изображается почти параллельными кривыми, хотя производительность системы со спекулятивной схемой примерно на 10% выше. Поскольку рабочая нагрузка в данном случае состоит из одноузловых и простых многоузловых транзакций, для спекулятивного выполнения всех этих транзакций оказывается достаточно одного координатора. Это позволяет выполнять транзакции параллельно, как и при использовании синхронизационных блокировок, но без накладных расходов на отслеживание блокировок. Когда доля многораздельных транзакций составляет более 50%, производительность системы со спекулятивной схемой начинает падать. В этой точке центральный координатор использует 100% ресурсов процессора и не может обрабатывать большее число сообщений. Для масштабирования системы в диапазоне от 50 до 100% доли многораздельных транзакций нужно было бы реализовать распределенное упорядочивание транзакций, как это описывалось в п. 4.2.2.
В этом эксперименте блокирование всегда оказывается хуже спекуляции и синхронизационных блокировок. Производительность системы со спекулятивной схемой превосходит производительность системы с синхронизационными блокировками в лучшем случае на 13%, прежде чем центральный координатор становится узким местом. После этого система с синхронизационными блокировками показывает производительность, на 45% (в лучшем случае) большую производительности системы со спекулятиной схемой.
5.2. Конфликты
Эффективность схемы с синхронизационными блокировками зависит от наличия или отсутствия конфликтов между транзакциями. При отсутствии конфликтов транзакции выполняются параллельно. Однако при их наличии возникают дополнительные накладные расходы на приостановку и возобновление выполнения. Для изучения влияния конфликтов мы изменяем распределение ключей, к которым обращаются клиенты. При запуске однораздельных транзакций первый клиент запускает только транзакции в первом разделе, а второй – только во втором разделе (вместо того чтобы выбирать раздел для своей транзакции случайным образом). Значения с ключами первых двух клиентов в их транзакциях изменяются. Чтобы вызвать конфликты, другие клиенты производят доступ к одному из таких "конфликтных" ключей с вероятностью
p или обращаются к одному из своих частных ключей с вероятностью 1 -
p. С высокой вероятностью такие транзакции попытаются изменить некоторое значение в то же время, что и первые два клиента. Увеличение
p приводит к большему числу конфликтов. Синхронизационные тупики в этой рабочей нагрузке невозможны, что позволило нам избежать влияния на производительность зависящих от реализации политик разрешения такие ситуаций.
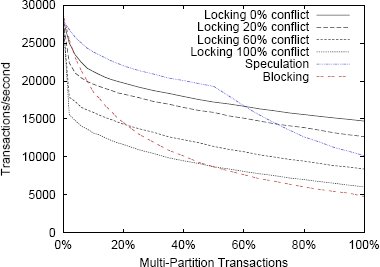
Рис. 5. Микротестирование при наличии конфликтов
На рис. 5 показаны результаты экспериментов. Графики зависимости производительности системы от общего числа транзакций и доли многораздельных транзакций в случаях использования блокирующей и спекулятивных схем не меняются при изменении вероятности конфликта. Так происходит потому, что в этих системах предполагается наличие конфликта между всеми транзакциями. С другой стороны, производительность системы с использованием схемы синхронизационных блокировок при повышении частоты конфликтов падает. Если при отсутствии конфликтов график проиводительности этого варианта системы близок к прямой, то при наличии конфликтов производительность системы резко падает при увеличении доли многораздельных транзакций. Это связано с тем, что по мере роста частоты конфликтов схема с синхронизационными блокировками ведет себя все более похоже на блокировочную схему. Тем не менее, система с синхронизационными блокировками превосходит по производительности систему с блокировочной схемой при наличии большого числа многораздельных транзакций, потому что в данной рабочей нагрузке каждая транзакция конфликтует только в одном разделе, так что некоторую часть работы удается выполнять параллельно. Однако эти результаты наводят на мысль, что преимущества подхода с отказом от управления параллелизмом становятся тем больше, чем более распространены конфликтные ситуации. В данном эксперименте система со спекулятивной схемой показала производительность, в два с половиной раза большую, чем система со схемой синхронизационных блокировок.
5.3. Аварийное завершение транзакций
Спекулятивная схема основана не предположении, что транзакции будут фиксироваться. Если транзакция завершается аварийно, то спекулятивно выполненные транзакции должны откатываться и выполняться заново, что приводит к лишним тратам времени процессора. Для лучшего понимания эффекта повторного выполнения мы случайным образом с вероятностью
p выбираем транзакцию для аварийного завершения. Если выбирается многораздельная транзакция, то только в одном разделе она будет аварийно завершена локально. В другом разделе ее аварийное завершение будет происходить в ходе двухфазной фиксации. Аварийно завершенные транзакции несколько дешевле выполнять повторно, чем обычные транзакции, поскольку аварийное завершение происходит в начале исходного выполнения. Во всех других отношениях они идентичны (например, требуются сетевые сообщения той же длины).
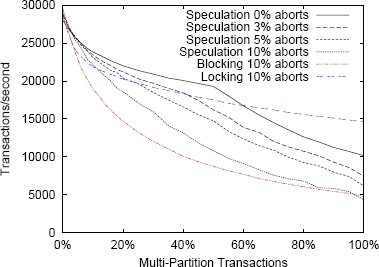
Рис. 6. Микротестирование с аварийным завершением транзакций
Результаты этого эксперимента показаны на рис. 6. Стоимость аварийного завершения изменчива, в зависимости от того, сколько спекулятивно выполненных транзакций требуется выполнить заново. Однако расхождения находятся в пределах 5%, и для простоты мы их не учитываем. Поскольку при использовании блокирующей схемы и схемы с синхронизационными блокировками каскадное аварийное завершение отсутствует, частота аварийных завершений не оказывает существенного влияния, и мы показываем только результаты для вероятности 10%. Пропускная способность системы оказывается немного выше, чем в случае, когда вероятность равняется 0%, поскольку для аварийного завершения транзакций требуется меньше процессорного времени.
Как и следовало ожидать, аварийные завершения снижают пропускную способность системы со спекулятивной схемой из-за расходов на повторное выполнение транзакций. При этом также увеличивается число сообщений, обрабатываемых центральным координатором, что приводит к его более быстрому "насыщению". Однако, несмотря на наличие ограничений центрального кординатора, производительность системы со спекулятивной схемой все еще превосходит производительность системы с синхронизационными блокировками, пока доля аварийно завершаемых транзакций не достигает 5%. Когда доля аварийно завершающихся транзакций достигает 10%, система со спекулятивной схемой становится близка по производительности к системе с блокировочной схемой, поскольку некоторые транзакции приходится повторно выполнять по много раз. Это говорит о том, что если у транзакций велика вероятность аварийного завершения, то лучше ограничить объем спекулятивного выполнения, чтобы избежать напрасных затрат процессорного времени.
5.4. Многораздельные транзакции общего вида
При выполнении многораздельной транзакции, для которой требуется несколько циклов коммуникаций, спекулятивное выполнение в некотором разделе можно начать только тогда, когда эта транзакция завершит всю свою работу в этом разделе. Это означает, что должны иметься простои между выполнением отдельных фрагментов транзакции. Что проанализировать влияние таких транзакций на производительность, мы изменили свои микротесты таким образом, что для выполнения многораздельных транзакций требовалось два цикла коммуникаций (т.е. многораздельные транзакции перестали быть простыми, как это было в ранее описанных экспериментах). В первом цикле каждой транзакции выполнялись операции чтения, и результаты возвращались координатору, который во втором цикле запрашивал выполнение операций записи. В результате выполнялся тот же объем работы, что и в исходном тестовом наборе, но сообщений было в два раза больше.
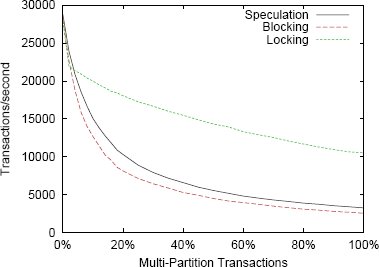
Рис. 7. Микротестирование транзакций общего вида
Результаты показаны на рис. 7. Пропускная способность системы с блокирующей схемой изменяется примерно так же, как и раньше, но она меньше, поскольку для выполнения транзакций с двумя циклами коммуникаций требуется почти в два раза больше времени, чем в предыдущих экспериментах. Спекулятивная схема работает лишь не намного лучше, поскольку после завершения одной многораздельной транзакции спекулятивно может выполняться только первый фрагмент следующей такой же транзакции. На систему со схемой синхронизационных блокировок добавление цикла сетевых коммуникаций влияет относительно меньше. Но, хотя для этой рабочей нагрузки система со схемой с синхронизационными блокировками, вообще говоря, превосходит по производительности все другие варианты, она уступает системе со спекулятивной схемой, когда доля многораздельных транзакций составляет менее 4%.
5.5. TPC-C
Тестовый набор TPC-C моделирует рабочую нагрузку системы обработки заказов. Он состоит из
смеси из шести транзакций с разными свойствами. Размер данных масштабируется путем добавления складов, в результате чего наборы соответствующих записей добавляются к другим таблицам. Как описывается в статье Стоубрейкера (Michael Stonebraker) и др. [26], мы разделяем базу данных TPC-C по складам. Мы вертикально разделяем таблицу наличных товаров и реплицируем во всех разделах только читаемые столбцы, оставляя обновляемые столбцы в одном разделе. Такое разделение приводит к тому, что 89% транзакций является однораздельными, а остальные – простыми многораздельными транзакциями.
В своей реализации мы стремимся следовать спецификации TPC-C, но имеются три отличия. Во-первых, в новой транзакции заказа мы изменяем порядок операций, чтобы избежать потребности в буфере отката при обработке аварийных завершений по инициативе пользователей. Во-вторых, у наших клиентов отсутствуют паузы. Вместо этого они сразу после получения результатов одной транзакции образуют следующую транзакцию. Это позволяет нам поддерживать высокий темп поступления транзакций при небольшом числе складов. Наконец, мы изменяем способ генерации запросов пользователей. В соответствии со спецификацией TPC-C клиентам назначается конкретная пара (склад, округ). Поэтому при добавлении складов добавляются и клиенты. Мы используем фиксированное число клиентов при изменении числа складов, чтобы можно было изменять только одну переменную. Чтобы достичь этого, в запросах наших клиентов используются назначенные номера складов, но округ выбирается случайным образом.
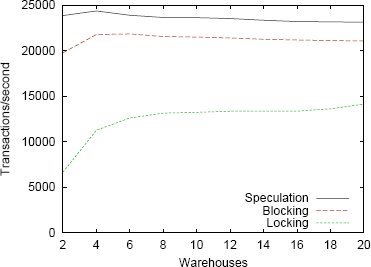
Рис. 8. Пропускная способность на TPC-C при изменении числа складов
Мы пропускали TPC-C над базой данных, в которой склады были поровну поделены между двумя разделами. В этой рабочей нагрузке доля многораздельных транзакций варьировалась от 5,7% с 20 складами до 10,7% с 2 складами. Пропускная способность для изменяющегося числа складов показана на рис. 8. При этой рабочей нагрузке производительность вариантов системы с блокировочной и спекулятивной схемами относительно мало меняется при возрастании числа складов. Наименьшая производительность демонстрируется при наличии двух складов, поскольку в этой ситуации наиболее велика вероятность появления многораздельных транзакций (10,7% против 7,2 при 4 складах и 5,7 при 20 складах) из-за применяемого способа генерации новых транзакций заказа. После возрастания числа складов до четырех производительность вариантов системы с блокировочной и спекулятивной схемами слегка падает. Это происходит из-за более крупного размера рабочего набора и соответствующего возрастания числа промахов при поиске данных в кэше и TLB. Производительность системы со схемой синхронизационных блокировок при росте числа складов возрастает, потому что уменьшается число конфликтующих транзакций. Так происходит из-за того, что на один склад TPC-C приходится меньше клиентов, а почти каждая транзакция модифицирует записи склада и округа. Эта рабочая нагрузка также приводит к синхронизационным тупикам, из-за чего возникают накладные расходы на обнаружение локальных тупиков и таймауты для распределенных тупиков. Это снижает производительность схемы с синхронизационными блокировками. Спекулятивная схема работает лучше всех других, поскольку доля многораздельных транзакций находится в пределах диапазона, для которого эта схема более всего пригодна. При 20 складах система со спекулятивной схемой обеспечивает производительность, на 9,7% более высокую, чем система с блокировочной схемой, и на 63% более высокую, чем система со схемой синхронизационных блокировок.
5.6. Многораздельное масштабирование TPC-C
Чтобы проанализировать влияние многораздельных транзакций на более сложную рабочую нагрузку, мы увеличивали долю транзакций TPC-C, затрагивающих несколько разделов. Мы выполняли рабочую нагрузку, на 100% состоящую из новых транзакций заказа с 6 складами. Затем мы соответствующим образом подбирали вероятность того, что некоторая позиция заказа поступает из "удаленного" склада, в результате чего получалась многораздельная транзакция. При параметрах TPC-C, используемых по умолчанию, эта вероятность составляет 0,01 (1%), что обеспечивает долю многораздельных транзакций, равную 9,5%. Мы изменяли этот параметр и вычисляли вероятность того, что транзакция является многораздельной. Пропускная способность системы при этой рабочей нагрузке показана на рис. 9.
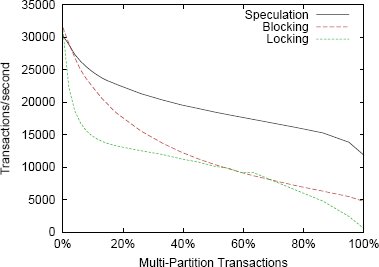
Рис. 9. 100% новых транзакций заказа из TPC-C
Результаты системы с блокировочной и спекулятивной схемами очень похожи на результаты микротестирования с рис. 4. В этом эксперименте производительность системы со схемой синронизационных блокировок очень быстро деградирует. При отсутствии многораздельных транзакций (0%) такая система работает эффективно без запросов блокировок. Но при появлении многораздельных транзакций блокировки должны запрашиваться. Накладные расходы на синхронизационные блокировки в тестовом наборе TPC-C выше, чем при микротекстировании, по трем причинам: больше блокировок запрашивается в каждой транзакции; более сложен сам менеджер блокировок; имеется большее число конфликтов. В частности, в этой рабочей нагрузке проявляются локальные и распределенные синхронизационные тупики, причиняющие существенный ущерб производительности. Это еще раз показывает, что конфликты делают традиционное управление параллелизмом более дорогостоящим, возрастают преимущества более простых схем.
Анализ результатов выборочного профилировщика при пропуске системы со схемой синхронизационных блокировок на TPC-C с вероятностью многораздельных транзакций, равной 10%, показывает, что 34% времени выполнения тратится на поддержку блокировок. Примерно 12% времени тратится на управление таблицы блокировок, 14% – на запросы блокировок, и 6% – на освобождение блокировок. Хотя в нашей реализации имеется простор для оптимизаций, эти цифры схожи с теми, которые были получены для Store, где на работу с синхронизационными блокировками тратилось до 16% команд процессора [14].
5.7. Резюме
Наши результаты показывают, что выбор наилучшего механизма управления параллелизмом зависит от свойств рабочей нагрузки. Спекулятивная схема работает значительно лучше, чем блокировочная схема и схема с синхронизационными блокировками, при наличии многораздельных транзакций с одним циклом коммуникаций и небольшой доли аварийно завершающихся транзакций. Наш метод синхронизационных блокировок с низкими накладными расходами оказывается предпочтительным, когда имеется много транзакций с несколькими циклами коммуникаций. В табл. 1 показано, какая схема оказывается наилучшей в зависимости от рабочей нагрузки. Мы полагаем, что исполнитель запросов мог бы собирать статистику во время выполнения и использовать некоторую модель, подобную той, что представлена в разд. 6, для динамического выбора наилучшей схемы.
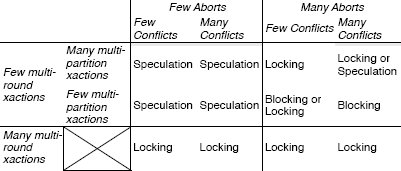
Табл. 1. Сводка наилучших схем управления параллелизмом для разных ситуаций. Спекулятивная схема является предпочительной, когда имеется немного транзакций с несколькими циклами коммуникаций (транзакций общего вида) и аварийных завершений транзакций
Другим "стандарным" алгоритмом управления параллелизмом является оптимистическое управление (optimistic concurrency control, OCC). При таком подходе отслеживается каждый прочитанный или записанный элемент, а затем на стадии валидации при наличии конфликтов некоторые транзакции завершаются аварийным образом. Интуитивно мы полагаем, что эффективность OCC должна быть близка к эффективности нашей схемы с синхронизационными блокировками. Дело в том, что, в отличие от традиционных реализаций синхронизационных блокировок, в которых требуются сложные менеджеры блокировок и тщательная синхронизация с помощью защелок для поддержки физической согласованности, наша схема является значительно более легковесной, поскольку в каждом разделе имеется только один поток управления (т.е. нам приходится заботиться только о логической согласованности). Поэтому наша реализация выполняет ненамного больше действий, чем требуется для отслеживания наборов чтения/записи для каждой транзакции, – а это приходится делать и OCC. Следовательно, основное преимущество OCC перед синхронизационными блокировками исчезает. У нас имеются некоторые начальные результаты, подтверждающие эту гипотезу, а в будущем мы планируем более тщательно сравнить плюсы и минусы OCC (и других методов управления параллелизмом) и нашей спекулятивной схемы.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС