Год эпохи перемен в технологии баз данных
Сергей Кузнецов4. Cloud Computing и новые критерии оптимальности архитектуры СУБД
Хотя «облачные» вычисления (cloud computing) постепенно входят в практику все большего числа разработчиков приложений, остается открытым вопрос, какими должны быть средства управления данными «в облаках»? Некоторые люди полагаются на использование распределенных файловых систем и подхода map/reduce, другие говорят о целесообразности использования массивно-параллельных систем баз данных (см. разд. 2), третьи пытаются приспособить к облачной инфраструктуре традиционные SQL-ориентированные СУБД (например, SQL Azur) от Microsoft; кстати, после появления в Microsoft проекта массивно-параллельной СУБД Madison (в настоящее время соответствующий продукт называется SQL Server 2008 R2 Parallel Data Warehouse), возможно, компания присоединится к лагерю параллельных облачных СУБД).
Свой подход к «облачным» СУБД предлагают Даниела Флореску (Daniela Florescu) и Дональд Коссман (Donald Kossmann) в статье «Переосмысление стоимости и производительности систем баз данных» (оригинал: Daniela Florescu, Donald Kossmann. Rethinking Cost and Performance of Database Systems. SIGMOD Record, Vol. 38, No. 1, March 2009). В качестве краткой справки заметим, что эти авторы наиболее известны своим активным участием в разработке стандарта языка XQuery и другими работами, связанными с языком XML.
Статья, по сути, состоит из двух основных частей. В первой части вводятся и обосновываются новые критерии оптимальности СУБД, соответствующие современной специфике (наличию облачной инфрастуктуры и крупных центров данных с дешевыми аппаратными средствами). Во второй части предлагается и объясняется архитектура СУБД, соответствующая этим критериям.
4.1. Новые критерии оптимизации
Традиционные критерии оптимизации, по мнению авторов, выглядят следующим образом:
При заданном наборе аппаратных ресурсов и гарантировании полной согласованности данных (т.е. при поддержке ACID-транзакций) требуется минимизировать время ответа за запросы и максимизировать пропускную способность системы по отношению к поступающим запросам.
Они считают, что в новых условиях они должны быть такими:
При заданных требованиях к производительности приложений (пиковая пропускная способность, предельно допустимое время ответа) требуется минимизировать требуемые аппаратные ресурсы и максимизировать согласованность данных.
Основным показателем, нуждающимся в оптимизации, является оценка денежных затрат. Наиболее важный вопрос состоит в том, сколько требуется машин, чтобы удовлетворить требования к производительности на заданной рабочей нагрузке. Аппаратные ресурсы – это теперь не одноразовая инвестиция; это отдельная существенная статья ежемесячных расходов IT.
Для большинства приложений производительность является заданным ограничением, а не целью оптимизации. Требуется, чтобы поддерживалась заранее заданная пиковая рабочая нагрузка. Имеется возможность поддержки, по существу, любой рабочей нагрузки, вопрос только в том, сколько это будет стоить, и чем дешевле, тем лучше.
Насущной потребностью любой современной информационной системы является неограниченная масштабируемость. Это требование удовлетворяется, если расходы на IT растут линейно по мере роста бизнеса, и этот рост ничем не ограничивается. У традиционных СУБД функция стоимости является ступенчатой, а масштабируемость – ограничена.
Для многих организаций предсказуемость приложений настолько же обязательна, что и масштабируемость. Имеется в виду предсказуемость и производительности, и стоимости. Оптимизация 99% операций более важна, чем оптимизация в среднем. Прилагаются огромные усилия для сокращения расходов на администрирование и достижения более устойчивой производительности СУБД, но радикальных успехов добиться до сих пор не удалось.
Транзакции в стиле ACID, обеспечивающие полную согласованность данных, и сервис-ориентированная архитектура, помогающая структурировать и развивать приложения, плохо совместимы. Более того, большинству приложений просто не требуется полная согласованность. Более приоритетным является требование стопроцентной доступности данных. В современных приложениях согласованность данных является целью оптимизации, а не ограничением, как в традиционных системах баз данных.
Гибкость – это возможность настройки программной системы к индивидуальным требованиям пользователя. По мере усложения приложений гибкость как цель разработки становится все более важной. В традиционных системах OLTP это требование отсутствовало, так что гибкость не являлась целью оптимизации в традиционных системах управления данными. Понятно, что гораздо проще обеспечить должные производительность и масштабируемость, если система не обладает гибкостью.
4.2. Новая архитектура СУБД
В традиционной архитектуре СУБД (рис. 1) все запросы инициируются пользователями на уровне представления, например, с использованием Web-браузера. Логика приложения программируется на среднем уровне; на среднем же уровне поддерживаются такие функциональные средства, как Web-сервер. Все управление данными производится на низшем уровне с использованием СУБД.
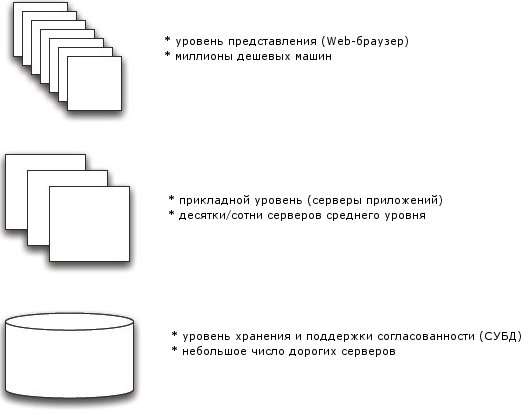
Рис. 1. Традиционная архитектура СУБД
Эта архитектура практически идеально отвечает критериям оптимальности традиционных СУБД. Согласованность данных поддерживается СУБД на нижнем уровне. Основная цель оптимизации (минимизация времени отклика и максимизация пропускной способности) достигается за счет применения на всех уровнях ряда отработанных методов (индексация, кэширование, разделение и т.д.). Верхние два уровня почти неограниченно масштабируются (масштабируемость нижнего уровня ограничена).
Однако целям новой оптимизации традиционная архитектура не удовлетворяет. Во-первых, она рассчитана на обеспечение ожидаемой пиковой производительности, которая может на несколько порядков превышать реальную среднюю производительность. В результате большая часть дорогостоящих аппаратных ресурсов простаивает. То же можно сказать о многих компонентах программного обеспечения СУБД, за которые приходится платить даже в том случае, когда они не требуются приложению. Во-вторых, традиционная архитектура не обеспечивает предсказуемость, поскольку при наличии многопользовательского доступа трудно понять, что происходит на уровне СУБД. В-третьих, как уже отмечалось, на нижнем уровне архитектуры масштабируемость ограничена. Наконец, не поддерживается гибкость, поскольку на всех трех уровнях используются разные модели данных и программирования (XML/HTML и скриптовые языки на верхнем уровне, объектно-ориентированный подход на среднем уровне и SQL – на нижнем уровне).
Двумя принципами разработки приложений в трехзвенной архитектуре являются контроль и передача запросов. Первый принцип означает, что весь доступ к данным полностью контролируется СУБД, а второй – что как можно большая часть логики приложений должна выполняться поблизости от данных, т.е. внутри СУБД (на основе хранимых процедур, определяемых пользователями типов данных и функций), По мнению авторов, эти два принципа подрывают масштабируемость, предсказуемость и гибкость, приводят к удорожанию и усложнению СУБД (хотя вполне согласуются с целями традиционной архитектуры).
Предлагаемая авторами архитектура показана на рис. 2. Здесь на нижнем уровне поддерживается только крупномасштабное распределенное хранение данных на основе, например, облачной службы Amazon S3. Согласованность данных обеспечивается на среднем уровне, причем эта согласованность не является строгой. Она поддерживается за счет применения всеми серверами приложений общих соглашений при чтении и записи данных через службу нижнего уровня.
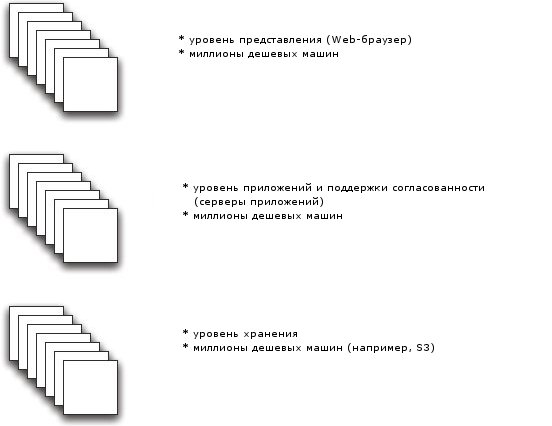
Рис. 2. Новая архитектура
На всех уровнях можно использовать дешевую аппаратуру и обеспечивать неограниченную масштабируемость. На каждом уровне допускается выход из строя любого узла: на нижнем уровне это возможно из-за репликации и слабой согласованности данных; на верхних – за счет работы узлов без сохранения состояния.
На основе этой новой архитектуры в компании 28msec реализуется система Sausalito. В качестве службы хранения данных используется Amazon S3, на среднем уровне применяются сервисы прикладного уровня Amazon EC2. Вся традиционная функциональность управления базами данных реализуется на этом же уровне на основе языка XQuery с расширениями, обеспечивающими возможность модификации данных (понятно, что в данном случае речь идет об XML-данных). Тот же язык используется для разработки Web-приложений, на поддержку которых и ориентирована система Sausalito.
4.3. Все ли так хорошо с новой архитектурой?
На мой взгляд, статья написана очень последовательно и логично. Правда, несколько смущает сходство предлагаемой архитектуры приложений баз данных с архитектурами файл-серверных СУБД. Фактически, в подходе Флореску и Коссмана Amazon S3 выполняет роль файл-сервера, а вынесение службы запросов и других функций СУБД на уровень приложения до боли напоминает организацию систем, существовавших до появления клиент-серверных архитектур, например, Informix SE.
И, конечно, что там не говори насчет отказа от принципа «передачи запросов», некоторые сомнения вызывает передача по Internet от узлов Amazon S3 в узлы серверов приложений, как минимум, XML-документов целиком (а может быть, и коллекций XML-документов). Непонятно, как при этом удается гарантировать, что время ответа на запрос не превышает заданные ограничения (если, конечно, не считать, что пользователи могут спокойно подождать и несколько минут).
Кроме того, я не уверен, что разработчики приложений придут в полный восторг от необходимости использования XQuery не только для запросов XML-данных, но и для написания логики приложений. Для системы это, конечно, очень удобно, а на месте разработчиков я бы, пожалуй, предпочел использовать для программирования что-нибудь более привычное.
Хотя, конечно, здесь нужно учитывать, что Флореску и Коссман входят в число родоначальников XQuery, и с их точки зрения, по-видимому, программирование приложений на XQuery является вполне естественным и удобным. Кстати, по этому поводу полезно почитать статью Мартина Кауфмана (Martin Kaufmann) и Дональда Коссмана «Developing an Enterprise Web Application in XQuery».
А может быть, я напрасно сомневаюсь, этот возврат к архитектурному прошлому закономерен, очень большие XML-документы в Web-приложениях не встречаются, а разработчики Web-приложений с энтузиазмом перейдут от программирования на PHP и Python к программированию на XQuery. Авторы достаточно убедительно демонстрируют, что их «новая» архитектура (а любое «новое», как известно, – это хорошо забытое «старое») обеспечивает неограниченное масштабирование приложений, гибкость системы и предсказуемость ее поведения. В конце концов, в старые и добрые времена файл-серверных СУБД не было облачных вычислений, не было Web-приложений, и требования к системам баз данных были другими.
5. Как справиться с большими данными?
В области управления данными ежегодно публикуется множество статей – в сборниках трудов многочисленных конференций, в специализированных журналах и изданиях универсальной софтверной тематики. Однако подавляющее большинство этих статей касается чрезвычайно узкой тематики, понятной только специалистам, профессионально занимающимся аналогичными вопросами. Лишь немногие люди решаются публично выразить свою более общую точку зрения, затрагивающую проблемы области в целом. И круг таких людей очень ограничен: Майкл Стоубрейкер, раньше – Джим Грей (Jim Gray), который, к всеобщему несчастью, пропал в океане зимой 2007 г., Кристофер Дейт (Chris Date), может быть, еще несколько человек. Новые люди в этом «элитном» сообществе появляются крайне редко.
Поэтому меня сразу заинтересовала статья Адама Якобса «Патологии больших данных» (оригинал: Adam Jacobs. The Pathologies of Big Data. ACM Queue, Vol. 7, Issue 6, July 2009). Привлекли амбициозное название статьи, а также неизвестность и явное «нахальство» автора, решившегося высказаться на такую тему. Как удалось выяснить, первой специализацией автора статьи была лингвистика, а степень PhD он получил в области вычислительной нейропсихологии. Ему приходилось заниматься аналитическими исследованиями больших объемов данных, и с начала 2000-х он работает в компании 1010data Inc., где руководит разработкой аналитической СУБД Tenbase.
Статья Якобса настолько меня затронула, что я написал по ее поводу отдельную заметку «О точности диагностики патологий», в которой серьезно (и, полагаю, заслуженно) раскритиковал автора. Не буду здесь пересказывать эту заметку, а остановлюсь только на том, что связывает статью Адама Якобса с основной темой моей статьи.
На основе своих рассуждений Якобс приводит следующее «метаопределение» больших данных:
Большими являются данные, размер которых вынуждает нас выходить за пределы проверенных временем методов, широко распространенных в данное время.
В середине 1980-х гг. приходилось иметь дело с наборами данных, которые были настолько масштабными, что для их обработки требовалось использовать специальные робототехнические решения, автоматизирующие работу с тысячами магнитных лент. В 1990-е гг. для анализа больших данных не хватало возможностей Microsoft Excel и персональных компьютеров, и в этом случае использовались рабочие станции с ОС Unix и более серьезным программным обеспечением. В настоящее время большими являются такие данные, для обработки которых оказываются недостаточными средства традиционных SQL-ориентированных СУБД и настольных статистических пакетов; требуется массивно-параллельное программное обеспечение.
Как видно, по мнению автора, с проблемой больших данных всегда приходится сталкиваться именно при анализе данных; в области оперативной обработки транзакций такой проблемы нет. И решить проблему больших данных в каждый период времени можно только за счет отказа разработчиков программных систем от традиционных, типовых решений, за счет понимания истинной природы имеющихся аппаратных средств и привлечения всего многообразия ранее созданных методов и алгоритмов. Мне кажется, что в этом идеи Якобса полностью созвучны идеям Стоунбрейкера, хотя он вообще на него не ссылается.
Что касается конструктивных предложений, то в статье Якобса я их вижу два:
- несмотря на совершенствование устройств внешней памяти (включая устройства флэш-памяти), их можно эффективно использовать только при последовательном доступе; поэтому следует избегать неоптимальных схем доступа к внешней памяти;
- в распределенных системах баз данных репликация должна служить не только целям повышения уровня доступности и отказоустойчивости системы; для повышения эффективности системы баз данных следует поддерживать реплики данных с разным физическим представлением.
Судя по всему, эти предложения используются при разработке упомянутой выше распределенной СУБД Tenbase. Как я уже отмечал, многие высказывания Якобса заслуживают критики. Еще раз отсылаю читателей к своей заметке «О точности диагностики патологий».
6. Новый взгляд на место аналитиков в системе баз данных
С идеями Стоунбрейкера интересным образом сплетается статья Джеффри Коэна, Брайена Долэна, Марка Данлэпа, Джозефа Хеллерстейна и Кейлэба Велтона «МОГучие способности: новые приемы анализа больших данных» (оригинал: Jeffrey Cohen, Brian Dolan, Mark Dunlap, Joseph M. Hellerstein, Caleb Welton. MAD Skills: New Analysis Practices for Big Data. Proceedings of the VLDB'09 Conference, Lyon, France, August 24-28, 2009). Главным автором статьи, безусловно, является Джо Хеллерстейн, профессор Калифорнийского университета в Беркли, научный руководитель компании Greenplum, в которой работают остальные авторы статьи, соратник Майкла Стоунбрейкера по разработке СУБД Postgres.
В статье утверждается, что традиционный, «ортодоксальный» подход к организации корпоративных хранилищ данных (Enterprise DataWarehouse, EDW), основанный классиками этого направления Эдгаром Коддом (Edgar Codd), Биллом Инманом (Bill Inmon) и Ральфом Кимболлом (Ralph Kimball), не соответствует реалиям настоящего времени. В этом традиционном подходе главным является тщательное проектирование и развитие схемы EDW, служащей основой интеграции корпоративных данных. Сервер баз данных, поддерживающий EDW, является основным вычислительным средством, центральным, масштабируемым механизмом корпоративной аналитики. EDW контролируется специально назначаемыми сотрудниками IT, которые не только сопровождают систему, но и тщательно контролируют доступ к ней.
В настоящее время хранение данных обходится настолько дешево, что за счет собственного бюджета базу данных громадного масштаба может иметь даже небольшое подразделение корпорации. Число внутрикорпоративных источников данных непрерывно возрастает, включая журналы Web-серверов, архивы электронной почты и т.д. Все отчетливее понимается важность аналитики, разной аналитики в разных подразделениях одной и той же компании. Для аналитики нужны как можно более свежие данные, целесообразна поддержка отдельных механизмов сбора и анализа данных для разных подразделений.
6.1. Вся власть – аналитикам!
Исходя из этого изменения ландшафта анализа данных, авторы предлагают подход MAD, являющийся акронимом от magnetic (магнетичность), agile (гибкость) и deep (основательность). В совокупности эти три характеристики подхода образуют MAD skills, новые, МОГучие способности анализа данных.
По мнению авторов, ортодоксальные EDW «отталкивают» новые источники данных: для интеграции в хранилище данных заново возникшего источника данных требуется, вообще говоря, изменить схему EDW, настроить (или даже создать) процедуру ETL (Extract-Transform-Load) и применить эту процедуру. Весь этот процесс может длиться месяцами, а может и вообще не закончиться. В результате аналитики остаются без данных, анализ которых мог бы принести большую пользу компании. Предлагаемая концепция магнетичного хранилища данных означает, что данные должны становиться доступными для анализа сразу после появления нового источника. Аналитики должны сами решать, что для них важнее, полная очищенность и согласованность данных или же быстрота доступа к ним. Диктовать условия доступа к данным должны не администраторы EDW, а пользователи, т.е. аналитики.
Процессы развития хранилища данных, должны быть быстрыми и гибкими. Должна допускаться возможность быстрого изменения физического и логического содержимого аналитической базы данных. В частности, это означает, что у «могучего» хранилища данных может отсутствовать ортодоксальная жесткая схема (хотя ее могут поддерживать сами аналитики). Может отсутствовать и ортодоксальная процедура ETL: аналитики сами должны решать, какой уровень согласованности данных им требуется.
В современных СУБД поддерживаются только минимальные средства, требуемые для анализа данных (типа CUBE BY). Серьезные статистические пакеты (SAS, Mathlab, R) выполняются на рабочих станциях, что ограничивает объем анализируемых данных и требует их передачи по сети. Основательность нового подхода к аналитике означает возможность разработки самими аналитиками и размещения поблизости от данных, внутри аналитической СУБД статистических пакетов любой сложности. При этом аналитикам не должен навязываться конкретный стиль разработки этих пакетов. Например, им должны быть равно доступны технологии SQL и MapReduce.
6.2. Новые возможности за счет старых средств
В соответствии с подходом MAD в компании Greenplum на основе свободно доступных исходных текстов СУБД Postgres (и PostgreSQL) разработана параллельная аналитическая СУБД, пригодная, в частности, для использования в среде cloud computing. Насколько я понимаю, основные усилия были затрачены на разработку массивно-параллельного варианта системы, поскольку Postgres никогда не была параллельной системой. Естественно, о качестве этой части работы, не испытав ее в реальных производственных условиях, говорить невозможно.
Но зато все остальные расширения (поддержка статистических пакетов вблизи от данных, реализация MapReduce) основываются на использовании стандартных средств Postgres, которая с самого начала разработки в середине 1980-х гг. задумывалась Стоунбрейкером, как расширяемая система. Определяемые пользователями типы данных и функции, возможность определения новых структур хранения и методов доступа, естественно, позволяют сравнительно легко добавлять в систему новые, даже совсем не ожидавшиеся возможности. В связи с этим меня всегда интересовал вопрос, насколько безопасны эти расширения, не могут ли они подорвать общую работоспособность системы? Ответ на этот вопрос в контексте Postgres (и позднее в контексте Informix Universal Server) я получить так и не смог. Не дают его и авторы данной статьи.
В заключение этого раздела отметим сходства и различия подхода Хеллерстейна с подходом Флореску и Коссмана, обсуждавшимся в разд. 4. В обоих случаях критикуется традиционная архитектура, в обоих случаях предлагается некоторая новая архитектура, более пригодная для использования в современных условиях, в частности, на основе инфраструктуры cloud computing. Основным отличием является, на мой взгляд, отношение к принципу «передачи запросов». Флореску и Коссман жертвуют этим принципом ради достижения масштабируемости и предсказуемости (а также в угоду SOA), а Хеллерстейн, по сути, целиком на нем основывается. Конечно, в первом случае речь идет о Web-приложениях обработки данных, а во втором – об аналитике. Но в любом случае идея физического приближения вычислений к данным всегда была притягательной: зачем передавать по сети данные, если можно передавать существенно менее объемные результаты их обработки?