MapReduce: внутри, снаружи или сбоку от параллельных СУБД?
Сергей Кузнецов
4. Параллельная СУБД на основе MapReduce
Начну этот раздел с того, что в одной из первых серьезных статей, посвященных сравнению эффективности технологий MapReduce и массивно-параллельных СУБД при решении аналитических задач [27], утверждалось, что развитость и зрелость технологии параллельных СУБД категории sharing-nothing позволяет им обходиться стоузловыми кластерами для поддержки самых крупных сегодняшних аналитических баз данных петабайтного масштаба. Вместе с тем, особые качества масштабируемости и отказоустойчивости технологии MapReduce проявляются при использовании кластеров с тысячами узлов. Из этого делался вывод, что в обозримом будущем эти качества параллельным СУБД не то чтобы не требуются, но, во всяком случае, не являются для них настоятельно необходимыми.Однако спустя всего несколько месяцев появилась статья [30], в которой звучат уже совсем другие мотивы (и это при том, что авторские коллективы [27] и [30] значительно пересекаются). В [30] говорится, что в связи с ростом объема данных, которые требуется анализировать, возрастает и число приложений, для поддержки которых нужны кластеры с числом узлов, больше ста. В то же время, имеющиеся в настоящее время параллельные СУБД не масштабируются должным образом до сотен узлов. Это объясняется следующими причинами.
- При возрастании числа узлов кластера возрастает вероятность отказов отдельных узлов, а массивно-параллельные СУБД проектировались в расчете на редкие отказы.
-
Современные параллельные СУБД расчитаны на однородную аппаратную среду (все узлы кластера обладают одной и той же производительностью), а при значительном масштабировании полной однородности среды добиться почти невозможно.
-
До последнего времени имелось очень небольшое число систем аналитических баз данных, для достижения требуемой производительности которых требовались кластеры с более чем несколькими десятками узлов. Поэтому существующие параллельные СУБД просто не тестировались в более масштабной среде, и при их дальнейшем масштабировании могут встретиться непредвиденные технические проблемы.
Однако объективно при обработке структурированных данных MapReduce не может конкурировать с параллельными СУБД по производительности, что объясняется отсутствием схемы у обрабатывемых данных, индексов, оптимизации запросов и т.д. В результате при выполнении многих типичных аналитических запросов MapReduce показывает производительность, более чем на порядок уступающую производительности параллельных СУБД [27, 31].
В проекте HadoopDB [48] специалисты из университетов Yale и Brown предпринимают попытку создать гибридную систему управления данными, сочетающую преимущества технологий и MapReduce, и параллельных СУБД. В их подходе MapReduce обеспечивает коммуникационную инфраструктуру, объединяющую произвольное число узлов, в которых выполняются экземпляры традиционной СУБД. Запросы формулируются на языке SQL, транслируются в среду MapReduce, и значительная часть работы передается в экземпляры СУБД. Наличие MapReduce обеспечивается масштабируемость и отказоустойчивость, а использование в узлах кластера СУБД позволяет добиться высокой производительности.
4.1. Общая организация HadoopDB
Архитектура HadoopDB показана на рис. 4, позаимствованном из [49]. Основой системы является реализация MapReduce, выполненная в проекте Hadoop [33]. К ней добавлены компоненты компиляции поступающих в систему SQL-запросов, загрузки и каталогизирования данных, связи с СУБД и самих СУБД. При реализации всех компонентов системы максимально использовались пригодные для этого программные средства с открытыми исходными текстами.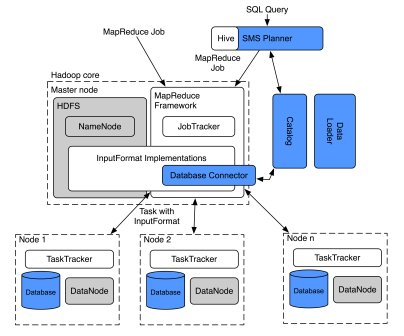
Рис. 4. Архитектура HadoopDB
4.1.1. Немного про Hadoop MapReduce
Как отмечалось в раз. 2, реализация Hadoop MapReduce основана на спецификациях Google, содержащихся в [24]. Однако в этом проекте используется собственная терминология, и для простоты описания особенностей HadoopDB в этом пункте кратко описывается организация Hadoop MapReduce в терминах Hadoop.
Hadoop MapReduce опирается на распределенную файловую систему HDFS (Hadoop Distributed File System) [36]. Файлы HDFS имеют блочную структуру, и блоки одного файла распределяются по узлам данных (DataNode). Файловая система работает под централизованным управлением выделенного узла имен (NameNode), в котором поддерживаются метаданные о файлах (в том числе, об их размерах, о размещении блоков и их реплик и т.д.).
В самой среде Hadoop MapReduce в соответствии с [24] поддерживаются один узел-распорядитель (в Hadoop он называется JobTracker) и много узлов-исполнителей (здесь TaskTracker). В узле JobTracker планируется выполнение MR-заданий, а также отслеживаются данные о загрузке узлов TaskTracker и доступных ресурсах. Каждое задание разбивается на задачи Map и Reduce, которые назначаются узлом JobTracker узлам TaskTracker с учетом требований локальности данных и балансировки нагрузки.
Требование локальности удовлетворяется за счет того, что JobTracker пытается назначать каждую задачу Map тому узлу TaskTracker, для которого данные, обрабатываемые этой задачей, являются локальными. Балансировка нагрузки достигается путем назначения задач всем доступным узлам TaskTracker. Узлы TaskTracker периодически посылают в узел JobTracker контрольные сообщения с информацией о своем состоянии.
Для обеспечения доступа к входным данным MR-задания поддерживается библиотека InputFormat. В Hadoop MapReduce имеется несколько реализаций этой библиотеки, одна из которых позволяет всем задачам одного MR-задания обращаться к JDBC-совместимой базе данных.
4.1.2. Собственные компоненты HadoopDB
Как показывает рис. 4, в архитектуре HadoopDB присутствует ряд компонентов, расширяющих среду Hadoop MapReduce.Коннектор баз данных (Database Connector)
Коннектор баз данных обеспечивает интерфейс между TaskTracker и независимыми СУБД, располагаемыми в узлах кластера. Этот компонент расширяет класс InputFormat и является частью соответствующей библиотеки. От каждого MR-задания в коннектор поступает SQL-запрос, а также параметры поключения к системе баз данных (указание драйвера JDBC, размер структуры выборки данных и т.д.).
Теоретически коннектор обеспечивает подключение к любой JDBC-совместимой СУБД. Однако в других компонентах HadoopDB приходится учитывать специфику конкретных СУБД, поскольку для них требуется по-разному оптимизировать запросы. В экспериментах, описываемых в [30], использовалась реализация коннектора для PostgreSQL, а в [49] уже упоминается некоторая поколоночная система. В любом случае, для среды HadoopDB эта реализация обеспечивает естественное и прозрачное использование баз данных в качестве источника входных данных.
Каталог
В каталоге поддерживаются метаданные двух сортов: параметры подключения к базе данных (ее месторасположение, класс JDBC-драйвера, учетные данные) и описание наборов данных, содержащихся в кластере, расположение реплик и т.д. Каталог сохраняется в формате XML в HDFS. К нему обращаются JobTracker и TaskTracker для выборки данных, требуемых для планирования задач и обработки данных.
Загрузчик данных (Data Loader)
Обязанностями загрузчика данных являются:
- глобальное разделение данных по заданному ключу при их загрузке из HDFS;
- разбиение данных, хранимых в одном узле, на несколько более мелких разделов (чанков, chunk);
- массовая загрузка данных в базу данных каждого узла с использованием чанков.
В GlobalHasher и LocalHasher используются разные хэш-функции, обеспечивающие примерно одинаковые размеры всех чанков. Эти хэш-функции отличаются от хэш-функции, используемой в Hadoop MapReduce для разделения данных по умолчанию. Это способствует улучшению балансировки нагрузки.
Планирование SQL-запросов
Внешний интерфейс HadoopDB позволяет выполнять SQL-запросы. Компиляцию и подготовку планов выполнения SQL-запросов производит планировщик SMS (SMS Planner на рис. 4), являющийся расширением планировщика Hive [50].
Планировщик Hive преобразует запросы, представленные на языке HiveQL (вариант SQL) в задания MapReduce, которые выполняются над таблицами, хранимыми в виде файлов HDFS. Эти задания представляются в виде ориентированных ациклических графов (directed acyclic graph, DAG) реляционных операций фильтрации (ограничения), выборки (проекции), соединения, агрегации, каждая из которых выполняется в конвейере: после обработки каждого очередного кортежа результат каждой операции направляется на вход следующей операции.
Операции соединения, как правило, выполняются в задаче Reduce MR-задания, соответствующего SQL-запросу. Это связано с тем, что каждая обрабатываемая таблица сохраняется в отдельном файле HDFS, и невозможно предполагать совместного размещения соединяемых разделов таблиц в одном узле кластера. Для HadoopDB это не всегда так, поскольку соединяемые таблицы могут разделяться по атрибуту соединения, и тогда операцию соединения можно вытолкнуть на уровень СУБД.
Для пояснения того, как работает планировщик Hive, и каким образом его функциональность расширяется в SMS, невозможно обойтись без примера, и для простоты воспользуемся примером из [30]. Пусть задан следующий простой запрос с агрегацией, смысл которого состоит в получении ежегодных суммарных доходов от продаж товаров:
SELECT YEAR(saleDate), SUM(revenue) FROM sales GROUP BY YEAR(saleDate);В Hive этот запрос обрабатывается следующим образом:
- Производится синтаксический разбор запроса, и образуется его абстрактное синтаксическое дерево.
-
Далее работает семантический анализатор, который выбирает из внутреннего каталога Hive MetaStore информацию о схеме таблицы
sales, а также инициализирует структуры данных, требуемые для сканирования этой таблицы и выборки нужных полей. - Затем генератор логических планов запросов производит план запроса – DAG реляционных операций.
- Вслед за этим оптимизатор перестраивает этот план запроса, проталкивая, например, операции фильтрации ближе к операциям сканирования таблиц. Основной функцией оптимизатора является разбиение плана на фазы Map и Reduce. В частности, перед операциями соединения и группировки добавляется операция переразделения данных (Reduce Sink). Эти операции отделяют фазу Map от фазы Reduce. Оценочная (cost-based) оптимизация не используется, и поэтому получаемые планы не всегда эффективны.
- Генератор физических планов выполнения запросов преобразует логический план в физический, допускающий выполнение в виде одного или нескольких MR-заданий. Первая (и каждая аналогичная) операция Reduce Sink помечает переход от фазы Map к фазе Reduce некоторого задания MapReduce, а остальные операции Reduce Sink помечают начало следующего задания MapReduce. Физический план выполнения приведенного выше запроса, сгенерированный планировщиком Hive, показан на рис. 5.
- Полученный DAG сериализуется в формате XML. Задания инициируются драйвером Hive, который руководствуется планом в формате SQL и создает все необходимые объекты, сканирующие данные в таблицах HDFS и покортежно обрабатывающие данные.
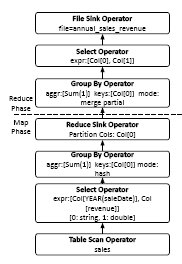
Рис. 5. Задание MapReduce, генерируемое Hive
В планировщике SMS функциональность планировщика Hive расширяется следующим образом. Во-первых, до обработки каждого запроса модифицируется MetaStore, куда помещается информация о таблицах базы данных. Для этого используется каталог HadoopDB (см. выше).
Далее, после генерации физического плана запроса и до выполнения MR-заданий выполняются два прохода по физическому плану. На первом проходе устанавливается, какие столбцы таблиц действительно обрабатываются запросом, и определяются ключи разделения, используемые в операциях Reduce Sink.
На втором проходе DAG запроса обходится снизу-вверх от операций сканирования таблиц до формирования результата или первой операции Reduce Sink. Все операции этой части DAG преобразуются в один или несколько SQL-запросов, которые проталкиваются на уровень СУБД. Для повторного создания кода SQL используется специальный основанный на правилах генератор.
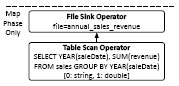
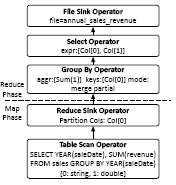
Рис. 6. Варианты MR-заданий, генерируемые SMS
На рис. 6 показаны два плана, которые производит SQL для приведенного выше запроса. План в левой части рисунка производится в том случае, если таблица sales является разделенной по YEAR(saleDate). В этом случае вся логика выполнения запроса выталкивается в СУБД. Задача Map всего лишь записывает результаты запроса в файл HDFS.
В противном случае генерируется план, показанный в правой части рис. 6. При выполнении запроса по этому плану на уровне базы данных производится частичная агрегация данных, а для окончательной агрегации требуется выполнение задачи Reduce, производящей слияние частичных результатов группировки, которые получены в каждом узле на фазе задачи Map.
4.2. Производительность, масштабируемость и устойчивость к отказам и падению производительности узлов кластера
В [30] описан ряд экспериментов, показывающих, что гибридное использование технологий MapReduce и баз данных в реализации HadoopDB позволяет добиться от этой системы производительности, соизмеримой с производительностью параллельных СУБД, и устойчивости к отказам и падению производительности узлов, свойственной MapReduce. Я не буду в этой статье описывать детали этих экспериментов, а лишь кратко отмечу их основные результаты.4.2.1. Производительность и маштабируемость
В большинстве экспериментов параллельные СУБД существенно превосходят HadoopDB по производительности, а HadoopDB оказывается значительно (иногда на порядок) производительнее связки Hive и Hadoop MapReduce. В экспериментах использовались поколоночная параллельная СУБД Vertica и некоторая коммерческая параллельная СУБД-X с хранением таблиц по строкам. Наибольшую производительность, естественно, демонстрировала Vertica, но в ряде случаев HadoopDB уступала ей значительно меньше, чем на десятичный порядок.В [30] значительное отставание HadoopDB от параллельных СУБД объясняется тем, что в качестве базовой СУБД в HadoopDB использовалась PostgreSQL, в которой отсутствует возможность хранения таблиц по столбцам (как уже отмечалось, в [49] в HadoopDB уже используется поколоночная СУБД). Кроме того, в экспериментах с HadoopDB не использовалось сжатие данных. Наконец, в HadoopDB возникали значительные накладные расходы на взаимодействие Hadoop MapReduce и PostgreSQL, которые потенциально можно снизить. Так что в целом производительность HadoopDB не должна критически отставать от производительности параллельных СУБД.
Время загрузки данных в HadoopDB в десять раз больше соответствующего времени для Hadoop MapReduce. Однако это окупается десятикратным выигрышем в производительности при выполнении некоторых запросов.
Как и следовало ожидать, при возрастании числа узлов в кластере при одновременном увеличении объема данных HadoopDB (как и Hadoop) масштабируется почти линейно. Но следует заметить, что в этом диапазоне не хуже масштабируется и Vertica (с СУБД-X дела обстоят несколько хуже), а эксперименты на кластерах большего размера не производились. Так что объективных данных в этом отношении пока нет.
4.2.2. Устойчивость к отказам и неоднородности среды
В экспериментах с отказоустойчивостью и падением производительности некоторого узла сравнивались HadoopDB, Hadoop MapReduce c Hive и Vertica. В первом случае работа одного из узлов кластера искусственным образом прекращалась после выполнения 50% обработки запроса. Во втором случае работа одного узла замедлялась за счет выполнения фонового задания с большим объемом ввода-вывода с тем же диском, на котором сохранялись файлы соответствующей системы.При продолжении работы после отказа узла СУБД Vertica приходилось выполнять запрос заново с использованием реплик данных, и время выполнения запроса возрастало почти вдвое. В HadoopDB и Hadoop MapReduce c Hive время выполнения увеличивалось примерно на 15-20% за счет того, что задачи, выполнявшиеся на отказавшем узле, перераспределялись между оставшимися узлами. При этом относительная производительность HadoopDB оказывается несколько выше, чем у Hadoop MapReduce c Hive, поскольку в первом случае обработка запроса проталкивалась на узлы, содержащие реплики баз данных, а во втором приходилось копировать данные, не являющиеся локальными для обрабатывающего узла.
При замедлении работы одного из узлов производительность Vertica определялась скоростью этого узла, и в экспериментах время выполнения запроса увеличивалось на 170%. При использовании HadoopDB и Hadoop MapReduce c Hive время выполнения запроса увеличивалось всего на 30% за счет образования резервных избыточных задач в недозагруженных узлах.
Проект HadoopDB представляется мне очень интересным и перспективным. В отличие от других систем, рассматриваемых в этой статье, HadoopDB – это проект с открытыми исходными текстами, так что потенциально участие в этой работе доступно для всех желающих. Помимо прочего, продукт HadoopDB открывает путь к созданию высокопроизводительных, масштабируемых и отказоустойчивых параллельных СУБД на основе имеющихся программных средств с открытыми кодами.
5. Использование MapReduce для подготовки данных параллельных СУБД
Я не могу считать себя специалистом в области различных средств ETL (Extract-Transform-Load), которых существует множество, и которые применяются во многих компаниях, использующих хранилища данных (я не буду даже пытаться как-то их классифицировать и/или сравнивать). Но, в любом случае, важность этих средств трудно переоценить, поскольку в хранилище данных по определению поступают данные из самых разнообразных источников: транзакционных баз данных, сообщений, участвующих в организации бизнес-процессов, электронной почты, журналов Web-серверов и т.д. Все эти данные нужно очистить, привести к единому формату, согласовать и загрузить в хранилище данных для последующего анализа.Наверное, можно согласиться с идеологами MAD-аналитики из Greenplum (см. п. 3.1.1), что при использовании ортодоксального подхода к организации хранилищ данных подключение нового источника к хранилищу данных может занять недопустимо много времени во многом как раз из-за потребности в создании соответствующей процедуры ETL. Наверное, можно согласиться и с тем, что для аналитиков гораздо важнее получить новые данные, чем быть вынужденными ждать неопределенное время их в согласованной форме. Но совершенно очевидно, что если данные в хранилище данных не очищать никогда, то со временем в них не разберется никакой, даже самый передовой аналитик.
Итак, что мы имеем. Число источников данных, пригодных для анализа в составе хранилища данных, все время растет. Их разнородность тоже все время возрастает. Все меньший процент составляют структурированные базы данных, данные поступают из частично структурированных файлов и совсем неструктурированных текстовых документов. Для каждой разновидности источников данных нужна своя разновидность процедуры ETL, и по причине роста объемов исходных данных для обеспечения умеренного времени их загрузки в хранилище данных эти процедуры должны выполняться в массивно-параллельной среде. И в этом может помочь технология MapReduce.
5.1. MapReduce и ETL
Как отмечается в [31], для канонического способа использования технологии MapReduce характерно применение следующих операций:- чтение журнальных данных из нескольких разных файлов-журналов;
- разбор и очистка журнальных данных;
- преобразования этих данных, в том числе их частичная агрегация;
- принятие решения о схеме результирующих данных;
- загрузка данных в хранилище данных или другую систему хранения.
Имелись попытки реализации процедур ETL внутри сервера баз данных средствами языка SQL. Разработчики параллельных СУБД с поддержкой MapReduce Greenplum Database и nCluster компании Aster Data тоже намекают, что их встроенный MapReduce можно использовать и для поддержки ETL. Но исторически системы ETL промышленного уровня существуют отдельно от СУБД. Обычно СУБД не пытаются выполнять ETL, а системы ETL не поддерживают функции СУБД.
5.2. Hadoop и Vertica
Эти рассуждения наводят на мысль, что если иметь в виду поддержку именно ETL, то наиболее грамотное (и самое простое) решение по интеграции технологий MapReduce и параллельных баз данных применяется в Vertica (см. рис. 7, позаимстованный из [51]).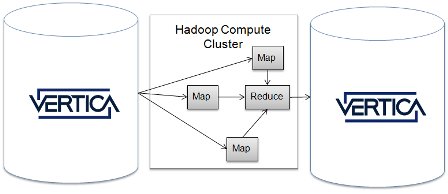
Рис. 7. MapReduce
В Vertica реализован свой вариант интерфейса DBInputFormat компании Cloudera [51] для Hadoop MapReduce, позволяющий разработчикам MapReduce выбирать данные из баз данных Vertica и направлять результирующие данные в эти базы данных. При этом подходе технологии MapReduce и параллельных баз данных тесно не интегрируются, но каждая из них может использовать возможности другой технологии.
Скорее всего, мы еще многое услышим о системах ETL, основанных на использовании технологии MapReduce, и, скорее всего, предводителем этого направления будет Vertica.
6. Заключение
Еще пару лет назад было непонятно, каким образом можно с пользой применять возникающие "облачные" среды для высокоуровневого управления данными. Многие люди считали, что в "облаках" системы управления базами данных будут просто вытеснены технологий MapReduce. Это вызывало естественное недовольство сообщества баз данных, авторитетные представители которого старались доказать, что пытаться заменить СУБД какой-либо реализацией MapReduce если не безнравственно, то, по крайней мере, неэффективно.Однако вскоре стало понятно, что технология MapReduce может быть полезна для самих параллельных СУБД. Во многом становлению и реализации этой идеи способствовали компании-стартапы, выводящие на рынок новые аналитические массивно-параллельные СУБД и добивающиеся конкурентных преимуществ. Свою лепту вносили и продолжают вносить и университетские исследовательские коллективы, находящиеся в тесном сотрудничестве с этими начинающими компаниями.
На сегодняшний день уже понятно, что технология MapReduce может эффективно применяться внутри параллельной аналитической СУБД, служить инфраструктурой отказоустойчивой параллельной СУБД, а также сохранять свою автономность в симбиотическом союзе с параллельной СУБД. Все это не только мешает развитию технологии параллельных СУБД, а наоборот, способствует ее совершенствованию и распространению.
Интересные работы ведутся и в направлении использования "облачных" сред для создания нового поколения транзакционных средств управления данными. Но это уже, как говорили братья Стругацкие, совсем другая история.