2010 г.
SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями
Эрик Фридман, Питер Павловски и Джон Кислевич
Перевод: Сергей Кузнецов
Назад Содержание Вперёд
4. Архитектура системы
В этом разделе мы сначала кратко представим системную архитектуру nCluster (подраздел 4.1), массивно-параллельной системы реляционных баз данных. Затем мы опишем, как SQL/MR интегрируется в nCluster (подраздел 4.2).
4.1 Общие сведения о СУБД nCluster
nCluster [3] – это параллельная СУБД без совместного использования ресурсов (shared-nothing) [8], оптимизированная для поддержки хранилищ данных и анализа данных.
nCluster работает на кластере серверов массового сектора рынка. Система разработана в расчете на масштабирование до сотен узлов и может поддерживать сотни терабайт активных данных.
Обработка запросов управляется одним или несколькими "королевскими" (Queen) узлами. Эти узлы анализируют запросы клиентов и распределяют их частичную обработку между рабочими (Worker) узлами. Каждое отношение в системе баз данных nCluster хэш-разделяется между рабочими узлами для обеспечения возможности внутризапросного (intra-query) параллелизма.
Кроме обработки запросов к базе данных, возможность автоматической управляемости в nCluster позволяет добавлять новые машины и реструктурировать данные с помощью операций, вызываемых одним нажатием на клавишу мыши, и система автоматически восстанавливается после сбоев, повторяет выполнение запросов и восстанавливает требуемый уровень репликации данных при отказах узлов. Эти характеристики важны при использоании крупных кластеров, в которых регулярно происходят сбои разного вида.
4.2 SQL/MR в nCluster
Для реализации инфрастуктуры SQL/MR в nCluster от нас потребовалось определить взаимодействия SQL/MR-функции с подсистемами планирования и выполнения запросов реляционной СУБД.
4.2.1 Планирование запросов
SQL/MR-функции являются динамически полиморфными в том смысле, что их входная и результирующая схемы зависят от контекста вызова. Мы определяем входную и результирующую схемы в течение фаз планирования запроса – эта задача возложена на планировщих запросов в "королевском" узле.
Планировщик запросов получает дерево грамматического разбора запроса. Он устанавливает входную и результирующую схемы вызовов SQL/MR-функций при обходе этого дерева снизу-вверх. Если при этом обходе встречается вызов некоторой SQL/MR-функции, планировщик использует уже известную схему входного отношения – вместе с разобранными разделами аргументов, заданными при вызове этой функции, – для инициализации функции путем вызова ее подпрограммы инициализации. Подпрограмма инициализации должна определиться со столбцами результирующей таблицы, которая будет произведена основной (runtime) подпрограммой функции во время выполнения запроса. (В нашем примере Java API подпрограмме инициализации соответствует контруктор класса, реализующего интерфейс функции над строками или разделами, а основной подпрграммой является метод, определяемый этим интерфейсом.)
Как отмечалось в п. 3.3.1, для функций используется метафора контракта: планировщик запросов обеспечивает некоторые гарантии относительно входных данных, а функция обеспечивает гарантии по поводу результирующих данных, и обе стороны обязываются соблюдать эти гарантии во время выполнения запроса. Это согласование позволяет функции иметь разные схемы при разных сценариях использования (это мы и называем динамическим полиморфизмом) при сохранении того свойства, что схема результата SQL-запроса точно устанавливается до его выполнения.
Кроме обеспечения возможности динамического полиморфизма, это понятие контракта позволяет добиться полной интеграции с планированием запросов. Разработчик функции может знать о некоторых особенностях ее выполнения. Например, функция может производить строки в некотором порядке, пропускать некоторые столбцы входной таблицы в выходную таблицу, иметь некоторую статистическую информацию относительно результирующих данных и т.д. Контракт является естественным каналом, которым может пользоваться функция для передачи этой информации оптимизатору запросов. Функция может передать такую информацию планировщику запросов при вызове ее подпрограммы инициализации во время планирования. С точки зрения простоты использования важно то, что в среде SQL/MR от конечного пользователя или администратора базы данных при инсталляции функции не требуется специфицировать разнообразные сложные разделы оператора CREATE FUNCTION, чтобы проинформировать планировщик запросов о свойствах этой функции. Вместо этого, такая информация может быть закодирована разработчиком функции и инкапсулирована в ней, после чего функция описывает сама себя во время планирования запросов.
4.2.2 Выполнение запросов
В локальных СУБД в рабочих узлах вызовы SQL/MR-функций трактуются как операции времени выполнения запросов: строки входной таблицы вызова функции обеспечиваются через итератор над разделом ON, а результирующие строки, в свою очередь, направляются в следующий узел дерева выполнения запроса. В случае разделяемых входных данных строки делятся на группы; это может делаться путем сортировки или хжширования строк в соответствии со значениями выражений раздела PARTITION BY.
SQL/MR-функции выполняются параллельно во всех узлах nCluster, и это выполнение также распараллеливается в нескольких потоках управления в каждом узле. Поскольку модель программирования, основанная на подходе MapReduce, не зависит от степени параллелизма, система может контролировать уровень параллелизма прозрачным образом, исходя из возможности использования доступных аппаратных ресурсов. В среде SQL/MR при вызове функции просто образуются ее экземпляры, по одному на каждый доступный поток управления. Входные строки распределяются между этими потоками управления, а результирующие строки собираются от всех задействованных потоков.
По разным причинам мы выполняем потоки каждого вызова SQL/MR-функций в отдельном процессе, а не в общем процессе локальной СУБД. Выполнение экземпляров функции в отдельном процессе позволяет эффективно изолировать от системы разработанный отдельно код и контролировать использование типичных механизмов операционной системы (для изоляции сбоев, планирования, ограничения использования ресурсов, насильственного завершения, поддержки безопасности и т.д.), не полагаясь на среду поддержки времени выполнения какого-либо конкретного языка программирования. Например, если какой-нибудь конечный пользователь решит прекратить выполнение некоторого запроса, в котором вызывается некоторая функция, мы просто насильственно завершаем процесс, в котором происходит ее выполнение. Эта модель чрезычайно помогает эффективно поддерживать общую жизнеспособность системы при наличии пользовательского кода. Изоляция функции в отдельном процессе позволяет нам как ограничить вред, который она может причинить системе, так и управлять планированием и распределением ресурсов с использованием имеющихся примитивов операционной системы.
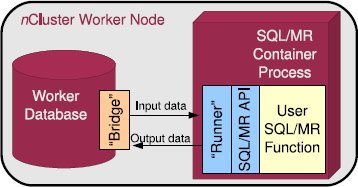
Рис. 7. Диаграмма реализации SQL/MR внутри СУБД nCluster.
На рис. 7 показана диаграмма реализации SQL/MR внутри СУБД nCluster. В СУБД рабочих узлов имеется компонент, называемый нами "мостом"; этот компонент отвечает за поддержку коммуникаций между СУБД и работающей в другом процессе SQL/MR-функцией. В этом отдельном процессе имеется аналог моста, называемый "связным" (runner), который отвечает за коммуникации SQL/MR-функции с СУБД. Поверх связного строится API, с использованием которого пользователи реализуют SQL/MR-функции. Эта модульность позволяет сравнительно просто добавлять в инфраструктуру SQL/MR поддержку новых языков программирования.
5. Приложения
В этом разделе мы представляем примеры приложений, которые можно реализовать с использованием инфраструктуры SQL/MR. Начнем с простого примера, который позволяет напрямую сравнить SQL/MR с подходом MapReduce, представленным в [7].
5.1 Счетчик слов
Со времени публикации [7] выполнение подсчета слов стало каноническим примером использования MapReduce, и здесь мы используем эту задачу для иллюстрации мощности SQL/MR. В отличие от примера MapReduce, SQL/MR позволяет пользователю сфокусироваться на интересном с вычислительной точки зрения аспекте этой проблемы – токенизации (tokenizing) входных данных, а для выполнения более прозаических операций группирования и подсчета уникальных слов – использовать доступную инфраструктуру SQL.
Мы написали SQL/MR-функцию общего назначения tokenizer с разделом специальных аргументов, в котором задается вид разделителя. Результирующие данные функции tokenizer – это просто токены1. Запрос, содержащий вызов этой функции, группирует ее результат по значениям токенов и вычисляет агрегат COUNT(*). Результирующая смесь SQL и SQL/MR является более сжатым средством подсчета слов, в котором используется существующая инфраструктура обработки запросов к базам данных:
SELECT token, COUNT(*)
FROM tokenizer(
ON input-table
DELIMITER(’ ’)
)
GROUP BY token;
Заметим, что это решение не только проще чистой реализации в среде MapReduce, но и позволяет оптимизатору запросов применять имеющиеся методы оптимизации параллельных запросов для вычисления агрегата в распределенной манере.
5.2 Анализ неструктурированных данных
В целом SQL плохо приспособлен для обработки неструктурированных данных. Однако SQL/MR позволяет пользователю поместить в базу данных процедурный код для преобразования неструктурированных данных в структурированное отношение, более пригодное для анализа. Хотя такое преобразование можно выполнить и с применением традиционных UDF, динамический полиморфизм SQL/MR-функций позволяет сделать такие трансформации гораздо более гибкими и практичными.
Рассмотрим функцию parse_documents, показанную ниже. Она разработана для формирования набора показателей, вычисляемых для заданных документов. Пользователь может указать интересующие его показатели в разделе аргументов METRICS, и функция вычислит эти показатели. Кроме того, в результирующей схеме функции будут отражаться требуемые показатели. Заметим, что эти показатели можно вычислить за один проход по данным, но инфраструктура позволяет указывать интересующие пользователя показатели нерегламентированным способом. В результате оказывается возможным построить над библиотекой текстовой аналитики оболочку, которую аналитики могут повторно использовать в разнообразных сценариях.
SELECT word_count, letter_count, ...
FROM parse_documents(
ON (SELECT document FROM documents)
METRICS(
’word_count’,
’letter_count’,
’most_common_word’,
...)
);
5.3 Параллельные загрузка и трансформация
SQL/MR-функции можно также использовать для чтения и преобразования данных из внешних источников. Рассмотрим сценарий, в котором сотни торговых площадок посылают в основной офис файлы с разделенными запятыми данными о дневном обороте, и эти данные требуется загрузить в nCluster. Распространенное решение состоит в том, что для загрузки данных используется некоторый внешний процесс. В nCluster можно выполнить преобразования данных внутри кластера, используя SQL/MR-функцию, которая принимает на входе набор URL, идентифицирующих внешние файлы, подлежащие загрузке, и раздел аргументов с определениями ожидаемой входной схемы и желательной результирующей схемы. После чтения и преобразования SQL/MR-функцией данные немедленно становятся доступными для использования при выполнении запросов. Если целью является загрузка в nCluster внешней таблицы, использование для преобразований SQL/MR-функции является выгодным, поскольку теперь эти преобразования будут производится параллельно внутри nCluster с использованием вычислительной мощности всех рабочих узлов. Повышению производительности загрузки и трансформации содействует и то, что процесс загрузки выполняется в том же месте, в котором будут сохраняться данные. Гибкость SQL/MR-функций позволяет поддерживать произвольные исходные форматы данных путем написания соответствующей SQL/MR-функции, которую затем можно будет использовать как библиотечную функцию для всех последующих загрузок данных из внешних источников.
5.4 Приблизительные процентили
Вычисление точных процентилей над крупными наборами данных может требовать слишком больших затрат, и поэтому мы использовали инфраструктуру SQL/MR для реализации вычисления приблизительных процентилей. Это позволяет распараллелить вычисление процентилей, если допустить наличие некоторой ошибки. В этой реализации также используется динамический полиморфизм SQL/MR, позволяющий вычислять приблизительные процентили над данными разных типов.

Рис. 8. Вычисление приблизительных процентилей с использованием SQL/MR.
Мы реализовали распределенный алгоритм вычисления приблизительных процентилей, описанный в [9], в виде пары SQL/MR-функций. Для применения этого средства требуется указать значения требуемых процентилей и максимальную относительную ошибку e (рис. 8). Относительная ошибка определяется следующим образом: для каждого значения v, которое алгоритм оценивает как относящееся к n-ой процентили, реальная процентиль v находится в интервале между n-e и n+e. Если не вдаваться в детали, алгоритм сначала вычисляет сводные данные в каждом узле, а потом склеивает в некотором одном узле эти сводные данные для получения приблизительных процентилей. Мы реализовали этот алгоритм с использованием функции approximate_percentile_summary, которая вызывается надо всеми уместными данными в заданном узле и выдает в качестве результата сводные данные. Затем все сводные данные переносятся в один узел с использованием конструкции PARTITION BY 12, где они склеиваются для получения окончательного результата функцией approximate_percentile_merge. Результирующая схема approximate_percentile_merge состоит из схемы входной таблицы, к которой добавлен столбец percentile.
6. Экспериментальные результаты
Инфраструктура SQL/MR позволяет существенно повысить выразительную мощность реляционных СУБД. В разд. 5 мы показали, что запросы, которые затруднительно или вообще невозможно выразить на традиционном SQL (например, вычисление приблизительных процентилей), могут быть легко выражены в инфраструктуре SQL/MR с использованием SQL/MR-функций. В этом разделе мы демонстрируем, что запросы, в которых используются средства SQL/MR, могут выполняться быстрее эквивалентных запросов, представленных на чистом SQL. Выполненные нами эксперименты показывает, что:
-
SQL/MR-запросы линейно масштабируются, если уровень параллелизма возрастает пропорционально размеру данных, к которым адресуются запросы;
-
возможность SQL/MR-функций манипулировать собственными структурами данных позволяет им выполнять задачи за один проход по данным, в то время как при использовании чистого SQL для выполнения тех же задач потребовалось бы несколько соединений.
Все эксперименты выполнялись с использованием системы nCluster на кластере серверов x86 с двумя двухъядерными процессорами Intel Xeon с частотой 2,33 Ггц, 4 Гб основной памяти и восьмью 72-гигабайтными дисковыми устройствами SAS (Serial Attached SCSI), сконфигурированными в RAID 0.
6.1 Анализ данных о посещаемости Web-сайтов
Администраторы Web-сайтов часто используют журналы регистрации посещений Web-страниц, чтобы понимать поведение своих пользователей. Это позволяет изменять структуру Web-сайта с тем, чтобы улучшить его показатели. Например, Web-рекламодателям часто требуется знать среднее число кликов, выполяемых пользователями от входа на начальную страницу конкретного Web-сайта до попадания на страницу с рекламой. Web-издателям может быть интересно среднее число статей, прочитываемых посетителями, которые начинают свою сессию с посещения раздела "Политика" и попадают, в конце концов, в раздел "Развлечения".
Если имеется отношение Clicks(user_id int, page_id int, category_id int, ts timestamp), в котором сохраняется информация о пользователе, идентификатор страницы, на которую перешел этот пользователь, и время, когда он это сделал, то каково среднее число страниц, посещенных пользователем в промежутке времени между посещением некоторой страницы категории X и некоторой страницы категории Y? Мы называем клик, приведший на страницу категории X, начальным кликом, а клик, приведший на страницу категории Y, – конечным кликом. Мы сгенерировали искусственный набор данных кликов с использованием SQL/MR-функции над строками, которой задается некоторая таблица пользователей, и из каждой строки этой таблицы получается набор строк кликов соответствующего пользователя. Для каждого пользователя генерировалась 1000 кликов со случайными значениями столбцов ts, category_id и page_id (во всех случаях использовалось равномерное распределение). На каждый узел пришлось пятьдесят миллионов строк.

Рис. 9. Запрос на чистом SQL, обеспечивающий ответ на вопрос о характере посещений Web-сайта.
Для ответа на сформулированый выше вопрос мы сначала написали показанный на рис. 9 запрос на чистом SQL. В этом запросе сначала соединяются каждый клик категории X с каждым кликом категории Y одного и того же пользователя, если клик категории Y был произведен позже клика категории X. Над результатом этого подзапроса выполняется SELECT DISTINCT, в результате которого остаются только те конечные клики, которые были произведены в самое близкое время после начальных кликов. Далее производится проекция этого результата на временные метки начального и конечного кликов и подсчитывается число кликов того же пользователя за этот промежуток времени. Наконец, это число усредняется для всех отобранных ранее пар начального и конечного кликов.
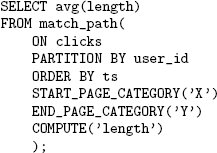
Рис. 10. SQL/MR-запрос, обеспечивающий ответ на вопрос о характере посещений Web-сайта.
После этого мы написали SQL/MR-функцию, обеспечивающую ответ на тот же вопрос. Запрос с вызовом этой функции показан на рис. 10. Мы разделяем входные данные по значениям столбца user_id и упорядочиваем каждый раздел по значениям ts. Кроме того, у функции имеются разделы аргументов, в которых указываются категория начальной страницы, категория конечной страницы и показатель, значения которого требуется вычислить (в данном случае, длина – length). После разделения и сортировки входных данных эта функция производит один проход по данным о посещениях сайта. Каждый раз, когда функция встречает строку с данными о посещении страницы начальной категории, она запоминает позицию этой строки, а когда ей встречается строка с данными о посещении страницы конечной категории, функция производит строку, содержащую разность между позицией конечной страницы и позицией начальной страницы.
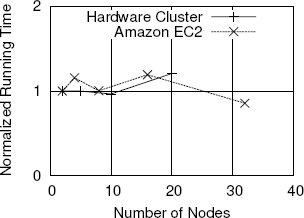
Рис. 11. Горизонтальная масштабируемость SQL/MR на аппаратном кластере и на кластере, размещенном в Amazon EC2.
Оба описанные выше запроса выполнялись в СУБД nCluster на "физическом" кластере с 2, 5, 10 и 20 узлами, а также на кластере, размещенном в Amazon EC2, с 2, 4, 8, 16 и 32 узлами. Объем данных в каждом узле оставался неизменным. На рис. 11 показана линейная горизонтальная масштабируемость SQL/MR. При росте размера кластера, пропорциональном росту объема данных, время обработки запроса остается неизменным. Поскольку почти все вычисления в данном случае могут выталкиваться на рабочие узлы, такое поведение было вполне предсказуемым.
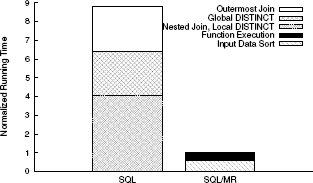
Рис. 12. Сравнение структур времени выполнения аналитических запросов данных о посещении Web-сайта, представленных на чистом SQL и с использованием SQL/MR.
Мы также сравнивали время выполнения SQL/MR-запроса с временем выполнения запроса, представленного на чистом SQL. SQL/MR-запрос выдал требуемые данные почти в девять раз быстрее SQL-запроса. На рис. 12 показана структура временных затрат на выполнение обоих запросов. Заметим, что время выполнения SQL/MR-запроса в равных долях тратится на сортировку входных данных (в соответствии с аргументами разделов PARTITION BY и ORDER BY) и на реальную обработку данных. При выполнении запроса на чистом SQL основное время тратится на выполнение соединения таблицы с самой собой и на локальное удаление дубликатов (local DISTINCT), а остальное время уходит на глобальное устранение дубликатов (global DISTINCT) и заключительное соединение.
6.2 Поиск корзин просмотров страниц
Поскольку SQL/MR-функция может поддерживать свои собственные структуры данных, она может производить однопроходный анализ данных, для выполнения над которыми запросов на чистом SQL требуется несколько проходов. Для демонстрации этой особенности мы рассмотрим задачу нахождения корзин просмотров страниц (basket of page views), содержащих заданный набор страниц. Для выполнения этого эксперимента мы использовали те же, что и ранее, данные о посещении страниц Web-сайта. Для выполнения запросов использовалась СУБД nCluster, работающая на кластере с 13 узлами. Теперь набор кликов каждого пользователя считается его корзиной просмотров страниц. Кроме того, мы определяем один или несколько наборов страниц, каждый из которых называется "поисковым набором". Корзина данного пользователя удовлетворяет условию этого запроса, если хотя бы один поисковый набор полностью содержится в корзине просмотров страниц этого пользователя. В каждом поисковом наборе может содержаться любое число различных страниц. Для решения этой задачи были созданы SQL- и SQL/MR-запросы. На рис. 13 показана нормализованная производительность выполнения этих запросов при возрастании размеров поискового набора.
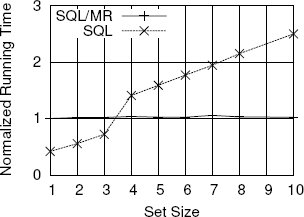
Рис. 13. Время нахождения корзин просмотров страниц, соответствующих заданным наборам страниц, с использованием SQL и SQL/MR.
Производительность обработки SQL-запроса деградирует по мере увеличения размеров наибольшего поскового набора. Так происходит из-за того, что для сборки корзин кликов, которые сравниваются с поисковыми наборами, используются соединения таблицы кликов с ней же самой. Для сборки в пользовательскую корзину всех наборов размера n требуется n-1 самосоединений таблицы кликов. Наиболее оптимизированный SQL-запрос, который нам удалось написать, слишком велик, чтобы можно было здесь его показать. Когда поисковый набор является небольшим, SQL-запрос выполняется производительнее SQL/MR-запроса, поскольку запрос с нулевым или небольшим числом соединений сравнительно просто оптимизируется и обрабатывается. При возрастании числа самосоединений усложняется и оптимизация, и обработка запроса. На самом деле, мы обнаружили, что задание нескольких поисковых наборов, особенно, разного размера существенно влияет на эффективность выполнения SQL-запроса. Время выполнения, показанное на рис. 14, относится к SQL-запросам, обрабатывемых наилучшим образом, – к тем запросам, для которых задается только один поисковый набор.
Ниже показан запрос с вызовом SQL/MR-функции findset, решающий ту же задачу. В разделе SETID указывается атрибут разделения корзин, а в разделе SETITEM – атрибут, являющийся предметом корзины. Каждый раздел SETn определяет один поисковый набор.
SELECT userid
FROM findset( ON clicks
PARTITION BY userid
SETID(’userid’)
SETITEM(’pageid’)
SET1(’0’,’1’,’2’)
SET2(’3’,’10) )
В отличие от производительности SQL, на производительность SQL/MR не влияют ни размер поискового набора, ни число этих наборов, поскольку требуется всего один проход по данным. В течение этого прохода производится всего лишь учет того факта, включают ли клики данного пользователя какой-либо возможный набор страниц. SQL/MR-запрос также проще расширить дополнительными поисковыми наборами, просто добавив новые разделы аргументов SETn. Добавление более крупного поискового набора к SQL-запросу потребовало бы дополнительных самосоединений.
Прим. переводчика. Комментарий по поводу этого раздела оказался настолько объемным, что пришлось выделить его в отдельную заметку «SQL и MapReduce: новые возможности или латание старых дыр?».
Назад Содержание Вперёд
1 Функция tokenizer реализована так, что создает токены для всех столбцов символьного типа входной таблицы, используя указанный разделитель. Для каждого несимвольного столбца возвращается один токен. Можно было бы легко расширить tokenizer, добавив еще один раздел аргументов, в котором указывалось бы, какие столбцы входной таблицы следует обрабатывать.
2 По умолчанию SQL/MR-функции разрабатываются как параллельные. Однако существуют ситуации, в которых требуется последовательная обработка данных. Для удовлетворения этой потребности мы допускаем наличие константы в разделе PARTITION BY. Это приводит к тому, что все входные данные собираются в одном рабочем узле и затем обрабатывются последовательно указанной SQL/MR-функцией. Пользователь предупреждается, что эта SQL/MR-функция не будет выполняться параллельно.




 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС