2010 г.
Доводы в пользу детерминизма в системах баз данных
Дэниел Абади и Александер Томсон
Перевод: Сергей Кузнецов
Назад Содержание
Приложение
Реализация прототипа и экспериментальная установка
Наш прототип реализован на языке Си++. Все транзакции вручную закодированы внутри системы. Все тестовые испытания производились на Linux-кластере, состоящем из четырехъядерных машин Intel Xeon 5140, каждая из которых была оснащена четырьмя гигабайтами основной памяти 667 MHz FB-DIMM DDR2. Все машины были объединены в полнодуплексную 100-мегабитную локальную сеть. Ни в одном из наших экспериментов пропускная способность сети не становилась узким местом.
Подробности эксперимента с "загромождением"
Индексный поиск происходил путем обхода B+-деревьев, а записи напрямую адресовались их первичными ключами. Обновляемые записи выбирались с использованием распределения Гаусса таким образом, чтобы любая пара транзакций конфликтовала, по крайней мере, на одном элементе данных с легко измеряемой и переменной вероятностью.
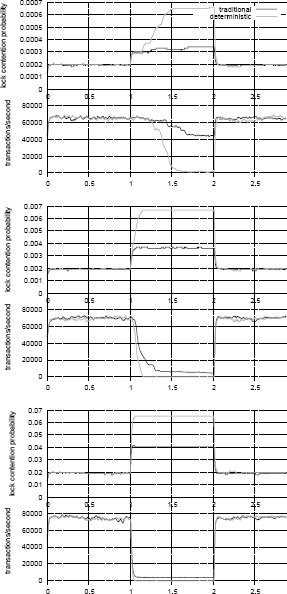
Рис.1. Измеренные вероятность конфликта блокировок и транзакционная пропускная способность за интервал времени в три секунды. Две транзакции конфликтуют с вероятностью 0,01%, 0,1% и 1% соответственно.
Как показывает рис. 1, независимо от схемы выполнения, пиковая производительность системы оказывается выше при более высокой интенсивности конфликтов. Возрастающий перекос в распределении выбора записей приводит к большей интенсивности конфликтов блокировок, поскольку возрастает вероятность обращения к некоторым записям всех транзакций. Но одновременно возрастает вероятность нахождения требуемых данных в кэше, что положительно влияет на пропускную способность при отсутствии загромождения.
Детали эксперимента с транзакциями New Order
тестового набора TPC-C
В этом эксперименте мы распределяли данные по двум разделам в разных физических машинах нашего кластера. Среднее время обмена сетевыми сообщениями составляло 130 микросекунд. В каждом разделе одно ядро выделялось для выполнения запросов. Все измерения производились в течение 10 секунд, после чего в течение короткого времени изменялись характеристики рабочей нагрузки.
Аналитическая модель производительности системы при наличии "загромождения"
Мы рассматриваем систему баз данных, выполняющую рабочую нагрузку, которая однородным образом составлена из транзакций с
n операциями обновления, где два обновления не затрагивают общих данных с вероятостью
s (т.е. они конфликтуют с вероятностью 1 -
s). Если мы запускаем транзакцию
Ti в ситуации, когда
k блокировок удерживается другими транзакциями, мы ожидаем, что для
Ti будет немедленно удовлетворен запрос всех
n блокировок с вероятностью
pn = (sk)n = skn
В этом случае мы предполагаем (поскольку транзакции являются короткими), что Ti зафиксируется и сразу освободит свои блокировки, так что Ti+1 также будет выполняться в среде, в которой блокированы k записей.
Однако если Ti обратится к какой-либо из этих k записей, она не сможет завершиться. В этом случае мы хотим оценить число удерживаемых Tiблокировок новых записей, чтобы определить, как изменяется k. В традиционной модели Ti запрашивает блокировки по ходу своего выполнения, блокируясь при возникновении первого конфликта, и больше блокировки не запрашивая. Поэтому ожидаемое приращение числа k в традиционном случае зависит от числа блокировок (обозначенного ниже как m), которые удалось получить в транзакции Ti до того, как она наткнулась на одну из k блокировок, уже удерживаемых другими транзакциями:
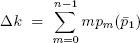
где
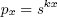 и
и 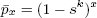 .
.
Еще раз повторим, что 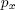 представляет вероятность того, что запросы всех x блокировок удовлетворяются, а
представляет вероятность того, что запросы всех x блокировок удовлетворяются, а 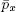 – что не удовлетворяется ни один из этих x запросов.
– что не удовлетворяется ни один из этих x запросов.
При использовании нашей детерминированной модели выполнения Ti запрашивает все блокировки в начале своего выполнения, независимо от того, какие из запросов удовлетворяются, так что ожидаемое приращение числа k зависит от общего числа записей, по которым Ti конфликтует при наличии k заранее удерживаемых запросов (ниже это обозначается как n-m, где m – это снова число новых запрашиваемых блокировок):
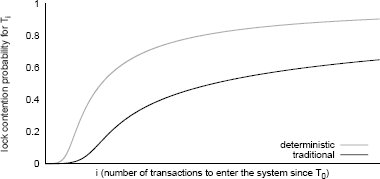
Рис.4. Вероятность того, что каждая новая транзакция, поступающая в систему, конфликтует с удерживаемыми к этому времени блокировками.
В обоих случаях нас интересует не просто то, сколько записей блокируется, а как это повлияет на последующее выполнение. На рис. 4 показано значение 1 - pn (вероятность того, что поступающие транзакции не смогут выполняться из-за конфликта блокировок) как функция от i (числа новых транзакций, поступивших в систему после транзакции T0).
Начало координат представляет собой точку выполнения транзакций сразу после приостановки T0: i = 0 и 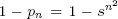 . При использовании обеих моделей выполнения на раннем этапе (до того, как много транзакций заблокируются прямо или косвенно из-за блокировок, удерживаемых T0) большинство транзакций сможет продолжать выполнение, не испытывая конфликта блокировок, так что значение k возрастает медленно. Потом застрянет большее число транзакций, загромождая менеджер блокировок и создавая цикл с положительной обратной связью, в котором уровень загромождения в течение некоторого времени экспоненциально возрастает, асимптотически приводя систему в состояние, в котором поступающие транзакции со стопроцентной вероятностью не смогут завершаться. Не удивительно, что взрывообразный рост загромождения наступает гораздо раньше в детерминированном случае, в котором даже транзакции, конфликтующие с другими транзакциями лишь по немногим записям, добавляют к набору заблокированных записей свои наборы чтения и записи целиком.
. При использовании обеих моделей выполнения на раннем этапе (до того, как много транзакций заблокируются прямо или косвенно из-за блокировок, удерживаемых T0) большинство транзакций сможет продолжать выполнение, не испытывая конфликта блокировок, так что значение k возрастает медленно. Потом застрянет большее число транзакций, загромождая менеджер блокировок и создавая цикл с положительной обратной связью, в котором уровень загромождения в течение некоторого времени экспоненциально возрастает, асимптотически приводя систему в состояние, в котором поступающие транзакции со стопроцентной вероятностью не смогут завершаться. Не удивительно, что взрывообразный рост загромождения наступает гораздо раньше в детерминированном случае, в котором даже транзакции, конфликтующие с другими транзакциями лишь по немногим записям, добавляют к набору заблокированных записей свои наборы чтения и записи целиком.
Поскольку назначение этой модели состоит не в том, чтобы предсказывать характеристики производительности реальных систем, а лишь в том, чтобы прояснить загроможденное поведение в целом, мы опускаем какие-либо аспекты горизонтального масштабирования и отмечаем, что для любых s, n и начального значения k наша модель приводит к графику подобного вида, возможно, уплотненному или сдвинутому. В этой простой модели имеются два недостатка, препятствующие ее полному соответствию экспериментальным данным. Во-первых, в ней не учитается активное переупорядочивание (путем освобождения блокировок и перезапуска всех медленных транзакций, кроме одной, приостановленной специальным образом) в случае традиционного выполнения. Во-вторых, на оси абцисс отмечается, сколько новых транзакций поступило в систему после приостановки T0, а число таких транзакций зависит от времени нелинейно, особенно в тех случаях, когда транзакции периодически перезапускаются, и когда выполнение производится за счет использования пула потоков управления фиксированного размера.
Аналитическая модель производительности декомпозированных зависимых транзакций первого порядка
Чтобы выявить и классифицировать ситуации, в которых эффективен метод декомпозиции транзакций, описанный в подразделе 4.2, мы вводим понятие
изменчивости (volatility) – часто обновления данной записи.
При наличии рабочих нагрузок, насыщенных декомпозированными зависимыми транзакциями, можно расчитывать на хорошую производительность, если зависимости транзакции обновляются не часто. Когда записи, от которых зависят транзакции рабочей нагрузки, становятся более изменчивыми, можно ожидать ухудшения производительности.
Пусть (T1, T2) – это декомпозиция зависимой транзакции первого порядка T, набор чтения/записи которой зависит от множества записей 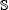 . Общее время, в течение которого обновление некоторой записи r ∈ должно привести к аварийному завершению и перезапуску T2, примерно совпадает со временем между запросом транзакции T1 на образование транзакции T2 и началом выполнения T2. Обозначим этот интервал времени как D. Если R обозначает общую транзакционную пропускную способность, и V – изменчивость , то вероятность того, что ни одна транзакция не обновит запись в течении любого интервала времени длиной D, выражается как
. Общее время, в течение которого обновление некоторой записи r ∈ должно привести к аварийному завершению и перезапуску T2, примерно совпадает со временем между запросом транзакции T1 на образование транзакции T2 и началом выполнения T2. Обозначим этот интервал времени как D. Если R обозначает общую транзакционную пропускную способность, и V – изменчивость , то вероятность того, что ни одна транзакция не обновит запись в течении любого интервала времени длиной D, выражается как
P = (1 - V/R)DR,
и ожидаемое число раз выполнения T2 вычисляется следующим образом:
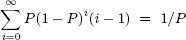
.
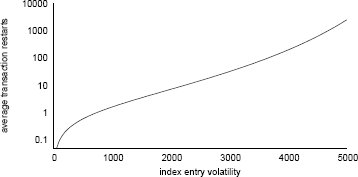
Рис. 5. Ожидаемое число перезапусков декомпозированной зависимой транзакции первого порядка как функция от общей изменчивости ее зависимостей.
На рис. 5 показано ожидаемое число перезапусков типичной декомпозированной транзакции как функция от изменчивости ее зависимостей.
Экспериментальные измерения декомпозированных зависимых транзакций первого порядка
Для экспериментального подтверждения описанных выше результатов мы реализовали декомпозицию простой зависимой транзакции первого порядка, схожей по структуре с транзакцией
U из разд. 4. Эта транзакция производит поиск по вторичному индексу и обновляет запись, идентифицируемую результатом этого поиска. В качестве "линии отсчета" мы также реализовали транзакцию, которая выполняет ту же задачу (индексный поиск с последующим обновлением записи), но без наличия зависимости (т.е. с передачей в качестве аргумента полного набора чтения/записи). Затем выполняли изменяемую смесь этих двух транзакций, а отдельный, выделенный процессор изменяемое число раз в секунду обновлял каждый элемент индекса, вынуждая этот элемент указывать на другую запись.
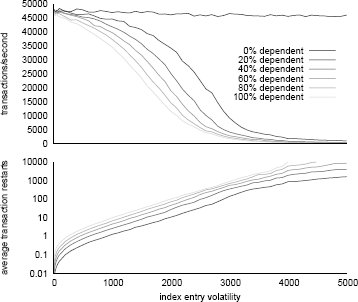
Рис. 6. Измеренные пропускная способность и среднее число перезапусков зависимых транзакций первого порядка как функция от изменичивости их зависимостей.
На рис. 6 показаны общая транзакционная пропускная способность и среднее число перезапусков транзакции до того, как она могла выполниться вплоть до завершения – и то, и другое как функции от средней изменчивости элементов индекса. Приведены результаты для рабочих нагрузок, включающих 0%, 20%, 40%, 60%, 80% и 100% зависимых транзакций.
Как и следовало ожидать на рабочую нагрузку, состоящую полностью из независимых транзакций, по сути, не влияет частоты изменений индекса, в производительность более зависимых рабочих нагрузок падает по мере роста изменчивости.
Однако мы выяснили, что при наличии даже сильно зависимых рабочих нагрузок, если изменчивость находится в разумных пределах (меньше 1000 обновлений каждой записи в секунду), то декомпозиция транзакций для обеспечения возможности работы с вычисляемыми наборами чтения/записи оказывает пренебрежимо малое влияние на производительность.
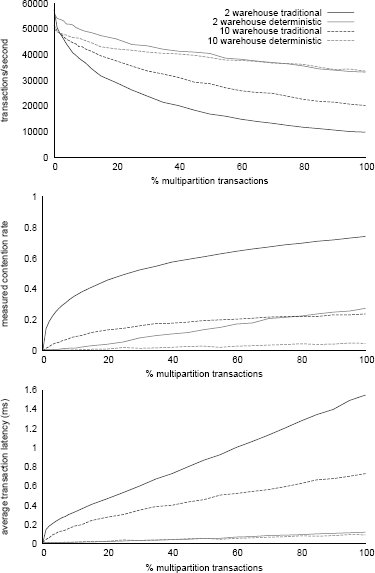
Рис. 7. Транзакционная пропускная способность TPC-C (100% транзакций New Order), измеренная интенсивность конфликтов блокировок и средняя задержка транзакций.
Дополнительные характеристики производительности TPC-C
Для подкрепления результатов анализа положительного влияния на производительность возможности избежать двухфазной фиксации в распределенных системах баз данных (обсуждавшейся в разд. 5), мы включили в графики на рис. 7 результаты измерений, полученных при выполнении тех же экспериментов, результаты которых приводились на рис. 3, – интенсивность конфликтов блокировок и средняя задержка транзакций (для удобства восприятия в верхней части рис. 7 воспроизводится рис. 3). Интенсивность блокировок измерялась как доля от общего числа транзакций тех транзакций, которые хотя бы раз блокировались из-за невозможности удовлетворить из запросы блокировок. Задержка транзакции измерялась с момента начала выполнения транзакции в системе, содержащей реплику базы данных, до момента ее фиксации в этой системе.
Графики интенсивности конфликтов блокировок и задержки демонстрируют два важных эффекта, которые помогают лучше понять детали поведения систем во время проведения наших экспериментов:
-
Стоимость двухфазной фиксации. При наличии многораздельных транзакций традиционное выполнение приводит к большим задержкам транзакций, чем детерминированное выполнение. Это приводит к более длительному удержанию блокировок, что, в свою очередь, способствует повышению интенсивности конфликтов блокировок.
-
Относительная стоимость возрастающей интенсивности конфликтов. Уменьшение числа складов с десяти до двух приводит к повышению интенсивности конфликтов и увеличению задержки при применении обеих схем выполнения. Влияние этого эффекта на пропускную способности ясно видно в традиционном случае. В детеминированном случае это влияние не настолько очевидно, поскольку для версии тестового набора с двумя складами демонстрируется лучшая производительность, чем для версии с десятью складами, почти для любой доли многораздельных транзакций. Однако истинное поведение системы затуманивается тем, что в случае с двумя складами лучше работает кэш. Углубленный анализ графиков показывает более резкое падение производительности при увеличении доли многораздельных транзакций в случае двух, а не десяти складов. Следовательно, возрастающая интенсивность конфликтов в случае двух скдадов при детерминированной реализации не способствует повышению производительности. В целом, мы видем, что возрастание интенсивности конфликтов при использовании обеих систем оказывает качественно одинаковое воздействие на пропускную способность. Но из-за большей величины задержки транзакций при традицонном выполнении падение производительности проявляется при гораздо меньшей доли многораздельных транзакций.
Предстоящая работа
Мы намереваемся продолжать исследования в нескольких направлениях.
Переупорядочивание в препроцессоре
В то время как произвольное переупорядочивание транзакций во время их выполнения, вероятно, подорвет детерминизм, начальный выбор порядка транзакций, эквивалентность которому обеспечивается, является гораздо более свободным. Нетрудно видеть, что если запрос на образование некоторой локальной транзакции поступает сразу после поступления заявки на образование некоторой конфликтной распределенной транзакции, то при сохранении порядка возникнет конфликт, а если поменять порядок локальной и распределенной транзакций, то вероятность конфликта, возможно, уменьшится. Мы планируем исследовать методы переупорядочивания транзакций, которые можно реализовать в препроцессоре, чтобы можно было снижать уровень конфликтности в рабочих нагрузках и расширять набор рабочих нагрузок, для которых была бы жизнеспособна модель детерминированного выполнения.
Гладкие переходы между детерминированной и недетерминированной моделями выполнения/репликации
Почти наверняка иногда будет разумно допускать недетерминированное переупорядочивание транзакций и их аварийное завершение в некоторых репликах. Очевидно, это нельзя делать бесконтрольным образом, потому что реплики могут рассогласоваться. Поэтому мы планируем проанализировать возможность поддержки других традиционных методов репликации (протоколов фиксации внутри реплики, согласованности в конечном счете и методов пересылки журнала) таким образом, чтобы система могла гладко динамически переключаться между традиционной и детерминированной моделями выполнения и репликации в зависимости от имеющейся рабочей нагрузки и других изменяющихся условий.
Планирование потоков управления в детерминированных системах
В традиционных системах транзакции блокируются только при запросе какой-либо одной блокировки. Поэтому планирование рабочих потоков управления может производится достачно простым образом: при освобождении ресурса нужно просто активизировать поток управления, который был блокирован вследствие его запроса. Если транзакции запрашивают сразу все блокировки и могут блокироваться из-за наличия нескольких конфликтов, такое решение может не быть наилучшим. Выполненные нами эксперименты показывают, что устранение лишних переключений контекста (т.е. отказ от преждевременной активизации потоков управления, заблокированных из-за наличия нескольких конфликтов) является важным фактором поддержки приемлемой производительности детерминированных систем при наличии высокой интенсивности конфликтов транзакций. В нашем текущем прототипе для обеспечения осмысленного планирования потоков управления используются методы, основанные на использовании таймеров, а также рандомизированные методы, но мы надеемся, что продолжение исследований в этой области позволит добиться более качественного планирования с меньшими накладными расходами.
Другие детерминированные схемы управления параллелизмом
Предложенная в этой статье детерминированная система, основанная на блокировках, обеспечивает эквивалентность некоторому предопределенному порядку следования транзакций, но, конечно, имеются и другие механизмы, обеспечивающие поддержку этого свойства. Было бы интересно разработать, сравнить и испытать на тестовых наборах детерминированные варианты других схем управления параллелизмом – в частности, версионное управление параллелизмом.
Назад Содержание



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС