Базы данных. Вводный курс
Сергей Кузнецов22.3.6. Точки сохранения
Как мы уже отмечали, использование долговременных транзакций повышает риск полного аннулирования результатов транзакции по причине нарушения ограничений с отложенной проверкой при выполнении каких-либо экспериментальных (недостаточно проверенных) операций. Конечно, теоретически можно было бы оформлять выполнение каждой такой подозрительной операции в виде отдельной транзакции, но это часто противоречит общей логике приложения, когда последовательность действий должна быть атомарной.
Частичное решение этой проблемы предоставляет механизм точек сохранения (savepoint) SQL:1999. Точка сохранения представляет собой своего рода пометку в последовательности операций транзакции, которую в дальнейшем можно использовать для частичного отката транзакции с сохранением жизнеспособности транзакции и результатов операций, выполненных в транзакции до точки сохранения. Пример использования точки сохранения показан на рис. 22.7.
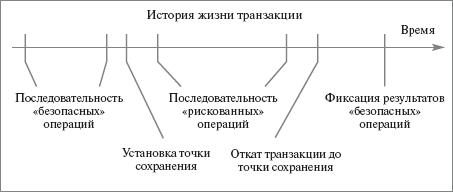
Рис. 22.7. Пример транзакции с точкой сохранения
На этом рисунке после выполнения последовательности проверенных «безопасных» операций, которые, по мнению пользователя, не могут нарушить ограничения целостности с отложенной проверкой, устанавливается точка сохранения. За этой точкой следует серия «рискованных» операций. Если по каким-то причинам (например, путем немедленной проверки отложенных ограничений) затем принимается решение о нецелесообразности фиксации результатов данных операций, то выполняется частичный откат транзакции к точке сохранения, а затем фиксируются результаты безопасных операций.
Допускается установка в одной транзакции нескольких последовательных точек сохранения. При установке каждой точки сохранения ей назначается некоторое (локальное в пределах транзакции) имя, которое в дальнейшем может использоваться в операции ROLLBACK для задания точки частичного отката транзакции (см. выше синтаксис оператора ROLLBACK). Если последовательно устанавливаются две точки сохранения SP1 и SP2 и затем выполняется операция ROLLBACK TO SAVEPOINT SP1, то восстановление производится до SP1 (через SP2), и точка сохранения SP2 «забывается»188).
Для установления точки сохранения используется оператор SAVEPOINT c очевидным синтаксисом
SAVEPOINT savepoint_name
Можно также отказаться от ранее установленной точки сохранения, удалив ее из контекста транзакции. Для этого предназначен оператор RELEASE, синтаксис которого также очевиден:
RELEASE SAVEPOINT savepoint_name
После выполнения этой операции в данной транзакции невозможно выполнять какие-либо другие операции над точкой сохранения с данным именем, пока не будет образована другая одноименная точка сохранения.
22.4. Подключения и сессии
Может показаться странным, что мы оставили на конец этой лекции материал, который, казалось бы, необходимо знать, чтобы иметь возможность приступить к работе с какой-либо из современных систем баз данных. Объяснение очень простое. Чем ниже уровень средств языка SQL, чем ближе эти средства соприкасаются с индивидуальными особенностями реализаций, тем менее точен и конкретен стандарт SQL. А в данном разделе речь идет о средствах, реализация которых в СУБД разных поставщиков обладает очень большой спецификой.
Сильно упрощая текущую ситуацию, можно сказать, что практически все современные продукты управления SQL-ориентированными базами данных основаны на архитектуре «клиент-сервер». Принципиальная схема клиент-серверной организации показана на рис. 22.8.
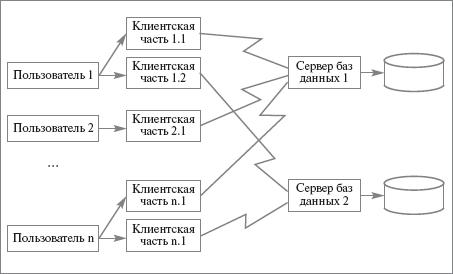
Рис. 22.8. Клиент-серверная архитектура СУБД
Конечно, это рисунок весьма условен. Под термином пользователь здесь, конечно, понимается некоторое приложение, с которым реально работает конечный пользователь (например, в этом приложении может быть реализован монитор прямого SQL). Клиентская часть СУБД – это тот системный компонент, с которым непосредственно взаимодействует пользователь. Данный компонент скрывает специфику реальных взаимодействий с серверной частью СУБД (например, используемые сетевые протоколы, если клиентская и серверная части СУБД разнесены по разным компьютерам сети). Наконец, сервер баз данных представляет собой основную часть СУБД, где, собственно, и происходит выполнение операторов SQL и осуществляется доступ к базе данных.
Важно обратить внимание, что программные компоненты, представляющие пользователя и клиентскую часть СУБД, обычно выполняются на одном компьютере, а сервер баз данных работает на другом (серверном) компьютере. Но вполне может быть, что все три перечисленных программных компонента в действительности размещены на одном компьютере.
22.4.1. Установление соединений
Начиная со стандарта SQL/92, при разработке языковых средств стала приниматься во внимание клиент-серверная организация СУБД. Если говорить более точно, стал очевиден тот факт, что во всех существующих СУБД до начала работы приложения со средствами управления базой данных требуется выполнить некоторые предварительные инициирующие действия. В частности, необходимо создать контекст, в котором будет работать система баз данных. В некоторых реализациях этот контекст создается автоматически при запуске приложения, поскольку клиентская часть СУБД компонуется к приложению. В других случаях прикладная программа связывается с СУБД за счет наличия специализированных реализационно зависимых средств подключения к СУБД. Иногда контекст формируется на основе состояния системных переменных.
Очевидно, что для выработки языковых средств, которые не противоречили бы существующим реализациям, требовался компромисс. Этот компромисс выразился в том, что в SQL:1999 допускается установление связи приложения с СУБД по умолчанию, а также обеспечиваются средства явного управления соединениями. Общий подход состоит в следующем.
- Почти все операторы SQL (с небольшим числом исключений) могут выполняться только при наличии подключения клиентской части СУБД к серверу базы данных.
- Если соединение с сервером установлено и приложение пытается выполнить один из операторов SQL (для выполнения которых требуется соединение), то его выполняет та СУБД, с которой установлено соединение.
- Если приложение пытается выполнить один из операторов SQL (для выполнения которых требуется соединение), а соединение не установлено, то, прежде всего, требуется установить соединение. В SQL:1999 указывается, что такое соединение является соединением с СУБД по умолчанию. Что собой представляет это умолчание, определяется в реализации. После установления соединения упомянутый оператор SQL выполняется той СУБД, с которой установлено соединение.
- Если первым (до установки соединения) выполняемым оператором SQL является оператор
CONNECT(это одно из исключений), то соединение по умолчанию не устанавливается, а происходит обращение к запрашиваемому серверу, и соединение устанавливается именно с ним. - Можно выполнять оператор
CONNECTдля установления соединений со вторым, третьим и т. д. серверами, не разрывая ранее установленные соединения. Каждое вновь установленное соединение называется текущим соединением (current connection), а все ранее установленные соединения – отложенными соединениями (dormant connection). - С каждым соединением ассоциирована сессия. Сессия, ассоциированная с текущим соединением, называется текущей сессией (current session), а сессии, ассоциированные с отложенными соединениями, называются отложенными сессиями (dormant session ).189)
- Если у приложения имеется несколько соединений, можно переключать их с помощью оператора
SET CONNECTION. - Для поддержания установленных соединений могут расходоваться значительные системные ресурсы. Поэтому может возникнуть потребность в ликвидации соединения. Это можно сделать с помощью оператора
DISCONNECT. Все соединения, не ликвидированные явно до завершения работы приложения, ликвидируются системой автоматически. Попытка ликвидировать текущее соединение, в котором выполняется транзакция, расценивается как ошибка. - В реализации определяется, можно ли переключать соединения во время выполнения транзакции. Однако если реализация это допускает, то, в соответствии со стандартом, все операторы, выполняемые в одной транзакции, но в разных соединениях, являются частью одной общей транзакции.
22.4.2. Операторы SQL для управления соединениями
Как отмечалось выше, в эту группу входят операторы CONNECT, SET CONNECTION и DISCONNECT.
Оператор CONNECT
Оператор определяется следующими синтаксическими правилами:
CONNECT TO connection_target
connection_target ::= SQL_server_name
[ AS connection_name ]
[ USER connection_user_name ]
| DEFAULT
Здесь SQL_server_name – это литерально заданная символьная строка, идентифицирующая сервер, к которому требуется подключиться. Смысл (и формат) этого имени определяется в реализации.
В необязательном разделе AS указываемое имя (connection_name) выступает в роли временного имени соединения, которое впоследствии может быть использовано в операторах SET CONNECTION и DISCONNECT. Если в операторе CONNECT раздел AS не содержится, то по умолчанию connection_name совпадает с SQL_server_name.
В необязательном разделе USER указываемое имя (connection_user_name) идентифицирует пользователя, от имени которого устанавливается соединение. При отсутствии раздела USER в качестве connection_user_name по умолчанию принимается текущий authID. В стандарте допускается, что реализация может ограничить возможные значения connection_user_name (например, потребовать, чтобы это имя всегда совпадало с текущим authID).
Эффект использования оператора в форме CONNECT TO DEFAULT почти не отличается от результата действия системы при отсутствии какого-либо явного требования соединения. (Напомним, что соединение по умолчанию неявно устанавливается при попытке выполнения первого оператора SQL, требующего соединения.) Однако имеется одно важное отличие. Если соединение по умолчанию устанавливается неявно, а затем вдруг прерывается из-за какой-то ошибки, то оно автоматически переустанавливается при выполнении следующего оператора SQL. Если же соединение по умолчанию устанавливается явным образом, то автоматическое повторное установление соединения после его разрыва не производится.
Оператор SET CONNECTION
Оператор определяется следующими синтаксическими правилами:
SET CONNECTION connection_object
connection_object::= { connection_name | DEFAULT }
Условием успешного выполнения операции является наличие отложенного установленного соединения с именем connection_name или отложенного установленного соединения по умолчанию. В этом случае текущее соединение становится отложенным, а указанное отложенное соединение – текущим.
Оператор DISCONNECT
Оператор имеет следующий синтаксис:
DISCONNECT { connection_object | ALL | CURRENT }
Необходимым условием для возможности ликвидации соединения является отсутствие активной транзакции в этом соединении.
Если в операторе указывается connection_object, то соответствующее имя должно соответствовать установленному (текущему или отложенному) соединению. Если указывается CURRENT, то должно существовать текущее соединение.
Если оператор применяется к текущему соединению, то это соединение ликвидируется, и ни одно соединение не является текущим. В таком случае для продолжения работы необходимо установить текущее соединение при помощи операторов CONNECT или SET CONNECTION.
Если в операторе указывается ALL, то ликвидируются все соединения, включая текущее.
22.5. Заключение
В этой лекции были рассмотрены три темы, которые являются относительно независимыми, но относятся к средствам языка SQL, предназначенным для регулирования доступа пользователей к базам данных. На первый взгляд материал этой лекции проще материала предыдущих лекций, посвященных языку SQL. Наверное, это действительно так, если говорить про чисто языковую сложность соответствующих операторов SQL. Но в действительности (которую мы старательно обходили в основных разделах лекции) дело обстоит гораздо сложнее.
Как легко видеть, при распространении привилегий и ролей могут возникать произвольно сложные ориентированные графы связей между объектами базы данных, владельцами привилегий, привилегиями и ролями. Если изображать сплошными стрелками передачу привилегий, прерывистыми – передачу ролей, пунктирными – владение привилегиями, а точечными – владение ролями, то даже по отношению к одной привилегии pr для одного объекта o может появиться следующий граф связей (userID означает authID, отличный от имени роли), показанному на рис. 22.8.
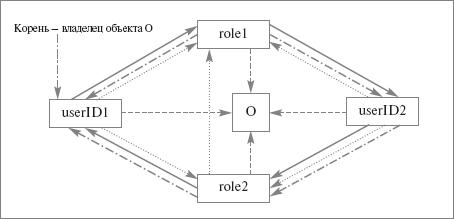
Рис. 22.9. Простейший граф идентификаторов пользователя, имен ролей, объектов и привилегий
Как мог появиться такой граф? Пользователь с authID, равным userID1 (это мы предположили для упрощения, а вообще-то это могло быть и именем роли), создает объект o, становится его владельцем и тем самым обладателем привилегии pr по отношению к этому объекту. Пользователь userID1 предоставляет полномочие pr роли role1 (с правом передачи). Затем пользователю userID1 предоставляется роль role1 (с правом передачи), и он получает право исполнять эту роль. От имени роли role1 полномочие pr передается пользователю userID2 (с правом передачи), и этот же пользователь получает право исполнять роль role1 (с правом передачи). Пользователь userID2 передает роли role2 роль role1 и полномочие pr (с правом передачи). Наконец, от имени роли role2 полномочие pr и сама роль role2 передаются пользователю userID1.
Попробуйте теперь проследить, как будет выполняться операция
REVOKE pr ON o FROM role1 CASCADED
Какие узлы и дуги останутся в графе? Задача не очень сложная, но, очевидно, нетривиальная. И такого рода задачи приходится ежедневно решать администраторам больших и динамических SQL-ориентированных баз данных.
Теперь немного поговорим об управлении транзакциями. В стандарте SQL:1999 ничего не говорится о возможной реализации различных уровней изоляции. Конечно, это правильно, поскольку спецификация языка не должна накладывать какие-либо ограничения на реализации. Но, к сожалению, при использовании SQL-ориентированной СУБД некоторые знания о реализации механизма транзакций необходимы. Например, предположим, что имеются две транзакции T1 и T2, выполняемые в режиме изоляции SERIALIZABLE. Предположим, что они должны работать по «симметричному» плану, показанному на рис. 22.9.
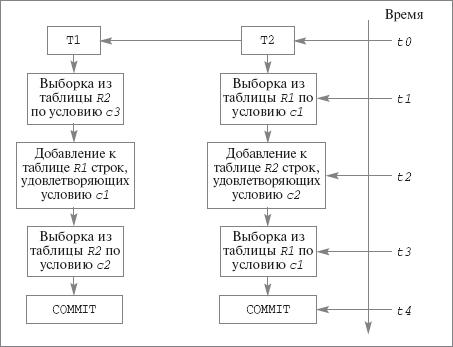
Рис. 22.10. Взаимные «фантомы»
Транзакции работают в наивысшем режиме изолированности. Эффект их выполнения должен быть эквивалентен эффекту некоторого последовательного выполнения транзакций T1 и T2. Но попробуйте придумать какой-либо корректный способ одновременного выполнения этих транзакций, который привел бы к эффекту их последовательного выполнения. Другими словами, для грамотного использования механизма транзакций на уровне языка SQL необходимо знать, каким образом данный механизм реализован в используемой СУБД.
И, конечно же, знания о реализации абсолютно необходимы при использовании механизма подключений и сессий. Слишком много в этой части стандарта отдается на волю реализации.
188 Обратите внимание, что оператор ROLLBACK TO SAVEPOINT savepoint_name, хотя и синтаксически схож с «обычным» оператором ROLLBACK, принципиально отличается по своей семантике. Откат транзакции до указанной точки сохранения не означает завершения транзакции. Видимо, из соображений здравого смысла, следовало бы ввести в язык SQL операцию ABORT TRANSACTION для аварийного завершения транзакции с ликвидацией всех последствий ее операций в базе данных и, отдельно, операцию ROLLBACK TO, в которой всегда явно указывалось бы, до какого уровня требуется откат. Кстати, заметим, что комбинация ROLLBACK AND CHAIN TO SAVEPOINT savepoint_name является недопустимой (поскольку текущая транзакция не завершается).
189 Каждому соединению соответствует одна и только одна сессия. В сообществе SQL эти термины часто используются попеременно для обозначения одного и того же. Более строгие блюстители терминологии утверждают, что термин подключение относится к сетевому пути между клиентом и сервером, а ессия – это контекст, в котором работает SQL-сервер.