2008 г.
Базы данных. Вводный курс
Сергей Кузнецов
Назад Содержание Вперёд
14.4. Восстановление после мягкого сбоя
К
числу основных проблем восстановления после мягкого сбоя относится
то, что одна логическая операция изменения базы данных может
изменять несколько физических блоков базы данных, например, блок
данных и несколько блоков индексов. Блоки базы данных буферизуются в
оперативной памяти и выталкиваются независимо. После мягкого сбоя
набор блоков внешней памяти базы данных может оказаться
несогласованным, т.е. часть блоков внешней памяти соответствует
объекту до изменения, часть – после изменения. Например, в
результате выполнения операции UPDATE
соответствующий
кортеж мог переместиться в другой блок. В этом случае (см. лекцию
12)
изменяются два блока: в описатель кортежа в его исходном блоке
записывается его новый tid,
а в новом блоке размещается сам модифицированный кортеж. Очевидно,
что если хотя бы один из этих блоков не попал во внешнюю память базы
данных к моменту мягкого сбоя, то при восстановлении не удастся
вернуть кортеж на его прежнее место. Другими словами, к такому
состоянию внешней памяти базы данных не применимы операции
логического уровня.
Состояние
внешней памяти базы данных называется физически
согласованным,
если наборы страниц всех объектов согласованы, т.е. соответствуют
состоянию любого объекта либо после его изменения, либо до
изменения.
14.4.1. Схема восстановления от точки физической согласованности
Будем
считать, что в журнале отмечаются точки физической согласованности
базы данных – моменты времени, в которые во внешней памяти
содержатся согласованные результаты операций, завершившихся до
соответствующего момента времени, и отсутствуют результаты операций,
которые не завершились, а буфер журнала вытолкнут во внешнюю память.
Немного позже мы обсудим, как можно достичь физической
согласованности. Назовем такие точки ppc
(point
of physical consistency).
Все возможные
состояния транзакций к моменту мягкого сбоя показаны на рис. 14.1.
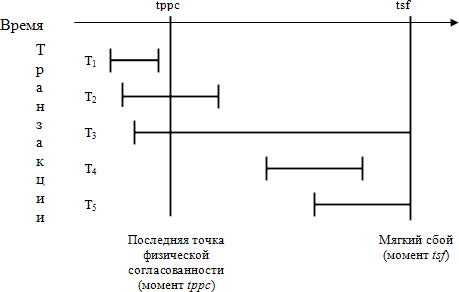
Рис. 14.1. Возможные состояния транзакций к моменту мягкого сбоя
Предположим,
что каким-то образом удалось восстановить внешнюю память базы данных
к состоянию на момент времени tppc
(как это можно сделать, обсудим в следующем подразделе). Тогда
восстановление последнего по времени логически целостного состояния
базы данных производится следующим образом.
- Для
транзакции
T1
никаких действий производить не требуется. Она закончилась до
момента tppc,
и все ее результаты гарантированно отражены во внешней памяти базы
данных.
- Для
транзакции
T2
нужно повторно выполнить (redo)
последовательность операций, которые выполнялись после установки
точки физически согласованного состояния в момент tppc.
Действительно, во внешней памяти полностью отсутствуют следы
операций, которые выполнялись в транзакции T2
после момента tppc.
Следовательно, повторное прямое (по смыслу и хронологии) выполнение
операций транзакции T2
корректно и приведет к логически согласованному состоянию базы
данных. (Поскольку транзакция T2
успешно завершилась до момента мягкого сбоя tfs,
в журнале содержатся записи обо всех изменениях базы данных,
произведенных этой транзакцией.)
- Для
транзакции
T3
нужно выполнить в обратном направлении (undo) ту часть операций,
которую она успела выполнить до момента tppc.
Действительно, во внешней памяти базы данных полностью отсутствуют
результаты операций T3,
которые были выполнены после момента tppc.
С другой стороны, во внешней памяти гарантированно присутствуют
результаты операций T3,
которые были выполнены до момента tppc.
Следовательно, обратное выполнение (по смыслу и хронологии) операций
T3
корректно и приведет к согласованному состоянию базы данных.
(Поскольку транзакция T3
не завершилась к моменту мягкого сбоя tfs,
при восстановлении необходимо устранить все последствия ее
выполнения.)
- Для
транзакции
T4,
которая успела начаться после момента tppc
и закончиться до момента мягкого сбоя tfs,
нужно произвести полное повторное выполнение операций в прямом
направлении. (Поскольку транзакция T4
успешно завершилась до момента мягкого сбоя tfs,
в журнале содержатся записи обо всех изменениях базы данных,
произведенных этой транзакцией).
- Наконец,
для транзакции
T5,
начавшейся после момента tppc
и не успевшей завершиться к моменту мягкого сбоя tfs,
никаких действий предпринимать не требуется. Результаты операций
этой транзакции полностью отсутствуют во внешней памяти базы данных.
14.4.2. Восстановление физической согласованности базы данных
Каким
же образом можно обеспечить наличие точек физической согласованности
базы данных, т.е. как восстановить состояние базы данных в момент
tppc?
Для этого используются два основных подхода: подход, основанный на
использовании теневого механизма, и подход, в котором применяется
журнализация постраничных изменений базы данных.
Теневой механизм
Теневой
механизм был изначально предложен для поддержания целостности файлов
при аварийном отключении питания компьютера. Общая идея теневого
механизма для файлов показана на рис. 14.2. Файл представляется как
набор блоков внешней памяти, для доступа к которым поддерживается
таблица отображения (см.
лекцию
1).
При открытии файла таблица отображения номеров его логических блоков
в адреса физических блоков внешней памяти считывается в оперативную
память. При модификации любого блока файла во внешней памяти
выделяется новый блок. При этом текущая таблица отображения (в
основной памяти) изменяется, а теневая остается неизменной. Если во
время работы с открытым файлом происходит сбой, во внешней памяти
автоматически сохраняется состояние файла до его открытия. Для
явного восстановления файла достаточно повторно считать в основную
память теневую таблицу отображения.
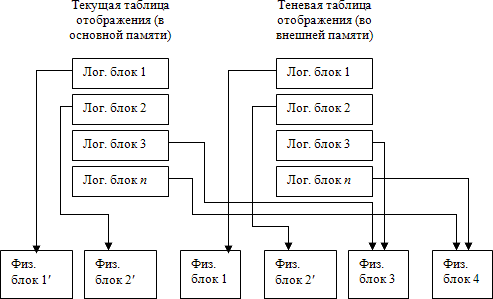
Рис. 14.2. Теневой механизм для файлов
В контексте базы
данных теневой механизм используется следующим образом [3.16].
Периодически выполняются операции установки точки физической
согласованности базы данных. При выполнении этой операции все
логические операции завершаются, все страницы буферного пула базы
данных, содержимое которых отличается от содержимого соответствующих
блоков внешней памяти, выталкиваются. Теневая таблица отображения
файлов (сегментов) базы данных заменяется текущей таблицей
отображения (правильнее сказать, текущая таблица отображения
записывается на место теневой).
Здесь имеется
некоторая проблема, состоящая в том, что в любой момент времени
теневая таблица отображения должна быть корректной, т.е.
соответствовать некоторому ранее зафиксированному физически
целостному состоянию базы данных. Для этого необходимо обеспечить
атомарность операции замены теневой таблицы отображения. В общем
случае таблица отображения может занимать несколько блоков внешней
памяти, и для записи текущей таблицы отображения на место теневой
таблицы в этом случае потребуется несколько обменов с дисками. Если
в промежутке между этими обменами возникнет мягкий сбой, то будет
благополучно утрачена текущая таблица отображения и безнадежно
испорчена теневая таблица, т.е. мы просто лишимся возможности
восстанавливаться за счет использования последнего физически
согласованного состояния базы данных.
Чтобы
это не произошло, во внешней памяти поддерживаются две области
хранения таблицы отображения файлов (будем называть их областями A
и B).
Кроме того, в отдельном блоке внешней памяти хранится флаг F,
показывающий, какая из этих областей в данный момент содержит
действующую теневую таблицу отображения (назовем соответствующие
значения флага FA
и FB).
Тогда, если сохраненным во внешней памяти значением флага является
FA,
то текущая таблица отображения записывается в область B.
Если эта операция выполняется успешно, то в блок флага записывается
значение FB.
Считается, что операция записи одного блока на диск является
атомарной. Если эта операция заканчивается успешно, это означает,
что новая теневая таблица отображения хранится в области B.
Если же запись текущей таблицы отображения в область B
не удалась, или если не выполнилась операция записи блока с флагом
F,
то продолжает действовать старая теневая таблица отображения.
Восстановление
хронологически последнего сохраненного физически согласованного
состояния базы данных происходит мгновенно: текущая таблица
отображения заменяет теневой таблицей (при восстановлении просто
считывается действующая теневая таблица отображения). Все проблемы
восстановления решаются, но за счет слишком большого перерасхода
внешней памяти. В пределе может потребоваться вдвое больше внешней
памяти, чем реально нужно для хранения базы данных.
Журнализация постраничных изменений
Возможен
другой подход, при использовании которого наряду с логической
журнализацией операций изменения базы данных производится
журнализация постраничных изменений. Первый этап восстановления
после мягкого сбоя состоит в постраничном откате недовыполненных
логических операций. Подобно тому, как это делается с логическими
записями по отношению к транзакциям, последней записью о
постраничных изменениях от одной логической операции является запись
о конце операции. Вообще, выполнение логических операций уровня RSS
носит транзакционный характер. В частности, как уже отмечалось выше,
при выполнении логической операции обновления базы данных, вообще
говоря, изменяется несколько блоков базы данных. Для обеспечения
возможности отката отдельной операции (а это может потребоваться,
например, если обнаруживается нарушение свойства уникальности
какого-либо индекса) приходится до конца операции монопольно
блокировать все страницы буферного пула базы данных, содержащие
копии изменяемых этой операцией блоков базы данных.
Чтобы распознать,
нуждается ли страница внешней памяти базы данных в восстановлении,
при выталкивании любой страницы из буферного пула основной памяти в
нее помещается номер последней записи о постраничном изменении этой
страницы. Этот же номер запоминается в самой записи. Тогда, чтобы
понять, нужно ли применить данную запись о постраничном изменении
соответствующего блока внешней памяти для восстановления состояния
этого блока, требуется всего лишь сравнить номер, содержащийся в
этом блоке, с номером, содержащимся в журнальной записи. Если в
блоке содержится номер, меньший номера журнальной записи, то это
означает, что буферная страница, в которой выполнялось
соответствующее изменение, не была к моменту мягкого сбоя вытолкнута
во внешнюю память, и применять данную запись для восстановления
соответствующего блока внешней памяти не требуется.
Для
иллюстрации на рис. 14.3 показано пять записей об изменении блока b
с номерами n-2,
n-1,
n,
n+1,
n+2.
В блоке b
содержится номер n.
Это означает, что в состоянии блока отражены результаты операций
изменения блока, соответствующих журнальным записям LR(b)n,
LR(b)n-1
и
LR(b)n-2.
Изменения блока, произведенные операциями, которым соответствуют две
хронологически последние журнальные записи LR(b)n+1
и LR(b)n+2,
в его состоянии во внешней памяти не отражены, поскольку не было
выполнено выталкивание во внешнюю память страницы буферного пула,
содержащей копию блока b.
Поэтому при восстановлении состояния блока требуется выполнить
обратные операции изменения блока
b,
соответствующие журнальным записям LR(b)n,
LR(b)n-1
и
LR(b)n-2.
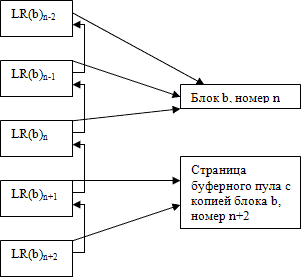
Рис. 14.3. Нумерация записей об изменении блока
В этом подходе
имеются два поднаправления. В первом поднаправлении поддерживается
общий журнал логических и страничных операций. Естественно, наличие
двух видов записей, интерпретируемых абсолютно по-разному, усложняет
структуру журнала. Кроме того, записи о постраничных изменениях,
актуальность которых носит локальный характер, существенно (и не
очень осмысленно) увеличивают журнал.
Поэтому
распространено поддержание отдельного (короткого) журнала
постраничных изменений. Такой журнал обычно называют физическим
журналом,
поскольку он содержит записи об изменении физических объектов –
блоков внешней памяти. В отличие от этого, журнал логических
операций принято называть логическим
журналом,
поскольку в нем содержатся записи об операциях над логическими
объектами – кортежами.
Как
уже отмечалось, логический и физический журналы имеют разную
природу. Во-первых, логический журнал должен поддерживать как
обратное выполнение журнализованных операций (undo),
так и их повторное прямое выполнение (redo).
В отличие от этого, от физического журнала требуется только
поддержка обратного выполнения постраничных операций.
Во-вторых,
логический журнал обычно начинает заполняться заново только после
выполнения операций резервного копирования базы данных или
архивирования самого журнала (см. следующий подраздел). До этого
времени он линейно растет. Понятно, что в любом случае для
размещения журнала выделяется внешняя память ограниченного размера.
Предельный размер журнала определяется администратором базы данных и
должен согласовываться с размером интервала времени, через которое
производится резервное копирование базы данных.
Потенциальное
переполнение логического журнала регулируется следующим образом. На
пути к достижению максимально возможного размера журнала
устанавливаются «желтая» и «красная» зоны.
Когда записи в журнал достигают «желтой» зоны, выдается
предупреждение администратору базы данных и прекращается образование
новых транзакций. Если все существующие транзакции завершаются до
достижения «красной»
зоны, автоматически выполняется архивация базы данных или
логического журнала. Если какие-то транзакции не успевают
завершиться до достижения «красной» зоны журнала,
выполняется их аварийный откат, после чего производится архивация
базы данных или журнала. Естественно, размер «желтой» и
«красной» зон логического журнала должен устанавливаться
администратором базы данных с учетом максимально допустимого числа
одновременно существующих транзакций и их возможной протяженности.
В
отличие от этого, физический журнал существует сравнительно недолгое
время (интервал времени между соседними операциями установки точки
физической согласованности базы данных) и, как
правило,
занимает существенно меньшее дисковое пространство, чем логический
журнал. При выполнении операции установки точки физической
согласованности выполняются следующие действия:
-
прекращают инициироваться
новые логические операции;
-
после завершения всех
выполняемых логических операций происходит выталкивание во внешнюю
память всех модифицированных страниц буферного пула;
-
формируется и
выталкивается во внешнюю память логического журнала специальная
запись о точке физически согласованного состояния;
-
в случае успешного
предыдущего действия разрешается инициация новых логических
операций, и физический журнал пишется заново.
Предпоследняя
операция является атомарной (это опять же запись одного блока на
диск): если она успешно выполняется, то при следующем восстановлении
после мягкого сбоя будет использоваться новая точка физически
согласованного состояния, иначе ситуация воспринимается как мягкий
сбой с восстановлением логически согласованного состояния базы
данных от предыдущей точки физически согласованного состояния (с
оповещением об этом администратора базы данных).
14.5. Восстановление базы данных после жесткого сбоя
Понятно, что для
восстановления последнего согласованного состояния базы данных после
жесткого сбоя журнала изменений базы данных явно недостаточно. Самый
простой способ восстановления основывается на использовании
логического журнала и архивной копии базы данных.
Восстановление
начинается с обратного копирования (на исправный носитель) базы
данных из архивной копии. Затем для всех закончившихся транзакций
выполняется redo,
т.е. операции повторно выполняются в прямом смысле.
Более
точно, происходит следующее:
- по
журналу в прямом направлении выполняются все операции;
- для
транзакций, которые не закончились к моменту сбоя, выполняется
откат.
Очевидно,
что после этого будет получено хронологически последнее до момента
жесткого сбоя логически согласованное состояние базы данных.
Следует
заметить, что при некоторой дисциплине выполнения логических
операций над базой данных при восстановлении базы данных после
жесткого сбоя можно просто последовательно повторно выполнять
операции в соответствии с журнальными записями, не обращая внимание
на то, в каких транзакциях они выполнялись до жесткого сбоя. В
частности, если сериализация транзакций основывается на блокировках
объектов, то эта дисциплина заключается в том, что при выполнении
операции в штатном режиме нужно сначала дождаться удовлетворения
блокировки изменяемого объекта, затем поместить запись в буфер
логического журнала,
и только после этого реально выполнять операцию.
На
самом деле, поскольку жесткий сбой не сопровождается утратой буферов
оперативной памяти, можно
восстановить базу данных до такого уровня, чтобы можно
было продолжить даже выполнение незавершенных транзакций. Но обычно
это не делается, потому что восстановление после жесткого сбоя –
это достаточно длительный процесс.
Хотя к ведению
журнала предъявляются особые требования по части надежности, в
принципе возможна и его утрата. Тогда единственным способом
восстановления базы данных является возврат к архивной копии.
Конечно, в этом случае не удастся получить последнее согласованное
состояние базы данных, но это лучше, чем ничего.
Последний вопрос,
который здесь следует еще раз обсудить, касается производства
архивных копий базы данных и/или журнала. Самый простой способ
состоит в архивировании базы данных по явному указанию
администратора или при переполнении журнала. Но можно выполнять
архивацию базы данных реже, чем переполняется журнал. Вместо базы
данных можно архивировать сам журнал. В пределе для полного
восстановления базы данных после жесткого сбоя достаточно иметь
исходную архивную копию базы данных, последовательность архивных
копий журналов и последний логический журнал. Может показаться, что
восстановление базы данных на основе таких архивных источников будет
занимать недопустимо большое время, однако здесь возможна
значительная оптимизация.
Во-первых,
архивированный логический журнал можно сжимать. Для этого для
каждого объекта базы данных нужно найти последовательность
журнальных записей, относящихся к этому объекту, в хронологическом
порядке и заменить их одной записью, соответствующей операции над
объектом, результат которой эквивалентен результату
последовательного выполнения журнализованных операций из построенной
последовательности. Например, на рис. 14.4 показан процесс сжатия
последовательности журнальных записей, соответствующих
последовательности операций над кортежем, у которого tid
= k
и
имеются четыре целочисленных поля. Заметим, что если хронологически
последней в последовательности является запись, соответствующая
операции DELETE,
то после
сжатия этой последовательности она станет пустой.
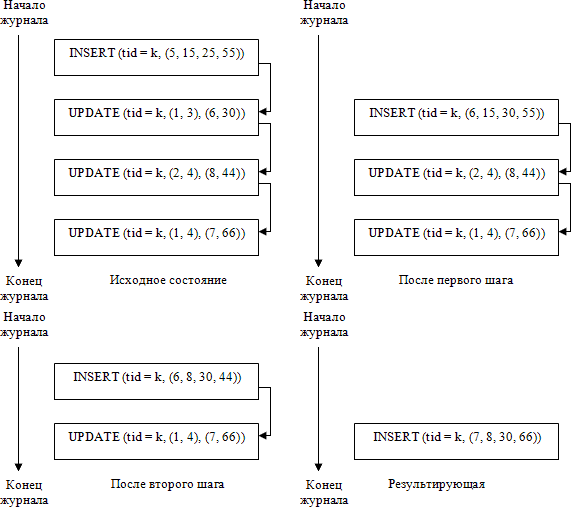
Рис. 14.4. Процесс сжатия последовательности журнальных записей
Во-вторых,
точно таким же образом можно совместно сжать два хронологически
последовательных полных или сжатых журнала. Таким образом, для
восстановления после жесткого сбоя можно воспользоваться исходной
архивной копией, одним сжатым архивным журналом и последним
логическим журналом. Снова могут возникнуть сомнения относительно
сложности и продолжительности процесса сжатия журнала. Но здесь
следует заметить, что эта работа может выполняться на отдельном
компьютере в режиме off-line.
Кроме того, если имеется архивная копия базы данных, сжатый архивный
журнал и набор еще не сжатых архивных журналов, то этого уже
достаточно для восстановления, так что сроки завершения процесса
полного сжатия не являются критическими.
14.6. Заключение
В
этой лекции
рассматривались основные принципы и алгоритмы подсистем СУБД,
предназначенных для управления буферами основной памяти,
журнализации и восстановления базы данных после различных сбоев.
Изложение велось без технических деталей, таких как возможные
структуры данных журналов.
Заметим,
что во многих современных производственных СУБД журнализация и
восстановление основаны на применении семейства алгоритмов ARIES,
разработанных в 1980-е гг. известным исследователем из компании IBM
К. Моханом (C.
Mohan).
В
этой лекции
не приводится описание алгоритмов семейства ARIES,
поскольку, по мнению автора, это перегрузило бы ее подробностями, не
способствующими пониманию основных идей. Тем не менее, читателям,
которых заинтересовала эта тема, полезно познакомится с этими
алгоритмами, для чего можно воспользоваться, например, [3.16] или
оригинальными статьями Мохана и его коллег.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС