2008 г.
Методы бикластеризации для анализа интернет-данных
Дмитрий Игнатов,
кафедра анализа данных и искусственного интеллекта ГУ-ВШЭ
Назад Содержание Вперёд
5.2. Анализ данных посещаемости сайтов с помощью ФАП
С момента создания сайта перед его владельцами и, возможно, потенциальными рекламодателями встает вопрос учета количества посещений с целью определения популярности ресурса и выявления целевой аудитории. Сейчас рынок таких услуг довольно широко представлен рядом компаний, которые готовы предоставить владельцам сайтов различные счетчики посещений, учитывающие как количество посещений отдельными пользователями, так и их географию, текущее время и продолжительность посещения.
Как показывает развитие отрасли, для эффективного анализа структуры аудиторий сайтов статистической информации недостаточно. Владельца сайта часто интересуют подгруппы его целевой (постоянной) аудитории. Например, покупатели бытовой техники в Интернет-магазине могут отличаться по различным категориям (домохозяйки, лица, недавно сделавшие ремонт, или новоселы, владельцы заведений общепита и т.д.). Это дает владельцам сайтов возможность корректировать предлагаемые услуги, выбирать адекватные рекламные средства, выстраивать линейку продуктов и т.п.
Выводы о принадлежности к той или иной группе целевой аудитории можно сделать, анализируя поведение посетителей сайта, а именно, рассматривая посещение ими же других сайтов и выдвигая соответствующие гипотезы. Наш подход основан на применение решеток формальных понятий, неплохо зарекомендовавших себя при анализе структур научных сообществ и других, по сути, социологических исследованиях. Ниже мы опишем постановку задачи и спектр возможных путей ее решения, а также пути преодоления возникающих трудностей.
Постановка задачи
Компания Spylog — одна из ведущих фирм на российском рынке, специализирующаяся на сборе и анализе статистики посещаемости веб-сайтов. В рамках сотрудничества нами решается задача построения релевантной таксономии сайтов. В качестве данных для проведения экспериментов нам предложена выборка по статистике посещений 10000 сайтов с прилагаемым плоским тематическим каталогом по 59 категориям. Для конкретных экспериментов мы отобрали из них четыре сайта следующих тематик: сайт университета, сайт Интернет-магазина бытовой техники, сайт крупного банка, сайт автомобильного Интернет-салона.
Необходимо построить "внешнюю" и "внутреннюю" таксономии каждого из сайтов. Под "внешней" таксономией мы будем понимать иерархическую структуру аудитории целевого сайта, выявленную по данным посещений остальных сайтов выборки. Ей будет в точности соответствовать решетка формальныx понятий, построенная по контексту
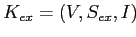 ,
где
,
где
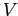 — множество всех посетителей целевого сайта,
— множество всех посетителей целевого сайта, 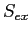 — множество всех сайтов выборки за исключением целевого сайта,
— множество всех сайтов выборки за исключением целевого сайта, 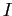 — отношение инцидентности
— отношение инцидентности 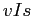 ,
имеющее место для
,
имеющее место для 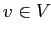
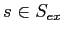 ,
тогда и только тогда, когда посетитель
,
тогда и только тогда, когда посетитель 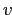 "ходил" на сайт
"ходил" на сайт 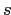 .
.
Под "внутренней" таксономией будем понимать иерархическую структуру аудитории целевого сайта построенную по данным посещений его собственных страниц (возможно сгруппированных по разделам). Соответствующий контекст определяется сходным образом
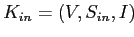 ,
где
— множество всех посетителей целевого сайта,
,
где
— множество всех посетителей целевого сайта, 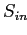 — множество всех собственных страниц целевого сайта,
— отношение инцидентности ,
имеющее место для
— множество всех собственных страниц целевого сайта,
— отношение инцидентности ,
имеющее место для
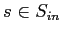 тогда и только тогда, когда посетитель
"ходил" на сайт .
Понятию такого контекста соответствует пара
тогда и только тогда, когда посетитель
"ходил" на сайт .
Понятию такого контекста соответствует пара 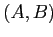 ,
такая что
,
такая что
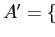 множество сайтов
множество сайтов 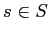 ,
которые посещали все посетители
,
которые посещали все посетители
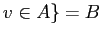 ,
а
,
а
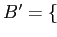 множество посетителей , которые посещали все сайты
множество посетителей , которые посещали все сайты
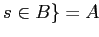 .
.
Исходные данные для построения "внешней" таксономии для каждого сайта представляются в виде файла записей следующего формата:
- id; \\id посетителя;
- last_ts; \\время первого захода на сайт;
- first_ts; \\время последнего захода на сайт;
- num; \\количество совершенных сессий за все время знакомства с сайтом.
Для построения внутренней таксономии используется аналогичная структура с дополнительным полем url_page, соответствующим посещенной странице данного сайта.
По этим данными формируются описанные выше контексты. Ниже описываются способы отбора посетителей и сайтов для формирования контекстов.
Пути решения и возникающие проблемы
Несмотря на то, что выборка из 10000 сайтов сравнительно мала для российского Интернет-пространства, использование всей информации для анализа аудитории конкретного сайта влечет слишком большие вычислительные затраты. А построенные таксономии, представленные диаграммами решеток понятий, громоздки для визуального анализа и последующей интерпретации. Обсудим пути сокращения размера входных данных.
- Отбор только тех посещений, которые превышают некоторый порог посещаемости. Это дает существенное сокращение числа объектов контекста, например, для 100000 посетителей порог посещаемости, поднятый до 20, может дать сокращение почти в 100 раз.
- Отбор признаков (сайтов) можно также организовать по посещаемости, т.е. учитывать при составлении контекста только те сайты, на которых данные посетители бывали больше заданного числа раз. Таким образом, из контекста исключаются сайты, не релевантные для данной аудитории.
- Целевой сайт также целесообразно рассматривать в терминах сайтов определенной тематики., например, в терминах сайтов газет или финансовых учреждений. Если учесть, что такие группы относительно невелики — 100-500 сайтов, то такой прием дает также существенное сокращение размера контекста.
- Для контекста, построенного по внутренней структуре сайта, можно укрупнять признаки, уменьшая, тем самым, их количество. Например, если посетители сайта банка имеют личную страницу, то целесообразно считать все такие страницы одним признаком "личная страница". Аналогично можно поступить со страницами товаров, принадлежащих к одной товарной группе.
- Предоставленные данные охватывают период около года, поэтому целесообразно выделить некий временной интервал и учитывать посещения, приходящиеся на него. Интервалом может быть месяц, день, время суток и т.п.
Но даже при таком сокращении размера входа, т.е. контекста, решетки понятий, а следовательно, и диаграммы имеют большие размеры и не слишком удобны для работы аналитика. Например, для контекста размера 4125×225 порождается 57 329 понятий.
Обсудим теперь, каким образом добиться уменьшения размера решетки на этом этапе, по возможности, без потери значимой информации.
- Использование индекса устойчивости понятий для отбора наиболее устойчивых понятий [48], т.е. понятий, индекс устойчивости которых превышает заданный порог. Мы использовали пороги, начиная от 0.9, что соответствовало 100-200 наиболее устойчивым понятиям.
- Применение отбора понятий по размеру объема, что соответствует построению решетки понятий, называемой айсбергом. Например, отбор 100 верхних понятий из всех понятий контекста, отсортированных по размеру объема.
- Использование вложенных диаграмм, хотя и не позволяет сократить число понятий, но является удобным средством для визуализации решеток, учитывающим, например, разные тематики признаков. Например,
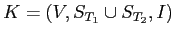 содержит подмножество сайтов тематики
содержит подмножество сайтов тематики 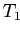 и
и 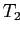 .
В каждом внешнем узле диаграммы, построенной по подконтексту первой тематики, можно увидеть внутреннюю решетку соответствующую подконтексту второй тематики.
.
В каждом внешнем узле диаграммы, построенной по подконтексту первой тематики, можно увидеть внутреннюю решетку соответствующую подконтексту второй тематики.
- Возможность комбинирования отбора по устойчивости и построения вложенных диаграмм. См. работу [63]
- "Склеивание" понятий на основе ассоциативных правил, т.е. фактически, добавление ассоциативного правила как импликации, что приведет к уменьшению размера решетки.
- Использование импликаций и ассоциативных правил как дополнительное средство выявления зависимостей. Поиск наиболее интересных импликаций следует производить, исходя из расположения понятий в решетке.
Остановимся подробнее на понятии индекса устойчивости [48, 49], который мы используем для отбора интересных групп посетителей при построении таксономий. С одной стороны, индекс устойчивости формального понятия служит показателем независимости содержания от частных объектов объема (наличие которых в контексте зависит от случайных факторов). С другой стороны, индекс устойчивости показывает, насколько сильно объем понятия отличается от похожих меньших объемов (если такая разница мала, то объем относится к устойчивой категории). Отметим, что впервые понятие устойчивости было предложено в работе [5].
Определение 5.1
Пусть
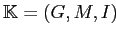
— формальный контекст,
некоторое формальное понятие
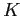
. Тогда
индекс устойчивости 
понятия
определяется выражением
Очевидно, что
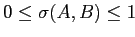
.
Даже если описание данных зашумлено, то понятия с индексом устойчивости, близким к 1, вероятно, объективно отражают реальное положение дел. Индекс устойчивости показывает, насколько стабильны интересы групп посетителей, даже если некоторые из более не активны.
Обсудим теперь важные для интерпретации особенности построения решеточных таксономий.
- При отборе посетителей по порогу посещаемости есть опасность построить таксономию для поведения поисковых роботов, а не реальных людей, интересующих владельца сайта. Когда порог по посещаемости велик, а промежуток времени, в течение которого происходили посещения, короткий, мы, фактически, исследуем поведение "поисковых маньяков" и поисковых роботов. Поэтому необходимо устанавливать разумные пороги по посещаемости как сверху, так и снизу, а также целесообразно использовать относительные пороги.
- Чтобы выявить схожие аудитории людей, не посещающих целевой сайт, можно расширить исходный контекст добавлением в него таких пользователей, причем таких, которые посещают сайты, уже входящие в контекст.
- Работа одновременно с внутренней структурой "целевого" сайта и прочими сайтами (признаки — сайты из имеющегося десятитысячного списка и страницы целевого сайта). В случае с сайтом университета это позволит, например, сравнить устремления людей, интересующихся разными факультетами.
- Работа с контекстом
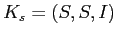 ,
где отмечается клетка на пересечении строки и столбца, если размер пересечения аудиторий двух сайтов не ниже некоторого порога. Это позволит выявить схожие устойчивые аудитории различных сайтов.
,
где отмечается клетка на пересечении строки и столбца, если размер пересечения аудиторий двух сайтов не ниже некоторого порога. Это позволит выявить схожие устойчивые аудитории различных сайтов.
- Для построения исходных контекстов можно отбирать только те сайты из десяти тысяч, размер пересечений аудитории которых с аудиторией целевого сайта не ниже некоторого порога. Это даст сокращение размера контекста и, возможно, повысит релевантность результатов.
Результаты
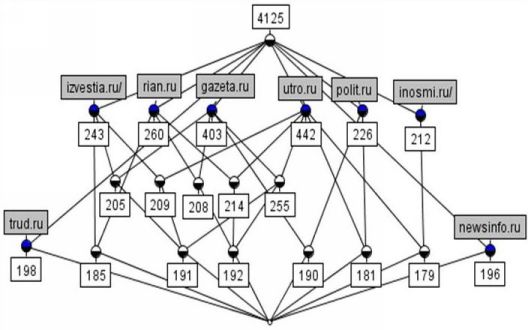
Рассмотрим некоторые результаты, полученные нами в ходе анализа посещаемости сайта ГУ-ВШЭ за ноябрь 2006 года. Мы построили как внутреннюю, так и внешние таксономии сайта. В качестве внешних сайтов мы рассматривали ресурсы новостной тематики, финансовых и образовательных учреждений. Приведем пример внешней таксономии для посетителей ГУ-ВШЭ в терминах ресурсов новостных сайтов. Отметим, что рассматриваемый временной промежуток — месяц, а порог на число посещений сайта ГУ-ВШЭ каждым пользователем равен 20.
На диаграмме решетки-айсберга для 25-ти понятий, имеющих наибольших объем, видны узлы, соответствующие СМИ середины политического спектра, которые посещаются "всеми" и потому не выявляют социальных групп.
Решетка понятий по 25-ти самым устойчивым понятиям содержит некоторые социологически значимые группы посетителей, такие как АИФ ("желтая пресса"), Cosmopolitan, Эксперт (профессионально-аналитические обзоры).
Выводы
Первые результаты придают уверенность в том, что средства ФАП окажутся подходящими для решения задачи выявления сообществ посетителей сайтов. В качестве направлений дальнейшей работы стоит выделить учет временных характеристик посещений и их последовательности. Необходимо обратить внимание на средства визуализации, такие как диаграммы вложенных решеток.
Назад Содержание Вперёд

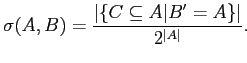

{kind=link}
{kind=link}