2003 г
Технология баз данных в системах поддержки принятия решений
Сураджит Чаудхури, Умешвар Дайал, Венкатеш Ганти
22.01.2002
Открытые системы, #01/2002
Системы поддержки принятия решений — основа ИТ-инфраструктуры различных компаний, поскольку эти системы дают возможность преобразовывать обширную бизнес-информацию в ясные и полезные выводы. Сбор, обслуживание и анализ больших объемов данных, — это гигантские задачи, которые требуют преодоления серьезных технических трудностей, огромных затрат и адекватных организационных решений.
Системы оперативной обработки транзакций (online transaction processing — OLTP) позволяют накапливать большие объемы данных, ежедневно поступающих из пунктов продаж. Приложения OLTP, как правило, автоматизируют структурированные, повторяющиеся задачи обработки данных, такие как ввод заказов и банковские транзакции. Эти подробные, актуальные данные из различных независимых точек ввода объединяются в одном месте, и затем аналитики смогут извлечь из них значимую информацию. Агрегированные данные применяются для принятия каждодневных бизнес-решений — от управления складом до координации рекламных рассылок.
Компоненты систем поддержки принятия решений
Система поддержки принятия решений — сложная структура с многочисленными компонентами. Рассмотрим гипотетическую компанию Footwear Sellers Company, которая производит обувь и предлагает ее покупателям по каналам прямых продаж и через реселлеров. Руководителям отдела маркетинга FSC необходимо извлечь следующую информацию из агрегированных бизнес-данных:
- пять штатов, сообщивших о самых больших за последний год темпах роста объема продаж в категории продуктов для молодежи;
- общий объем продаж обуви в Нью-Йорке за последний месяц по различным видам продуктов;
- 50 городов с самым большим количеством индивидуальных клиентов;
- один миллион клиентов, которые, скорее всего, приобретут новую модель обуви Walk-on-Air.
Прежде чем создавать систему, которая предоставит такую информацию, в FSC должны рассмотреть и решить три основных вопроса:
- какие данные накапливать и как на концептуальном уровне моделировать данные и управлять их хранением;
- как анализировать данные;
- как эффективно загрузить данные из нескольких независимых источников.
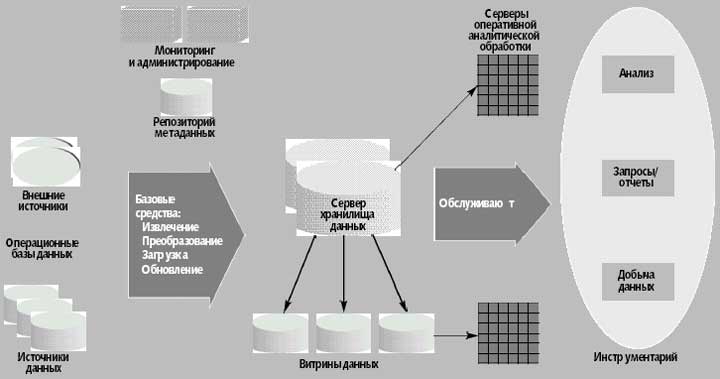
Как показано на рис. 1, эти вопросы можно соотнести с тремя основными компонентами системы поддержки принятия решений: сервер хранилища данных, инструментарий оперативной аналитической обработки и добычи данных и инструменты для пополнения хранилища данных.
|
|
Рис. 1. Архитектура систем поддержки принятия решений, которая состоит из трех основных компонентов: серверов хранилища данных, инструментария анализа и добычи данных и базовых средств хранилища данных
|
Хранилища данных (data warehouse) содержат информацию, собранную из нескольких оперативных баз данных. Хранилища, как правило, на порядок больше оперативных баз, зачастую имея объем от сотен гигабайт до нескольких терабайт. Как правило, хранилище данных поддерживается независимо от оперативных баз данных организации, поскольку требования к функциональности и производительности аналитических приложений отличаются от требований к транзакционным системам. Хранилища данных создаются специально для приложений поддержки принятия решений и предоставляют накопленные за определенное время, сводные и консолидированные данные, которые более приемлемы для анализа, чем детальные индивидуальные записи. Рабочая нагрузка состоит из нестандартных, сложных запросов, которые обращаются к миллионам записей и выполняют огромное количество операций сканирования, соединения и агрегирования. Время ответа на запрос в данном случае важнее, чем пропускная способность.
Поскольку конструирование хранилища данных — сложный процесс, который может занять несколько лет, некоторые организации вместо этого строят витрины данных (data mart), содержащие информацию для конкретных подразделений. Например, маркетинговая витрина данных может содержать только информацию о клиентах, продуктах и продажах и не включать в себя планы поставок. Несколько витрин данных для подразделений могут сосуществовать с основным хранилищем данных, давая частичное представление о содержании хранилища. Витрины данных строятся значительно быстрее, чем хранилище, но впоследствии могут возникнуть серьезные проблемы с интеграцией, если первоначальное планирование проводилось без учета полной бизнес-модели.
Инструментарий оперативной аналитической обработки и добычи данных позволяет проводить развернутый анализ информации. Базовые инструменты — средства извлечения, преобразования и загрузки — служат для пополнения хранилища из внешних источников данных.
Хранилище данных
Большинство хранилищ используют технологию реляционных баз данных, поскольку она предлагает надежные, проверенные и эффективные средства хранения и управления большими объемами данных. Важнейший вопрос, связанный с конструированием хранилищ данных, — архитектура базы данных, как логическая, так и физическая. Создание логической схемы корпоративного хранилища данных требует всеобъемлющего моделирования бизнеса.
Логическая архитектура базы данных
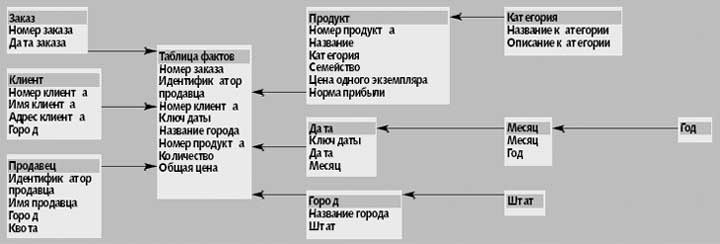
В архитектуре, основанной на схеме «звезда», база данных состоит из таблицы фактов, которая описывает все транзакции, и таблицы измерений для каждой из сущностей. В примере с FSC каждая транзакция охватывает несколько сущностей — клиент, продавец, продукт, заказ, дата сделки и город, где сделка состоялась. Каждая сделка также имеет параметры — в нашем случае число проданных экземпляров продукта и общая сумма, которую заплатил покупатель.
Каждый кортеж в таблице фактов состоит из указателя на каждый объект в транзакции и численные параметры, связанные с транзакцией. Каждая таблица измерений состоит из столбцов, которые соответствуют атрибутам объекта. Вычисление соединения между таблицей фактов и набором таблиц измерений — более эффективная операция, чем вычисление соединения произвольных реляционных таблиц.
Некоторые сущности, однако, связаны в иерархии, которые схема «звезда» корректно не поддерживает. Иерархия — это многоуровневая группировка, каждый уровень которой состоит из непересекающихся групп значений уровня, находящегося непосредственно ниже данного. Так, все продукты могут группироваться в непересекающееся множество категорий, которые, в свою очередь, сгруппированы в непересекающееся множество семейств.
Схема «снежинка» — усовершенствованная схема «звезда», в которой иерархия измерений представляется точным образом благодаря нормализации таблиц измерений. В «звезде», приведенной на рис. 2, набор атрибутов описывает каждое измерение и может быть связан иерархией отношений. Например, измерение продукта FSC состоит из пяти атрибутов: имя продукта (Running Shoe 2000), категория (спортивная), семейство продуктов (обувь), цена (80 долл.) и маржа (80%).
|
|
Рис. 2. Схема «снежинка» для гипотетической компании Footwear Sellers Company. Набор атрибутов описывает каждое измерение и связывается через иерархию отношений.
|
Физическая архитектура базы данных
Системы баз данных используют избыточные структуры, такие как индексы и материализованные представления для эффективной обработки сложных запросов. Определение самого подходящего набора индексов и представлений — это сложная задача формирования физической архитектуры. Хотя поиск в индексе и сканирование индекса могут быть эффективны для запросов, связанных с выбором данных, запросы, предполагающие интенсивную обработку данных, могут потребовать последовательного сканирования всей реляционной таблицы или ее вертикальных фрагментов. Увеличение эффективности сканирования таблиц и использование распараллеливания для уменьшения времени ответа на запрос — важные моменты, которые следует учитывать при проектировании физической архитектуры [1].
Индексные структуры
Методы обработки запросов, которые используют операции пересечения и объединения индексов, полезны при ответе на запросы с множественными предикатами. Пересечение индексов используется при выборке по нескольким условиям и может значительно снизить необходимость (или вообще устранить ее) в доступе к базовым таблицам, если все столбцы проекции можно получить посредством сканирования индексов.
Благодаря особой природе «звезды» соединение индексов детальных данных особенно удобно для систем поддержки принятия решений. Хотя индексы традиционно устанавливают соответствие значения в столбце списку строк с этим значением, соединенный индекс поддерживает связь между внешним ключом и соответствующими ему первичными ключами. В контексте схемы «звезда» соединенный индекс может связать значения одного или нескольких столбцов таблицы измерений с соответствующими строками таблицы фактов. Схема на рис. 2, к примеру, может поддерживать соединенный индекс по атрибуту «Город», который каждому городу ставит в соответствие список идентификаторов тех кортежей в таблице фактов, которые описывают продажи в данном городе. Важно подчеркнуть, что соединенный индекс предварительно вычисляет бинарное соединение.
Соединенные индексы по нескольким ключам могут представлять предварительно вычисленные n–кратные соединения. Например, многомерный соединенный индекс, созданный на основе базы данных продаж, может соединять Город.Название Города и Продукт.Название в таблице фактов. Элемент индекса для (Сиэтл, Running Shoe) указывает на идентификаторы записей в кортежах таблицы «Продажи» с такой комбинацией.
Материализованные представления
Многие хранилища данных используют запросы, которые требуют сводных данных и потому работают с агрегатами. Материализация сводных данных (т.е. их вычисление и сохранение) может ускорить обработку многих распространенных запросов. В примере с FSC два представления — общий объем продаж, сгруппированный по семейству продуктов и городу, и общее число клиентов, сгруппированное по городам, — могут эффективно применяться для ответов на три первых из четырех «главных» запросов отдела маркетинга (см. выше).
Задачи, которые возникают при использовании материализованных представлений, аналогичны тем, которые возникают при работе с индексами:
- определение представлений, которые следует материализовывать;
- использование материализованных представлений для ответа на запросы;
- обновление материализованных представлений при загрузке новых данных.
Поскольку использование этого механизма требует исключительно большого дискового пространства, в настоящее время применяются решения, которые поддерживают только ограниченный класс структурно простых материализованных представлений.
Оперативные аналитические приложения
В типичном оперативном аналитическом приложении запрос агрегирует численные параметры более высоких уровней в иерархию измерений. Пример — первый маркетинговый запрос FSC, для выполнения которого необходим набор агрегированных параметров — пять штатов, сообщивших о самом большом увеличении объема продаж в категории молодежных продуктов за последний год. «Штат» и «Год» — обобщения сущностей «Город» и «Дата».
Применительно к хранилищу данных FSC типичный сеанс OLAP, необходимый для определения региональных объемов продаж спортивной обуви в прошлом квартале, может выглядеть следующим образом.
- Аналитик выдает запрос select sum(sales) group by country («суммарный объем продаж для каждой страны»), чтобы просмотреть распределение объемов продаж спортивной обуви в последнем квартале по всем странам.
- После выбора страны с самым высоким или самым низким объемом продаж относительно размеров рынка, аналитик выдает второй запрос на вычисление сводного объема продаж в каждом штате данной страны, чтобы понять причины таких отклонений.
Аналитик движется вниз по иерархии, связанной с измерением «Город». Такой анализ сверху вниз по иерархии от самого обобщенного до самого детального уровня называется уточненным (drill-down). При операции обобщения (roll-up) аналитик поднимается на один уровень — скажем, от уровня штата до уровня страны — в иерархии измерений.
Ключевые вопросы, касающиеся OLAP, связаны с концептуальной моделью данных и серверными архитектурами.
Концептуальная модель данных
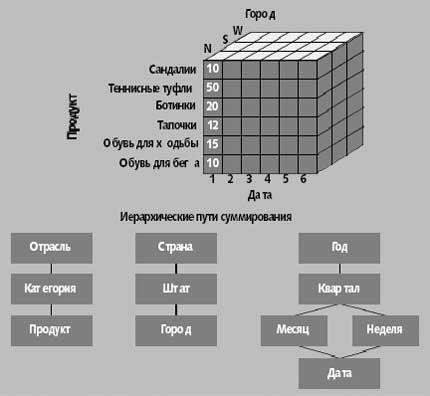
Многомерная модель, изображенная на рис. 3, использует численные параметры как объекты своего анализа. Каждый численный параметр в концептуальной модели данных зависит от измерений, которые описывают сущности в транзакции. Например, измерения, связанные с продажами в примере FSC, — это клиент, продавец, город, название продукта и дата совершения сделки. Все вместе измерения уникальным образом определяют параметр, поэтому многомерная модель данных трактует параметр как значение в многомерном пространстве.
|
|
Рис. 3. Пример многомерной базы данных
|
В многомерном представлении данных запросы drill-down и roll-up — это логические операции на кубе. Еще одна популярная операция — сравнить два параметра, которые агрегированы по одним и тем же измерениям, такими как продажи и бюджет.
OLAP-анализ может включать в себя более сложные статистические вычисления, нежели простые агрегаты, такие как сумма или среднее. Примером может служить такая функция, как изменение процента агрегата в определенный период по сравнению с различными периодами времени. Подобные дополнительные функции поддерживают многие коммерческие средства OLAP.
Измерение «Время» имеет особое значение для таких процессов поддержки принятия решений, как анализ тенденций. К примеру, аналитикам FSC может понадобиться проследить покупательскую активность в отношении спортивной обуви перед крупнейшими национальными легкоатлетическими соревнованиями или после них. Развернутый анализ тенденций возможен, если база данных поддерживает встроенную информацию о календаре и ряд других характеристик «Времени». OLAP Council (www.olapcouncil.org) определил перечень операций для многомерных кубов.
Архитектуры OLAP-серверов
Традиционные реляционные серверы не обеспечивают эффективное выполнение сложных OLAP-запросов и поддержку многомерных представлений данных. Но, тем не менее, три типа реляционных серверов баз данных — реляционной, многомерной и гибридной оперативной аналитической обработки — позволяют выполнять OLAP-операции в хранилищах данных, построенных с использованием систем управления реляционными базами данных.
Серверы ROLAP. Размещаются между основным реляционным сервером, где находится хранилище данных и клиентским инструментарием переднего плана. Серверы ROLAP поддерживают многомерные OLAP-запросы и, как правило, оптимизированы для конкретных реляционных серверов. Они указывают, какие представления должны быть материализованы, возможные запросы пользователей в терминах соответствующих материализованных представлений, и генерируют сложные SQL-серверы для основного сервера. Они также предусматривают дополнительные службы, такие как планирование запросов и распределение ресурсов. Серверы ROLAP наследуют возможности масштабирования и работы с транзакциями реляционных систем, однако существенные различия между запросами в стиле OLAP и SQL могут стать причиной низкой производительности.
Нехватка производительности становится менее острой, благодаря ориентированным на задачи OLAP расширениям SQL, реализованным в серверах реляционных баз данных наподобие Oracle, IBM DB2 и Microsoft SQL Server. Такие функции, как median, mode, rank, percentile дополняют агрегатные функции. К другим дополнительным возможностям относятся агрегатные вычисления на перемещающихся окнах, текущие сводные значения и точки прерывания для улучшенной поддержки формирования отчетов.
Многомерные электронные таблицы требуют группировки по различным наборам атрибутов. Для того чтобы удовлетворить эти требования Джим Грей и его коллеги [2] предлагают расширить SQL двумя операторами — roll-up и cube. Свертка списка атрибутов, включающего продукт, год и город, помогает находить ответы на вопросы, в которых фигурируют:
- группировка по продуктам, годам и городам;
- группировка по продуктам и годам;
- группировка по продуктам.
Пусть дан список из k столбцов, оператор cube предлагает группировку по каждой из 2**k комбинаций столбцов. Многочисленные операции «group by» могут быть выполнены эффективно за счет распознавания общих частей вычислений [3]. Разумно подобранные предварительные вычисления могут увеличить производительность серверов OLAP [4].
MOLAP. Серверная архитектура, которая не опирается на функциональность основных реляционных систем, но напрямую поддерживает многомерные представления данных с помощью многомерного механизма хранения. MOLAP позволяет реализовывать многомерные запросы на уровне хранения путем установки прямого соответствия. Основное преимущество MOLAP заключается в превосходных свойствах индексации; ее недостаток — низкий коэффициент использования дискового пространства, особенно в случае разреженных данных. Многие серверы MOLAP при работе с разреженными множествами данных используют двухуровневую организацию памяти и сжатие. При двухуровневой организации пользователь либо непосредственно, либо с помощью специальных инструментов проектирования, идентифицирует набор подмассивов, которые, скорее всего, будут плотными и представляет их в виде массива. Индексировать эти массивы меньшего размера можно с помощью традиционных индексных структур. Многие из методик, разработанных для статистических баз данных, подходят и для MOLAP. Серверы MOLAP обладают хорошей производительностью и функциональностью, но не в состоянии должным образом масштабироваться в случае очень больших баз данных.
HOLAP. Гибридная архитектура, которая объединяет технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда данные более менее плотные, серверы ROLAP лучше в тех случаях, когда данные довольно разрежены. Серверы HOLAP применяют подход ROLAP для разреженных областей многомерного пространства и подход MOLAP — для плотных областей. Серверы HOLAP разделяют запрос на несколько подзапросов, направляют их к соответствующим фрагментам данных, комбинируют результаты, а затем предоставляют результат пользователю. Материализация выборочных представлений в HOLAP, выборочное построение индексов, а также планирование запросов и ресурсов аналогично тому, как это реализовано в серверах MOLAP и ROLAP.
Добыча данных
Предположим, что FSC хочет начать кампанию по рассылке каталогов, на которую отводится бюджет не более 1 млн. долл. Учитывая это ограничение, аналитики отдела маркетинга хотят определить круг клиентов, которые, вероятнее всего, отреагируют на эту акцию и начнут делать покупки по каталогу. Инструментарий добычи данных предлагает необходимые для этого функции прогнозирования и анализа за счет определения шаблонов и характеристического поведения в пределах набора данных.
Обнаружение знаний (knowledge discovery) — процесс определения и достижения цели посредством итеративной добычи данных — как правило, состоит из трех этапов:
- подготовка данных;
- построение модели и ее оценка;
- применение модели.
Подготовка данных
На этапе подготовки данных аналитик готовит набор данных, содержащий достаточно информации, для того чтобы создать точные модели на последующих этапах. В случае с FSC, точная модель должна помочь прогнозировать, с какой вероятностью клиент купит продукты, рекламируемые в новом каталоге. Поскольку эти прогнозы основаны на факторах, потенциально влияющих на покупки клиентов, множество данных в модели будет включать в себя всех клиентов, отреагировавших на рассылаемые по почте каталоги за последние три года, их демографическую информацию, десять самых дорогих продуктов, которые приобрел каждый клиент, а также информацию о каталоге, послужившем стимулом для этих покупок.
Подготовка данных может включать в себя сложные запросы с объемными результатами. К примеру, подготовка множества данных FSC предусматривает соединение таблицы клиентов и таблицы продаж, а также выявление 10 самых дорогих покупок для каждого клиента. Все эти вопросы, касающиеся эффективной обработки запросов для поддержки принятия решения, одинаково актуальны в контексте добычи данных. Фактически, платформы добычи данных используют реляционные серверы или серверы OLAP для решения своих задач по подготовке данных.
Как правило, добыча данных включает в себя итеративно создаваемые модели на основе подготовленного множества данных, а затем применение одной или нескольких моделей. Поскольку создание моделей на больших множествах данных может оказаться весьма дорогостоящим, аналитики часто сначала работают с несколькими выборками множества данных. Платформы добычи данных, таким образом, должны поддерживать вычисления на случайно выбранных экземплярах данных в сложных запросах.
Построение и оценка моделей
Только после того, как принято решение о том, какую модель применять, аналитик создает модель на всем подготовленном множестве данных. Цель этого этапа создания модели — указать шаблоны, которые определяют целевой атрибут (target attribute). Пример целевого атрибута во множестве данных FSC: приобрел ли клиент хотя бы один продукт из предыдущего каталога.
Предсказать как точно указанные, так и скрытые атрибуты помогают несколько классов моделей добычи данных. На выбор модели влияют два важных фактора: точность модели и эффективность алгоритма для создания модели на больших множествах данных. С точки зрения статистики, точность большинства моделей увеличивается с ростом объема используемых данных, поэтому алгоритмы, на основе которых строятся модели добычи данных, должны быть эффективными и приемлемым образом масштабироваться при росте наборов обрабатываемых данных.
Типы моделей
Классификационные модели позволяют делать прогнозы. Для данного нового кортежа классификационные модели прогнозируют, принадлежит ли кортеж одному из набора целевых классов. В примере с каталогом FSC классификационная модель, основываясь на накопленных к текущему моменту данных, определяет, приобретет ли клиент товар из каталога. Деревья решений и простые байесовы модели — два самых популярных типа классификационных моделей [5-7].
Регрессионные деревья и логистическая регрессия — два самых распространенных типа регрессионных моделей, которые прогнозируют численные атрибуты, такие как зарплата или возраст клиента [5].
В некоторых приложениях аналитики точно не знают набора целевых классов и полагают их скрытыми. Модели кластеризации, подобные K-Means и Birch, используются для определения соответствующего множества классов и классификации нового кортежа с отнесением его к одному из этих скрытых классов [6, 7].
Модели на базе правил, в частности модель правил ассоциаций, используются, чтобы выяснить, является ли покупка конкретного набора предметов обуви, с определенной степенью уверенности, индикатором приобретения и другого продукта.
Дополнительные факторы при оценке моделей
Не существует одного класса моделей или алгоритма, которые позволили бы в любом случае создать идеальную модель для всех приложений. В силу этого платформы добычи данных должны поддерживать несколько типов построения моделей и предоставлять дополнительные средства для обеспечения расширяемости моделей и взаимодействия между ними.
В некоторых случаях аналитикам может потребоваться уникальная корреляционная модель, которую не поддерживает платформа добычи данных. Для этого платформы добычи данных должны быть расширяемыми.
Многие коммерческие продукты создают модели для конкретных областей применения, но реальная база данных, на которой должна применяться такая модель, возможно, будет работать с другим сервером баз данных. Платформы добычи данных и серверы баз данных, таким образом, должны поддерживать взаимозаменяемость моделей.
Недавно рабочая группа Data Mining Group (www.dmg.org) предложила воспользоваться Predictive Model Markup Language, стандартом на базе XML, для обмена рядом популярных классов моделей прогнозирования. Идея состоит в том, чтобы любая база данных, поддерживающая этот язык, могла импортировать и применять любую описанную на нем модель.
Применение модели
На этом этапе аналитики применяют выбранную модель к наборам данных, чтобы прогнозировать целевой атрибут с неизвестным значением. Для каждого текущего набора клиентов в примере FSC, прогноз касается того, будут ли они приобретать продукты из нового каталога. Применение модели на входном наборе данных может породить другой набор данных. В примере FSC этап применения модели указывает подмножество клиентов, которым будет разослан каталог.
Когда входной набор данных очень большой, стратегия применения модели должна быть достаточно эффективной. В этом случае может потребоваться использование индексов на входной таблице для фильтрации кортежей, которые не будут входить в развертываемый результат, но это требует более тесной интеграции между системами управления базами данных и применением модели.
Дополнительные вопросы OLAP и добычи данных
К другим важным вопросам в контексте OLAP и технологии добычи данных относятся пакетные приложения, платформы и их API-интерфейсы, влияние XML, приближенная обработка запросов, интеграция OLAP и добычи данных, а также добыча данных в Web.
Пакетные приложения
При разработке полного решения добычи данных аналитик должен выполнить серию сложных запросов и создать, настроить и применить сложные модели. Компенсировать разрыв между требованиями реального решения для хорошо понятных областей и поддержкой данной платформы добычи данных или OLAP, призваны несколько коммерческих инструментальных средств. Пакетные приложения и средства формирования отчетов могут использовать знания о конкретной вертикальной отрасли для упрощения задачи анализа путем учета специфических для отрасли абстракций более высокого уровня. Data Warehousing Information Center (www.dwinfocenter.org) и KDnuggets (www.kdnuggets.com) предлагают обширный список решений, ориентированных на конкретные отрасли.
Компании могут приобрести такие пакеты, а не разрабатывать свое собственное аналитическое решение, но пакеты, ориентированные на конкретную область применения, меняющиеся по мере развития бизнеса, ограничены по набору своих функций и потому не могут удовлетворить все потенциальные требования к анализу.
API-интерфейсы и влияние XML
Некоторые платформы OLAP и добычи данных предлагают API-интерфейсы, которые позволяют аналитикам создавать собственные решения. Однако поставщики решений, как правило, вынуждены писать специальные программы для различных платформ, чтобы предоставить не зависящее от платформ решение. Новые ориентированные на XML службы на базе Web обеспечивают общий интерфейс для механизмов OLAP. Компании Microsoft и Hyperion опубликовали XML for Analysis (www.essbase.com/downloads/ XML_Analysis_spec.pdf), API-интерфейс, основанный на протоколе SOAP, предназначенный специально для стандартизации взаимодействий при доступе к данным между клиентским приложением и источником данных, работающими через Web. На основе этой XML-спецификации поставщики решений смогут писать программы с помощью одного API-интерфейса, а не использовать множество интерфейсов, ориентированных на решения разных производителей.
Приближенная обработка запросов
Обработка сложных агрегатных запросов, как правило, требует обращения к огромным объемам данных. Например, вычисление среднего объема продаж FSC в различных городах требует сканирования всех данных в хранилище. Во многих случаях, однако, очень быстро и достаточно точную оценку позволяет получить приближенная обработка запросов. Идея состоит в том, чтобы на основе базовых данных максимально точно сформировать сводные данные, а затем получать ответы на агрегатные запросы с помощью этих сводных, а не полных данных. Дополнительную информацию по этому вопросу можно найти в описании проектов Approximate Query Processing (www.research.microsoft.com/dmx/ApproximateQP) и AQUA Project (www.bell-labs.com/project/aqua).
Интеграция OLAP и добычи данных
OLAP-инструментарий помогает аналитикам выявить актуальные порции данных, а модели добычи данных обогащают эту функциональность. Например, если темпы роста объема продаж FSC не соответствуют прогнозируемым, специалисты по маркетингу хотели бы знать аномальные регионы и категории продуктов, для которых не выполняются заданные показатели. Пробный анализ, который выявляет аномалии, использует методику, позволяющую отметить агрегатный параметр на более высоком уровне в иерархии измерений с аномальным результатом. Аномальный результат определяет общее отклонение реальных агрегатных величин от соответствующих прогнозируемых значений над всеми своими потомками [8, 9]. Для вычисления прогнозируемых значений аналитики могут использовать такие средства добычи данных, как регрессионные модели.
Добыча данных в Web
Большинство крупных компаний поддерживают Web-сайты, где клиенты могут просмотреть информацию, запросить данные о товарах и приобрести их. Поскольку каждый клиент имеет личный контакт с компанией через Web-сайт, компании могут персонифицировать работу с ним. Например, сайт может рекомендовать клиенту продукты, услуги или статьи, относящиеся к области его интересов. Одной из первых такие персонифицированные системы начала развертывать компания Amazon.com.
При создании таких Web-систем возникают два важных вопроса: сбор данных и методы персонификации. Анализ данных регистрации, автоматически накапливаемых данных о поведении клиента на Web-сайте, позволяет выявить привычки предпочтения клиентов. Анализ такого рода позволит FSC предложить специальные спортивные носки клиентам, покупающим обувь. Модели добычи данных могут использовать подобную информацию о поведении клиента, особенно, когда она сочетается с данными, которые клиенты вводят при регистрации или оплате, чтобы персонифицировать посещаемые клиентами Web-страницы и снабдить их соответствующей рекламой. Со временем, по мере роста числа пользователей, компания может рекомендовать дополнительные продукты, учитывая схожесть предпочтений клиентов.
Инструментарий хранилищ данных
Создание хранилища данных из независимых источников данных — многоэтапный процесс, который предусматривает извлечение данных из каждого источника, преобразование их в соответствии со схемой хранилища данных, очистку, а затем загрузку в хранилище. Data Warehousing Information Center опубликовал обширный список инструментальных средств ETL (extract, transform, load — «извлечение, преобразование, загрузка»), выполняющих эту последовательность операций.
Извлечение и преобразование
Цель этапа извлечения данных — перенести данные из разнородных источников в базу данных, где их можно модифицировать и добавить в хранилище. Цель последующего этапа преобразования данных — устранить несоответствия в схеме и соглашениях о значениях атрибутов. Набор правил и скриптов, как правило, выполняет преобразование данных из исходной схемы в итоговую схему.
К примеру, дистрибьютор может разделить имя каждого клиента на три части: имя, отчество (или инициалы) и фамилия. Чтобы добавить предоставленную дистрибьютором информацию о продажах в хранилище FSC, схема которого показана на рис. 2, аналитик сначала должен извлечь записи, а затем, для каждой записи, преобразовать все столбцы с соответствующими тремя частями имени, чтобы получить значение для атрибута «Имя клиента».
Очистка данных
Ошибки при вводе данных и различия в схемах могут привести к тому, что таблица измерений «Клиент» будет иметь несколько соответствующих кортежей для одного клиента, что приводит к неточным ответам на запросы и некорректным моделям добычи данных. К примеру, если таблица клиентов содержит по несколько кортежей для некоторых клиентов FSC в Нью-Йорке, то Нью-Йорк может ошибочно попасть в список первых 50 стран с самым большим числом индивидуальных клиентов. Инструменты, которые помогают определить и исправить аномалии данных, могут иметь высокую отдачу; значительное число исследований посвящено проблемам устранения дублирования [10] и инструментам очистки данных [11].
Загрузка
После того, как данные извлечены и преобразованы, возможно, что их еще необходимо дополнительно обработать перед тем, как добавить в хранилище. Как правило, утилиты фоновой загрузки поддерживают такие функции, как проверка ограничений целостности; сортировка; суммирование, агрегирование и выполнение других вычислений для создания производных таблиц, размещаемых в хранилище; создание индексов и других способов доступа. Помимо наполнения хранилища, утилита загрузки должна позволять системным администраторам проверять статус; отменять, приостанавливать и возобновлять загрузку; возобновлять работу после ошибки без потери целостности данных. Поскольку утилиты загрузки для хранилищ данных обрабатывают значительно больше данных, чем содержится в транзакционных системах, они используют разного рода алгоритмы распараллеливания [1].
Обновление
Обновление хранилища данных состоит в распространении обновлений на исходные данные, которые соответственным образом обновляют базовые таблицы и производные данные, материализованные представления и индексы, размещенные в хранилище. Должны быть рассмотрены два вопроса: когда обновлять и как обновлять.
Обычно хранилища данных обновляются периодически в соответствии с заранее установленным расписанием, например, ежедневно или еженедельно. Распространять каждое обновление необходимо только в том случае, если для выполнения OLAP-запросов требуются текущие данные. Администраторы хранилища данных определяют правила обновления в зависимости от требований пользователей и трафика. Расписание обновлений может быть различным для разных источников данных. Администратор должен выбрать циклы обновления таким образом, чтобы накладные расходы, вызванные обработкой больших объемов данных, не превысили расходы на выполнение утилиты инкрементальной загрузки. Большинство коммерческих инструментов используют инкрементальную загрузку при обновлении с тем, чтобы сократить объем данных, добавляя только измененные кортежи, если, конечно, источники данных позволяют извлекать соответствующие фрагменты данных. Однако процесс инкрементальной загрузки может оказаться сложным в управлении, поскольку изменения должны быть скоординированы с текущими транзакциями.
Управление метаданными
Метаданные — информация любого рода, которая требуется для управления хранилищем данных, а управление метаданными — существенный компонент архитектуры хранения. К административным метаданным относится вся информация, которая требуется для настройки и использования хранилища данных. Бизнес-метаданные включают в себя бизнес-термины и определения, принадлежность данных и правила оплаты услуг хранилища. Оперативные метаданные — это информация, собранная во время работы хранилища данных, такая как происхождение перенесенных и преобразованных данных; статус использования данных (активные, архивированные или удаленные); данные мониторинга, такие как статистика использования, сообщения об ошибках и результаты аудита. Метаданные хранилища часто размещаются в репозитории, который позволяет совместно использовать метаданные различным инструментам и процессам при проектировании, установке, использовании, эксплуатации и администрировании хранилища.
Согласованные усилия коммерческих компаний и научных кругов привели к серьезному технологическому прогрессу в решении задач хранения данных. Это нашло отражение во множестве коммерческих продуктов, которые доступны для каждой из трех основных операций: пополнение хранилища данных из независимых транзакционных систем; хранение данных и управление ими; анализ данных с целью принятия обоснованных бизнес-решений. Однако, несмотря на изобилие коммерческого инструментария, остается еще несколько важных направлений для исследования.
Очистка данных связана с интеграцией данных из неоднородных источников, проблемой, которую изучают уже много лет. На сегодняшний день основные усилия концентрируются на проблемах несогласованности данных, а не на проблемах несогласованности схем. Хотя очистка данных в последнее время привлекает большое внимание исследователей, предстоит еще немало сделать для создания инструментальных средств, не зависящих от предметной области, которые решают разнообразные проблемы очистки данных, связанные с разработкой хранилищ.
Большая часть исследований в области добычи данных касается разработки алгоритмов для создания более точных моделей или алгоритмов, позволяющих ускорить этот процесс. Два других этапа процесса выявления знаний — подготовка данных и применение модели добычи данных — по большей части игнорируются. На обоих этапах возникает несколько проблем, в частности, связанных с достижением большей гармонии между системами управления базами данных и технологией добычи данных. В конечном итоге, новые инструментальные средства должны дать аналитикам более эффективные способы подготовки наборов данных, отвечающих конкретной цели, и более эффективные способы применения моделей к результатам произвольных SQL-запросов.
Литература
- T. Barclay et al., «Loading Databases Using Dataflow Parallelism», SIGMOD Record, Dec. 1994
- J. Gray et al., «Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub Totals», Data Mining and Knowledge Discovery J., Apr. 1997
- S. Agrawal et al., «On the Computation of Multidimensional Aggregates», Proc. VLDB Conf., Morgan Kaufmann, San Francisco, 1996
- V. Harinarayan, A. Rajaraman, J.D. Ullman, «Implementing Data Cubes Efficiently», Proc. SIGMOD Conf., ACM Press, New York, 1996
- L. Breiman et al., Classification and Regression Trees, Chapman & Hall/CRC, Boca Raton, Fla., 1984
- V. Ganti, J. Gehrke, R. Ramakrishnan, «Mining Very Large Data Sets», Computer, Aug. 1999
- J. Han, M. Kamber, Data Mining: Concepts and Techniques, Morgan Kaufmann, San Francisco, 2001
- S. Sarawagi, «User Adaptive Exploration of OLAP Data Cubes», Proc. VLDB Conf., Morgan Kaufmann, San Francisco, 2000
- J. Han, «OLAP Mining: An Integration of OLAP with Data Mining», Proc. IFIP Conf. Data Semantics, Chapman & Hall/CRC, Boca Raton, Fla., 1997
- M. Hernandez, S. Stolfo, «The Merge/Purge Problem for Large Databases», Proc. SIGMOD Conf., ACM Press, New York, 1995
- H. Galhardas et al., «Declarative Data Cleaning: Model, Language, and Algorithms,» Proc. VLDB Conf., Morgan Kaufmann, San Francisco, 2001
Сураджит Чаудхури (surajitc@microsoft.com) — ведущий научный сотрудник и менеджер группы Data Management, Exploration, and Mining Group исследовательского подразделения Microsoft Research. К области его научных интересов относятся самонастраивающиеся системы управления базами данных, системы поддержки принятия решений, а также интеграция текстовой, реляционной и полуструктурированной информации.
Умешвар Дайал (dayal@hpl.hp.com) — старший научный сотрудник лаборатории Hewlett-Packard Laboratories. Он занимается вопросами добычи данных, управления бизнес-процессами, управления распределенной информацией и технологий поддержки принятия решений, особенно в применении к электронному бизнесу.
Венкатеш Ганти (vganti@microsoft.com) — научный сотрудник группы Data Management, Exploration, and Mining Group исследовательского подразделения Microsoft Research. К области его научных интересов относятся добыча данных и мониторинг больших эволюционирующих множеств данных, а также системы поддержки принятия решений.
Модели добычи данных могут использовать накопленную информацию о поведении клиента для того, чтобы выполнять персонификацию Web-страниц, которые видит клиент.
Специальные решения для конкретных отраслей ограничены по своим функциям, и они не могут удовлетворить все требования к анализу, выдвигаемые предприятием по мере развития его бизнеса.
Требуется еще немало сделать для создания не зависящих от конкретной предметной области инструментальных средств, которые решают проблемы очистки данных, связанные с развитием хранилищ данных.
Surajit Chaudhuri, Umeshwar Dayal, Venkatesh Ganti, Database Technology for Decision Support Systems. IEEE Computer, December 2001. Copyright IEEE Computer Society, 2001. All rights reserved. Reprinted with permission.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС