2015 г.
Что сулит будущее?
Сергей Кузнецов
Обзор январского 2014 г. номера журнала Computer (IEEE Computer Society, V. 47, No 1, январь, 2014).
Авторская редакция.
Также обзор опубликован в журнале «Открытые системы»
По традиции темой январского номера являются «Перспективы» (Outlook). По той же традиции тематическая подборка готовится без приглашенного редактора.
Кэрин Страусс и Дуг Бургер (Karin Strauss, Doug Burger, Microsoft Research) написали статью «Что сулит будущее твердотельной памяти?» («What the Future Holds for Solid-State Memory»).
Феноменальный рост компьютерной индустрии в последние десятилетия был бы невозможен без постоянного повышения плотности микросхем запоминающих устройств. Однако возрастающие потребности приложений относительно объема и качества памяти приводят к появлению множества проблем. При разработке технологий памяти (как оперативной памяти, в частности, DRAM, так и внешней памяти, в частности, флэш-памяти) полупроводниковая индустрия стремилась обеспечить стабильность, точность и постоянную корректность. Однако при повышающейся плотности микросхем требуется все большее число механизмов, позволяющих компенсировать сбои. Поддержка «постоянной корректности» оказывается настолько трудной и дорогостоящей, что, по-видимому, от нее придется отказаться с соответствующими последствиями для разработчиков программного обеспечения. В статье обсуждаются некоторые проблемы, которые потребуется решить, чтобы можно было продолжать повышать плотность микросхем памяти. Предсказывается переход к использованию все более неоднородных иерархий памяти (включая специализированные запоминающие устройства), что приведет к потребности в новых видах взаимодействия аппаратных и программных средств, существенным изменениям приложений, средств разработки и поддержки системного программного обеспечения.
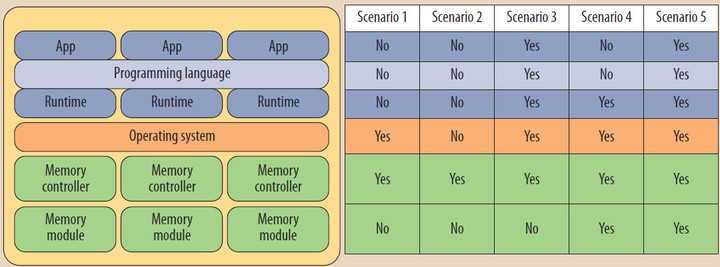
Рис. 1. Пять сценариев использования некоторой гипотетической системы; уровни системы (слева), затрагиваемые в каждом сценарии. В первом сценарии операционная система отвечает за распределение памяти трех типов, у каждого из которых имеются свои достоинства и недостатки. Второй сценарий показывает, что для защиты сохраненных данных от атак холодной перезагрузки (cold-boot attack) могут потребовать изменения в контроллере памяти. Третий сценарий демонстрирует, что для поддержки долговременно хранимых данных на основе их загрузки и выгрузки в обычное адресное пространство приложения потребуются изменения в нескольких уровнях системы. Сценарий 4 показывает, что наличие постоянных сбоев может влиять на несколько уровней системы. Наконец, пятый сценарий демонстрирует уровни, на которые влияет перекладывание ответственности за нахождение компромисса между производительностью и надежностью на программистов.
Авторами статьи «Компьютерам хватит энергии радиоэфира» («The Emergence of RF-Powered Computing») являются Шиамнат Голлакота, Мэттью Рейнольдс, Джошуа Смит и Дэвид Уэзеролл (Shyamnath Gollakota, Matthew S. Reynolds, Joshua R. Smith, David J. Wetherall, University of Washington).
Расширению областей применения мобильных компьютерных устройств, в частности, переходу к практическому использованию «Интернета вещей» мешает потребность этих устройств в специальных механизмах питания. Шнуры питания лишают возможности свободно перемещать устройства, батареи увеличивают вес, объем и стоимость устройств, оказывают негативное влияние на экологию. Однако все более реальной является возможность использования для питания небольших компьютерных устройств энергии случайных радиосигналов. Конечно, от типичного радиосигнала можно получить только очень небольшую мощность. Но и энергоэффективность самих компьютеров возрастает экспоненциально (малоизвестное следствие закона Мура). В настоящее время при небольших вычислительных нагрузках для питания компьютерных устройств достаточно мощности порядка микроватта, что соизмеримо с мощностью, которую можно получить от радиосигналов.
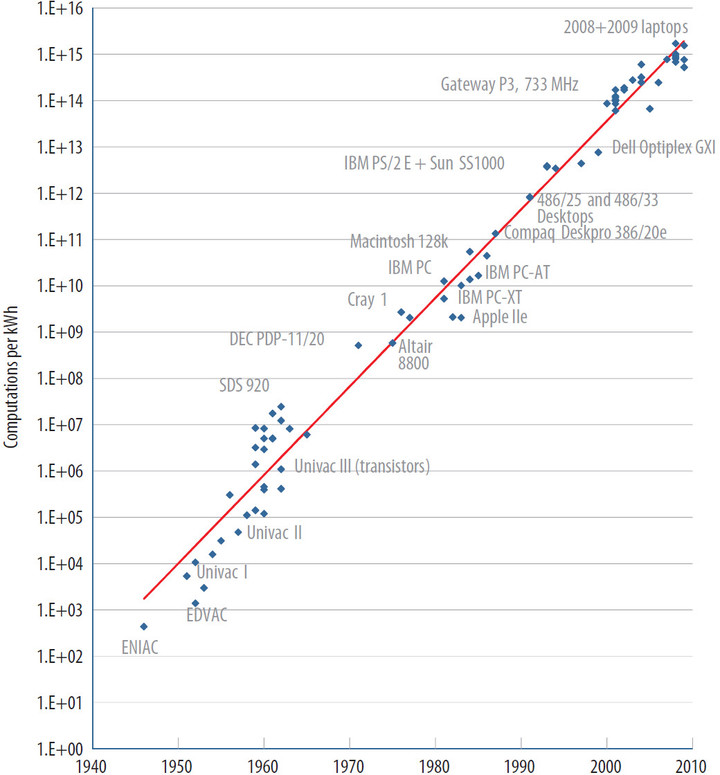
Рис. 2. В период от 1950 до 2010 гг. эффективность энергопотребления компьютеров выросла на 12 порядков
Статья «Обеспечение возможности быстрой разработки и внедрения речевых пользовательских интерфейсов» («Enabling the Rapid Development and Adoption of Speech-User Interfaces») представлена Ануджем Кумаром, Флорианом Меце и Мэттью Кэмом (Anuj Kumar, Florian Metze, Carnegie Mellon University, Matthew Kam, American Institutes for Research).
Хотя пользовательские интерфейсы на основе речевого ввода/вывода полезны и востребованы обществом, количество работоспособных и достаточно точных служб распознавания речи все еще невелико. В основном это связано с наличием двух проблем. Во-первых, от полезного распознавателя речи требуется возможность оптимизации для каждой группы пользователей, каждого языка и конкретных акустических условий. Эта задача обычно пугает разработчиков. Во-вторых, наибольшую выгоду приложения, связанные с распознаванием речи, приносят в мобильных телефонах, а для современных мобильных служб распознавания речи требуется надежное подключение к сети. В своей статье авторы описывают разработанный ими инструментарий, который позволяет встраивать экспертные знания в приложения распознавания речи, а также новую модель систем распознавания речи для мобильных устройств, которая устраняет потребность в надежном подключении к сети.
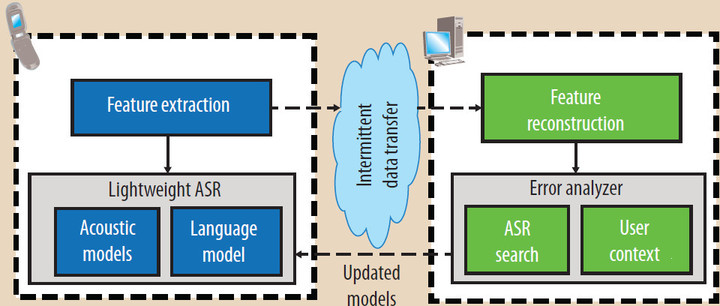
Рис. 3. Гибридный подход. Автоматическое распознавание речи производится в локальном мобильном устройстве, где имеется настройка на специфику пользователя и контекста, производимая при наличии соединения с сервером.
Статью «Будущее социального обучения в области программной инженерии» («The Future of Social Learning in Software Engineering») написал Эмерсон Мерфи-Хилл (Emerson Murphy-Hill, North Carolina State University).
Для удовлетворения возрастающих требований к корректности, надежности и безопасности программного обеспечения его разработчикам нужно постоянно повышать свою квалификацию. Для этого нужно уметь получать и новые фундаментальные знания, которые будут полезны в будущей работе, и краткосрочную информацию, помогающую решать текущие задачи. Подобную информацию естественнее и проще всего можно получить в процессе социального обучения (social learning). В контексте инженерии программного обеспечения социальное обучение понимается как использование опыта разработки ПО для упрощения текущей работы других разработчиков. В ходе социального обучения могут использоваться разные методы, но общая последовательность выглядит следующим образом.
- Специалисты решают некоторую задачу, связанную с разработкой ПО.
- Информация об этой задаче фиксируется, хотя бы всего лишь в памяти.
- Позже другой специалист решает или планирует решить новую задачу, связанную с разработкой ПО.
- Элементы этой новой задачи сопоставляются с данными о ранее решавшихся задачах.
- Из этих данных извлекается релевантная информация, и она предоставляется специалисту, решающему новую задачу, в виде рекомендаций, позволяющих облегчить эту работу.
Хотя эта последовательность повторяется в любой ситуации, применяемые методы зачастую различны, и именно эти методы обозреваются в статье.
Последняя статья тематической подборки называется «Социальный геном: применение больших данных в информатике населения» («Social Genome: Putting Big Data to Work for Population Informatics») и представлена Хай-Чун Камом, Ашоком Кришнамурти, Ашвином Мачанавадхала и Стенли Ахалтом (Hye-Chung Kum, Texas A&M Health Science Center, Ashok Krishnamurthy, University of North Carolina at Chapel Hill, Ashwin Machanavajjhala, Duke University, Stanley C. Ahalt, University of North Carolina at Chapel Hill).
В наше время за каждым человеком тянется «цифровой след»: данные об изменении состояния здоровья, размера заработной платы и т.д. Если собрать эти цифровые трассы для групп населения (в масштабе города, области или страны), они образуют социальный геном (social genome) населения. Должные интеграция, анализ и интерпретация данных социальных геномов могут помочь понять, как лучше всего можно удовлетворить потребности общества в областях здравоохранения, экономики, образования и т.д. Использование «больших данных» стимулировало развитие многих областей – от климатологии и биоинформатики до бизнес-аналитики. Однако проблемы, связанные с потребностью поддержки конфиденциальности данных, особенностями доступа к данных, их интеграции и управления ими, пока позволяют использовать в областях общественных наук, здравоохранения и т.д. только микроданные (данных об отдельных людях). Крупные базы данных используются редко. Совершенствование возможностей анализировать крупные коллекции данных, включающие данные об отдельных людях, является не только интересным исследовательским направлением. Результаты могут способствовать формированию эффективных политик принятия решения и управления социальными программами. Данные социальных геномов могут обеспечить информацию о жизни людей, позволить правильно реагировать на изменения и принимать решения.
Вне тематической подборки опубликована статья Паоло Монтуски и Альфредо Бенсо (Paolo Montuschi, Alfredo Benso, Polytechnic University of Turin) «Дополненное чтение: настоящее и будущее электронных научных публикаций» («Augmented Reading: The Present and Future of Electronic Scientific Publications»).
Постоянное ускорение процессов получения новых исследовательских результатов и данных, разработка все более быстрых и масштабных средств распространения информации приводят к потребности пересмотра понятия «научная публикация». Во-первых, нужно искать новые способы совместного использования исследовательских данных, которые позволят более полно понять смысл соответствующих публикаций. Во-вторых, требуется научиться надежно фильтровать эти данные, чтобы читатели могли эффективно обращаться к тем данным, которые соответствуют их потребностям и интересам. В-третьих, простота публикаций в расчете на использование электронных книг и планшетов лишает финансовой привлекательности применение традиционных бумажных технологий. В 2010 г. авторы статьи предложили термин «дополненное чтение», имея в виду тему исследований, а не некоторую конкретную технологию. Целью этого направления является выявление новых парадигм доставки научного контента с использованием технологий, основанных на когнитивных моделях, учете человеческих и социальных факторов, требований эргономики. Оптимальные режимы реализации подхода зависят как от имеющихся технологий и платформ, так и от особенностей публикуемых идей и данных. В своей статье авторы обсуждают, каким образом концепция дополненного чтения может изменить процессы планирования, написания и доставки научных публикаций, какие новые способы распространения знаний обеспечивают электронные публикации.

Рис. 4. Вехи развития электронного издательства в Computer Society.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС