2015 г.
Тысячи ядер: когерентность кэшей
Сергей Кузнецов
Обзор октябрьского, 2013 г. номера журнала Computer (IEEE Computer Society, V. 46, No 10, октябрь 2013).
Авторская редакция.
Также обзор опубликован в журнале «Открытые системы»
Октябрьский номер журнала посвящен проблеме когерентности кэшей в современных многоядерных процессорах. Этой теме посвящены четыре крупных статьи. Приглашенным редактором тематической подборки является Сринивас Девадас (Srinivas Devadas, MIT). Его вводная заметка называется «На пути к модели когерентной памяти для многоядерных процессоров» («Toward a Coherent Multicore Memory Model»).
В последнее десятилетие ограничения теплоотдачи приостановили повышение тактовой частоты процессоров. Но плотность транзисторов продолжает возрастать, и в настоящее время на рынке процессоров общего назначения не редки процессоры с восемью и даже большим числом ядер. Для дальнейшего повышения производительности и более эффективного использования перспективными представляются архитектуры многоядерных процессоров среднего и крупного масштаба. Примерами соответствующих академических разработок являются Raw, TRIPS и the Execution Migration Machine, а в индустрии известны архитектуры компании Tilera, проекты Intel TeraFLOPS и Intel Phi. Эксперты предсказывают появление в ближайшие 10 лет процессоров более чем с 1000 ядер.
Однако можно ли будет программировать для этих процессоров с громадным числом ядер? Хотя архитектуры с моделями ограниченного доступа к памяти (большей частью графические процессоры) очень успешно используются в конкретных приложениях (например, в области визуализации), большинство программистов предпочитает модель общей памяти, и в коммерческих многоядерных процессорах поддерживается именно эта модель.
Основной вопрос состоит в том, каким образом можно обеспечить когерентную общую память при наличии сотен или даже тысяч ядер? В каждом из этих ядер обычно будут иметься кэши первого и второго уровней, поскольку требования к энергопитанию кэша возрастают в квадратичной зависимости от его размера. Следовательно, единственным путем к реализации крупного кэша является его физическое распределение по кристаллу, чтобы каждое ядро располагалось поблизости от некоторой части кэша.
Для обеспечения удобства программирования ядра должны поддерживать единое адресное пространство, а в целях обеспечения эффективности это пространство должно автоматически управляться на аппаратном уровне. Для поддержки общей памяти должна поддерживаться когерентность кэшей первого уровня (а также второго уровня, если кэши второго уровня являются частными кэшами ядер). Применение протоколов поддержки когерентности кэшей, используемых при наличии малого числа ядер (например, четырех), оказывается невозможным в многоядерных архитектурах из-за накладных расходов на сериализацию. Еще одна трудность следует из невозможности дальнейшего масштабирования традиционных сетей шинных и перекрестных соединений (из-за ограничений пропускной способности и доступной площади). Вместо этого во многих многоядерных мультипроцесорах используется «плиточная» (tiled) архитектура, в которой массивы «плиток» связываются каждый с каждым общей сетью соединений кристалла.
При наличии числа ядер, при котором не работают шинные механизмы, традиционным подходом к обеспечению общей памяти является поддержка когерентности на основе использования справочников. При этом подходе логически центральный справочник координирует совместное использование частных кэшей ядер, а каждое ядро должно согласовывать возможность совместного (только по чтению) или монопольного (по чтению и записи) доступа к каждому кэшу на основе протокола поддержки когерентности. Однако и при использовании справочников возникают проблемы. В частности, поддержка когерентности может порождать значительный трафик, приводящий к возрастанию задержек, перегрузке соединений и повышению уровня энергопотребления.
Первую регулярную статью тематической подборки под названием «Влияние динамических справочников на сеть соединений многоядерных процессоров» («The Impact of Dynamic Directories on Multicore Interconnects») представили Абхишек Дас, Мэттью Шушард, Никос Хардавеллас, Гохан Мемик и Алок Чоудхари (Abhishek Das, Intel, Matthew Schuchhardt, Nikos Hardavellas, Gokhan Memik, Alok Choudhary, Northwestern University).
Для борьбы с внутрикристальными проводными задержками, увеличивающимися по мере роста числа ядер и размеров кэшей, архитектуры многоядерных процессоров делаются более распределенными. Например, в процессорах Intel Xeon Phi и Tilera TILE-Gx внутрикристальный кэш верхнего уровня разделяется на несколько частей, распределенных по кристаллу вместе с ядрами. Для поддержки передачи данных и коммуникаций между ядрами в таких процессорах используется сложная внутрикристальная сеть соединений, потребляющая 10-28% всей энергии, которая питает многоядерный процессор. При дальнейшем росте числа ядер эта доля будет только возрастать.
Для сокращения этого энергопотребления в последнее время был предложен ряд схемотехнических методов, повышающих эффективность энергопотребления схем соединений и маршрутизирующей микроархитектуры, обеспечивающих динамическое масштабирование напряжения и управление питанием и поддерживающих маршрутизацию с учетом температурных характеристик. Однако в этих работах не учитывается, что значительная часть внутрикристального трафика порождается пакетами, используемыми для поддержки когерентности данных, а не пакетами, передающими совместно используемые данные.
Требование когерентности появляется из-за оптимизации производительности доступа к данным. Для обеспечения более быстрого доступа части распределенного кэша часто обрабатываются как частные кэши соседних ядер. В результате образуются «плитки», каждая из которых содержит ядро и часть кэша. Когерентность данных в этих кэшах поддерживается на основе протокола когерентности с использованием распределенного справочника, адреса в котором чередуются между плитками. Однако в этом чередовании адресов не учитываются доступы к данным и паттерны их совместного использования. Часто случается так, что блок кэша отображается в часть справочника в плитке, которая физически удалена от ядер, обращающихся к соответствующим данным. Для обеспечения совместного использования блока кэша ядра должны много раз проходить по сети соединений кристалла для общения со справочником вместо того, чтобы общаться напрямую. Эти излишние проходы порождают дополнительный трафик и увеличивают энергопотребление.
Учитывая наличие этого недостатка, компания Tilera в своем процессоре TILEPro64 реализовала механизм, способствующий сокращению трафика по причине общения со справочником за счет того, что программное обеспечение получает возможность назначать каждой странице кэша «домашнюю» плитку. Этот метод похож на метод динамических справочников, где аппаратура вместе с операционной системой устраняет потребность в размещении элементов справочника в предопределенных плитках. Хотя в TILEPro64 поддерживается механизм размещения, компания Tilera не выступает в поддержку какой-либо конкретной политики размещения. Кроме того, неизвестны публикации, в которых бы оценивалась эффективность этого метода.
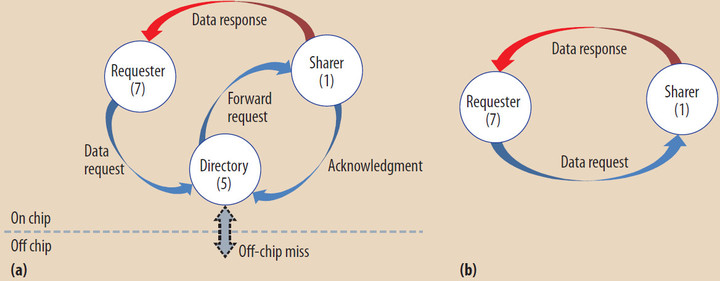
Трафик совместного использования данных в основных архитектурах многоядерных процессоров. (a) Поток пакетов в случае, когда плитка №7 запрашивает данные из блока, которым владеет плитка №5. (b) Поток пакетов в случае, когда каталог размещается вместе с данными.
Авторы статьи оценивают влияние динамических справочников на производительность многоядерных процессоров и энергопотребление. Демонстрируется эффективность метода при использовании простой политики замещения элементов справочника, когда эти элементы располагаются поблизости от ядер, наиболее активно совместно использующих соответствующие блоки кэша.
Следующая статья написана Арвиндт Шрираман, Хонжу Жао и Сандхия Дваркадас (Arrvindh Shriraman, Simon Fraser University, Hongzhou Zhao, Sandhya Dwarkadas, University of Rochester) и называется «Ориентированный на приложения подход к аппаратной поддержке когерентности кэшей» («An Application-Tailored Approach to Hardware Cache Coherence»).
Проектировщики микропроцессоров продолжают искать способы поддержки модели когерентной памяти при постоянном возрастании числа ядер и специализированных ускорителей. Обычно аппаратная реализация когерентности кэша при наличии многочисленных ядер и ускорителей значительно усложняет и удорожает архитектуру. Поэтому во многих графических и многоядерных процессорах (например, в Intel Single-Chip Cloud Computer) используется технология управления сверхбыстродействующей памятью, требующая программно-управляемого перемещения и хранения данных.
Ни один из этих подходов не обеспечивает явного выигрыша в производительности. С одной стороны, аппаратная поддержка когерентности кэша связана с накладными расходами на хранение метаданных, поддержкой дополнительного трафика во внутрикристальной сети соединений, соответствующим ростом энергопотребления и коммуникационными задержками. Эти расходы обычно возрастают с ростом числа ядер и потенциального объема кэшируемых данных. С другой стороны, любое преимущество программного управляемого кэша может происходить только из возможности приспосабливаться под особенности конкретных приложений, а вовсе не из того, что при этом устраняется потребность в аппаратной поддержке когерентности. Теоретически, можно было бы обеспечить настройку под особенности приложений и при аппаратной реализации.
Тем не менее, от потребности поддержки внутрикристальной когерентности кэша никуда не денешься, и авторы полагают, что накладные расходы аппаратной поддержки когерентности связаны не с родовыми свойствами модели, а с желанием архитекторов обеспечить гарантии когерентности в худшем случае и с жесткостью имеющихся аппаратных реализаций. Правильно разработанный протокол поддержки когерентности позволяет избежать излишних коммуникаций с тем, чтобы и управляющие сообщения, и пересылки данных соответствовали поведению выполняемого приложения. В то же время такой протокол не должен приводить к потребности хранения излишних метаданных.
Авторы предлагают приспосабливаемый к особенностям приложений подход к аппаратной поддержке когерентности кэшей в процессорах с большим числом ядер. Этот подход позволяет сократить накладные расходы на хранение метаданных, а также на обеспечение трафика, требуемого для поддержки когерентности, без потребности в соответствующем программном обеспечении. Предлагаемую стратегию можно применить для повышения эффективности системы при аппаратной или программной реализации любого протокола поддержки когерентности. Основная идея состоит в том, что учитываются особенности доступа к памяти и совместному ее использованию нитей параллельных приложений, выполняемых в разных ядрах. Это позволяет протоколам поддержки когерентности масштабироваться к возрастающему количеству ядер.
Авторами статьи «Однотактный многопрыжковый асинхронный повторяющийся обход: будущее внутрикристальных сетей с использованием подхода SMART» («Single-Cycle Multihop Asynchronous Repeated Traversal: A SMART Future for Reconfigurable On-Chip Networks») являются Тушар Кришна, Чиа-Син Овен Чен, Сонхен Пак, Ву-Чел Кон, Сувинай Субраманиан, Ананта Чандракасан и Ли Чиуан Пе (Tushar Krishna, Chia-Hsin Owen Chen; Sunghyun Park, Woo-Cheol Kwon, Suvinay Subramanian, Anantha P. Chandrakasan, Li-Shiuan Peh, MIT).
В сегодняшних архитектурах многоядерных процессоров требуется масштабируемая топология сети (например, сетка – mesh), поддерживающая коммуникации между ядрами. Масштабируемая внутрикристальная сеть соединяет ядра проводной сеткой, содержащей узловые коммутаторы (crosspoint router), которые управляют этим потоком коммуникаций, обеспечивая совместное использование сегментов линий связи и буферизуя сообщения при возникновении конфликтов. Наименьшие компоненты сетевых сообщений (флиты – flit) обходят ряд сегментов маршрутизаторов и линий связи («прыжков», или «хопов») на пути от источника сообщения к месту его назначения. Длина хопа каждого флита равняется ширине плитки – расстоянию между двумя маршрутизаторами.
Сетевая задержка флита T подсчитывается по формуле T = H(tr + tw) + Tc, где H – число хопов, tr задержка конвейера маршрутизатора, tw – проводная задержка, обычно составляющая один такт, а Tc – задержка из-за возникновения сетевых конфликтов. В последние десять лет исследователям микропроцессорных архитектур удалось снизить величину tr от пяти тактов до одного такта, так что для низко загруженной сети задержка флита, передаваемого от ядра-источника в ядро назначения, составляет сумму числа маршрутизаторов и числа сегментов линий связи (удвоенного числа хопов) между этими ядрами.
Однако при возрастании числа ядер неизбежно возрастает H, что приводит к пропорциональному росту T. Возрастающая внутрикристальная задержка не только увеличивает время, требуемое для удовлетворения запроса, но из-за наличия зависимостей тормозит выполнение других запросов, что ухудшает пропускную способность и вызывает общее замедление системы. По этой причине (для минимизации среднего числа сетевых хопов) разработчики протоколов поддержки когерентности кэшей предпочитают архитектуры с частными кэшами второго уровня, а программисты и разработчики компиляторов и операционных систем стараются располагать данные поблизости от ядер, отвечающих за их совместное использование. Но этим и ограничиваются возможности протоколов и программного обеспечения: в конце концов, у каждого ядра имеется ограниченное число односкачковых соседей, и чем больше имеется ядер, тем больше хопов требуется для передачи сообщения по внутрикристальной сети. При имеющихся в настоящее время ограничениях попытка разработать чип с 1024 ядрами приведет к возникновению ужасающих уровней задержки и расхода энергии, что существенно замедлит всю систему.
Для преодоления этой проблемы авторы статьи предлагают парадигму многопрыжкового однотактного асинхронного повторяющегося обхода (multihop asynchronous repeated traversal, SMART), позволяющую устранить зависимость T от H за счет создания однотактных многопрыжковых маршрутов – путей, проходимых по сети за один такт независимо от физического числа хопов между соответствующими узлами. Основная методология состоит в асинхронном пропуске сигнала через несколько маршрутизаторов и линий связи без блокировок. Оценки показывают, что SMART может уменьшить на 61% трафик системы на кристалле и на 50-57% трафик, требуемый для поддержки когерентности кэшей второго уровня.
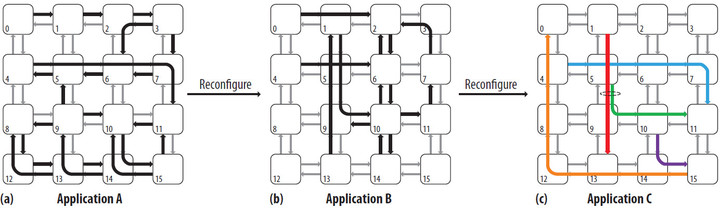
Пример однотактного многопрыжкового асинхронного повторяющегося обхода (SMART) для трех сценариев трафика a, b и c. Все многопрыжковые пути, выделенные жирными стрелками, обходятся за один такт. Для приложения c пути раскрашены, чтобы показать, что красный и зеленый пути конкурируют за общую линию связи между маршрутизаторами 5 и 9.
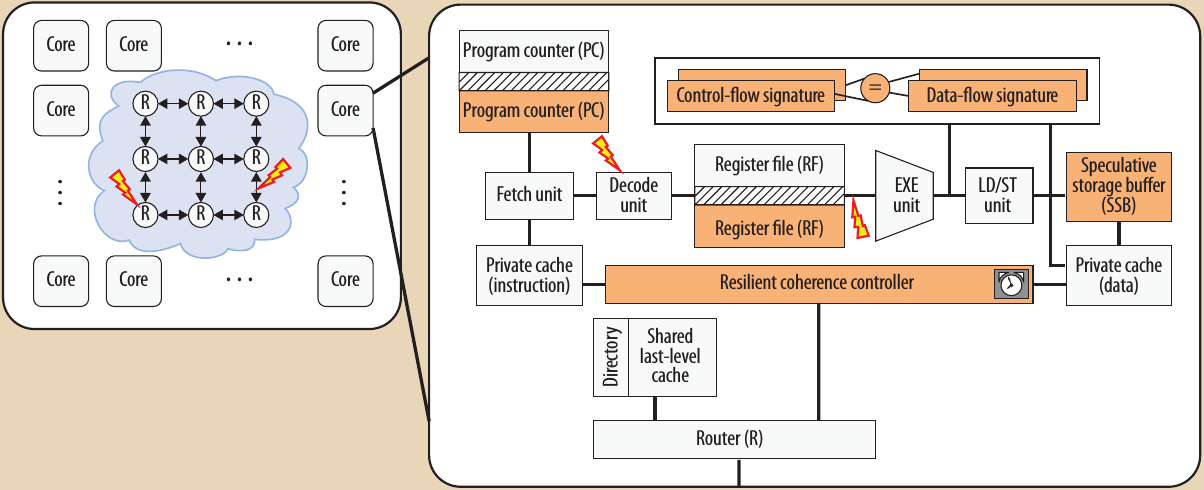
Завершает тематическую подборку статья «На пути к многоядерным процессорам с общей памятью, устойчивым к единичным неисправностям» («Toward Holistic Soft-Error-Resilient Shared-Memory Multicores»), авторами которой являются Кинчуан Ши и Омер Хан (Qingchuan Shi, Omer Khan, University of Connecticut).
Закон Мура позволяет интегрировать в одной микросхеме многие миллиарды транзисторов. Однако это сопровождается все большей неустойчивостью процессов функционирования микросхем, а также усугублением проблем старения и надежности. Процессоры должны обеспечивать высокую производительность в условиях ограниченного энергоснабжения, но действительно серьезную проблему для будущих компьютерных систем вызывает наличие единичных неисправностей. Неустойчивые искажения логических значений могут привести к эффектам, видимым пользователям, от ошибок программного обеспечения, возникновения синхронизационных тупиков на уровнях приложений, протоколов и аппаратуры до полного отказа системы. Разработчики микросхем не могут справиться с такими ошибками на основе тестирования и вынуждены полагаться на методы поддержки устойчивости во время работы микросхем.
Сегодняшние многоядерные микропроцессоры содержат набор разнотипных ядер и встроенных подсистем памяти, связываемых все более сложными коммуникационными сетями и протоколами. На уровне аппаратуры устойчивость базируется в основном на избыточности, что влияет на размеры микросхем, их энергопотребление и производительность. Выполнявшиеся ранее исследования в области аппаратной избыточности концентрировались на последовательных или независимых мультипрограммных приложениях, выполняемых на одноядерных многопотоковых процессорах (см., например). Протоколы, поддерживающие совместное использование памяти, сложны, и любая протокольная ошибка, проявляющаяся внутри ядра или коммуникационной среды, может привести к синхронизационным тупикам на уровне аппаратуры, повреждению состояния программы из-за несогласованности данных, а в худшем случае – к катастрофическому отказу системы. Поэтому требуется разработать механизмы, обеспечивающие устойчивое к ошибкам выполнение будущих многоядерных процессоров с общей памятью.
Авторы предлагают архитектуру устойчивого к единичным сбоям многоядерного процессора, в котором ядра, поддерживающие многопотоковые приложения, могут повторно выполнять детерминированные непрерываемые последовательности команд без потребности в глобальных контрольных точках, откатах и синхронизации. Этот подход напоминает подход транзакционной памяти. Каждое ядро автономно восстанавливает состояние программы и производит ее перезапуск на основе локально доступных данных. Предлагаемая архитектура обеспечивает повторное выполнение последовательностей команд в тех случаях, в которых аппаратура наиболее уязвима к единичным сбоям. Это обеспечивает динамический механизм, позволяющий балансировать требования к производительности и энергопотреблению с требованием устойчивости системы к единичным сбоям.
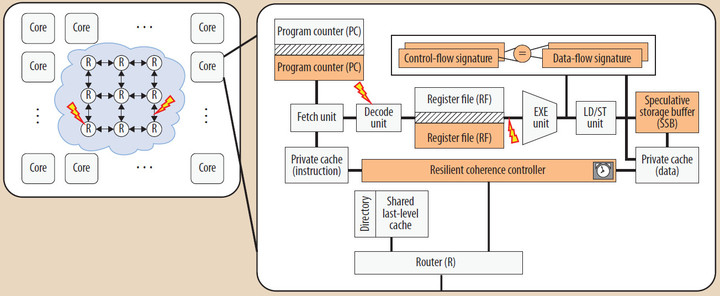
Увеличить рисунок
Архитектура устойчивого к единичным сбоям многоядерного процессора с общей памятью. Выделенные цветом модули поддерживают предлагаемый механизм избыточности для выявления и устранения единичных сбоев. Во внутрикристальном кэше используется механизм информационной избыточности (контроль четности или код, исправляющий ошибки).
Вне тематической подборки опубликованы две крупные статьи. Статью «Количественная оценка влияния программного обеспечения» («Quantifying Software’s Impact») написали Михаэль ван Генухтен и Лес Хэттон (Michiel van Genuchten, MTOnyx, Les Hatton, Oakwood Computer Associates and Kingston University, London).
После прихода к власти программного обеспечения в 1980-е гг. компьютерная индустрия решительно и необратимо изменилась. Развитие программного обеспечения подолжает оказывать влияние на целый ряд индустрий (от автомобилестроения до здравоохранения) и воздействует на жизнь большинства людей. В настоящее время с появлением операционной системы с открытым исходным текстом Android программное обеспечение производит глубокие изменения в индустрии мобильных телефонов. Важность программного обеспечения получила широкое признание в средствах массовой информации, о чем свидетельствуют заголовки статей: «Любой бизнес – это софтверный бизнес», «Любая компания – это софтверная компания» и «Почему программное обеспечение поглощает мир».
Для обеспечения количественной оценки влияния программного обеспечения на различные индустрии авторы статьи основали в 2010 г. в журнале IEEE Software рубрику, в которой публиковались заметки авторитетных представителей индустрии, менеджеров и софтверных профессионалов. Обычно авторы этих заметок работали в бизнесе в течение многих лет. Основатели рубрики ставили перед собой цель составить мировую карту программного обеспечения настолько же точную, насколько точны были карты Земли, составленные путешественниками с 15-го по 17-й века: топологически приемлемую, но не обязательно аккуратную с топографической точки зрения. В данной статье подводится итог полученной информации.
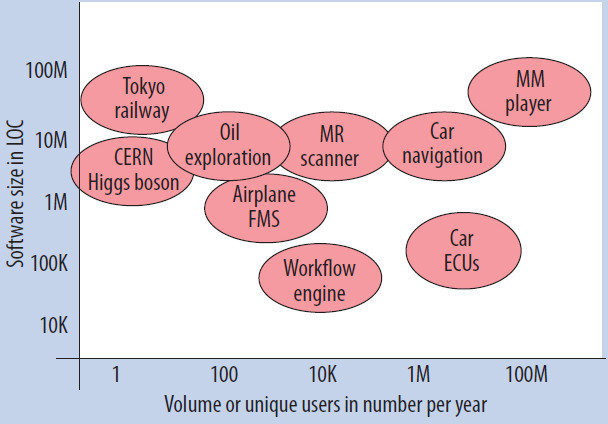
Размеры и общий объем программного обеспечения, используемого в различных индустриях. На горизонтальной оси показано число программных продуктов, приобретенных в течение года. На вертикальной оси показан размер программного обеспечения – число строк кода.
Последняя крупная статья номера называется «Защита критических систем управления в 21-м веке» («Critical Control System Protection in the 21st Century») и написана Кристиной Алкараз и Шерали Зидалли (Cristina Alcaraz, University of Malaga, Spain, Sherali Zeadally, University of Kentucky).
Повсеместное использование информационно-коммуникационных технологий (ИКТ) приводит к повышению эффективности, снижению стоимости и повышению качества жизни людей. ИКТ, мобильные технологии и устройства, рост Интернета позволяют получать доступ к информации в любом месте и в любое время.
Особо важная инфраструктура – это взаимосвязь набора систем и объектов (физических или виртуальных), поддерживающих большинство человеческих каждодневных активностей – путешествия, энергопотребление, банковские транзакции, телекоммуникации и т.д. В настоящее время ИКТ играют важнейшую роль в реализации, функционировании и поддержке многих особо важных инфраструктур (вода, энергия, продукты питания, газ, электричество и т.д.).
Для многих особо важных инфраструктур необходимо наличие критических систем управления, называемых также системами диспетчерского контроля и сбора данных (supervisory control and data acquisition, SCADA). Отдельные люди, компании и правительственные организации в своей повседневной деятельности полагаются именно на эти критические системы управления. Нарушения в их работе может вызвать серьезные социальные и экономические последствия национального уровня (в основном из-за наличия сильных связей между разными особо важными инфраструктурами).
Для обеспечения высокой эффективности, надежности и безопасности особо важных инфраструктур необходимо разработать и внедрить меры для их защиты. Это ведет к образованию новой области исследований, которую часто называют защитой особо важных инфраструктур (critical infrastructure protection, CIP). В статье описываются основные задачи, стоящие перед исследователями в этой области.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС