2015 г.
Визуальное будущее аналитики
Сергей Кузнецов
Обзор июльского, 2013 г. номера журнала Computer (IEEE Computer Society, V. 46, No 7, Июль 2013).
Авторская редакция.
Также обзор опубликован в журнале «Открытые системы»
Темой июльского номера в этом году является визуальная аналитика (visual analytics). Заметка приглашенных редакторов Марка Стрейта и Оливера Бимбера (Marc Streit, Oliver Bimber, Johannes Kepler University Lin) называется «Визуальная аналитика: в поисках неизвестного» («Visual Analytics: Seeking the Unknown»).
В настоящее время существует много алгоритмических и математических решений для анализа крупных наборов данных, таких как биомолекулярные данные или исходный код сложных программных систем. Для получения новых знаний из этих данных требуется указать, что именно ищется: от кластеров пациентов с одной и той же генной экспрессией до ошибок в программных системах. Но что делать в тех случаях, когда неизвестно, что следует искать?
Например, нерешенной проблемой является выявление геномных изменений и процессов, ведущих к возникновению конкретных разновидностей рака. Поскольку у биологов отсутствуют требуемые подходы, они не могут разработать алгоритмы, должным образом анализирующие биомолекулярные данные.
Визуальная аналитика – это перспективная, быстро развивающаяся область, в которой объединяются преимущества графической визуализации и мощность аналитических умозаключений. Визуальная аналитика поддерживает обнаружение новых и неизвестных знаний путем нахождения связей, паттернов, трендов и аномалий в потенциально больших и сложных данных. Поскольку уникальные способности аналитиков к осмыслению данных тесно связываются с методами интерактивной визуализации, визуальная аналитика может способствовать совершению открытий, которые не могут сделать ни человек, ни компьютер по отдельности.
Первую из пяти регулярных статей тематической подборки – «Инфраструктуры визуальной аналитики: от управления данными к исследованию данных» («Visual Analytics Infrastructures: From Data Management to Exploration») – написал Жан-Даниэль Фекете (Jean-Daniel Fekete, INRIA).
Одной из серьезных проблем визуальной аналитики является поддержка исследований больших данных и взаимодействий с ними. Выступая в этой роли, визуальная аналитика должна не только справляться с управлением данными и их анализом (где имеются свои сложности), но также и удовлетворять специфические требования к исследованию данных. Сталкиваясь с большими объемами незнакомых данных, люди нуждаются в их общих описаниях, а также в возможности к переходу на более детальный уровень. Это облегчает поиск паттернов и корреляций, нахождение феноменов, эмпирических моделей и теорий, связанных с исследуемыми данными.
С точки зрения разработчиков программного обеспечения реализация приложения визуальной аналитики затрудняется тем, что в традиционных уровнях аппаратуры и программного обеспечения отсутствуют важные сервисы, требуемые человеческим когнитивным системам при обработке сложной информации. Требования визуальной аналитики не удовлетворяются даже в самых новых средствах аналитики и управления данными. Для решения этих сложных проблем требуются работы, в результате которых визуальная аналитика сможет полностью справиться с поддержкой интеракивных исследований больших данных.
Двигаясь в этом направлении, группа проекта Aviz исследует когнитивные возможности людей, определяющие требования к исследованию данных, а также то, как следует изменить визуализацию информации, чтобы она отвечала этим требованиям. Двумя открытыми проблемами являются ограниченные возможности человеческого познания и возрастающее давление на программные системы со стороны данных. Основной причиной этого давления является несоответствие потребностям визуальной аналитики возможностей средств аналитики и управления данными.Устранение этого несоответствия будет полезно не только для инструментов визуальной аналитики, но и для аналитики и управления данными в целом.
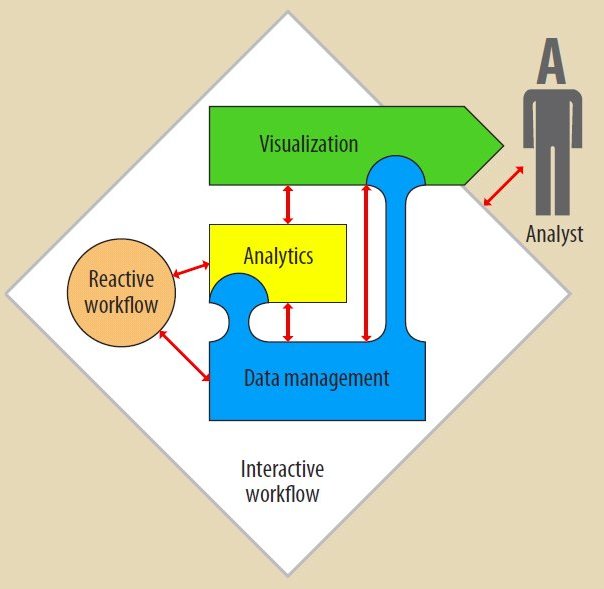
Три уровня программного и аппаратного обеспечения и их взаимосвязь с потоками работ более высокого уровня и с аналитиком. Красные стрелки изображают управляющие механизмы, область, закрашенная синим, соответствует совместному использованию и распространению данных, а зеленая область представляет визуализацию как коммуникационную среду системы и аналитика.
Статью «Поддержка визуальной аналитики для анализа разведывательных данных» («Visual Analytics Support for Intelligence Analysis») представили Карстен Горг, Юн А Канг, Жичен Лью и Джон Стаско (Carsten Görg, University of Colorado, Youn-ah Kang, Google, Zhicheng Liu, Stanford University, John Stasko, Georgia Tech).
Анализ разведывательных данных является ключевой областью применения визуальной аналитики с тех пор, как Министерство национальной безопасности США в 2004 г. создало Национальный центр визуализации и аналитики (National Visualization and Analytics Center). В исходном плане исследовательских работ описывались проблемы и цели этой новой прикладной области, а также обозначались задачи, данные и аналитические сценарии, касающиеся в основном национальной безопасности и предотвращения террористических актов.
Большая часть проблем, упомянутых в этом документе, осталась нерешенной, хотя технологии визуальной аналитики, безусловно, очень перспективны. Появилось несколько коммерческих инструментов визуальной аналитики для анализа разведывательных данных, в частности, Analyst’s Notebook от IBM i2, nSpace компании Oculus и семейство систем компании Palantir. Однако для дальнейшего развития требуется углубленное понимание специфики анализа разведывательных данных и роли аналитиков, а также выяснение того, каким образом визуальная аналитика может помочь исследователям.
Масштабность, разнородность и сложность подлежащей исследованию разведывательной информации вызывают потребность в привлечении к анализу больших когнитивных возможностей. Информация часто представляется в виде повествовательных текстов, не поддающихся автоматическому анализу. Проблемными аспектами процесса исследования являются стоимость просмотра текста, оценки его важности и выбора элементов, заслуживающих большего внимания; трудности генерации и проверки гипотез.
Для улучшения понимания возможностей применения визуальной аналитики авторы статьи выполнили несколько проектов, посвященных анализу разведывательных данных. В этих проектах, длившихся с 2008 по 2013 гг., изучались характеристики процесса анализа. Кроме того, была разработана система визуальной аналитики текстов Jigsaw, в которой интегрируются средства вычислительного анализа текстов с возможностями интерактивной визуализации для исследования коллекций неструктурированных и полуструктурированных текстовых документов.
Авторами статьи «Визуализация и анализ крупномасштабных графов» («Large-Scale Graph Visualization and Analytics») являются Кван Лью Ма и Крис Мюлдер (Kwan-Liu Ma, Chris W. Muelder, University of California, Davis).
Растущая популярность сетевых приложений вызывает потребность в средствах эффективного анализа сложных коллекций данных. Википедия включает миллионы статей, образующих сеть через перекрестные ссылки. Facebook связывает более миллиарда пользователей в чрезвычайно сложную структуру друзей, приглашений в группы, игр, рекламных объявлений, видеочатов и т.д. Эти и подобные им сети продолжают расширяться и усложняться.
Для изучения динамики таких сложных сетей неэффективно и непрактично использовать простые статистические данные. Все чаще аналитики предпочитают применять визуализацию – не только пассивный процесс отображения чисел в графической форме, но и набор интерактивных методов, соединяющих графические представления с анализом сетей. Такой анализ может позволить получить важные знания. Например, аналитики социальных сетей могут обнаружить особенности образования групп друзей, а анализ распределительной электрической сети может выявить, что в основном требуется для усовершенствования инфраструктуры.
Визуализация графов (graph drawing) — это область, возникшая в 1960-х гг., задачей которой является визуализация структуры сетей. Одним из наиболее распространенных и интуитивно понятных представлений является диаграмма «узел-ребро», в которой узлы представляют объекты, а ребра между узлами — взаимосвязи объектов. Хотя этот метод относительно прост и практически пригоден для визуализации небольших сетей, он может оказаться неприменимым в случае наличия крупных и сложных сетей.
Дополнительные проблемы возникают при работе с сетями, изменчивыми во времени (такими, как Facebook). Социальная сеть разрастается при образовании каждой новой дружеской связи и сокращается, когда дружеские отношения ослабевают или прекращаются. Поскольку каждое добавление или удаления узла может воздействовать на более масштабные паттерны (например, кластеры), нахождение и понимание смысла небольших изменений может обеспечить знания о развитии сети в целом.
Визуализация и анализ графов требуют дальнейших исследований в связи с продолжающимся ростом масштабности и сложности данных и информационных систем. Новые методы должны затрагивать все аспекты представления сетей: от фундаментальной проблемы размещения крупных графов до анализа графов и упрощения динамически изменяемых графов. В своей работе авторы статьи выявили нерешенные проблемы и предложили пути к их решению. Результаты показывают перспективность визуализации для поддержки новых форм анализа сетей.
Статью «Визуальный анализ текстовых потоков в реальном времени» («Real-Time Visual Analytics for Text Streams») представили Даниэль Кейм, Милош Крстажич, Кристиан Рохрданц и Тобиас Шрек (Daniel A. Keim, Miloš Krstajic, Christian Rohrdantz, Tobias Schreck, University of Konstanz, Germany).
Ежедневно в киберпространство вводятся текстовые данные огромного объема, генерируемые профессионалами (например, авторами текста новостей) или обычными пользователями через блоги, социальные сети или комментарии на Web-сайтах. Большая часть генерируемого текста является общедоступной, но значительная доля предназначена только для внутреннего использования. Например, доступ к ценной информации, получаемой при опросе пользователей Интернет-магазина, может быть ограничен некоторой группой лиц или организаций. Кроме того, группы пользователей могут порождать важный контент при возникновении новых событий, появлении новых продуктов, услуг и компаний.
При должной обработке эти разнородные потоки текста позволяют обеспечить мгновенную обратную связь, отслеживать и совершенствовать безнес-деятельность. Компании могут анализировать эти потоки для выявления проблем, связанных со временем, например, время, когда потребители начали жаловаться на качество услуг или продуктов. Полученные знания можно использовать для быстрого улучшения ситуации, избежав потери клиентов или подрыва репутации компании.
Теоретически, в реальном времени можно обрабатывать любую информацию, но при обработке текстов возникают задержки. В текстовых потоках может присутствовать как относящаяся к делу, так и лишняя информация, а семантическая структура может отсутствовать. Для отбора релевантной информации и извлечения высокоуровневой семантической структуры (события, темы, настроения и т.д.) аналитикам требуются методы автоматической обработки текстов. При использовании таких методов приходится поддерживать баланс между скоростью аналитической обработки и качеством результатов, причем существенны собственные приоритеты конкретного аналитика.
Независимо от извлеченной семантической структуры только люди могут осмыслить полученные результаты и сделать выводы, пригодные для принятия решений. Интерактивная визуализация может устранить разрыв между вычислительными методами и требованиями аналитиков. Именно эта идея является движущей силой визуальной аналитики.
Большая часть исследований, посвященных применению визуальной аналитики, ориентируется на объединение автоматического анализа и интерактивной визуализации с целью обеспечения пользователям возможности исследования интенсивных потоков текстов. В исследовании, выполненном авторами статьи, разработан подход к анализу текстовых потоков в соответствии с трендами, выявляемыми на основе анализа плотности. В ходе исследования обнаружено несколько открытых проблем в области обработки и анализа текстов в реальном времени. Построена таксономия существующих методов обработки текстов с учетом возможных компромиссов между точностью и эффективностью.
Последняя статья тематической подборки написана Ярке ван Вайком (Jarke J. van Wijk, Eindhoven University of Technology) и называется «Оценка: проблема визуальной аналитики» («Evaluation: A Challenge for Visual Analytics»).
Визуальная аналитика помогает людям понимать смысл разнородных данных большого объема за счет интеграции нескольких методологий анализа данных, но достижение хороших результатов остается проблематичным. Отсутствуют решения многих практических проблем, а имеющиеся решения трудно оценить. В целом в области визуальной аналитики отсутствуют убедительные модели и теории. В результате визуальная аналитика еще не скоро станет зрелой технологией.
Важную роль в развитии этой области будут играть методы оценки, но характеристики визуальной аналитики, в частности, огромный размах и направленность на обеспечение знаний, затрудняют обеспечение должной оценки. Здесь имеется в виду оценка качества артефактов визуальной аналитики, включая инструменты, методы, модели и теории. Качество затрагивает эффективность и результативность и включает такие аспекты, как удовлетворенность пользователей, производительность, простоту использования, а также то, как данный артефакт вписывается в имеющиеся потоки работ.
Результаты оценки важны для всех заинтересованных лиц. Интеграторам и пользователям визуальной аналитики нужно знать качество артефактов. Разработчикам систем, опирающимся на использование методов визуальной аналитики, нужны критерии выбора конкретного набора методов. Даже пользователям, выбирающим систему, метод или хотя бы параметры настройки, нужна соответствующая информация для принятия решения. Кроме того, хорошие оценочные результаты могут помочь убедить интеграторов и пользователей использовать новые методы. Однако, невзирая на возрастающую важность визуальной аналитики, обеспечение должной оценки затруднительно. Обсуждению имеющихся проблем посвящена основная часть статьи.
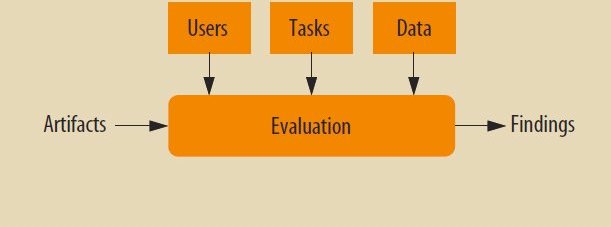
Компоненты процесса оценки визуальной аналитики. Цель состоит в получении выводов о качестве артефактов для конкретных пользователей, задач и данных.
Вне тематической подборки опубликованы две крупные статьи. Диана Кук, Арон Крендал, Брайан Томас и Нараян Кришнан (Diane J. Cook, Aaron S. Crandall, Brian L. Thomas, and Narayanan C. Krishnan, Washington State University) представили статью «CASAS: умный дом в коробке» («CASAS: A Smart Home in a Box»).
В последнее десятилетие методы машинного обучения и технологии повсеместного компьютинга стали настолько зрелыми, что оказалась возможной интегрированная автоматическая поддержка повседневной среды обитания людей. Физическим воплощением такой системы является умный дом. Программное обеспечение опирается на использование сенсорной сети и методов искусственного интеллекта для получения знания состояния как физической среды дома, так и его обитателей. На основе этого знания предпринимаются действия для достижения заданных целей.
В ходе функционирования системы сенсоры собирают и передают данные, а жители дома живут своей обычной жизнью. Сенсорные данные сохраняются в базе данных, которая используется интеллектуальным агентом для генерации полезных знаний – паттернов, предсказаний и тенденций. На основе этой информации умный дом может выбирать и выполнять действия.
Многие исследователи отмечают исключительную важность потенциального использования технологии умных домов в таких приложениях, как мониторинг состояния здоровья и автоматизация эффективного энергопотребления. Однако большинство имеющихся реализаций в основном ориентировано на использование в лабораторных условиях. Большая часть затруднений связана с созданием полностью функциональной инфраструктуры умного дома. Хотя имеются реалистичные прототипы умного дома, доводка их до уровня продукта очень затруднительна.
Целью проекта CASAS Вашингтонского университета является разработка умного дома в коробке (smart home in a box, SHiB). Набор элементов этого умного дома невелик, инфраструктура облегчена, расширение функций достигается минимальными усилия, а основные возможности обеспечиваются в виде, готовом к использованию.
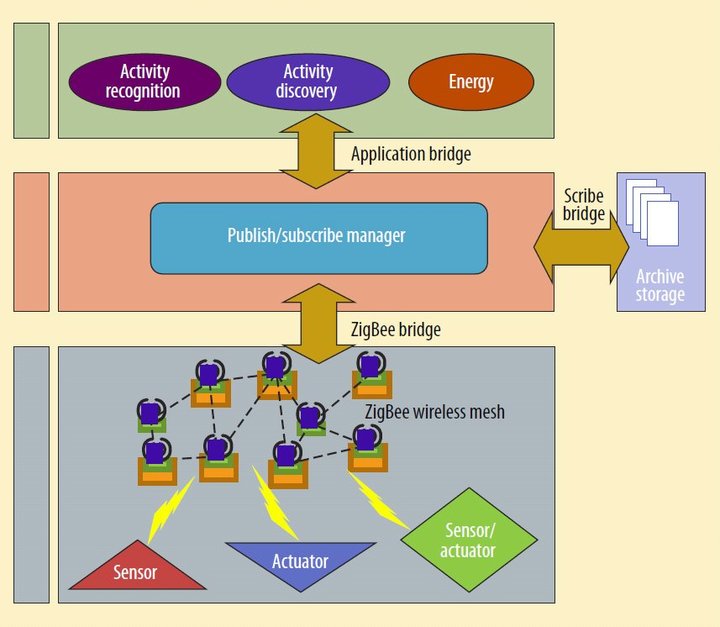
Компоненты умного дома CASAS. Во время отслеживания состояния управление передается от физических компонентов к программным приложениям. Когда интеллектуальная среда инициирует действие, управление передается от уровня приложения физическим компонентам. Каждый из уровней легковесен, расширяем и готов к использованию.
Последняя крупная статья июльского номера называется «Оптимальное распределение ресурсов с использованием MultiAmdahl» («Optimal Resource Allocation with MultiAmdahl») и представлена Цахи Зиденбергом, Исааком Кесласси и Ури Вейзером (Tsahee Zidenberg, Isaac Keslassy, Uri Weiser, Technion, Israel).
В новых неоднородных мультипрорцессорных кристаллах будет интегрирорваться большое число различных вычислительных блоков. Эти блоки могут включать крупные ядра для последовательной обработки и несколько более мелких ядер для параллельной обработки, а также графические процессоры, вспомогательные процессоры (helper processor), сигнальные процессоры, программируемые логические матрицы (field-programmable gate arrays, FPGA) и специализированные жестко скомпонованные схемы (application-specific hardware circuit). Эти блоки, разработанные в расчете на конкретную рабочую нагрузку, могут настраиваться под заданное приложение, что делает их намного более мощными по отношению к этому приложению, чем блоки общего назначения.
Однако неоднородность даром не дается. На кристалле имеется ограниченные доступные ресурсы, такие как площадь пластины или общая потребляемая мощность. За эти ресурсы конкурируют все компоненты кристалла. Если один кристалл содержит несколько блоков с разными функциями, системный архитектор должен распределить ресурсы между этими блоками. Для достижения оптимального решения архитектор должен принимать во внимание эффективность блоков, а также их рабочую нагрузку.
Во фреймворке MultiAmdahl распределение ресурсов внутри кристалла трактуется как оптимизационная проблема. Входными данными этой проблемы является рабочая нагрузка системы, характеристики разных блоков, доступные ресурсы кристалла и цель разработки. Обеспечивается простая модель этой проблемы, решаемой с использованием множителей Лагранжа. Эта модель впоследствии используется для выяснения тенденций в разработке микропроцессорных кристаллов.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
