2015 г.
Большой мир больших данных
Сергей Кузнецов
Обзор июньского, 2013 г. номера журнала Computer (IEEE Computer Society, V. 46, No 6, июнь 2013).
Авторская редакция.
Также обзор опубликован в журнале «Открытые системы»
Тема июньского номера – «Большие данные: новые возможности и новые проблемы» (Big Data: New Opportunities and New Challenges). Тематика больших данных чрезвычайно популярна в последние годы. Различным аспектам особенностей обработки данных сверхбольшого объема посвящались тематические выпуски различных журналов (к этой теме обращался и наш журнал), проводились и проводятся многочисленные конференции (в том числе и в России). Теперь появился и номер журнала Computer, посвященный этой теме. И это очень интересно, потому что в разных компьютерных сообществах термин «большие данные» трактуется по-разному, выделяются и решаются разные проблемы. Журнал же Computer адресуется к компьютерному миру в целом, и поэтому его трактовка проблемы больших данных может оказаться наиболее сбалансированной.
Приглашенными редакторами июньского номера являются Катина Майкл и Кейт Миллер (Katina Michael, University of Wollongong, Keith W. Miller, University of Missouri–St. Louis). Название их очень содержательной вводной заметки совпадает с объявленной темой номера.
Не секрет, что частные компании и правительственные организации нуждаются в лучшем понимании поведения и настроений людей. Используются различные аналитические методы (в том числе, краудсорсинг, генетические алгоритмы, нейронные сети, анализ тональности (sentiment analysis) и т.д.) для исследования структурированных и неструктурированных форм данных. Эти данные собираются из многочисленных источников, включающих сенсорные сети, правительственные фонды данных, базы данных лидирующих компаний и общедоступные данные социальных сетей.
Хотя интеллектуальный анализ данных в той или иной форме применяется с тех пор, как люди начали сохранять данные, так называемым большим данным свойственны не только большие объемы, но и наличие данных разных типов, которые никогда раньше не анализировались совместно. Для этих потоков данных требуется постоянно возрастающая скорость обработки, возможность экономного хранения и поддержка своевременной обратной связи с бизнес-процессами.
Со времени возникновения Internet человечество непрерывно двигается в направлении расширения используемых типов данных (изображений, видеоданных, интерактивных карт и т.д.), а также разновидностей метаданных (например, геолокационной и темпоральной информации). Двадцать лет назад для каналов ISDN пределом была передача данных базовой графики, но сегодняшние высокоскоростные сети справляются с передачей данных любого типа, невзирая на объем.
Например, пользователи смартфонов могут производить высококачественные фотографии и видеоролики и напрямую загружать их в социальные сети с использованием Wi-Fi или сотовых сетей 3G или 4G. Непрерывно растут и объемы данных, накапливаемых в ходе двунаправленных взаимодействий (человек-машина и машина-машина) с использованием телемеханических и телеметрических устройств в системах систем. Все более важны сети здравоохранения, обеспечивающие слияние и совместное использование изображений с высоким разрешением в форме рентгенограмм, магнитно-резонансных и компьютерных томограмм пациентов.
Достижения в областях хранения и анализа данных обеспечивают возможность сохранения данных возрастающего объема, прямо или косвенно производимых пользователями, и их анализа для получения новых ценных знаний. Например, компании могут изучать тенденции покупательского поведения потребителей для улучшения маркетинга. Кроме того, близкие к реальному времени данные с мобильных телефонов могут обеспечить детальные характеристики посетителей магазинов, помогающие понять их сложные процессы принятия решений во время посещения магазина.
Большие данные могут помочь выявить скрытые модели поведения и даже понять намерения людей. Более точно, анализ таких данных может устранить разрыв между намерениями людей и их реальным поведением, позволить понять их манеры взаимодействия с другими людьми и окружающей средой. Эта информация полезна для правительственных организаций и частных компаний для поддержки принятия решений в областях охраны правопорядка, социального обеспечения, национальной безопасности и т.д.
В научной области повторное применение данных пациентов может способствовать изобретению лекарств для лечения или предотвращения болезней. Завершенный в 2003 г. проект «Геном человека», раскрывающий генетические причины заболеваний, был первым проектом, продемонстрировавшим возможности больших данных. Теперь исследователи концентрируются на двух основных проектах: Human Brain Project (EU) и US BRAIN Initiative. Эти проекты предполагают суперкомпьютерное моделирование работы мозга человека. Дополнительным результатом должно стать решение проблем, связанных с болезнями Альцгеймера и Паркинсона. Большие данные других разновидностей можно анализировать для решения научных проблем в различных областях — климатологии, геофизике, нанотехнологии и т.д.
Хотя большие данные могут нести исключительно полезную информацию, они также порождают новые проблемы, связанные с хранением данных, стоимостью хранения, безопасностью и требуемой продолжительностью хранения. Например, и компании, и правоохранительные организации все больше полагаются на видеоданные для поддержки систем наблюдения и оперативно-розыскной деятельности. Во многих коммерческих зданиях и общественных помещениях внедрены системы кабельного телевидения. В полицейских автомашинах установлены телекамеры для фиксации преследований и проверок автомобилей, а также видеорегистраторы, данные которых используются при разборе жалоб. Многие организации экспериментируют с нательными видеокамерами для фиксации происшествий и сбора непосредственных доказательств на месте преступления для использования их в суде. Крошечными видеокамерами теперь оснащаются даже тазеры. Поскольку все эти устройства могут быстро производить огромные объемы данных, хранение которых обходится дорого, а обработка требует большого времени, операторам приходится решать, следует ли позволять камерам работать непрерывно, или же более эффективным решением является фиксация отдельных изображений или сцен.
Большие данные порождают и новые этические проблемы. В компаниях большие данные используются для получения большей информации об используемой рабочей силе, повышения производительности, введения новых бизнес-процессов. Однако эти новшества не даются даром. Постоянная слежка за служащими и непрерывное измерение производительности их труда могут плохо влиять на общую атмосферу компании. Подобный мониторинг может представлять огромный интерес для компании, но далеко не всегда в нем заинтересованы люди, работающие в этой компании.
Кроме того, по мере возрастания распространенности больших наборов мультимедийных данных стираются границы между общедоступными и конфиденциальными данными. Появляющиеся онлайновые приложения, уже сегодня позволяющие загружать видеоданные в социальные сети в беспроводном режиме, скоро будут опираться на использование переносимых устройств в виде цифровых часов или очков и позволять производить непрерывную фиксацию происходящего. По сути, человек станет видеокамерой. Объем таких публично доступных данных неизмеримо превзойдет объем данных, генерируемых сегодняшними камерами систем кабельного телевидения.
Однако, в отличие от камер наблюдения, смартфоны и нательные устройства не обеспечивают никакой защиты конфиденциальности, например, для невинных прохожих, которые неожиданно для себя попали в кадр. Например, при расследовании недавних взрывов в Бостоне несколько людей попали в число подозреваемых из-за того, что их фотографии на месте теракта были размещены на сайтах социальных сетей.
На самом деле, одной из основных проблем больших данных является защита конфиденциальности. В повседневной жизни за каждым человеком тянутся цифровые следы, комбинация которых может обеспечить уникальную информацию о человеке (вроде ДНК), которая в противном случае могла бы остаться незамеченной. К числу примеров относятся особенности использования языка и пунктуации в блогах, особенности одежды, надеваемой в разных условиях и т.д. Особенности человека характеризуются даже тем, как он использует энергию у себя дома.
Аналитика над большими данными будет опираться на аспекты домашней, рабочей и общественной жизни людей и позволять делать предположения о типичной «сегментации рынка», отвечая на вопрос, к какому сегменту относится каждый отдельный человек. Последствия могут быть неожиданными. Возможно, например, люди будут постоянно изменять свой образ жизни, изменять свое поведение в наблюдаемых местах, чтобы защитить свою конфиденциальность. Большие данные изменят образ жизни людей. Не ведут ли они к полностью контролируемому обществу? Или же удастся использовать большие данные без разрушения частной жизни, способствуя повышению качества жизни людей?
Первая регулярная статья тематической подборки называется «Анализ общественного мнения для инноваций, продвигаемых данными» («Public Policy Considerations for Data-Driven Innovation») и написана Джесс Хемерли (Jess Hemerly, Google).
Термин «большие данные» относится не только к размеру данных, но также характеризует скорость, вычислительную и аналитическую мощность, требуемые для управления такими данными и получения знаний. Сегодняшние данные являются «большими» из-за потребности совместного использования многих разных форм данных: операционных, технологических, статистических данных, агрегированных таблиц, лингвистических данных из документов, этнографических данных, а также метаданных. Поскольку с генерацией, преобразованием, сбором, обеспечением безопасности данных и обеспечением доступа к ним связаны существенные расходы, они представляют собой ресурс, в который осуществляются огромные инвестиции. Поскольку размер этих инвестиций продолжает расти, имеется повсеместное желание научиться правильно их использовать и найти новые способы принятия решений, совершенствования процессов и т.д. Другими словами, нужно научиться использовать данные для продвижения инноваций.
Часто можно численно оценить преимущества от использования или анализа данных, ценность технологии, построенной над этими данными. Например, люди могут согласиться платить $1.99, если после анализа данных производительность используемого ими приложения выросла на X процентов. Но сами по себе данные не обладают присущей им измеримой ценностью: невозможно «оценить» набор данных и присвоить ему денежную стоимость на основе размера или содержимого. Один и тот же набор данных может использоваться в одном алгоритме для предсказания задержек в транзитных перевозках и в другом для эффективной реорганизации логистики. Семантический анализ постов в Твиттере может показать тенденции развития массовой культуры или же подсказать пути выхода из конкретной кризисной ситуации. Данные – это первичный возобновляемый ресурс.
Но данные бессмысленны, пока они не сравниваются с другими данными, не визуализируются в некотором контексте или не анализируются. Алгоритм можно считать Розеттским камнем для данных, преобразующим их в форму, осмысленную для людей. Однако, в отличие от Розеттского камня, нет ограничений на число различных ключей, которые можно создать для извлечения знаний из одного набора данных. При наличии такого объема данных столь многих видов число пригодных для использования Розеттских камней (и число людей с научной подготовкой, достаточной для преобразования данных в осмысленную форму) растет экспоненциально. По словам Эдда Дамбилла из компании O’Reilly, термин «большие данные» в действительности означает «разумное использование данных».
Даже если этот термин когда-нибудь исчерпает себя, данные будут продолжать стимулировать процессы инноваций. Решения проблем будут получаться путем тщательного анализа данных и применения новых способов их интерпретации. Продукты, услуги и процессы, создаваемые под влиянием данных для продвинутых пользователей, можно называть инновациями, продвигаемыми данными (data-driven innovation). Подобные инновации являются будущим «больших данных», но их место в обществе, в конечном счете, будет определяться общественным мнением.
Автором статьи «Корпоративное управление большими данными: перспективы значимости, риска и стоимости» («Corporate Governance of Big Data: Perspectives on Value, Risk, and Cost») является Пол Теллон (Paul P. Tallon, Loyola University Maryland).
Во многих организациях продолжается экспоненциальный рост объемов накапливаемых и сохраняемых данных. В таких компаниях, как Intel, Google и Wal-Mart в настоящее время хранится и используется по несколько петабайт данных, что в сотни раз превышает объем содержимого Библиотеки Конгресса США. В среднем объемы данных, сохраняемых в корпоративных центрах данных, возрастают на 40% ежегодно. В некоторых отраслях (например, в областях здравоохранения и фармацевтики) этот ежегодный рост составляет 100%. Хотя этот экспоненциальный рост является новой нормой, многие организации не могут ответить на два важных вопроса:
- Зачем нужны эти большие данные?
- В чем их истинная ценность?
Расходы на сбор и хранение данных всегда оправдывались тем, что ценность больших данных больше этих расходов. Однако истинность этого предположения редко проверялась (если вообще когда-нибудь проверялась). При отсутствии четкого понимания ценности данных и ее изменения со временем организациям свойственно допускать ошибки. Это может приводить к исключительно высокому уровню технического, экономического и репутационного риска, если организация решается на сверхвысокие расходы на поддержку технологии хранения очень ценных данных. Например, при создании новых лекарств хранение данных клинических испытаний в ненадежных устройствах хранения не приводит к высоким расходам, но вызывает большой риск. Аналогично, организации могут излишне много тратить на хранение не слишком ценных данных, прибегая к излишней репликации или используя дорогие надежные устройства в тех случаях, когда было бы достаточно пользоваться менее дорогими системами.
Проблемой, стоящей перед организациями, является разработка механизмов управления (политик и структур), которые позволяли бы балансировать расходы и риски при наличии растущих объемов данных и улучшенных и удешевленных технологий хранения данных. Эти политики и структуры должны защищать данные от ошибочных факторов, которые могут обесценить данные, но при этом не должны ограничиваться возможности организаций для получения реальной пользы от данных.
Исследование, выполненное в Мерилендском университете Лойола, показывает, что управление данными отражает то, как организации оценивают свои информационные активы и насколько они готовы тратиться на развитие технологий хранения для защиты этих активов от различных рисков. Поскольку «безразмерные» (one-size-fits-all) решения здесь вряд ли помогут, организациям следует выбирать одно из существующих решений для управления данными, а затем модифицировать его с учетом особенностей своей прикладной области и текущих обстоятельств.
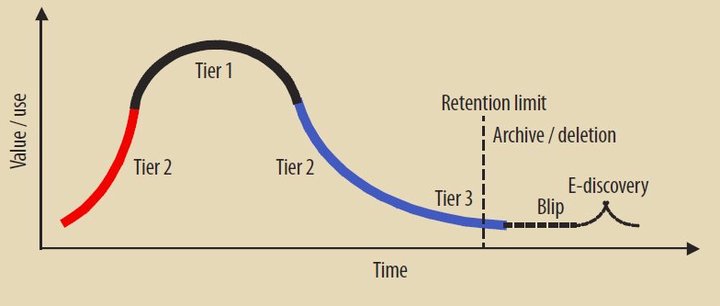
Кривая жизненного цикла информации. С течением времени ценность информации повышается и понижается соразмерно ее полезности в процессах принятия решений.
Статья «Превращение больших данных в коллективную осведомленность» («Transforming Big Data into Collective Awareness») представлена Джереми Питтом, Айкатерини Бурацери, Анджеем Новаком, Магдой Рошинской, Агнешкой Рыхвальской, Инмакуладой Родригез Сантьяго, Майте Лопез Санчез, Моникой Флореа и Михаем Сандуляком (Jeremy Pitt, Aikaterini Bourazeri, Imperial College London, Andrzej Nowak, Magda Roszczynska-Kurasinska, Agnieszka Rychwalska, University of Warsaw, Inmaculada Rodríguez Santiago, Maite López Sánchez, University of Barcelona, Monica Florea, SIVECO Romania SA, Mihai Sanduleac, ECRO SRL).
Люди, живущие в физическом пространстве, нуждаются в доступе к его ресурсам и службам – воде, энергии, цифровой информации и т.д. Для облегчения этого доступа должна разрабатываться и внедряться соответствующая инфраструктура. По мере того, как инфрормационно-телекоммуникационные технологии (ИКТ) обеспечивают все большую автоматизацию, по мере того, как возрастает уровень связности сенсоров и устройств, эта инфраструктура становится «интеллектуальной». Например, появляются «умные» электросети или города.
Интеллектуальная инфраструктура должна поддерживать разные роли, которые могут исполнять пользователи. Например, в умном городе пользователь может играть роль покупателя или продавца на рынке электроэнергии, участника процесса принятия решений об инвестициях в энергетику и т.д. Кроме того, исполняя данную роль, пользователи должны понимать, как их действия воздействуют на более крупную систему. Другими словами, они должны использовать одни и те же данные и один правовой, социальный и культурный контекст для интерпретации этих данных. Эта коллективная осведомленность является важным элементом сотрудничества сообществ, в особенности, сообществ, организуемых с компьютерной поддержкой.
Коллективной осведомленности можно достичь путем анализа больших данных, генерируемых сетевыми сенсорами и устройствами, а также пользователями, владеющими возможностями ИКТ. Технологии поиска, интеллектуального анализа данных и визуализации позволяют определять тенденции и предсказывать вид кривых изменения переменных. В свою очередь, это делает возможными коллективные действия, без которых нельзя изменить поведение сообщества для достижения желаемого результата.
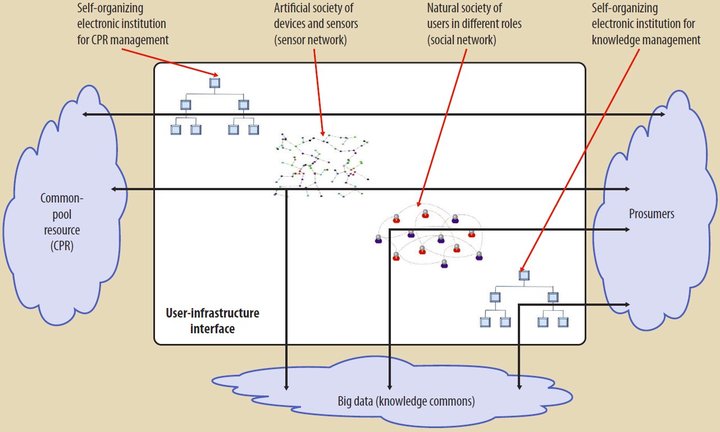
Интеллектуальная инфраструктура для превращения больших данных в коллективную осведомленность
Статью «Большие сюрпризы больших данных» («Big Data’s Big Unintended Consequences») написали Маркус Вайгон и Роджер Кларк (Marcus R. Wigan, Oxford Systematics, Swinburne University, and the University of Melbourne, Roger Clarke, Xamax Consultancy, University of New South Wales, and Australian National University).
В 1988 г. был предложен подход слежки на основе данных (dataveillance, от database и suveillance), который определяется автором как «систематическое использование систем работы с персональными данными в целях расследований или мониторинга действий или коммуникаций одного или нескольких человек». Этот подход является более экономичным, чем физическая или электронная слежка.
К числу ранних методов относились предварительная верификация (front-end verification) и установление соответствия данных (data matching). Важным направлением в этой области стала профилировка (profiling), позволяющая вывести из имеющихся наборов данных характеристики заданной категории людей с тем, чтобы впоследствии можно было выбрать других людей, обладающих близкими характеристиками.
После появления технологии нейронных сетей и других средств генерации правил стали использоваться более масштабные процессы. Появился термин «data mining» (интеллектуальный анализ данных), поначалу связанный со средствами нахождения новых товаров, которые могли бы привлечь внимание потребителей и способствовать увеличению объема продаж. В этом подходе данные используются в качестве исходного сырья, а процесс состоит в раскопке этого сырья с целью извлечения малозаметных сложных, часто многомерных связей.
Выражение «большие данные», употребляемое с 1990-х гг., обычно относится не только к конкретным крупным наборам данных, но также и к коллекциям данных, объединяющим много наборов данных из нескольких источников, и даже к методам, используемым для управления этими данными и их анализа. Похоже, что большими данными первыми стали пользоваться физики, для которых вычислительный анализ и эксперименты оказались существенно более экономными, чем традиционные дорогостоящие лаборатории. Огромные объемы данных генерируются приложениями больших данных в таких проектах, как Поиск внеземных цивилизаций (Search for Extraterrestrial Intelligence, SETI), Большой адронный коллайдер (Large Hadron Collider, LHC), Квадратная километровая решётка (Square Kilometre Array), геномные проекты (см. выше).
Методы больших данных впоследствии стали применяться и в других областях и привели к появлению вычислительной социологии. Уже существуют данные огромного объема в областях здравоохранения и социального обеспечения. Новыми источниками данных являются данные о местоположении из систем управления дорожным движением и из систем, отслеживающих мобильные телефоны.
Компании относятся к большим данным как с средству достижения коммерческого успеха, в особенности, в области маркетинга. В последнее время идея больших данных овладела правоохранительными организациями и организациями, обеспечивающими национальную безопасность, которые рассчитывают на основе методов больших данных обеспечить более качественное обнаружение криминальных и террористических элементов.
Компании и государственные организации, использующие большие данные, часто сталкиваются с проблемами легальности и качества данных, неоднозначности смысла данных, качества процессов обработки и анализа. Это может приводить к неверным решениям, подвергающим людей большому риску. Отрицательные последствия использования больших данных могут сказываться не только на отдельных людях, но и на общественной жизни, экономике и политике. Предлагается подход, который в принципе может снизить влияние этих побочных эффектов больших данных.
Последняя статья тематической подборки написана Каролин Мак-Грегор (Carolyn McGregor, University of Ontario Institute of Technology, Canada) и называется «Большие данные в интенсивной терапии новорожденных» («Big Data in Neonatal Intensive Care»).
Преждевременные роды со сроком беременности менее 37 недель являются одной из наиболее существенных перинатальных проблем в развитых странах. Например, в Канаде от 75 до 85% случаев перинатальной смертности возникают именно в результате преждевременных родов (учитываются мертворожденные дети и младенцы, не дожившие до возраста в 7 дней).
Отделения интенсивной терапии новорожденных (neonatal intensive care unit, NICU) обеспечивают интенсивную терапию недоношенным и больным младенцам. Для лечения таких младенцев требуется клиническая поддержка сложных решений в реальном времени, опирающаяся на медицинские данные из многих источников, поскольку преждевременные роды могут вызвать у младенца различные повреждения (мозга, легких, глаз и т.д.). По мере своего роста младенец становится сильнее, и опасности осложнений уменьшаются. Однако если недоношенного младенца не подвергнуть интенсивной терапии, проблемы со здоровьем могут остаться у него на всю жизнь.
Отделение интенсивной терапии новорожденных – это сложная среда, в которой решения принимаются совместно разными специалистами. Несмотря на происходящий переход от традиционных форм ведения медицинской документации к электронным формам, медицинские специалисты продолжают обсуждать большую часть клинической информации на качественном уровне из-за отсутствия инструментов, методов и политик, поддерживающих сложные, интенсивные потоки физиологических данных.
Эти «большие данные» остаются неиспользуемым ресурсом, который потенциально может существенно повысить качество лечения. Поддержка клинических решений при интенсивной терапии новорожденных (и интенсивной терапии в целом) значительно выиграет от применения онлайновых аналитических платформ, опирающихся на физиологические и другие медицинские данные. В статье описывается прототип такой платформы, разработанной автором.
Вне тематической подборки в июньском номере опубликованы две крупные статьи. Первая из них называется «Конфиденциальность в социальных сетях: политика и управление» («Social Networking Privacy: Understanding the Disconnect from Policy to Controls») и написана Паулиной Антонисами, Филом Гринвудом и Аваисом Рашидом (Pauline Anthonysamy, Phil Greenwood, Awais Rashid, Lancaster University, UK).
Хотя сайты социальных сетей продолжают привлекать миллионы пользователей по всему миру, в них продолжает нарушаться конфиденциальность данных, что приводит к неудовлетворенности и недоверию пользователей. Несмотря на многочисленные попытки исправления этой ситуации большая часть пользователей социальных сетей так и не знает, как происходит управление их персональной информацией, и как работают средства поддержки конфиденциальности.
Чтобы продемонстрировать наличие средств, защищающих конфиденциальность, провайдеры социальных сетей должны показать, что средства поддержки конфиденциальности отражают установленную политику конфиденциальности. Но можно ли установить доступное для контроля отображение между двумя этими сущностями?
Для ответа на этот вопрос авторы исследовали доступные для наблюдения взаимосвязи политики и функций управления известных социальных сетей. Под политикой конфиденциальности понимались действия, выполняемые на сайте социальной сети над данными, поставляемыми пользователями. Средства поддержки конфиденциальности – это операции, предоставляемые пользователям для управления персональной информацией. Доступные для наблюдения взаимосвязи – это пользовательское восприятие взаимодействия с социальной сетью, т.е. то, как пользователь видит взаимодействие, реализованное на основе средств поддержки конфиденциальности, и то, как эти средства соотносятся с политикой конфиденциальности данной социальной сети.
Выполненный анализ позволяет ответить на три вопроса:
- Что общее у политик конфиденциальности разных социальных сетей?
- Какие средства поддержки конфиденциальности доступны пользователям социальных сетей?
- До какой степени можно проследить взаимосвязь между политикой конфиденциальности и средствами ее поддержки?
Исследование также показало наличие значительного разрыва между политиками конфиденциальности и средствами поддержки в большинстве социальных сетей. Формальное описание разработанного метода обеспечивает возможность его применения в других областях, связанных с наличием контента, генерируемого пользователями.
Последняя крупная статья июньского номера представлена Е. Томасом Эвингом, Самах Гад и Нареном Рамакришной (E. Thomas Ewing, Samah Gad, Naren Ramakrishnan, Virginia Tech) и называется «Анализ архивных газет для изучения распространения эпидемий» («Gaining Insights into Epidemics by Mining Historical Newspapers»).
Органы здравоохранения всегда находятся в состоянии готовности к появлению сообщений о вспышках эпидемий смертельно опасных заболеваний, чтобы принять меры на случай возникновения пандемии и скоординировать действия на местном, национальном и мировом уровнях.
Анализ документальных источников, посвященных пандемиям, может обеспечить полезные знания о способах распространения заболеваний, уязвимостях человеческого общества, действенности медицинской помощи и т.д. С этой целью в проекте, выполняемом авторами статьи, новые методы интеллектуального анализа данных применяются к корпусу оцифрованных газет, вышедших в 1918 г. во время эпидемии «испанки».

Заглавная статья газеты Colorado Springs Gazette, посвященная мерам общественного здравоохранения, принятым в ответ на возникновение пандемии испанки.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

