2012 г.
Совместная разработка: путь к экзафлопсам
Сергей Кузнецов
Обзор ноябрьского 2011 г. номера журнала Computer (IEEE Computer Society, V. 44, No 11, ноябрь, 2011).
Авторская редакция.
Также обзор опубликован в журнале «Открытые системы»
Темой ноябрьского номера журнала Computer является совместная разработка аппаратуры и программного обеспечения систем экзафлопсного диапазона (codesign for exascale systems). Этой теме посвящены три полноценных статьи, которым предшествует вводная заметка приглашенных редакторов под названием «Совместная разработка систем и приложений: прокладывание пути к вычислениям экзафлопсного диапазона» («Codesign for Systems and Applications: Charting the Path to Exascale Computing»). Редакторами тематической подборки являются Владимир Гетов, Адольфи Хойзи и Харви Вассерман (Vladimir Getov, University of Westminster, Adolfy Hoisie, Pacific Northwest National Laboratory, Harvey J. Wasserman, Lawrence Berkeley National Laboratory).
В 21-м веке наука о вычислениях (computational science) стала жизненно важным инструментом, оказывающим решающее воздействие на развитие практически всех научных и инженерных дисциплин, включая многие области, которые имеют значительное общественное влияние. Постоянная потребность в возрастающей вычислительной мощности стимулировала сообщество высокопроизводительных вычислений (high-performance computing, HPC) начать искать пути к обеспечению вычислений экзафлопсного диапазона (exascale computing).
Чтобы обеспечить высокоэффективные экзафлопсные вычисления, требуется решить ряд сложнейших проблем. В прошлом рост производительности вычислений происходил за счет комбинации повышения рабочей частоты процессоров и увеличения размеров систем. Для достижения возможности вычислений экзафлопсного диапазона при имеющихся ограничениях на надежность и энергопотребление систем, а также при неизбежном возрастании на несколько порядков требуемого уровня параллелизма приведет к изменению способов разработки систем и приложений.
Недавнее исследование, выполненное в DARPA, показало, что даже при наличии технических возможностей экзафлопсные системы, разработанные по применяемой в настоящее время технологии, были бы непрактичными, поскольку потребляли бы энергию в сотни мегаватт в час и являлись бы недопустимо ненадежными. Таким образом, рост частоты процессоров больше не подчиняется закону Мура, и целью сообщества HPC становится достижение сверхвысокой производительности при наличии строгих ограничений на надежность и энергопотребление.
Проблемы, с которыми столкнется сообщество HPC на пути к экзафлопным вычислениям, настолько же важны для всех архитектур и средств крупномасштабного компьютинга, не только для самых крупных и не только для тех, которые имеют отношение к научным вычислениям. В разных областях могут различаться рабочие нагрузки, но проблемы энергопотребления являются общими. Поскольку потребляемая энергия является важнейшей аппаратной проблемой, эффективность энергопотребления будет важна для вычислений любого масштаба. Более того, проблемы потребления энергии будут влиять на все уровни вычислительных систем, включая процессоры, взаимосвязи, алгоритмы, программное обеспечение и модели программирования.
Сложность пугающе разрастающегося пространства ограничений вынуждает искать новые тактики и новые подходы оптимизации, новые методологии разработки систем. Например, громадные расходы энергии на перемещение данных приводят к потребности в минимизации таких перемещений, и эту задачу требуется решать на всех уровнях системы, от аппаратуры до прикладного программного обеспечения.
Аналогичным образом, для оптимизации триады «производительность/потребляемая энергия/надежность» требуется переосмыслить алгоритмы, модели программирования и аппаратную архитектуру, а для этого нужно добиться невиданного уровня сотрудничества в области совместной разработки аппаратных средств, системных архитектур, системного программного обеспечения и приложений. Для этого необходим совершенно новый подход, основанный на одновременном проектировании и разработке всех уровней систем с использованием согласованного набора параметров и точных количественно оцениваемых методологий.
Для встраиваемых систем совместная разработка обычно означает разделение понятий процесса разработки с целью создания систем, соответствующих требованиям производительности, отлаженности и другим спецификациям, в более коротком цикле разработки. Цель этого подхода, используемые методологии и получаемые преимущества являются общепризнанными в течение многих лет. Ключевой особенностью подхода является достижение общесистемных целей путем нахождения оптимального соотношения аппаратных и программных средств в ходе интегрированного процесса совместной разработки. Дополнительное преимущество достигается за счет автоматизации или полуавтоматизации этого процесса, но наиболее важным аспектом является одновременность разработки: аппаратные и программные средства разрабатываются реально параллельно.
В подходе совместной разработки встроенных систем неопределенной оставалась точная природа взаимодействий аппаратных и программных средств. Со временем эти взаимодействия эволюционировали на основе расширяющегося использования усовершенствованных инструментов автоматизации разработки; ускоренных инструментов разработки специализированных интегральных схем, позволяющих быстро и недорого реализовывать сложные алгоритмы на уровне аппаратных схем; технологии вычислений с ограниченным набором команд (reduced-instruction-set computing), обеспечивающей возможность программной реализации традиционно аппаратных функций.
Во многом совместная разработка встраиваемых систем понадобилась из-за того, что разнообразные факторы привели к целесообразности использования программного обеспечения в системах, которые ранее полностью основывались на аппаратных средствах. В результате усложнилось программное обеспечение микроконтроллеров, цифровых сигнальных процессоров (digital signal processor) и даже процессоров общего назначения. Дополнительную роль сыграли снижающаяся стоимость микроконтроллеров, быстро возрастающее количество доступных транзисторов, появление развитой технологии эмуляции и возрастающая эффективность компиляторов языков программирования высокого уровня. Основной мотивировкой подхода была потребность в средствах, позволяющих справиться с возрастающей сложностью встраиваемых систем, что требуется и для достижения возможности вычислений экзафлопсного диапазона.
Особенностью встраиваемых систем является наличие всего лишь нескольких приложений, известных во время разработки системы и не программируемых конечными пользователями. Для этих приложений имеются требования фиксированного времени выполнения, т.е. дополнительная динамически обеспечиваемая мощность энергии для них не нужна. При совместной разработке встраиваемых систем учитываются стоимость, потребляемая энергия, предсказуемость и соответствие установленным временным характеристикам.
В отличие от этого, в вычислительных системах общего назначения выполняется широкий класс приложений, программируемых конечными пользователями. Чем быстрее эти приложения выполняются, тем лучше, а для этого в критерии разработки требуется включать стоимость и пиковую скорость. Суть проблемы совместной разработки систем экзафлопсного диапазона состоит в том, что при использовании критериев разработки встраиваемых систем (стоимость и энергопотребление) требуется создавать системы, полезные и эффективные при выполнении разнообразных научных приложений. «Одноразовые» экзафлопсные системы обречены на неудачу.
В области HPC также используется совместная разработка, и поэтому этот подход не является полностью новым для экзафлопсных вычислений. Подход совместной разработки использовался, в частности, при создании суперкомпьютера BlueGene/L компании IBM и в проекте PERCS той же компании, выполнявшемся в рамках программы DARPA High-Productivity Computing Systems (HPCS). Два прекрасных дополнительных примера совместной разработки суперкомпьютеров для поддержки приложений молекулярной динамики представляют проекты MDGrape японского исследовательского института RIKEN и Anton лаборатории D.E. Shaw Research.
В проекте RoadRunner компании IBM были намечены пути к использованию гибридных архитектур, когда в систему в дополнение к процессорам общего назначения включаются сопроцессорные специализированные элементы, позволяющие ускорить выполнение конкретной рабочей нагрузки. Неоднородность результирующей архитектуры, для использования которой требуется смесь из нескольких моделей программирования, вызывает значительные проблемы, которые требуется решить для обеспечения полезности сопроцессорного подхода при разработке систем HPC, эффективных при выполнении широкого класса приложений. Кроме того, в приведенных примерах совместной разработки критерием успеха была производительность, а энергопотребление и надежность во внимание не принимались.
В настоящее время в сообществе HPC ощущается потребность в применении методов совместной разработки для создания систем и приложений экзафлопсного диапазона. Применяются следующие основные подходы:
- описание системы на высоком уровне абстракции;
- использование моделей, позволяющих анализировать и исследовать архитектуры систем, проверять истинность предположений, касающихся архитектуры, исследовать эксплуатационные параметры реализации и проверять, что архитектурные решения, сделанные на основе использования высокоуровневых моделей системы, были целесообразными;
- создание методологий и инструментальных средств с использованием которых разработчики могли бы «подправить» платформу, добавляя, удаляя или изменяя параметры для определения их влияния на архитектуру и производительность системы.
Для достижения возможности экзафлопсных вычислений требуется переосмыслить прикладное программное обеспечение, включая оптимизацию алгоритмов и кода программ с целью минимизации перемещения данных для обеспечения эффективного энергопотребления и реализации механизмов отказоустойчивости. Следовательно, эти виртуальные испытательные стенды требуются для выполнения начальной оптимизации разработчиками как систем, так и приложений до того момента, как действительно потребуются дорогостоящие настоящие реализации.
Первая регулярная статья тематической подборки написана Джон Шелф, Дэн Квинлан и Картис Янссен (John Shalf, Lawrence Berkeley National Laboratory, Dan Quinlan, Lawrence Livermore National Laboratory, Curtis Janssen, Sandia National Laboratories) и называется «Переосмысление совместной разработки аппаратуры и программного обеспечения систем экзафлопсного диапазона» («Rethinking Hardware-Software Codesign for Exascale Systems»).
В течение многих лет пользователи систем HPC наблюдали повышение пиковой производительности этих систем без соразмерного повышения производительности приложений. Кроме того, по мере того, как эти системы достигают экзафлопсного диапазона, их разработчики сталкиваются с многочисленными требованиями, относящимися к электрическому питанию. Ожидается, что расходы на энергоснабжение превысят стоимость приобретения систем HPC, что, в конце концов, ограничит уровень практичности их применения.
Если разработчики систем не будут упорно работать с поставщиками аппаратных средств и представителями научного сообщества над разработкой решений с улучшенной энергоэффективностью, эта тенденция приведет к кризису в индустрии HPC. В традиционных методологиях разработки систем HPC ограничениям энергопитания и аспектам отказоустойчивости не уделяется настолько большое внимание, которое требуется при создании экзафлопсных систем. Кроме того, можно предвидеть, что тектонические сдвиги в архитектуре компьютеров приведут к радикальным изменениям в модели программирования и программной среде в будущих компьютерных системах любого масштаба. У разработчиков аппаратных и программных компонентов систем HPC имеется насущная потребность в систематической методологии, отражающей будущие проблемы и ограничения разработки.
В программе создания систем и приложений экзафлопсного диапазона Министерства энергетики США (US Department of Energy’s (DoE) основной стратегией считается совместная разработка аппаратуры и программного обеспечения. Идея состоит в том, чтобы создать новое партнерство разработчиков, в котором ученые из прикладных областей начинают участвовать в коллективном итерационном процессе разработки задолго до того, как соответствующая система выводится на рынок. Ускорение этого цикла разработки могло бы привести к значительному повышению энергоэффективности и практически полезной производительности систем.
В совместном проекте, в котором участвуют три лаборатории, упомянутые выше, формируется комплексная среда совместной разработки аппаратуры и программного обеспечения Codesign for Exascale (CoDEx), который обеспечит разработчикам приложений и алгоритмов небывалую возможность влиять на направление развития будущих архитектур систем HPC в соответствии с требованиями программы DoE. В CoDEx объединяются три элемента:
- очень гибкая потактовая симуляция архитектур узлов с использованием результатов проекта Green Flash Национальной Лоуренсовской лаборатория в Беркли (Lawrence Berkeley National Laboratory);
- новые средства извлечения и экзамасштабной экстраполяции трасс обращений к памяти и сетевых взаимодействий с использованием инфраструктуры компилятора ROSE Ливерморской национальной лаборатории имени Лоуренса (Lawrence Livermore National Laboratory);
- масштабируемая симуляция массивных межсетевых соединений с использованием набора инструментальных средств Национальной лаборатории Сандия (Structural Simulation Toolkit (SST)/macro).
Эти инструментальные средства смогут поддерживать процесс совместной разработки аппаратуры и программного обеспечения, весьма пригодный для разработки сложных систем HPC.
Статья «Совместная разработка кластеров, основанных на InfiniBand» («Codesign for InfiniBand Clusters») представлена Саянтаном Суром, Кришной Кандаллой, харри Субрамони, Дхабалесваром Пандой и Карен Томко (Sayantan Sur, Sreeram Potluri, Krishna Kandalla, Hari Subramoni, Dhabaleswar K. Panda, Ohio State University, Karen Tomko, Ohio Supercomputer Center).
Научные вычисления жизненно необходимы во многих областях человеческой деятельности – от поиска новых лекарственных средств и авиакосмической промышленности до прогнозирования погоды и сейсмического анализа. В научных вычислениях приходится иметь дело с громадными объемами данных, и соответствующие алгоритмы основаны на использовании математических моделей. Из-за своей насыщенности вычислениями и данными такие приложения часто бывают параллельными, т.е. вычисления выполняются одновременно на нескольких компьютерах.
В списке TOP500 перечисляются наиболее мощные суперкомпьютерные центры всего мира. В настоящее время системы высшего класса преодолели петафлопсный барьер (1015 операций над числами с плавающей точкой в секунду). Эксперты ожидают достижения экзафлопсного уровня (1018) в течение десятилетия. Этот быстрый рост мощности высокопроизводительных вычислений опирается на доступность недорогих компонентов массового спроса: процессоры общего назначения компаний Intel, AMD и IBM; графические процессоры Nvidia и других компаний; шины ввода-вывода типа PCI Express и аппаратура межсетевых соединений типа InfiniBand.
По мере роста размеров и мощности компьютеров должны эволюционировать и стеки коммуникаций и приложений. Основным принципом разработки высокопроизводительных вычислительных систем является раскрытие (а не сокрытие) тех возможностей системы, которые позволяют добиться более высокой производительности. Однако по мере возрастания сложности систем разработчики коммуникационных библиотек стремятся раскрывать их таким образом, чтобы не перегрузить деталями разработчиками приложений.
Чтобы сохранить возможность масштабирования приложений на все более мощных системах, необходимо исследовать новые архитектуры с системной точки зрения и новые парадигмы программирования – с позиций разработчиков приложений. В подходе к совместной разработке, описываемом в статье, применяются развитые возможности аппаратуры межсетевых соединений массового спроса InfiniBand, разработка опирается на использование современной коммуникационной библиотеки поддержки интерфейса отмена сообщениями (message-passing interface, MPI), а затем приложения модифицируются так, чтобы в них максимально применялись эти новые возможности.
Авторами последней статьи тематической подборки являются Даррен Кербисон, Абхинав Вишну, Кевин Вишну и Адольфи Хойси (Darren J. Kerbyson, Abhinav Vishnu, Kevin J. Barker, Adolfy Hoisie, Pacific Northwest National Laboratory). Статья называется «Проблемы совместной разработки систем экзафлопсного диапазона: производительность, энергопотребление и надежность» («Codesign Challenges for Exascale Systems: Performance, Power, and Reliability»).
Сложность современных систем с учетом их масштабности, наличия иерархий памяти и запутанности топологии межсетевых соединений делает оптимизацию хотя бы лишь производительности колоссальной задачей. В настоящее время привычным делом являются системы с сотнями тысяч процессоров, иерархии памяти обычно включают три уровня кэша, и в ближайшее время будут доминировать топологии межсетевых соединений с петлями (mesh), утолщенными деревьями (fat tree) и полной иерерахической связанностью.
Оптимизация по отношению к некоторой архитектуре – это всего лишь одна из многих фаз жизненного цикла приложения. Однако этот распространенный процесс можно назвать «односторонним», поскольку он применяется по отношению к уже разработанным и реализованным архитектурам. У будущих систем и приложений будут иметься дополнительные требования производительности, энергопотребления и отказоустойчивости, порождающие многомерную проблему оптимизации. Процесс совместной разработки может помочь совместно оптимизировать два или большее число подобных характеристик с целью получения улучшенного решения. В конечном счете, этот процесс ведет к созданию настраиваемых систем и рабочих нагрузок экзафлопсного диапазона.
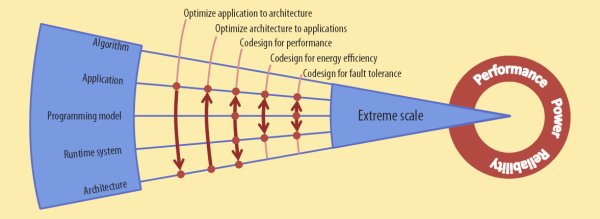
Пять факторов, влияющих на возрастание сложности систем экзаплопсного диапазона: алгоритмы, приложения, модели программирования, системы поддержки времени выполнения и архитектуры. Стрелки показывают примеры взаимного влияния этих факторов в ходе проектирования и совместной разработки систем экстремально крупного масштаба
Как показывает рисунок, в процессе совместной разработки крупномасштабных систем пять факторов способствует повышению сложности:
- Разные алгоритмы, используемые в вычислениях, могут обладать разными вычислительными характеристиками. Реализации сеточных алгоритмов с неизменным шагом сетки требуют больше памяти и обменов сообщениями, чем реализации алгоритмов с измельчением сетки.
- Приложение является реализацией некоторого метода и компонентов общей рабочей нагрузки. При совместном использовании нескольких приложений можно одновременно обследовать несколько аспектов физической системы.
- В основе приложения лежит модель программирования, определяющая способ представления вычислений. Распространены два подхода к представлению параллелизма: подход, основанный на процессах, при применении которого межпроцессные взаимодействия представляются явным образом с использованием, например, MPI, и подход, в центре которого находятся данные, и доступ к любым данным системы может быть произведен с любого узла (например, Global Arrays, Unified Parallel C (UPC) и Co-Array Fortran (CAF)).
- Система поддержки времени выполнения обеспечивает удовлетворение динамических требований приложений и отображение этих требований на ресурсы системы. Такая система включает, в частности, управление процессами и данными.
- Архитектура включает микроархитектуру ядер процессоров, компоновку ядер внутри кристалла, иерархию памяти, системные межсетевые соединения и подсистемы хранения данных.
Ни один процесс совместной разработки не охватывает полностью все эти факторы, но в некоторых из них принимаются во внимание поднаборы факторов и их соотношения:
- Оптимизация приложения по отношению к архитектуре. При наличии уже реализованной системной архитектуры в этом процессе требуется отобразить прикладные рабочие нагрузки на характеристики архитектуры. Этот подход распространен в областях разработки приложений и программной инженерии, но обычно не считается совместной разработкой.
- Оптимизация архитектуры по отношению к приложениям. При наличии уже реализованного приложения этот процесс оптимизирует архитектуру для достижения высокой производительности. Примером является направленная на достижение высокой производительности приложений разработка крупномасштабных систем IBM Power7.
- Совместная разработка для оптимизации производительности. Этот подход позволяет добиться наилучшего соответствия между приложением и архитектурой и обеспечивает потенциал для достижения наивысшей производительности. Примером является процесс разработки приложений для первой петафлопсной системы IBM Roadrunner.
- Совместная разработка для повышения эффективности энергопотребления. Энергопотребление экстремально масштабных систем становиться все более существенным ограничением разработки и фактором, влияющим на совокупную стоимость владения такими системами. Сегодняшние крупнейшие системы потребляют мощность более чем в 10 мегаватт, что приводит к ежегодным расходам не менее 10 миллионов долларов. Эксперименты авторов статьи в области совместной разработки для повышения эффективности потребления энергии включали создание приложения, обеспечивающего информацию об ожидаемых периодах простоя, и системы поддержки времени выполнения, способствующей снижению энергопотребления.
- Совместная разработка для обеспечения отказоустойчивости. Решающим фактором использования экстремально масштабных систем является их отказоустойчивость. Традиционные методы на основе механизмов установки контрольных точек и восстановления после отказов не масштабируются должным образом при росте размеров системы. Однако использование избирательных методов (таких как репликация только важнейших данных в памяти узлов системы) может помочь восстановить состояние отказавших узлов и продолжить выполнение задания. В этом направлении авторы статьи используют процесс совместной разработки, затрагивающий факторы приложения, модели программирования и подсистемы поддержки времени выполнения.
Вне тематической подборки опубликованы три крупных статьи. Статью «iPlant Collaborative: киберинфраструктура снабжения мира продовольствием» («The iPlant Collaborative: Cyberinfrastructure to Feed the World») представил Дан Станционе (Dan Stanzione, University of Texas at Austin).
Общепризнанна важность вычислений для получения новых научных результатов, и финансирующие организации десятилетиями вкладывают капитал в крупномасштабные вычисления, поддерживающие научные исследования. Одним из наиболее крупных достижений является среда Extreme Science and Engineering Discovery Environment (XSEDE), ранее называвшаяся TeraGrid. Эта среда была создана в ходе пятилетнего проекта, поддерживавшегося Национальным научным фондом (National Science Foundation, NSF), и предоставляет тысячам исследователей со всего мира доступ к 16 суперкомпьютерам и развитым электронным ресурсам.
Проект iPlant Collaborative во многих отношениях представляет пример нового подхода к крупномасштабным инвестициям в научные вычисления. iPlant является одним из первых киберинфраструктурным (cyberinfrastructure, CI) проектом, финансируемым NSF и направленным на поддержку наук, опирающихся на истинные, а не модельные данные. Кроме того, этот проект должен предоставить иследователям не просто доступ к суперкомпьютерной системе, базе данных и инструментальным средствам, а снабдить их полной архитектурой CI, предназначенной для поддержки растениеводства. Наконец, проект iPlant направлен не на поддержку решения каких-либо конкретных научных задач, а опирается на уникальный синтетический подход, позволяющий научному сообществу формулировать фундаментальные проблемы, решению которых способствует CI. Проект iPlant актуален для профессионалов в области вычислений во многих отношениях, поскольку в растениеводстве имеются многочисленные сложные вычислительные проблемы.
Почему таких вычислительных инвестиций заслужила ботаника, если учесть, что общее финансирование науки продолжает сокращаться, а в других научных областях в части вычислений в прошлом имелись крупные достижения? Ответ на этот вопрос состоит из трех частей.
Во-первых, растения критически важны для обеспечения надежного будущего: ожидаемому к 2050-му году 9,3-миллиардному населению Земли потребуется в два раза больше продовольствия. Во-вторых, ботаника находится на той стадии, когда от возможности вычислений зависит получение новых научных результатов. Например, при наличии имеющихся тенденций в технологии получения последовательностей ДНК небольшая лаборатория может каждые несколько дней производить терабайт данных, и скорость производства данных растет быстрее, чем требовал бы закон Мура. В-третьих, сегодняшняя ботаника – это наука, опирающаяся на истинные данные, и она может быть хорошей моделью для внедрения CI, которые в течение многих лет служили наукам, основанным на моделировании.
Авторами статьи «Защита от уязвимостей переполнения буфера» («Defending against Buffer-Overflow Vulnerabilities») являются Бинду Мадхави Падманабхуни и Хи Бен Куан Тан (Bindu Madhavi Padmanabhuni, Hee Beng Kuan Tan, Nanyang Technological University, Singapore).
В 2003 г. уязвимости переполнения буфера называли “уязвимостями десятилетия”. В следующем году сообщество Open Web Application Security Project (OWASP) сочло этот класс уязвимостей пятой по уровню серьезности слабостью Web-приложений. За первые пять месяцев 2010 г. В Национальной базе данных уязвимостей (National Vulnerability Database) было зафиксировано 176 уязвимостей этой категории, из которых 136 были признаны серьезными. Переполнение буфера и сегодня остается одной из основных дыр в системах безопасности, занимая третье место в списке 25-ти наиболее опасных программных ошибок (Top 25 Most Dangerous Software Errors) Common Weakness Enumeration/SANS.
Переполнение буфера происходит во время выполнения программы, когда приложение производит запись за пределами границ заранее выделенного буфера фиксированного размера. Эти данные затирают содержимое смежных ячеек памяти и изменяют поведение программы. Эта ошибка возможна из-за отсутствия операций проверки выхода адреса за пределы буфера. Уязвимости такого типа обычно свойственны приложениям, написанным на языках Си и Си++, поскольку в них допускается запись в любую область памяти без проверки выхода адреса за установленные границы.
Обзор компьютерных вторжений с использованием уязвимостей переполнения буфера и анализ имеющихся решений для защиты от таких вторжений демонстрируют недостатки существующих систем безопасности, а также обеспечивают основу для внесения в них изменений, защищающих от таких вторжений.
Последнюю крупную статью номера написали Джузеппе Нути, Махнуш Мирфаеми, Филип Треливен и Чайакорн Йингсаери (Giuseppe Nuti, Mahnoosh Mirghaemi, Philip Treleaven, Chaiyakorn Yingsaeree, UK Centre in Financial Computing, London) . Она называется «Алгоритмический трейдинг» («Algorithmic Trading»).
Достижения телекоммуникационных и компьютерных технологий последнего десятилетия привели к созданию сложных динамических мировых рынков, что, в свою очередь, стимулирует развитие торговли с использованием компьютерных программ и приводит к появлению систем алгоритмического трейдинга, автоматизирующих одну или несколько стадий процесса трейдинга. Эти системы направлены на поиск аномалий в рыночных ценах, использование статистических паттернов одного или нескольких финансовых рынков, оптимальное исполнение заказов, маскировку намерений трейдера и обнаружение и использование стратегий конкурентов. В конечном счете, движущей силой любой системы трейдинга является прибыль – в форме экономии расходов, коммисионных, получаемых от клиентов, или выручки от собственной торговли.
Институциональные трейдеры и менеджеры пенсионных фондов, паевых фондов и фондов венчурного инвестирования все чаще внедряют алгоритмические трейдинговые системы. Эти системы в настоящее время управляют 50-60% всех торговых операций над акциями в США и ЕС. Высокочастотный алгоритмический трейдинг в 2009 г. отвечал за продажу и покупку 60% объемов акций в США и является основной движущей силой развития компьютинга и аналитики, в особенности, машинного обучения и вычислений с использованием Grid и графических процессоров.
Однако алгоритмический трейдинг является и серьезной проблемой для контрольно-надзорных органов, как иллюстрируют события 6 мая 2010 г., когда индекс Доу-Джонса упал на 600 пунктов в течение 5 минут, что привело к потере 600 миллиардов долларов в рыночной стоимости американских облигаций. Это происшествие показывает недостаточность знаний о высокочастотном алгоритмическом трейдинге и его потенциальную уязвимость. Чтобы защититься от возможности повторения таких событий, требуется глубокое понимание процесса трейдинга, которое частично обеспечивается материалом этой статьи.
Всего вам доброго, Сергей Кузнецов (kuzloc@ispras.ru).

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
