2011 г.
Компьютерные потребности финансовой индустрии
Сергей Кузнецов
Обзор декабрьского 2010 г. номера журнала Computer (IEEE Computer Society, V. 43, No 12, Декабрь, 2010).
Авторская редакция.
Также обзор опубликован в журнале "Открытые системы"
Темой декабрьского номера в 2010 г. является «вычислительная наука о финансах» (Computational Finance). Замечу, что я не нашел в Рунет общераспространенного русскоязычного термина, соответствующего Computational Finance. Имеются попытки называть эту область «вычислительными финансами» (нескладная калька англоязычного термина), а иногда «финансовой инженерией» или «прикладным финансовым анализом» (что ограничивает смысл термина). По этой причине я буду использовать в данном обзоре свой термин, не претендуя на его повсеместное внедрение. Теме номера посвящены три из пяти больших статей номера (приглашенные редакторы отсутствуют).
Первая статья называется так же, как и тема номера. Ее написали Чаякорн Йингсаери, Филип Треливен и Джузеппе Нути (Chaiyakorn Yingsaeree, Philip Treleaven, UK Centre for Financial Computing, London, Giuseppe Nuti, Citadel Securities, New York).
Банки и инвестиционные фонды все чаще основывают свою конкурентоспособность на качестве своих количественных методов – программирования, аналитики и финансовых приложений, и эта тенденция делает критически важной вычислительную науку о финансах.
Вычислительная наука о финансах – это междисциплинарная область, которая направлена, прежде всего, на поддержку индустрии финансовых услуг. Эта область опирается на финансовую математику (mathematical finance), численные методы и компьютерное моделирование (computer simulation) для поддержки принятия решений по поводу торговых и страховых сделок, а также инвестиций. Кроме того, она облегчает управление портфельными рисками (рисками, связанными с качеством активов банков и их распределением по отдельным видам и категориям).
Между родственными областями финансового моделирования, финансовой математики и финансовой инженерии (financial engineering) имеется значительное перекрытие.
- Финансовое моделирование, являясь наиболее общей из этих трех связанных областей, отвечает за финансовые вычисления, такие как моделирование оценки стоимости опционов (option pricing), с первичной целью моделирования стоимости в условиях неопределенности.
- Финансовая математика – это ветвь прикладной математики, занимающаяся финансовыми рынками. Традиционно ассоциируемая со стохастическим исчислением, на практике эта дисциплина охватывает несколько направлений прикладной математики.
- Финансовая инженерия фокусируется на инновациях, помогая производить новые ценные бумаги, такие как опционы и деривативы фьючерских рынков.
| Аналитический метод |
Техника программирования |
Финансовые приложения |
| Классификация |
Методы, основанные на правилах: обучение деревьев решений, обучение первого порядка.
Геометрические методы: нейронные сети, метод опорных векторов.
Вероятностные методы: наивные Байесовские классификаторы, классификаторы по максимальной энтропии.
Методы, основанные на прототипах: классификация по ближайшим соседям. |
Выбор акций
Прогнозы банкротств
Рейтинг облигаций
Выявление мошенничества |
| Оптимизация |
Модельная «закалка» (simulated annealing), генетические алгоритмы.
Динамическая оптимизация: динамическое программирование, укрепляющее обучение (reinforcement learning).
Статическая оптимизация: симплекс-методы, методы внутренней точки. |
Выбор портфеля
Управление рисками
Управление активами и пассивами |
| Регрессия |
Словарное представление (dictionary representation): линейная регрессия, полиномиальные оценки, вейвлетная регрессия, нейронные сети.
Ядерное представление (kernel representation): k ближайших соседей, методы опорных векторов. |
Финансовые прогнозы.
Опционное ценообразование
Прогнозы рынков |
| Моделирование |
Стохастическое моделирование: Марковские цепи, моделирование методом Монте-Карло.
Моделирование на основе агентов: генетические алгоритмы, генетическое программирование. |
Опционное ценообразование
Микроструктура рынков |
В таблице показана простая таксономия вычислительной науки о финансах. Эта наука является подобластью науки о вычислениях (computational science) и состоит из двух разных ветвей. Интеллектуальный анализ данных (data mining) позволяет разыскивать скрытые паттерны в огромных массивах данных, позволяя выдвигать гипотезы. Компьютерное моделирование обеспечивает анализ на основе симуляции, позволяя проверить осмысленность этих гипотез. К числу дополнительных дисциплин, включаемых в вычислительную науку о финансах, относятся компьютерные символьные вычисления, численный анализ, вычислительная геометрия (computational geometry), а также визуализация и машинная графика.
Следующую статью написали Бадриш Чандрамули, Мохамед Али, Джонатан Голдстейн, Бейсин Сежин и Балан Сету Раман (Badrish Chandramouli, Mohamed Ali, Jonathan Goldstein, Beysim Sezgin, Balan Sethu Raman, Microsoft). Статья называется «Системы управления потоками данных для вычислительной науки о финансах» («Data Stream Management Systems for Computational Finance»).
У вычислительных финансовых приложений имеются уникальные потребности, связанные с повсеместным применением сетевых технологий и непрерывно продолжающейся автоматизацией бизнес-процессов. Для достижения эффективности этим приложениям требуется быстрая обработка нескончаемого потока данных. Любая система, управляющая этим потоком, должна уметь с очень низкой задержкой обрабатывать запросы над непрерывно изменяемыми данными и инкрементно включать результаты в происходящие бизнес-процессы. Такая система также должна поддерживать обработку данных, архивируемых для исторического анализа, что включает выполнение аналитических запросов и запросов обратного тестирования.
В этой быстро изменяющейся среде для большинства организаций основным требованием является сокращение задержки при обработке данных. Поэтому разработчики финансовых приложений часто предпочитают для каждой конкретной проблемы использовать специальные решения. Но такая специализация требует больших затрат, и, как правило, специализированные решения не слишком хорошо обобщаются, так что такой вариант плохо пригоден для предприятий с разнотипными приложениями.
Для построения таких финансовых приложений можно было бы использовать и базы данных. Технология баз данных не только обеспечивает простую и одновременно мощную модель данных, но также позволяет приложениям обращаться к системе с декларативными запросами над множествами элементов данных. Однако традиционные базы данных не удовлетворяют уникальным потребностям финансовых приложений, для которых требуется высокопроизводительная обработка сложных запросов над темпоральными данными.
Осознавая потребность в более реактивных универсальных платформах, многие организации начинают отдавать предпочтение системам управления потоками данных (СУПД – data stream management system, DSMS). СУПД – это промежуточное программное обеспечение, принимающее и обрабатывающее долговременные запросы над темпоральными потоками данных. При использовании СУПД приложения могут зарегистрировать в системе запросы, которые выполняются и инкрементно выдают результаты по мере поступления новых данных.
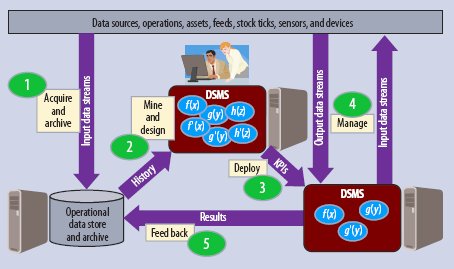
Поток исторических данных и данных реального времени в СУПД, поддерживающей приложение биржевых торгов
В СУПД используется цикл мониторинга данных, управления данными и анализа данных для поддержки сложных запросов потоковых финансовых приложений. В таких приложениях, включающих активности над потоками данных реального времени и историческими данными, важнейшим понятием является время. Одним из примеров является торговля на бирже. Приложения управления рисками должны выявлять различные модели изменения курсов ценных бумаг в соответствии с последними показателями, а модель торгов основывается на годами накапливаемых исторических данных. Другие приложения поддерживают трейдинговые решения на основе алгоритмов, обеспечивая финансовые рекомендации с использованием и исторических данных, и данных, прогнозирующих будущее.
В нескольких организациях, академических и коммерческих, разрабатываются прототипы и полностью функциональные СУПД. К их числу относятся:
- система Oracle Complex Event Processing (CEP), основанная на исследовательской модели Stanford Stream;
- СУПД StreamBase, основанная на исследовательских моделях Aurora и Borealis;
- система StreamInsight, основанная на результатах проекта Complex Event Detection and Response (CEDR) компании Microsoft;
- IBM InfoSphere Streams, основанная на результатах исследовательского проекта System S, и
- СУПД Coral8 (купленная Sybase).
Разработчики финансовых приложений на основе этих систем могут выбирать разные модели выполнения, семантику и способы выполнения запросов, механизмы расширений и т.д.
Последняя статья тематической подборки называется «Высокопроизводительные вычисления на Уолл-Стрит» («High-Performance Computing on Wall Street») и написана Брэдом Спайерсом и Денисом Уэйлзом (Brad Spiers, Denis Wallez, Bank of America Merrill Lynch).
В последние годы наблюдается взрывообразный рост использования высокопроизводительных вычислений в индустрии финансовых услуг. Частично это объясняется появлением очень сложных продуктов (в частности, опционов), для поддержки которых требуются финансовые модели, опирающиеся на гораздо больший объем вычислений. Эту тенденцию укрепил мировой экономический кризис 2008 года, вынудивший правительственных чиновников обязать финансовые компании применять новые механизмы управления рисками.
Авторы статьи анализируют основные высокопроизводительные приложения, применяемые на Уолл-Стрит, а также алгоритмы, аппаратные средства и языки программирования, используемые при создании и использовании этих систем. Кроме того, в статье исследуются проблемы, с которыми сталкиваются программисты при переходе к распараллеливанию финансовых приложений для использования соответствующих возможностей новых компьютеров.
Вне тематической подборки в декабрьском номере журнала опубликованы две большие статьи. Статью «Медиаскопия: идентификация мультимедийного контента для управления цифровыми правами» («Mediaprinting: Identifying Multimedia Content for Digital Rights Management») представили Тайжун Хуанг, Йонфонг Тиан, Вен Гао и Жиан Лю (Tiejun Huang, Yonghong Tian, Wen Gao, Peking University, Jian Lu, Shanda Interactive Entertainment).
Internet коренным образом изменяет порядок распространения мультимедийного контента, обеспечивая пользователям небывалые возможности совместного использования цифровых фотографий, аудио- и видео-файлов. Но это одновременно ставит серьезные проблемы при управлении цифровыми правами (digital rights management, DRM).
Простота загрузки и скачивания любого материала значительно облегчает и злоупотребления, пиратство, плагиат и незаконное присваивание. В 2000 г. компания A&M Records и другие ведущие компании грамзаписей подали в суд на сайт Napster, поддерживавший файлообменную пиринговую сеть для совместного использования музыкальных файлов, за пособничество нарушению авторских прав. Семь лет спустя компания Viacom вызвала в суд YouTube за «массовое намеренное нарушение авторских прав». Эти и другие судебные процессы подчеркивают возрастание важности защиты контента и управления авторскими правами по мере того, как Internet становится всемирной платформой распространения мультимедийного контента.
С технологических позиций, термин DRM относится к технологиям и системам, которые защищают права, связанные с использованием цифрового контента, и обеспечивают соблюдение этих прав. В последние два десятилетия появились два превентивных подхода к управлению цифровыми правами: шифрование мультимедийного контента для преотвращения неавторизованного доступа и встраивание в контент «водяных знаков» для последующего установления его подлинности. Однако у обоих подходов имеется много ограничений, и ни один из них не может помочь при решении проблемы с авторскими правами при наличии огромных объемов контента, распространяемого миллионами пользователей Internet.
Это привело к появлению нового подхода к управлению цифровыми правами, ориентированного на защиту авторских прав «задним числом» путем идентификации мультимедийного контента и проверки законности его распространения и совместного использования в Internet. Медиаграммы (mediaprint) – это компактные описатели, которые, в отличие от внешних идентификаторов (например, «водяных знаков»), присоединяемых к мультимедийному контенту, извлекаются из самого контента. Поэтому медиаграмму невозможно разрушить или подделать, поскольку ее всегда можно заново вычислить на основе контента. В отличие от криптографических хэш-кодов, которые вычисляются на основе бинарных данных и всегда являются исключительно уязвимыми и чувствительными к данным, медиаграммы устойчивы к разнообразным изменениям и преобразованиям одного и того же контента, но существенно различны для каждого отдельного элемента контента.
Медиаграммы при идентификации контента имеют сходство с отпечатками пальцев или спектрограммами голоса при идентификации личности. Для разных типов контента имеются разные типы медиаграмм, и поэтому медиаграммы для изображений, аудио- и видео-контента называются графограммами (imageprint), аудиограммами (audioprint) и видеограммами (videoprint) соответственно. Можно ввести также докграммы (docprint) для документов и софтграммы (softwareprint) для исходного кода программ. Можно было бы также назвать медиаграммы «отпечатками пальцев» мультимедийного контента, перцепционными хэш-кодами, аудио- и видео-сигнатурами и ДНК мультимедийного контента.

Рисунок иллюстрирует свойства устойчивости и уникальности медиаграмм. Здесь показаны 64-битные графограммы, полученные путем применения дискретного косинусного преобразования к двум исходным изображениям и шести преобразованным копиям каждого из них. Хотя внешне изображения очень похожи, у двух исходных изображений имеются разные графограммы (при вычислении с использованием расстояния Хэмминга сходство составляет 0.6563). При преобразовании изображений их графограммы остаются очень близкими.
Последняя крупная статья номера – «Формальная разработка приложений интеллектуального восприятия внешней среды» («Formal Design of Ambient Intelligence Applications») – написана Антонио Коронадо и Джузеппе Де Пьетро (Antonio Coronato, Giuseppe De Pietro, ICAR-CNR, Naples, Italy)
Интеллектуальное восприятие внешней среды (Ambient Intelligence, AmI) характеризует возможность программной системы воспринимать изменения физической среды, приспосабливаться к ним и реагировать на эти изменения. Технологии AmI все чаще применяются в критических системах с очень изменчивыми внешними условиями (например, в больницах, при ликвидации чрезвычайных ситуаций и при кризисном регулировании).
К приложениям AmI, в разработке которых участвуют авторы статьи, относятся система контроля пациентов больниц, а также системы удаленного мониторинга, обрабатывающие физиологические данные, поступающие из сетей физиологических датчиков и управляющих адаптеров устройств типа дозаторов инсулина. Такие приложения должны обрабатывать данные в реальном масштабе времени. Более того, при получении критических показателей требуется очень быстро поднять тревогу. Понятно, что функциональные некорректности или ошибки времени выполнения программных систем могут иметь катастрофические последствия для пациентов.
При создании таких критически важных приложений разработчики должны учитывать наличие жестких требований к надежности. Для достижения этой цели авторы используют формальные методы, повышающие надежность системы за счет устранения ошибок при спецификации требований и на ранних стадиях разработки. Формальные методы позволяют наиболее эффективно и четко специфицировать требования, предотвращая появление в них ошибок. В то же время, они обеспечивают средства формальной верификации требований, что позволяет выявлять и устранять ошибки в начале процесса разработки.
В течение многих лет авторы выполняют исследования в области мобильного компьютинга. В частности, они разрабатывали новые методы, инструментальные средства и сервисы для определения местоположения мобильных пользователей и ресурсов, придания мобильным средам свойства осведомленности о контексте и обеспечения возможности самоуправления компонентам программного обеспечения. Однако при переходе от прототипов к реальным системам AmI пришлось столкнуться с отсутствием как средств моделирования требований, так и четких процессов разработки. Поэтому авторы решили разработать собственную методологию формальной разработки приложений AmI. Ими создан соответствующий набор инструментальных средств, поддерживающих формальные методы спецификации требований и верификации этих спецификаций.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС