2010 г.
Глобальное потепление и ICT
Сергей Кузнецов
Обзор январьского 2010 г. номера журнала Computer (IEEE Computer Society, V. 43, No 1, февраль, 2010).
Авторская редакция.
Также обзор опубликован в журнале "Открытые системы"
Традиционно основная часть статей январского номера журнала посвящена перспективным технологиям (четыре из шести больших статей). Эти статьи, как и две статьи, посвященные отдельным исследовательским проектам, не связаны какой-либо общей темой.
Первую большую статью представил Ларри Смарр (Larry Smarr, University of California, San Diego). Статья называется «Проект GreenLight: оптимизация кибер-инфрастуктуры для мира с ограниченным выбросом парниковых газов» («Project GreenLight: Optimizing Cyber-infrastructure for a Carbon-Constrained World»).
Все теперь знают о возрастающей угрозе глобального изменения климата, однако менее известно то, что сообщество информационных и телекоммуникационных технологий (information and communication technology, ICT) может сыграть ключевую роль в преодолении грядущего кризиса. Группа климата (Climate Group) консорциума Глобальная инициатива по экологической устойчивости (Global eSustainability Initiative, GeSI) недавно опубликовала на эту тему отчет Smart 2020: Enabling the Low Carbon Economy in the Information Age. В нем утверждается, что повышение эффективности потребления энергии системами ICT, а также применение этих систем для оптимизации сетей электропередачи, систем поставок, интеллектуальных транспортных систем и строительной инфраструктуры могло бы сократить на 15% объем выбросов парниковых газов (greenhouse gas, GHG), ожидаемый в мире к 2020 г. Это могло бы существенно содействовать глобальной цели общего сокращения объема выброса GHG.
В первой части своей статьи Смарр говорит о некоторых важных научных результатах, иллюстрирующих изменения, которые уже происходят в атмосфере Земли и начинают воздействовать на климатические условия. Вторая часть, более близкая к компьютерной тематике, посвящена обсуждению роли, которую в настоящее время играет ICT в загрязнении атмосферы парниковыми газами, и некоторым достижениям, которые могут позволить снизить уровень выбросов GHG по вине ICT.
В отчете Smart 2020 приводятся оценки, в соответствии с которыми в 2007 г. вклад индустрии ICT в мировые выбросы GSG составил 2-3% от общего объема выбросов, причем объем выбросов GSG по вине индустрии ICT ежегодно возрастает примерно на 6%, т.е. с 2002 до 2020 г. этот объем почти утроится. В диаграммах на рисунке учитываются метан, закись азота и другие парниковые газы в «эквиваленте CO2». Темно-зеленый цвет на диаграммах показывает выбросы, связанные с изготовлением и утилизацией оборудования. Светло-зеленый цвет представляет выбросы «эквивалента CO2», связанные с производством электроэнергии, требуемой для питания и охлаждения оборудования ICT.
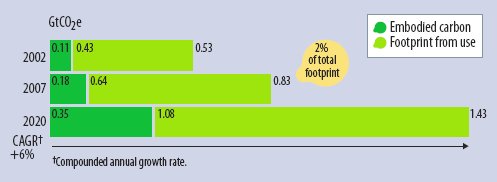
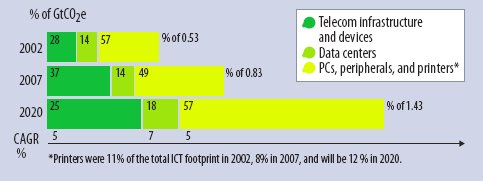
В отчете также производится классификация выбросов GSG по вине ICT: выбросы из-за потребности поддержки фиксированной и мобильной инфраструктур телекоммуникаций/Internet; выбросы, связанные с наличием центров данных; выбросы по вине устройств «на краю сети» (Edge of the Network). При обсуждении проблемы выбросов в сообществе ICT наибольшее внимание уделяется центрам данным, используемым в академических и производственных организациях или образующим «серверную часть» Internet (центры данных, используемые в Google, Amazon, Yahoo и Microsoft). В этом есть смысл, поскольку такие «суперкластеры» включают сотни тысяч PC. Тем не менее, в отчете утверждается, что объем выбросов GSG, связанных с центрами данных, в 2020 г. составит менее 20% от общего объема выбросов по вине ITC. Основная часть выбросов (57%) поступит с «края сети»: от PC, периферийного оборудования и принтеров. Это связано с громадными масштабами роста использования PC в Китае и Индии. К 2020 г. в мире будет иметься 4 миллиарда PC.
Решение проблемы управления энергопотреблением в таких устройствах требуется начинать с системного уровня, сосредотачиваясь на интеграции аппаратной и программной архитектур. Нужна координация процессорной обработки, организации коммуникаций и поддержки сетей в современной среде, включающей PC, серверы, лаптопы и смартфоны. У всех этих устройств имеется сложная архитектура, объединяющая несколько радиоустановок, специализированных интегральных схем (applications specific integrated circuit, ASIC), микропроцессоров, цифровых сигнальных процессоров (digital signal processor, DSP), устройств основной памяти, батарей, выпрямителей, дисков и дисплеев. Это сильно усложняет проблему мониторинга и оптимизации энергопотребления.
Энергопотребление каждого компонента может различаться в 6-10 раз в зависимости от того, активен ли этот компонент или находится в режиме ожидания, а для радиоустройств это различие даже больше. Как можно воспользоваться этим для оптимизации общего энергопотребления? Одна из стратегий состоит в том, чтобы применять устройства, потребляющие наименьшую энергию, для отключения более крупных устройств, когда они не нужны. Например, можно координировать работу радиоустройств (Wi-Fi, cellular Internet, Bluetooth, Zigbee и т.д.) и использовать их для взаимной поддержки эффективного энергопотребления.
В университете Сан-Диего Раджеш Гупта (Rajesh Gupta) показал, что с алгоритмической точки зрения в архитектуре, оптимизирующей энергопотребление, следует либо отключать не требуемые в данный момент компоненты с использованием динамического управления питанием, либо замедлять их функционирование с применением динамического частотного масштабирования (dynamic frequency scaling), либо одновременно применять оба подхода. Для демонстрации этих идей совместно с Microsoft Research группа Гупты разработала архитектуру Somniloquy. Реализация этого подхода, которая представляет собой стандартное USB-устройство, вставляемое в лаптоп ThinkPad, управляет радиоустройствами и другими компонентами аппаратуры, так что оказывается возможно снизить энергопотребление до одного ватта при выполнении обычной работы и достичь времени жизни батарей в 63 часа (по сравнению со временем от четырех до шести часов при использовании стратегий обычного энергопотребления (16 ватт) или пониженного энергопотребления (11 ватт)). Широкое использование таких устройств или внедрение аналогичных возможностей в сами PC могло бы существенно повлиять на объемы выбросов GSG по вине ICT.
В последние четыре года специалистами, эксплуатирующими центры данных, были достигнуты существенные сдвиги в удельном энергопотреблении. Например, при выполнении проекта Data Center Demonstration, который был инициирован организацией Silicon Valley Leadership Group и Lawrence Berkeley National Laboratory, было установлено, что при применении передовых практических методов повышение удельного энергопотребления может быть прекращено. Для этого можно использовать ряд методов, позволяющих заменить стратегию охлаждения машинных залов целиком стратегией охлаждения только тепловыделяющих процессоров.
Одним из инновационных решений для организации небольших центров данных является заключение стоек в контейнер, объем которого не намного больше объема самого оборудования. Например, компания Sun Microsystems разработала модельный центр данных (Modular Data Center), размещаемый в стандартном грузовом контейнере, в котором могут быть установлены семь стоек с воздушным и водяным охлаждением, а также датчики, отслеживающие температуру и энергопотребление и обеспечивающие возможность активного управления дисками, процессорами, маршрутизаторами и т.д. В финансируемом NSF проекте GreenLight, который выполняется в университете Сан-Диего, были приобретены два таких центра данных для изучения возможного влияния программного обеспечения и приложений на повышение эффективности энергопотребления.
Для обеспечения реалистической загрузки системы в этом проекте был подобран широкий ассортимент вычислительных научных приложений. Например, конечный пользователь, занимающийся метагеномикой, может использовать сервис-ориентированную архитектуру для удаленного выполнения приложения, выбирая различные алгоритмы и выполняя их на различных компьютерных архитектурах (многоядерные процессоры, графические процессоры, программируемые вентильные матрицы), для любой комбинации которых имеются свой профиль энергопотребления и время выполнения. Эта информация собирается и публикуется в Web. Кроме того, участники проекта разрабатывают промежуточное программное обеспечение, ориентированное на автоматизацию оптимального конфигурирования аппаратуры и программного обеспечения.
Татьяна Симунич Роузинг (Tajana Simunic´ Rosing) вместе со своими коллегами показала, что динамическое управление энергопотреблением с одновременным применением метода машинного обучения на основе данных от датчиков и счетчиков производительности может обеспечить управление напряжением и частотой. Для некоторого класса рабочих нагрузок это позволяет добиться 70-процентной экономии потребляемой энергии. Для динамического управления тепловыми режимами (thermal management) методы машинного обучения могут предсказать, что некоторый, скажем, графический алгоритм при своем выполнении на процессоре вызывает значительное выделение тепла. Тогда система может предварительно охладить процессор для немедленного отвода тепла, что позволяет на 60% уменьшить энергопотребление без какого-либо падения производительности.
Еще одним примером является виртуализация. В университетах вычислительные кластеры обычно устанавливаются в недостаточно кондиционируемых помещениях, и вычисления часто занимают только небольшую часть времени, в то время как энергия на поддержку работоспособности оборудования и его охлаждение расходуется круглосуточно. Если использовать в режиме виртуализации более крупные системы, помещенные в эффективную среду энергопотребления, то можно добиться их гораздо более высокой полезной загрузки (до 80%) и при том же потреблении энергии производить намного больше вычислений.
Наконец, наилучший вариант состоит в том, чтобы производить электроэнергию без выбросов парниковых газов. В некоторых университетах начали использовать в качестве источников энергии солнечные батареи или топливные элементы. Так почему бы не использовать их для энергообеспечения центров данных? Помимо прочего, они производят постоянный ток, так что их можно напрямую подключать к компьютерам, не прибегая к использованию выпрямителей тока, которые тоже потребляют энергию.
Следующую статью написал Дэвид Парнас (David Lorge Parnas, Middle Road Software). Статья называется «Реальное переосмысление ‘формальных методов’» («Really Rethinking ‘Formal Methods’»).
Со времени появления первых идей по поводу использования формальных методов для разработки программ (более сорока лет тому назад) много раз происходили «революции» в аппаратной части и в человеко-машинных интерфейсах. К сожалению, сопоставимого прогресса в формальных методах нет. Были предложены новые языки и новые логики, но ошибки проектирования, которые встречались в 1960-е г.г., можно найти и в нынешнем программном обеспечении (ПО). Исключительно редкое применение формальных методов в производственной разработке ПО только подчеркивает, что использование таких методов не стало установившейся практикой. Следует подвергнуть сомнению предположения, лежащие в основе современных формальных методов, чтобы понять, что в них нужно изменить. Полный перевод статьи Парнаса находится здесь.
Авторами статьи «Воплощение концепции самоуправляемых компьютерных систем » («Fulfilling the Vision of Autonomic Computing») являются Саймон Добсон, Рой Стеррит, Пэдди Никсон и Майк Хинчи (Simon Dobson, University of St. Andrews, UK, Roy Sterritt, University of Ulster, Northern Ireland, Paddy Nixon, Mike Hinchey, Lero—the Irish Software Engineering Research Centre).
В 2001 г. исследователи из IBM предсказали, что к концу десятилетия индустрии IT понадобится 200 миллионов работников для помощи миллиарду сотрудников, работающих в миллионе компаний, в которых используется триллион устройств, соединенных посредством Internet. Как ожидалось, справиться с этой проблемой можно только путем обеспечения самоуправления компьютеров, что само по себе является сложной исследовательской проблемой.
В настоящее время видно, что, подобно ситуации с проблемой 2000-го года, положение дел не настолько критично, как ожидалось. Так была ли тревога ложной, или же прошедшее десятилетие было очень продуктивным для индустрии IT? Удалось ли нам решить проблему, поставленную IBM, или же далось обойтись какими-то другими мерами?
Призывая всех под знамена самоуправляемого компьютинга, люди из IBM сравнивали IT-индустрию в 2001-м году с телефонной индустрией в США в 1920-м г. В то время быстрое развитие телефонной индустрии и проникновение телефонов в повседневную жизнь людей вызвало серьезную проблему нехватки подготовленных операторов для работы с ручными коммутаторами. Аналитики предсказывали, что к 1980-му году для удовлетворения этой потребности половина населения США будет вынуждена работать телефонными операторами. Реализация компанией AT&T/Bell System автоматического протокола коммутации и появление других технологических новшеств позволили предотвратить этот кризис.
В 2001 г. только в IT-индустрии США имелись сотни тысяч незанятых рабочих мест, и ожидалось, что в мировом масштабе за следующие пять лет потребность в IT-специалистах возрастет более чем на 100%. Сегодняшнее число служащих в области IT трудно точно установить, поскольку в правительственной статистике не учитываются люди, занятые системным администрированием, сопровождением и выполняющие другие связанные с этим функции. Однако по предварительным данным Бюро по учету занятости (Bureau of Labor Statistics) в США насчитывается примерно 260000 работников в области IT, и их число медленно, но верно сокращается, несмотря на громадное возрастание доступной вычислительной мощности. Это говорит о том, что консолидация вычислительной мощности, возрастающая вследствие использования «облачных вычислений» и Web 2.0, позволяет сократить объем обслуживания в расчете на единицу предоставления услуг.
Однако эта история, безусловно, не так проста. Семь лет тому назад Джеффри Кефарт и Дэвид Чесс опубликовали в журнале Computer статью «Концепция саморегулирующихся вычислений», в которой описывалась точка зрения IBM на самоуправляемые вычисления в контексте управления корпоративными системами. Эта статья оказала важное влияние на будущее, изучение самоуправляемых систем стало существенным компонентом в области исследования систем. В частности, появились специализированные конференции, журналы, был создан специальный технический комитет IEEE Computer Society (Technical Committee on Autonomous and Autonomic Systems, TCAAS).
В концепции IBM поразительным образом сочетались элементы революции и экономии. Сосредотачиваясь на совокупной стоимости владения корпоративными системами, Кефард и Чесс подчеркивали, что системы IT могут оказать важнейшее влияние на экономику современных предприятий. Для внедрения, сопровождения и развития корпоративных систем часто требуются огромные усилия исключительно дорогостоящих служащих, успешная работа которых приносит лишь небольшую видимую пользу для бизнеса, а неудачи могут иметь катастрофические последствия. В наиболее широком смысле, самоуправляемый компьютинг направлен на сокращение потребности в подобных героических усилиях и связанных с этим рисков.
До какой степени удалось воплотить концепцию, изложенную Кефардом и Чесом? Каково современное состояние самоуправляемых компьютерных систем сегодня, и какое влияние оказывают выполненные исследования?
Расширяющееся использование информационных систем для обнаружения, сбора, анализа, сопоставления, обобщения и другой обработки информации оказывает огромное влияние на современную жизнь. Поскольку большая часть изменений сказывается на выполнении внутренних операций компаний, легко недооценить, в какой степени разработка, построение и, в особенности, сопровождение этих систем бросают вызов нашим инженерным способностям. Сбои систем в основном возникают при взаимодействии их функциональных компонентов, и основная забота системных администраторов при внедрении новых функциональных возможностей состоит именно в том, чтобы избежать этих взаимодействий.
В некоторых умах сегодняшний самоуправляемый компьютинг остается тесно связанным с исходной инициативной IBM, но в IEEE и других организациях теперь этот термин понимается в более широком смысле «развитой технологии управления развитыми технологиями». С этим направлением связан ряд других, в том числе, органический компьютинг (organic computing), биоинспирированный компьютинг (bio-inspired computing), самоорганизующиеся системы (self-organizing), сверхустойчивый компьютинг (ultrastable computing), автономные и адаптивные системы (autonomous and adaptive systems). Термин «самоуправляемость» (autonomic) теперь охватывает все эти инициативы.
Корпоративные системы являются всего лишь одним элементом класса сложных систем, которые должны согласованным и надежным образом функционировать при отсутствии постоянного участия человека. Многие задачи управления теперь невозможно достаточно решать силами даже достаточно подготовленных операторов. Система должна сама приспосабливаться к изменению условий. Эта потребность в самонастраиваемом поведении характеризует прикладные области, в которых идеи самоуправляемого компьютинга получают всяческую поддержку.
Общепризнанными элементами самоуправляемых систем являются свойства «самости» (self-*). Самоуправляемые системы должны быть самоконфигурируемыми (self-configuring), самовосстанавливаемыми (self-healing), самооптимизирующимися (self-optimizing) и самозащищающимися (self-protecting), демонстрируя при этом свойства самоосведомленности (self-awareness), самоотслеживания (self-monitoring) и саморегулирования (self-adjustment). Несмотря на кажущуюся простоту этих свойств, для их достижения требуется сложная взаимосвязь поведения системы с решаемыми ею задачами, пользователями и внешней средой. Мы можем оптимизировать систему только в соответствии с некоторыми внешними критериями, и самооптимизируемость означает, что эти критерии должны каким-то образом становиться известными системе управления. Кроме того, для обеспечения возможности композиции и анализа систем требуется, чтобы такие критерии представлялись явным образом в форме, пригодной для машинной обработки, а не встраивались неявно в алгоритмы.
Если говорить о системах, а не просто о машинах, требуется принимать во внимание и коммуникации как компонент проблемного пространства (отсутствие этого аспекта является наиболее известным упущением в концепции Кефарда и Чесса). Недавно было предложено понятие самоуправляемых коммуникаций (autonomic communications), которое стало объектом активных исследований, в особенности, в Европе. Отдельного изучения заслуживает взаимосвязь аспектов коммуникаций и вычислений в самоуправляемых системах.
Авторами последней статьи из рубрики Outlook – «Opportunities in Opportunistic Computing» («Перспективы оппортунистического компьютинга») – являются Марко Конти и Мохан Кумар (Marco Conti, Italian National Research Council, Mohan Kumar, University of Texas at Arlington).
В последние годы популярны оппортунистические сети (opportunistic networks), основанные на развитии идей мобильных временных сетей (mobile ad hoc networks, MANET). В оппортунистических сетях узлы входят во взаимный контакт оппортунистическим образом (по мере возможности) на основе беспроводных коммуникаций. Оппортунистические сети являются антропоцентрическими (human-centric), поскольку в них воспроизводится способ налаживания контактов между людьми. Тем самым, оппортунистические сети тесно связаны с социальными сетями.
Технологические достижения наполняют мир мобильными и стационарными датчиками, мобильными телефонами и автомобилями, оборудованными разнообразными измерительными и вычислительными устройствами, что прокладывает путь к множеству возможностей попарных контактов между устройствами. В оппортунистическом компьютинге используются оппортунистические коммуникации между парами устройств (и выполняемых на них приложений) для совместного использования контента, ресурсов и сервисов каждого из них. Оппортунистический компьютинг является новым направлением увлекательных исследований и разработок, позволяя, в то же время, более полно использовать потенциал оппортунистических сетей для решения прикладных проблем реального мира.
Можно сомневаться в целесообразности вычислительной парадигмы, основанной на попарных контактах между узлами. Однако концепция оппортунистического компьютинга мотивируется целым рядом факторов: ключевые технологические разработки, в том числе, беспроводные коммуникации и архитектуры устройств; появление новых прикладных областей; повсеместное распространение антропоцентрического компьютинга; развитие социальных сетей.
Повсеместно доступны за умеренную цену мобильные телефоны с возможностями Wi-Fi, Bluetooth, цифровой фотографии. Встроенные компьютерные средства имеются в современных автомобилях и мобильных и стационарных сенсорных устройствах, включая устройства видеонаблюдения. Широкая распространенность таких устройств создает массу возможностей для полезных контактов между ними, открывая путь к оппортунистическим коммуникациям. Потенциальная частота таких контактов является огромной, поскольку рынок мобильных телефонов ежегодно расширяется на 22%.
По оценкам аналитиков, во всем мире мобильными телефонами пользуются 3,3 миллиарда человек – немного больше половины общего населения Земли. Тем самым, в любой момент, когда включены два миллиарда мобильных телефонов, потенциально может возникнуть миллиард параллельных оппортунистических контактов. При заниженной оценке каждый мобильный телефон обладает процессорной мощностью в 100 миллионов команд в секунду и возможностью передачи данных со скоростью в 200 килобит в секунду. Использование этих оппортунистических контактов потенциально может обеспечить решение около 100 квадрильона вычислительных задач и передачу одного петабайта данных в секунду. Эта оценка существенно повысится, если принять во внимание 10 миллиардов ARM-процессоров, используемых во встраиваемых системах автомобилей, бытовых приборах и других устройствах.
При наличии множества проводных и беспроводных коммуникационных технологий и упомянутых возможностей устройств оппортунистические контакты между парами устройств являются нормальным явлением, а не редкостью. Инфраструктура оппортунистического компьютинга доступна повсеместно. Оппортунистические сети обеспечивают конкретные протоколы коммуникаций, а сценарии приложений – мотивацию решения проблем оппортунистического компьютинга. Вопрос только в том, когда и как нам удастся решить проблемы требуемого расширения существующих приложений и разработки новых приложений. По своей сути, крупномасштабный оппортунистический компьютинг, который можно считать просто устойчивым к задержкам распределенным компьютингом (delay-tolerant distributed computing, DTDC), обладает огромным потенциалом.
На самом деле, мобильный и всеобъемлющий компьютинг также можно считать естественным развитием традиционного распределенного компьютинга. Однако в мобильных и всеобъемлющих вычислительных системах ситуации разрыва связи или перехода устройства в неактивное состояние являются отклонениями от нормы, а в оппортунистическом компьютинге оппортунистическая связность позволяет обеспечить доступ к ценным ресурсам и информации.
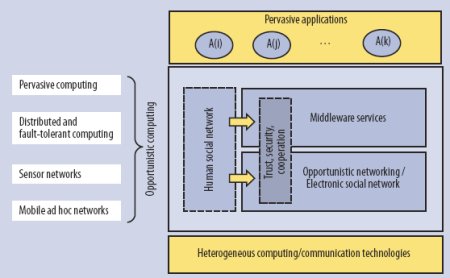
Как показывает рисунок, в оппортунистическом компьютинге используются коммуникационные возможности для обеспечения вычислительных услуг, удовлетворяющих потребностям всеобъемлющих приложений. Исследования в области оппортунистических сетей опираются на результаты прошлых лет в областях мобильных временных сетей и сетей, устойчивых к задержкам, а всеобъемлющий, мобильный и социальный компьютинг стимулируют их соответствующее применение.
В оппортунистическом компьютинге используются все доступные ресурсы оппортунистической среды для обеспечения платформы выполнения распределенных вычислительных задач. Основной проблемой является эффективное использование оппортунистических контактов для обеспечения доступности информации и предоставления вычислительных сервисов приложениям и пользователям. Чтобы превратить оппортунистический компьютинг в реальность, требуются службы промежуточного программного обеспечения, маскирующие разрывы связи и задержки и управляющие разнородными вычислительными ресурсами, службами и данными для обеспечения приложениям однородного представления системы.
Становлению оппортунистического компьютинга могут содействовать результаты исследований в областях всеобъемлющих и сенсорных систем, распределенных и отказоустойчивых вычислений, мобильных временных сетей. Однако многие проблемы оппортунистического компьютинга являются уникальными.
В рубрике «Исследовательские статьи» опубликована статья Роберта Шумейкера и Хсинчун Чена (Robert P. Schumaker, Iona College, New Rochelle, New York, Hsinchun Chen, University of Arizona) «Дискретная система предсказания биржевого курса акций на основе финансовых новостей » («A Discrete Stock Price Prediction Engine Based on Financial News»).
Несмотря на громадные усилия исследователей, до сих пор не удалось найти метода точного предсказания изменения биржевых курсов акций. Трудности предсказания вызываются сложностями динамики рынка, параметры которого постоянно изменяются и не полностью определены.
Некоторых успехов в этой области удается добиться на основе использования текстовых данных. Информация из квартальных отчетов и новостных сообщений может существенно влиять на стоимость акций. Применение вычислительных методов к этим текстовым данным образует основу финансового интеллектуального анализа текстов (financial text mining). Большинство существующих методов финансового анализа текстов применяется к новостным статьям, в которых используются только отдельных термины, и этим терминам назначаются веса в зависимости от направления изменений биржевого курса. При предсказании эти взвешенные термины применяются к некоторой новой статье для определения вероятного направления изменения. Эти упрощенные методы показывают слабую, но вполне определенную возможность предсказания направления изменения биржевого курса, но не могут предсказать сами цены акций.
Однако использование вычислительных алгоритмов для предсказания биржевого курса на основе финансовых данных не является чем-то уникальным. В последние годы повысился интерес к «количественным фондам» (quantitative fund), или квантам (quant), которые автоматически обрабатывают финансовые данные и выпускают биржевые рекомендации. Все эти системы основываются на проприетарных технологиях и различаются объемом отслеживаемых коммерческих операций, от систем рекомендаций для какой-то одной биржи до систем поддержки выполнения сделок. Используя исторические рыночные данные и сложные математические модели, эти методы способны производить анализ только в рамках существующей информации. Это ограничение означает невозможность реагирования на непредвиденные события, не укладывающиеся в рамки исторических норм. Однако этот недостаток не мешает менеджерам ведущих инвестиционных фондов вкладывать миллиарды долларов, основываясь на решениях, которые подсказываются подобными вычислительными системами.
Система Arizona Financial Text (AZFinText) представляет собой иной тип квант-трейдера, обеспечивающего дискретные численные предсказания на основе комбинирования материалов из финансовых новостей с данными о биржевых курсах. В то время как в предшествующих методах финансового текстового анализа отслеживалось только направление изменения цен, в AZFinText используется статистическое обучение для предсказания количественных объемов цен, и на основе этого предлагаются рекомендации о сделках.
Наконец, последняя (также исследовательская) статья номера написана (Thomas F. Stafford, Robin Poston, University of Memphis) и называется «Онлайновые угрозы безопасности и намерения пользователей компьютеров» («Online Security Threats and Computer User Intentions»).
Ваша идентификационная информация может быть похищена, пароли – взломаны, ваш компьютер может быть захвачен и превращен в зомби, рассылающего спам, номер вашей кредитной карты может быть скопирован и переслан мошенникам. Это всего лишь некоторые угрозы которым подвергаются неосторожные пользователи со стороны шпионского программного обеспечения (spyware). Серьезную и все углубляющуюся проблему безопасности представляет скрытая установка на компьютере пользователя программного обеспечения, отслеживающего действия и информацию пользователя, и передающего полученные данные злоумышленникам через пользовательское соединение с Inteernet.
Федеральная торговая комиссия США (Federal Trade Commission) определяет spyware, как «программное обеспечение, назначение которого состоит в сборе информации об отдельной личности или организации без их ведома, и которое может посылать эту информацию другому объекту без согласия пользователя». Гуру в области spyware Стив Гибсон (Steve Gibson) считает шпионским любое программное обеспечение, которое тайно использует подключение к Internet для связи с каким-либо внешним сервером.
Вред, приносимый несанкционированным мониторингом, варьируется от посягательств на конфиденциальную информацию до эксплуатационных потерь из-за снижения производительности компьютера и до экономических потерь, возникающих из-за похищения идентификационных данных и прямого воровства. Некоторые разновидности spyware просто занимают часть ресурса процесса и пропускной способности сети для рассылки спама из компьютера пользователя, в то время как другие добывают пароли и учетные номера для кражи услуг и финансовых ресурсов. Новейшие виды шпионского программного обеспечения, продолжающие развиваться, являются конгломератами вредоносных программ, включающими одновременно и средства заражения компьютеров, и коммуникационные средства, которые позволяют использовать одноранговые сети.
Хотя шпионское программное обеспечение действительно представляет проблему, имеется и намного более опасный симптом – апатия пользователей. Пользователи Internet осведомлены о spyware, но до странности неохотно прибегают к применению безопасных методов использования компьютеров или эффективных антишпионских приложений. Частично это можно объяснить недостатком знаний, но антишпионское программное обеспечение используется настолько небольшим числом людей, что, очевидно, основной проблемой является отсутствие побудительных мотивов.
Чтобы понять, с чем это связано, авторы исследовали неспособность пользователей к защите своей безопасности и конфиденциальности на основе теории защитной мотивации (protection motivation theory, PMT), которая широко используется для изучения причин отсутствия у людей побуждений к защите от угроз собственному здоровью и безопасности, таких как вождение автомобиля в нетрезвом виде, курение и распространение заразных заболеваний.
Всего вам доброго, до следующей встречи, Сергей Кузнецов.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
