2009 г.
Где бы еще покопаться в данных?
Сергей Кузнецов
Обзор августовского, 2009 г. номера журнала Computer (IEEE Computer Society, V. 42, No 8, Август 2009).
Темой августовского номера являются интеллектуальный анализ данных (data mining) и машинное обучение (machine learning). Теме посвящены четыре статьи, которым предшествует небольшая вводная заметка приглашенного редактора Нарена Рамакришнана (Naren Ramakrishnan, Virginia Tech) «Вездесущность интеллектуального анализа данных и машинного обучения» («The Pervasiveness of Data Mining and Machine Learning»).
Целью исследований в областях интеллектуального анализа данных и машинного обучения является извлечение правил и знаний из данных. Многие исследователи различают понятия data mining и machine learning, и эти различия обычно говорят о том, на чем акцентируются и откуда происходят исследования. Но в последнее время наблюдается взаимное обогащение идеями и перемещение авторов между соответствующими сообществами.
Статьи тематической подборки показывают возрастающую важность применения интеллектуального анализа данных в нескольких областях: системах рекомендаций, сенсорных сетях, автоматизации научной деятельности и программной инженерии.
Первая основная статья подборки написана Иегудой Кореном, Робертом Беллом и Крисом Волински (Yehuda Koren, Yahoo Research, Haifa, Robert Bell, Chris Volinsky, AT&T Labs—Research) и называется «Методы факторизации матриц для систем рекомендаций» («Matrix Factorization Techniques for Recommender Systems»).
У современных потребителей имеется масса возможностей выбора. Электронные розничные магазины и поставщики контента предлагают огромный выбор продуктов, способный удовлетворить самым разнообразным потребностям и вкусам. Подбор для потребителей наиболее подходящих для них продуктов способствует росту уровня удовлетворенности и доверия пользователей. Поэтому все больше розничных торговцев нуждается в системах рекомендаций, которые анализируют характер предпочтений пользователей и вырабатывают персонифицированные рекомендации, соответствующие вкусам пользователей. В частности, системы рекомендаций стали существенной частью Web-сайтов лидеров электронной коммерции, таких как Amazon.com и Netflix.
Такие системы особенно полезны для развлекательных продуктов, таких как фильмы, музыка и телепрограммы. Многие потребители смотрят один и тот же фильм, и, вероятно, каждый потребитель смотрит много разных фильмов. Пользователи соглашаются сообщать об уровне своего удовлетворения конкретными фильмами, и по этой причине имеется огромный объем данных о том, какие фильмы понравились или не понравились различным потребителям. Компании могут анализировать эти данные, чтобы рекомендовать фильмы конкретным пользователям.
Грубо говоря, системы рекомендаций основываются на одной из двух стратегий. При использовании подхода фильтрации контента (content filtering) для каждого пользователя или продукта создается профиль, характеризующий его основные свойства. Например, профиль фильма может включать атрибуты, касающиеся его жанра, участвующих актеров, кассовых сборов и т.д. Профили пользователей могли бы включать демографическую информацию или ответы на соответствующий набор вопросов. Профили позволяют программам связать пользователей с подходящими им продуктами. Конечно, для реализации стратегии на основе фильтрации контента требуется собирать внешнюю информацию, что может быть нелегко или даже невозможно.
Успешная реализация фильтрации контента выполнена в системе рекомендаций Music Genome Project, которая используется в службе Internet-радио Pandora.com. В Music Genome Project подготовленный музыкальный аналитик оценивает каждую песню на основе сотен различных музыкальных характеристик. Эти атрибуты, или гены отражают не только музыкальную индивидуальность песни, но и многие важные качества, которые существенны для понимания музыкальных предпочтений слушателей.
Альтернативный подход к организации систем рекомендаций опирается только на данные о предыдущем поведении пользователей (выполненные ими транзакции или выставленные ими оценки продуктов) и не требует создания явных профилей. Этот подход называется совместной фильтрацией (collaborative filtering); этот термин был введен разработчиками первой системы рекомендаций Tapestry. При использовании совместной фильтрации для нахождения новых ассоциаций анализируются связи между пользователями и взаимозависимости между продуктами.
Привлекательной чертой подхода совместной фильтрации является то, что он не привязан к какой-либо прикладной области и может применяться по отношению к тем аспектам данных, для которых трудно применять профилирование. Хотя, как правило, совместная фильтрация обеспечивает лучшую точность рекомендаций, чем фильтрация контента, этому подходу свойственна проблема «холодного» старта (cold start) – система не может работать с данными о новых пользователях и продуктах. В этом аспекте преимуществами обладает фильтрация контента.
Двумя основными областями применения совместной фильтрации являются методы ближайших соседей (nearest neighborhood method) и модели скрытых признаков (latent factor model). Методы соседей концентрируются на вычислении связей между продуктами или между пользователями. В первом случае предпочтение пользователем некоторого продукта оценивается на основе оценок «соседних» продуктов, выставленных этим же пользователем. «Соседи» данного продукта – это другие продукты, которые, вероятно, получили бы от данного пользователя близкие оценки. Например, пусть требуется оценить предпочтение пользователя по отношению к фильму «Спасти рядового Райана» («Saving Private Ryan»). «Соседями» этого фильма могли бы быть другие фильмы о войне, другие фильмы Стивена Спилберга (Steven Spielberg), другие фильмы, в которых снимался Том Хэнкс (Tom Hanks) и т.д. Для предсказания оценки пользователя фильма «Спасти рядового Райана» можно было бы опираться на ближайших «соседей» этого фильма, которые уже были оценены данным пользователем. Во втором случае определяются пользователи-единомышленники, оценки каждого из которых дополняют оценки любого другого пользователя той же группы (см. рис. 1).
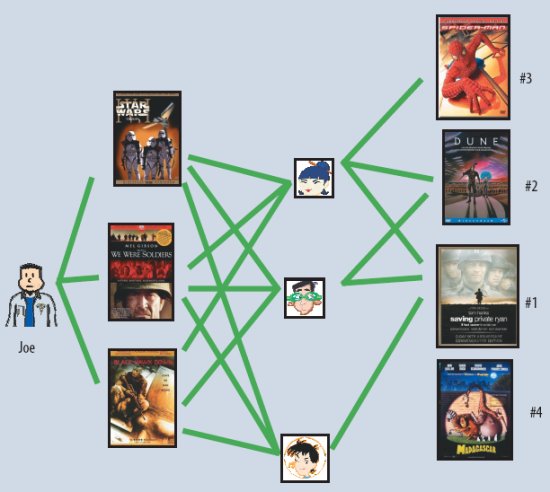
Рис. 1. Метод ближайших соседей, ориентированный на пользователей. Джо нравятся три фильма в левой части рисунка. Чтобы порекомендовать ему другие фильмы, система находит похожих пользователей, которым также нравятся эти фильмы, а затем определяет, какие еще фильмы им нравятся. В данном случае всем трем нравится фильм «Спасти рядового Райана», так что это будет первая рекомендация для Джо. Двоим нравится «Дюна» (Dune), и это будет вторая рекомендация и т.д.
При применении моделей скрытых признаков система пытается истолковать оценки путем получения характеристик и продуктов, и пользователей, используя при этом от 20 до 100 признаков, выводимых из структуры оценок. По сути, такие признаки являются компьютеризованной альтернативой упоминавшихся выше создаваемых людьми генов песен. Для фильмов такие признаки могут включать очевидные измерения, такие как жанр, динамичность сюжета, ориентация на детей; менее четко определенные измерения, такие как глубина раскрытия образов или причудливость фильма; а также полностью неинтерпретируемые признаки. Каждый признак пользователей показывает, насколько нравятся данному пользователю фильмы, высоко оцениваемые в измерении соответствующего признака фильмов.
На рис. 2 эта идея иллюстрируется на упрощенном примере с двумя измерениями. Рассмотрим два гипотетических измерения, характеризующих ориентацию фильмов на женщин или мужчин и серьезный или развлекательный жанр фильмов. На рисунке показано, как этом двухмерном пространстве могло бы быть размещено несколько известных фильмов и несколько фиктивных пользователей. В этой модели предсказываемая оценка некоторого фильма некоторым пользователем относительно средней оценки данного фильма вычисляется как скалярное произведение векторов от начала координат до данного фильма и данного пользователя. Например, можно было бы ожидать, что пользователю Гусу понравится фильм «Тупой, еще тупее» («Dumb and Dumber»), не понравится фильм «Цветы лиловые полей» («The Color Purple»), и что он средним образом оценит фильм «Храброе сердце» («Braveheart»). Заметим, что в этом пространстве некоторые фильмы (например, «Одиннадцать друзей Оушена» («Ocean’s 11»)) и некоторые пользователи (например, Дейв) характеризовались бы полностью нейтральным образом.
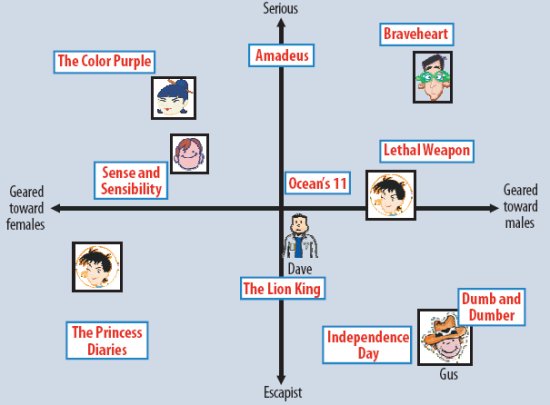
Рис. 2. Упрощенная иллюстрация подхода скрытых признаков, в котором пользователи и фильмы характеризуются по двум осям – мужчина и женщины, а также серьезные и развлекательные фильмы
Некоторые успешные реализации моделей скрытых признаков основываются на факторизации матриц (matrix factorization). В своей базовой форме метод факторизации матриц характеризует продукты и пользователей векторами признаков, выводимых из структуры оценок товаров. Рекомендация вырабатывается при наличии высокого уровня соответствия между товаром и пользователем. Методы факторизации матриц заслужили популярность в последние годы за счет сочетания хорошей масштабируемости и точности предсказаний. Кроме того, они обладают достаточной гибкостью для моделирования различных ситуаций реального мира.
Системы рекомендаций опираются на различные типы входных данных, которые часто размещаются в матрице по одному измерению для пользователей и по другому – для продуктов. Наиболее удобны данные, явно получаемые от пользователей (explicit feedback) и отражающие уровень их заинтересованности в продуктах. Например, в Netflix собираются оценки, выставляемые пользователями фильмам, а пользователи TiVo показывают свои предпочтения по поводу телепрограмм, нажимая кнопки «thumbs-up» («большой палец вверх») и «thumbs-down» («большой палец вниз»). Обычно явные данные образуют разреженную матрицу, поскольку каждый отдельный пользователь, вероятно, оценивает только небольшую часть возможных продуктов.
Одной из сильных сторон метода факторизации матриц является возможность использования дополнительной информации. Если явные данные от пользователей недоступны, система рекомендаций может выводить предпочтения пользователей, используя неявные данные (implicit feedback), косвенным образом выражающие мнения пользователей. Такие данные могут включать историю покупок, схемы поиска или даже перемещения мыши. Неявные данные обычно говорят о наличии или отсутствии некоторого события, и обычно они представляются плотно заполненной матрицей.
Эксперименты с реальными наборами данных, такими как данные, используемые в соревновании Netflix Prize, показывают, что методы факторизации матриц обеспечивают большую точность, чем классические методы ближайших соседей. В то же время, на основе этих методов возможно построение компактных, эффективных по использованию основной памяти моделей, которые сравнительно легко обучаются системой.
Статью «Оптимизация сбора сенсорных данных: из воды в Web» («Optimizing Sensing: From Water to the Web») представили Андреас Краузе и Карлос Герстин (Andreas KrauseCarlos Guestrin, Carnegie Mellon University).
Высокий уровень загрязняющих веществ (в частности, нитратов) в озерах и реках может приводить к быстрому росту водорослей. Это цветение воды может являться серьезной угрозой ресурсам питьевой воды. Например, цветение воды в июне 2007 г. в озере Тайху в китайской провинции Цзянсу лишило питьевой воды четыре миллиона человек, и на его очистку потребовалось около 14,5 миллиардов долларов.
Многие процессы, связанные с цветением воды, все еще недостаточно хорошо поняты, и изучать их нужно в озерах, а не в лабораториях. Естественный подход к получению новых знаний состоит в мониторинге параметров окружающей среды, таких как температура, распределение питательных веществ и флуоресценция, сопровождающих такое цветение воды. Перспективная технология для этих целей опирается на использование датчиков, установленных на роботизированные лодки, позволяющие получать измерения на больших площадях. Однако, для получения каждого измерения требуется значительное время, поскольку роботу требуется доплыть из одной точки водной поверхности в другую. Поэтому важно планировать траекторию лодки так, чтобы получить как можно больше полезной информации об изучаемом явлении.
Аналогичная проблема возникает в контексте мониторинга муниципальных распределительных сетей питьевой воды. Случайное или злонамеренное загрязнение таких сетей может затронуть большую группу населения и нанести серьезный ущерб. Потенциально такое загрязнение можно выявить путем размещения датчиков в сети водопроводов. Однако эти сенсоры весьма дороги. Например, в системе Water Distribution Monitorin компании Hach стоимость одного датчика в настоящее время составляет 13000 долларов. Поэтому необходимо оптимизировать размещение этих дорогостоящих сенсоров, чтобы добиться их максимальной эффективности.
В более общем смысле, целью оптимизации сбора сенсорных данных является изучение каких-либо аспектов состояния мира (температуры в заданной местности или имеется ли там загрязнение) путем оптимального выполнения небольшого числа измерений. Основной вопрос состоит в том, как получить наибольший объем полезной информации при наименьших затратах? Эта проблема изучается с привлечением нескольких дисциплин, включая статистику (планирование экспериментов), машинное обучение (активное обучение), исследование операций (размещение оборудования) и робототехника. Однако большая часть имеющихся подходов опирается на негарантированные эвристики, которые потенциально могут работать плохо. Также имеется несколько алгоритмов, которые разработаны для нахождения оптимального решения, в частности, алгоритмы, основанные на частично наблюдаемых марковских процессах принятия решения (partially observable Markov decision processes, POMDP) и смешанном целочисленном программировании (mixed-integer programs, MIP). Но методы, в которых используются такие алгоритмы, часто не удается масштабировать для решения крупных проблем.
В статье описывается новый класс алгоритмов с теоретически обоснованными гарантиями эффективности, которые могут масштабироваться к крупным проблемам оптимизации сбора сенсорных данных. Алгоритмы основываются том наблюдении, что многие проблемы этой области удовлетворяют свойству подмодульности (submodularity) – интуитивному свойству убываемой отдачи: лучше добавить наблюдение в тот участок, где делалось мало наблюдений, чем туда, где уже было выполнено много наблюдений.
Авторами следующей статья являются Росс Кинг и др. (всего 12 авторов) из Абериствисского и Кембриджского университетов (Великобритания) (Ross D. King, Aberystwyth University). Статья называется «Робот-ученый Адам» («The Robot Scientist Adam»).
В области компьютерных наук все в большей степени формируется общенаучная программа исследований. Использование компьютеров для выполнения экспериментов способствует получению данных постоянно возрастающего объема. Этот рост данных, в свою очередь, вызывает потребность в активном использовании компьютеров для моделирования и анализа.
Применение компьютерных наук приводит также к изменению способов представления и передачи исследователями научных знаний. Большая часть этих знаний представляется с использованием только естественного языка – исключением, подтверждающим это правило, является математика. Желание сделать научные данные более пригодными для компьютерного анализа стимулирует развитие таких направлений, как онтологии и Semantic Web. Эти направления полезны для всех наук, поскольку научные знания лучше всего представляются с использованием формальной логики, поскольку она помогает достичь семантической четкости, что, в свою очередь, способствует свободному обмену научными знаниями.
Ветвь искусственного интеллекта, посвящаемая научным приложениям, называется обнаружением научных знаний (scientific discovery). Первыми достижениями в этой области были разработанные в 1960-е гг. системы анализа масс-спектрометрических данных Dendral и Meta-Dendral, являвшиеся одними из первых системами машинного обучения. Впоследствии системы Prospector, Bacon, Fahrenheit и их преемники продемонстрировали возможности частичной автоматизации планирования научных проектов, анализа получаемых данных и извлечения из них знаний. Однако большинство программ обнаружения научных знаний разрабатывалось в расчете на выработку ответа с последующим прекращением работы. Они «не замыкали круг» в том смысле, что не принимали решения о следующих шагах на основе анализа результатов экспериментов, не выполняли потенциально бесконечную циклическую последовательность исследований. У большей части систем обнаружения научных знаний имеется еще одно важное ограничение – отсутствие возможности выполнять свои собственные эксперименты. Эта возможность требуется, чтобы такие системы могли выполнять работу в лабораториях в полуавтономном режиме.
Роботы-ученые – это естественное развитие тенденции к все более широкому использованию компьютерных систем в науке. В этих системах применяются разнообразные методы искусственного интеллекта для автоматического выполнения циклов научных экспериментов. Как показано на рис. 3, робот-ученый производит гипотезы, объясняющие наблюдения; разрабатывает эксперименты для проверки этих гипотез; интерпретирует результаты экспериментов; и затем повторяет этот цикл.
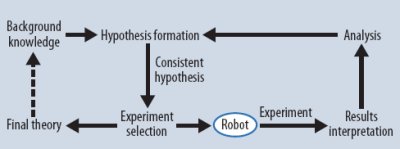
Рис. 3. Генерация гипотез и замкнутый цикл экспериментов робота-ученого.
Для разработки роботов-ученых имеются и философские, и технологические мотивации. С философских позиций основной довод в пользу таких систем состоит в том, что мы не сможем полностью понять какое-либо явление, пока не сконструируем машину, воспроизводящую его. Преимущество этого подхода к философии науки состоит в его конструктивности и объективности.
С технологической точки зрения роботы-ученые нужны для повышения продуктивности науки. Во многих областях у исследователей имеется больше возможностей генерации данных, чем их анализа. У роботов-ученых имеется возможность изменить эту ситуацию за счет интеграции циклов формирования и проверки гипотез.
У роботов-ученых также имеется возможность повысить уровень воспроизводимости и повторного использования научных знаний, поскольку производимые ими эксперименты могут описываться очень подробно и семантически четко. Поскольку роботы-ученые разрабатывают и выполняют эксперименты в автоматическом режиме, они могут формализовать и поддерживать в электронном виде все аспекты научного процесса: гипотезы, цели экспериментов, результаты, выводы и т.д.
В 2004 г. авторы предложили свою концепцию робота-ученого и продемонстрировали возможности такой системы по автоматическому выполнению циклов формирования гипотез и экспериментов. Эта система была ограничена в трех отношениях. У робота-ученого имелась лишь возможность повторного обнаружения уже известных научных знаний; эксперименты выполнялись не полностью автоматически; и шаги научного процесса не формализовались и явно не выделялись.
Робот-ученый Адам разрабатывался с целью преодоления этих ограничений. Аппаратная платформа робота позволяет полностью автоматически выполнять микробиологические эксперименты. Программное обеспечение достаточно развито, чтобы обеспечить обнаружение новых научных знаний. Научные процессы формализованы и четко описываются с применение формальной логики.
Последняя статья тематической подборки называется «Интеллектуальный анализ данных в программной инженерии» («Data Mining for Software Engineering») и написана Тао Ксаем, Сурешем Таманелентой, Дэвидом Ло и Чао Лиу (Tao Xie, Suresh Thummalapenta, North Carolina State University, David Lo, Singapore Management University, Chao Liu, Microsoft Research in Redmond, Washington).
Поскольку программное обеспечение играет решающую роль в бизнесе, правительственных и общественных организациях, важной целью программной инженерии является совершенствование эффективности и качества программного обеспечения. Достижению этой цели могут способствовать средства интеллектуального анализа данных программной инженерии. Применение подхода data miming в этой области является перспективным из-за постоянного роста объемов таких данных и уже продемонстрированного полезного применения этого подхода в ряде других практически важных областей.
Популярные системы управления версиями программного обеспечения, такие как CVS и Subversion позволяют разработчикам не только сохранять мгновенные снимки текущей базы кодов, но также и поддерживать полную историю версий. На основе систем, подобных Bugzilla, возможно организовать учет и обработку ошибок на протяжении всего жизненного цикла программной системы. Мощные измерительные средства, такие как Dr. Watson компании Microsoft, позволяют получать разнообразные данные во время выполнения программ. Эти средства используются непосредственно разработчиками, а также в инструментах мониторинга программных систем уровня конечных пользователей.
Данные программной инженерии касаются людей, процессов и продуктов. К числу людей относятся разработчики, тестировщики, менеджеры проектов и пользователи. Процессы включают различные фазы и активности разработки: выработку требований, проектирование, реализация, тестирование, отладка, сопровождение, внедрение. Продукты могут быть структурированными (например, исходный код) или неструктурированными (например, документация).
Алгоритмы интеллектуального анализа данных применимы к различным задачам программной инженерии. Например, такие алгоритмы могут помочь разработчикам разобраться в том, как вызывать методы API, поддерживаемые в сложной и недостаточно полно документированной библиотеке. При поддержке программного обеспечения алгоритмы data mining могут способствовать определению того, какие части кода требуется изменить при изменении других частей кода. Разработчики программного обеспечения могут использовать алгоритмы интеллектуального анализа данных и при поиске потенциальных ошибок, которые могут привести к отказу системы во время ее эксплуатации, а также при определении ошибочных строк кода, ответственных за уже известные отказы.
Вне тематической подборки опубликованы две большие статьи. Чарльз Рич (Charles Rich, Worcester Polytechnic Institute) представил статью «Создание пользовательских интерфейсов, основанных на описании задач, с применением стандарта ANSI/CEA-2018» («Building Task-Based User Interfaces with ANSI/CEA-2018»).
Исследования показывают, что половина возвращаемой в магазины якобы неисправной бытовой электроники на самом деле полностью работоспособна – покупатели просто не смогли разобраться, как обращаться с приобретенными устройствами. Проблемы начались в 1980-е гг. с мигающих часов в видеомагнитофонах и с тех пор многократно усугубились, поскольку в любом покупаемом сегодня бытовом устройстве имеется управляющий им процессор.
У наблюдаемого кризиса удобства использования имеются, по меньшей мере, два разных аспекта: сложность и несогласованность. Во-первых, применение компьютеров упростило (возможно, чрезмерно упростило) добавление в бытовые устройства новых возможностей, и результирующая сложность устройств превышает возможности имеющихся сегодня пользовательских интерфейсов, разработанных в расчете на интуицию пользователей. Во-вторых, пользовательские интерфейсы однотипных устройств или устройств, производимых одной и той же компанией, почти (или полностью) не согласованы.
Логическим решением проблемы несогласованности должна была бы являться стандартизация. Но, к сожалению, компании-производители бытовой электроники неуклонно противодействуют всем попыткам стандартизации пользовательских интерфейсов устройств с однотипными функциями. Они полагают, что внешнее представление и функциональные особенности их интерфейсов важны для идентификации брэнда и индивидуализации продуктов. По их мнению, стандартизация пользовательских интерфейсов – это первый шаг по направлению к унификации, что, возможно, хорошо для потребителей, но чревато снижением размеров прибыли.
Стандартизация пользовательских интерфейсов для продуктов одного и того же производителя не встречает такого сопротивления, но обеспечивает гораздо меньше преимуществ. Например, у типичного потребителя имеется всего одна модель радиоприемника, и его мало волнует согласованность интерфейсов у всех моделей радиоприемников данного поставщика, кроме того, вряд ли возможно согласовать интерфейсы радиоприемника и, скажем, микроволновой печки.
Недавно принятый стандарт ANSI/CEA-2018 прямо способствует решению проблемы сложности, обеспечивая новый вид взаимодействия пользователя с системой без стандартизации внешнего вид пользовательского интерфейса. Эта хитроумная (но необходимая) стратегия может привести к значительному повышению уровня удобства использования бытовой электроники и программного обеспечения в целом.
Наконец, статью «Шаблоны специализированных продуктов» («Application-Specific Product Generics») написали Джон Лэч и Вину Виджай Кумар (John Lach, University of Virginia, Vinu Vijay Kumar, Texas Instruments).
Повышение стоимости проектирования и производства полупроводниковых приборов приводит ко все большей потребности в мелкосерийных специализированных заказных полупроводниковых устройствах. Стоимость проектирования возрастает экспоненциально в зависимости от сложности системы. Для полной отладки и верификации системы требуется много человеко-часов и зачастую несколько циклов работы. При этом процессы производства полупроводниковых устройств становятся все более сложными и трудоемкими; одна только стоимость изготовления маски часто превышает миллион долларов. В материалах консорциума International Technology Roadmap for Semiconductors отмечается, что рост невозвращаемой стоимости проектного этапа (nonrecurring engineering costs) является наибольшей проблемой на пути дальнейшего развития полупроводниковых систем.
Эта суровая действительность стимулирует разработчиков аппаратных средств агрегировать несколько мелкосерийных проектных решений в более крупное обобщенное решение, сокращая, тем самым, невозвращаемую стоимость проектного этапа. Имеющиеся в настоящее время подходы к созданию таких обобщенных проектных решений опираются на использование специализированных интегральных схем (application-specific integrated circuits, ASIC), настраиваемых процессоров (customizable processor) и программируемых вентильных матриц (field-programmable gate array, FPGA). Хотя применение этих платформ решает проблему стоимости проектного этапа, за это приходится расплачиваться недостаточной миниатюрностью, не слишком высокой производительностью и слишком большой потребляемой мощностью результирующих устройств. Предлагались методы разработки более эффективных обобщенных продуктов (например, проблемно-ориентированная настойка (domain-specific customization)), но ни один из них не обеспечивает показателей качества заказных ASIC, проектируемых специально для данного приложения.
Новый подход «шаблонов специализированных продуктов» (Application-specific product generics, ASPG) к проектированию и производству полупроводниковых систем обеспечивает достаточную гибкость, позволяющую реализовать целое семейство устройств на основе единого этапа проектирования и запуска производства, но при этом показатели получаемых устройств близки к показателям заказных ASIC. В этом подходе максимально используются сходства, присущие отдельным устройствам (например, общие черты алгоритмов цифровой обработки сигналов), чтобы обеспечить производство схемы с фиксированными логическими функциями. На стадии постпроизводственного конфигурирования устройства остается выполнить только минимальную настройку.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
