Темой мартовского номера журнала Computer являются системы поддержки поиска информации (information seeking support systems). Этой теме посвящены шесть из семи больших статей номера. Кроме того, имеется заметка приглашенных редакторов, которыми на этот раз являются Гари Марчионини и Райен Уайт (Gary Marchionini, University of North Carolina at Chapel Hill, Ryen W. White, Microsoft Research). Название заметки совпадает с темой номера.
Появление Всемирной Паутины и разнообразных поисковых машин, индексирующих ее содержимое, привело к тому, что информационный поиск стал частью повседневной деятельности большинства людей. Люди уже давно привыкли к возможности мгновенного доступа к информации на любую тему в любое время и в любом месте.
Информационный поиск достаточен для пользователя, если его потребности четко определены у него в голове. Но если информация ищется в целях обучения, принятия решения или совершения какой-либо другой умственной деятельности, выполняемой на протяжении некоторого времени, то информационный поиск остается необходимым, но перестает быть достаточным. Для выполнения этих задач нужны инструментальные средства и службы поддержки, помогающие людям управлять найденной информацией, анализировать ее и совместно использовать. Соответствующие возможности обеспечивают системы поддержки поиска информации (information seeking support system, ISSS).
Поиск информации является важнейшей человеческой деятельностью, обеспечивающей «первичный материал» для запланированного поведения (planned behavior), принятия решений и производства новых информационных продуктов. Люди ищут информационные объекты, содержащие идеи, прилагают умственные усилия для их понимания и затрачивают дополнительные усилия на применение этого понимания для решения проблем.
Принято считать, что процесс поиска информации включает семь подпроцессов: осознание потребности, признание наличия проблемы, формулировка проблемы, выражение потребности, анализ результатов, переформулировка проблемы и переход к использованию. Эти подпроцессы повторяются по мере понимания информации пользователем. В «информационно-продовольственной» теории (information foraging theory) Питера Пиролли (Peter Pirolli) и Стюарта Карда (Stuart K. Card) эти процессы считаются высоко адаптивными к информационной среде. При такой трактовке поиска информации информационные потребности пользователей могут быть как совсем простыми (например, узнать номер телефона для заказа пиццы), так и протяженными во времени, связанными, например, с выполнением исследований в быстро изменяющейся прикладной области. Допускается также возможность, что на любой итерации пользователи могут прекратить попытки решения своей проблемы, чтобы, например, не допустить информационной перегрузки.
Кроме того, сочетание естественной склонности человека к сбору информации для формирования собственного поведения с наличием компьютерных средств Web стимулирует применение в повседневной жизни компьютеризованного образа мышления. Появление и развитие Всемирной Паутины и соответствующих поисковых инструментов расширило поисковые возможности человека, привело к тому, что наличие соответствующих навыков предполагается у всех грамотных людей, и все чаще человечество полагается на доступ к информации и на ее использование во всех жизненных ситуациях.
Кроме того, что легкий доступ к фактам, изображениям и документам приводит к изменению ролей традиционных информационных и справочных служб, в нем реализуется важный элемент концепции компьютинга как средства расширения возможностей человеческого интеллекта, введенной Дугласом Энгельбартом (Douglas Engelbart) около 50 лет тому назад. Web расширяет возможности нашей памяти, позволяя нам тратить больше умственных усилий на интерпретацию и использование информации для обучения и принятия решений.
По мере упрощения доступа к информации возрастают потребности людей в повсеместном доступе к ней во всех возможных ситуациях. Лавинообразный эффект повсеместного доступа к информации вкупе с ожидаемым расширением диапазона поисковых задач ставят новую проблему в областях теории поиска информации и разработки ISSS.
У этой проблемы имеются три взаимозависимых аспекта: более разумные модели взаимодействия человека с информацией; новые инструменты и службы, пригодные для использования при решении новых задач поиска информации; улучшенные методы оценки качества поиска информации.
Автором первой регулярной статьи тематической подборки является Питер Пиролли (Peter Pirolli, Palo Alto ResearchCenter). Его статья называется «Степени десятки: моделирование сложных систем поиска информации в разных масштабах» («Powers of 10: Modeling Complex Information-Seeking Systems at Multiple Scales»).
Для ученых и разработчиков в области систем поддержки поиска информации (ISSS) наступило увлекательное время. Новая технология продолжает способствовать резкому росту объема доступной информации, а это, в свою очередь, воздействует на жизнь людей, обеспечивая ресурсы для приспособления к все усложняющемуся миру, и также новые способы развлечений.
Появляются новые способы взаимодействия со все более содержательным контентом, а также создания контента. Национальные мероприятия, такие как инициатива Cyberinfrastucture в США, позволяют создавать более мощные платформы для работы с информацией. Эта развивающаяся область предоставляет ученым новые благоприятные возможности, поскольку имеется множество новых объектов исследования, множество новых идей, и результаты исследований потенциально могут оказать огромное влияние на будущие разработки.
Первая возможность основывается на том, что в области поиска информации, которая представляла собой эмпирическую дисциплину, опиравшуюся на несколько концептуальных схем, теперь используются строгие научные теории и прогнозирующие модели. Прогресс в областях когнитивистики и человеко-машинного взаимодействия ведет к образованию согласованного набора теорий и моделей, позволяющих решать проблемы поиска информации в разных масштабах, от долгосрочных социальных взаимодействий до ежеминутных индивидуальных запросов.
Вторая возможность опирается на расширение диапазона исследуемых и разрабатываемых объектов. Поиск информации в современном мире затрагивает далеко не только отдельных изолированных пользователей, работающих с каким-то одним инструментом для выборки некоторого документа или факта. Информационная среда используется для долгосрочных исследований и обучения. Она становится в большей степени социальной. Люди плодотворно используют для разных целей множество инструментальных средств и систем. Теперь информация – это не только пассивный текст; она образует среду, в которой можно искать факты, искать пользователей, искать пользователей, ищущих факты и т.д.
Эд Чи (Ed H. Chi, Palo Alto Research Center) представил статью «Поиск информации может быть общественным» («Information Seeking Can Be Social»).
Являясь частным случаем поиска информации, исследовательский поиск (exploratory search) подразумевает наличие плохо структурированных проблем и изменяемых целей. Процесс такого поиска имеет долгосрочный, изменчивый, итерационный и многоаспектный характер, и он в большей степени способствует обучению, а не получению ответов на конкретные вопросы. В то время как для поиска с целью извлечения фактов важно нахождение оптимального пути к документам, содержащим требуемую информацию, деятельность по изучению и исследованию чего-либо приводит к продолжительному изыскательскому процессу, в котором знания, получаемые в ходе этого «путешествия», не менее важны, чем его окончательные результаты. Поэтому системы поддержки поиска информации должны обеспечивать ориентиры, такие как родственные ключевые слова или рекомендуемые документы, повышающие эффективность этих изысканий. Одно из возможных решений состоит в создании социальных систем поиска информации, в которых используются общественные ориентиры, обеспечиваемые большим числом пользователей.
Исследователи в области информационного поиска обычно представляют поиск информации как изолированное действие одиночного человека, использующего Web-браузер. Это представление постепенно изменяется. Все больший интерес представляет совместный поиск и использование общественных закладок (social bookmarking).
Эти тенденции указывают на социальную природу поиска информации. В группе расширенного социального познания (Augmented Social Cognition) исследовательского центра в Пало-Альто (Palo Alto Research Center, PARC) проводились исследования со 150 участниками, показавшие, что многие активности, связанные с поиском информации, переплетаются с общественными взаимодействиями. Участники исследования опрашивались относительно своего последнего поиска с использованием методологии анализа критических случаев (critical-incident analysis methodology). Исследователей интересовали причины потребности в этом поиске, применявшиеся способы поиска и виды последующего использования результатов. Полученные ответы обрабатывались вручную с целью представления полной картины того, общались ли участники исследования с другими людьми до, во время и после поиска, и если да, то какова была природа этих общественных взаимодействий.
Многие участники взаимодействовали с другими людьми до начала поиска в Web. В ходе этого общения собиралась информация о том, на каких Web-сайтах и по каким ключевым словам следует искать. Общественные взаимодействия продолжались и в ходе поиска. Люди часто советовались с коллегами, например, относительно улучшения набора ключевых поисковых слов. В целом до начала и во время поиска в общественных взаимодействиях участвовало около 40% опрашиваемых. Пользователи часто распространяют результаты своего поиска в социальных сетях. В проводившемся исследовании результаты поиска распространяло около 60% опрашиваемых.
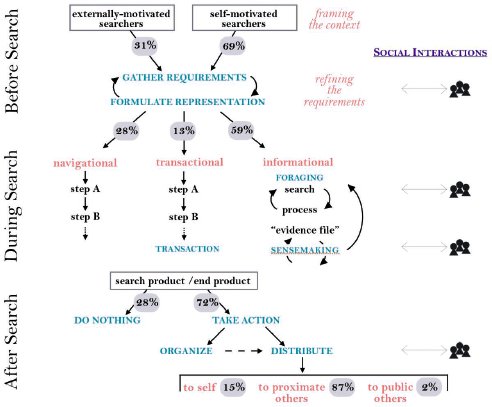
Рис. 1. Каноническая модель общественного поиска показывает наличие трех фаз процесса поиска, переплетающихся с социальными взаимодействиями
Результаты исследования были интегрированы с результатами предыдущих работ для формирования канонической модели общественного поиска информации, представленной на рис. 1. Поиск информации – это далеко не то же, что запрос к базе данных. Процесс поиска часто встраивается в общественные взаимоотношения. Социальные сети являются как источниками поисковых запросов, так и пунктами назначения, в которых распространяются полученные результаты.
Авторами статьи «Совместный поиск информации» («Collaborative Information Seeking») являются Джин Головчинский, Пернилла Кварфорд и Джереми Пикенс (Gene Golovchinsky, Pernilla Qvarfordt, Jeremy Pickens, FX Palo Alto Laboratory).
При поиске информации люди часто работают вместе, но традиционные системы поиска информации не поддерживают такое поведение, вынуждая людей прибегать к обходным путям, например, заниматься навигацией в Internet, подглядывая за действиями коллеги, или посылать ссылки по электронной почте, чтобы компенсировать отсутствие пригодных инструментов. Это наблюдение привело к тому, что несколько исследовательских групп занялось изучением различных аспектов поддержки совместного информационного поиска. Целью исследований является создание инструментальных средств поддержки совместного поиска на основе явным образом устанавливаемых общих потребностей в информации. В статье описываются промежуточные результаты этих исследований.
Следующая статья называется «Создание знания: что находится за пределами поиска по ключевым словам?» («Building Knowledge: What’s Beyond Keyword Search?»). Ее написала Моника Шрейфел (m.c. schraefel, Royal Academy of Engineering).
Нельзя спорить, что сегодня Web является основным поставщиком информации. Ключом к успеху Всемирной Паутины явилась возможность нахождения содержащейся в ней информации.
Основной способ доступа к Web основывается на использовании «прозрачного ящика», который по нескольким задаваемым нами словам угадывает наши желания и возвращает ссылки на требуемые ресурсы. Этот подход к нахождению информации настолько успешен, что трудно вспомнить, как мы ухитрялись искать информацию до появления средств поиска в Web по ключевым словам.
Успешные парадигмы могут иногда ограничивать нашу возможность представления других способов задавания вопросов, которые могли бы открыть новые и более мощные возможности. Ньютоновская модель вселенной как часового механизма, например, все еще может объяснить суть многих физических явлений. Можно сказать, что имелись только некоторые мелкие явления, которые хорошо не описывались этой моделью. И именно эти явления привели к потребности в улучшенной модели, другой парадигме. Теория относительности и квантовая механика, обеспечивающие совсем другие способы представления мира, позволили гораздо лучше понять нашу вселенную.
Успех поисковых машин может стать новой Ньютоновой парадигмой для Web. Этот подход позволяет нам обнаруживать так много информации, что трудно представить, чего с его применением нельзя было бы достичь. Но может ли эта парадигма быстро и эффективно помочь одинокой женщине найти лучшую работу, соответствующую ее увлечениям и навыкам? И если бы эта дама могла получить дополнительную подготовку и найти эту лучшую работу, как она могла бы получить требуемую информацию, оставаясь в рамках ограниченной парадигмы поиска по ключевым словам?
В литературе по информационному поиску и поиску информации эти разновидности сложного обнаружения информации и создания знаний моделируются в терминах стратегии и тактики поиска. В относительно новых исследованиях, посвященных так называемому изыскательскому поиску, упор делается на гармонизацию человеко-машинного взаимодействия с моделями поиска информации для разработки новых инструментов, направленных на поддержку альтернативных видов поиска и построения знаний.
Авторами статьи «Проблемы и направления развития в области оценки качества систем поддержки поиска информации» («Evaluation Challenges and Directions for Information-Seeking Support Systems») являются Диана Келли, Сьюзан Дьюмейс и Джем Педерсен (Diane Kelly, University of North Carolina at Chapel Hill, Susan Dumais, Microsoft Research, Jan O. Pedersen, A9.com).
Вы подумываете взять отпуск и провести его в каком-нибудь новом месте. Каким образом лучше подобрать устраивающие вас места отдыха, и услугами каких систем стоит воспользоваться? Поисковая ли это задача или же нечто более общее? Как оценить успешность ее решения?
Поисковые инструменты, поддерживающие решение подобных неоднозначных задач, принято называть системами поддержки поиска информации (ISSS). Центральным вопросом разработки ISSS является оценка ее качества. Как понять, работает ли ISSS достаточно хорошо, как измерить показатели ее качества, как использовать полученную информацию при создании более удачных систем?
В области информационного поиска (IR) оценка качества систем имеет долгую историю, восходящую к исследованиям методов автоматической индексации, начатым Сирилом Клевердоном (Cyril Cleverdon) в 1960-е гг. в Кренфилдском университете. Базовая модель оценки качества информационного поиска была расширена благодаря усилиям, связанным с организацией серии конференций TREC (Text Retrieval Conference), которые проводятся с 1992 г. ежегодно при поддержке Национального института стандартов и технологии (National Institute of Standards and Technology) и Министерства обороны США.
При применении базовой модели оценки качества IR исследователи совместно используют тестовые коллекции, включающие корпус текстов, запросы и показатели релевантности документов запросам. Поскольку при оценивании качества систем используются общие ресурсы и руководства, обеспечивается возможность сравнения поисковых систем и совершенствования алгоритмов.
В то время как в большинстве случаев основным показателем качества IR является эффективность поиска, в области интерактивного информационного поиска (IIR) наибольший интерес представляет то, как люди используют системы для поиска информации. Интерактивный трек (Interactive Track) конференции TREC формализовал метод оценки качества IIR, и он стал стандартом лабораторной оценки качества систем, ориентированных на поддержку IIR.
Модели оценки качества IR и IIR рассчитаны на лабораторную оценку качества, но исследователи в обеих областях проводят оценку качества систем и в реальных производственных средах. Например, специалисты компаний, которые производят поисковые машины, могут анализировать журналы, содержащие миллиарды записей. В некоторых случаях могут производиться испытания экспериментальных алгоритмов или поисковых интерфейсов путем их включения в вариант системы, доступный части пользователей.
Однако по многим причинам все эти подходы непригодны для оценки качества ISSS. Во-первых, при традиционной оценке качества IR учитываются не все типы задач, активностей и ситуаций поиска информации. Во-вторых, по причине динамической природы Web постоянно изменяется база объектов, доступных для поиска. В-третьих, задачи поиска информации часто бывают сложными, и в них отсутствуют стабильные, поддающиеся определению конечные точки. Наконец, поиск информации может происходить в течение длительного времени, из чего следует потребность в средствах продолжительной оценки, учитывающих происходящие изменения. В статье описываются направления, в которых развиваются модели и методы оценки качества ISSS.
Последняя статья тематической подборки называется «Взаимосвязи индустрии и академии» («Industry-Academic Relationships»). Ее автор – Дэниел Рассел (Daniel M. Russell, Google).
Индустрия и академия всегда работали вместе. Иногда работали хорошо, а временами испытывали взаимное непонимание. В области поиска информации исторически взаимоотношения были вполне понятными: академическая среда способствовала созданию первых поисковых машин.
Без академии мир поиска информации был бы сегодня совсем другим. Возможно, технология поисковых машин появилась бы и без участия университетов, но, несомненно, университетские исследования сыграли важную роль в развитии идей индексации, поисковых роботов и пользовательского интерфейса.
Теперь ситуация изменилась. В 1998 г., когда вслед за Yahoo и AltaVista появилась поисковая машина Google, работы университетского масштаба еще могли глубоко влиять на развитие фундаментальных исследований. Однако по мере развития технологии поисковых машин некоммерческим организациям стало трудно выполнять некоторые виды исследований. В таких исследовательских областях как алгоритмы ранжирования, масштабируемые распределенные системы и т.д. быстро стали требоваться дорогие и крупные инструменты и наборы данных почти такого же масштаба, как те, которые используются в физике высоких энергий.
Равно как отдельному физику вряд ли под силу построить свой собственный Большой адронный коллайдер (Large Hadron Collider, LHC), никакой отдельной академической исследовательской группе не удастся успешно выполнить исследования, для которых требуются тысячи процессоров, крупные бригады программистов, реализующих и поддерживающих программный код, и развитая вспомогательная инфраструктура.
Однако физика не перестала быть областью интенсивных исследований после того, как для некоторых ее направлений понадобились инструменты масштаба LHC. Аналогично, в области ISSS имеются направления, которые можно вполне успешно исследовать в университетах. Анализу этих направлений и посвящена основная часть статьи.
Единственную статью вне тематической подборки представил Бехруз Пархами (Behrooz Parhami, University of California, Santa Barbara). Статья называется «Головоломные проблемы вычислительной техники» («Puzzling Problems in Computer Engineering»).
Много пишется о нехватке квалифицированных специалистов в области информационной технологии и о потребности привлечения большего числа студентов к учебным программам по информатике и вычислительной технике. В США ситуация усугубляется ожидаемой волной ухода на пенсию специалистов старшего возраста.
Привлечение студентов к учебным программам по информатике и вычислительной технике необходимо и полезно, но это позволяет решить только часть проблемы. Соответствующие усилия должны подкрепляться стратегиями по закреплению студентов в области информационной технологии после того, как они приступили к изучению этих учебных программ. К сожалению, таким стратегиям не уделяется явное внимание в учебных планах, рекомендуемых IEEE Computer Society и ACM.
Поскольку студентам колледжей до начала занятий с реальными приложениями требуется получить базовую научную подготовку, студенты, специализирующиеся в области ИТ, не вступают в полный контакт с этой дисциплиной до третьего года обучения. Многие студенты добиваются отличных успехов в математике, физике и других предметах, но неохотно занимаются ими в изоляции от своей основной специализации. В конце концов, если бы у них имелась соответствующая склонность, они могли бы специализироваться в какой-либо фундаментальной науке. В результате студенты младших курсов воспринимают свои первые годы в колледже так же, как последние школьные годы: отсутствует контекст, связывающий курсы по математике, физике и даже программированию с практическими проблемами их области специализации.
Для решения этой проблемы на факультете электроники и вычислительной техники Калифорнийского университета в Санта-Барбара образован семинар для студентов младших курсов «Десять головоломных проблем вычислительной техники». Этот семинар, обязательный для студентов, специализирующихся в области вычислительной техники, знакомит студентов с некоторыми наиболее сложными проблемами, с которыми приходится сталкиваться специалистам-компьютерщикам в их повседневной деятельности.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС