В январском номере журнала продолжается традиция новогоднего обзора исследовательских работ, которые могут оказать существенное воздействие на развитие компьютерных технологий в следующие несколько лет. Статьи номера не объединены какой-либо общей темой и рассматриваются здесь в том порядке, как они размещены в журнале.
Первую статью написал Майкл Кусумано (Michael A. Cusumano, Massachusetts Institute of Technology). Она называется «Изменение софтверного бизнеса: переход от продуктов к услугам» («The Changing Software Business: Moving from Products to Services»).
Разительные изменения, происшедшие в софтверном бизнесе в последние несколько лет, оказывают серьезное влияние как на пользователей, так и на производителей программных продуктов и сервисов. Падали объемы продаж, снижалась стоимость лицензий, и значительную часть дохода компаниям стали приносить услуги, такие как предоставление пользователям пачей и оказание им технической поддержки на основе ежегодной платы.
Эти изменения наиболее характерны для поставщиков корпоративного программного обеспечения. Характерен пример компании Siebel, объем продаж которой серьезно падал до поглощения этой компании компанией Oracle в 2005 г. Десятилетием раньше на подобном перепутье находилась сама Oracle – доходы от сервиса и поддержки начинали превосходить доходы от продаж продуктов. Трудно сказать, предшествовало ли этому сокращение объемов продаж или снижение цен на продукты, но в любом случае доходы от услуг (включая поддержку, доходы от которой составляют до 60% от общего объема доходов от услуг) стали более существенными, чем доходы от продажи продуктов.
Имеются некоторые исключения. Доходы от продаж продолжают составлять большую часть доходов компаний, производящих игровое программное обеспечение, хотя в области онлайновых игр быстро возрастают доходы от услуг. Платформо-ориентированные компании, такие как Microsoft, опирающаяся на крупную экосистему производителей персональных компьютеров, а также корпоративных и индивидуальных пользователей, которым удается успешно продавать Windows и Office, продолжают получать огромные доходы от продаж продуктов. Но даже Microsoft сталкивается с изменениями. По сведениям компании, в финансовом 2007-м году доход от услуг в сегменте серверов и инструментальных средств составил 3% от общего дохода компании, а доход от онлайновых услуг (MSN) – 5%. Всего лишь несколько лет тому назад весь доход Microsoft происходит из продажи продуктов.
В статье приводится анализ состояния текущего бизнеса разных софтверных компаний, и предлагаются некоторые характеристики бизнес-модели, которая складывается в этой новой ситуации.
Автором следующей статьи является известный многим Дэвид Харел (David Harel, Weizmann Institute of Science). Статья называется «Можно ли освободить программирование, пауза?» («Can Programming Be Liberated, Period?»).
Девять лет назад автор решил написать о своей мечте, исполнение которой позволило бы программистам вести разработку, начиная от «проигрывания» инкрементных сценариев поведения программной системы и заканчивая работающим программным кодом. В этой статье некоторые части, представляющие наибольшие технические затруднения, были представлены без достаточного обоснования осуществимости предлагаемых подходов. Поэтому автор назвал свою идею «мечтой». Со времени первой публикации статьи (Computer, Jan. 2001, pp. 53-60, см. также http://www.osp.ru/os/2001/02/179956/) эта мечта не только не исчезла, но с каждым годом продолжает все больше изводить автора, расширяясь и уточняясь.
Более существенным является тот факт, что с того времени была выполнена довольно большая работа, результаты которой пока еще далеки от того, чтобы можно была превратить мечту в план работ, но, тем не менее, обеспечивают некоторое предварительное обоснование реализуемости этой мечты. Поэтому автор решил еще раз вернуться к этой теме и описать свою мечту заново, более точно, предложив ее более яркий и расширенный вариант.
Статья не является специальной или технической. Более того, как отмечает автор, не считая материала, размещенного во вкладке (обоснование осуществимости подхода к программированию на основе сценариев), к статье можно относиться, как к сбивчивым рассуждениям восторженной и ошеломленной личности. Для дополнительного привлечения публики название статьи основано на названии Тьюринговской лекции и статьи Джона Бэкуса (John Backus) «Can Programming Be Liberated from the von Neumann Style? A Functional Style and Its Algebra of Programs».
Мы прошли долгий путь с того времени, когда программирование заключалось в утомительном и скучном перечислении команд машинного уровня, предписывающих правила изменения и перемещения бит и слов в памяти конкретного компьютера. В намерения автора не входило создание обзора истории программирования, однако ее можно охарактеризовать как удивительное восхождение по ступеням лестницы создания компьютерных языков: от машинных языков к языкам ассемблера, затем к традиционным императивным языкам программирования, и от них – к разнообразным современным стилям программирования – функциональному, логическому, параллельному, визуальному, синхронному, основанному на ограничениях, объектно-ориентированному, аспектно-ориентированному и т.д. Имеется также множество специализированных языков, разработанных для конкретных видов приложений.
Однако в некотором смысле программирование все еще остается тем же самым технически утомительным делом, хотя и выполняется на более высоком, более адекватном уровне абстракции. По-прежнему приходится писать программы, обычно используя символы, ключевые слова и операционные инструкции, чтобы сказать компьютеру, что ему следует делать. Компилятор – это всего лишь средство трансляции высокоуровневых программ в программы, доступные для понимания и исполнения машинами. И от программиста по-прежнему требуется тестирование и отладка (а лучше, верификация) программ для обеспечения уверенности в том, что при выполнении программы от компьютера будут получены требуемые результаты. Более того, необходимо тщательно специфицировать, какие именно результаты требуется получить, и эти спецификации зачастую не менее сложны и чреваты ошибками, чем сами программы.
В настоящее время появилась дополнительная сложность, происходящая из возрастающего числа приложений, несколько частей которых выполняется параллельно и часто в распределенном режиме. Для примера достаточно рассмотреть Internet-приложения и Web-сервисы. В этих случаях дополнительная проблема состоит в том, что каждую часть приходится программировать по отдельности, а затем убеждаться в том, что совместное поведение частей системы, их оркестровка приводят к требуемым результатам.
Автор утверждает, что, в общем и целом, даже наиболее современным подходам свойственны следующие три ограничения, которые он называет «оковами» программирования: (i) необходимость записывать программу в виде символьного, текстуального или графического артефакта; (ii) необходимость специфицировать требования («что») отдельно от программы («как») и противопоставлять их друг другу; (iii) необходимость структурировать поведение в соответствии со структурой системы, обеспечивая поведение каждой части или каждого объекта системы.
Можно ли освободить программирование от этих ограничений: от клавиатуры, от неблагодарного противопоставления «что» и «как», от потребности разделения динамики между строками программной структуры? В чем состоит альтернатива? Как можно программировать компьютер, не говоря ему точно, что он должен делать, без потребности использования в использовании материальной среды для представления этого предписания? Как можно убедиться в том, что будут получены желаемые результаты, если каким-то образом не сформулировать требования и способ их удовлетворения и не сравнить эти формулировки? И как можно программировать множество вещей, не обеспечивая каждую из них отдельными инструкциями?
Конечно, имеются целостные подходы к программированию, явным назначением которых является устранение или смягчение некоторых ограничений из числа трех перечисленных выше. Например, по отношению к ограничению (i) для некоторых прикладных областей разработаны новые методы для сокращения объема трудозатрат при написании программ, соответствующих некоторому классу требований. Примерами таких методов являются Query-By-Example для реляционных баз данных, а также электронные таблицы.
Что касается ограничения (ii), то логические и функциональные языки, а также многие работы в области, обобщенно называемой автоматическим программированием, в частности, чрезвычайно амбициозная и интересная идея интенционального программирования, направлены на то, чтобы позволить программисту формулировать то, чего он хочет, оставляя много из того, как это можно сделать, на компилятор или интерпретатор. Аналогичная цель преследуется в языках, основанных на ограничениях, и специализированных генераторах приложений.
В связи с ограничением (iii) в области аспектно-ориентированного программирования исследователи пытаются снизить потребность в полном выравнивании поведения со структурой программы путем обеспечения возможности добавления к внутреннему поведению объектов специального многоаспектного поведения, охватывающего несколько объектов.
Мечта автора статьи более амбициозна. Он хочет всего сразу. Почему бы не натянуть надо всем этим общую оболочку и не попытаться изменить облик программирования? Причем эти изменения должны происходить не только за счет создания нового поколения языков программирования или новой методологии, а и за счет применения совсем иного подхода к программированию. Мечта состоит в освобождении программистов от оков программирования, предоставлении им возможности работать в условиях гораздо большей свободы, превращении программирования в интуитивный, естественный и приносящий удовольствие процесс. Автор призывает к тому, чтобы использовать всю огромную мощь компьютеров для реализации этой идеи, для совершения гораздо более глубокого перехода, чем тот, который связан с компиляцией, перехода, основанного на использовании естественных и почти игровых средств программирования, для получения полностью функциональных и исполняемых машиной программ.
Чтобы читатели не подумали, что автор предлагает очередное волшебное решение всех проблем, он добавляет, что у него нет никакого решения. У него нет ничего, что работало бы для всех видов программирования, и, безусловно, нет ничего волшебного. Однако некоторые предварительные факты показывают, что стоит пройтись по этой «дороге в Изумрудный город», хотя бы для некоторых типов программ. Но основная идея статьи состоит не в том, что если пойти путем автора, то все будут счастливы, а в том, что, возможно, об этом стоит побольше подумать.
Статью «Оценка архитектур, основанных на интегрированных цифровых клеточных автоматах» («An Assessment of Integrated Digital Cellular Automata Architectures») представили Виктор Жирнов, Ральф Кэвин, Грег Лиминг и Космас Галацис (Victor Zhirnov, Ralph Cavin, Semiconductor Research Corporation, Greg Leeming, Microelectronics Advanced Research Corporation, Kosmas Galatsis, FCRP Center on Functional Engineered Nano Architectonics, UCLA).
Недавнее внедрение двухъядерных процессоров, возможно, означает начало широкомасштабного перехода к параллельной обработке. Как будет развиваться параллельная обработка, и какой будет доминирующая компьютерная архитектура в будущем? По мере того, как технология достигает пределов CMOS и превосходит их, ответы на эти вопросы могут определяться физическими реалиями компьютерной аппаратуры.
Уровень интеграции наномасштабных электронных устройств может, в конечном счете, достичь показателей в 1010 – 1011 устройств на квадратный сантиметр (www.itrs.net/reports.html). На этом уровне длинные внутренние шины представляют значительную проблему для функционирования (потребление энергии), проектирования и производства (нерегулярные массивы внутренних шин с произвольными соединениями). Кроме того, наномасштабным элементам, вероятно, будет свойственна более высокая интенсивность отказов, чем их сегодняшним аналогам. Требования же к низкому энергопотреблению и малым размерам транзисторов, видимо, приведут к более высокой интенсивности тепловых и квантовых ошибок. Более того, проблема проектирования сложных нерегулярных структур на этих уровнях плотности становится все менее и менее разрешимой.
При наличии этих реалий будущая наномасштабная технология может привести к использованию совсем других подходов к обработке информации и вычислениям. Один из возможных подходов может опираться на цифровые клеточные автоматы. Недавнее появление многоядерных архитектур, вызванное ограничениями полупроводниковой технологии, побуждает к исследованиям архитектур, основанных на клеточных автоматах, как альтернативному подходу к обработке информации.
Этот возможный переход к новым компьютерным архитектурам предсказывался ранее. Джанфранко Биларди и Франко Препарата еще в 1993 г. утверждали, что при достижении компьютерной технологией физических пределов масштабирования (определяемых скоростью света), предельно малых размеров устройств, предельных значений коэффициентов разветвления по входу и выходу практические компьютерные архитектуры придется основывать на регулярных массивах локально соединенных вычислительных элементов.
Архитектуры, основанные на клеточных автоматах, являются возможной альтернативой так называемых фон-неймановских архитектур. В действительности, фон Нейман предложил оба эти подхода в начале 1950-х гг.
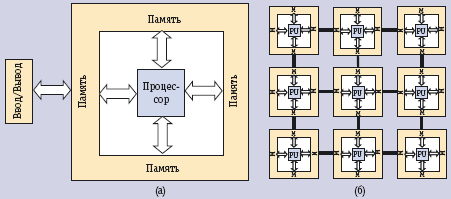
Как показано на рис. (a), традиционная фон-неймановская, или последовательная архитектура характерна для компьютера, состоящего из процессора (PU) и запоминающего устройства (M). В памяти хранятся и команды, и данные, и последовательность логических операций основывается на флагах и шинах управления. На основе такой системы локальной памяти и логических устройств можно реализовать компьютер общего назначения.
С другой стороны, как показано на рис. (b), клеточный автомат состоит из одинаковых ячеек с одной и той же структурой соединений с соседними ячейками. Каждую ячейку отличает от ее соседей только состояние. Состояние каждой ячейки – это некоторая функция от состояний соседних ячеек.
Для изучения возможности применения клеточных автоматов в качестве архитектурной основы реализации компьютеров общего назначения авторы стремились найти ответы на следующие основные вопросы:
- какова должна быть минимальная внутренняя сложность ячеек клеточного автомата, чтобы поддерживать вычисления общего назначения?
- сколько должно содержаться ячеек в архитектурах, основанных на цифровых клеточных автоматах, чтобы они были бы настолько же эффективны при вычислениях общего назначения, как и фон-неймановские архитектуры?
- могут ли устройства, основанные на пост-CMOS технологии, обеспечить реальные вычислительные преимущества в архитектуре, основанной на клеточных автоматах?
- уменьшается ли сложность внутренних взаимосвязей в архитектуре, основанной на клеточных автоматах?
- существуют ли реальные методы обеспечения устойчивости к жестким и мягким ошибкам в клеточных автоматах?
- обеспечивают ли архитектуры, основанные на клеточных автоматах, преимущества по отношению к потребляемой мощности, надежности, проектированию и производству?
Частичные ответы на эти вопросы приводятся в статье. В частности, авторы установили, что для построения клеточного автомата с изменяемыми правилами формирования состояния ячеек потребуются ячейки, содержащие по 2300 элементов, что составляет малую часть от числа ячеек базового микропроцессора, такого как Intel 4004. Но не удалось установить, сколько потребуется ячеек в архитектуре, основанной на клеточном автомате, чтобы она была настолько же вычислительно эффективна, что и фон-неймановские архитектуры общего назначения.
Авторами статьи «На пути к соревновательному роботу, играющему в бильярд» («Toward a Competitive Pool-Playing Robot») являются Майкл Гринспан, Джозеф Лэм, Марк Годард, Имран Заиди, Сэм Джордан, Уилл Лекай, Кен Андерсон и Донна Дюпуа (Michael Greenspan, Joseph Lam, Marc Godard, Imran Zaidi, Sam Jordan, Queen’s University, Will Leckie, Nortel, Ken Anderson, Larus Technologies, Donna Dupuis, University of British Columbia).
Из-за закрытой двери одной из комнат в здании студенческого городка доносится характерный стук бильярдных шаров. Это не студенческая комната отдыха, а лаборатория, где разрабатывается основанная на машинном зрении интеллектуальная роботехническая система, предназначенная для игры в соревновательный пул. Система, называемая Deep Green, в настоящее время играет на уровне выше любительского, и целью авторов является развитие системы до такой степени, чтобы она могла играть на равных с умелым противником-человеком, в пределе на чемпионском уровне.
Пул (под этим термином авторы объединяют все виды спорта с использованием бильярдного стола, киев и шаров, включая бильярд, карамболь и снукер) обычно ассоциируется с прокуренными барами, а не с современной роботехникой. Пул появился в королевских судах средневековой Европы как комнатный вариант крокета. Сегодня во всем мире наблюдается возрождение этой игры. В различные варианты пула играют почти во всех странах, а в 1998 г. на олимпиаде в Нагано пул был признан демонстрационным видом спорта. По данным на 2005 г. только в Соединенных Штатах в пул играет более 35 миллионов людей. По популярности эта игра занимает восьмое место, после велоспорта и рыбной ловли.
Первая попытка автоматизировать пул была предпринята в Бристольском университете в 1980-х гг., где выполнялся проект Snooker Machine, кульминацией которого стала телевизионная игра в научной программе QED компании BBC. С этого времени исследователи разработали ряд робототехнических систем для игры в пул, а также обучающих систем, в которых имелся компонент машинного зрения, но отсутствовали роботехнические воздействия.
Статью «Использование цифровой эволюции» («Harnessing Digital Evolution») написали Филип Маккинли, Бетти Ченг, Чарльз Офриа, Дэвид Ноустер, Бенджамин Бекман и Хизер Голдсбай (Philip McKinley, Betty H.C. Cheng, Charles Ofria, David Knoester, Benjamin Beckmann, Heather Goldsby, Michigan State University).
Около 150 лет тому назад Чарльз Дарвин объяснил, как эволюция и естественный отбор преобразовали самые ранние примитивные формы жизни в сегодняшнее богатое разнообразие жизненных форм. По оценкам ученых, этот процесс длится на Земле, по меньшей мере, 3,5 миллиарда лет.
Но сейчас наблюдается период расцвета эволюции другого мира: мира компьютеров. Эволюция этого мира помогает людям решать сложные технические проблемы и обеспечивает понимание процесса эволюции в природе. По мере повышения вычислительной мощности компьютеров исследователи и разработчики применяют эволюционные алгоритмы для решения все более разнообразных проблем. В области эволюционных вычислительных методов, такие как генетические алгоритмы, уже удалось достичь значительных успехов. Получаемые результаты во многих прикладных областях, таких как разработка карт флэш-памяти или проектирование крыльев самолетов, конкурентноспособны с результатами, получаемыми людьми, и иногда и превосходят их.
Авторы исследуют проблему применимости компьютерных методов эволюции для помощи при построении более качественного программного обеспечения. Эту работу мотивирует все возрастающее взаимодействие между компьютерной технологией и физическим миром. Системы должны адаптироваться к своей среде, восстанавливаться после сбоев, оптимизировать свою производительность и защищаться от атак злоумышленников с минимальным участием людей.
Для создания надежных и отказоустойчивых систем можно воспользоваться опытом природы. У живых организмов имеется поразительная возможность приспосабливаться к изменениям окружающей среды, как к краткосрочным за счет фенотипической пластичности, так и к дальнесрочным на основе дарвиновской эволюции. Действительно, сложность ни одной существующей киберсистемы не превосходит сложности биосферы Земли, а жизнь на Земле эволюционирует не только для того, чтобы справляться с этой сложностью, но и чтобы процветать на ее основе.
Многие исследователи изучают, как можно было бы использовать характеристики природных систем для разработки улучшенных компьютерных систем. В одном из подходов имитируется поведение общественных насекомых и представителей других биологических видов. Однако, хотя такие биоимитационные методы перспективны при управлении группами автономных роботехнических систем и в других приложениях, они опираются только на поведение, наблюдаемое в природе сегодня. В чисто биоимитационных подходах имитируются результаты эволюции, но не принимается во внимание процесс естественного отбора, в результате которого возникло такое поведение.
Например, можно разработать управляющее программное обеспечение микроробота, в котором имитируется некоторое поведение муравьев. Однако, хотя у робота могут иметься некоторые физические характеристики, напоминающие характеристики муравья, число различий безмерно превзойдет число сходных черт. С другой стороны, если бы имелась возможность эволюции управляющего программного обеспечения, в которой принимались бы во внимание возможности робота и характеристики окружающей среды, то могла бы возникнуть новое поведение, способствующее более эффективному управлению роботом.
Подобную возможность предоставляет цифровая эволюция, и авторы исследуют, как она может помочь при разработке надежных вычислительных систем. Цифровая эволюция – это форма эволюционных вычислений, в которой самовоспроизводящиеся компьютерные программы эволюционируют внутри определяемой пользователем вычислительной среды. Эти цифровые организмы получают ограниченное число ресурсов, использование которых должно ими тщательно балансироваться, чтобы они могли выжить. При размножении организмов происходят мутации на уровне команд, производящие изменения внутри популяции. При смене поколений естественный отбор может приводить к появлению последовательностей команд, реализующих более сложное поведение, в котором иногда обнаруживаются неожиданные и поразительно остроумные стратегии решения проблем.
В описываемом исследовании используется и расширяется платформа цифровой эволюции Avida. Каждый цифровой организм состоит из циклического списка команд (генома) и виртуального центрального процессора, на котором выполняются эти команды. В среде Avida содержится несколько ячеек, в каждой из которых содержится не более одного организма, называемого авидианом (Avidian). Когда авидиан размножается, система помещает отпрыска в случайным образом выбираемую ячейку, прекращая существование любого ее предыдущего обитателя. Организмы могут посылать друг другу сообщения, производить и потреблять ресурсы, а также воспринимать и изменять свойства своей окружающей среды. На основе этих взаимодействий организм может приобретать или утрачивать циклы виртуального ЦП, что влияет на его скорость выполнения команд.
Архитектура виртуального ЦП, используемого в большинстве выполненных авторами исследований, является простой: три регистра общего назначения, два стека общего назначения и четыре специализированных головки. Эти головки служат указателями на геном организма и напоминают традиционный счетчик команд или указатель стека. Набор команд этого виртуального ЦП является полным по Тьюрингу, и, следовательно, на нем можно реализовать любую вычислительную функцию. Доступные команды позволяют выполнять основные вычислительные действия (сложение, умножение, сдвиги), управлять потоком выполнения, производить коммуникации и размножаться. Хотя набор команд напоминает традиционный язык ассемблера, он разработан таким образом, что случайная мутация (вставка, удаление или изменения инструкций) всегда приводит к образованию синтаксически корректной программы.
Авидианы получают поощрительные циклы виртуального ЦП для выполнения определяемых пользователями задач, которые обычно определяются в терминах наблюдаемого извне поведения организмов – их фенотипа. Например, от организма можно потребовать выполнение конкретной математической или логической операции с выводом результата или коммуникацией с соседними организмами, полезной для распределенного решения проблемы. Задачи оказывают на популяцию давление отбора, причем поддерживаются геномы, мутации которых производят последовательности команд, позволяющие добиться решения задачи.
В исследованиях авторов длина эволюционирующих сегментов кода для выполнения задач составляла от нескольких команд до нескольких десятков команд. Эволюционное решение может быть не оптимальным, если рассматривать задачи по отдельности, но, вероятно, в нем будут содержаться свойства, делающие его хорошо приспособленным к среде, например, устойчивость к мутациям. Кроме того, код для выполнения задач не может мутировать в геном за счет размножения, что является единственным механизмом, посредством которого организмы могут передавать свой генетический материал будущим поколениям. Наиболее успешные авидианы – быстрее других размножающиеся или выполняющие определяемые пользователями задачи – с большей вероятностью распространятся и, в конце концов, будут доминировать в популяции. В действительности Avida удовлетворяет трем условиям, необходимым для поддержки эволюции: размножение, изменение (мутация) и дифференцированная биологическая реакция популяции на естественный отбор (соревнование).
Платформа Avida была создана, в основном, для исследования эволюции в природе. Наблюдения эволюции цифровых организмов позволяют исследовать вопросы, которые трудно или невозможно изучать на основе органических форм жизни, такие как эффекты явного запрета некоторых мутаций или анализ геномов всех организмов на некотором пути эволюции. Однако Avida является расширяемой платформой, что позволяет исследователям и разработчикам применять цифровую эволюцию к различным прикладным областям, включая те из них, которые не относятся к биологии. Пользователь может полностью настроить многие характеристики Avida, включая архитектуру виртуального ЦП, набор команд и задачи. Сегодня пользователь с использованием современного вычислительного кластера за один может исследовать сотни популяций, миллионы поколений. По сути, Avida обеспечивает исследователей цифровой «чашкой Петри» для создания и анализа новых видов компьютерного поведения.
Авторами последней большой статьи январского номера являются Роберт Рейнольдс, Мостафа Али и Тэер Яуси (Robert G. Reynolds, Mostafa Ali, Thaer Jayyousi, Wayne State University). Статья называется «Анализ общественного строя древних городских центров с применением культуральных алгоритмов» («Mining the Social Fabric of Archaic Urban Centers with Cultural Algorithms»).
Применение набора инструментальных средств искусственного интеллекта и интеллектуального анализа данных к существующим археологическим данным из доисторического городского центра Монте Альбан (Monte Albán) обеспечивает потенциал для построения основанных на агентах моделей вновь обнаруживаемых древних городских центров. Более точно, авторы исследовали период, связанной с появлением этого древнего городища. Целью являлось порождение набора правил принятия решений с использованием методов анализа данных с последующим применением комплекса инструментальных средств культуральных алгоритмов (cultural algorithm toolkit, CAT) для установления исходных социальных взаимодействий между первыми обитателями.

Археологический объект Монте Альбан находится в Долине Оахака (Oaxaca) в Центральной Мексике. На рисунке показан общий вид городища, центральная площадь которого находится в южной части плоской вершины холма, на 400 метров выше уровня долины. В этом месте имеется более 2000 террас, на которых жили и работали обитатели городища.
В период Тьеррас-Ларгас (Tierras Largas) (1400-1150 гг. до н. э.) в долине Оахака появились первые деревенские поселения, и лишь спустя три периода общественного развития в период Монте Альбан Ia (500-300 гг. до н. э.) возникло государство Монте Альбан. Долина перешла под управление государством в период Монте Альбан II (c 150-100 гг. до н. э. до 100 года нашей эры). В период Монте Альбан III (200-500 гг.) наблюдался упадок государства и образование ряд городов-государств в разных частях долины. Эти фазы представляют неравномерные срезы времени, определенные на основе образцов керамики, которые были найдены в Монте Альбан. Каждой фазе свойственны изменения в преобладающем стиле керамики. Хронология фаз определялась на основе радиоактивного изотопа углерода, присутствующего в образцах керамики каждого стиля.
Каждая терраса в Монте Альбан описывается сотнями характеристик культуры и окружающей среды, полученных в ходе интенсивного археологического исследования, которое проводилось в рамках проекта Valley of Oaxaca Settlement Pattern. В описываемом исследовании набор данных об этих террасах обрабатывался с использованием нескольких различных методов анализа данных, включая обучение на основе деревьев принятия решения.
Гипотетические модели урбанизации поселений, таких как Монте Альбан, показывают, что они относятся к наиболее интересным поселениям доколумбовой Центральной Америки. Эти доисторические городские центры являлись, с одной стороны, появились в результате социальных изменений, а с другой стороны, представляли собой платформу для будущих изменений. Такие архаические поселения описываются в следующих измерениях: количество населения или площадь города; местоположение или природные условия (на реке, на морском побережье, на вершине горы и т.д.); функция (культовая, коммерческая, оборонная или административная); позиция в иерархии поселений; морфология, или форма, на которую влияют все остальные измерения.
Подход авторов опирается, главным образом, на морфологию поселения, поскольку в ней отражаются все остальные характеристики. Типовой древний город состоит из четырех основных частей: однородные части, такие как крупные многосемейные кварталы; центральная часть, или площадь; уличная сеть; специальная область, такая как рынок. Не во всех городах обязательно присутствуют все части, но в них отражаются особенности, которые были запланированы в морфологии, или форме города.
В морфологии города также присутствуют незапланированные компоненты, отражающие его развитие или упадок во времени. За последние десятилетия разработано несколько моделей для описания изменяющегося облика современных городов. Эти модели включают следующее: концентрические зоны, основанные на росте современных городов, с центром города, окруженным концентрическими зонами деятельности; сектора, в которых сохраняются различия в использовании земли вблизи центра, и которые все более расширяются при удалении от центра по мере роста города (эти различия могут возникать по жилищным, экономическим и культовым причинам); несколько дополнительных центров, вокруг которых деятельность организуется в концентрических зонах или секторах.
Упомянутые модели отчетливо показывают, что внутри современного города будут присутствовать образцы, отражающие структуру города в целом, а также образцы, отражающие специфические области деятельности. Авторы ожидают, что в случае успешного применения ими методов интеллектуального анализа данных будут получены правила, свойственные образцам архаического города, а также правила, свойственные конкретным регионам. Пространственное расширение этих извлеченных правил может позволить распознать конкретную морфологию, связанную с заданным городом. Задача авторов состоит в том, чтобы убедиться в возможности использования какой-либо из упомянутых моделей для описания морфологии архаического города.
Естественным средством представления правил поддержки принятия решения является дерево принятия решений. В предыдущих исследованиях авторы использовали деревья принятия решений для получения характеристик образцов поселений в области, примыкающей к Монте Альбан, для одного периода времени, однако проводимое теперь исследование городского поселения гораздо сложнее изучения более мелких периферийных поселений. Дерево принятия решений – это направленный ациклический граф, описывающий некоторый образец в терминах вариантов, выбираемых в соответствии со значениями выбранных переменных. Варианты, выбираемые в верхней части дерева, более важны при определении образца, чем те, которые выбираются вблизи листьев. Путь в дереве принятия решений от корня дерева к некоторому листовому узлу представляет последовательность действий или вариантов.
В данном случае структура дерева принятия решений является особенно уместной, поскольку авторы усматривают некоторую иерархическую структуру в том, как переменные влияют на принятие решения, учитывая, что во всех моделях формирование города происходит относительно некоторого центрального компонента – например, главной площади или уличная сеть.
Культуральные алгоритмы (КА) – это один из нескольких подходов к моделированию общественного интеллекта (social intelligence) для решения оптимизационных проблем. КА включают класс вычислительных моделей, полученных на основе наблюдений над процессом культурной эволюции в природе. Авторы встроили инфраструктуру КА в систему имитационного моделирования Repast. Полученная система, получившая название CAT, включает культуральные алгоритмы, ядро системы, подсистему визуализации, базу данных (Access или MySQL) и подсистему анализа.
Всего вам доброго, до следующей встречи, Сергей Кузнецов.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

