Часть 1. Общее представление об информационной системе
В уже достаточно долгой истории компьютерной индустрии (скоро будем отмечать 50-летний юбилей) всегда можно было выделить два основных направления: вычисления, а также накопление и обработка информации. Как известно, возникновение компьютеров главным образом стимулировалось необходимостью проведения массивных расчетов для создания ядерного оружия и ракетной техники. Объемы требуемых вычислений просто не позволяли произвести их в приемлемое время традиционным коллективом расчетчиков. Итак, первыми пользователями компьютеров и разработчиками компьютерных программ стали вычислительные математики. До сих пор многие представители старшего поколения программистов предпочитают называть себя математиками, даже если в последние 20-30 лет им не приходилось написать хотя бы одну вычислительную программу, не говоря уже о разработке методов и алгоритмов компьютерных вычислений.
Однако, почти сразу на появление компьютеров обратили внимание бизнесмены. Как правило, в гражданском бизнесе не требуются массивные расчеты за исключением таких отраслей как, например, авиа- или автомобилестроение. В более распространенных видах гражданского бизнеса (банковское дело, биржевые операции, системы резервирования билетов или мест в гостиницах) основной проблемой всегда являлись объемы информации, которую необходимо собирать, надежно хранить и оперативно обрабатывать. Появление информационных систем, основным назначением которых является решение отмеченной проблемы, явилось ответом компьютерной индустрии на требования мира бизнеса.
В этой вводной части курса будет введено общее представление о сути понятия "информационная система". Основной целью является формулировка понятийной основы, на которой будет базироваться более конкретный материал следующих частей. Часть состоит из четырех разделов. В первом разделе определяются общие специфические черты класса программных систем, которые можно отнести к информационным системам. Второй раздел посвящен рассмотрению типовых задач, для решения которых используются информационные системы. В третьем разделе обсуждаются типичные проблемы, с которыми приходится сталкиваться при проектировании, разработке и сопровождении информационных систем. Наконец, в четвертом разделе анализируются требования к техническим средствам, на основе которых разумно строить информационную систему.
1.1. Специфика информационных программных систем
Конечно, в зависимости от конкретной области применения информационные системы могут очень сильно различаться по своим функциям, архитектуре, реализации. Однако можно выделить, по крайней мере, два свойства, которые являются общими для всех информационных систем. Во-первых, любая информационная система предназначена для сбора, хранения и обработки информации. Поэтому в основе любой информационной системы лежит среда хранения и доступа к данным. Среда должна обеспечивать уровень надежности хранения и эффективность доступа, которые соответствуют области применения информационной системы. Заметим, что в вычислительных программных системах наличие такой среды не является обязательным. Основным требованием к программе, выполняющей численные расчеты (если, конечно, говорить о решении действительно серьезных задач), является ее быстродействие. Нужно, чтобы программа произвела достаточно точные результаты за установленное время. При решении серьезных вычислительных задач даже на суперкомпьютерах это время может измеряться неделями, а иногда и месяцами. Поэтому программисты-вычислители всегда очень скептически относятся к хранению данных во внешней памяти, предпочитая так организовывать программу, чтобы в течение как можно более долгого времени обрабатываемые данные помещались в основной памяти компьютера. Внешняя память обычно используется для периодического (нечастого) сохранения промежуточных результатов вычислений, чтобы в случае сбоя компьютера можно было продолжить работу программы от сохраненной контрольной точки.
Во-вторых, информационные системы ориентируются на конечного пользователя, например, банковского клерка. Такие пользователи могут быть очень далеки от мира компьютеров. Для них терминал, персональный компьютер или рабочая станция представляют собой всего лишь орудие их собственной профессиональной деятельности. Поэтому информационная система обязана обладать простым, удобным, легко осваиваемым интерфейсом, который должен предоставить конечному пользователю все необходимые для его работы функции, но в то же время не дать ему возможность выполнять какие-либо лишние действия. Иногда этот интерфейс может быть графическим с меню, кнопками, подсказками и т.д. Сейчас очень популярны графические интерфейсы, и как мы увидим в следующих частях курса, многие современные средства разработки информационных приложений прежде всего ориентированы на разработку графических интерфейсов. С другой стороны, немного странным фактом является то, что многие конечные пользователи (например, банковские операционисты) не любят графические терминалы, предпочитая более убогие интерфейсные средства доступа к информационной системе с современного, но традиционного алфавитно-цифрового терминала. Это кажется действительно несколько странным, потому что на Западе, где практически любой кассовый аппарат является в действительности персональным компьютером, невозможно увидеть ни одного алфавитно-цифрового монитора. Возможно, в России это просто временный социально-психологический эффект: после многих лет общения с низкокачественными отечественными цветными телевизорами люди считают, что использовать графический монитор более вредно, чем монохромный алфавитно-цифровой. Но в любом случае наличие развитых интерфейсных средств является обязательным для любой современной информационной системы.
И снова заметим, что вычислительные программные системы не обязательно обладают развитыми интерфейсами. Конечно, это зависит от степени отчуждаемости программного продукта. Если система предназначена для продажи, то она должна обладать хорошим интерфейсом хотя бы в целях маркетинга. Но как правило, серьезные вычислительные программы почти уникальны. Расчеты выполняются либо разработчиками программ, либо людьми из того же окружения. Для них гораздо важнее быстродействие вычислений, чем удобство запуска программы, а наличие развитого интерфейса предполагает существенный расход компьютерных ресурсов. Как профессионалы компьютерного мира, эти люди могут справиться с некоторыми неудобствами при работе с компьютером.
1.2. Задачи информационных систем
Конкретные задачи, которые должны решаться информационной системой, зависят от той прикладной области, для которой предназначена система. Области применения информационных приложений разнообразны: банковское дело, страхование, медицина, транспорт, образование и т.д. Трудно найти область деловой активности, в которой сегодня можно было обойтись без использования информационных систем. С другой стороны, очевидно, что, например, конкретные задачи, решаемые банковскими информационными системами, отличаются от задач, решение которых требуется от медицинских информационных систем.
Но можно выделить некоторое количество задач, не зависящих от специфики прикладной области. Естественно, такие задачи связаны с общими чертами информационных систем, рассмотренных в предыдущем разделе. Прежде всего, кажется бесспорным мнение о том, что наиболее существенной составляющей является информация, которая долго накапливается и утрата которой невосполнима.
В качестве примера рассмотрим ситуацию, существующую в Зеленчукской астрофизической лаборатории. В этой лаборатории в горах в районе Нижнего Архыза установлен один из крупнейших в мире зеркальных телескопов (диаметр зеркала - 6 метров). Уникальные природные условия этого района Северного Кавказа позволяют максимально эффективно использовать возможности обсерватории. В самом Зеленчуке имеется крупнейший в России радиотелескоп. Комбинированное использование этих ресурсов в течение многих лет (более 10) позволило астрофизикам накопить уникальную информацию относительно разного рода космических объектов. К сожалению, компьютерные возможности лаборатории в первые годы ее существования были весьма ограничены, и поэтому накапливаемые данные хранились в основном на магнитных лентах. Известно, что любой магнитный носитель стареет, а магнитные ленты еще и пересыхают. В результате основной проблемой группы поддержки информационных ресурсов уже несколько лет является копирование старых магнитных лент на новые носители. Старые ленты часто не читаются, и приходится тратить громадные усилия и средства для их реанимирования. Здесь уже не до создания информационной системы. Успеть бы спасти информацию. Хотя, конечно, астрофизикам очень нужны информационные системы, позволяющие хотя бы частично автоматизировать огромные объемы работ по анализу и обобщению накопленной информации. Основной вывод, который можно сделать на основе этой нравоучительной истории, состоит в том, что если некоторая организация планирует долговременное накопление ценной информации, то с самого начала должны быть обдуманы надежные способы ее долговременного хранения. В частности, информация, накопленная Зеленчукской лабораторий, должна храниться вечно.
Конечно, уровень надежности и продолжительность хранения информации во многом определяются конкретными требованиями корпорации к информационной системе. Например, можно представить себе малую торговую компанию с быстрым оборотом, в информационной складской системе которой достаточно поддерживать информацию о товарах, имеющихся на складе, и об еще неудовлетворенных заявках от потребителей. Но кто знает, не потребуется ли впоследствии полная история работы склада с момента основания компании.
Следующей задачей, которую должно выполнять большинство информационных систем, - это хранение данных, обладающих разными структурами. Трудно представить себе более или менее развитую информационную систему, которая работает с одним однородным файлом данных. Более того, разумным требованием к информационной системе является то, чтобы она могла развиваться. Могут появиться новые функции, для выполнения которых требуются дополнительные данные с новой структурой. При этом вся накопленная ранее информация должна остаться сохранной. Теоретически можно решить эту задачу путем использования нескольких файлов внешней памяти, каждый из которых хранит данные с фиксированной структурой. В зависимости от способа организации используемой системы управления файлами эта структура может быть структурой записи файла (как, например, в файловых системах DEC VMS) или поддерживаться отдельной библиотечной функцией, написанной специально для данной информационной системы (если, конечно, не удастся найти подходящую функцию в одной из существующих библиотек). Ко второму способу решения проблемы пришлось бы прибегать при работе в среде ОС UNIX.
При использовании такого подхода информационная система перегружается деталями организации хранилища данных. При выполнении функций уровня пользовательского интерфейса информационной системе самой приходится выполнять выборку информации из файлов по заданному критерию. Некоторые системы управления файлами позволяют выбирать записи по простому критерию, например, по заданному значению ключа записи. Но, во-первых, такие возможности выборки всегда ограничены, и с большой вероятностью придется вынести хотя бы часть функций выборки в код самой информационной системы. Во-вторых, наличие нескольких файлов данных разной структуры неявно предполагает, что при выполнении некоторых функций информационной системы потребуется выборка согласованной (по заданному критерию) информации из нескольких файлов. Такие возможности никогда не поддерживаются файловыми системами.
Известны примеры реально функционирующих информационных систем, в которых хранилище данных планировалось основывать на файлах. В результате развития большинства таких систем в них выделился отдельный компонент, который представляет собой примитивную разновидность системы управления базами данных (СУБД). Самодельные СУБД - главный бич информационных систем. Поначалу кажется, что все очень просто: набор возможных запросов становится известным при проектировании информационной системы; для каждого типа запроса можно придумать эффективный способ выполнения запроса. После этого остается простая программистская работа, и специализированная СУБД готова. Однако, потом оказывается, что не все возможные запросы были учтены при проектировании. Бедный разработчик СУБД постоянно добавляет в нее новые функции, пока не решает создать общий язык запросов, на котором можно сформулировать любой запрос к базе данных соответствующей информационной системы. Через некоторое время в корпорации принимают решение разработать еще одну информационную систему, структуры хранимых данных которой, естественно, отличаются от тех, что были в базе данных первой информационной системы. Что же, делать еще одну специализированную СУБД? Нет, говорит начальство. У нас уже есть одна. Давайте попробуем применить ее. И это приводит к тому, что наивный самодельщик вынужден сделать простую (скорее всего, персональную) СУБД общего назначения, которая может получить из базы данных информацию о структуре ее файлов (т.е. в базе данных хранятся теперь еще и метаданные, определяющие структуры обычных данных, - схема базы данных), а также выполнить произвольный запрос к этой базе данных. В результате, даже если удается добиться работоспособности разработанной СУБД, это означает всего лишь изобретение еще одного велосипеда, поскольку СУБД такого уровня существует великое множество. Они дешевы и поддерживаются производителями.
До сих пор мы говорили о тех функциях информационной системы, которые требуют выборки данных из внешнего хранилища, например, производят отчеты. Но откуда берутся данные во внешнем хранилище? Каким образом поддерживается соответствие хранимой информации состоянию предметной области? Конечно, для этого должны существовать дополнительные функции информационной системы, которые обеспечивают ввод, обновление и удаление данных. Поддержка этих функций существенно повышает уровень требований к СУБД.
Если говорить о групповых или корпоративных информационных системах, то их наличие предполагает возможность работы с системой с нескольких рабочих мест. Некоторые из конечных пользователей изменяют содержимое базы данных (вводят, обновляют, удаляют данные). Другие выполняют операции, связанные с выборкой из базы данных. Третьи делают и то, и другое. Вся проблема состоит в том, что такая коллективная работа должна производиться согласованно и желательно, чтобы согласованность действий обеспечивалась автоматически. Под согласованностью действий мы понимаем то, что оператор, формирующий отчеты, не сможет воспользоваться данными, которые начал, но еще не закончил формировать другой оператор. Оператор формирующий данные, не сможет выполнить операцию над данными, которыми пользуется другой оператор, начавший, но не закончивший формировать отчет. Оператор, желающий обновить или удалить данные, не сможет выполнить операцию до тех пор, пока не закончится аналогичная операция над теми же данными, которую ранее начал, но еще не закончил другой оператор. При поддержке согласованности действий все результаты, получаемые от информационной системы, будут соответствовать согласованному состоянию базы данных, т.е. будут достоверны и непротиворечивы.
Подобные рассуждения вызвали появления понятия классической транзакции. Будем понимать под целостным состоянием базы данных информационной системы такое ее состояние, которое соответствует требованиям прикладной области (или, вернее, требованиям модели прикладной области, на основе которой проектировалась информационная система). Тогда классической транзакцией называется последовательность операций изменения базы данных и/или выборки из базы данных, воспринимаемая СУБД как атомарное действие. Это означает, что при успешном завершении транзакции СУБД гарантирует наличие в базе данных результатов всех операций изменения, произведенных при выполнении транзакции. Условием успешного завершения транзакции является то, что база данных находится в целостном состоянии. Если это условие не выполняется, то СУБД производит полный откат транзакции, ликвидируя в базе данных результаты всех операций изменения, произведенных при выполнении транзакции. Тем самым, легко видеть, что база данных будет находиться в целостном состоянии при начале любой транзакции и останется в целостном состоянии после успешного завершения любой транзакции.
Все развитые СУБД поддерживают понятие транзакции. Если информационная система базируется на СУБД такого класса, то для обеспечения согласованности действий параллельно работающих конечных пользователей достаточно при проектировании системы правильно связать операции информационной системы с транзакциями СУБД. Это относится уже к области проектирования, и мы подробно обсудим проблемы в следующих частях курса.
Еще одно небольшое замечание относительно транзакций. СУБД может очень просто обрабатывать транзакции, выполняя их последовательно. Этого достаточно, чтобы обеспечить согласованность действий "параллельно" работающих операторов. Но реальной параллельности в этом случае, конечно, не будет. СУБД выстроит всех пользователей в общую очередь и будет пропускать по-одному даже если они вовсе не конфликтуют по данным. Развитые СУБД так не работают. Они стремятся максимально перемешивать запросы и операторы изменения базы данных, поступающие от разных транзакций, с тем лишь условием, что конечный результат выполнения всего набора транзакций будет эквивалентен результату их некоторого последовательного выполнения. В мире баз данных такая политика СУБД называется политикой полной сериализации смеси транзакций. Очевидно, что полная сериализация транзакций достаточна для достижения согласованности действий теперь уже действительно параллельной работы операторов информационной системы. Но полная сериализация транзакций не всегда является необходимой для требуемой согласованности действий. Существуют модели ослабленной сериализации, которая допускает еще большую параллельность и вызывает меньшие накладные расходы.
На первый взгляд кажется, что понятие транзакции чуждо персональным СУБД, с которыми в любой момент времени работает только один пользователь. Однако рассмотрим еще раз упоминавшуюся задачу надежного хранения данных. Что это означает более конкретно? Теперь, после того, как мы ввели понятия целостного состояния базы данных и транзакции, под надежностью хранения данных мы понимаем гарантию того, что последнее по времени целостное состояние базы данных будет сохранено СУБД при любых обстоятельствах. Одно такое возможное обстоятельство мы уже упоминали: нарушение целостности базы данных при окончании транзакции. Традиционное решение - откат транзакции. Второй возможный случай - аварийное выключение питания, в результате чего теряется содержимое основной памяти, в буферах которой, возможно, находились измененные, но еще не записанные во внешнюю память блоки базы данных. Традиционное решение - откат всех транзакций, которые не завершились к моменту аварии, и гарантированная запись во внешней памяти результатов завершившихся транзакций. Естественно, это можно сделать только после возобновления подачи питания в ходе специальной процедуры восстановления. Наконец, третий случай - авария внешнего носителя базы данных. Традиционное решение - переписать на исправный внешний носитель архивную копию базы данных (конечно, нужно ее иметь), после чего повторить операции всех транзакций, которые были выполнены после архивации, а затем выполнить откат всех транзакций, не закончившихся к моменту аварии. С разными модификациями развитые СУБД обеспечивают решение этих проблем за счет поддержки дополнительного файла внешней памяти - журнала базы данных. В журнал помещаются записи, соответствующие каждой операции изменения базы данных, а также записи о начале и конце каждой транзакции. Файл журнала требует особой надежности хранения (пропадет журнал - базу данных не восстановишь), что обычно достигается путем поддержки зеркальной копии. Вернемся к началу этого абзаца. Разве надежность хранения данных не нужна персональным информационным системам, если, конечно, они не совсем примитивны? Как мы видели, надежности хранения невозможно добиться, если не поддерживать в СУБД понятие транзакции. К сожалению, до последнего времени в большинстве персональных СУБД транзакции не поддерживались (само собой отсутствовали и средства определения и поддержки целостности баз данных). Поэтому о надежности хранения информации в информационных системах, основанных на персональных СУБД, можно говорить только условно.
В корпоративных информационных системах по естественным причинам часто возникает потребность в распределенном хранении общей базы данных. Например, разумно хранить некоторую часть информации как можно ближе к тем рабочим местам, в которых она чаще всего используется. По этой причине при построении информационной системы приходится решать задачу согласованного управления распределенной базой данных (иногда применяя методы репликации данных). При однородном построении распределенной базы данных (на основе однотипных серверов баз данных) эту задачу обычно удается решить на уровне СУБД (большинство производителей развитых СУБД поддерживает средства управления распределенными базами данных). Если же система разнородна (т.е. для управления отдельными частями распределенной базы данных используются разные серверы), то приходится прибегать к использованию вспомогательных инструментальных средств интеграции разнородных баз данных типа мониторов транзакций.
Традиционным методом организации информационных систем является двухзвенная архитектура "клиент-сервер" (рисунок 1.1). В этом случае вся прикладная часть информационной системы выполняется на рабочих станциях системы (т.е. дублируется), а на стороне сервера(ов) осуществляется только доступ к базе данных. Если логика прикладной части системы достаточно сложна, то такой подход порождает проблему "толстого" клиента. Каждая рабочая станция должна обладать достаточным набором ресурсов, чтобы быть в состоянии произвести прикладную обработку данных, поступающих от пользователя и/или из базы данных. Для того, чтобы клиенты могли быть "тощими", а зачастую и для повышения общей эффективности системы, все чаще применяются трехзвенные архитектуры "клиент-сервер" (рисунок 1.2). В этой архитектуре, кроме клиентской части системы и сервера(ов) базы данных, вводится промежуточный сервер приложений. На стороне клиента выполняются только интерфейсные действия, а вся логика обработки информации поддерживается в сервере приложений. В следующих частях курса мы рассмотрим возможные технологии организации трехзвенных архитектур.
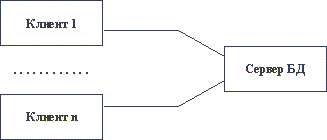
Рис. 1.1. Традиционная двухзвенная архитектура "клиент-сервер"
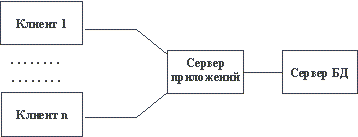
Рис. 1.2. Трехзвенная архитектура "клиент-сервер" с выделенным сервером приложений
Заметим, что некоторые черты трехзвенности могут присутствовать и в двухзвенной архитектуре. Если, например, используемый сервер баз данных поддерживает развитый механизм хранимых процедур (например, такой, как в Oracle V.7), то можно перебросить некоторую часть логики приложения на сторону баз данных. Заметим, что механизм хранимых процедур недостаточно полно специфицирован в стандарте языка SQL. Как только вы решаетесь использовать действительно развитые средства, то немедленно привязываете свою информационную систему к конкретному производителю серверов баз данных. Развязаться будет очень трудно.
И наконец, еще один класс задач относится к обеспечению удобного и соответствующего целям информационной системы пользовательского интерфейса. Более или менее просто выяснить функциональные компоненты интерфейса, например, какого вида должны предлагаться формы и какого вида должны выдаваться отчеты. Но построение действительно удобного и неутомительного для пользователя интерфейса - это задача дизайнера интерфейса. Простой аналог: при наличии полного набора качественной мебели хороший дизайнер сможет красиво оформить удобную для жизни квартиру (все на месте и под рукой). Плохой же дизайнер, скорее всего, добьется лишь того, что сможет запихнуть в квартиру всю мебель, а потом хозяину квартиры все время будет казаться, что у него слишком много ненужной мебели и ничего невозможно найти. Нужно отдавать себе отчет в том, что задача эргономичности интерфейса не формализуется. При ее решении не помогут никакие средства автоматизации разработки интерфейса. Такие средства облегчают только построение компонентов интерфейса. Построение же полного интерфейса - это творческая задача, при решении которой нужно учитывать требования эстетичности и удобства, а также принимать во внимание особенности конкретной области применения информационной системы.
На первый взгляд упомянутая задача кажется не очень существенной. Можно полагать, что если информационная система обеспечивает полный набор функций и ее интерфейс обеспечивает доступ к любой из этих функций, то конечные пользователи должны быть удовлетворены. На самом деле, это не так. Пользователи часто судят о качестве системы в целом исходя из качества ее интерфейса. Более того, эффективность использования системы зависит от качества интерфейса. Поскольку, как отмечалось выше, задача построения эргономичного интерфейса не формализуется, мы больше не будем затрагивать ее в этом курсе, а ограничимся рассмотрением вопросов построения компонентов интерфейса.
1.3. Проблемы построения ИС
Самой первой проблемой является проблема проектирования. Нельзя начинать техническую разработку, не имея тщательно проработанного проекта. Если начинать с решения наиболее очевидных задач, не обращая внимания на потенциально существующие, то такая система будет непрерывно находиться в стадии разработки и переделки.
Первой стадией проектирования должен быть анализ требований корпорации. Для этого на основе экспертных запросов необходимо выявить все актуальные и потенциальные потребности корпорации, которые должны удовлетворяться проектируемой информационной системой, понять какие потоки данных существуют внутри корпорации, оценить объемы информации, которые должны поддерживаться и обрабатываться информационной системой. Эта стадия, как правило, носит неформальный характер, хотя, конечно, очень важно сохранить полученную информацию, поскольку она должна входить в документацию системы. Существуют CASE-средства верхнего уровня, которые помещают полученные данные в общий репозиторий проекта и позволяют использовать их на следующих стадиях проектирования.
Следующая стадия проектирования - выработка концептуальной схемы базы данных, которая будет лежать в основе информационной системы. Сначала придется выбрать систему нотаций, в которой будет представляться концептуальная схема (правильнее было бы сказать - выбрать концептуальную модель). Таких нотаций существует великое множество, и хотя практически все они диаграммные (в духе ER-модели), они отличаются одна от другой. Заметим, что даже в случае использования некоторых CASE-средств вам все равно предлагается на выбор несколько нотаций. Заметим, что хотя, на взгляд автора, выбор нотации - дело вкуса (по возможностям они почти эквивалентны), это ответственный выбор. Концептуальное представление базы данных должно сохраняться как часть документации информационной системы на все время ее существования и будет использоваться при ее сопровождении и развитии.
Далее, с большой вероятностью в основе информационной системы будет лежать реляционная база данных. Несмотря на очевидную привлекательность объектно-ориентированных (ObjectStore, Objectivity, O2, Jasmin и т.д.) и объектно-реляционных (Illustra, UniSQL) СУБД, в ближайшие годы придется работать с хорошо отлаженными, развитыми, сопровождаемыми системами, поддерживающими стандарт SQL-92 (например, Oracle, Informix, CA-OpenIngres, Sybase, DB2). Просто потому, что должно пройти время, чтобы эти системы устоялись, обрели необходимую надежность, стали бы опираться на какие-либо стандарты и т.д.
Поэтому, с большой вероятностью, на следующей стадии проектирования понадобится на основе имеющейся концептуальной схемы произвести набор определений схемы реляционной базы данных в терминах языка SQL. К сожалению, несмотря на наличие стандарта языка, на этой стадии иногда невозможно не учитывать специфику сервера баз данных, который будет использоваться. Вы спросите, почему "к сожалению"? Да потому, что на самом деле мы еще не дошли до той стадии, когда конкретные особенности сервера действительно необходимо учитывать. В принципе, на данной стадии мы все еще находимся на уровне абстрактной реляционной модели. Но все дело в том, что когда производители серверов баз данных провозглашают соответствие своих серверных продуктов стандарту языка SQL-92, то в основном они понимают соответствие так называемому "ядру" стандарта. К сожалению, ядро стандарта не включает средств определения схемы базы данных. Поэтому диалекты SQL, реализуемые разными производителями, различаются в деталях соответствующих языковых средств. По этой причине необходимо внимательно изучить "целевой" диалект SQL, если трансляция концептуальной схемы в реляционную производится вручную (например, на основе методологии, предлагаемой компанией Oracle), или указать название используемого серверного продукта, если используется продукто-независимое CASE-средство (например, Silverrun).
На этой же стадии необходимо решить, какие таблицы будут реально хранимыми, а какие - представляемыми (view).
После того, как выработана общая реляционная схема базы данных, необходимо определиться с архитектурой системы. В частности, очень важно решить, какой будет база данных - централизованной или распределенной (другими словами будет ли использоваться только один сервер баз данных или их будет несколько). Если принимается решение о распределенном характере базы данных, то необходимо произвести соответствующую декомпозицию набора определений схемы базы данных. (Заметим, что, вообще говоря, принятие решения об архитектуре системы возможно и до выработки общей реляционной схемы базы данных. Тогда декомпозиция производится на уровне концептуальной схемы, а затем для каждой отдельной части концептуальной схемы создается реляционная схема в терминах языка SQL.)
Наиболее простым случаем декомпозиции является тот, когда образующиеся разделы базы данных логически автономны. В терминах концептуальной схемы это означает, что между разделенными сущностями отсутствуют прямые или транзитивные (через другие сущности) связи. В терминах реляционной схемы: ни в одном разделе не присутствует таблица, ссылающаяся на таблицу, которая располагается в другом разделе (рисунки 1.3 и 1.4). Если требование логической автономности компонентов распределенной базы данных выполнено, то дальнейшее проектирование можно производить для каждого компонента независимо.

Рис. 1.3. Распределенная база данных с логически автономными разделами
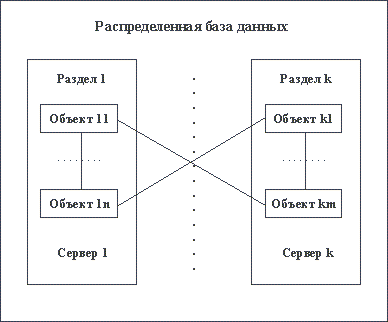
Рис. 1.4. Распределенная база данных с логически неавтономными разделами
В чем, собственно, состоит проблема распределенных баз данных с логически неавтономными разделами? Все дело в том, что любая связь, отраженная в схеме базы данных (между сущностями в концептуальной модели или между таблицами в реляционной модели), соответствует ограничению целостности, которое впоследствии должно сохраняться в базе данных и поддерживаться СУБД. В настоящее время общая технология организации распределенных баз данных (даже однородных, основанных на SQL) отсутствует. Некоторые производители решают эту задачу путем расширения функций сервера, и тогда, вообще говоря, в базе данных могут присутствовать ограничения целостности, содержащие ссылки на таблицы, которые располагаются в других разделах. В других системах задача управления распределенной базой данных решается на стороне клиента. В этом случае сервер, управляющий разделом распределенной базы данных ничего не знает о существовании других разделов и не может поддерживать ограничения целостности, включающие ссылки на объекты "чужих" разделов. Тогда целостность распределенной базы данных приходится поддерживать за счет написания явного кода в приложении. Другими словами, если невозможно произвести декомпозицию схемы общей базы данных в набор схем логически независимых разделов, то снова необходимо учитывать возможности используемого серверного продукта и двигаться дальше соответствующим образом.
Следующая стадия проектирования состоит в дополнении реляционных схем разделов распределенной базы данных определениями общих ограничений целостности, триггеров и хранимых процедур. На каждом из этих компонентов схемы следует остановиться отдельно. Начнем с общих ограничений целостности.
Язык SQL-92 позволяет определить ограничения целостности, относящиеся к общему состоянию базы данных и включающие ссылки на произвольное число таблиц. Семантика таких ограничений целостности может быть существенно шире, чем ограничения, задаваемые связями 1 к n и даже n к m (1-to-many и many-to-many). Поэтому часто ограничения общего вида не выводятся автоматически из концептуальной схемы базы данных и их приходится добавлять к реляционной схеме вручную. Для того, чтобы понять, какие ограничения общего вида должны быть включены в реляционные схемы разделов, приходится возвращаться к документу, содержащему анализ требований корпорации. Задача проектировщика состоит в том, чтобы, с одной стороны, выявить все необходимые ограничения целостности и, с другой стороны, не перегрузить базу данных необязательными ограничениями (любое дополнительное ограничение целостности вызывает дополнительные проверки на стороне сервера при выполнении операций изменения базы данных; проверки для ограничений общего вида могут быть весьма громоздкими). Конечно, если предполагается использование распределенной базы данных, то опять придется учитывать возможности сервера по части ссылок на объекты "чужих" разделов. Это может повлиять на выбор ограничений целостности и/или повлечь создание новой декомпозиции общей базы данных на разделы.
Триггер - это, фактически, хранимая процедура без параметров, содержащая оператор(ы) изменения базы данных и вызываемая сервером баз данных автоматически при совершении некоторого события (обычно под событием понимается выполнение определенного рода операторов изменения базы данных). Более точно, при определении триггера указывается вид события, возбуждающего триггер, условие его срабатывания и набор операторов, которые должны быть выполнены при выполнении условия. Имеется несколько практических областей применения механизма триггеров. Во-первых, триггеры позволяют поддерживать логическую целостность базы данных в тех случаях, когда пользовательская транзакция не может не нарушить эту целостность. Простой пример: информационная система отдела кадров. База данных состоит из двух таблиц:
СОТРУДНИКИ(НОМЕР_ПРОПУСКА, ФИО, НОМЕР_ОТДЕЛА, ЗАРПЛАТА)
ОТДЕЛЫ (НОМЕР_ОТДЕЛА, НОМЕР_ПРОПУСКА_НАЧАЛЬНИКА, ЧИСЛО_СОТРУДНИКОВ,
ФОНД_ЗАРПЛАТЫ)
Естественные ограничения целостности могут быть выражены следующим образом:
SELECT ЧИСЛО_СОТРУДНИКОВ FROM ОТДЕЛЫ =
SELECT COUNT (*) FROM СОТРУДНИКИ
WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
SELECT ФОНД_ЗАРПЛАТЫ FROM ОТДЕЛЫ <=
SELECT SUM (ЗАРПЛАТА) FROM СОТРУДНИКИ
WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
Предположим, что в отделе кадров работает всего два человека: начальник отдела кадров, который, естественно, имеет доступ к обеим таблицам и, в частности, является ответственным за выполнение операций смены начальника отдела или изменения фонда заработной платы. Второй человек - рядовой клерк, который по указанию начальника выполняет рутинную работу оформления новых сотрудников или увольнения ранее работавших. Естественно, что для выполнения его операций достаточно иметь доступ только к таблице СОТРУДНИКИ. Но тогда при выполнении любой из двух операций он просто не может не нарушить, по крайней мере, первое из упомянутых выше ограничений целостности. Конечно, можно внести соответствующие корректирующие действия в код прикладной программы, соответствующей операциям клерка, но тогда он неявно получит доступ по изменению ответственной таблицы ОТДЕЛЫ. Поэтому лучше определить триггеры вида
ON INSERT TO СОТРУДНИКИ
UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) + 1
WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
ON DELETE FROM СОТРУДНИКИ
UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) - 1
WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
Эти триггеры будут автоматически вызываться на стороне сервера баз данных и незаметно для клерка поддерживать логическую целостность базы данных. Вторая область применения триггеров - автоматический мониторинг действий конечных пользователей. Снова приведем очень простой пример. Начальник отдела кадров хочет знать, сколько операций в день выполняет его клерк. Тогда он должен сказать об этом на стадии анализа требований, и в результате, например, будет создана таблица
СТАТИСТИКА (ТЕКУЩАЯ_ДАТА, ЧИСЛО_ОПЕРАЦИЙ)
и триггер вида
ON INSERT, DELETE FROM СОТРУДНИКИ
IF EXISTS (SELECT * FROM СТАТИСТИКА WHERE ТЕКУЩАЯ_ДАТА = TODAY)
UPDATE СТАТИСТИКА SET
NEW (ЧИСЛО_ОПЕРАЦИЙ) = OLD (ЧИСЛО_ОПЕРАЦИЙ) + 1
WHERE ТЕКУЩАЯ_ДАТА = TODAY
ELSE
INSERT INTO СТАТИСТИКА (TODAY, 1)
Два замечания. Во-первых, в распространенном на сегодня стандарте SQL-92 механизм триггеров не специфицирован. В СУБД, которые поддерживают этот механизм, соответствующие языковые средства и их семантика различаются. Например, в Oracle V.7 для определения триггеров можно использовать процедурное расширение языка SQL PL/SQL в то время, как другие системы позволяют использовать только "чистые" конструкции SQL. Поэтому на текущий момент использование механизма триггеров неявно влечет сильную привязку к конкретному производителю. Во-вторых, как и в случае определения представлений и ограничений целостности, при определении триггеров необходимо учитывать распределенный характер базы данных и возможности сервера ссылаться на "чужие" таблицы.
Наконец, в базе данных могут храниться хранимые процедуры. Интересно, что в стандарте SQL-92 вообще не встречается термин "хранимая процедура". В стандарте специфицированы два способа взаимодействия прикладной программы с сервером баз данных. Первый, наиболее часто используемый способ состоит в встраивании операторов языка SQL в программу, написанную на одном из традиционных языков программирования. В самом стандарте определены правила встраивания SQL в программы, которые написаны на языках Си, Паскаль, Фортран, Ада и т.д. Второй способ основан на специфицированном в стандарте "языке модулей SQL". С использованием этого языка можно определить модуль, содержащий несколько процедур, каждая из которых соответствует некоторому параметризованному оператору SQL. В прикладной программе содержатся не операторы SQL, а лишь вызовы процедур (с указанием фактических параметров) из модуля SQL, с которым эта прикладная программа связана (правила связывания в стандарте не определены). Заметим, что стандарт не обязывает следовать каким-то конкретным правилам при реализации встроенного SQL или языка модулей. Посмотрим, что же делается в реализациях.
Что касается встроенного SQL, то во всех реализациях прикладная программа, содержащая операторы SQL, подвергается прекомпиляции с помощью соответствующего программного продукта, который входит в состав программного обеспечения сервера баз данных. В результате прекомпиляции всегда формируется текст прикладной программы на используемом языке программирования, уже не содержащий напрямую текста на языке SQL. Каждое вхождение оператора SQL в исходный текст программы заменяется на вызов некоторой процедуры или функции в синтаксисе включающего языка программирования. Основная разница между разными реализациями состоит в том, что из себя представляет эта процедура или функция. В большинстве систем (Oracle, Informix, Sybase, CA-OpenIngres) такая процедура представляет собой обращение к клиентской части СУБД с передачей в качестве параметра текста оператора на языке SQL. Вся обработка оператора, включая его грамматический разбор и выработку процедурного плана производится сервером во время выполнения прикладной программы (конечно, при повторном выполнении оператора сервер использует уже подготовленный план). Однако имеется и другой подход, исторически используемый компанией IBM в ее серии продуктов DB2. В DB2 прекомпилятор, выбрав текст очередного оператора SQL, сам обращается к серверу с запросом на компиляцию оператора. Сервер выполняет грамматический разбор и строит процедурный план выполнения оператора, сохраняя этот план в базе данных и привязывая к соответствующей прикладной программе. В качестве ответа от сервера прекомпилятор получает идентификатор, указание которого серверу повлечет выполнение соответствующего плана (грубо говоря, имя удаленной процедуры). Тогда в тексте прикладной программы появится вызов процедуры-переходника (stub), которая жестко привязана к соответствующей удаленной процедуре. Другими словами, более распространен метод динамической компиляции встроенного SQL (при выполнении прикладной программы), но имеются примеры реализаций со статической компиляцией встроенных операторов SQL (при прекомпиляции текста прикладной программы со встроенным SQL) (таблица 1.1.). В этом курсе мы не будем рассматривать сравнительные преимущества и недостатки динамического и статического подходов.
Таблица 1.1. Характеристики динамической и статической схем обработки встроенного SQL
| Вид подхода | Прекомпиляция | Выполнение |
| Динамическая схема | На стороне клиента | Компиляция и выполнение на стороне сервера |
| Статическая схема | На стороне клиента, компиляция на стороне сервера | Выполнение на стороне сервера |
Идея же процедур SQL, определяемых на языке модулей, повлекла внедрение во многие реализации механизма хранимых процедур. Хранимая процедура - это именованная, параметризованная конструкция, определяемая на языке SQL или некотором его расширении, встраиваемая в прикладную программу, компилируемая на стороне сервера во время обработки текста процедуры прекомпилятором. Выполняемый или интерпретируемый код хранимой процедуры сохраняется в базе данных, а сама она может быть вызвана из любой прикладной программы авторизованного пользователя (того, кто получил привилегию на выполнение этой процедуры) с указанием фактических параметров (рисунок 1.5). Пожалуй, механизмы хранимых процедур возникли прежде всего для того, чтобы обеспечить некоторое подобие статической компиляции встроенных операторов SQL в СУБД, которые поддерживают динамическую схему. Компания Oracle пошла дальше, разработав процедурное расширение SQL - язык PL/SQL. С использованием этого языка можно отсылать на сервер компоненты логики приложения. (Похоже, что в следующем стандарте языка SQL - SQL-3 - появится нечто похожее на PL/SQL.) Как мы отмечали выше, фактически это можно трактовать как первое приближение к трехзвенной организации информационной системы. Как правило, развитые СУБД поддерживают язык модулей SQL, но язык хранимых процедур обычно шире и не стандартизован. Поэтому с хранимыми процедурами нужно обращаться осторожно, если вы не хотите попасть в полную зависимость от конкретного производителя. Кроме того, в случае использования распределенной базы данных следует внимательно отслеживать возможности ссылок на таблицы, размещающиеся в разных разделах.
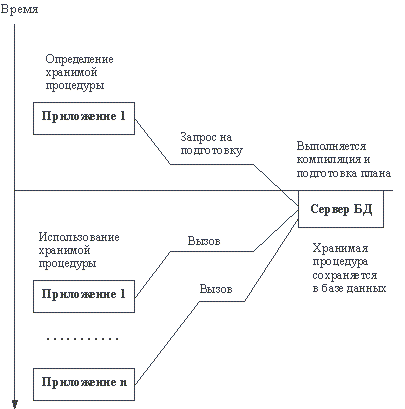
Рис. 1.5. Подготовка и использование хранимой процедуры
Наконец-то мы закончили с логическим проектированием базы данных информационной системы и можем приступать к следующим стадиям. По крупному, их осталось две: физическое проектирование базы данных; проектирование и разработка интерфейсов и обрабатывающей части прикладной системы. Эти две стадии могут выполняться параллельно.
Физическое проектирование включает два основных шага, первый из которых, как правило, не зависит от особенностей выбранного серверного SQL-ориентированного продукта, а второй зависит, причем критически. На первом шаге этой стадии определяется набор требуемых индексов. Для того, чтобы правильно выбрать этот набор, необходимо еще раз тщательно проанализировать требования корпорации и оценить, какие запросы будут выполняться наиболее часто. Это непростая задача, но нужно учитывать, что создание индекса на большой заполненной таблице (когда информационная система уже функционирует) требует значительного времени. Нужно также иметь в виду, что операторы определения (создания) и уничтожения индексов не определены в стандарте SQL. Хотя имеется негласное соглашение между производителями SQL относительно вида этих операторов, они все же могут различаться в разных системах. Кроме того, следует иметь в виду, что в большинстве систем индексы автоматически создаются для полей таблицы, которые объявлены первичным, возможными или внешними ключами.
Второй шаг состоит в определении областей внешней памяти, в которых будут храниться фрагменты базы данных. По этому поводу вообще невозможно дать какие-либо общие рекомендации, поскольку вопрос непосредственного размещения данных во внешней памяти является специфическим для каждой конкретной СУБД. Если нет человека, имеющего опыт администратора данной системы, единственный выход состоит во внимательном изучении руководства администратора. Обычно эти руководства содержат по меньшей мере описание того, как СУБД работает с внешней памятью. Конечно, окончательное решение остается на совести проектировщика.
Кстати, заметим, что, видимо, целесообразно выполнять работы, связанные с физическим проектированием, совместно со специалистом, который в дальнейшем будет выполнять функции администратора базы данных. Если на стадии физического проектирования такой специалист еще не назначен, необходимо тщательно документировать детали физического проекта.
Параллельно с физическим проектированием базы данных информационной системы может проводиться проектирование и разработка интерфейса системы и ее обрабатывающей части. В принципе, к этому моменту уже должно быть ясно, что вы хотите от интерфейса и какие функции должна выполнять система. Так что основной проблемой этой стадии является выбор инструментальных средств, которые позволят достаточно быстро произвести достаточно эффективную реализацию. Мы недаром два раза употребили слово "достаточно". Нужно понять, что важнее для корпорации - как можно быстрее ввести информационную систему в действие или добиться требуемого уровня эффективности.
Понятно, что в любом случае в наше время неразумно программировать интерфейсные функции вручную. Нужно использовать имеющиеся полуфабрикаты. Но здесь имеется большая возможность выбора: базовые библиотеки используемой оконной системы (например, X Toolkit Intrinsics в оконной системе X), универсальные инструментальные средства построения графического пользовательского интерфейса более высокого уровня (например, Motif или Tcl/Tk), языки и системы программирования 4-го поколения (например, PowerBuilder, Jam и т.д.). На наш взгляд, выбор определяется вкусом и привычками разработчика, а также общей ориентацией проекта. Например, если с самого начала проект был ориентирован на использование продуктов компании Oracle и ведется в интегрированной среде Designer/Developer 2000, то было бы странно покидать эту среду при разработке интерфейсов.
Что же касается обрабатывающих частей информационной системы, то все зависит от того, что они должны делать. Имеется масса примеров информационных систем, в которых вся обработка данных состоит в преобразовании их форматов при вводе и выводе, формировании отчетов и т.д. Такие функции можно фактически не программировать, поскольку любой 4GL может сгенерировать их автоматически по соответствующему описанию. Но если требуется более сложная обработка данных, то в любом случае потребуется явное программирование, и тогда уже неважно, на каком языке это программирование будет вестись. В частности, если вы используете Delphi для разработки интерфейсов, то для программирования разумно использовать Object Pascal (прекрасный язык, но пока жестко привязанный к Intel-платформам). В других случаях можно применять процедурную часть 4GL (обычно все они похожи на Basic) или Си/Си++ (как правило, стыковка 4GL с этими языками поддерживается).
Последнее замечание этого раздела. Мы описали одну из возможных схем проектирования и разработки информационной системы, представив весь процесс в виде последовательно выполняемых стадий. Если проект основывается на некотором интегрированном CASE-средстве с единым репозитарием, то эти стадии, вообще говоря, могут перемешиваться. Возможности использования интегрированных инструментальных средств при проектировании, сопровождении и реинжиниринге информационных систем будут рассмотрены в следующих частях курса.
1.4. Требования к техническим средствам, поддерживающим ИС
Естественно, что требования к техническим средствам определяются требованиями к информационной системе в целом. Какие бы информационные возможности не требовались сотрудникам корпорации, окончательное решение всегда принимается ее руководством, которое корректирует требования к информационной системе и формирует окончательное представление об аппаратной среде. На наш взгляд, имеются четыре возможных позиции руководства по поводу места информационной системы в корпорации: пессимистическая, пессимистически-оптимистическая, оптимистически-пессимистическая и оптимистическая.
Руководитетель-пессимист рассуждает следующим образом. Корпорации нужно продержаться хотя бы какое-то время. Без информационной системы это невозможно. Нужно выбрать самое дешевое решение, которое может быть реализовано максимально быстро. Руководитель не думает, что будет с корпорацией через два года (вернее, поскольку он пессимист, то думает, что, скорее всего, через два года корпорация просто не будет существовать или у нее сменится руководитель). При такой позиции наиболее подходящим является некоторое закрытое и законченное техническое решение. Например, это может быть полностью сбалансированная локальная сеть Novell с выделенным файл-сервером и фиксированным числом рабочих станций. Жесткость решения затем закрепляется соответствующим программным обеспечением информационной системы. Возможности расширения системы отсутствуют, реинжиниринг требует практически полной переделки системы.
Пессимистически-оптимистический руководитель не ожидает краха корпорации или своего собственного увольнения. Но он не надеется на изменение статуса компании, например, на появление зарубежных филиалов. Возможно, корпорация будет несколько развиваться, возможно, появятся новые виды бизнеса, возможно, увеличится число сотрудников. Но поскольку руководитель все-таки более пессимист, чем оптимист, то он не очень высоко оценивает шансы на развитие (дай-то Бог, чтобы за два года мы выросли на 20%). Такой позиции руководства больше всего подходит закрытое решение, обладающее ограниченными возможностями расширения. Например, это может быть локальная сеть Novell, в которой пропускная способность превосходит потребности имеющихся рабочих станций, а файл-сервер может быть оснащен дополнительными магнитными дисками. Если пессимизм руководителя окажется неоправданным, то корпорация встретится с потребностью сложного реинжиниринга.
Руководитель с оптимистически-пессимистической позицией ставит своей целью развитие корпорации. Он учитывает, что при развитии корпорации потребуется соответствующее развитие информационной системы, для чего, вообще говоря, может понадобиться сменить сервер баз данных. Он учитывает, что при развитии корпорации могут образоваться территориально разнесенные офисы, в результате чего, возможно, потребуется перейти к использованию распределенной базы данных. Он учитывает, в конце концов, что корпорации могут потребоваться развитые средства телекоммуникации с удаленными филиалами и/или партнерами. Пессимизм руководителя состоит только в том, что он заранее делает ставку на одного производителя (эти-то продукты я знаю). Например, может быть сделана установка на использование только Intel-платформ в среде Microsoft или только Alpha-платформ с VAX/VMS. Вообще говоря, это здоровый пессимизм, поскольку однородность аппаратно-программной среды существенно облегчает ее администрирование. Но как обидно будет этому руководителю, если ему предложат дешево купить прекрасный аппаратный продукт другого производителя. Придется либо отказаться, либо снова производить изнурительный реинжиниринг.
Наконец, руководитель-оптимист разделяет позицию оптимистически-пессимистического руководителя по поводу перспектив развития корпорации, но при этом желает сохранить возможность использования различных аппаратных платформ. Он стимулирует построение открытой корпоративной информационной системы, которая может неограниченно наращиваться за счет подключения новых сегментов сети, включения новых серверов и рабочих станций. Оптимистический подход, естественно, требует применения международных стандартов, что облегчает комплексирование аппаратного комплекса и обеспечивает реальное масштабирование информационной системы. Если начать построение корпоративной системы с сети Ethernet с использованием стека протоколов TCP/IP, то это начало оптимистического решения. В этом случае проблемы реинжиниринга практически отсутствуют (пока не сменятся стандарты).
Конечно, приведенная классификация является несколько утрированной. В жизни все гораздо сложнее. В частности, нельзя не учитывать влияние на руководителя технических специалистов. Чем грамотнее составляется обоснование на приобретение технических средств, тем обоснованнее оптимизм или пессимизм руководителя. Конечно, многое определяется возможными денежными затратами. Но стоит заметить, что оптимистический подход (по сути дела, это подход открытых систем) требует минимальных затрат на начальном этапе становления корпоративной системы (если, конечно, не учитывать необходимость приобретения хорошего программного сервера баз данных).
Главный вывод этого раздела состоит в том, что выбор технических средств для построения корпоративной информационной системы - это непростая задача, включающая технические, политические и эмоциональные аспекты. Ни в коем случае комплексирование аппаратуры нельзя пускать на самотек. Простой пример. Многие считают, что чем больше тактовая частота аппаратного сервера баз данных, то тем быстрее будет работать СУБД. Вообще говоря, это неправильно. Быстродействие любого сервера баз данных в основном определяется объемом основной памяти и/или числом процессоров. Другими словами, с одинаковой тщательностью нужно относиться и к выбору общей аппаратной архитектуры системы, и к выбору конфигурации каждого из ее компонентов.
Назад |
Содержание |
Вперед

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
